Developing a Novel Machine Learning-Based Classification Scheme for Predicting SPCs in Colorectal Cancer Survivors



Abstract
:1. Introduction
2. Methods
2.1. MARS
2.2. RF
2.3. SVM
2.4. ELM
2.5. XGboost
2.6. Model Implementation
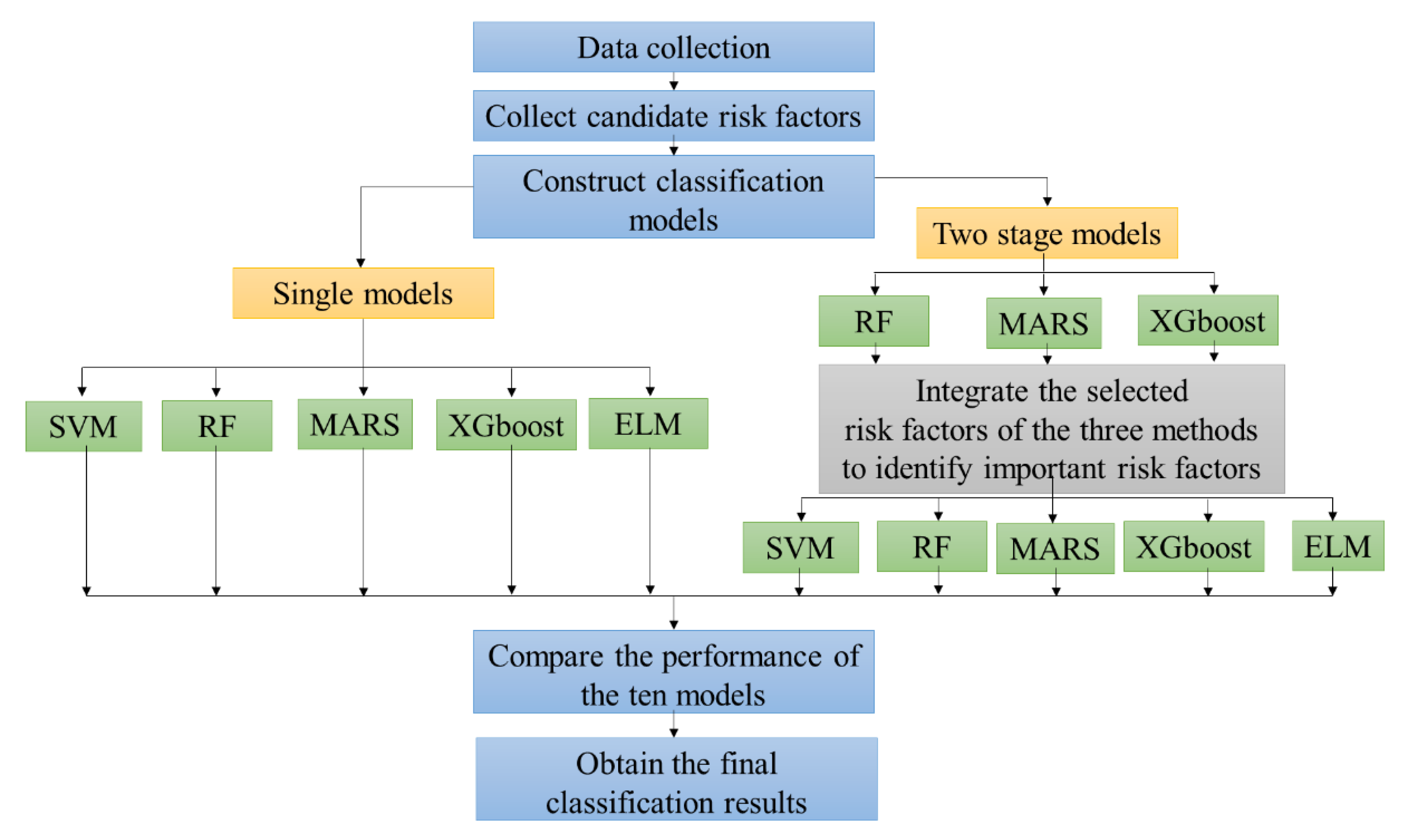
3. Proposed Prediction Scheme
4. Empirical Results
5. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zinatizadeh, N.; Khalili, F.; Fallah, P.; Farid, M.; Geravand, M.; Yaslianifard, S. Potential preventive effect of lactobacillus acidophilus and lactobacillus plantarum in patients with polyps or colorectal cancer. Arq. Gastroenterol. 2018, 55, 407–411. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sakellakis, M. Multiple primary malignancies: A report of two cases. Chin. J. Cancer Res. 2014, 26, 215–218. [Google Scholar] [PubMed]
- Santangelo, M.L. Immunosuppression and multiple primary malignancies in kidney-transplanted patients: A single-institute study. BioMed Res. Int. 2015, 2015, 183–523. [Google Scholar] [CrossRef]
- Xu, W. Multiple primary malignancies in patients with hepatocellular carcinoma: A largest series with 26-year follow-up. Medicine 2016, 95, e3491. [Google Scholar] [CrossRef] [PubMed]
- Li, F. Multiple primary malignancies involving lung cancer. BMC Cancer 2015, 15, 696. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, L.L.; Gu, K.S. Clinical retrospective analysis of cases with multiple primary malignant neoplasms. Genet. Mol. Res. 2014, 13, 9271–9284. [Google Scholar]
- Meng, L.V.; Zhang, X.; Shen, Y.; Wang, F.; Yang, J.; Wang, B.; Chen, Z.; Li, P.; Zhang, X.; Li, S.; et al. Clinical analysis and prognosis of synchronous and metachronous multiple primary malignant tumors. Medicine 2017, 96, e6799. [Google Scholar]
- Huang, C.S.; Yang, S.H.; Lin, C.C.; Lan, Y.T.; Chang, S.C.; Wang, H.S.; Chen, W.S.; Lin, T.C.; Lin, J.K.; Jiang, J.K. Synchronous and metachronous colorectal cancers: Distinct disease entities or different disease courses? Hepato Gastroenterol. 2015, 62, 838–842. [Google Scholar]
- Patricia, A.G.; Jacqueline, C.; Erin, E.H. Ensuring quality care for cancer survivors: Implementing the survivorship care plan. Semin. Oncol. Nurs. 2015, 24, 208–217. [Google Scholar]
- Vogt, A.; Schmid, S.; Heinimann, K.; Frick, H.; Herrmann, C.; Cerny, T.; Omlin, A. Multiple primary tumours: Challenges and approaches, a review. ESMO Open 2017, 2, e000172. [Google Scholar] [CrossRef] [Green Version]
