From Electricity and Water Consumption Data to Information on Office Occupancy: A Supervised and Unsupervised Data Mining Approach



Abstract
1. Introduction
2. Methodology
2.1. Case Study
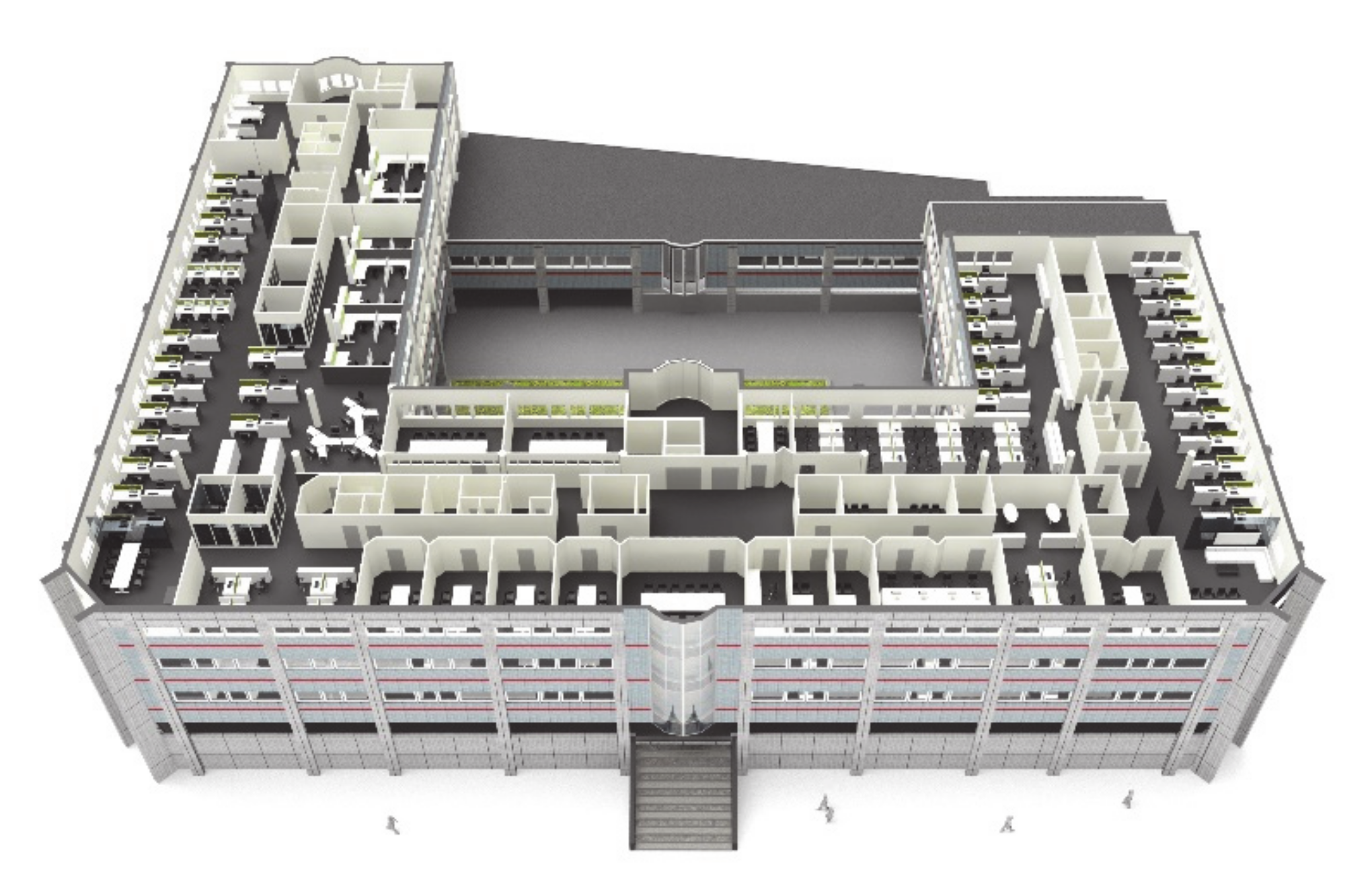
2.1.1. The Building
2.1.2. Electricity Sub-Metering
2.1.3. Water Consumption
2.1.4. Ground Truth
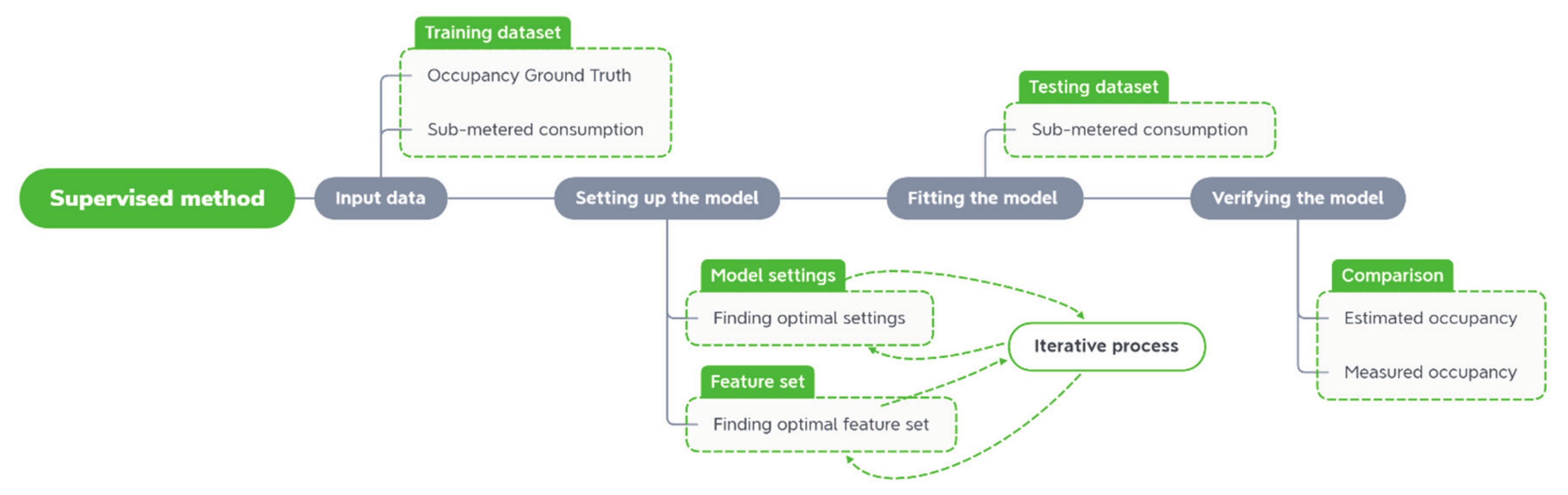
2.2. Supervised Method—Random Forest
Error Metrics for the Supervised Method
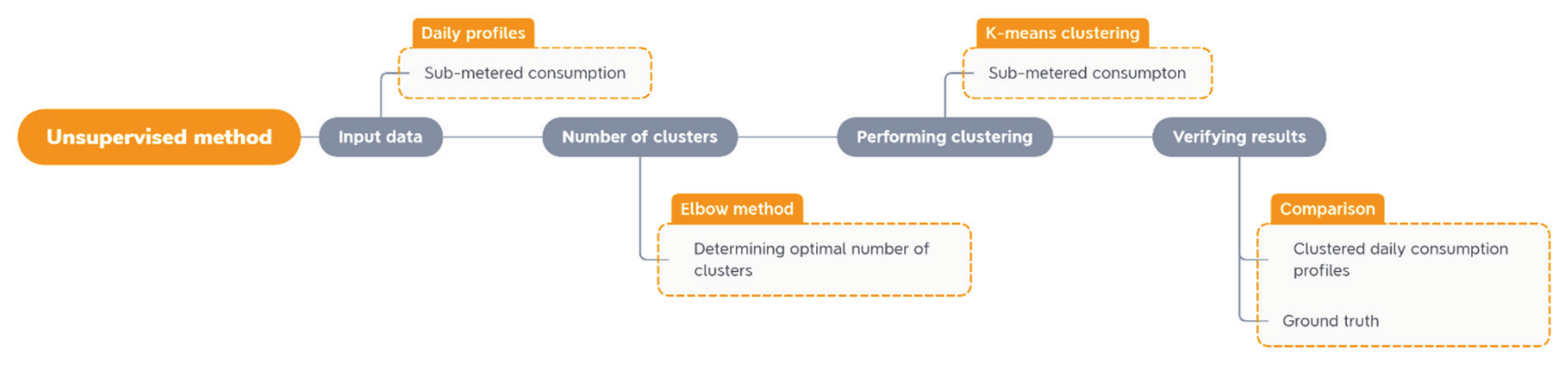
2.3. Unsupervised Method—The k-Means Clustering
3. Results
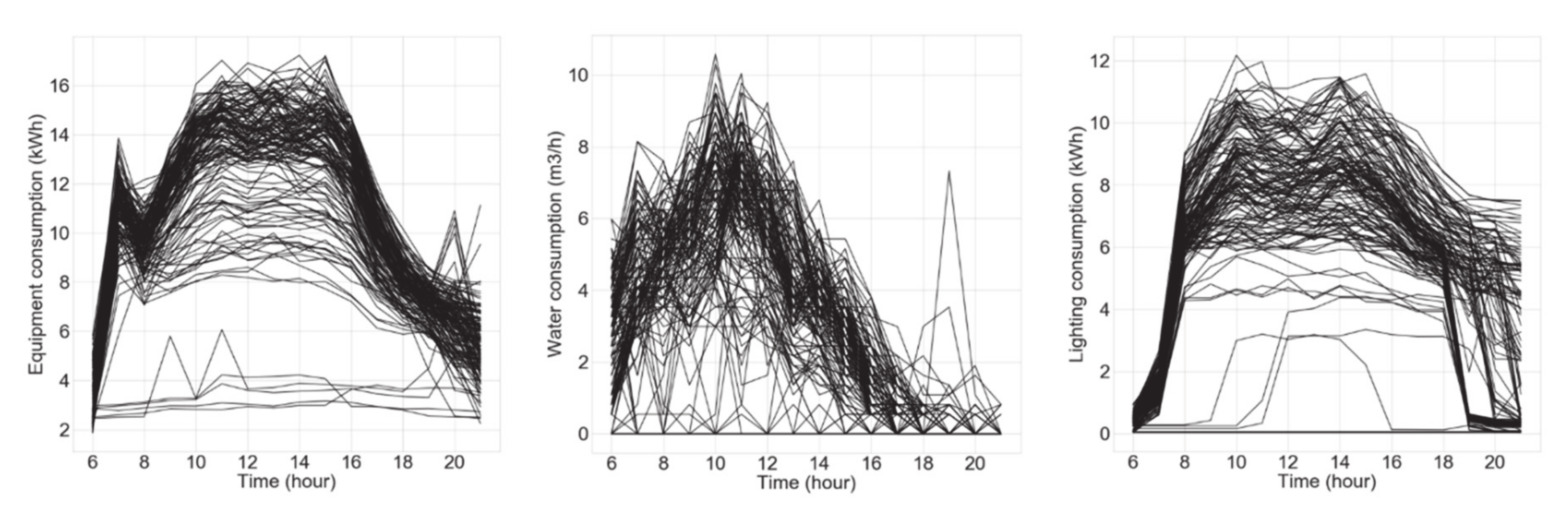
3.1. Data Gathering and Processing
3.2. Results of the Supervised Method
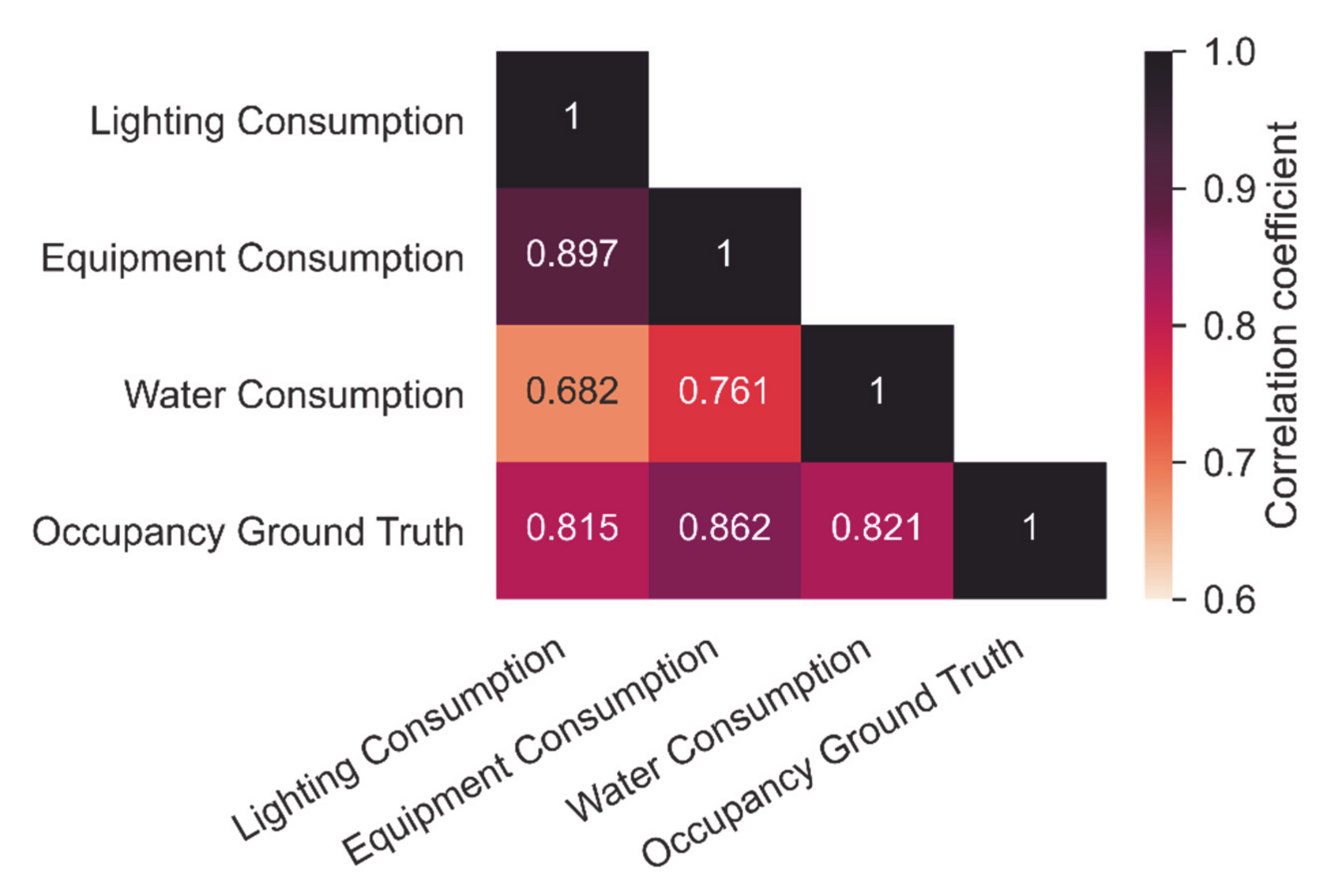
3.2.1. Selection of Features
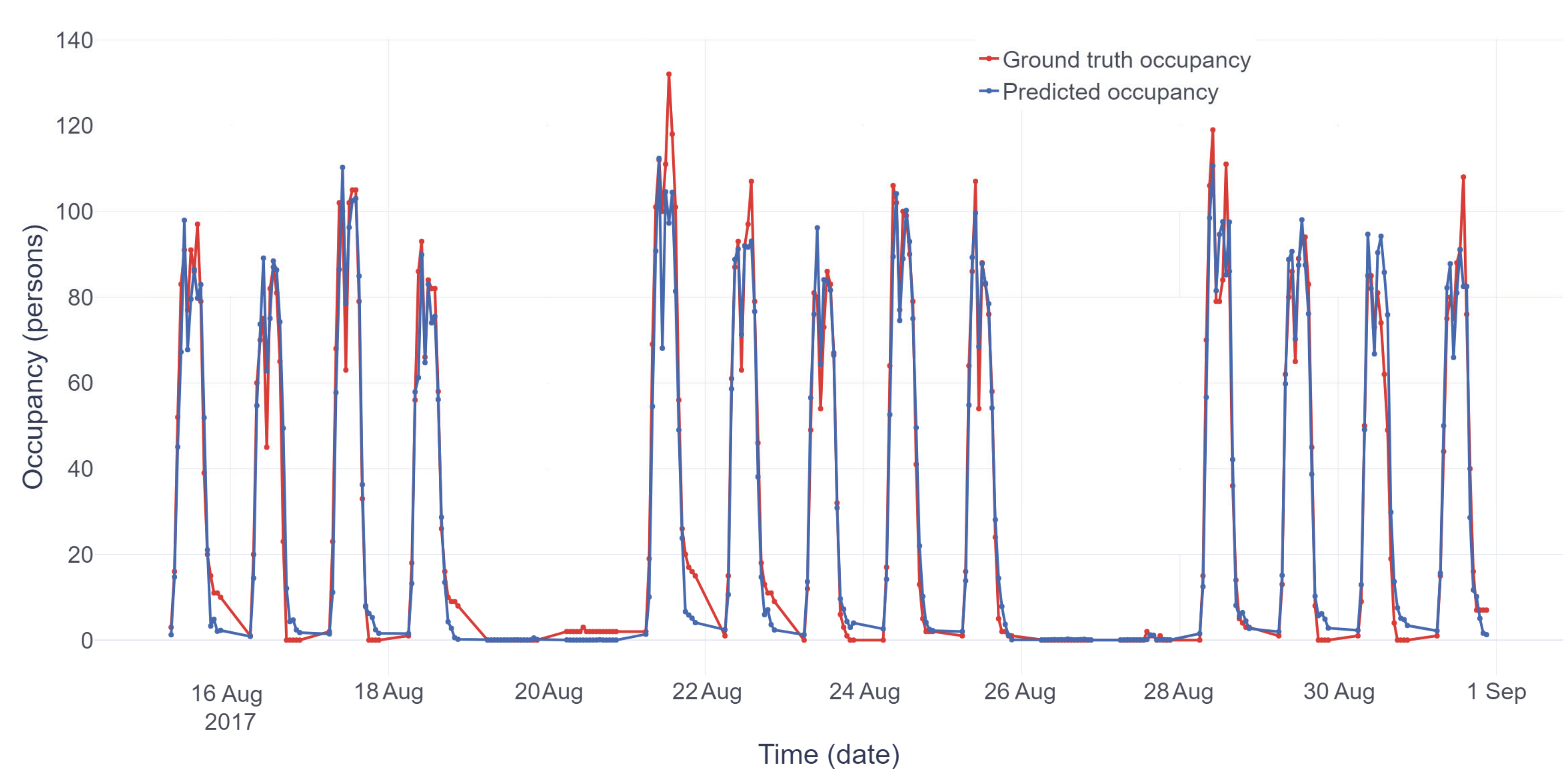
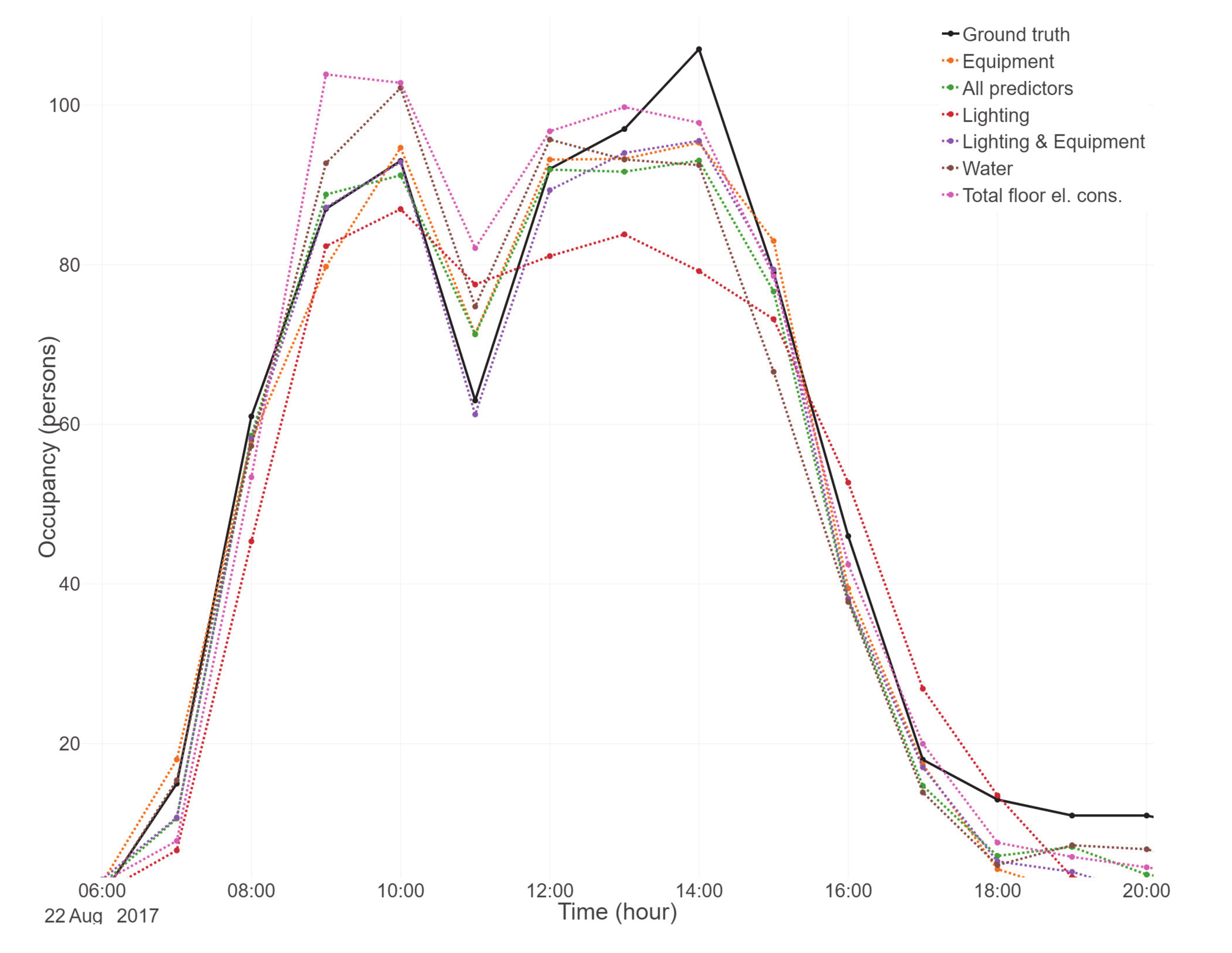
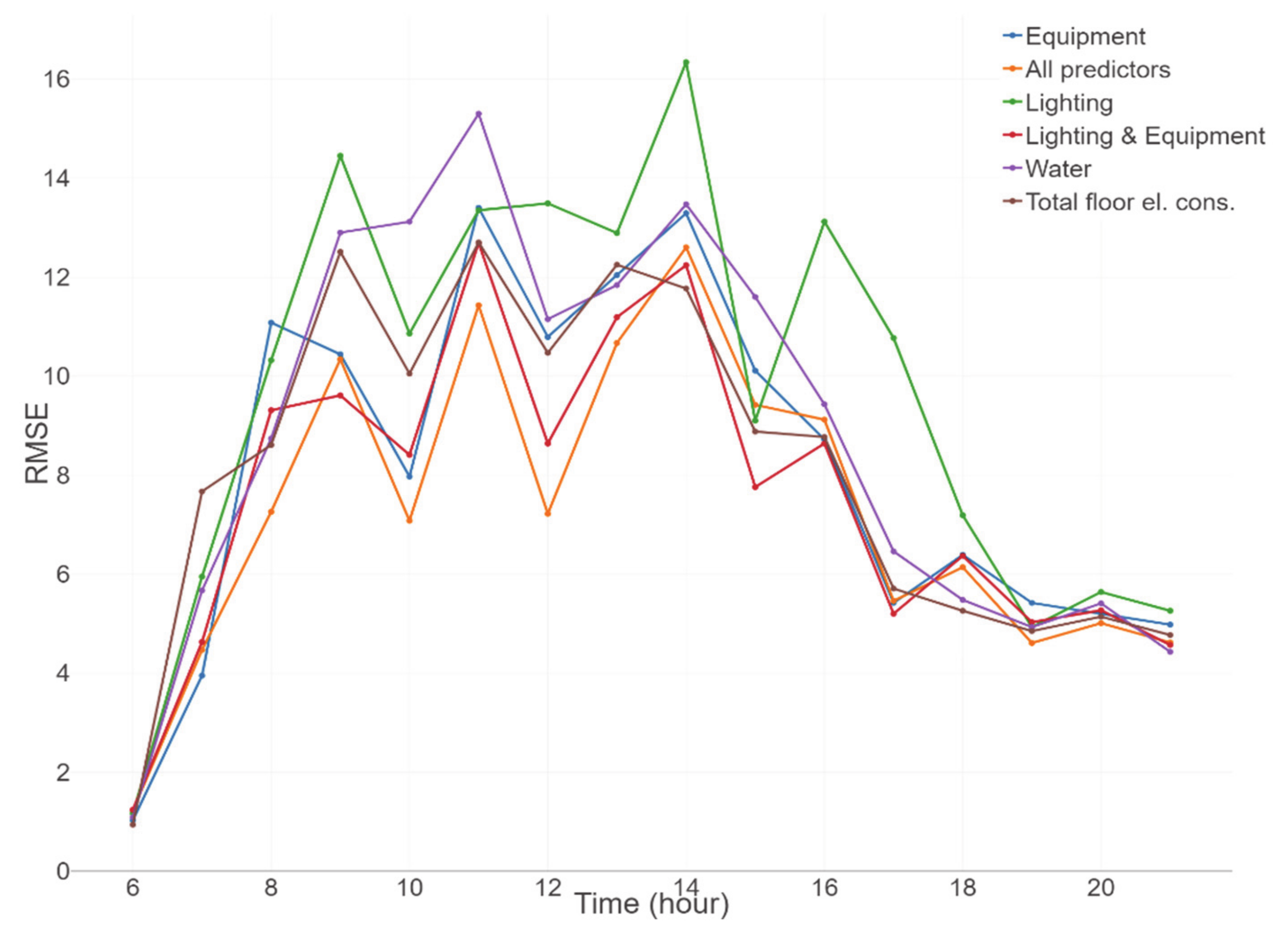
3.2.2. Data Analysis and Results
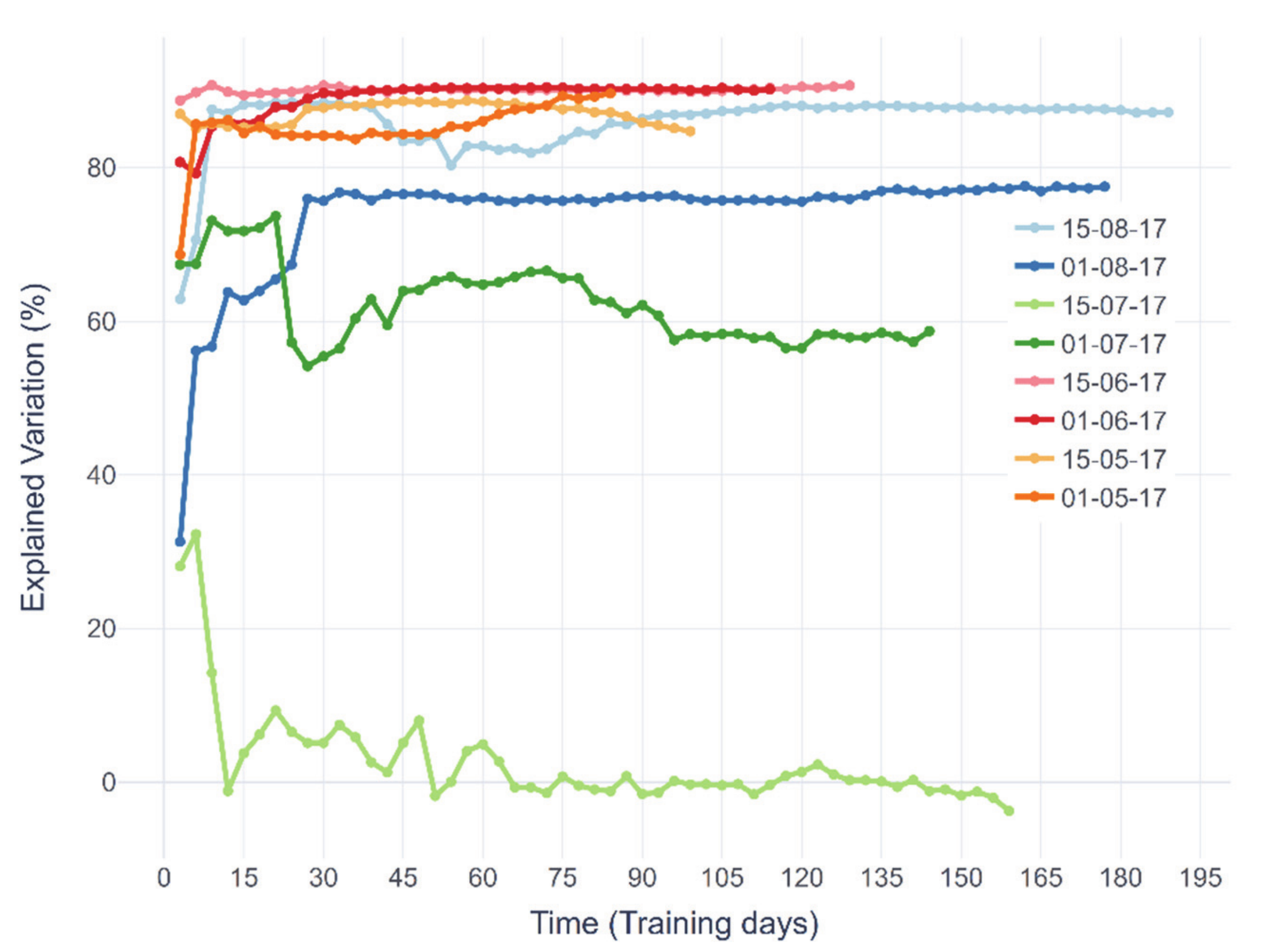
3.2.3. Data Sufficiency Analysis and Generalisation Analysis
3.2.4. Summary of the Supervised Method Results
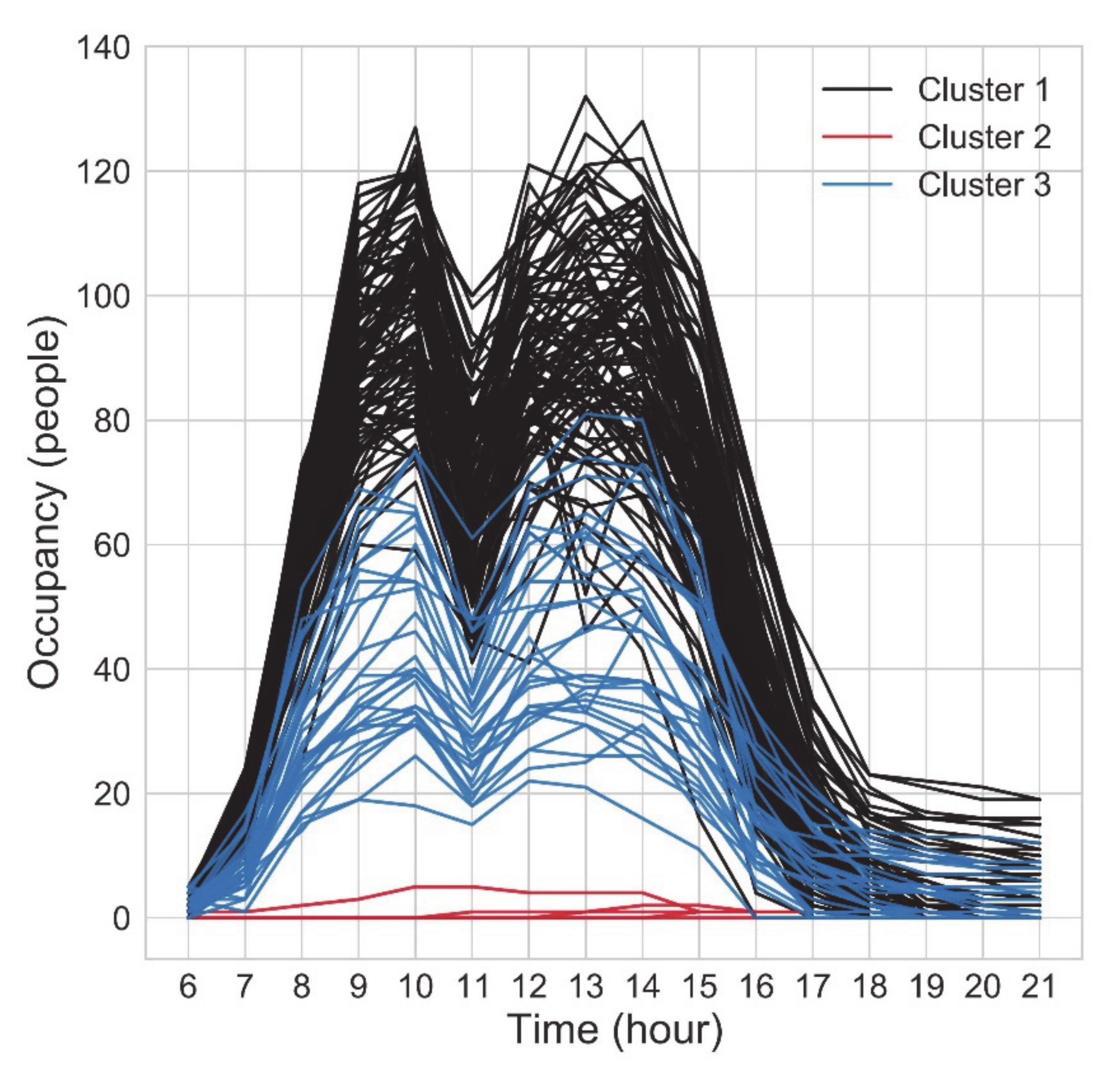
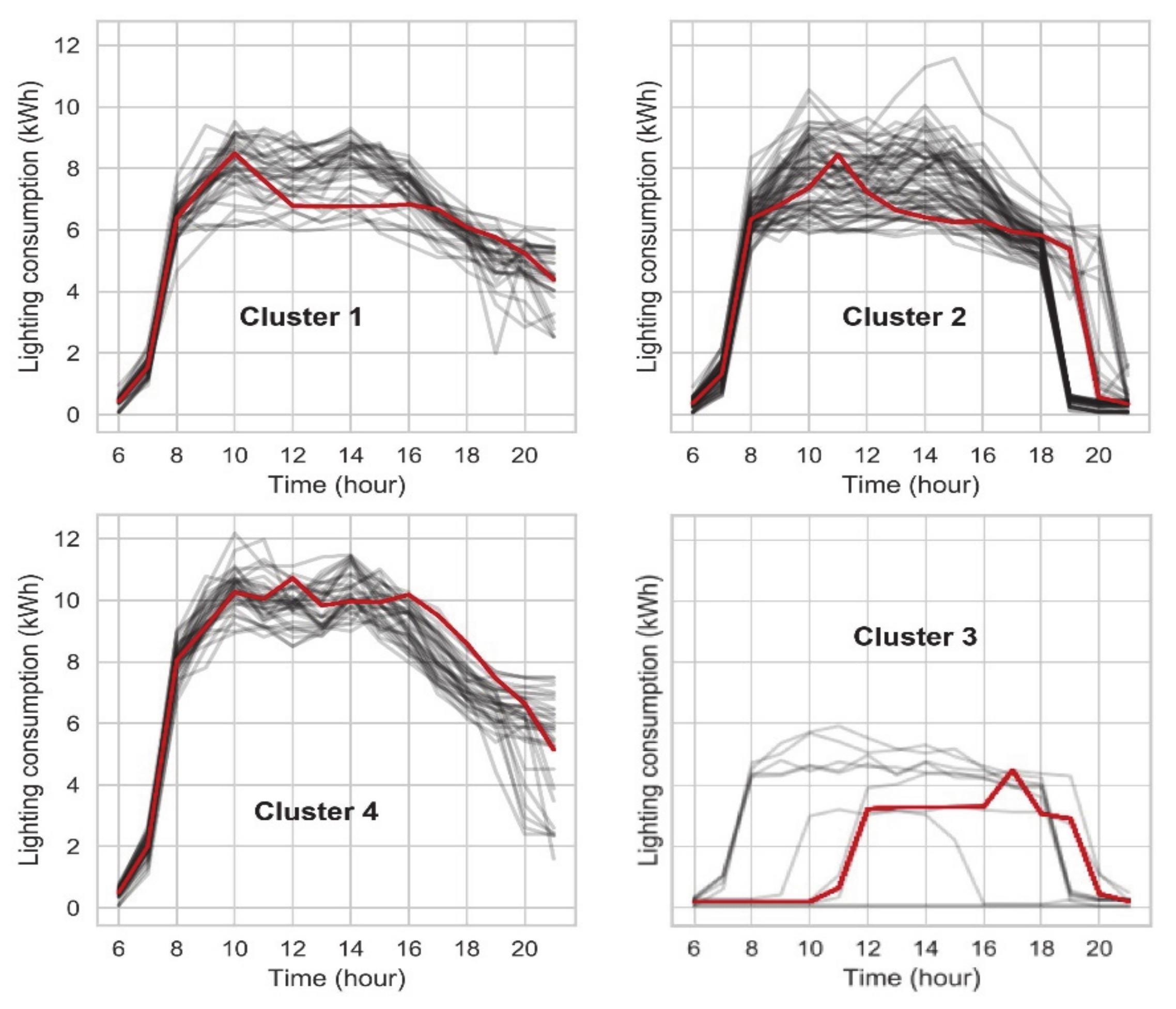
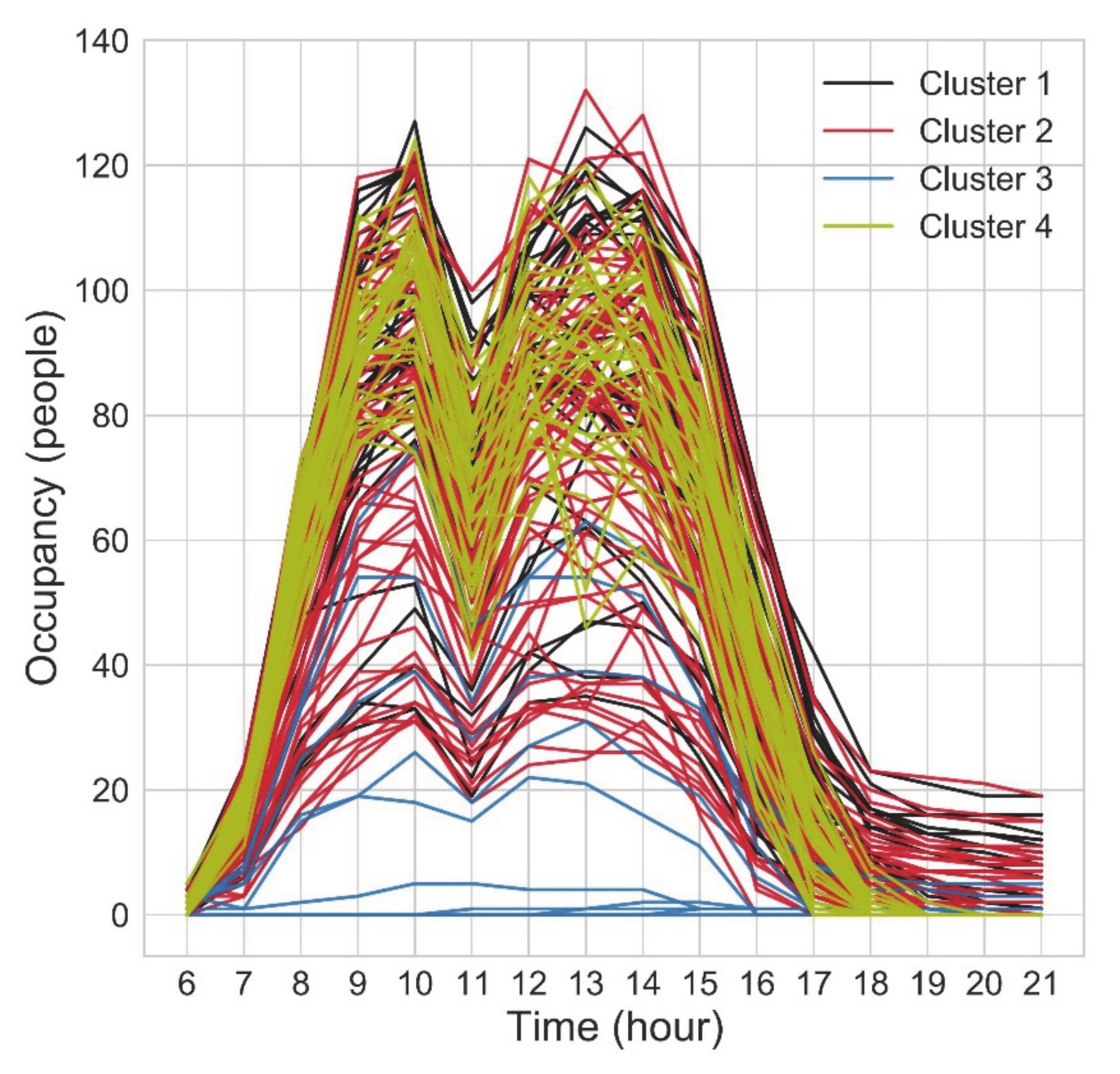
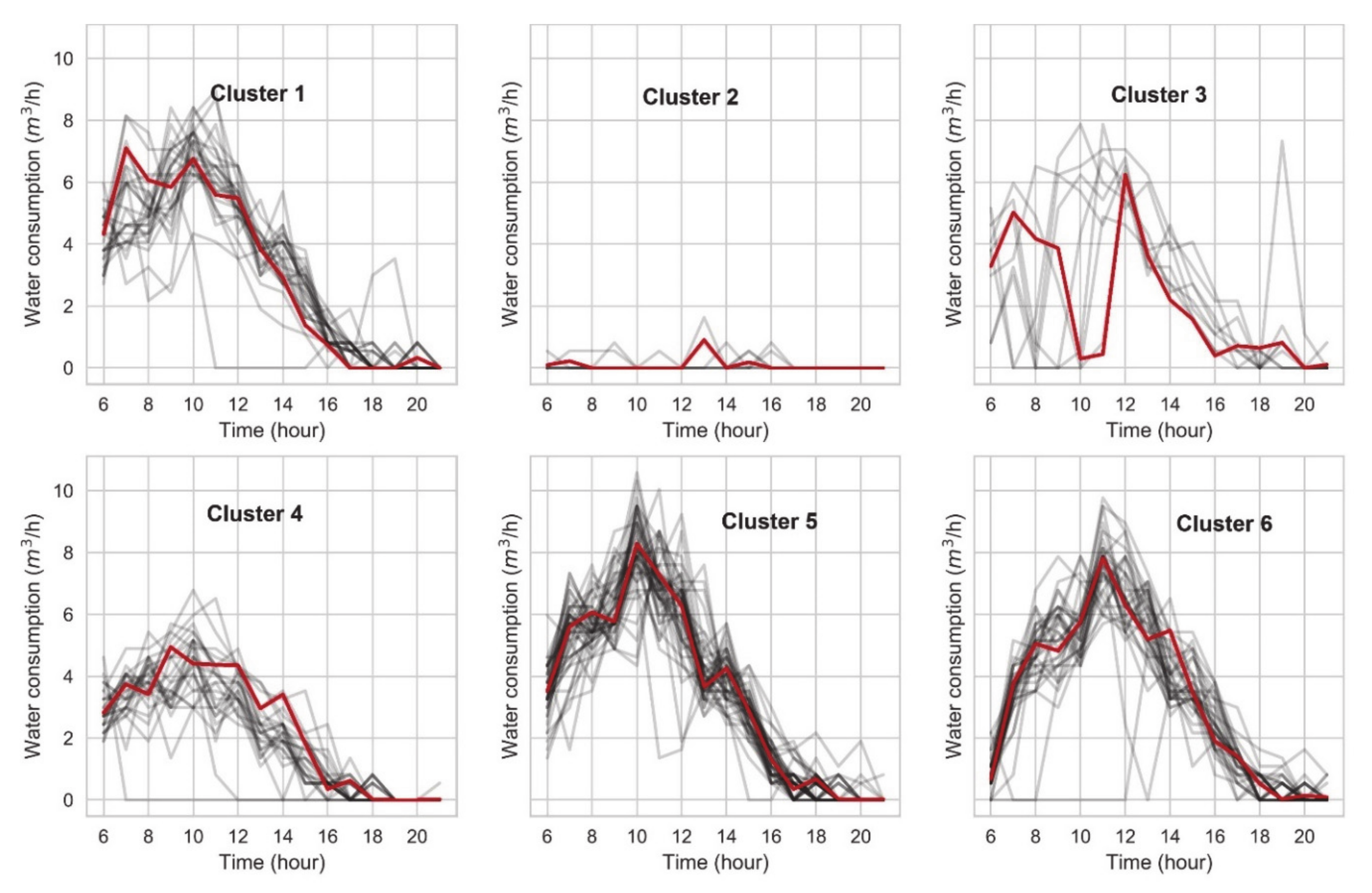
3.3. Results of the Unsupervised Method
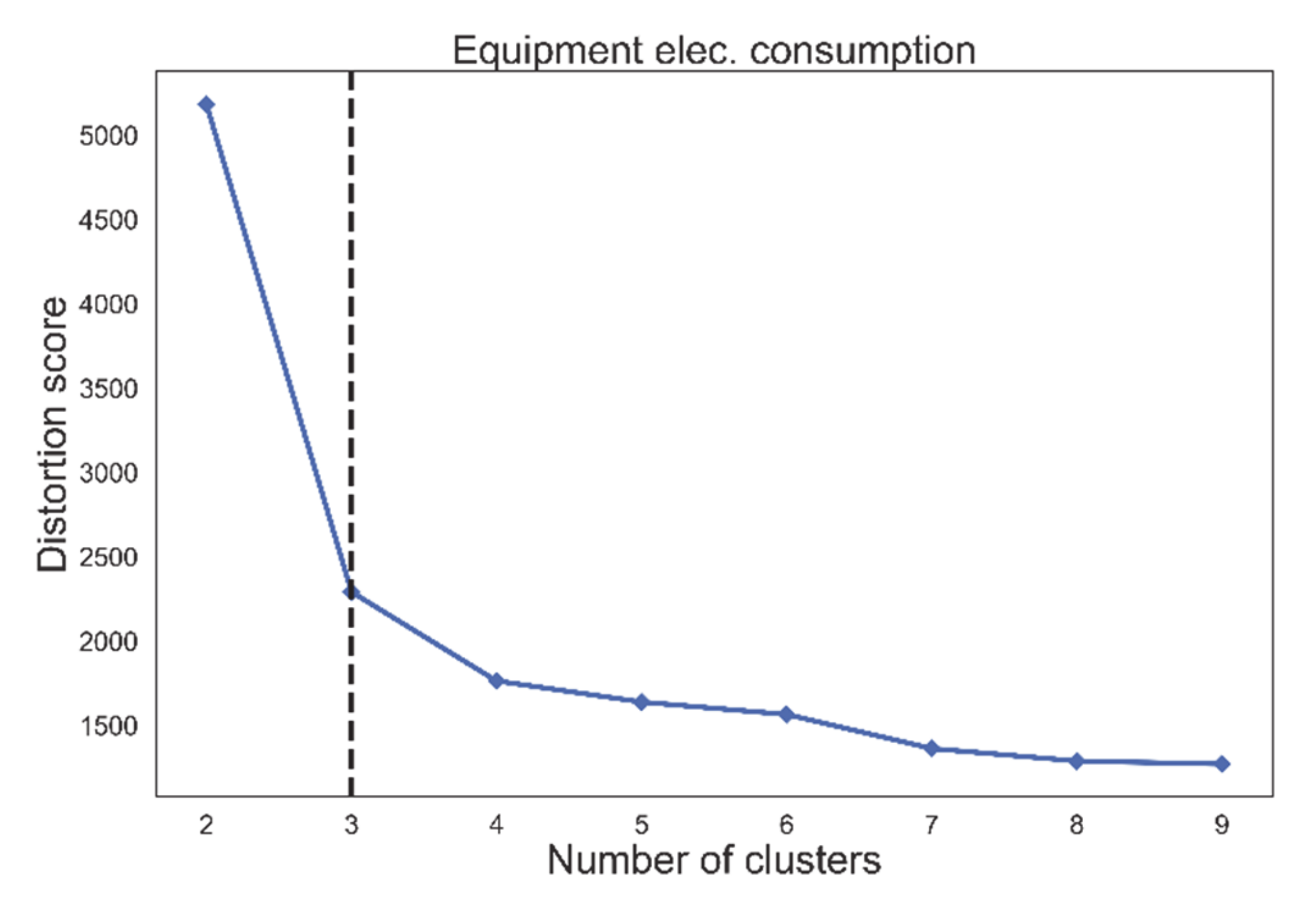
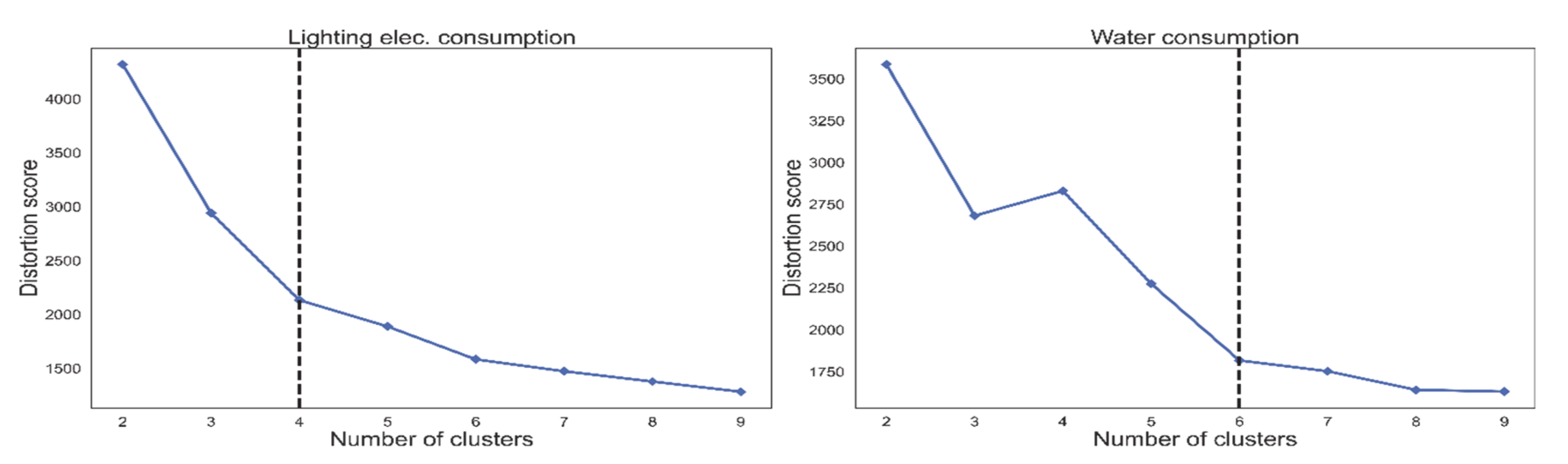
3.3.1. Choosing a Suitable Number of Clusters
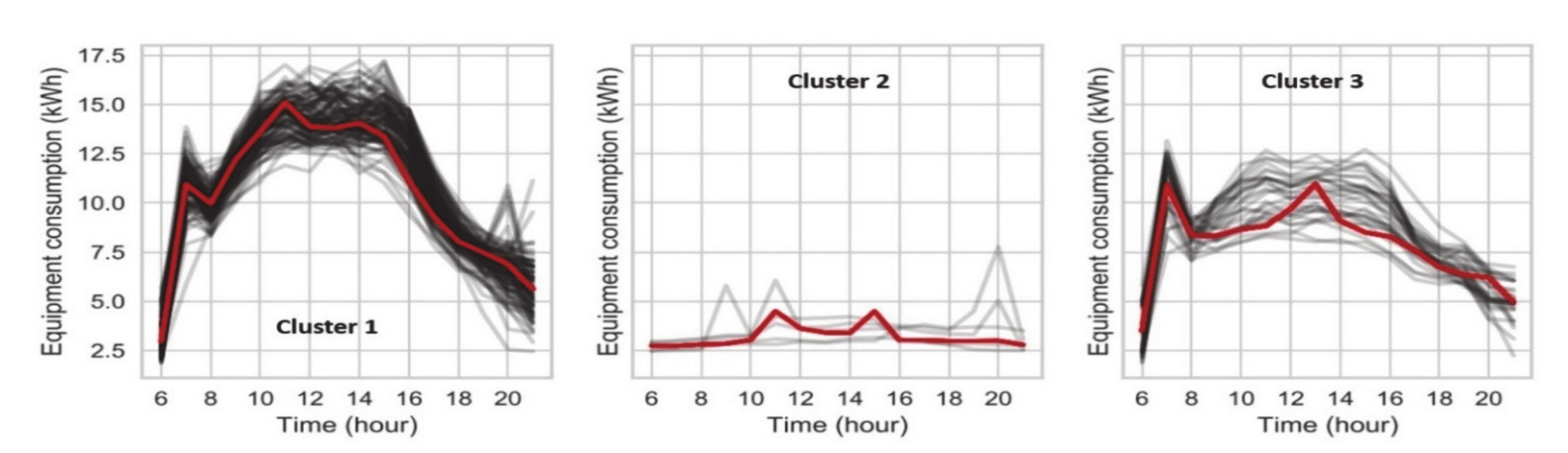
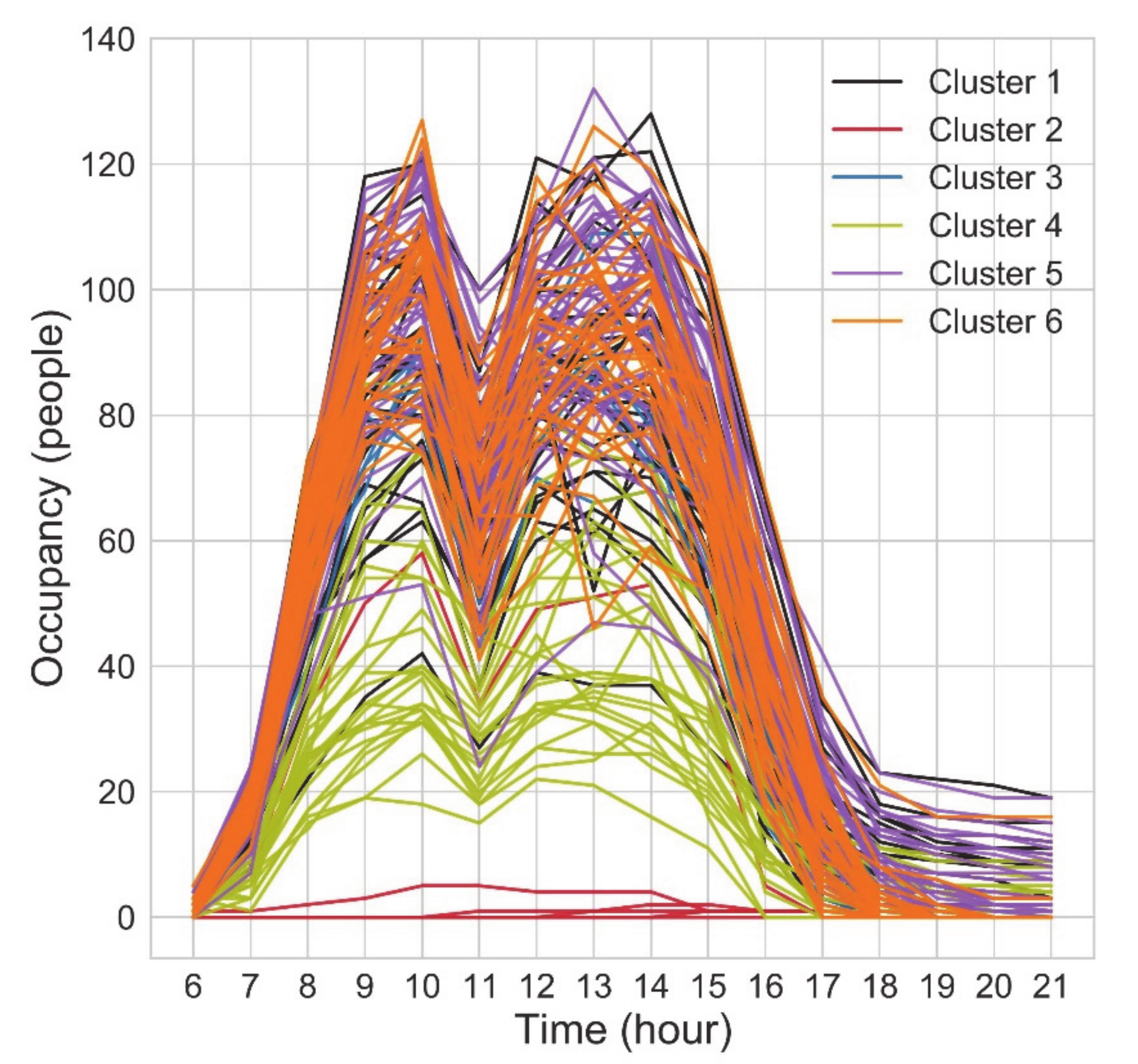
3.3.2. Clustering Results
3.3.3. Summary of the Unsupervised Method Results
- Zero (or nearly zero) occupancy level, occurring during the holidays,
