Developing a New Hourly Forest Fire Risk Index Based on Catboost in South Korea


Abstract
:1. Introduction
2. Study Area and Data
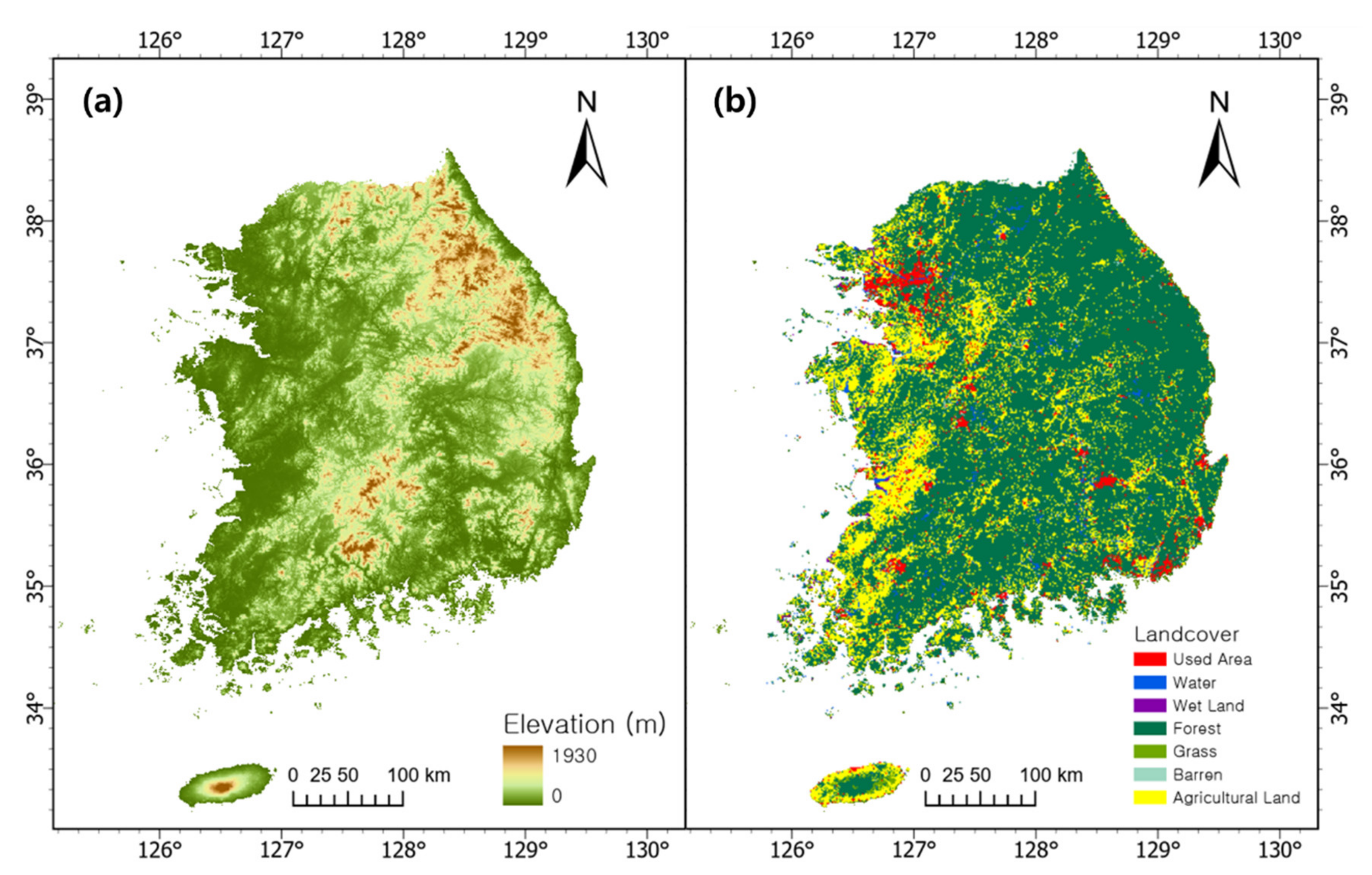
2.1. Study Area
2.2. Data
2.2.1. Weather Data
2.2.2. Geographical Data
2.2.3. Fuel Data
2.2.4. Time-Related Data
2.2.5. In Situ Observation Data
3. Methods
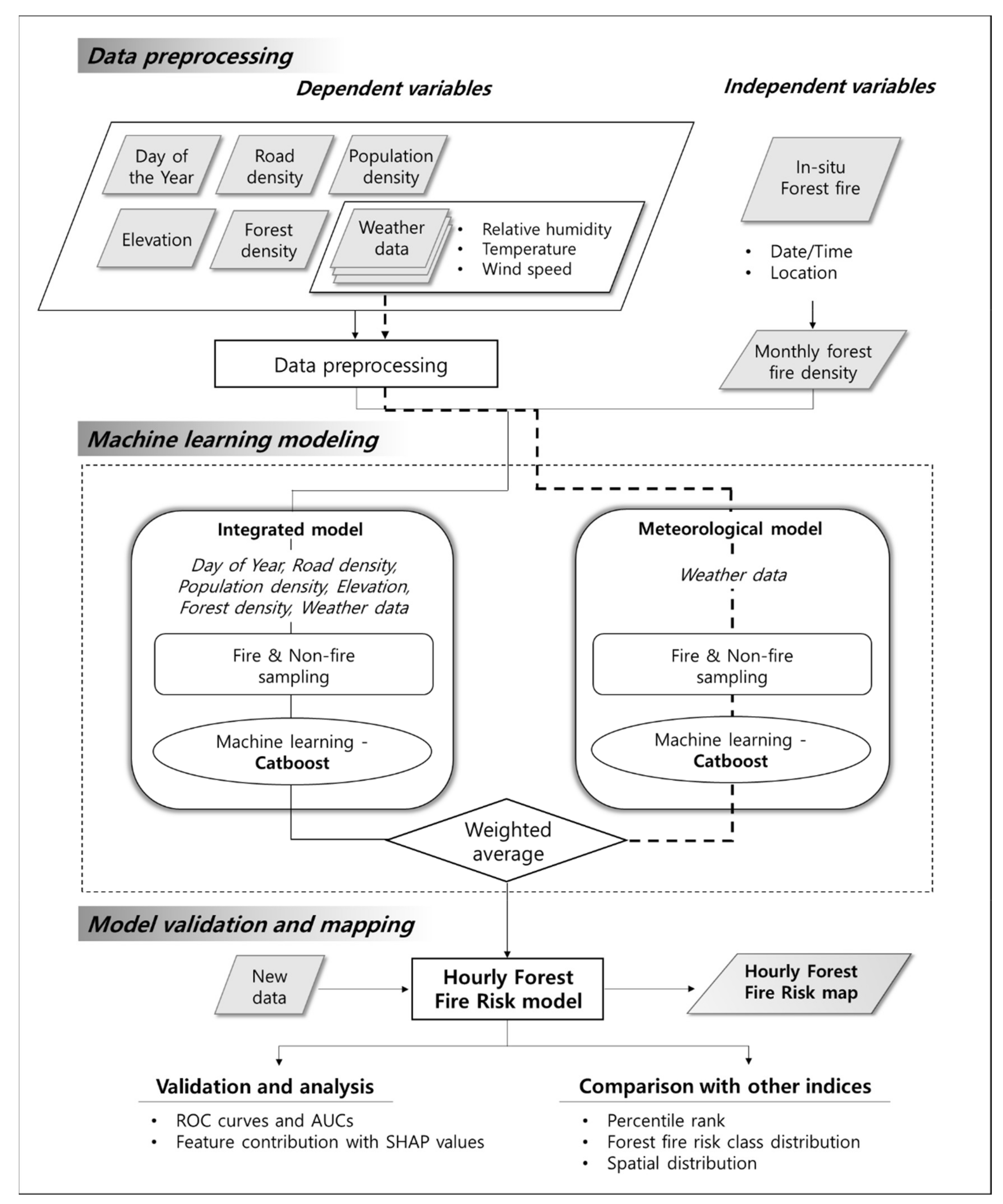
3.1. Data Preprocessing
3.2. Machine Learning Modeling
3.3. Model Validation and Comparison
4. Results and Discussion
4.1. One-Year-Out Cross-Validation with ROC Curve
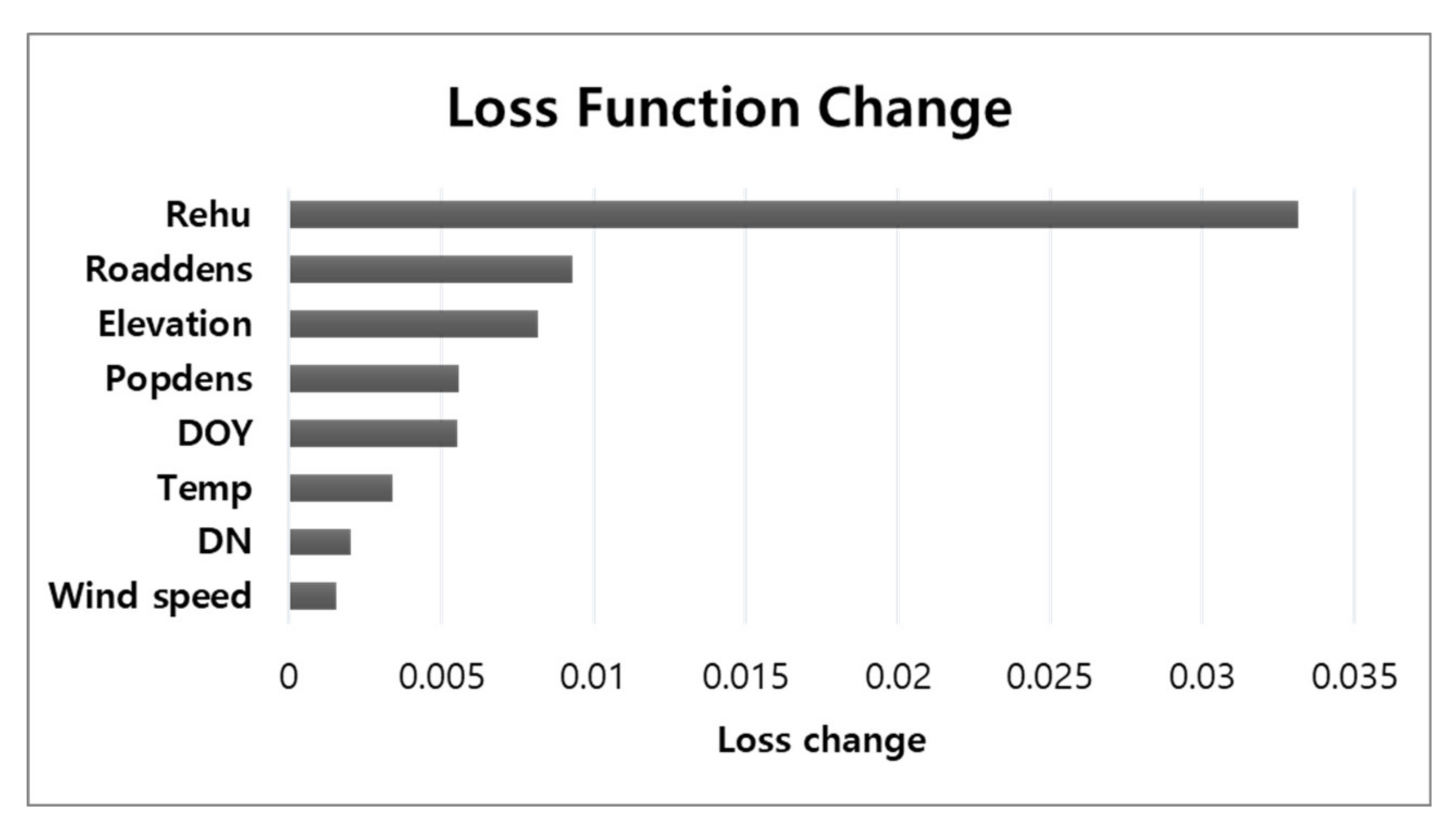
4.2. Feature Contribution Based on the Catboost Feature Importances
4.3. Comparison of Percentile Rank between HFRI, Revised FFMC, and DWI
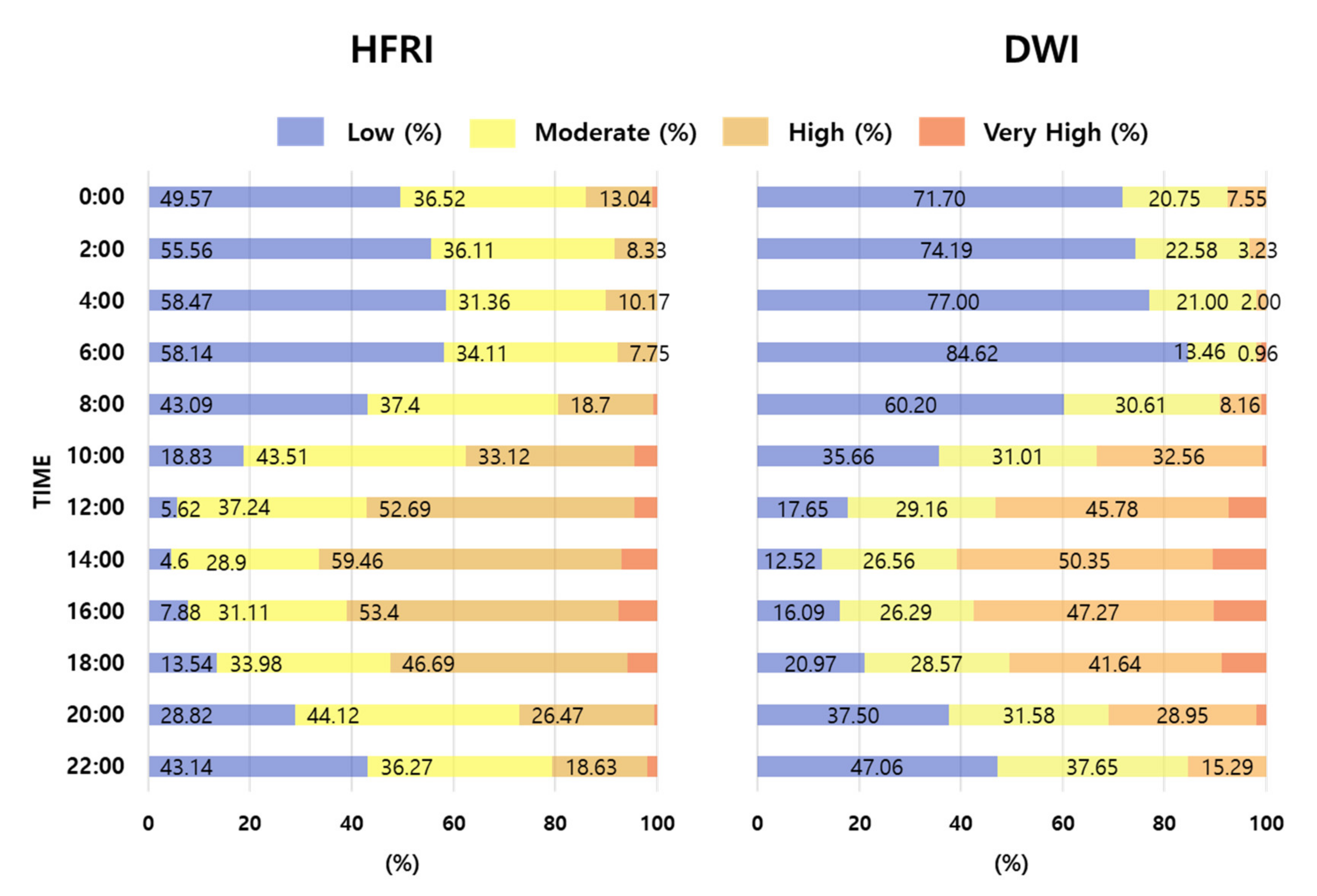
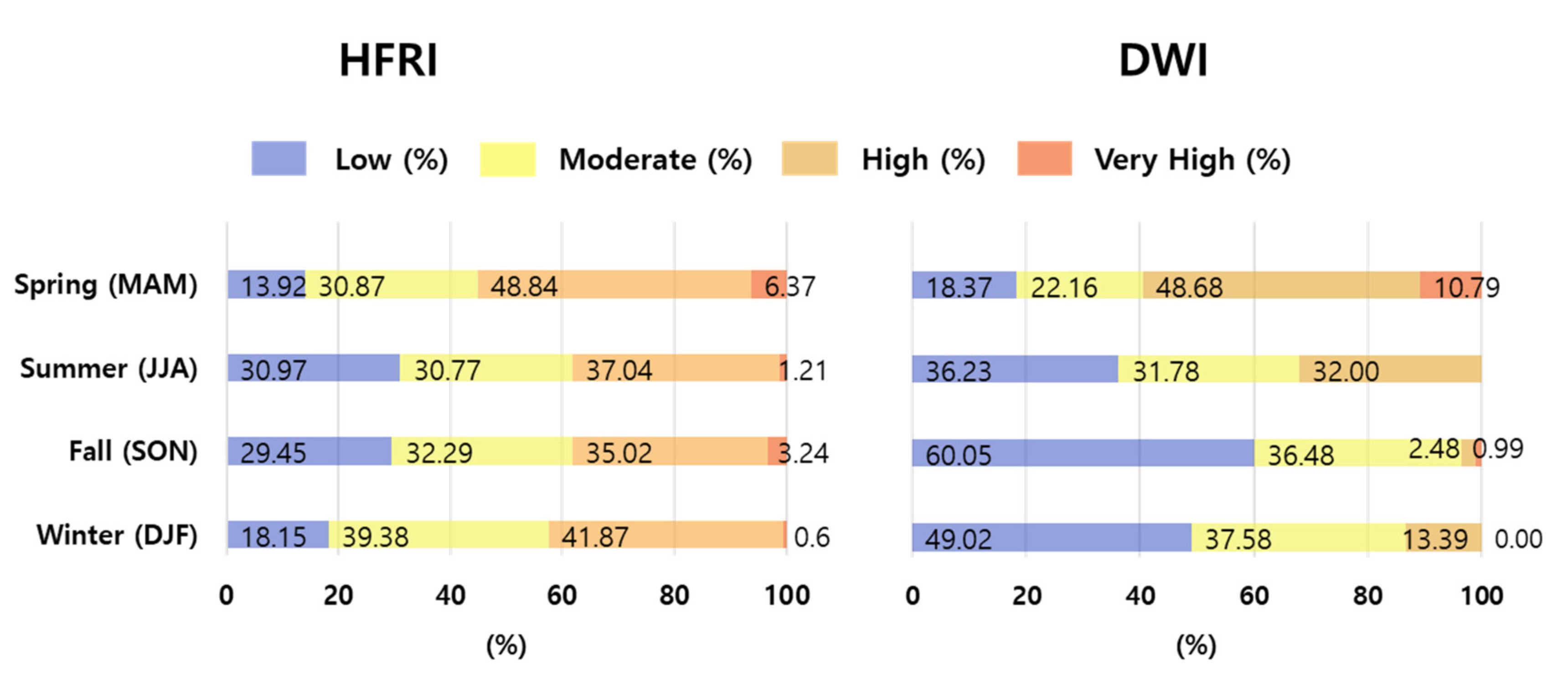
4.4. Comparison of Forest Fire Risk Classes between HFRI and DWI
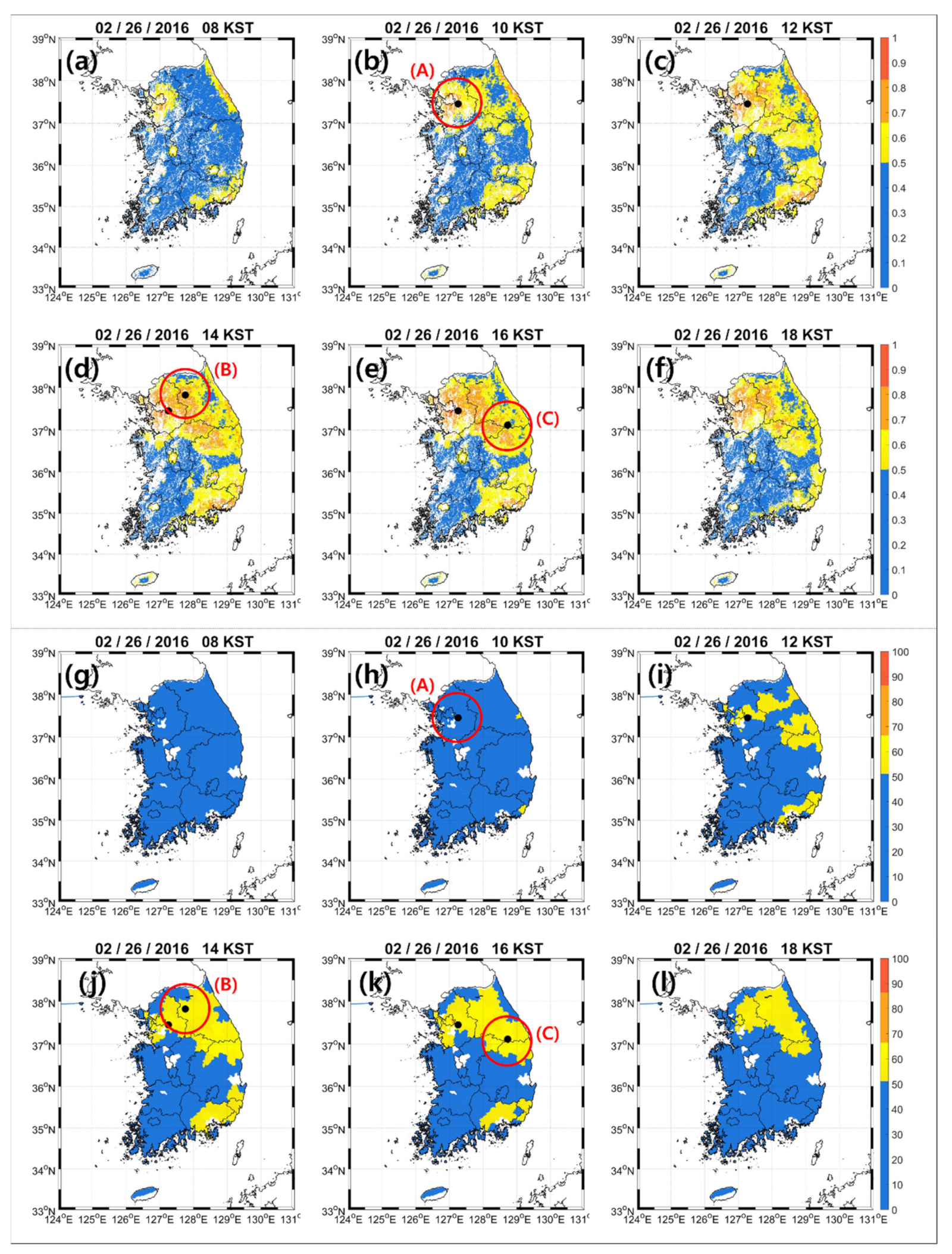
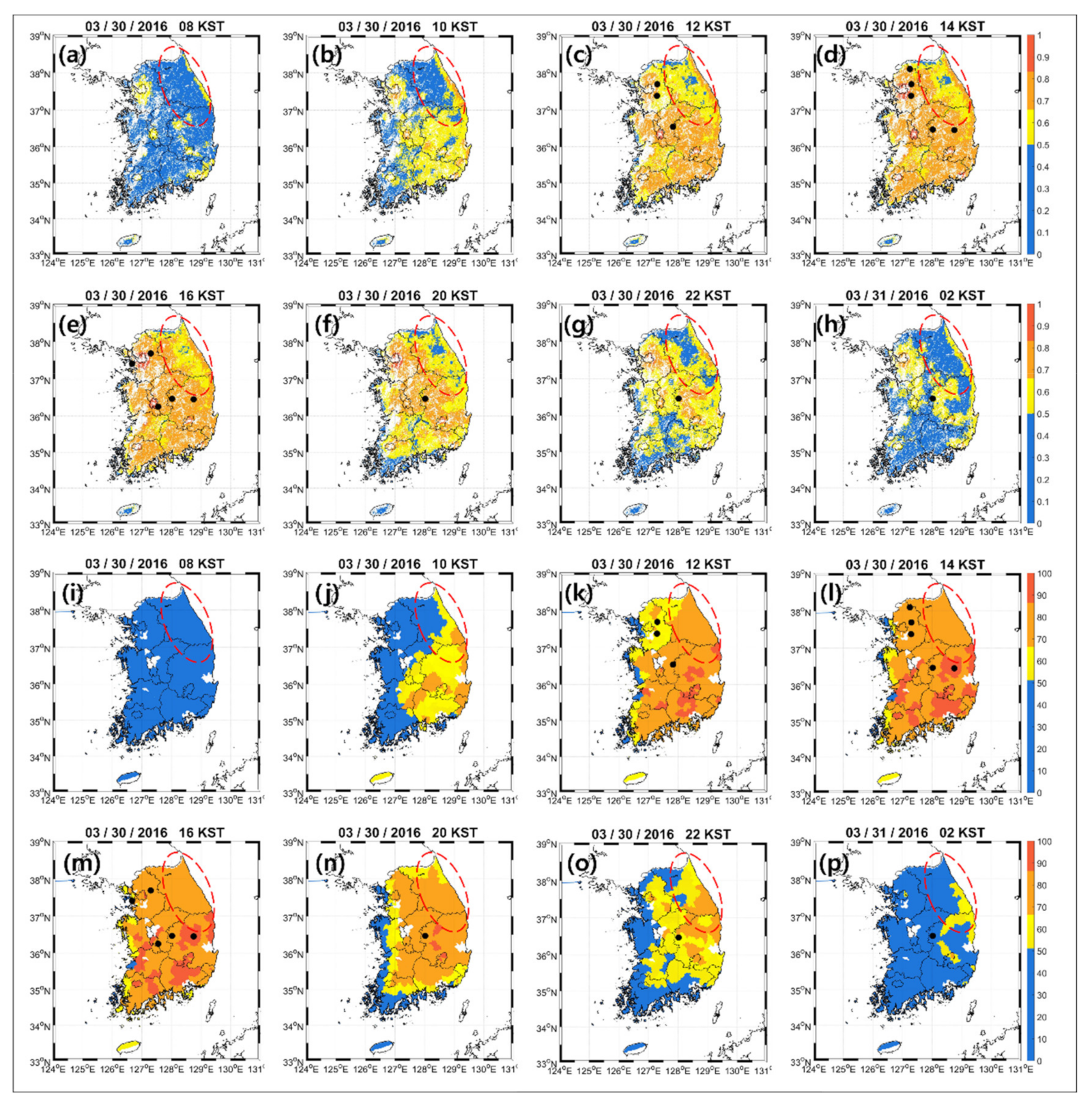
4.5. Mapping Results of HFRI and DWI
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Van Hoang, T.; Chou, T.Y.; Fang, Y.M.; Nguyen, N.T.; Nguyen, Q.H.; Xuan Canh, P.; Ngo Bao Toan, D.; Nguyen, X.L.; Meadows, M.E. Mapping Forest Fire Risk and Development of Early Warning System for NW Vietnam Using AHP and MCA/GIS Methods. Appl. Sci. 2020, 10, 4348. [Google Scholar] [CrossRef]
