1. Introduction
Video Activity Recognition aims to automatically analyze and interpret particular events within video sequences. In the last years action recognition has gained interest, thanks to the growth of multimedia files availability and due to the amount of tasks it is useful for.
Currently, multimedia information generates large volumes of data, and this increases the need of developing automatic or semi-automatic systems which allow the labelling of video actions with different applications. For example, video cameras record data from different environments in real-time, which is useful, for instance, in security matters.
Many different domains can take advantage from video activity recognition, such as video security, video retrieval, or human-computer interaction. There are many different situations where a system that warns about suspicious actions in real time is highly beneficial, and since the enormous growth that multimedia data has experienced in recent years makes manual tagging tedious and sometimes impractical, video recognition can be used to perform annotation and indexing of videos. Furthermore, it can be useful to generate interactive systems for social purposes or for entertainment industry.
Identifying human actions in videos is a complex task. It is more challenging than image recognition, where a single frame represents the whole scene. In video recognition, a frame of a video where someone appears walking could also be a frame of a sequence of someone running, more frames are needed to see what action is taking place. The complexity of this task comes from the high intra-class variability that exists between the instances. This intra-class variability is caused by different factors, such as the diversity among people both in their appearance and in the style of execution of the action, the movements of the camera, the environment, which is usually affected by changes in lighting, shadows or occlusions, the viewpoint and the distance of the subject from the camera, and other factors, such as differences in resolution. Human actions are associated with a spatial and a temporal component, both random, so the performance of the same action is never identical.
In this paper, taking as a basis the work of Reference [
1], a new approach for video action recognition is presented, where Common Spatial Pattern (CSP) algorithm is used, a method which is normally used in Brain Computer Interface (BCI) for electroencephalography (EEG) systems [
2]. CSP is a dimensionality reduction technique which consists of finding an optimum spatial filter to separate a multidimensional signal into two classes, maximizing the variance of one of them while minimizing the variance of the other. In our approach input videos are represented as frame sequences and the temporal sequence of each pixel is treated as a signal (channel) to feed the CSP. After CSP is applied, some signals descriptors are selected for classification purposes. In classical CSP applications, only the signal variances and Linear Discriminant Analysis (LDA) classifier [
3] are used; in this research, variances, minimum, maximum, and interquartil range (IQR) are taken as descriptors, and LDA, K Nearest Neighbors (KNN) [
4] and Random Forests (RF) [
5] as classifiers.
The rest of the paper is organized as follows—First, in
Section 2 some related works are mentioned in order to introduce the topic. In
Section 3 a theoretical framework is presented to explain the proposed approach in detail. In
Section 4 the experimental setup is presented, the used data-set and the different experimentation carried out are explained thoroughly. To conclude, in
Section 5 the obtained results are shown and a comparison between our approach and another method is made.
2. Related Work
Different trends have been identified when it comes to video action recognition. Several approaches have been developed to deal with this problem along the years [
6,
7,
8]. The existing techniques can be divided in four main groups: the identification of space-time interest points, the representation of action sequence as 3D spatio-temporal volume, the use of motion information and the use of deep learning to process sequences of frames.
Space-time interest points extracted from video have been widely used for action recognition. For instance, the authors of Reference [
9] extract accumulated holistic features from clouds of interest points in order to use the global spatiotemporal distribution of interest points. This is followed by an automatic feature selection. Their model captures robust and smooth motions, where denser and more informative interest points are obtained. In Reference [
10] a compact video representation is presented, using 3D Harris and 3D SIFT for feature extraction. K-means clustering is used to form a visual word codebook which is later classified by a Support Vector Machine (SVM) and a Naive Bayes classifiers. The authors of Reference [
11] apply surround suppression together with local and temporal constraints to achieve a robust and selective STIP detection. A vocabulary of visual-words is built with a bag-of-video words (BoVW) model of local N-jet features and a Support Vector Machine (SVM) is used for classification.
In order to try to improve the activity recognition, RGB Depth (RGB-D) cameras are used (e.g., Microsoft Kinect, Intel RealSense), which are robust to illumination changes. The authors of Reference [
12] extract random occupancy pattern (ROP) semi-local features from depth sequences captured by depth cameras. These features are encoded with a sparse coding approach. The training phase of the presented approach is fast, robust and it does not require careful parameter tuning. In Reference [
13] both RGB and Depth Camera are used to extract motion features, generating a Salient Information Map. For each motion history image, a Complete Local Binary descriptor is computed, extracting sign, magnitude and center descriptors from the Salient Information Map. Canonical Correlation Analysis and dimensionality reduction are used to combine depth and RGB features. The classification is performed by a multiclass SVM.
