This section contains information about the experimental conditions, datasets used in the experiments and parameter selection. Lastly, the classification results obtained are presented.
3.1. Experimental Conditions
All the experiments were run using the classification scheme and network architecture described in
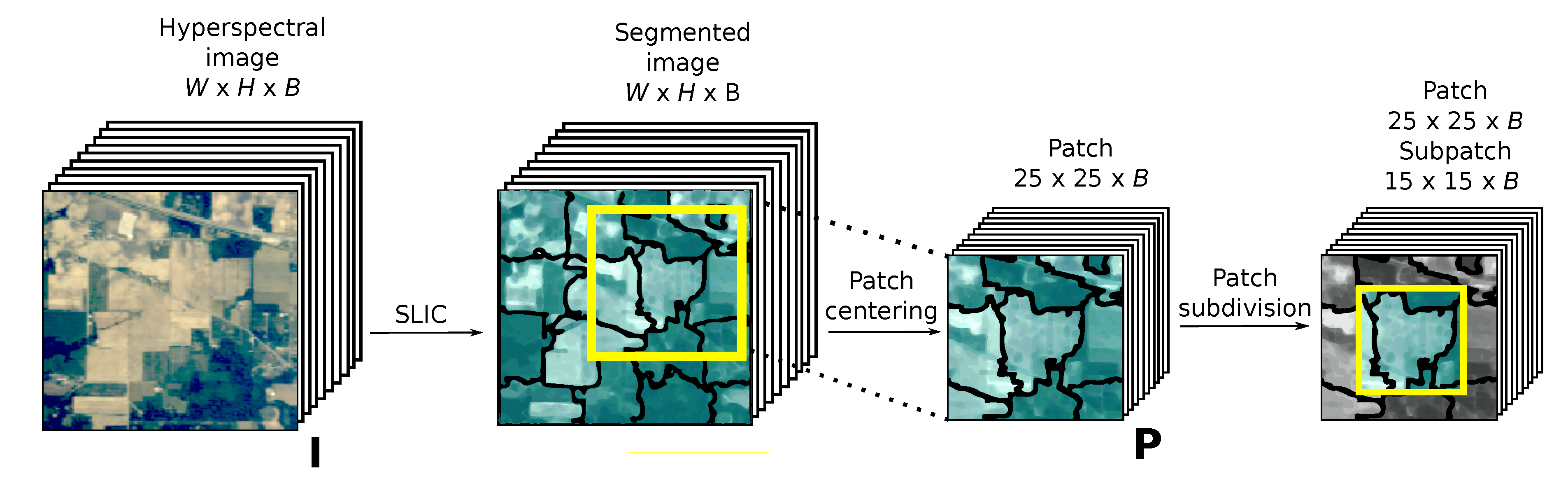
Figure 6. The figure shows, on the left, a patch extracted from the HSI. The black boundaries represent the superpixel edges. The extraction process is explained in
Section 2.1. The data augmentation technique of choice was then applied to the patch. The data augmentation techniques based on DWS are explained in
Section 2.3. The patches resulting from this data augmentation process were then fed to the CNN.
The network consists of two blocks of 2D-convolutional layers coupled with 2D-max-pooling layers, and two dense layers. With the aim of reducing overfitting, two dropout layers were added to the network, both of them using an aggressive dropout ratio of 0.5.
Table 1 details the parameters for each layer. ELU activations were used for all layers due to the advantages this function has over others such as the ReLU family. Namely, ELU provides more robust training and faster learning rates [
25]. All trainings were run for 112 epochs using a NADAM [
26] optimizer with
,
,
,
.
In the experiments, data augmentation was performed online for the first epoch and then cached for the rest of the training. The techniques considered are a set of commonly used data augmentation techniques from the literature and the four proposals introduced as part of this work. In the first group we have: rotate, the standard 90 degree rotation applied four times; flip, the standard flip over both axes of the image; PVS(+/−) or pixel-value shift augmentation, where pixel values of the input image are shifted relative to the average band [
12]; and random occlusion, which removes rectangular regions of the patch on up to 50% of the input patches in a batch [
13]. The new proposals to be studied include inner-rotate, inner-flip, dual-rotate and dual-flip, as described in
Section 2.3. The results are compared in terms of classification accuracy after the application of the different data augmentation techniques.
All the tests were run on a 6-core Intel i5 8400 CPU at 2.80 GHz and 48 GB of RAM, and an NVIDIA GeForce GTX 1060 with 6 GB. All experiments were run under Ubuntu Linux 16.04 64-bits, Docker 19.03.5, Python 3.6.7, Tensorflow 2.0.0 and CUDA toolkit 10.0. All the training instances were performed on Tensorflow with GPU support enabled, using single-precision arithmetic.