- Mallinis, G.; Mitsopoulos, I.; Chrysafi, I.J.G.; Sensing, R. Evaluating and comparing Sentinel 2A and Landsat-8 Operational Land Imager (OLI) spectral indices for estimating fire severity in a Mediterranean pine ecosystem of Greece. GISci. Remote Sens. 2018, 55, 1–18. [Google Scholar] [CrossRef]
- Gelabert, P.; Montealegre, A.; Lamelas, M.; Domingo, D.J.G.; Sensing, R. Forest structural diversity characterization in Mediterranean landscapes affected by fires using Airborne Laser Scanning data. GISci. Remote Sens. 2020, 57, 497–509. [Google Scholar] [CrossRef]
- Abdollahi, M.; Islam, T.; Gupta, A.; Hassan, Q.K. An advanced forest fire danger forecasting system: Integration of remote sensing and historical sources of ignition data. Remote Sens. 2018, 10, 923. [Google Scholar] [CrossRef] [Green Version]
- Laneve, G.; Pampanoni, V.; Shaik, R.U. The Daily Fire Hazard Index: A Fire Danger Rating Method for Mediterranean Areas. Remote Sens. 2020, 12, 2356. [Google Scholar] [CrossRef]
- Cheret, V.; Denux, J.-P.J.G.; Sensing, R. Analysis of MODIS NDVI time series to calculate indicators of Mediterranean forest fire susceptibility. GISci. Remote Sens. 2011, 48, 171–194. [Google Scholar] [CrossRef]
- Gigović, L.; Pourghasemi, H.R.; Drobnjak, S.; Bai, S. Testing a new ensemble model based on SVM and random forest in forest fire susceptibility assessment and its mapping in Serbia’s Tara National Park. Forests 2019, 10, 408. [Google Scholar] [CrossRef] [Green Version]
