1. Introduction
Malaysia is enriched with 189 river basins nationwide. This natural resource performs a crucial role in the economic and social development of the country [
1]. More specifically, rivers are the major source of water for irrigation, residential, industrial, agricultural, and other human activities. Surface water in the form of streams and rivers contributes 97% of raw water supply [
2]. Consequently, due to the over-dependence on surface water for food, recreation, water supply, transportation, and energy, the quality of river water is threatened by various factors [
3]. Physicochemical and biological indicators have been used to assess and estimate the quality of river water [
4].
Another important aspect of hydrology in Malaysia is water resource management. Water resource management can be defined as a procedure for evaluating the scope, source, quality, and amount of water resources for adequate water resource management and utilization. In the aspect of quantity, artificial neural networks (ANNs) have been employed in previous studies for the prediction of river flow modelling in Malaysia and other countries [
5]. For instance, in the case of Malaysian rivers, Mustafa et al. [
6] applied a radial basis function (RBF) neural network in forecasting the suspended sediment (SS) discharge of the Pari River. The outcome of the study showed that the RBF neural network models are adequate and they can forecast the nonlinear activity of the suspended solid discharge. Tengeleng and Armand [
7] applied cascade-forward backpropagation neural networks to predict rain rate, radar reflectivity and water content with raindrop size distribution. The research was conducted in five localities of African countries; Côte d’Ivoire, Cameroon, Senegal, Congo-Brazaville and Niger.
Furthermore, the performance of two ANNs such as RBF and feed-forward neural networks (FFNN) has been compared in the study of Rantau Panjang streamflow station, Sungai Johor [
8]. The result indicated that the FFNN model gave a better performance in estimating the sediment load compared to the RBF model. Memarian and Balasundram [
9] compared two other ANNs, namely, Multi-Layer Perceptron (MLP) and RBF for predicting sediment load at Langat River. However, MLP showed better performance, although both ANNs models have demonstrated limited effectiveness in estimating large sediment loads. Similarly, Uca et al. [
10] compared the performance of Multiple Linear Regression (MLRg) and ANN in the prediction of SS discharge of the Jenderam catchment area. The ANN methods used are RBF and feed-forward multi-layer perceptron with three learning algorithms, i.e., Broyden–Fletcher–Goldfarb–Shanno Quasi-Newton (BFGS), Levenberg–Marquardt (LM), and Scaled Conjugate Descent (SCD). The effect of different numbers of neurons in the ANN trained with difference algorithms were studied. Moreover, Hayder et al. [
1] applied ANN in predicting the physicochemical parameters of Kelantan River. The ANN model was trained by using the optimized value of look back and epoch number. The performance criteria were obtained by calculating the Pearson correlation coefficient (PCC), root mean square error (RMSE), and mean absolute percentage error (MAPE). The findings of the study indicated that the estimation of the pH parameter gave the best performance. Moreover, the lowest kurtosis values of pH suggest that the presence of outliers impacted on the model.
However, artificial neural networks (ANNs) require further elaboration for their experimentations and applications. Machine learning tools, including ANNs, need to be trained before being deployed into real applications to solve a given task. This process is performed in order to identify the best combination of bias and weight values of each neuron by optimizing a cost function that quantifies the mean differences between the predicted and actual output [
11]. In light of the above discussion, ANN training is commonly performed using a gradient-based algorithm known as backpropagation (BP) and its variants [
12]. Despite its widespread applications in ANN training, the performance of BP algorithm is highly dependent on the weight and bias values of each neuron initialized in the multi-layer ANNs. Furthermore, BP also tends to produce suboptimal solutions of neuron weight and bias values during the training process, hence restricting the performance of ANN [
11,
12,
13]. Recently, there are growing interests in exploiting the excellent global search ability and stochastics natures of metaheuristic search algorithms (MSAs), including Particle Swarm Optimization (PSO) used in this study, to perform ANNs training [
11,
12,
13,
14,
15,
16,
17]. As compared to the BP algorithm, MSAs have more competitive advantages in solving ANNs training problems with faster convergence without requiring good initial solutions [
11,
13].