- Tseng, C.J.; Chang, C.C.; Lu, C.J.; Chen, G.D. Application of machine learning to predict the recurrence-proneness for cervical cancer. Neural Comput. Appl. 2014, 24, 1311–1316. [Google Scholar] [CrossRef]
- Tseng, C.J.; Lu, C.J.; Chang, C.C.; Chen, G.D.; Cheewakriangkrai, C. Integration of data mining classification techniques and ensemble learning to identify risk factors and diagnose ovarian cancer recurrence. Artif. Intell. Med. 2017, 78, 47–54. [Google Scholar] [CrossRef] [PubMed]
- Ting, W.C.; Lu, Y.C.; Lu, C.J.; Cheewakriangkrai, C.; Chang, C.C. Recurrence impact of primary site and pathologic stage in patients diagnosed with colorectal cancer. J. Qual. 2018, 25, 166–184. [Google Scholar]
- Chang, C.C.; Chen, S.H. Developing a novel machine learning-based classification scheme for predicting SPCs in breast cancer survivors. Front. Genet. 2019, 10, 848. [Google Scholar] [CrossRef] [PubMed]
- Kopetz, S.; Tabernero, J.; Rosenberg, R.; Jiang, Z.Q.; Moreno, V.; Bachleitner-Hofmann, T.; Lanza, G.; Stork-Sloots, L.; Maru, D.; Simon, I.; et al. Genomic classifier ColoPrint predicts recurrence in stage II colorectal cancer patients more accurately than clinical factors. Oncologist 2015, 20, 127–133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gao, S.; Tibiche, C.; Zou, J.; Zaman, N.; Trifiro, M.; O’Connormccourt, M.; Wang, E. Identification and construction of combinatory cancer hallmark-based gene signature sets to predict recurrence and chemotherapy benefit in stage II colorectal cancer. JAMA Oncol. 2016, 2, 37–45. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, L.; Xiong, Z.; Xie, Q.K.; He, W.; Liu, S.; Kong, P. Second primary colorectal cancer after the initial primary colorectal cancer. BMC Cancer 2018, 18, 931. [Google Scholar] [CrossRef]
- Sun, L.C.; Tai, Y.Y.; Liao, S.M.; Lin, T.Y.; Shih, Y.L.; Chang, S.F. Clinical characteristics of second primary cancer in colorectal cancer patients: The impact of colorectal cancer or other second cancer occurring first. World J. Surg. Oncol. 2014, 12, 73. [Google Scholar] [CrossRef] [Green Version]
- Ringland, C.L.; Arkenau, H.T.; O’Connell, D.L.; Ward, R.L. Second primary colorectal cancers (SPCRCs): Experiences from a large Australian Cancer Registry. Ann. Oncol. 2010, 21, 92–97. [Google Scholar] [CrossRef]
