Time Series Forecasting of Agricultural Products’ Sales Volumes Based on Seasonal Long Short-Term Memory

Abstract
:1. Introduction
2. Literature Review
3. Materials and Methods
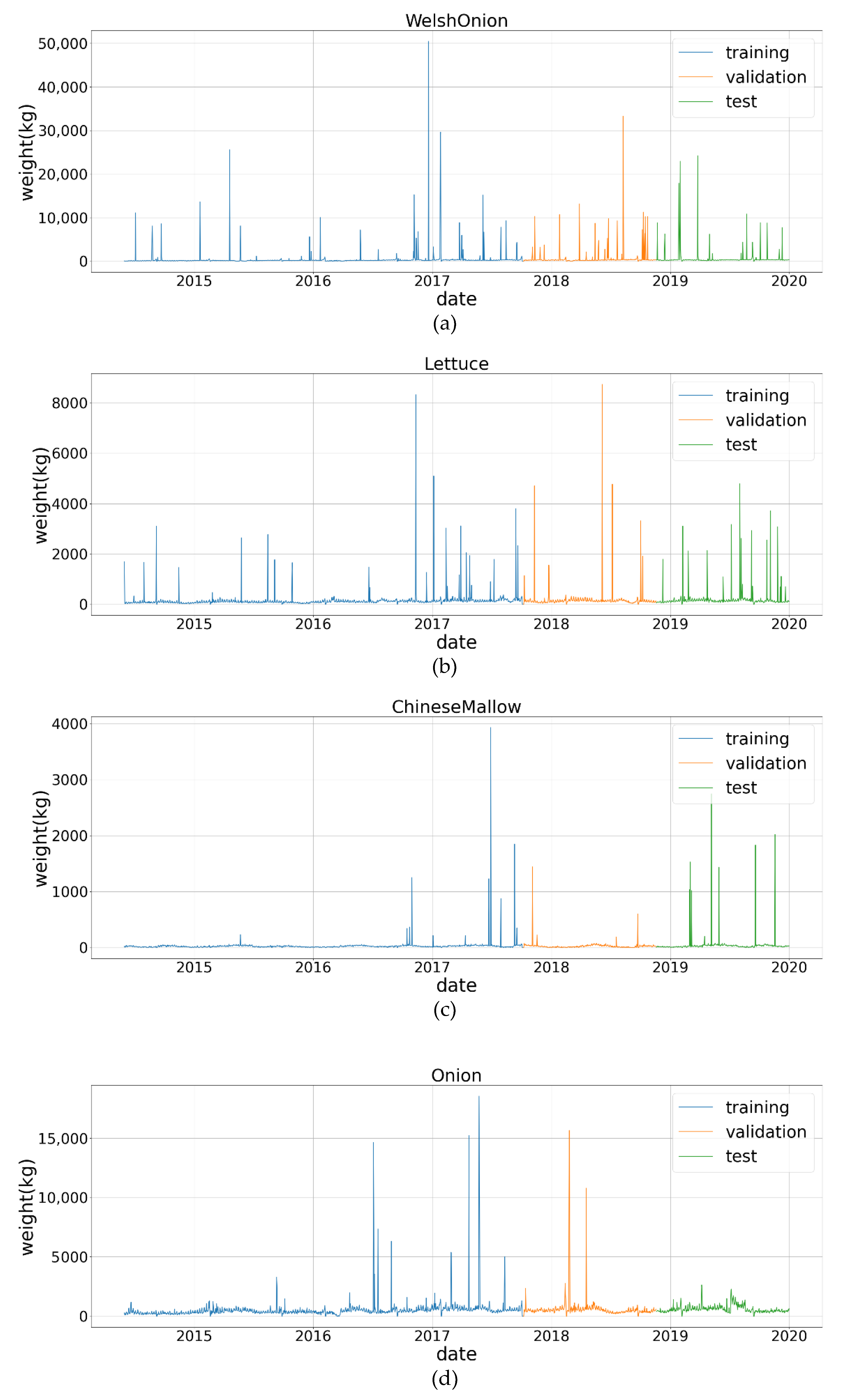
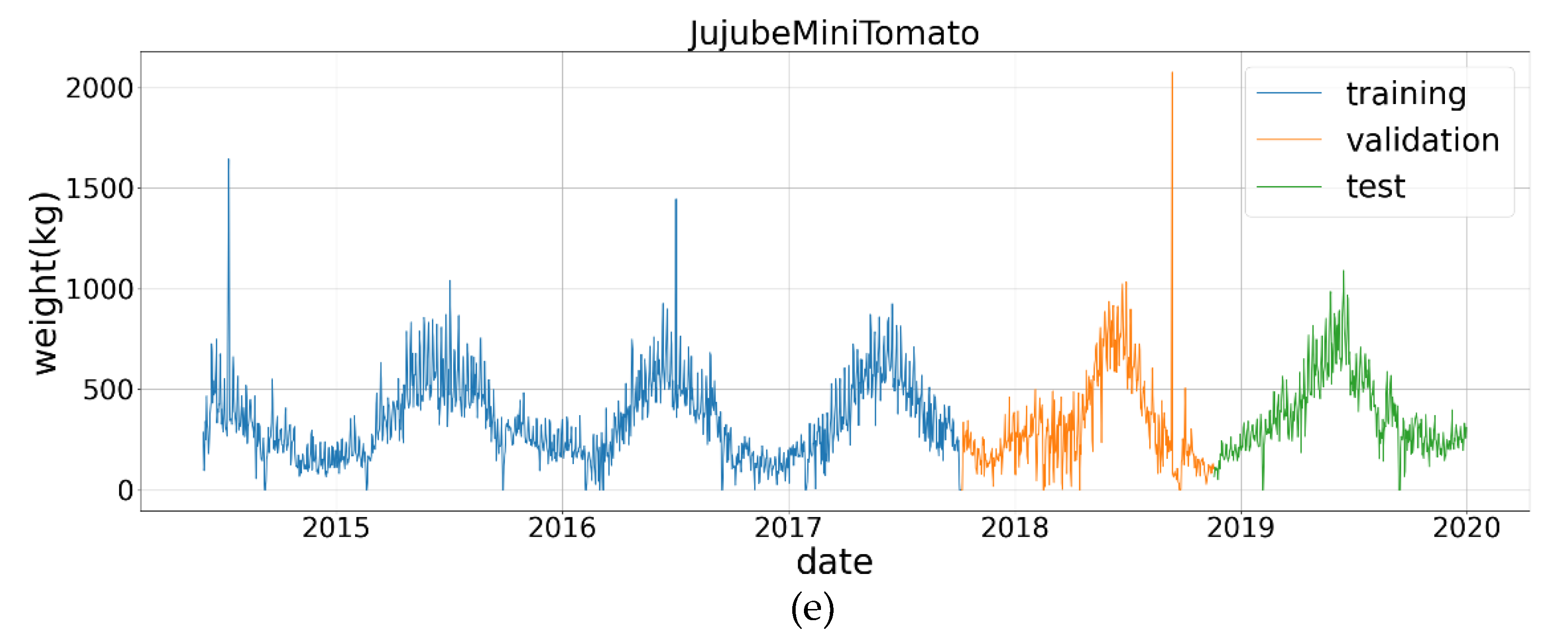
3.1. Data
3.1.1. Data Collection and Observations
3.1.2. Data Preprocessing
3.2. Forecasting Models
3.2.1. AutoArima
3.2.2. Prophet
3.2.3. Long Short-Term Memory
3.2.4. Seasonal Long Short-Term Memory
4. Experimental Results and Discussions
4.1. Experimental Environments
4.2. Performance Comparisons
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Huchet-Bourdon, M. Agricultural Commodity Price Volatility: An Overview (No. 52); OECD Food, Agriculture and Fisheries Papers; OECD Publishing: Paris, France, 2011. [Google Scholar] [CrossRef]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldu, F.X. A review on the practice of big data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldu, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Kurumatani, K. Time series forecasting of agricultural product prices based on recurrent neural networks and its evaluation method. SN Appl. Sci. 2020, 2, 1434. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Z.; Li, X.; Zhou, H. Artificial bee colony-based combination approach to forecasting agricultural commodity prices. Int. J. Forecast. 2019. [Google Scholar] [CrossRef]
- Ahmad, A.; Javaid, N.; Mateen, A.; Awais, M.; Khan, Z.A. Short-term load forecasting in smart grids: An intelligent modular approach. Energies 2019, 12, 164. [Google Scholar] [CrossRef] [Green Version]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Dauta, M.A.M.; Hassana, M.Y.; Abdullaha, H.; Rahmana, H.A.; Abdullaha, M.P.; Hussina, F. Building electrical energy consumption forecasting analysis using conventional and artificial intelligence methods: A review. Renew. Sustain. Energy Rev. 2017, 70, 1108–1118. [Google Scholar] [CrossRef]
- Deb, C.; Zhang, F.; Yanga, J.; Lee, S.E.; Shah, K.W. A review on time series forecasting techniques for building energy consumption. Renew. Sustain. Energy Rev. 2017, 74, 902–924. [Google Scholar] [CrossRef]