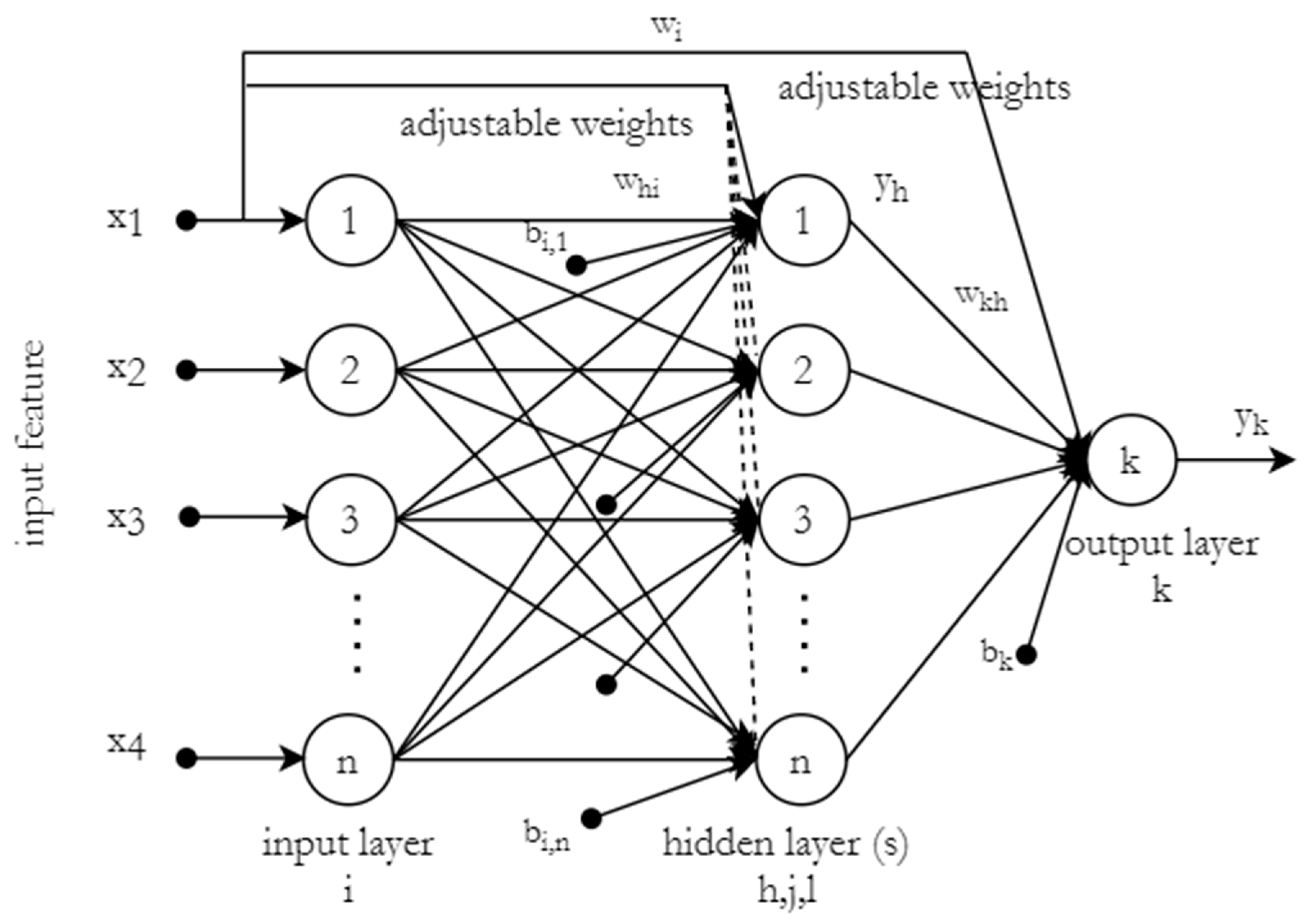
Therefore, this study presents the application of ANNs-based predictive modelling trained using PSO. Particularly, cascade-forward neural networks trained with PSO (CFNNPSO) for the prediction of river flow are presented. This study validates the functional ability and significance of ANN techniques in the simulation of real-world and complex nonlinear water system processes. In addition, this research gives an insight into ANNs modelling in the Kelantan river scenario and the importance of understanding a river basin and variables before attempting to model the river flow. River flow can be effectively modelled with intelligent ANNs models, despite the spatial changes in the study field.