Approaches which focus in motion information usually rely on optical flow or appearance. In Reference [
14] the authors propose dense trajectories to describe videos. From each frame dense trajectories are extracted and a dense optical flow algorithm is used to track them. To encode this information, the authors introduce a descriptor based on motion boundary histograms. They improve their work in Reference [
15] by taking into account camera motion, using SURF descriptors and dense optical flow to match feature points between frames. A human detector is also used to avoid inconsistent matches between human motion and camera motion. The authors of Reference [
16] decompose visual motion into dominant and residual motions. Then, they propose a new motion descriptor based on differential motion scalar quantities: divergence, curl and shear; the DCS descriptor, which captures additional information on the local motion patterns. The VLAD coding technique is used.
Recently, deep models have gained interest due to the good results they have obtained for image recognition. They are able to learn multiple layers of features hierarchies and automatically build high-level representations of the raw input. For video action recognition, Convolutional Neural Network (CNN) has been the most used model, extracting frames from videos and automatically classifying them by sending them as input features for the network. However, this way, temporal information is ignored and only spatial features are learnt. In Reference [
17] they propose a two-stream CNN, where both spatial and temporal information are incorporated. The input of the spatial network is composed by the frames extracted from videos, whereas that of the temporal network is formed by the dense optical flow. Then, these two CNNs are combined by late fusion. Recurrent Neural Networks (RNNs) have also been proven to be effective for video activity recognition, specially Long Short-Term Memory (LSTM) networks. The authors of Reference [
18] propose the use of a CNN along with a deep bidirectional LSTM (DB-LSTM) network. First, they use pre-trained AlexNet to extract deep features from every sixth frame of the videos. Then, sequence information from the features of video frames are learnt by the DB-LSTM. In Reference [
19] the authors present a two-steam attention based LSTM network, which focuses on the effective features and assigns different weights to the outputs of each deep feature maps. They also propose a correlation network layer to identify the information loss and adjust the parameters.
3. CSP-Based Approach
Similar to Reference [
1], the use of CSP is the main idea of the presented approach, although this time the signals to be processed are composed by temporal sequences of pixel. In this section, the used algorithm is explained, as well as the approach that is being introduced.
The Common Spatial Pattern (CSP) algorithm [
20], a mathematical technique applied in signal processing, has been widely used in Brain Computer Interface (BCI) applications for electroencephalography (EEG) systems [
21,
22,
23]. Research has also been published applying CSP in the field of electrocardiography (ECG) [
24], electromyography (EMG) [
25,
26] or even in astronomical images for planet detection [
27]. CSP was presented as an extension of Principal Component Analysis (PCA) and it consists of finding an optimum spatial filter which reduces the dimensionality of the original signals. Considering just two different classes, a CSP filter maximizes the difference of the variances between the classes, maximizing the variance of filtered signals of EEG of one of the targets while minimizing the variance for the other.
It must be clarified that, although the CSP algorithm has been used mainly with EEG problems, in this paper a new application is presented, the use of CSP filters for feature extraction in the human action recognition task. In our approach, each video represents a trial and each pixel is treated as an EEG channel, so the videos are taken as time series where the pixels are the channels which change over time. This is an application outside the usual field of analysis of physiological signals, somehow justified by the successful use in astronomical image processing [
27], but here it is extended to videos depicting actions.