- Gao, Y.; Fang, C.; Ruan, Y. A novel model for the prediction of long-term building energy demand: LSTM with Attention layer. IOP Conf. Ser. Earth Environ. Sci. 2019, 294, 012033. [Google Scholar] [CrossRef]
- Nguyen, H.V.; Naeem, M.A.; Wichitaksorn, N.; Pears, R. A smart system for short-term price prediction using time series models. Comput. Electr. Eng. 2019, 76, 339–352. [Google Scholar] [CrossRef]
- Poornima, S.; Pushpalatha, M. Prediction of rainfall using intensified LSTM based recurrent neural network with weighted linear units. Atmosphere 2019, 10, 668. [Google Scholar] [CrossRef] [Green Version]
- McNally, S.; Roche, J.; Caton, S. Predicting the price of bitcoin using machine learning. In Proceedings of the 26th Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Cambridge, UK,, 21–23 March 2018; pp. 339–343. [Google Scholar] [CrossRef] [Green Version]
- Vochozka, M.; Vrbka, J.; Suler, P. Bankruptcy or success? the effective prediction of a company’s financial development using LSTM. Sustainability 2020, 12, 7529. [Google Scholar] [CrossRef]
- Hao, Y.; Gao, Q. Predicting the Trend of Stock Market Index Using the Hybrid Neural Network Based on Multiple Time Scale Feature Learning. Appl. Sci. 2020, 10, 3961. [Google Scholar] [CrossRef]
- Mondal, P.; Shit, L.; Goswami, S. Study of effectiveness of time series modeling (ARIMA) in forecasting stock prices. Int. J. Comput. Sci. Eng. Appl. (IJCSEA) 2014, 4, 13–29. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Chou, J.S.; Ngo, N.T. Time series analytics using sliding window metaheuristic optimization-based machine learning system for identifying building energy consumption patterns. Appl. Energy 2016, 177, 751–770. [Google Scholar] [CrossRef]
- Divina, F.; Torres, M.G.; Vela, F.A.G.; Noguera, J.L.V. A comparative study of time series forecasting methods for short term electric energy consumption prediction in smart buildings. Energies 2019, 12, 1934. [Google Scholar] [CrossRef] [Green Version]