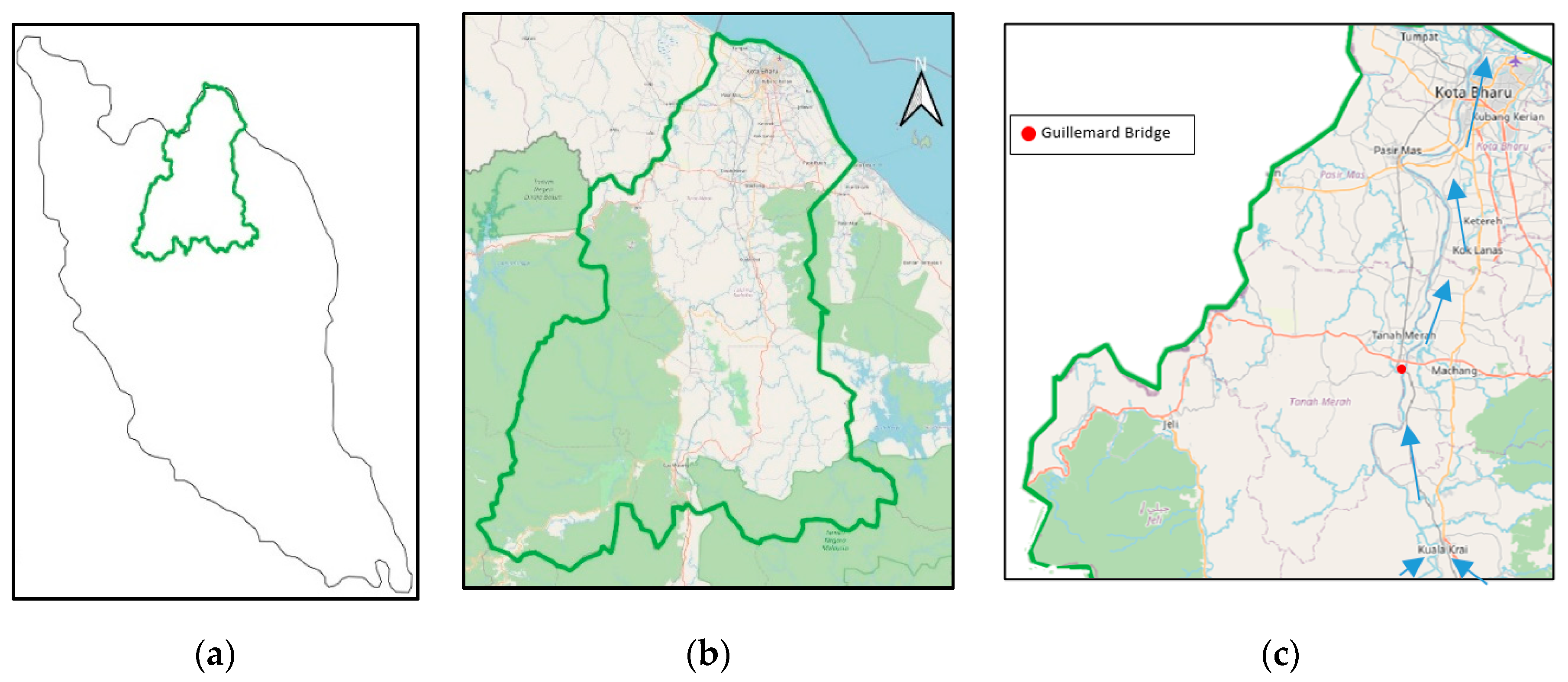
The river flow of Sungai Kelantan in the northeast part of Malaysia is predicted by using FFNN and CFNN based on available meteorological input variables (features) namely; weighted rainfall (mm), evaporation (mm), min of temperature (°C), mean of temperature (°C) and max of temperature (°C). Some of the ANNs-related experimentation carried out in this study includes; feature/input variables selection, the effective number of hidden layer neurons, and performance comparison between CFNN and standard multi-layer FFNN trained with PSO and other common training algorithms such as Levenberg–Marquardt (LM), Bayesian Regularization (BR) backpropagation. This study has practical meaning from the perspective of the current state-of-the-art in artificial intelligence (AI) and the Internet of Things (IoT) technology. The machine learning model can be deployed in different ways, such as using a web app or real-time monitoring device to predict Kelantan river flow based on the readily available meteorological data. The applicability of this tool will be of importance nowadays in the realm of Industrial Revolution 4.0.