- Zhang, G.; Wang, M.; Liu, K. Forest fire susceptibility modeling using a convolutional neural network for Yunnan province of China. Int. J. Disaster Risk Sci. 2019, 10, 386–403. [Google Scholar] [CrossRef] [Green Version]
- Pham, B.T.; Jaafari, A.; Avand, M.; Al-Ansari, N.; Dinh Du, T.; Yen, H.P.H.; Phong, T.V.; Nguyen, D.H.; Le, H.V.; Mafi-Gholami, D. Performance evaluation of machine learning methods for forest fire modeling and prediction. Symmetry 2020, 12, 1022. [Google Scholar] [CrossRef]
- Hong, H.; Tsangaratos, P.; Ilia, I.; Liu, J.; Zhu, A.-X.; Xu, C. Applying genetic algorithms to set the optimal combination of forest fire related variables and model forest fire susceptibility based on data mining models. The case of Dayu County, China. Sci. Total Environ. 2018, 630, 1044–1056. [Google Scholar] [CrossRef]
- Bui, D.T.; Bui, Q.-T.; Nguyen, Q.-P.; Pradhan, B.; Nampak, H.; Trinh, P.T. A hybrid artificial intelligence approach using GIS-based neural-fuzzy inference system and particle swarm optimization for forest fire susceptibility modeling at a tropical area. Agric. For. Meteorol. 2017, 233, 32–44. [Google Scholar]
- Sachdeva, S.; Bhatia, T.; Verma, A. GIS-based evolutionary optimized Gradient Boosted Decision Trees for forest fire susceptibility mapping. Nat. Hazards 2018, 92, 1399–1418. [Google Scholar] [CrossRef]