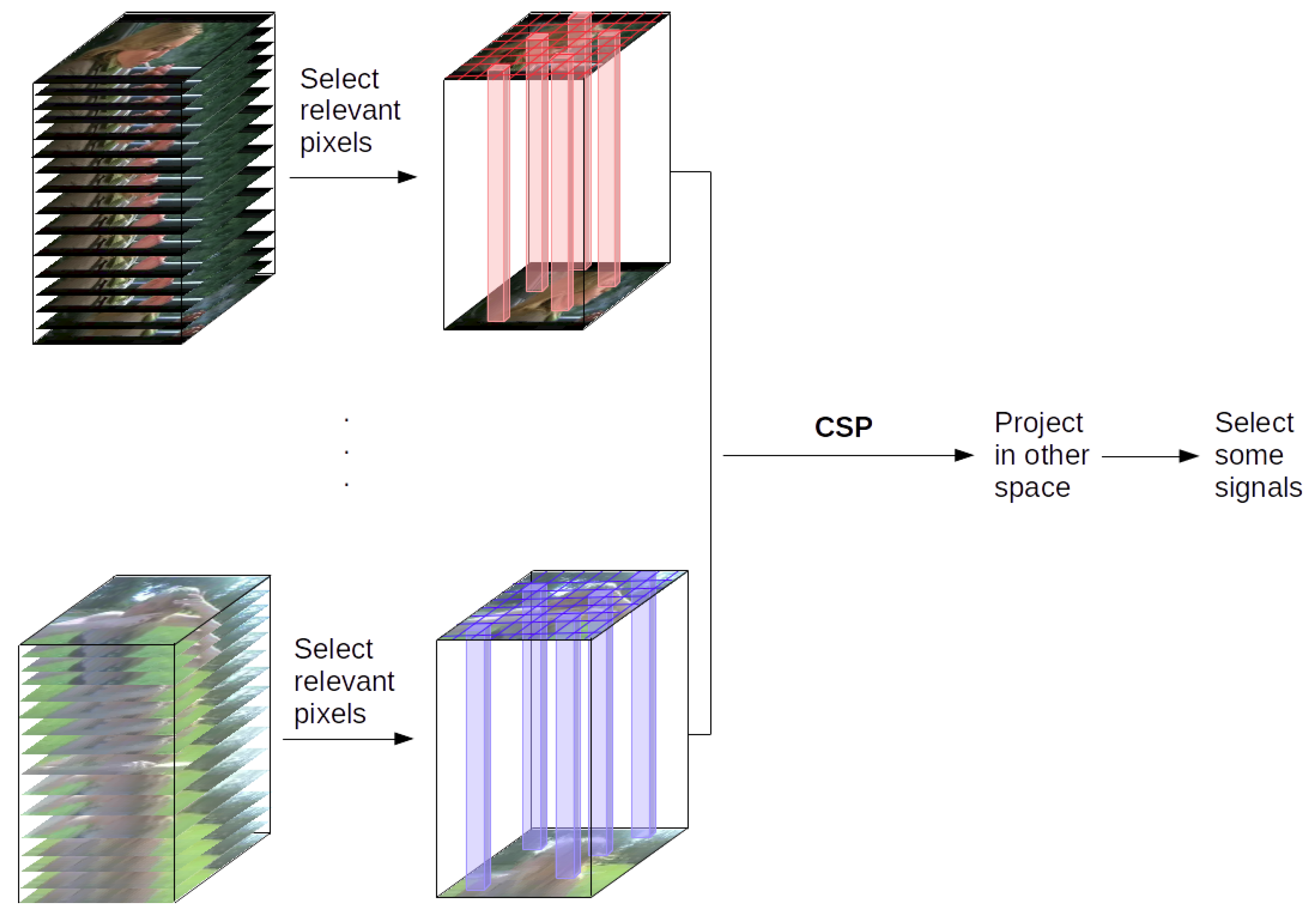
The full process can be seen in
Figure 1. The first step consists of selecting the most relevant pixels of the frame sequences, that will be used to feed the CSP. In order to select the most relevant pixels, those which have the biggest variance are chosen, that is, the pixels that change most in the frame sequence. Once the pixels are selected and, hence, the signals are formed, the CSP is computed in order to separate the classes according to their variance.
