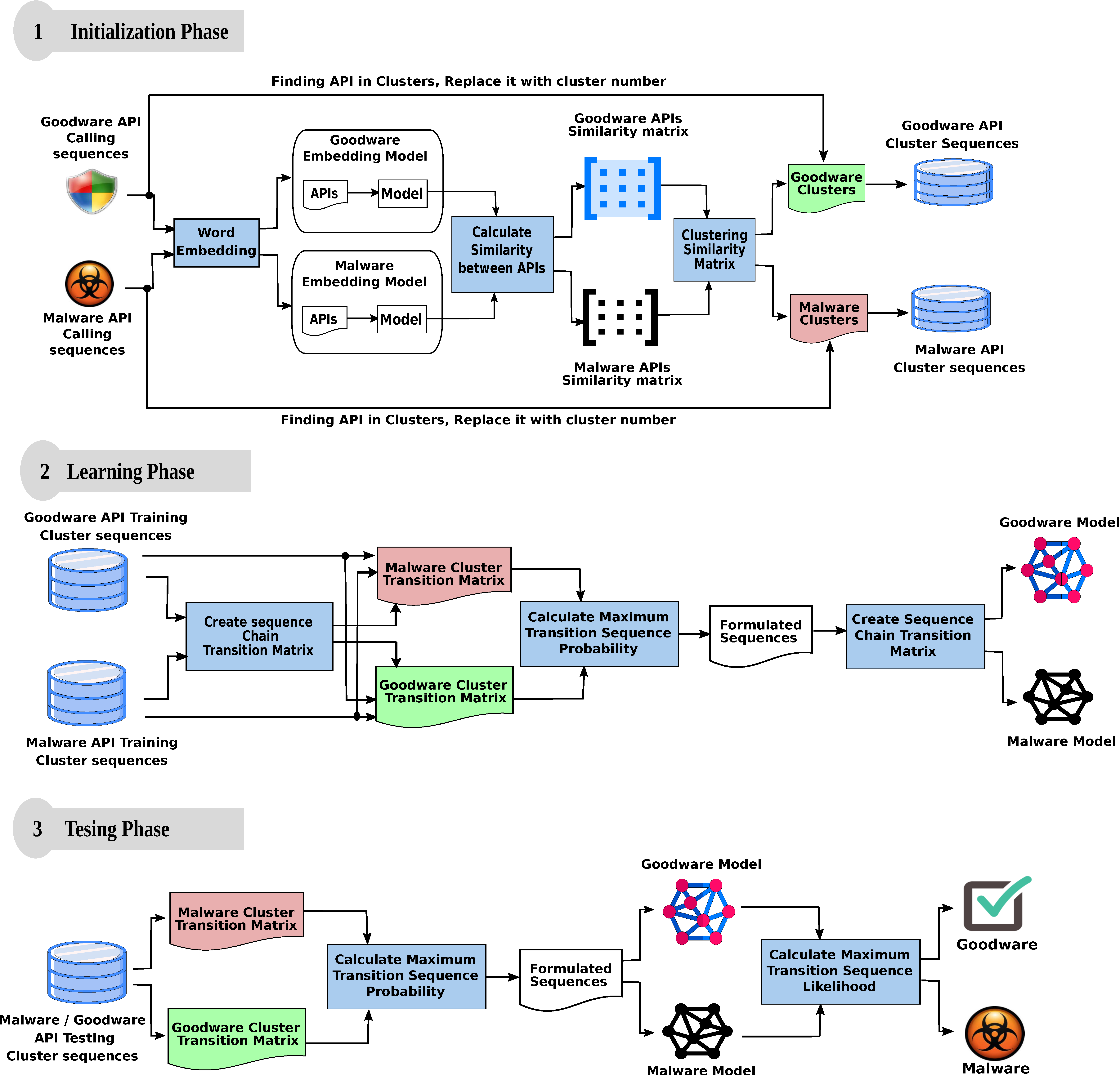
Throughout this section, we evaluate our model through various datasets using standard evaluation metrics. We show that our model could efficiently recognize whether a sequence of API calls leads to malicious activities or not.
