1. Introduction
Defects considerably affect the quality of plastic products, and defect inspections are conducted for quality control. Defects can stain the surfaces of plastic products if quality control is not performed thoroughly, which could lead to a decrease in the sales of the product because of unfavorable impression on the customer, and consequently cause losses to the company. The most common technique of plastic product fabrication is injection molding, which involves producing parts by melting granular plastic and injecting them into a mold, and subsequently cooling the product. However, granular plastic defect inspection is difficult because the size of the defects is at microscale. Furthermore, the inside of the granular plastic can have defects. Therefore, granular plastics can be first compressed into plastic resin films. This increases microscale defect visibility. Thus, the inspection can be conducted easily. Industrial inspection systems for defect detection can mostly be divided into two types, namely the traditional procedure and the automatic procedure. The traditional procedure, which is currently prominent, involves observing whether plastic resin film quality is satisfactory through human vision by using a magnifier as the inspection tool. This inspection procedure has the following problems:
Because numerous items must be inspected, high-intensity repetitive inspection can cause fatigue and lethargy in inspectors. The quality of inspected products is not guaranteed in such scenarios. This method is prone to workplace injuries because the inspecting staff can injure their eyes.
Human vision cannot precisely discern how large any defect is; humans have at best an approximate awareness of whether a defect is present. This may cause the inspection process to miss some defects. Furthermore, it is nearly impossible to standardize human vision; each inspector’s eyesight will have its own peculiarities.
In some cases, the manufacturer may want to tolerate no defect larger than 25 μm. However, human vision is limited to objects larger than approximately 50 μm; this limit is not acceptable for high-quality products.
Defect detection is not immediate. Using human vision for the inspection process is considerably time consuming and inefficient. The average number of plastic resin films that can be checked by a person in a day is approximately 12 to 15.
Automatic procedures, including machine vision-based methods of defect detection, have gained considerable popularity for their high speed, high precision, and real-time performance. Several strategies for defect detection have been explored in numerous studies. These machine vision-based methods are used in the inspection of many industrial products, such as metal [
1], fabric [
2], steel [
3], car surfaces [
4], and light-emitting diode chips [
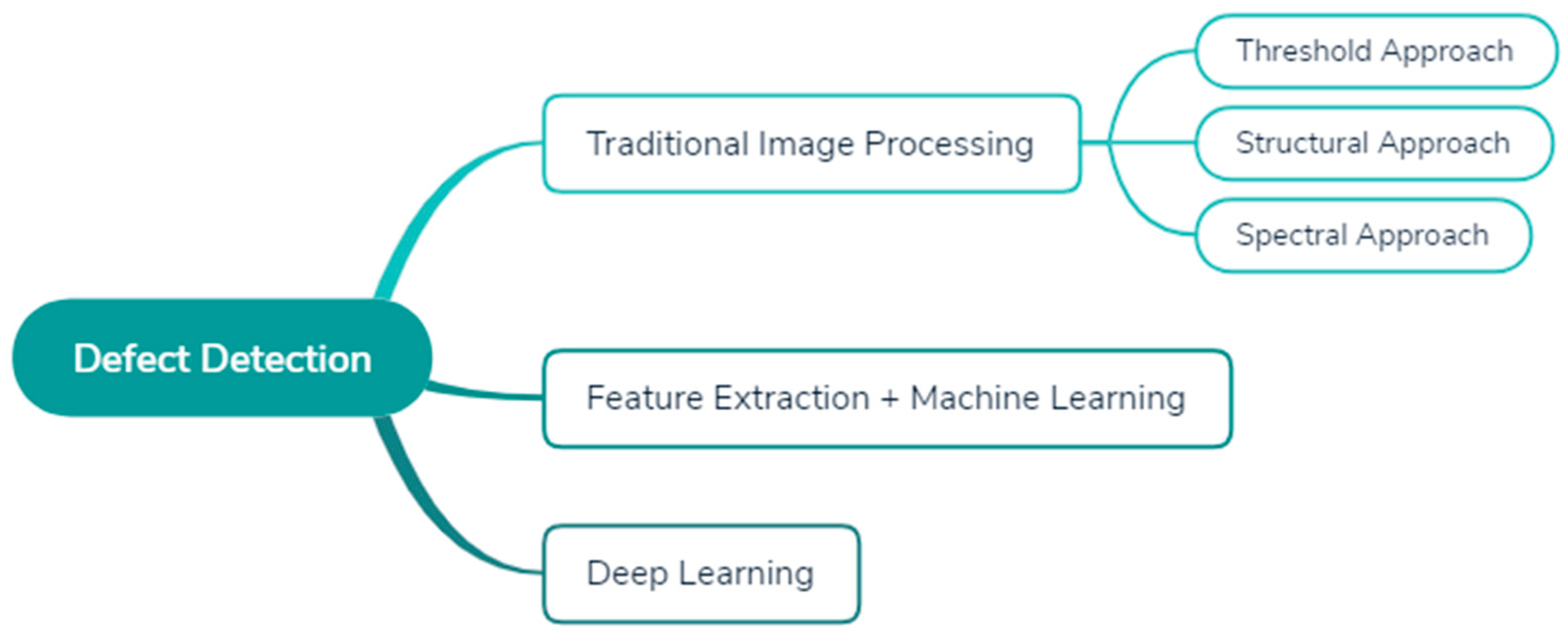
5]. The methods of surface defect detection can be divided into three types, as depicted in
Figure 1, namely traditional image processing, feature extraction with machine learning, and deep learning methods.
Primitive attributes are used to detect defects in traditional image processing methods. These methods can be divided into three approaches, namely threshold, structural, and spectral. The threshold approach involves transforming grayscale images to binary images, separating the background and defects by applying various types of thresholds such as adaptive thresholding method [