- Friedman, J.H. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–141. [Google Scholar] [CrossRef]
- Zhang, W.; Goh, A.T. Multivariate adaptive regression splines and neural network models for prediction of pile drivability. Geosci. Front. 2016, 7, 45–52. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Yuk, E.; Park, S.; Park, C.S.; Baek, J.G. Feature-learning-based printed circuit board inspection via speeded-up robust features and random forest. Appl. Sci. 2018, 8, 932. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Li, T.; Gao, M.; Song, R.; Yin, Q.; Chen, Y. Support vector machine classifier for accurate identification of piRNA. Appl. Sci. 2018, 8, 2204. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.X. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef] [Green Version]
- Torlay, L.; Perrone-Bertolotti, M.; Thomas, E.; Baciu, M. Machine learning–XGBoost analysis of language networks to classify patients with epilepsy. Brain Inform. 2017, 4, 159. [Google Scholar] [CrossRef]
- Mitchell, R.; Frank, E. Accelerating the XGBoost algorithm using GPU computing. PeerJ Comput. Sci. 2017, 3, e127. [Google Scholar] [CrossRef]
- Milborrow, S.; Hastie, T.; Tibshirani, R.; Miller, A.; Lumley, T. Earth: Multivariate Adaptive Regression Splines. R Package Version 5.1.2. Available online: https://www.rdocumentation.org/packages/earth (accessed on 1 October 2019).
- Liaw, A.; Wiener, M. randomForest: Breiman and Cutler’s Random Forests for Classification and Regression. R Package Version, 4.6.14. Available online: https://www.rdocumentation.org/packages/randomForest (accessed on 1 October 2019).
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group (Formerly: E1071), TU Wien, 2017. R Package Version, 1.7-1. Available online: https://www.rdocumentation.org/packages/e1071 (accessed on 1 October 2019).
- Gosso, A.; Martinez-de-Pison, F. elmNN: Implementation of ELM (Extreme Learning Machine) Algorithm for SLFN (Single Hidden Layer Feedforward Neural Networks). R Package Version, 1. Available online: https://www.rdocumentation.org/packages/elmNN (accessed on 1 October 2019).
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Kenkel, B. Caret: Classification and Regression Training. R Package Version 6.0-84. Available online: https://www.rdocumentation.org/packages/caret (accessed on 1 October 2019).