- Karali, A.; Roussos, A.; Giannakopoulos, C.; Hatzaki, M.; Xanthopoulos, G.; Kaoukis, K. Evaluation of the Canadian Fire Weather Index in Greece and future climate projections. In Advances in Meteorology, Climatology and Atmospheric Physics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 501–508. [Google Scholar]
- Tian, X.; McRae, D.J.; Jin, J.; Shu, L.; Zhao, F.; Wang, M. Wildfires and the Canadian Forest Fire Weather Index system for the Daxing’anling region of China. Int. J. Wildland Fire 2012, 20, 963–973. [Google Scholar] [CrossRef]
- Ziel, R.H.; Bieniek, P.A.; Bhatt, U.S.; Strader, H.; Rupp, T.S.; York, A. A Comparison of Fire Weather Indices with MODIS Fire Days for the Natural Regions of Alaska. Forests 2020, 11, 516. [Google Scholar] [CrossRef]
- Dimitrakopoulos, A.; Bemmerzouk, A.; Mitsopoulos, I. Evaluation of the Canadian fire weather index system in an eastern Mediterranean environment. Meteorol. Appl. 2011, 18, 83–93. [Google Scholar] [CrossRef]
- Jeong, J.-Y.; Woo, S.-H.; Son, R.-H.; Yoon, J.-H.; Jeong, J.-H.; Lee, S.-J.; Lee, B.-D. Spring Forest-Fire Variability over Korea Associated with Large-Scale Climate Factors. Atmosphere 2018, 28, 457–467. [Google Scholar]