6] and the Otsu [
7,
8] method. The structural approach includes edge [
9], skeleton [
10], and morphological operations [
11]. Fourier [
12], wavelet [
13], and Gabor transforms [
14] are used in the spectral approach. However, it is difficult to classify various nondefect objects using traditional image processing because nondefect items are not easily filtered.
In feature extraction using a machine learning method, defect detection has two stages, namely feature extraction and machine learning, that is, using a feature extraction algorithm to extract various features from images, then using machine learning techniques to determine the pattern or relationship among different classes. Shumin [
15] proposed a novel fabric defect detection technique using a histogram of oriented gradient (HOG) for counting occurrences of gradient orientation in localized portions of an image, AdaBoost was used to select a small set of HOG data for support vector machine (SVM) to classify fabric defects. Kuang et al. [
16] proposed a method for bamboo strip defect detection using a set of features based on local binary pattern (LBP) and gray level co-occurrence matrix (GLCM). LBP is used to describe the local texture features of the image and GLCM is used to characterize the texture of an image by calculating how often pairs of pixels with specific values in a specified spatial relationship occur in an image. After extracting the features, an SVM was proposed to classify defects. Chang et al. [
17] proposed a method for defect detection on the compact lens. He segmented objects by applying weighted Sobel filters and watersheds and then used the SVM for classification. Watershed is a transformation that considers the images as topographic maps, the brightness of the images representing its height and finds the lines that run along the tops of ridges. Watershed can segment two objects that are close to each other. Zhou et al. [
18] proposed a surface defect for a vehicle body by using a multiscale Hessian matrix fusion method to determine defect regions and SVM to classify defects.
Deep learning methods have achieved excellent results in many fields [
19,
20,
21] and surface defect detection is one of them. Several defect detection methods based on convolutional neural networks (CNNs) have been proposed. Arikan et al. [
22] proposed a CNN model for classification, setting two classes: defect or nondefect. This model was designed to handle capacity and real-time speed requirements. A generative adversarial network (GAN) was used to generate more data. Wang et al. [
23] proposed a fast and robust CNN-based defect detection model by using CNNs with a sliding window to localize the product damage. The sliding window is time consuming and is not sufficiently efficient for our data. Mei et al. [
24] designed a multiscale convolutional denoising autoencoder network (MSCDAE) model for fabric defect detection by using reconstructed image patches with the model at multiple Gaussian pyramid levels and synthesized results from these pyramid levels. Defective regions in the reconstruction residual maps were generated using the CDAE networks. This model can be trained with only a small set of defect-free samples and can deliver excellent performance. These two methods can only localize and detect defects but cannot classify the type of defects.