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y. Xgboost: Extreme Gradient Boosting. R Package Version 0.90.0.2. Available online: https://www.rdocumentation.org/packages/xgboost (accessed on 1 October 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Description |
|---|---|
| X1. Sex | Male/female |
| X2. Age at diagnosis | Age at diagnosis |
| X3. Primary site | Colon/rectal |
| X4. Grade/differentiation | Grade of tumor differentiation |
| X5. Tumor size | Distinguish by unit size (in center meter) |
| X6. Regional lymph nodes positive | Regional lymphoid node involved by tumor |
| X7. Combined stage | Combined pathological and clinical stage as mixed stages |
| X8. Surgical margins of the primary site | Residual/no residual |
| X9. Radiation therapy/no radiation therapy | Radiation therapy/no radiation therapy |
| X10. Chemotherapy/no chemotherapy | Chemotherapy/no chemotherapy |
| X11. BMI | BMI (Body Mass Index) |
| X12. Smoking behavior | Smoking behavior/no smoking behavior |
| X13. Betel nut chewing | Betel nut chewing/no betel nut chewing |
| X14. Drinking | Drinking/no drinking |
| Y: SPC | 1: No, 2: yes |
| Risk factors | RF | MARS | XGboost | Average Rank |
|---|---|---|---|---|
| X1 | 10 | 2 | 4 | 5.3 |
| X2 | 2 | 3 | 2 | 2.3 |
| X3 | 11 | 5 | 11 | 9.0 |
| X4 | 6 | 14 | 5 | 8.3 |
| X5 | 5 | 8 | 3 | 5.3 |
| X6 | 7 | 9 | 9 | 8.3 |
| X7 | 1 | 1 | 1 | 1.0 |
| X8 | 4 | 4 | 8 | 5.3 |
| X9 | 14 | 9 | 14 | 12.3 |
| X10 | 13 | 14 | 13 | 13.3 |
| X11 | 3 | 6 | 6 | 5.0 |
| X12 | 12 | 7 | 12 | 10.3 |
| X13 | 9 | 14 | 10 | 11.0 |
| X14 | 8 | 14 | 7 | 9.7 |
| Methods | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
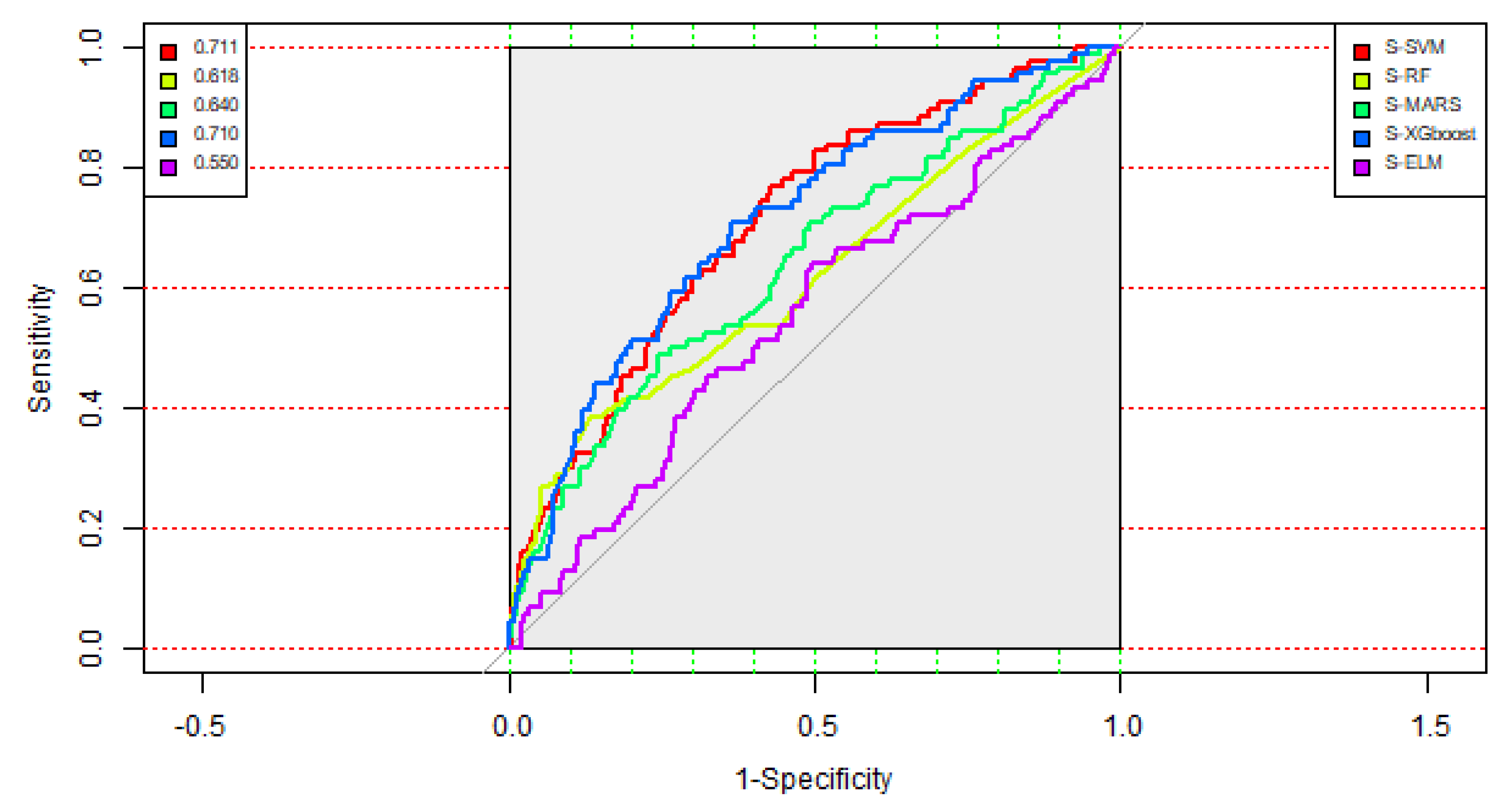
| S-SVM | 0.408 | 0.233 | 0.428 | 0.711 |
| S-RF | 0.819 | 0.384 | 0.868 | 0.618 |
| S-MARS | 0.727 | 0.488 | 0.754 | 0.640 |
| S-XGboost | 0.641 | 0.709 | 0.633 | 0.710 |