- Medium occupancy level, occurring mostly during the “semi-holidays” (vacation and holiday bridge days),
- High occupancy level, occurring during regular working days.
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| DBA | DTW barycenter averaging |
| DTW | Dynamic time warping |
| EV | Explained variation |
| FD | First order difference |
| FDE | First order difference—equipment |
| FDL | First order difference—lighting |
| FDT | First order difference—total |
| FDW | First order difference—water |
| k | Number of clusters |
| MA1 | 1-step Moving average |
| MA1E | 1-step Moving average—equipment |
| MA1L | 1-step Moving average—lighting |
| MA1T | 1-step Moving average—total |
| MA1W | 1-step Moving average—water |
| MA2 | 2-step Moving average |
| MA2E | 2-step Moving average—equipment |
| MA2L | 2-step Moving average—lighting |
| MA2T | 2-step Moving average—total |
| MA2W | 2-step Moving average—water |
| MBE | Mean bias error |
| RMSE | Root mean square error |
| SD | Second order difference |
| SDE | Second order difference—equipment |
| SDL | Second order difference—lighting |
| SDT | Second order difference—total |
| SDW | Second order difference—water |
References
- EUR-Lex. European Union Directive 2018/844 of the European Parliament and of the Council of 30 May 2018 amending Directive 2010/31/EU on the energy performance of buildings and Directive 2012/27/EU on energy efficiency. Off. J. Eur. Union 2018, 156, 75–91. [Google Scholar]