4. Experimental Setup
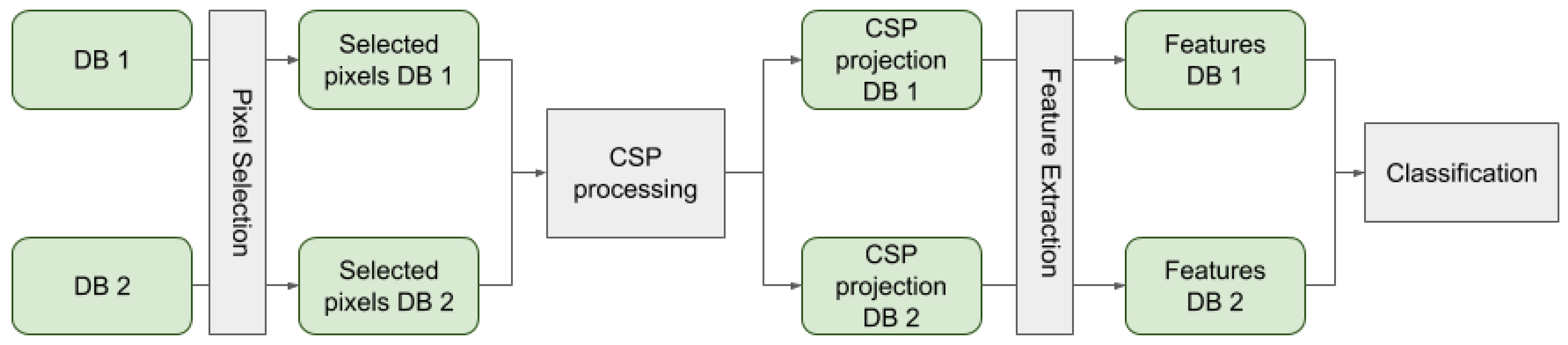
In this section the details of the experiments that have been carried out are explained. First, the database used is presented. Then, different modalities are introduced and, finally, the optical flow method is explained, which has been used to make a comparison with the CSP approach. In
Figure 2 a graphical overview of the presented approach is shown.
HMDB51
http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database [
28] is an action recognition database which collects videos from various sources, mainly from movies but also from public databases such as YouTube, Google and Prelinger Archives. It consists of 6849 videos with 51 action categories and a minimum of 101 clips belong to each category. The action categories can be divided into 5 main groups:
General facial actions: smiling, laughing, chewing, talking.
Facial actions with object manipulation: smoking, eating, drinking.
General body movements: cartwheeling, clapping hands, climbing, going up stairs, diving, falling down, backhand flipping, handstanding, jumping, pull-ups, push-ups, running, sitting down, sitting up, somersaulting, standing up, turning, walking, waving.
Body movements with object interaction: brushing hair, catching, drawing a sword, dribbling, playing golf, hitting something, kicking a ball, picking something, pouring, pushing something, riding a bike, riding a horse, shooting a ball, shooting a bow, shooting a gun, swinging a baseball bat, drawing sword, throwing.
Body movements for human interaction: fencing, hugging, kicking someone, kissing, punching, shaking hands, sword fighting.
Apart from the action label, other meta-labels are indicated in each clip. Those labels provide information about some features describing properties of the clip, such as camera motion, lighting conditions, or background. As some videos are taken from movies or YouTube, the variation of features is high and that extra information can be useful. The quality of the videos has also been measured (good, medium, bad), and they are rated depending on whether body parts vanish while the action is executed or not. It is worth mentioning that this extra information has not been used in this paper.
For our experiments only 6 classes have been selected due to the large amount of images. The selected classes are
brushing hair, cartwheeling, fencing, punching, smoking and
walking. To work with videos, their frames have been extracted in the first place. It has been decided to extract the same number of frames in every video of each class, so the largest video has been selected and the number of frames of the videos of that class is defined by it (in order not to cut any video and maybe lose the action performance). In
Table 1 the number of videos and number of frames are indicated for each class. In the case of HMDB51 as the number and length of the videos vary a lot, the number of frames changes in each class. However, the process to get the frames is the same, first the largest video is selected and it is used to determine the number of frames for the class. As some videos need to be extended to get the determined length, some of the frames of these videos are repeated.
Due to the difference between the number of videos of some of the classes, it has been decided to use the same amount of videos for both classes when performing the classification. The class with fewer instances indicates the number of videos in each of the experiments. For instance, when performing the classification between fencing (116) and smoke (109) 109 videos are used from each class, with a total of 218 videos. Since the class with the fewest instances has 103 videos, it was decided that it is a sufficient amount of instances to do the tests without having to apply any other more complicated balancing method.