An object detection method is required for resin films because an image can contain various objects at the same time. Object detection is used to detect objects inside an image and many studies have been conducted on object detection. Li et al. [
25] proposed an improved you-only-look-once (YOLO) network to detect six types of defects on steel strip surfaces. Cha et al. [
26] proposed a structural visual inspection method based on faster R-CNN to detect five types of defects, namely steel delamination, steel corrosion, bolt corrosion, and concrete cracks. Yuan et al. [
27] proposed a modified segmentation method and deep neural network to detect defects on the cover glass of mobile phones. GAN was used to generate more data for the deep learning network to overcome the problem of small amount of data. Ferguson et al. [
28] used a defect detection system based on the mask region-based CNN (mask R-CNN) architecture to detect the casting defects on the GDXray dataset. Excellent performance is achieved based on transfer learning, using weights pre-trained on the ImageNet dataset, and then trained the defect detection system on the COCO (Common Objects in Context) dataset. Wen et al. [
29] proposed an object detection method to detect defects on bearing rollers, using CNN to extract the features of the defects, then classified the defects, and calculated the position of the defects simultaneously. Chen et al. [
30] proposed a novel vision-based method in which deep CNNs (DCNNs) are applied in the defect detection of the fasteners on the catenary support device. The system cascades three DCNN-based detection stages, including single shot multibox detector (SSD) and YOLO to localize the cantilever joints and their fasteners. Then, a classifier was used to classify defects. Li et al. [
31] proposed a surface defect detection model based on the SSD network that was combined with a MobileNet to detect the sealing surface of an oil chili to achieve real-time and accurate detection. The Hough circle transform was applied to detect the oil chili. However, while above mentioned methods proposes object detection networks that calculated the position and classifies defects in one whole network, traditional image processing methods are sufficient for finding the objects because of the simple background in the proposed system. Therefore, object detection networks such as YOLO, faster R-CNN are not required for our inspection systems. The proposed method in this is mostly inspired by the following methods. Song et al. [
32] proposed a deep CNN-based technique for detecting micro defects on metal screw surfaces by using traditional image processing methods to detect metal screws, then using a CNN network to classify whether a metal screw was defective. Tao et al. [
33] designed a cascaded autoencoder architecture to obtain accurate and consistent defect detection results under complex lighting conditions and ambiguous defects. The autoencoder could distinguish the nonbackground objects and only required the basic thresholding method to separate nonbackground objects and the background. A deep convolution network was used to classify various types of defects.
In the proposed method, we used a small microscope to observe data. Two types of plastic resin films were present in our data, namely those with transparent and white backgrounds.
Figure 2 illustrates how the resin films appear under the microscope. Various types of nonbackground objects are present on the surface; scratches (
Figure 2b) and bubbles (
Figure 2c) are not defined as defects. Pollutants in the industrial environment, nondefective items, such as dust (
Figure 2d) may appear on the inspected surface. Different nonbackground objects have distinct features. Therefore, an image processing method to segment the nonbackground objects was proposed, and a classification module was then used to classify the defects. The results prove that the proposed method exhibited performance.
However, although the method exhibited excellent results, some disadvantages were observed under the microscope. First, the microscope FOV was small—we need to capture hundreds of images to compose one plastic resin film. Therefore, this method does not immediately raise efficiency. It is also difficult to scan the plastic resin film completely without missing any parts; we have no method to consider whether any parts have gone unscanned. Second, identifying defects and determining the corresponding positions is difficult under the microscope. The aforementioned method is not suitable for our study because our final goal is to increase the number of inspected samples. Therefore, we proposed a machine-assisted method with a 2K-resolution camera. One plastic resin film can be captured completely by one picture using the machine; in other words, the machine can speed up the process and increase the number of samples that can be inspected in a day.