- UN Environment; International Energy Agency. Towards a Zero-Emission, Efficient, and Resilient Buildings and Construction Sector; Global Status Report; United Nations: New York, NY, USA, 2017. [Google Scholar]
- Yu, Z.; Fung, B.C.M.; Haghighat, F. Extracting knowledge from building-related data—A data mining framework. Build. Simul. 2013, 6, 207–222. [Google Scholar] [CrossRef]
- International Energy Agency. Definition and Simulation of Occupant Behavior in Buildings International Energy Agency, EBC Annex 66 Definition and Simulation of Occupant Behavior in Buildings; The Regents of the University of California and Tsinghua University, China; International Energy Agency: Paris, France, 2018; ISBN 9780999696477. [Google Scholar]
- Yan, D.; Hong, T.; Dong, B.; Mahdavi, A.; Oca, S.D.; Gaetani, I.; Feng, X. IEA EBC Annex 66: Definition and simulation of occupant behavior in buildings. Energy Build. 2017, 156, 258–270. [Google Scholar] [CrossRef]
- Cuerda, E.; Guerra-Santin, O.; Sendra, J.J.; Neila González, F.J. Comparing the impact of presence patterns on energy demand in residential buildings using measured data and simulation models. Build. Simul. 2019, 12, 985–998. [Google Scholar] [CrossRef]
- Zhao, J.; Lasternas, B.; Lam, K.P.; Yun, R.; Loftness, V. Occupant behavior and schedule modeling for building energy simulation through office appliance power consumption data mining. Energy Build. 2014, 82, 341–355. [Google Scholar] [CrossRef]
- Ahn, K.; Kim, D.; Park, C.; Wilde, P. De Predictability of occupant presence and performance gap in building energy simulation. Appl. Energy 2017, 208, 1639–1652. [Google Scholar] [CrossRef]