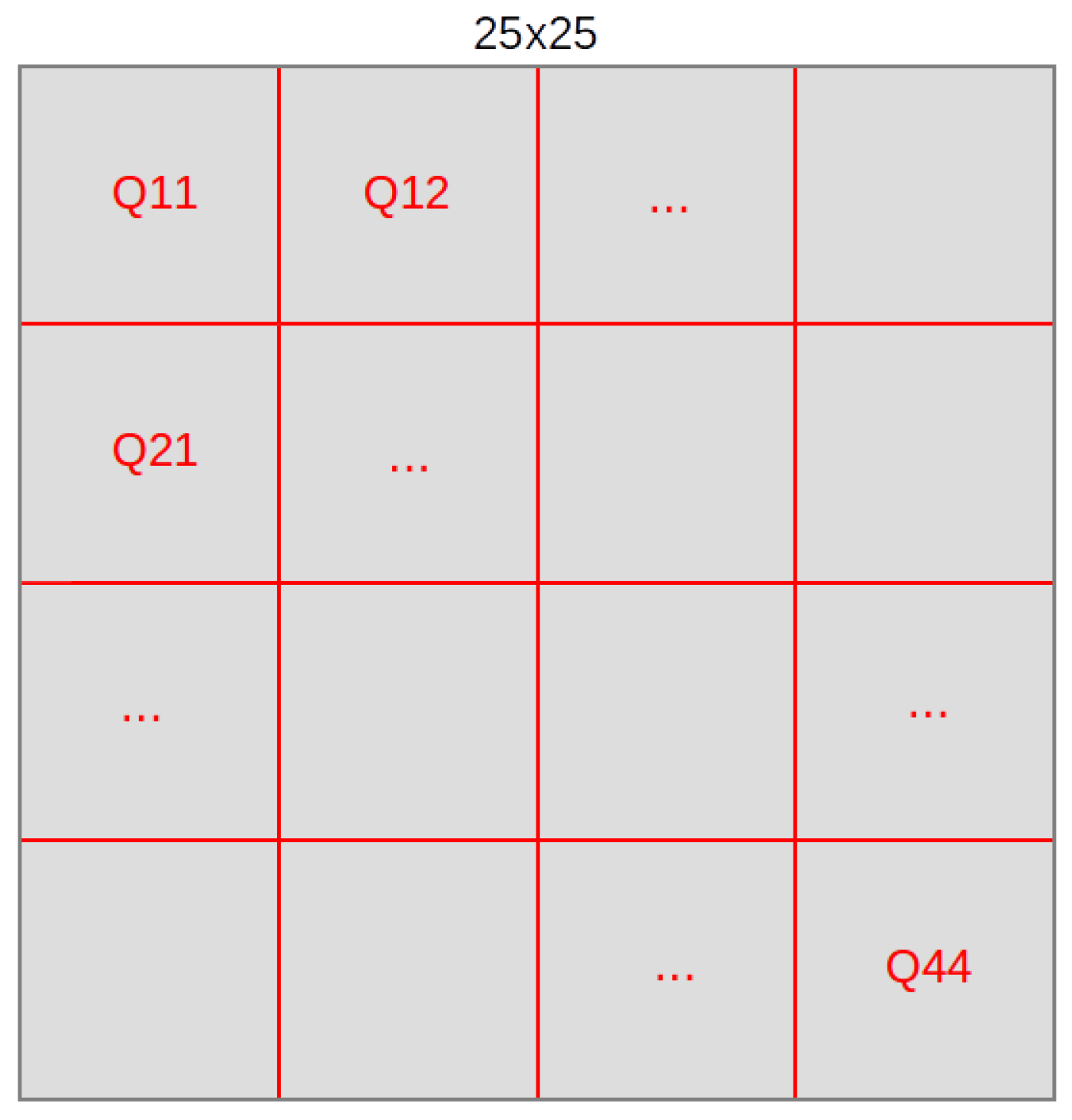
It must also be mentioned that in order to perform all the introduced experiments, the size of the images is set to 25 × 25 due to the computational requirements of CSP. Moreover, the used CSP method is implemented to work with just 2 classes, therefore all the tests have been carried out using pairs of classes, one versus one [
29].
4.1. Experiments
In this section the performed experiments are presented. They were developed using the technique introduced in
Section 3, where the main idea is to consider the temporal sequence of pixel
as a signal to be fed to the CSP. Taking that algorithm as a basis, different methods have been computed to make a comparison between them and see which one performs better.
Modalities
CSP algorithm was used in several modalities. The main change between the performed tests consists of deciding which pixels of the image are used to make the signals (channels) to calculate the CSP.
Once the relevant pixels are selected and the quadrant separation has been decided, the classification is performed using different features extracted after the CSP filter. The main focus of the experimentation is the use of the variances of the signals after applying the Common Spatial Pattern filter. However, apart from the variances, many other information can be extracted from these transformed signals. Hence, some experiments are performed with just the information of the variances and other experiments also with information about the maximum and minimum values of the signal and the interquartile range (). This information may be useful when performing the classification, and a comparison has been made between the results obtained by these two ways of performance:
4.2. Optical Flow
A comparison between the use of optical flow vectors and CSP features has been made, in order to analyze which features provide the best information about the action of the videos.