4.3. Malware Detection Evaluation
In our experimentation, we split our data into 50% for training and 50% for testing. Throughout the training process, we implemented a modified version of the k-fold strategy called the random subsamples (with replacement). The implemented model is slightly different from the k-fold in that, during each iteration, the selection of the training and testing samples are performed at random. The superiority of random subsamples (with replacement) comes from its elastically to determine the number of iterations and the size of training and testing samples. Our training samples were populated at random while maintaining a condition of eliminating any duplication for samples that may exist in the training or testing samples.
Our model avoided the training bias through performing our experiments 10 times for each dataset. We calculated the average returned results for all experiments per each dataset to be its final evaluation measure. Experimental results demonstrated high proficiency in detecting and discriminating unseen samples.
Our model has a high accuracy detection rate with tiny false positives.
Table 5 shows that our method provides an average precision, recall, F-measure, and accuracy of 0.990, an average false-positive rate of 0.010, and an average false-negative rate of 0.010.
According to the malware detection accuracy measures,
Table 7 showed that our proposed work outperformed other peer dynamic analysis approaches that used the API call sequence. We compared our results with different approaches to prove its competency. Our model showed an average accuracy of 0.999, which is considered the most trustworthy one compared to other approaches.
4.4. Fake Goodware Detection
Despite our perceptible model accuracy in recognizing malware, there were particular types of malware samples falsely identified as goodware. When we investigated those kinds of examples, we discovered that malicious transitions are surrounded by many non-malicious ones. Therefore, those types of malware contain many non-malicious transitions compared to malicious ones. In other meaning, those kinds of malware