- Tianzhen, H.; Langevin, J.; Sun, K. Building simulation: Ten challenges. Build. Simul. 2018, 871–898. [Google Scholar] [CrossRef]
- Zaki, M.J.; Meira, W.J. Data Mining and Analysis; Cambridge University Press: Cambridge, UK, 2014; ISBN 9780521766333. [Google Scholar]
- Fan, C.; Xiao, F.; Li, Z.; Wang, J. Unsupervised data analytics in mining big building operational data for energy efficiency enhancement: A review. Energy Build. 2018, 159, 296–308. [Google Scholar] [CrossRef]
- Kleiminger, W.; Beckel, C.; Staake, T.; Santini, S. Occupancy Detection from Electricity Consumption Data. In Proceedings of the 5th ACM Workshop on Embedded Systems For Energy-Efficient Buildings, Rome, Italy, 14–15 November 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Mora, D.; Fajilla, G.; Austin, M.C.; De Simone, M. Occupancy patterns obtained by heuristic approaches: Cluster analysis and logical flowcharts. A case study in a university office. Energy Build. 2019, 186, 147–168. [Google Scholar] [CrossRef]
- Yang, L.; Ting, K.; Srivastava, M.B. Inferring occupancy from opportunistically available sensor data. In Proceedings of the 2014 IEEE International Conference on Pervasive Computing and Communications (PerCom), Budapest, Hungary, 24–28 March 2014; pp. 60–68. [Google Scholar] [CrossRef]
- Kleiminger, W.; Beckel, C.; Santini, S. Household occupancy monitoring using electricity meters. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 975–986. [Google Scholar] [CrossRef]