- Ruekkasaem, L.; Sasananan, M. Forecasting agricultural products prices using time series methods for crop planning. Int. J. Mech. Eng. Technol. (IJMET) 2018, 9, 957–971. [Google Scholar]
- Box, G.E.P.; Jenkins, G.M. Time Series Analysis: Forecasting and Control; Holden Day: San Francisco, CA, USA, 1976. [Google Scholar]
- Taylor, S.J.; Letham, B. Forecasting at scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Tran, N.; Nguyen, T.; Nguyen, B.M.; Nguyen, G. A multivariate fuzzy time series resource forecast model for clouds using LSTM and data correlation analysis. Procedia Comput. Sci. 2018, 126, 636–645. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Neil, D.; Pfeiffer, M.; Liu, S.C. Phased LSTM: Accelerating recurrent network training for long or event-based sequences. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 9 September 2016; pp. 3889–3897. [Google Scholar] [CrossRef]
- Hsu, D. Multi-period time series modeling with sparsity via Bayesian variational inference. arXiv 2018, arXiv:1707.00666v3. [Google Scholar]
- Khashei, M.; Bijari, M.; Ardali, G.A.R. Improvement of auto-regressive integrated moving average models using fuzzy logic and artificial neural networks (ANNs). Neurocomputing 2009, 72, 956–967. [Google Scholar] [CrossRef]
- Cenas, P.V. Forecast of agricultural crop price using time series and Kalman filter method. Asia Pac. J. Multidiscip. Res. 2017, 5, 15–21. [Google Scholar]
- Anggraeni, W.; Mahananto, F.; Sari, A.Q.; Zaini, Z.; Andri, K.B. Sumaryanto, Forecasting the price of Indonesia’s rice using Hybrid Artificial Neural Network and Autoregressive Integrated Moving Average (Hybrid NNs-ARIMAX) with exogenous variables. Procedia Comput. Sci. 2019, 161, 677–686. [Google Scholar] [CrossRef]
- Fang, Y.; Guan, B.; Wu, S.; Heravi, S. Optimal forecast combination based on ensemble empirical mode decomposition for agricultural commodity futures prices. J. Forecast. 2020, 39, 877–886. [Google Scholar] [CrossRef]
- Smith, T.G. Pmdarima: ARIMA Estimators for Python. 2017. Available online: http://www.alkaline-ml.com/pmdarima (accessed on 25 February 2020).