3.2. Datasets
This section describes the characteristics, including the compositions of the disjoint training and testing sets, of the six scenes used to evaluate the performance of the proposed data augmentation techniques. Three widely available hyperspectral scenes [
27] from the literature (standard dataset, from now onwards) and four large multispectral images from river basins belonging to the the Galicia dataset [
28] were considered. All the images of the Galicia dataset were captured at an altitude of 120 m by a UAV mounting a MicaSense RedEdge multispectral camera [
29]. Its spatial resolution is 0.082 m/pixel and it covers a spectral range from 475 to 840 nm.
Figure 7 and
Figure 8 display the false color composite and reference data for the scenes of the standard and Galicia datasets, respectively.
More specifically, the Salinas Valley, Pavia University and Pavia Centre scenes from the standard dataset along with the River Oitavén, Creek Ermidas, Eiras Dam and River Mestas scenes from the Galicia dataset were selected for the experiments. The detailed descriptions of the scenes are as follows:
Salinas valley (Salinas): Mixed vegetation scene in California. It was obtained by the NASA AVIRIS sensor with a spatial resolution of 3.7 m/pixel, covering a spectral range from 400 to 2500 nm. The image is pixels and has 220 spectral bands. The reference information contains sixteen classes. The scene is located at 363933.8 N 1213958.7 W.
Pavia University (PaviaU): Urban scene acquired by the ROSIS-03 sensor over the city of Pavia, Italy. Its spatial resolution is 2.6 m/pixel and covers a spectral range from 430 to 860 nm. The image is pixels and has 103 spectral bands. The ground truth contains nine classes. The scene is located at 451209.2 N 90808.6 E.
Pavia Centre (PaviaC): Urban scene acquired by the ROSIS-03 sensor over the city of Pavia, Italy. Its spatial resolution is 2.6 m/pixel and covers a spectral range from 430 to 860 nm. The image is pixels and has 103 spectral bands. The ground truth contains nine classes. The scene is located at 451112.7 N 90848.7 E.
River Oitavén (Oitaven): Multispectral vegetation scene of the Oitaven river from Pontevedra, Spain. The image is pixels and has 5 bands. The scene is located at 422215.3 N 82547.4 W.
Creek Ermidas (Ermidas): Multispectral vegetation scene showing the point where Creek Ermidas and River Oitavén meet, from Pontevedra, Spain. The image is 11,924 × 18,972 pixels and has 5 bands. The scene is located at 422251.9 N 82453.5 W.
Eiras Dam (Eiras): Multispectral vegetation scene showing the reservoir that supplies running water to the town of Vigo from Pontevedra, Spain. The image is 5176 × 18,224 pixels and has 5 bands. The scene is located at 422046.5 N 83010.5 W.
River Mestas (Mestas): Multispectral vegetation scene showing the River Mestas from Pontevedra, Spain. The image is pixels and has 5 bands. The scene is located at 433829.8 N 75842.2 W.
Table 2 and
Table 3 show the number of samples for each class for all the scenes in all the scenarios considered in this comparison. The scenes from both datasets were used as follows: 60% for training samples, 20% for testing samples and 20% for validation samples for superpixel-based classification.
Table 2 also displays the number of samples for pixel-based classification; 20% of the samples were used, again, as the validation set for this scenario. The number of samples was chosen to prevent an excessively high baseline accuracy when no data augmentation technique was used.
Scenes 1 to 3 were segmented using SLIC with a superpixel size of 50 and a compactness parameter of 20, whereas datasets 4, 5, 6 and 7 used a superpixel size of 800 and a compactness parameter of 40. The compactness determines the balance of space and spectral proximity, with higher values favoring space proximity and causing segments to take on a more square shape.
Two augmentation factors of
and
were considered, and are displayed in the tables next to the name of each data augmentation technique. For every experiment, the following three accuracy measures [
30] are reported: overall accuracy (OA), representing the number of overall pixels correctly predicted; average accuracy (AA), the mean of correctly classified pixels per class; and Kappa (
), which measures the agreement between pixel predictions across all classes, also taking into account the occurrences attributed to chance [
31]. The values shown are the results of 20 Monte Carlo runs for each scenario. All the values were obtained under identical experimental conditions.
3.3. Superpixel-Based Classification
This section contains the experimental results of the proposal for superpixel-based classification, as described in
Section 2. A single scenario training the network with the 60% of the labeled superpixels available has been considered. The classification performance was measured at the pixel level, i.e., considering the same label for all the pixels in the same superpixel.