- De Jong, M.C.; Wooster, M.J.; McCall, F.F. Calibration and evaluation of the Canadian Forest Fire Weather Index (FWI) System for improved wildland fire danger rating in the United Kingdom. Nat. Hazards Earth Syst. Sci. 2016, 16, 1217. [Google Scholar] [CrossRef] [Green Version]
- Van Wagner, C.; Forest, P. Development and Structure of the Canadian Forest Fire Weather Index System; Canadian Forestry Service Headquarters: Ottawa, ON, Canada, 1987. [Google Scholar]
- Satir, O.; Berberoglu, S.; Donmez, C. Mapping regional forest fire probability using artificial neural network model in a Mediterranean forest ecosystem. Geomat. Nat. Hazards Risk 2016, 7, 1645–1658. [Google Scholar] [CrossRef] [Green Version]
- Adab, H.; Atabati, A.; Oliveira, S.; Gheshlagh, A.M. Assessing fire hazard potential and its main drivers in Mazandaran province, Iran: A data-driven approach. Environ. Monit. Assess. 2018, 190, 670. [Google Scholar] [CrossRef]
- Viedma, O.; Urbieta, I.; Moreno, J. Wildfires and the role of their drivers are changing over time in a large rural area of west-central Spain. Sci. Rep. 2018, 8, 17797. [Google Scholar] [CrossRef] [Green Version]
- Won, M.; Jang, K.; Yoon, S. Development of the National Integrated Daily Weather Index (DWI) Model to Calculate Forest Fire Danger Rating in the Spring and Fall. Korean Soc. Agric. Meteorol. 2018, 20, 348–356. [Google Scholar]