samples are falsely acting as goodware ones. Our model identified these kinds of mimicry malware or fake goodware sequences through tracking their likelihood behavior.
Our experiments showed that most malware samples contain a majority of malicious transitions. However, we showed that malware transitions might also include partial non-malicious transitions, even if it does not affect its malicious collective likelihood behavior. However, in malware mimicry, we noticed that the API call sequence contains a significant amount of non-malicious transitions compared to malicious ones. In addition, we observed a continually changing behavior for those fake goodware samples during progressive transitions. Therefore, in our model, we used the behavior inconsistency as a sign, which indicates that a sequence is performing malicious activities.
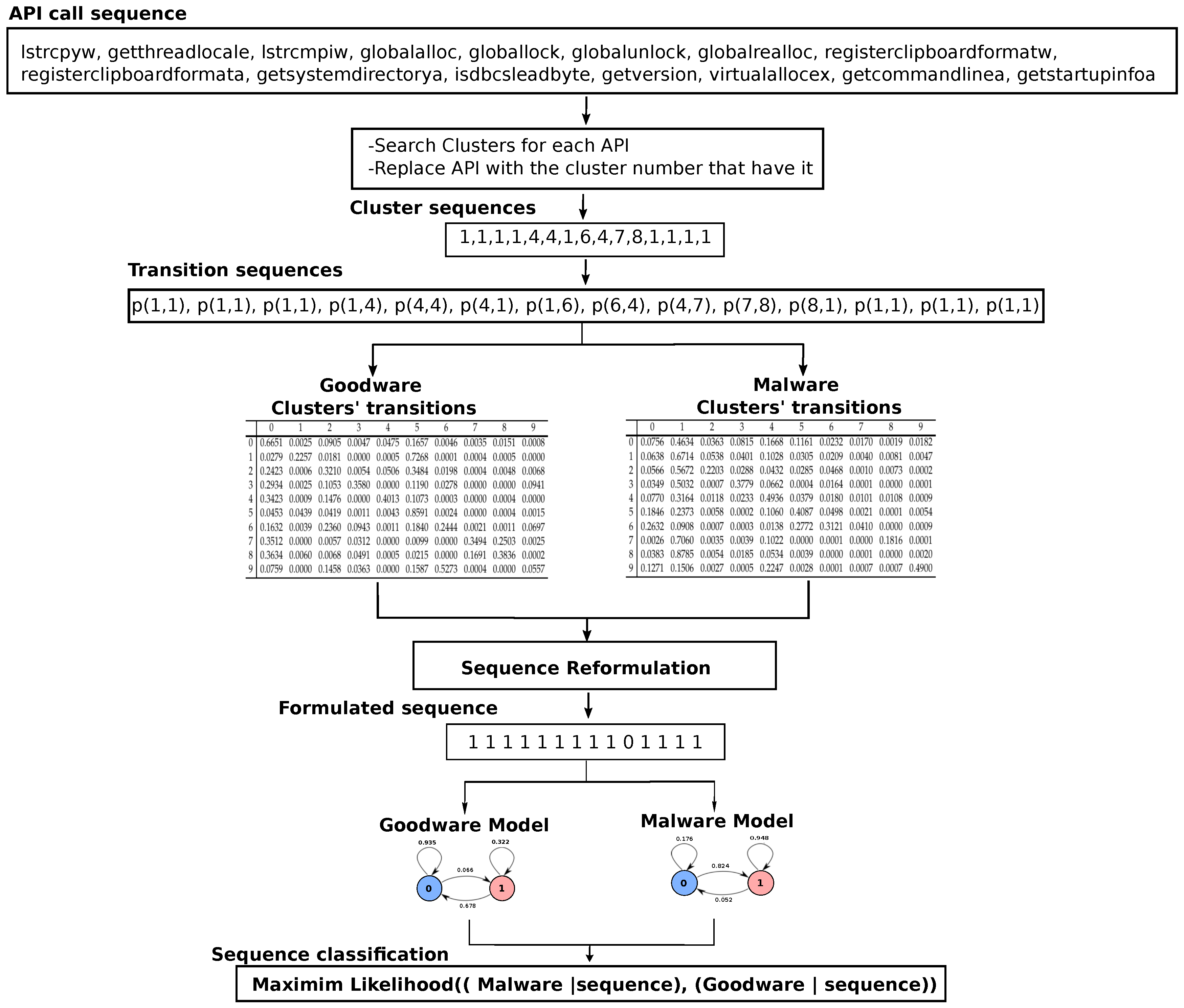
To clarify our opinion, we provided sample sequences in
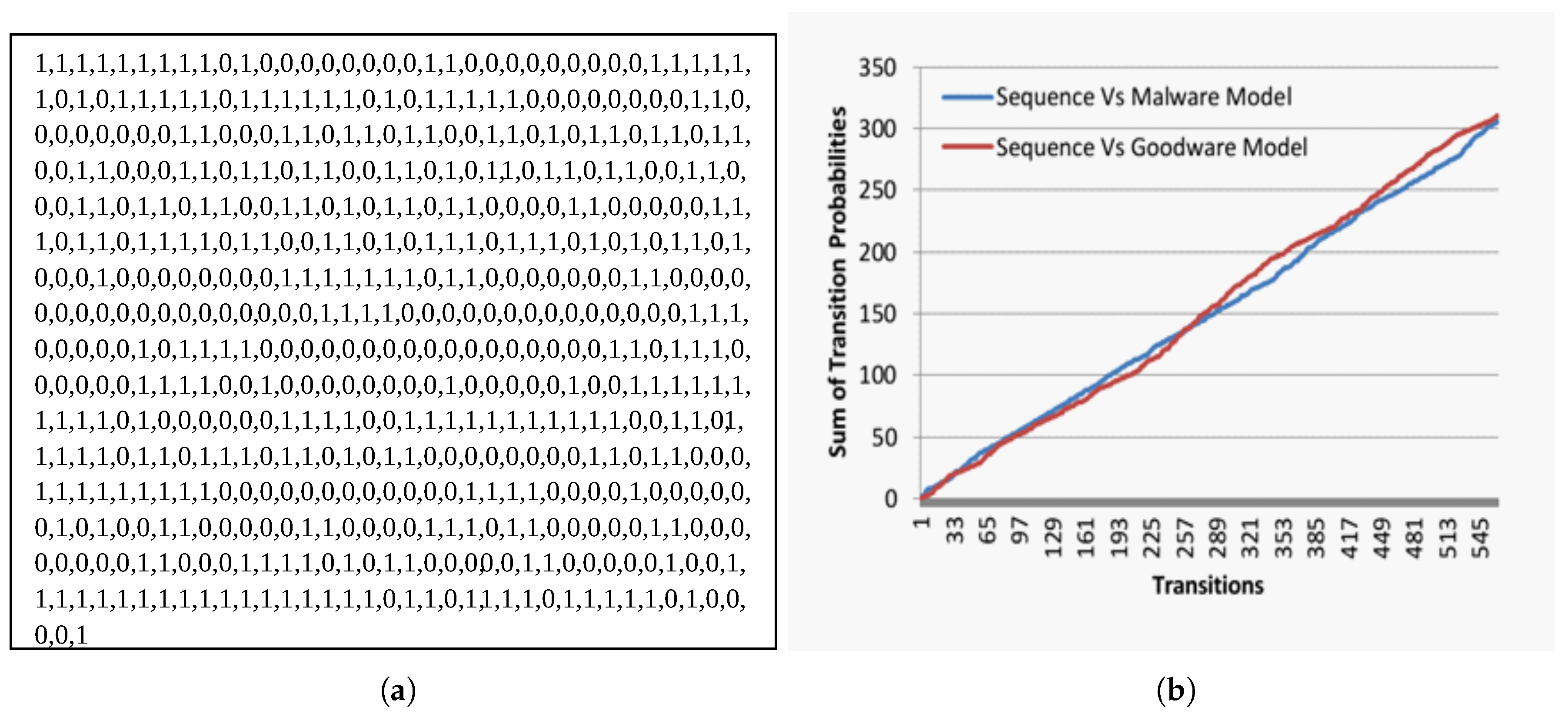
Figure 4a and
Figure 5a. Both sequences are malware transition sequences. However, our model correctly recognizes the first sequence in