Figure 3a,b depicts the transparent-background and white-background plastic resin film surfaces under a 2K-resolution camera. The transparent and white plastic resin film results vary considerably under the 2K-resolution camera compared with the data from the microscope. The defects depicted in
Figure 3(a1,b1) are mostly small and dot-like, whereas the scratch and dust are shown in
Figure 3(a2,b2) and
Figure 3(a4,b4), respectively, are similar to lines. Bubbles depicted in
Figure 3(a3,b3) are circular. The difference between each type of nonbackground objects is not as obvious in the microscale version. However, only a few images are required for composing one plastic resin film.
A microscale defect inspection architecture that could automatically identify defects for plastic resin films has been presented in this paper. The proposed method on the 2K-resolution camera was modified based on the microscope method. The microscale defect inspection architecture consists of two steps. In the first part of the architecture, an image preprocessing method for the detection part, segments, and local nonbackground objects was proposed. In the second part, a classification module is used to classify the objects. Compared with traditional procedure, the proposed method has the following advantages:
With the same standards for defect detection, the proposed method can obtain the precise area and location of defects.
The proposed method has high precision and high speed, which speeds up the inspection process and reduces labor cost. The average amount of plastic resin films that can be checked in a day increases.
The rest of paper is organized as follows: In
Section 2, the overall system and proposed approach are described in detail. Experimental results are presented in
Section 3 and the discussion is presented in
Section 4. Finally, the conclusion is provided in
Section 5.
4. Discussion
During the development of the proposed method, a number of experiments were performed to deliver high performance. In this section, details during experimentation are discussed. The image processing stage is discussed in
Section 4.1 and
Section 4.2 and the hyperparameters during the training of the CNN model are discussed in
Section 4.3. Finally, implementation issues are discussed in
Section 4.4 4.1. Threshold
When selecting the suitable thresholding method, the Otsu method and the basic thresholding method did not provide a satisfactory performance on both kinds of data. On the microscope data, the low-quality image causing too much noise on the image, therefore Otsu did not performance great. As for the 2K-resolution camera data, the objects were small and not sufficiently obvious for Otsu to obtain. The basic threshold, in which a pixel value was selected and set as the boundary line did not provide satisfactory results because the microscope data and 2K-resolution camera has varying light at the center. Therefore, the adaptive threshold is the most suitable approach among others. There are different kinds of adaptive thresholding method, such as mean, Niblack [
38] and Sauvola [
39]. The adaptive threshold sets the boundary line as shown in Equation (3), different adaptive thresholding methods determine the
value differently. The Niblack and Sauvola formula is shown as below.
where m (x,y) is the mean of the blocksize × blocksize neighborhood, s (x,y) is the standard deviation. The parameter K gets positive values, and R is the dynamic range of standard deviation. The results after using different thresholding methods are shown in
Figure 12. As shown in
Figure 12a,b, nonuniform light source causes bad performance on the basic thresholding method. In
Figure 12c, Otsu cannot get any objects on the plastic resin film. Although Niblack and Sauvola shows better performance compared to the two methods mentioned above, these methods gain a lot of unrequired noises, making it difficult for the contour detection afterwards. In addition, many objects are fragmented while using Sauvola. Their computation time is also rather slow compared to the mean adaptive threshold. Therefore, we chose mean adaptive threshold.
However, the parameters for the mean adaptive threshold must be adjusted because of the data difference and light effect, which requires time. Finding the best parameters for the adaptive threshold consumed the most amount of time in the experiment. We mainly attempted the combination and compared each of them.
Figure 13 shows the comparison between different parameter values.