There are some algorithms which compute the optical flow. In this paper the OpenCV implementation of Gunnar Farneback’s algorithm [
30] is used. It provides a dense optical flow, which means that it calculates the optical flow for every point of the image. Dense techniques are slower but can be more accurate than sparse ones, which only compute the optical flow for some points of interest of the image. The result of Farneback’s method is a two dimensional array containing the vectors which represent the displacement of each point of the scene.
After having calculated the optical flow for every pixel, the vectors are divided into 10 bins and, according to the gradient direction of each pixel, a histogram is created. To create the histogram, the directions are separated in 8 stripes as can be seen in
Figure 5. The features that are then trained are taken from this information.
Once the features for each video have been obtained, the classification is performed.
5. Experimental Results
After explaining how the process has been defined, the experimental results are presented.
There are seven different accuracy results for each pair of classes:
HOF: the results obtained with the optical flow vectors as features.
Variance: after calculating the CSP, only the variances are taken as features.
- (a)
q = 3 : 6 (2*q) variance values are used.
- (b)
q = 5 : 10 (2*q) variance values are used.
- (c)
q = 10 : 20 (2*q) variance values are used.
More info: after calculating the CSP, apart from the variances, the minimum, the maximum and the IQR values of the curve are also taken as features.
- (a)
q = 3 : 6 (2*q) variance values are used, plus three additional features (min, max, IQR).
- (b)
q = 5 : 10 (2*q) variance values are used, plus three additional features (min, max, IQR).
- (c)
q = 10 : 20 (2*q) variance values are used, plus three additional features (min, max, IQR).
Variable q indicates how many feature vectors are considered in the projection, sorting the feature vectors of the spatial filter by variance the q first and q last vectors are selected. Therefore, a feature vector of dimensionality is obtained after applying CSP. Exactly, q first and q last vectors are used, which yield the smallest variance for one class and simultaneously, the largest variance for the other class.
The results for classifiers KNN, LDA and RF can be seen in
Table 2,
Table 3 and
Table 4, respectively. In each table the accuracy values obtained for every pair of the selected classes of HMDB51 database are presented, with the best values in bold. These results have been obtained by dividing the images in sixteen quadrants and getting the 25 pixels that change the most over time (the ones with the greater variance) for each quadrant, taking into account 400 pixels (channels) out of 625 (25 × 25).
Analyzing the results, it can be seen that the KNN classifier obtains the worst results. The other two classifiers, LDA and RF, achieve more similar results, although results with RF classifier are, in general, better. That is, for most pairs of classes, the KNN classifier gets the lowest accuracy values. The best accuracy for each pair is sometimes achieved by LDA and other times by RF, RF being the one which gets the best outcomes most of the times.
Regarding the feature extraction techniques, there is not a clear winner. The best results are highlighted in the mentioned tables. As it can be seen, depending on the targets and the classifiers, one technique or the other is preferred. There is not much difference between the use of the different features. As the obtained results are not clear enough to determine which features are better to use, a statistical test is performed to compare them.
Before performing the comparison, another aspect of the classification must be mentioned, the target classes. Depending on the classes that are being classified, the results may vary, because some pairs can be more distinguishable than others. For instance, the pair brush hair and cartwheel classes get high accuracy values for every technique and algorithm, with a mean of 0.95. However, other classes such as walk are more difficult to discriminate, no matter what algorithm, technique or even what class it is compared with. This could be due to the videos related to the class, since they can be confusing and the information may not be well represented. It must also be mentioned that when the resolution of the images is 25 × 25 the obtained results are surprisingly good.
In
Table 5 a summary of the results is presented. For each classifier, the results are divided in
variance,
more info and
HOF. The value of
best is calculated with the mean of the best values of every pair of classes. However, the
mean best value is the mean of the results of the configuration which gets the best mean result calculated with every pair of classes. The
best value is an optimistic summary, due to the fact that only the best values are taken into account, while the value presented in
mean best is more realistic. As the
HOF method only has one value per pair of classes (because it does not have the
q parameter), the mean between these values is the value indicated in the table. Looking at the results, it can be seen that RF classifier gets the best values. Besides, when more information is used, better values are obtained.