3. Results and Discussion
According to the summary listed in
Table 2, some experimentation needs to be carried out to investigate various setups of the ANN model that will give the optimum prediction results. The first result is a related feature selection, as this is the first stage of data preparation before ANN training. The features were selected based on the correlation score between the independent variable (input features) and the dependent variable (target).
Table 3 shows the correlation score for each feature and the target/output variable. The result indicates a strong correlation (R = 0.739) between weighted rainfall (
) and the river flow (
). It can be concluded that the correlation between a min of temperature (
) and the target variable (
) is very low and therefore
was removed from the input feature. The lowly correlated feature would degrade the prediction accuracy if it was not removed from the feature.
With these four selected features (after removing ), the ANN training experimentation proceeds and the evaluation is performed. For the model parsimony reason, further removal of either feature or is also investigated to ascertain whether it affects the model accuracy. This is because these two features are of the same type, i.e., temperatures.
The first experimentation is mainly to investigate the number of hidden layer neurons and comparisons between FFNN and CFNN trained with the LM algorithm.
Table 4 shows the results of this experimentation. The two numbers in the hidden layer neurons indicated that two hidden layers were used with the corresponding number of neurons in each layer. In the first column of
Table 4, the notation in the square bracket indicates the number of hidden layer neurons, for example, [
5] meaning there are 5 neurons in 1 layer, {10 + 10} meaning that there are 10 neurons in two hidden layers, etc.
The main finding in this experimentation is that the ANN trained with LM algorithm have a high tendency of overfitting, i.e., good prediction (even perfect, ) for training data but poor prediction of testing data. This occurs in both models using FFNN and CNNN structure. Some worse cases of this situation are highlighted in gray where the obtained RMSE is very high such that the ANN failed to make predictions, i.e., resulting negative values of , marked with ‘−’ in the Table. In addition, increasing the number of neurons (and layers) tends to increase the chance of overfitting.
The second experimentation is the same as the first, but the BR training algorithm was used.
Table 5 shows the results of this experimentation. In
Table 5, the lower RMSEs obtained during model testing are marked by ‘*’ and the overfitting situations are highlighted in gray. It can be seen from
Table 5 that, generally, CFNN with one hidden layer (5 to 20 number of hidden neurons) sufficiently produced lower RMSEs when it is trained with BR algorithms. Moreover, the increasing number of neurons (and layers) did not give a satisfactory performance as can be seen from both
Table 4 and
Table 5. Especially for the FFNN, poor generalization capability (overfitting) was observed when the number of hidden neurons gets larger. During testing, the lowest RMSE of 211.1 was obtained when CFNN with 20 hidden neurons (1 layer) was trained with the BR algorithm.
The third experimentation was conducted to show the results of FFNN and CFNN training using the PSO algorithm (FFNNPSO and CFNNPSO respectively) where Clerc’s PSO version was used. The number of populations used in the PSO is set to 40, and the iteration number is set to 1000, the same as the one used in the LM and BR algorithms. The results are shown in
Table 6. As compared to the previously trained ANN with LM and BR algorithm, both FFNN and CFNN trained with PSO (FFNNPSO and CFNNPSO) generally show good prediction ability in both the training and testing dataset, except for a few cases when two hidden layers are used (highlighted in gray). Therefore, it is preferable to use only one hidden layer to prevent overfitting. Thus, in the next experimentation, only one hidden layer was used with some variations in the number of neurons. The few lowest RMSE during testing were obtained (marked by ‘*’) for both FFNNPSO and CFNNPSO with 1 hidden layer, except for 1 case of FFNNPSO (row 5 of
Table 6). In all experimentations with one hidden layer, only FFNNPSO with 10 hidden neurons shows slightly lower RMSE during the testing, as shown in row 2 of
Table 6.
Furthermore, the fourth and fifth experimentation was conducted to investigate the CFNN model performance when only three features were used as the parsimonious model. The three features (
) were used in the fourth experimentation, while another combination of three features (
) were used in the fifth experimentation. The result of the fourth experimentation is shown in
Table 7, where FFNNPSO and CFNNPSO with a different number of neurons in one hidden layer were investigated. The result indicates that it is possible to have a parsimonious model with only three features (
) as the ANN input. The prediction on testing data gave the best performance of
,
cms and
when CFNNPSO with 10 hidden neurons was trained despite slightly lower RMSE during the training as compared to the rest. This makes sense since the feature
and
are basically of the same type, i.e., mean and max temperatures, as compared to the result in
Table 6 with four features. Similarly, the results obtained in this study corroborates with the work of Khaki et al. [
35], who reported an
value of 0.84 in the estimation of Langat Basin using a feed-forward neural network. Additionally, Hong and Hong [
36] obtained
values of 0.85, 0.81, and 0.85 for validation, training and testing datasets, respectively, when multi-layer perceptron neural network models were applied in estimating the water levels of Klang River.