- Harvey, A.; Peters, S. Estimation procedures for structural time series models. J. Forecast. 1990, 9, 89–108. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Item | Sales Days | Period | T |
|---|---|---|---|---|
| 1 | WelshOnion | 2014 | 1 June 2014~31 December 2019 | 2040 |
| 2 | Lettuce | 2014 | 1 June 2014~31 December 2019 | 2040 |
| 3 | ChineseMallow | 2012 | 1 June 2014~31 December 2019 | 2040 |
| 4 | Onion | 2009 | 1 June 2014~31 December 2019 | 2040 |
| 5 | JujubeMiniTomato | 2011 | 1 June 2014~31 December 2019 | 2040 |
| Item | Metric | Auto_Arima | Prophet | LSTM | SLSTM | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| sw | sm | sq | swm | smq | swq | swmq | |||||
| WO | MAE | 122.87 | 139.83 | 121.2 | 114.47 | 113.9 | 111.45 | 111.37 | 113.96 | 111.75 | 113.67 |
| RMSE | 430.72 | 438.1 | 428.6 | 402.59 | 402.22 | 399.56 | 400.76 | 402.22 | 400.62 | 401.67 | |
| NMAE | 0.32 | 0.33 | 0.26 | 0.19 | 0.19 | 0.19 | 0.18 | 0.19 | 0.18 | 0.19 | |
| Lettuce | MAE | 50.18 | 49.0 | 45.73 | 33.06 | 38.18 | 38.98 | 32.83 | 36.99 | 34.06 | 33.35 |
| RMSE | 88.99 | 87.1 | 83.49 | 77.55 | 80.22 | 80.59 | 77.88 | 79.92 | 78.94 | 77.30 | |
| NMAE | 0.28 | 0.31 | 0.29 | 0.19 | 0.24 | 0.24 | 0.19 | 0.23 | 0.20 | 0.20 | |
| CM | MAE | 7.94 | 8.3 | 7.5 | 7.31 | 7.77 | 7.74 | 7.44 | 7.82 | 7.43 | 8.27 |
| RMSE | 12.95 | 13.4 | 12.8 | 12.79 | 13.11 | 12.95 | 13.04 | 12.99 | 12.71 | 13.85 | |
| NMAE | 0.35 | 0.37 | 0.35 | 0.27 | 0.3 | 0.3 | 0.28 | 0.29 | 0.29 | 0.3 | |
| Onion | MAE | 233.47 | 233.6 | 237.6 | 208.99 | 225.36 | 235.73 | 196.55 | 212.95 | 190.74 | 192.3 |
| RMSE | 373.37 | 358.8 | 376.1 | 347.8 | 362.86 | 374.16 | 331.97 | 348.26 | 324.47 | 325.64 | |
| NMAE | 0.29 | 0.29 | 0.31 | 0.25 | 0.28 | 0.29 | 0.25 | 0.27 | 0.24 | 0.25 | |
| JMT | MAE | 114.51 | 89.2 | 78.3 | 76.57 | 74.23 | 76.09 | 65.32 | 75.62 | 74.89 | 74.32 |
| RMSE | 156.06 | 105.8 | 101.8 | 100.81 | 96.09 | 100.05 | 85.75 | 98.7 | 99.69 | 96.53 | |
| NMAE | 0.34 | 0.27 | 0.26 | 0.23 | 0.20 | 0.23 | 0.17 | 0.20 | 0.19 | 0.19 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, T.-W.; Oh, I.-S. Time Series Forecasting of Agricultural Products’ Sales Volumes Based on Seasonal Long Short-Term Memory. Appl. Sci. 2020, 10, 8169. https://doi.org/10.3390/app10228169
Yoo T-W, Oh I-S. Time Series Forecasting of Agricultural Products’ Sales Volumes Based on Seasonal Long Short-Term Memory. Applied Sciences. 2020; 10(22):8169. https://doi.org/10.3390/app10228169
Chicago/Turabian StyleYoo, Tae-Woong, and Il-Seok Oh. 2020. "Time Series Forecasting of Agricultural Products’ Sales Volumes Based on Seasonal Long Short-Term Memory" Applied Sciences 10, no. 22: 8169. https://doi.org/10.3390/app10228169