- Won, M.; Yoon, S.; Jang, K. Developing Korean forest fire occurrence probability model reflecting climate change in the spring of 2000s. Korean J. Agric. For. Meteorol. 2016, 18, 199–207. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.J.; Lim, C.-H.; Kim, G.S.; Lee, J.; Geiger, T.; Rahmati, O.; Son, Y.; Lee, W.-K.J.R.S. Multi-temporal analysis of forest fire probability using socio-economic and environmental variables. Remote Sens. 2019, 11, 86. [Google Scholar] [CrossRef] [Green Version]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Aryal, J. Forest fire susceptibility and risk mapping using social/infrastructural vulnerability and environmental variables. Fire 2019, 2, 50. [Google Scholar] [CrossRef] [Green Version]
- Pourtaghi, Z.S.; Pourghasemi, H.R.; Aretano, R.; Semeraro, T.J.E.i. Investigation of general indicators influencing on forest fire and its susceptibility modeling using different data mining techniques. Ecol. Indic. 2016, 64, 72–84. [Google Scholar] [CrossRef]
- Ricotta, C.; Bajocco, S.; Guglietta, D.; Conedera, M. Assessing the influence of roads on fire ignition: Does land cover matter? Fire 2018, 1, 24. [Google Scholar] [CrossRef] [Green Version]
- Korea Forest Service. Available online: http://www.forest.go.kr/newkfsweb/kfi/kfs/frfr/selectFrfrStats.do?searchCnd=2010&mn=KFS_02_02_01_05_01 (accessed on 19 August 2020).