- Akbar, A.; Nati, M.; Carrez, F.; Moessner, K. Contextual occupancy detection for smart office by pattern recognition of electricity consumption data. In Proceedings of the 2015 IEEE International Conference on Communications (ICC), London, UK, 8–12 June 2015; pp. 561–566. [Google Scholar] [CrossRef]
- Razavi, R.; Gharipour, A.; Fleury, M.; Justice, I. Energy & Buildings Occupancy detection of residential buildings using smart meter data: A large-scale study. Energy Build. 2019, 183, 195–208. [Google Scholar] [CrossRef]
- Rhodes, J.D.; Cole, W.J.; Upshaw, C.R.; Edgar, T.F.; Webber, M.E. Clustering analysis of residential electricity demand profiles. Appl. Energy 2014, 135, 461–471. [Google Scholar] [CrossRef]
- McLoughlin, F.; Duffy, A.; Conlon, M. A clustering approach to domestic electricity load profile characterisation using smart metering data. Appl. Energy 2015, 141, 190–199. [Google Scholar] [CrossRef]
- Pan, S.; Wang, X.; Wei, Y.; Zhang, X.; Gal, C.; Ren, G.; Yan, D.; Shi, Y.; Wu, J.; Xia, L.; et al. Cluster analysis for occupant-behavior based electricity load patterns in buildings: A case study in Shanghai residences. Build. Simul. 2017, 10, 889–898. [Google Scholar] [CrossRef]
- Yang, J.; Ning, C.; Deb, C.; Zhang, F.; Cheong, D.; Lee, S.E.; Sekhar, C.; Tham, K.W. K-Shape clustering algorithm for building energy usage patterns analysis and forecasting model accuracy improvement. Energy Build. 2017, 146, 27–37. [Google Scholar] [CrossRef]
- D’Oca, S.; Hong, T. Occupancy schedules learning process through a data mining framework. Energy Build. 2015, 88, 395–408. [Google Scholar] [CrossRef]
- Liang, X.; Hong, T.; Qiping, G. Occupancy data analytics and prediction: A case study. Build. Environ. 2016, 102, 179–192. [Google Scholar] [CrossRef]
