Laryngeal Image Processing of Vocal Folds Motion

 ,
,
Abstract
:1. Introduction
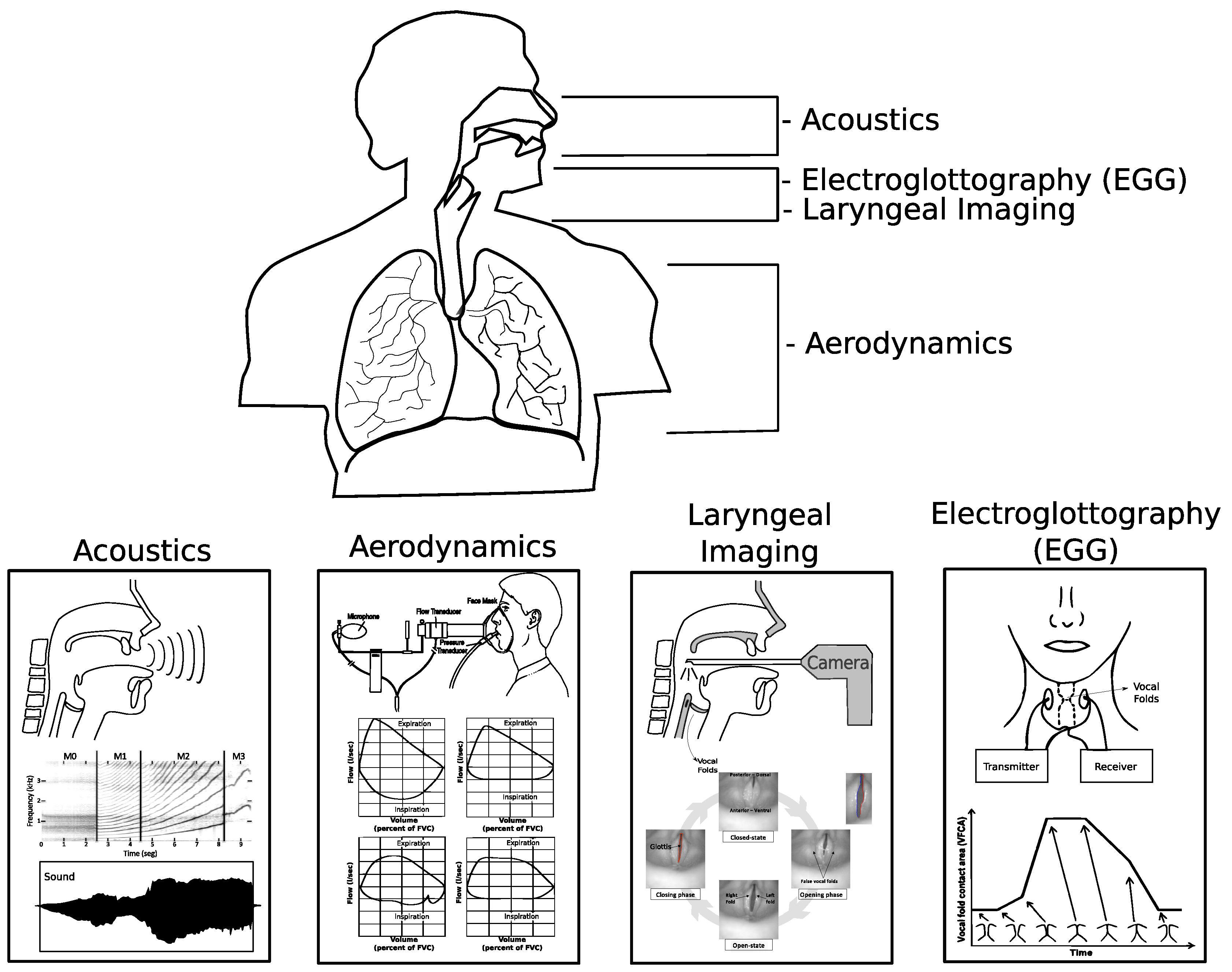
2. Laryngeal Image Modalities
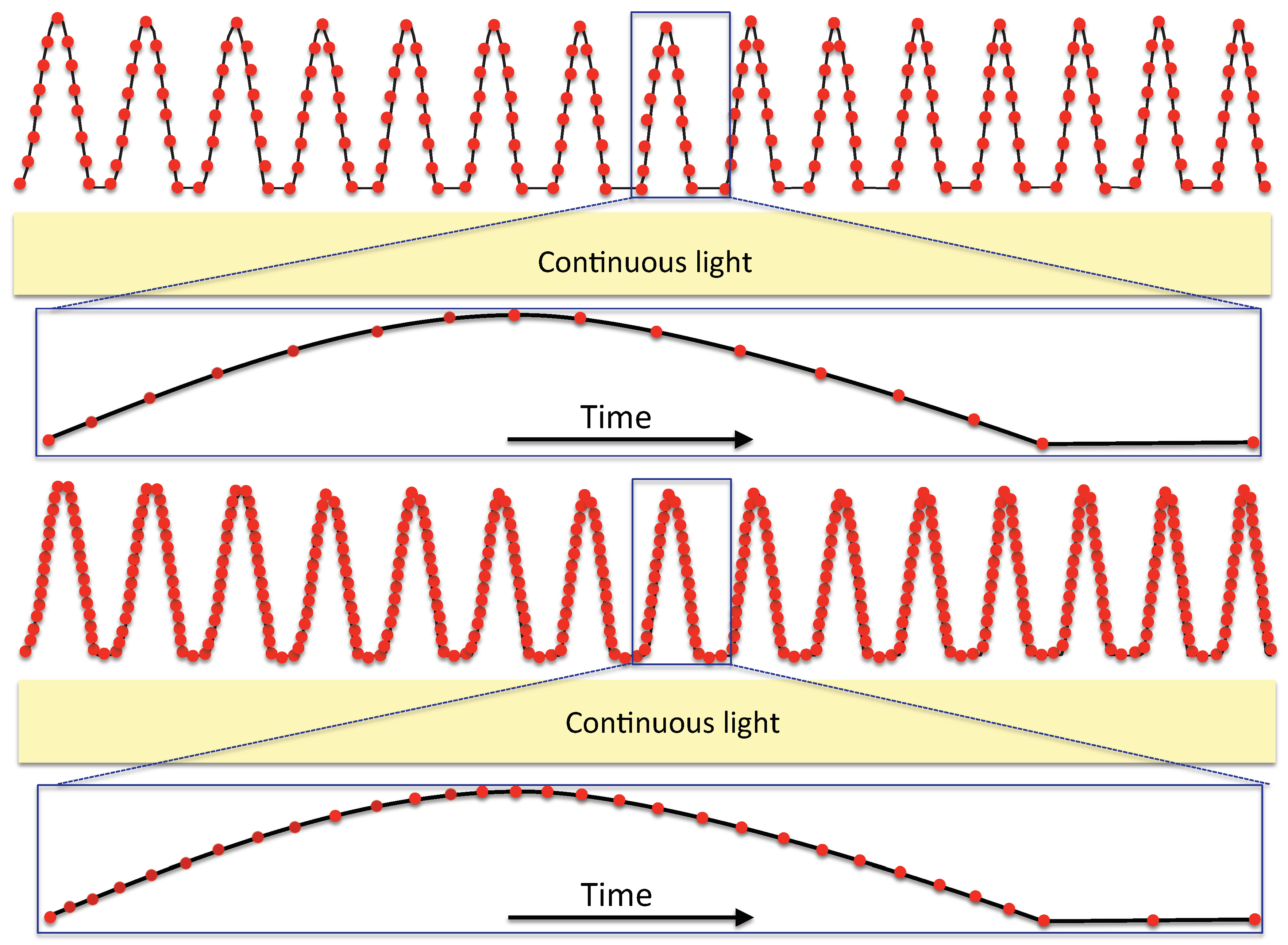
2.1. Laryngeal Videostroboscopy
2.1.1. Advantages
- It can be used with Distal Chip Laryngoscopy (DCL) and Flexible Fiberoptic Laryngoscopy (FOL) [28] during articulated speech and singing. DCL is identical to FOL regarding diagnostic accuracy, but DCL is superior to FOL in image quality and interrater reliability. Despite flexible endoscope optics have lower quality than a rigid endoscope, it is possible to obtain an image quality comparable to the rigid laryngoscope using DCL [29,30].
- It can be coupled with high-definition cameras, providing a higher spatial resolution of the vocal fold structures involved in phonatory vibration (e.g., mucosa, superficial vasculature, etc.) [18]. The High-Definition Digital Stroboscopy System by KayPENTAX Model 9310HD, for example, records interlaced video frames with a spatial resolution of 1920 × 1080 full-HD letting real-time viewing of exam video in uncompressed HD. 4K video format with a spatial resolution of 3840 × 2160 pixels has been tested in VS. Despite the fact that its clinical implementation is feasible, its usefulness must be proven [31].
2.1.2. Limitations
- It does not provide a real view of the vocal folds’ vibratory pattern, so it is restricted to stable and periodic vocal folds vibrations. Therefore, VS is incapable of revealing vocal fold vibratory patterns in patients with severe dysphonia [32]. In addition, VS limits scientific and diagnostic knowledge of the vocal function during voice onset and voice offset.