In order to select values for superpixel size and patch size, some tests were run using one image considered as representative of each of the datasets. PaviaC was selected from the standard dataset and Oitaven was chosen as the counterpart from the Galicia dataset. The results were obtained for two scenarios, one where no augmentation was applied, and a second one where the DWS-based dual-flip technique was used in order to improve accuracy. Values for superpixel sizes each represent an average superpixel area used in the SLIC segmentation. Values for patch sizes each represent the size of a side of the square patch used in the CNN classification process. Inner region sizes are 10 pixels smaller than the corresponding outer regions. The relationship between inner and outer size was chosen as a trade-off between the variability introduced by the transformations applied to the data and the relevance of the inner region. Small changes in inner patch size would not significantly alter the results obtained.
Figure 9 and
Figure 10 show the overall classification accuracy for the PaviaC and Oitaven images, respectively, as the superpixel area (left) and the patch size (right) vary. In general, we can observe an inverse correlation between superpixel sizes and accuracy of the CNN model. The accuracy without applying data augmentation is correlated with patch size, and bigger patches produce better results for the Oitaven image. The observed effect is smaller in the case of PaviaC. In this last case, the oscillations in the graph are caused by the dispersion of the values across experiments. Finally, results show a very limited increase in accuracy as the size of the patches grows when using the dual-flip augmentation technique.
The patch size selected for the experiments was pixels, with an inner region size of . The complexity of the proposed CNN is low, and as such, increases in patch size have a small impact during training, allowing us to work with larger amounts of data at this stage. In contrast to this, the amount of samples, most especially when augmentation is applied, has a large impact on the speed of the training stage. Due to this, and in order to keep computation times at moderate values, 50 and 800 were selected as the superpixel sizes for the scenes of the standard and Galicia datasets, respectively.
Figure 11,
Figure 12,
Figure 13 and
Figure 14 show the evolution of the training metrics across all the training epochs. It can be seen how the additional data generated by the augmentation methods cause the training process to converge earlier. As a result, significantly steeper curves in both loss and accuracy can be observed.
Table 4 shows the classification results for Salinas, PaviaU and PaviaC. These images were used for comparison purposes due to their prevalence in land-cover classification papers. Nevertheless, scenes of a size this small see limited benefits from a superpixel level classification, as they are low-resolution and contain very small and irregular structures. Dual-rotate
obtained the highest OA for Salinas, which contains bigger and more regular structures. The best results for PaviaU and PaviaC scenes were obtained by the flip
and rotate
techniques.
Table 5 shows the classification results for the large multispectral scenes of the Galicia dataset, namely, Oitaven, Ermidas, Eiras and Mestas. It can be seen that the proposed classification scheme obtained high accuracy across all datasets, even when no data augmentation was applied during training. Among the techniques tested, approaches based on the DWS framework introduced in this work achieved the best results: dual-rotate
and dual-flip
reached 96.20% and 96.19% OA for Oitaven, respectively. The results for Ermidas, Eiras and Mestas share many similarities, with dual-flip
and dual-rotate
leading in terms of OA. When a lower data augmentation factor is considered (
), inner-flip
and inner-rotate
can be seen systematically obtaining higher OA values than other methods. It can be seen that techniques based on flips tend to perform better than those based on rotations when applied under similar constraints.
Figure 15 shows the resulting classification maps for the images of the dataset.
In order to summarize the results,
Table 6 displays the performance differences between the baseline performance and each of the augmentation techniques. The results for the standard dataset show dual-rotate
was the best performing method overall, followed by flip
. For the Galicia dataset, dual-flip
and dual-rotate
obtained the highest increase in OA, with 1.51% and 1.42%, respectively.
3.4. Pixel-Based Classification
This section contains the experimental results of the proposal for pixel-based classification. This scenario was considered in order to show the performances of the proposed augmentation techniques with a traditional pixel-based classification scheme. The scheme applied was the same one described in
Section 2, albeit without the superpixel segmentation step. The patches are centered on pixels using a sliding window approach. Tests were run for the Salinas, PaviaU and PaviaC scenes.
Table 7 displays the execution times of all the augmentation techniques reviewed in this study for the PaviaC scene. Based on the data obtained, we can observe that the total execution times are significantly higher in the case of pixel-based classification. Training times have a very strong linear correlation with the augmentation factor, and thus, with the number of samples being processed. Prediction times are only dependent on the dimensions of the image, and there is little variation across the different executions. It is worth noting that pixel-based classification is not practical for large images due to the large execution time required. The large number of pixels that need to be predicted, three orders of magnitude higher than the number of training samples, causes prediction times to be significantly higher than training times.
Table 8 summarizes the pixel-based classification results for the Salinas, PaviaU and PaviaC images. It can be seen that dual-flip
obtained the highest OA for the Salinas scene; inner-flip
yielded the highest OA for PaviaU; and flip
was the best performing technique for PaviaC. Methods based on flip operations consistently outperformed rotations in this scenario.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}