Figure 4a as malware. In contrast, it misclassified the second one and identified it as a goodware. When we investigated the transition sequence in
Figure 4a, we observed that it contains a plurality of malicious transition sub-sequences (transitions of contiguous 1s) in comparison to the non-malicious sub-sequences (transitions of contiguous 0 s). However, in the second sequence shown in
Figure 5a, we found that it includes a plurality of non-malicious transition sub-sequences compared to the malicious sub-sequences.
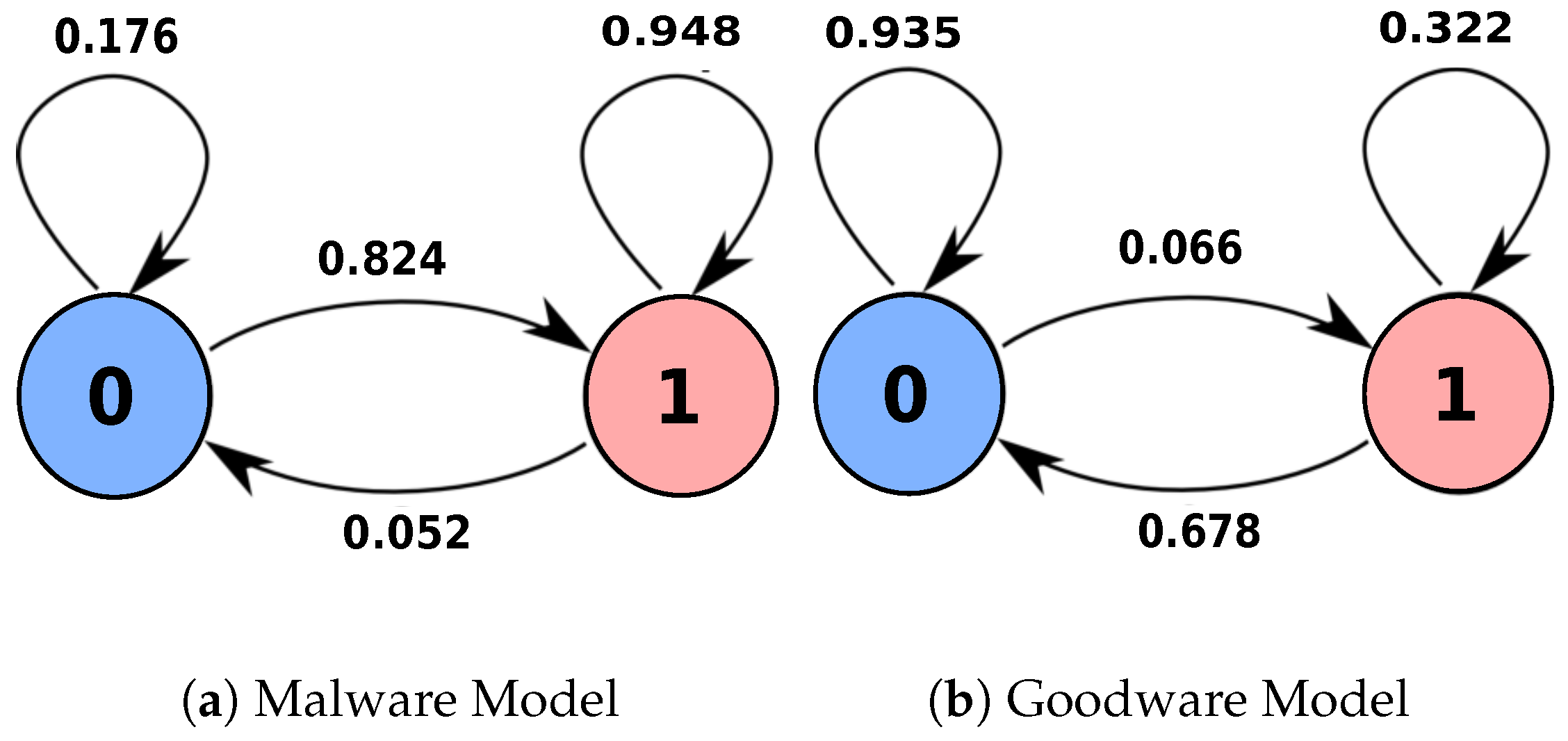
When we inspected both sequences’ behavior, as shown in
Figure 4b and
Figure 5b against our malware and goodware models in
Figure 2a,b, we noticed an exceptional distinction between both behaviors.
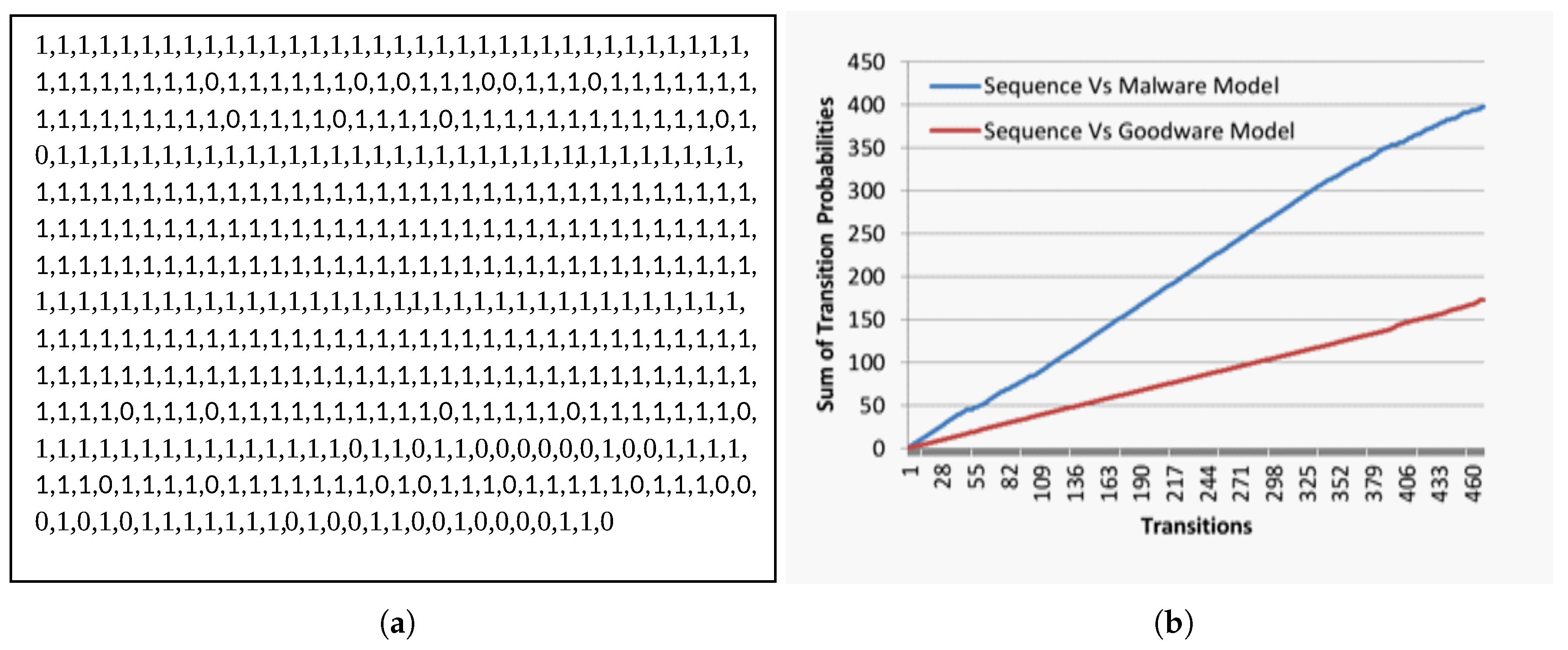
Figure 4b and
Figure 5b explain the relationship between the successive transitions sequence (
x-axis) and the associated collective evolutionary behavior likelihood (
y-axis) for sequences in
Figure 4a and
Figure 5a, respectively.