- Causone, F.; Carlucci, S.; Ferrando, M.; Marchenko, A.; Erba, S. A data-driven procedure to model occupancy and occupant-related electric load profiles in residential buildings for energy simulation. Energy Build. 2019, 202, 109342. [Google Scholar] [CrossRef]
- Dong, B.; Kjærgaard, M.B.; De Simone, M.; Gunay, H.B.; O’Brien, W.; Mora, D.; Dziedzic, J.; Zhao, J. Sensing and data acquisition. In Exploring Occupant Behavior in Buildings: Methods and Challenges; Springer: Cham, Switzerland, 2017; pp. 77–105. ISBN 9783319614649. [Google Scholar]
- Dong, B.; Yan, D.; Li, Z.; Jin, Y.; Feng, X.; Fontenot, H. Modeling occupancy and behavior for better building design and operation—A critical review. Build. Simul. 2018, 11, 899–921. [Google Scholar] [CrossRef]
- Kuutti, J.; Blomqvist, K.H.; Sepponen, R.E. Performance of Commercial Over-Head Camera Sensors in Recognizing Patterns of Two and Three Persons: A Case Study. In Proceedings of the 2013 IEEE Jordan Conference on Applied Electrical Engineering and Computing Technologies (AEECT), Amman, Jordan, 3–5 December 2013. [Google Scholar]
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 3, 18–22. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. 1978, 26, 43–49. [Google Scholar] [CrossRef]
- Petitjean, F.; Ketterlin, A.; Gançarski, P. A global averaging method for dynamic time warping, with applications to clustering. Pattern Recognit. 2011, 44, 678–693. [Google Scholar] [CrossRef]
