Generative Adversarial Network for Class-Conditional Data Augmentation


Abstract
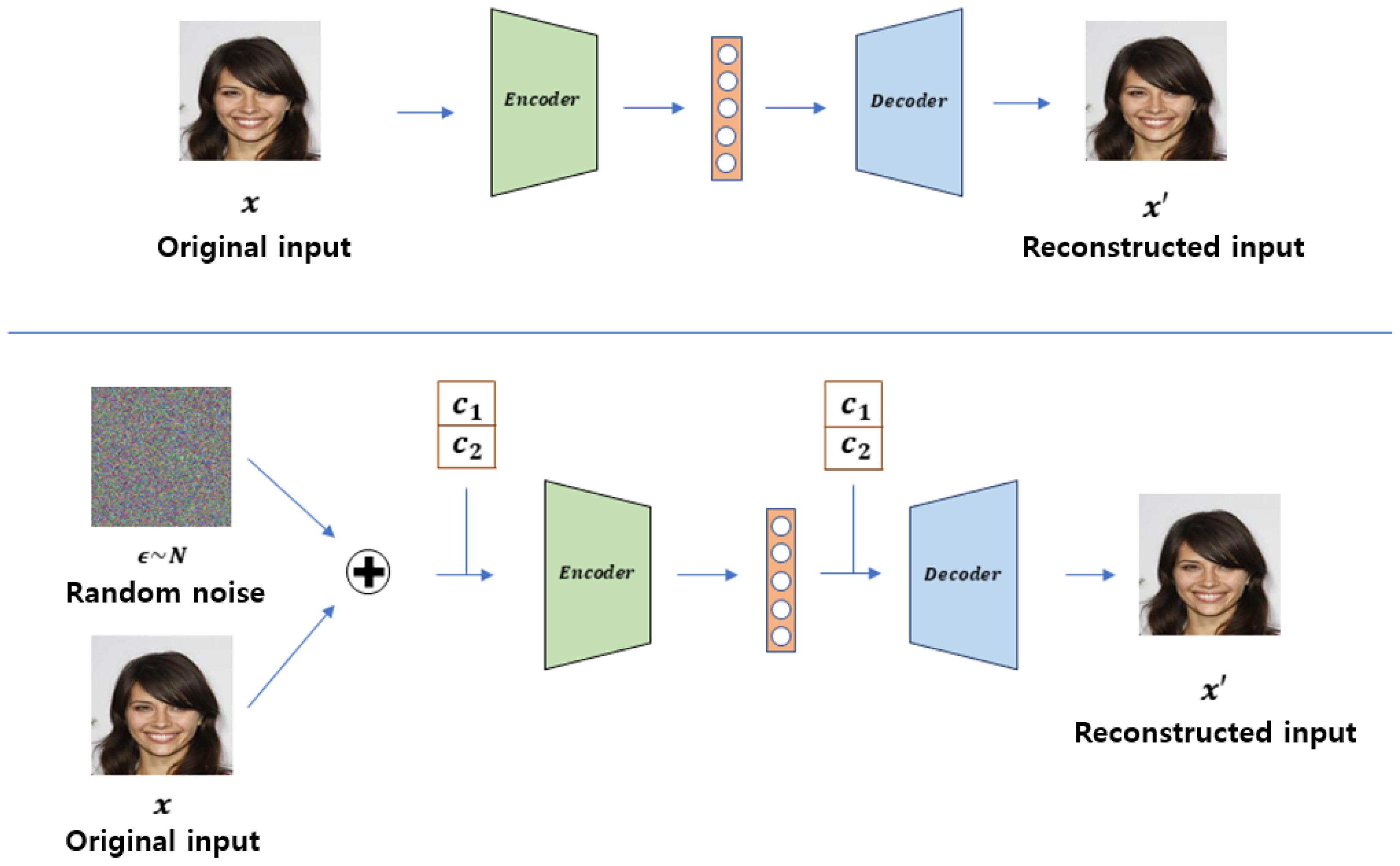
1. Introduction
- We present a novel data augmentation method based on GANs. Our proposed method can generate minority class data accurately in imbalanced datasets.
- For stable GAN training, we present a new denoising autoencoder initialization technique with explicit class conditioning in the latent space.
- We conduct various experiments showing underlying problems in conventional methodologies. We experimentally show that majority class data can help generate minority class data and considerably enhance its classification accuracy.