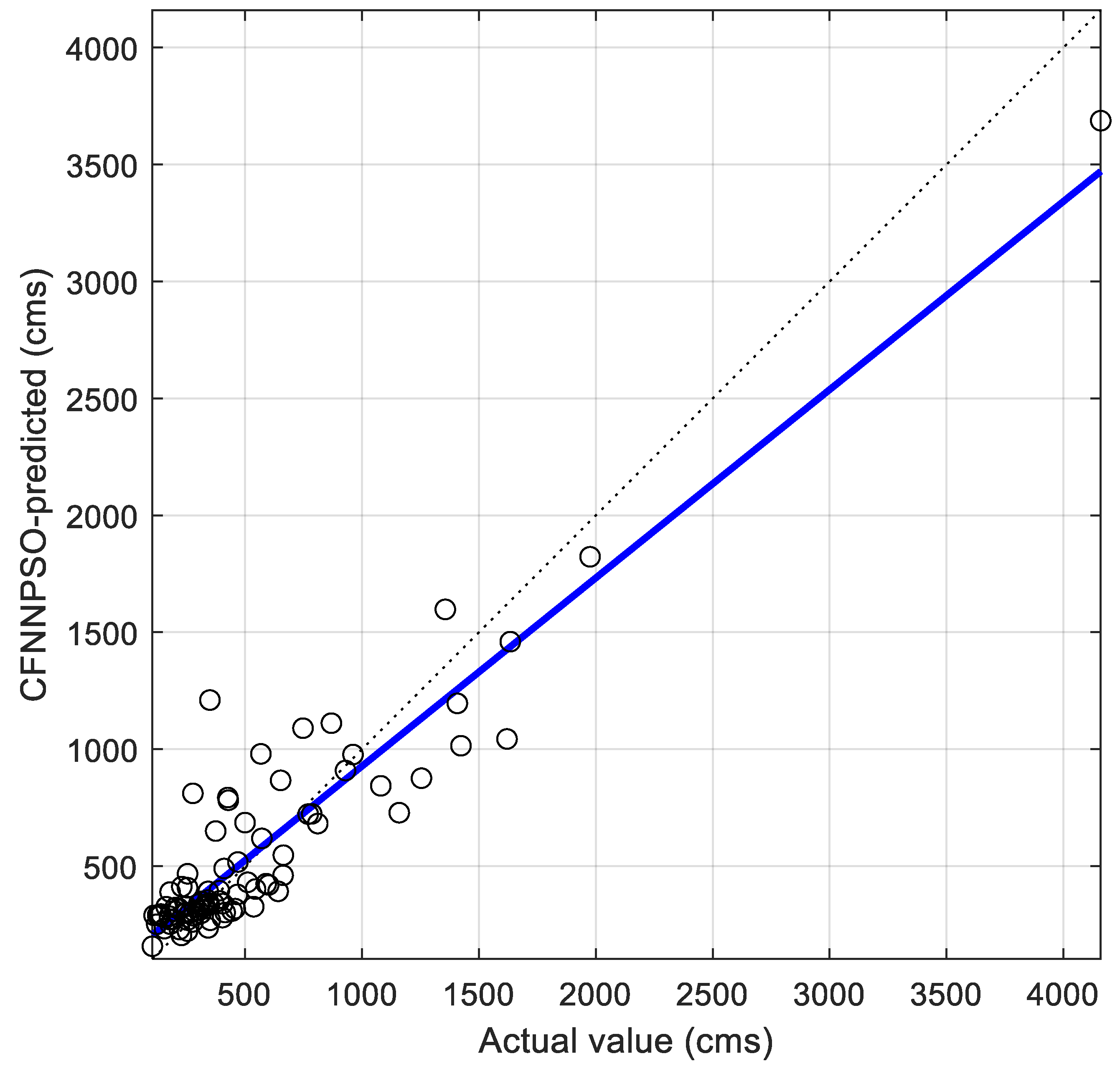
Figure 4 shows the regression plot of the best testing performance for CFNNPSO, with 10 hidden neurons (1 layer) and three input features (
), resulting to
,
cms and
.