- Tavenard, R.; Faouzi, J.; Vandewiele, G.; Divo, F.; Androz, G.; Holtz, C.; Payne, M.; Yurchak, R.; Rußwurm, M.; Kolar, K.; et al. Tslearn: A Machine Learning Toolkit Dedicated to Time-Series Data. 2017. Available online: https://tslearn.readthedocs.io/ (accessed on 23 March 2020).
- Thorndike, R.L. Who belongs in the family. Psychometrika 1953, 18, 267–276. [Google Scholar] [CrossRef]
- Satopää, V.; Albrecht, J.; Irwin, D.; Raghavan, B. Finding a “ Kneedle ” in a Haystack: Detecting Knee Points in System Behavior. In Proceedings of the 31st International Conference on Distributed Computing Systems Workshops, IEEE, Minneapolis, MN, USA, 20–24 June 2011; pp. 1–6. [Google Scholar]
- Bengfort, B.; Bilbro, R.; Danielsen, N.; Gray, L.; McIntyre, K.; Roman, P.; Morris, A.; Sharma, S.; Chestnut, M.; Garod, M.; et al. Yellowbrick 2018. Available online: https://www.scikit-yb.org/ (accessed on 23 March 2020).
- Granlund Granlund Manager. Available online: https://www.granlundmanager.com/ (accessed on 23 March 2020).
- Cerqueira, V.; Torgo, L.; Mozetic, I. Evaluating time series forecasting models: An empirical study on performance estimation methods. Mach. Learn. 2020, 109, 1997–2028. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Feature | Description |
|---|---|---|
| 1 | First-order difference (FD) | |
| 2 | Second-order difference (SD) | |
| 3 | 1-step Moving average (MA1) | |
| 4 | 2-step Moving average (MA2) |
| Main Predictor | Selected Features |
|---|---|
| Lighting | FDL, month, hour, weekday |
| Equipment | FDE, MA2E, hour, weekday |
| Light and Equipment (separate) | SDL, SDE, MA2L, MA2E, hour, weekday |