| S-ELM | 0.483 | 0.361 | 0.496 | 0.550 |
| Methods | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
| A-SVM | 0.294 | 0.407 | 0.281 | 0.672 |
| A-RF | 0.615 | 0.558 | 0.622 | 0.604 |
| A-MARS | 0.731 | 0.361 | 0.772 | 0.566 |
| A-XGboost | 0.611 | 0.767 | 0.593 | 0.714 |
| A-ELM | 0.425 | 0.442 | 0.424 | 0.546 |
| Methods | Accuracy | Sensitivity | Specificity | AUC |
|---|---|---|---|---|
| S-SVM | 0.625 | 0.647 | 0.623 | 0.666 |
| S-RF | 0.691 | 0.539 | 0.709 | 0.637 |
| S-MARS | 0.741 | 0.486 | 0.771 | 0.636 |
| S-XGboost | 0.675 | 0.671 | 0.675 | 0.706 |
| S-ELM | 0.482 | 0.649 | 0.455 | 0.535 |
| A-SVM | 0.609 | 0.642 | 0.605 | 0.641 |
| A-RF | 0.732 | 0.455 | 0.763 | 0.616 |
| A-MARS | 0.696 | 0.553 | 0.713 | 0.652 |
| A-XGboost | 0.695 | 0.672 | 0.697 | 0.723 |
| A-ELM | 0.503 | 0.632 | 0.479 | 0.539 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ting, W.-C.; Chang, H.-R.; Chang, C.-C.; Lu, C.-J. Developing a Novel Machine Learning-Based Classification Scheme for Predicting SPCs in Colorectal Cancer Survivors. Appl. Sci. 2020, 10, 1355. https://doi.org/10.3390/app10041355
Ting W-C, Chang H-R, Chang C-C, Lu C-J. Developing a Novel Machine Learning-Based Classification Scheme for Predicting SPCs in Colorectal Cancer Survivors. Applied Sciences. 2020; 10(4):1355. https://doi.org/10.3390/app10041355
Chicago/Turabian StyleTing, Wen-Chien, Horng-Rong Chang, Chi-Chang Chang, and Chi-Jie Lu. 2020. "Developing a Novel Machine Learning-Based Classification Scheme for Predicting SPCs in Colorectal Cancer Survivors" Applied Sciences 10, no. 4: 1355. https://doi.org/10.3390/app10041355
APA StyleTing, W.-C., Chang, H.-R., Chang, C.-C., & Lu, C.-J. (2020). Developing a Novel Machine Learning-Based Classification Scheme for Predicting SPCs in Colorectal Cancer Survivors. Applied Sciences, 10(4), 1355. https://doi.org/10.3390/app10041355