- Ministry of Land, Infrastructure, and Transport, National Geographic Information Institute. Available online: http://map.ngii.go.kr/ms/pblictn/nationMapBook.do (accessed on 19 August 2020).
- Advanced Land Observing Satellite. Available online: https://www.eorc.jaxa.jp/ALOS/en/aw3d30/index.htm (accessed on 19 August 2020).
- Environmental Geographic Information. Available online: https://egis.me.go.kr/main.do (accessed on 19 August 2020).
- Won, M.; Lee, M.; Lee, W.; Yoon, S. Prediction of Forest Fire Danger Rating over the Korean Peninsula with the Digital Forecast Data and Daily Weather Index (DWI) Model. Korean Soc. Agric. Meteorol. 2012, 14, 1–10. [Google Scholar] [CrossRef]
- Srock, A.F.; Charney, J.J.; Potter, B.E.; Goodrick, S.L. The hot-dry-windy index: A new fire weather index. Atmosphere 2018, 9, 279. [Google Scholar] [CrossRef] [Green Version]
- Tadono, T.; Nagai, H.; Ishida, H.; Oda, F.; Naito, S.; Minakawa, K.; Iwamoto, H. Generation of the 30 M-mesh global digital surface model by ALOS PRISM. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41. [Google Scholar]
- Santillan, J.; Makinano-Santillan, M. Vertical accuracy assessment of 30-m resolution Alos, Aster, and SRTM global dems over northeastern Mindanao, Philippines. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41. [Google Scholar]
- Courty, L.G.; Soriano-Monzalvo, J.C.; Pedrozo-Acuña, A. Evaluation of open-access global digital elevation models (AW3D30, SRTM, and ASTER) for flood modelling purposes. J. Flood Risk Manag. 2019, 12, e12550. [Google Scholar] [CrossRef] [Green Version]
- Socioeconomic Data and Applications Center. Available online: https://sedac.ciesin.columbia.edu/data/set/gpw-v4-population-density-rev11/data-download (accessed on 19 August 2020).
- Global Roads Inventory Project. Available online: https://www.globio.info/download-grip-dataset (accessed on 19 August 2020).
- Meijer, J.R.; Huijbregts, M.A.; Schotten, K.C.; Schipper, A.M. Global patterns of current and future road infrastructure. Environ. Res. Lett. 2018, 13, 064006. [Google Scholar] [CrossRef] [Green Version]
- Forest Geospatial Information System. Available online: http://www.forest.go.kr/newkfsweb/kfs/idx/SubIndex.do?orgId=fgis&mn=KFS_03_08_01 (accessed on 19 August 2020).
- Zhan, Y.; Luo, Y.; Deng, X.; Chen, H.; Grieneisen, M.L.; Shen, X.; Zhu, L.; Zhang, M.J.A.e. Spatiotemporal prediction of continuous daily PM2. 5 concentrations across China using a spatially explicit machine learning algorithm. Atmos. Environ. 2017, 155, 129–139. [Google Scholar] [CrossRef]
- Park, S.; Shin, M.; Im, J.; Song, C.-K.; Choi, M.; Kim, J.; Lee, S.; Park, R.; Kim, J.; Lee, D.-W. Estimation of ground-level particulate matter concentrations through the synergistic use of satellite observations and process-based models over South Korea. Atmos. Chem. Phys. 2019, 19, 1097–1113. [Google Scholar] [CrossRef] [Green Version]
- Franke, G.R. Multicollinearity. In Wiley International Encyclopedia of Marketing; Wiley: Hoboken, NJ, USA, 2010. [Google Scholar]
- Tien Bui, D.; Hoang, N.-D.; Samui, P. Spatial pattern analysis and prediction of forest fire using new machine learning approach of Multivariate Adaptive Regression Splines and Differential Flower Pollination optimization: A case study at Lao Cai province (Viet Nam). J. Environ. Manag. 2019, 237, 476–487. [Google Scholar] [CrossRef] [PubMed]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2020, 1–31. [Google Scholar] [CrossRef]
- Huang, G.; Wu, L.; Ma, X.; Zhang, W.; Fan, J.; Yu, X.; Zeng, W.; Zhou, H. Evaluation of CatBoost method for prediction of reference evapotranspiration in humid regions. J. Hydrol. 2019, 574, 1029–1041. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Canada, December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2018. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1999; pp. 4765–4774. [Google Scholar]
- Zhang, Y.; Zhao, Z.; Zheng, J. CatBoost: A new approach for estimating daily reference crop evapotranspiration in arid and semi-arid regions of Northern China. J. Hydrol. 2020, 588, 125087. [Google Scholar] [CrossRef]
- Catboost. Available online: https://catboost.ai/ (accessed on 21 October 2020).