2. Related Work
2.1. Data Augmentation Methods
2.2. Methods for Imbalanced Datasets
2.3. GAN-Based Methods
3. The Proposed Method
3.1. Difficulties in Autoencoder Initialization
3.2. Difficulties in High-Resolution Data Generation
3.3. Class-Conditional GAN-Based DA
4. Experiments
4.1. Implementation Details
4.2. Ablation Study
4.3. Data Augmentation Comparison
4.4. Data Classification Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Mariani, G.; Scheidegger, F.; Istrate, R.; Bekas, C.; Malossi, A.C.I. BAGAN: Data Augmentation with Balancing GAN. arXiv 2018, arXiv:1803.09655. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinouscie, Poland, 9–12 May 2018. [Google Scholar]
- Galdran, A.; Alvarez-Gila, A.; Meyer, M.I.; Saratxaga, C.L.; Araújo, T.; Garrote, E.; Aresta, G.; Costa, P.; Mendonça, A.M.; Campilho, A. Data-Driven Color Augmentation Techniques for Deep Skin Image Analysis. arXiv 2017, arXiv:1703.03702, 2017. [Google Scholar]
- Kwasigroch, A.; Mikołajczyk, A.; Grochowski, M. Deep convolutional neural networks as a decision support tool in medical problems—Malignant melanoma case study. In Trends in Advanced Intelligent Control, Optimization and Automation; Mitkowski, W., Kacprzyk, J., Oprze dkiewicz, K., Skruch, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Okafor, E.; Schomaker, L.; Wiering, M.A. An analysis of rotation matrix and colour constancy data augmentation in classifying images of animals. J. Inf. Telecommun. 2018, 2, 465–491. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]
- Drummond, C.; Holte, R. C4.5, Class imbalance, and cost sensitivity: Why under-sampling beats oversampling. In Proceedings of the Workshop on Learning from Imbalanced Datasets II, Washington, DC, USA, 21–24 August 2003. [Google Scholar]
- Estabrooks, A.; Jo, T.; Japkowicz, N. A Multiple Resampling Method for Learning from Imbalanced Data Sets. Comput. Intell. 2004, 20, 18–36. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning; Advances in Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Maciejewski, T.; Stefanowski, J. Local neighbourhood extension of SMOTE for mining imbalanced data. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011. [Google Scholar]
- Oquab, M.; Bottou, L.; Laptev, I.; Sivic, J. Learning and Transferring Mid-Level Image Representations Using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, Y.; Chawla, N.V.; Krasser, S. SVMs Modeling for Highly Imbalanced Classification. IEEE Trans. Syst. Man Cybern. Part B 2009, 39, 281–288. [Google Scholar] [CrossRef] [PubMed]
- Thai-Nghe, N.; Gantner, Z.; Schmidt-Thieme, L. Cost-sensitive learning methods for imbalanced data. In Proceedings of the The 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010. [Google Scholar]
- Yang, C.Y.; Yang, J.S.; Wang, J.J. Margin calibration in SVM class-imbalanced learning. Neurocomputing 2009, 73, 397–411. [Google Scholar] [CrossRef]
- Zadrozny, B.; Langford, J.; Abe, N. Cost-sensitive learning by cost-proportionate example weighting. In Proceedings of the Third IEEE International Conference on Data Mining (ICDM), Melbourne, FL, USA, 19–22 December 2003. [Google Scholar]
- Zhou, Z.H.; Liu, X.Y. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2006, 18, 63–77. [Google Scholar] [CrossRef]
- Ting, K.M. A Comparative Study of Cost-Sensitive Boosting Algorithms. In Proceedings of the 17th International Conference on Machine Learning (ICML), Stanford, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Wang, Y.; Gan, W.; Yang, J.; Wu, W.; Yan, J. Dynamic Curriculum Learning for Imbalanced Data Classification. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Aggarwal, U.; Popescu, A.; Hudelot, C. Active Learning for Imbalanced Datasets. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 2–5 March 2020. [Google Scholar]
- Liu, Z.; Miao, Z.; Zhan, X.; Wang, J.; Gong, B.; Yu, S.X. Large-Scale Long-Tailed Recognition in an Open World. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Learning to Model the Tail. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hayat, M.; Khan, S.; Zamir, S.W.; Shen, J.; Shao, L. Gaussian Affinity for Max-Margin Class Imbalanced Learning. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kim, J.; Jeong, J.; Shin, J. M2m: Imbalanced Classification via Major-to-Minor Translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Lim, S.K.; Loo, Y.; Tran, N.T.; Cheung, N.M.; Roig, G.; Elovici, Y. DOPING: Generative Data Augmentation for Unsupervised Anomaly Detection with GAN. In Proceedings of the IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018. [Google Scholar]
- Douzas, G.; Bao, F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Expert Syst. Appl. 2018, 91, 464–471. [Google Scholar] [CrossRef]
- Li, Z.; Jin, Y.; Li, Y.; Lin, Z.; Wang, S. Imbalanced Adversarial Learning for Weather Image Generation and Classification. In Proceedings of the 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018. [Google Scholar]
- Mullick, S.S.; Datta, S.; Das, S. Generative Adversarial Minority Oversampling. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 12 October–2 November 2019. [Google Scholar]
- Cai, Z.; Wang, X.; Zhou, M.; Xu, J.; Jing, L. Supervised Class Distribution Learning for GANs-Based Imbalanced Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 12 October–2 November 2019. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral Normalization for Generative Adversarial Networks. arXiv 2018, arXiv:1802.05957, 2018. [Google Scholar]
- LeCun, Y.; Cortes, C.; Burges, C. MNIST Handwritten Digit Database. ATT Labs. 2010, Volume 2. Available online: http://yann.lecun.com/exdb/mnist (accessed on 5 July 2020).