In
Figure 4b, we observed that, although both malicious and non-malicious behaviors are growing, they are not scaling at the same rate. In another meaning, there is a continual separation gap between both behaviors during the progressive transitions. In contrast, the behaviors in
Figure 5b converge and intersect at some progressive transition.
In our model, we utilized the
behavior monitoring (BM) as a heuristic that identifies whether a sequence retains or modifies its behavior while being examined by our model. Equation (
8) describes the behavioral intersection ratio where:
S denotes the input sequence,
n is the total number of transitions of a given sequence,
refers to cumulative transition probabilities for the sequence up to the i-th transition in malware and goodware models,
The exterior summation counts the events concerning the internal comparison between the two inner sums judged as true.
The behavior monitoring equation originally assumes that any given sequence is non-malicious until its behavior shows the opposite. Therefore, it continually tracks the sequence transitions’ likelihood probabilities’ in malware and goodware models simultaneously. When the sequence is malicious, as in the transition sequences in
Figure 4a, then the
accumulated malicious likelihood will be greater than its
accumulated non-malicious likelihood. In other words, the differences between both behavioral likelihood accumulations in real malware will always be
positive. However, in the case of fake goodware, as in the transition sequences in
Figure 5a, the differences between both behavioral likelihood accumulations are inconsistent and tend to be
negative during progressive transitions.
Our analysis concluded that a sequence is recognized as malicious if it has a cumulative changing behavioral ratio of 10% among its transitions. We examined our conclusion with malware false positives that emerged through our experiments in
Table 5. As clarified in
Table 8, our heuristic is capable of identifying malware mimicry sequences and recognizing them as a possible malicious sequence with an average detection accuracy of 0.993. The high accuracy in detecting mimicry malware adds another reliability dimension to our model in identifying malware.
Along with monitoring the sequence behavior, there is a necessity for estimating the malicious degree of the sequence. Therefore, we have adjusted with a minor change the heuristic that monitors the sequence behavior to perform as a behavior confidence factor (BCF). Through assessing the sequence behavior, the sequence is also given a behavioral evaluation. Equation (
9) describes how we evaluate the malicious ratio for a sequence where:
the numerator denotes the number of times where the inner comparison is evaluated as false,
denotes the total number of transitions in the sequence S.
To clarify the assessment evaluation process for the behavioral sequence, we also relied on the transition sequences in
Figure 4a and
Figure 5a.
Figure 4a contains 469 transitions, including (423 malicious transitions and 46 non-malicious transitions). According to Equation (
9), the behavior confidence factor will be
, which is interpreted as the sequence is malicious with a confidence factor of
. However, the transition sequence in
Figure 5a contains 562 transitions, including (232 malicious transitions and 330 non-malicious transitions). Accordingly, the sequence is malicious with a confidence factor
.
Even with the indecisive confidence factor for the sequence in
Figure 5a, the behavioral monitoring value is complementing the shortage that may occur when relying only on the behavioral confidence factor. Therefore, any sequence can be classified through the behavioral monitoring heuristic and assigned a confidence score through the confidence factor equation.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}