Table 8 shows the results of the fifth experimentation using another three combinations of features (
). However, the result shows quite significant degradation of the model performance, particularly with the training dataset. This means that the combination of the three features is not feasible to build a parsimonious predictive model. As the final remarks on the feature selection, the accurate model can be achieved using four features (
) or using three features (
) as these two can achieve comparable performance as long as one hidden layer is used. In other words, ANNs trained with PSO were able to achieve acceptable accuracy in predicting river flow by using only weighted rainfall, average evaporation and max temperature as input variables. However, CFNN structure is generally preferable as this can produce more robust generalization performance despite the number of neurons applied.
Furthermore, as a comparison, Multiple Linear Regression (MLR) is also used to benchmark the prediction outcome of the ANNs above. The MLR is trained via Lasso regression/L1 [
37] with the regularization parameter value (
as the same one used during training using the BR algorithm. With the three features (
), the resulting MLR prediction of the river flow can be expressed in the following equation:
The MLR prediction on the test dataset produces a regression coefficient () of 0.73 and an RMSE of 279.3 cms, which is lower accuracy compared to the FFNNPSO and CFNNPSO prediction. This makes sense since MLR assume linear relation on the variables.
Finally, the results of this study can be improved from the enhancement of data and improvement of the algorithm. Data-driven predictive modelling relies on the quantity and quality of the recorded data. Moreover, collection of field data is a costly practice that provides a series of snapshots of watercourse behaviour and supplements existing information. Therefore, it is essential to carry out a collaborative desk analysis to gather established existing records from different sources (consultants, environment agency or water services company) to improve current understanding and expertise deficiencies [
38]. Additionally, hydrological and mathematical models play a significant role in the forecasting of river basins using field data obtained from different temporal and spatial scales [
39].
4. Conclusions
Predictive modelling of river flow based on meteorological weather data using the Multilayer Artificial Neural Networks (ANNs) Particle Swarm Optimization (PSO) algorithm has been discussed. Sungai Kelantan river flow data ranging from January 1988 to December 2016 was used. The results demonstrate the potential applications of ANNs as an artificial intelligence-machine learning tool to predict river flow variables based on meteorological and weather data as studied in this paper, where two ANNs structures were used: feed-forward neural networks (FFNN) and cascade-forward neural networks (CFNN). The PSO algorithm used to train the ANN has also contributed to the advancement of the predictive model building. Generally, ANNs with one hidden layer trained using PSO were able to produce acceptable accuracy and good generalization for both the training and testing dataset. This result is better than the prediction performance of the Multiple Linear Regression (MLR) trained via Lasso Regression/L1. Moreover, a parsimonious model with reduced features was proposed; this feature was carefully selected. From the parsimonious model experimentation, it was possible to build an ANNs predictive model that can achieve acceptable accuracy in predicting river flow by using only weighted rainfall, average evaporation and max temperature as input variables. The experimentation results also indicate that CFNN trained using the PSO algorithm has more robust generalization performance compared to FFNN in the reduced feature (parsimonious) model. The model accuracy can still be improved using advanced techniques in machine learning modelling such as the ensemble method, improvement of the optimizer and cross-validation training procedure.
Furthermore, future research will work on some areas including benchmarking with other machine learning algorithms, benchmarking with other mete-heuristic algorithms for ANN training, data augmentation to enhance the diversity of the available data without generating actual data and real-time deployment of the predictive model in the Internet of Things (IoT) scenario. Despite the efficiency of ANNs as a black box model for river flow modelling, further exploration of research in this area is required. These include an automated feature selection mechanism, the possibility of using Deep learning neural networks regression, and improvement of accuracy to reduce overfitting via different optimizer algorithms. Another area includes the deployment stage of the machine learning model, which can involve Big Data, IoT and the Cloud computing platform. As AI tools in this regard are easily available nowadays, the area of this study promises high applicability of hydro-informatics systems, especially in Malaysia. This hydro-informatics concept and implementation need more extensive attention by authorities and decision makers to deal with water resource management which is currently a serious issue in some countries.







{kind=link}
{kind=link}
{kind=link}
{kind=link}