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Rosenberg, A.; Hirschberg, J. V-Measure: A Conditional Entropy-Based External Cluster Evaluation Measure. In Proceedings of the Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Input Size | Output Size |
|---|---|---|
| Encoder | ||
| Conv + SN + lReLU | ||
| Conv + SN + lReLU | ||
| Conv + SN + lReLU | ||
| Conv + SN + lReLU | ||
| Conv + SN + lReLU | ||
| Conv + SN + lReLU | ||
| Conv + SN + lReLU | ||
| Conv + SN + lReLU | ||
| Flatten | ||
| Concat | , | |
| Dense | ||
| Decoder (Generator) | ||
| Concat | ||
| Dense + ReLU | ||
| Dense + ReLU | ||
| Tconv + ReLU | ||
| Tconv + ReLU | ||
| Tconv + ReLU | ||
| Tconv + ReLU | ||
| Tconv + Tanh | ||
| Discriminator | ||
| Encoder (partial) | ||
| flatten | ||
| Dense + Softmax |
| Method (Removal Ratio) | IS ↑ | FID ↓ |
|---|---|---|
| CelebA (real) | 2.79 ± 0.09 | 11.53 |
| BAGAN (0.6) | 1.89 ± 0.02 | 79.79 |
| BAGAN (0.7) | 1.79 ± 0.03 | 82.20 |
| BAGAN (0.8) | 1.78 ± 0.03 | 138.97 |
| BAGAN (0.9) | 1.83 ± 0.02 | 167.62 |
| GANDA (0.6) | 2.18 ± 0.05 | 48.89 |
| GANDA (0.7) | 1.93 ± 0.03 | 65.32 |
| GANDA (0.8) | 1.93 ± 0.02 | 71.45 |
| GANDA (0.9) | 1.84 ± 0.02 | 91.86 |
| V-Score (K-Means) | |
|---|---|
| GANDA (conditional denoising autoencoder initialization) | 0.779 |
| BAGAN (denoising autoencoder initialization) | 0.739 |
| 60 | 80 | 90 | 95 | 97.5 | |
|---|---|---|---|---|---|
| Plain | 99.13 | 98.87 | 98.62 | 96.51 | 95.4 |
| Vanilla GAN [1] | 98.96 | 98.92 | 98.35 | 96.64 | 95.12 |
| ACGAN [7] | 99.21 | 98.73 | 98.43 | 96.72 | 95.96 |
| BAGAN [2] | 99.38 | 98.87 | 98.67 | 97.75 | 96.2 |
| GANDA (ours) | 99.79 | 99.48 | 99.18 | 97.63 | 96.42 |
| 60 | 70 | 80 | 90 | |
|---|---|---|---|---|
| Plain | 92.52 | 91.54 | 89.24 | 83.94 |
| BAGAN | 93.55 | 90.33 | 88.49 | 82.73 |
| GANDA (ours) | 94.59 | 93.67 | 90.79 | 85.73 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Yoon, Y.; Kwon, J. Generative Adversarial Network for Class-Conditional Data Augmentation. Appl. Sci. 2020, 10, 8415. https://doi.org/10.3390/app10238415
Lee J, Yoon Y, Kwon J. Generative Adversarial Network for Class-Conditional Data Augmentation. Applied Sciences. 2020; 10(23):8415. https://doi.org/10.3390/app10238415
Chicago/Turabian StyleLee, Jeongmin, Younkyoung Yoon, and Junseok Kwon. 2020. "Generative Adversarial Network for Class-Conditional Data Augmentation" Applied Sciences 10, no. 23: 8415. https://doi.org/10.3390/app10238415
APA StyleLee, J., Yoon, Y., & Kwon, J. (2020). Generative Adversarial Network for Class-Conditional Data Augmentation. Applied Sciences, 10(23), 8415. https://doi.org/10.3390/app10238415