Here,
x, y are the parameters of the adaptive threshold where
x is the constant
c and
y is the blocksize, the total number of the missing ground true defect are depicted in
Figure 13a and the total number of contours that were found are illustrated in
Figure 13b. The figure shows that only the parameter with blocksize 55 and c 5 has gotten all the defects, however while our goal is to find all the defects as many as possible, we also want to reduce the number of objects being detected. Therefore, we observe the data under four different combination; each combination has a different amount of missing ground true, the objects being detected on the threshold image are shown in
Figure 14. It is obvious that blocksize 55, c 5 is not a suitable parameter; as shown in
Figure 14d, it is not suitable for finding the objects on the plastic resin film,
Figure 14b will detect a lot of noises. Other than that due to observation, the parameters used on
Figure 14c would cause some same scratches being detected as different objects, these sub-scratches have similar features as the defects, which would cause it hard to classify between defect and scratches. Therefore, because of the aforementioned results, a blocksize of 55 and a constant
c of 19 were set.
4.2. Contour Extraction
During contour extraction, when the minimum bounding box of the contours in the microscope data, we did not apply the minimum on the camera data. This is mainly because we detected the possibility of objects with area less than 10 pixels. The minimum bounding box that was used to extract the object would then be difficult to train during the classification stage.
As depicted in
Figure 15, if we selected to extract the object by the minimum bounding box of the contour, limited background details could be compared. Because our input for the LeNet-5-adjusted network must be of the same size, loss of attribute features occurred during resizing, which caused the accuracy to decrease during classification. In this case, we expanded the bounding box. The extracted objects attribute features were more obvious (
Figure 14b), we expanded the area to approximately 5, 10, and 15 pixels; then we trained them on the LeNet-5-adjusted network. The best results were obtained for 15 pixels during the classification stage.
4.3. Hyperparameter
Fine adjustments were performed under the light camera. When creating the model, dropout and pooling layers were used. However, these did not have a considerable effect. The batch size was switched between 16, 32, and 64. Excellent results were obtained for the white-background plastic with a batch size of 16, whereas excellent results were obtained with a batch of 32 for transparent background. During tuning, we added different poolings, but did not achieve better results than that using the nonpooling model. The use of the dropout layer did not achieve better results on the data.
4.4. Implementation Issues
Camera data issue: 2K resolution does not have sufficient quality for the plastic resin film; the nonbackground object is still considerably blurry under the camera and sometimes it is difficult to distinguish between a bubble and a defect. Many defects were less than 5 pixels across and the CNN could not be trained to detect them. Raising the platform and lowering the FOV, the defects increased to 10 to 15 pixels and exhibited a superior result in classification. However, three images were required to compose one plastic resin film. This leads to other problems such as localization of the defects in one combined image and ensuring every part of the plastic resin film is captured in the three images. Therefore, we did not raise the height of the platform, and although classification was not better and the nonbackground objects were not clearer, it was considerably efficient during the inspection process.
Data labeling: Considerable time was required for training the data, as every object was cropped to be classified as the right class, most of the time microscope was required to classify the object into the correct class. Furthermore, expanded area of 5, 10, and 15 pixels exhibited different data. This is time consuming and careful scrutiny is required at this stage because this strongly affects the efficiency of our classification model.
During the classification of the camera data, unstable results were obtained for the white background when divided into three categories, and bubbles and scratch would be categorized as defects as shown in
Table 7a and
Figure 16a. Both models were trained on the same data with the same hyperparameters. Therefore, the bubble and the scratch classes were combined, which exhibited superior results as depicted in
Table 7b and
Figure 16b.
However, while white-background plastic has better results while dividing into two categories, the transparent-backgound plastic does not. As shown in
Table 8 and
Figure 17, the recall of the defect class is higher when dividing into three categories. Therefore, during training the transparent-background plastic data, we choose to divide the data into three categories: defect, bubble and scratches.
4.5. Increasing Accuracy
To increase time efficiency, the 2K-resolution camera was selected, and although recall is our priority, precision should also increase. Therefore, the data was doubly verified by applying the 2K-resolution camera first, and then using the microscope method.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}