| Total floor electric consumption (Light and Equipment summed) | FDT, SDT, month, hour, weekday |
| Water consumption | FDW, MA1W, MA2W, hour, weekday |
| All predictors | FDL, SDL, FDE, SDE, SDW, MA1E, MA1W, month, hour, weekday |
| Set of Predictors | RMSE (Persons) | MBE (Persons) | EV (%) |
|---|---|---|---|
| Lighting | 10.52 | −1.6 | 93 |
| Equipment | 8.87 | −2.34 | 95 |
| Light and Equipment | 8.14 | −2.07 | 96 |
| Total floor electricity consumption | 8.8 | 0.41 | 95 |
| Water consumption | 9.67 | −0.5 | 94 |
| All predictors | 7.88 | −0.66 | 96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stjelja, D.; Jokisalo, J.; Kosonen, R. From Electricity and Water Consumption Data to Information on Office Occupancy: A Supervised and Unsupervised Data Mining Approach. Appl. Sci. 2020, 10, 9089. https://doi.org/10.3390/app10249089
Stjelja D, Jokisalo J, Kosonen R. From Electricity and Water Consumption Data to Information on Office Occupancy: A Supervised and Unsupervised Data Mining Approach. Applied Sciences. 2020; 10(24):9089. https://doi.org/10.3390/app10249089
Chicago/Turabian StyleStjelja, Davor, Juha Jokisalo, and Risto Kosonen. 2020. "From Electricity and Water Consumption Data to Information on Office Occupancy: A Supervised and Unsupervised Data Mining Approach" Applied Sciences 10, no. 24: 9089. https://doi.org/10.3390/app10249089
APA StyleStjelja, D., Jokisalo, J., & Kosonen, R. (2020). From Electricity and Water Consumption Data to Information on Office Occupancy: A Supervised and Unsupervised Data Mining Approach. Applied Sciences, 10(24), 9089. https://doi.org/10.3390/app10249089