- Pan, J.; Wang, W.; Li, J. Building probabilistic models of fire occurrence and fire risk zoning using logistic regression in Shanxi Province, China. Nat. Hazards 2016, 81, 1879–1899. [Google Scholar] [CrossRef]
- Regmi, N.R.; Giardino, J.R.; Vitek, J.D. Modeling susceptibility to landslides using the weight of evidence approach: Western Colorado, USA. Geomorphology 2010, 115, 172–187. [Google Scholar] [CrossRef]
- Pourghasemi, H.R.; Mohammady, M.; Pradhan, B. Landslide susceptibility mapping using index of entropy and conditional probability models in GIS: Safarood Basin, Iran. CATENA 2012, 97, 71–84. [Google Scholar] [CrossRef]
- Abedi Gheshlaghi, H.; Feizizadeh, B.; Blaschke, T. GIS-based forest fire risk mapping using the analytical network process and fuzzy logic. J. Environ. Plan. Manag. 2020, 63, 481–499. [Google Scholar] [CrossRef]
- Adab, H.; Kanniah, K.D.; Solaimani, K. Modeling forest fire risk in the northeast of Iran using remote sensing and GIS techniques. Nat. Hazards 2013, 65, 1723–1743. [Google Scholar] [CrossRef]
- Tehrany, M.S.; Jones, S.; Shabani, F.; Martínez-Álvarez, F.; Bui, D.T. A novel ensemble modeling approach for the spatial prediction of tropical forest fire susceptibility using logitboost machine learning classifier and multi-source geospatial data. Theor. Appl Climatol. 2019, 137, 637–653. [Google Scholar] [CrossRef]
- Kang, Y.; Park, S.; Jang, E.; Im, J.; Kwon, C.; Lee, S. Spatio-temporal enhancement of forest fire risk index using weather forecast and satellite data in South Korea. J. Korean Assoc. Geogr. Inf. Stud. 2019, 22, 116–130. [Google Scholar]
- Park, H.; Lee, S.; Chae, H.; Lee, W. A Study on the Development of Forest Fire Occurrence Probability Model using Canadian Forest Fire Weather Index -Occurrence of Forest Fire in Kangwon Province. J. Korean Soc. Hazard Mitig. 2009, 9, 95–100. [Google Scholar]
- Chowdhury, E.H.; Hassan, Q.K. Development of a new daily-scale forest fire danger forecasting system using remote sensing data. Remote Sens. 2015, 7, 2431–2448. [Google Scholar] [CrossRef] [Green Version]
- Bedia, J.; Golding, N.; Casanueva, A.; Iturbide, M.; Buontempo, C.; Gutiérrez, J.M. Seasonal predictions of Fire Weather Index: Paving the way for their operational applicability in Mediterranean Europe. Clim. Serv. 2018, 9, 101–110. [Google Scholar] [CrossRef]
- Acosta, M.; Darenova, E.; Krupková, L.; Pavelka, M. Seasonal and inter-annual variability of soil CO2 efflux in a Norway spruce forest over an eight-year study. Agric. For. Meteorol. 2018, 256–257, 93–103. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Source | Variables | Abbreviation |
|---|---|---|---|
| Weather data | Korea Meteorological Administration | Relative humidity | Rehu |
| Temperature | Temp | ||
| Wind speed | Wind speed | ||
| Geographical data | JAXA ALOS | AW3D30 v3.1 | Elevation |
| NASA Gridded Population of the World (GPW), v4 | Populated area raster | Popdens | |
| GRIP global roads dataset | Road vector | Roaddens | |
| Fuel data | Forest Geospatial Information System | Forest density | DN |
| Time-related data | Day of the Year | DOY |
| Monthly Forest Fire Density Percentile | 0 ≤ X < 25 | 25 ≤ X < 50 | 50 ≤ X < 75 | 75 ≤ X | |
|---|---|---|---|---|---|
| Assigned values | Fire | 1 | |||
| Non-fire | 0 | 0.1 | 0.2 | - | |
| Time Scale | Fire | Non-Fire for the Integrated Model | Non-Fire for the Meteorological Model |
|---|---|---|---|
| Hour | |||
| 0:00 | 180 | 140 | 771 |
| 2:00 | 168 | 129 | 787 |
| 4:00 | 182 | 129 | 783 |
| 6:00 | 196 | 154 | 782 |
| 8:00 | 183 | 154 | 787 |
| 10:00 | 236 | 190 | 805 |
| 12:00 | 664 | 502 | 948 |
| 14:00 | 1176 | 906 | 1202 |
| 16:00 | 1085 | 934 | 1123 |
| 18:00 | 531 | 402 | 866 |
| 20:00 | 263 | 197 | 829 |
| 22:00 | 165 | 131 | 771 |
| Season | |||
| Spring | 5775 | 4302 | 6448 |
| Summer | 1503 | 1197 | 5032 |
| Fall | 717 | 602 | 5002 |
| Winter | 2001 | 1542 | 4419 |
| Year | |||
| 2014 | 1301 | 1328 | 3396 |
| 2015 | 2018 | 1288 | 3641 |
| 2016 | 1176 | 1292 | 3549 |
| 2017 | 2184 | 1204 | 3394 |
| 2018 | 1562 | 1275 | 3417 |
| 2019 | 1755 | 1256 | 3504 |
| Index | Class | |||
|---|---|---|---|---|
| Low | Moderate | High | Very High | |
| HFRI | 0–0.49 | 0.5–0.66 | 0.67–0.83 | 0.84–1 |
| DWI | 0–50 | 51–65 | 66–85 | 86–100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, Y.; Jang, E.; Im, J.; Kwon, C.; Kim, S. Developing a New Hourly Forest Fire Risk Index Based on Catboost in South Korea. Appl. Sci. 2020, 10, 8213. https://doi.org/10.3390/app10228213
Kang Y, Jang E, Im J, Kwon C, Kim S. Developing a New Hourly Forest Fire Risk Index Based on Catboost in South Korea. Applied Sciences. 2020; 10(22):8213. https://doi.org/10.3390/app10228213
Chicago/Turabian StyleKang, Yoojin, Eunna Jang, Jungho Im, Chungeun Kwon, and Sungyong Kim. 2020. "Developing a New Hourly Forest Fire Risk Index Based on Catboost in South Korea" Applied Sciences 10, no. 22: 8213. https://doi.org/10.3390/app10228213
APA StyleKang, Y., Jang, E., Im, J., Kwon, C., & Kim, S. (2020). Developing a New Hourly Forest Fire Risk Index Based on Catboost in South Korea. Applied Sciences, 10(22), 8213. https://doi.org/10.3390/app10228213