It can be observed that when just variance is used, LDA gets the worst results and, furthermore, when more information is used, KNN is the worst with a remarkable difference. Regarding the methods, it can be observed that more info and HOF methods get more similar results than variance methods, at least for some of the classifiers.
Comparison
Deciding whether our approach is better than the Histogram of Optical Flow is not trivial and can not be assumed by the obtained results due to the lack of clear differences. For that reason, a statistical test needs to be performed to determine if there is a difference between the approaches presented and if the test indicates that a difference exists, we could determine which model is better by the individual results.
The statistical test that has been used is the Friedman Test. The Friedman Test is used when the data is dependant and it can be considered as an extension of Wilcoxon signed-rank test for more than two groups. The Friedman Test is computed this way:
When applying this test, the null hypothesis is that there are no differences between the tested groups. As in Equation (
3), if the calculated probability is lower than the significance level, the null hypothesis is rejected, which indicates that at least 2 of the tested groups are significantly different from each other. In our approach, the hypotheses are defined this way:
The dependant variable is formed by the accuracy values obtained with each model, the grouping variable is the definition of the models and the blocking variable the ranking of the models, from 1 to 15 in our case.
After computing the Friedman Test, the obtained results indicate that there is evidence that at least two of the tested models are different (
,
p-value
), therefore the null hypothesis is rejected. Although it has been proven that a difference exists between the tested models, a post-hoc analysis is required to determine which groups are significantly different from each other. To do so, we have used the Nemenyi test [
31].
In
Table 6 the obtained
p-values can be seen. As our objective is to compare our results to the ones achieved by the Histogram of Optical Flow method, the values that are presented in
Table 6 are specifically these comparisons. The names of our approaches are defined by the regular expression of Equation (
4).
where 3, 5, 10 indicate the
q value, _var indicates if just the variance is taken as feature and KNN, LDA or RF define the algorithm that is used to create the model.
In the obtained results most of the p-value are not significant. However, there are some of them that indicate an evident difference between the models. The values in green are significant (<0.05) and the values in red are very significant (<0.01). There are a total of eleven pairs where a significant differences have been detected.
Referring to the original values, we observe that HOF-RF beats the CSP approach five times, while CSP-RF beats HOF-LDA three times.
It is not surprising to obtain better results with HOF-RF model, because the Random Forest classifier achieves better results than Linear Discriminant Analysis or K-Nearest Neighbors algorithms. Thus, in this case the difference and the adequacy of the Histogram of Optical Flow models is more related to the selected algorithm than to the features that are used to train the models.
As in the previous explanation, the CSP-RF against HOF-LDA results can be related to the selected algorithm without taking into account which features are used to train the models.
CSP3-LDA and HOF-LDA, p-value .
CSP5-LDA and HOF-LDA, p-value .
CSP10-LDA and HOF-LDA, p-value .
However, in the above three comparisons the same algorithm is used, Linear Discriminant Analysis, so in these cases, the significant differences are due to the selected features. Analyzing the performance of these models, it can be seen that CSP models beat HOF models, the features extracted by CSP are better for LDA classification than HOF features. In conclusion, our approach gets better results than Histogram of Optical Flow approach for at least one classification algorithm.
The rest of the comparisons do not show significant differences and they are considered as the same. However, our approach achieves better outcomes for some cases and maybe by carrying out different tests, the results would improve.
6. Conclusions
In this paper, a new approach for human activity recognition task is presented. It consists of the application of CSP (normally used in EEG systems) as feature extraction method before performing the classification. The resolution of the used videos is low (images of 25 × 25) in order to complete different tests. After getting the results, HOF features are extracted and new models are created to compare them to the results obtained by the CSP method.
As previously mentioned, our approach gets good results taking into account the resolution of the images. Furthermore, after performing the statistical test, it has been shown that, at least for one of the methods, CSP features are better than HOF features.
As future work other databases could be used, or the extra information provided by HMDB51 data-set could be taken into account, since apart from the action label, other meta-labels are also indicated in each clip. This information could be useful to make some preprocessing before the feature extraction method. Besides, the resolution of the images could be improved if more computational capacity was obtained, doing tests with different sizes of images (25 × 25, 40 × 40, 60 × 60, …). In our approach three different classifiers have been used, but in the future more classifiers or even deep learning techniques could be applied after doing the feature extraction with the CSP method.
In conclusion, it is shown that with a simple method normally used for other tasks acceptable results can be obtained, without having to use very complicated ideas to achieve our goals.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}