2.2. Laryngeal High-Speed Videoendoscopy
2.2.1. Advantages
- It is useful to get insights into tissue vibratory characteristics, influence of aerodynamical forces and muscular tension, vocal length, phonatory breaks, laryngeal spams, vocal folds contact and evaluation of normal laryngeal functioning in situation of rapid pitch change such as onset and offset of voicing or glides [5,43].
2.2.2. Limitations
- It is not possible to provide real-time audiovisual feedback due to the high temporal resolution of HSV. However, it is possible to align HSV with acoustics and EGG signals to provide more precise measures that can improve clinical diagnosis.
3. Glottal Gap Segmentation and Facilitative Playbacks
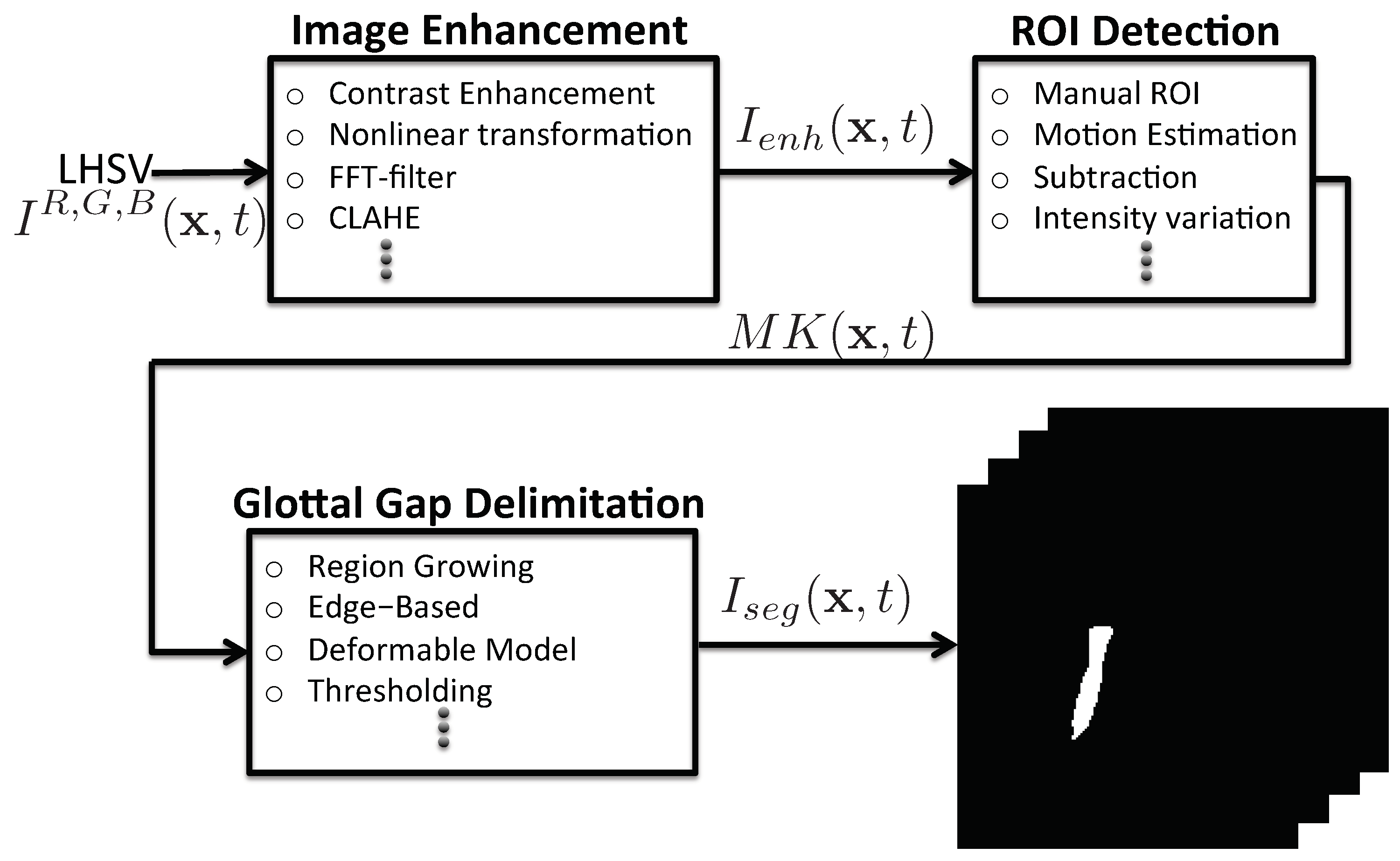
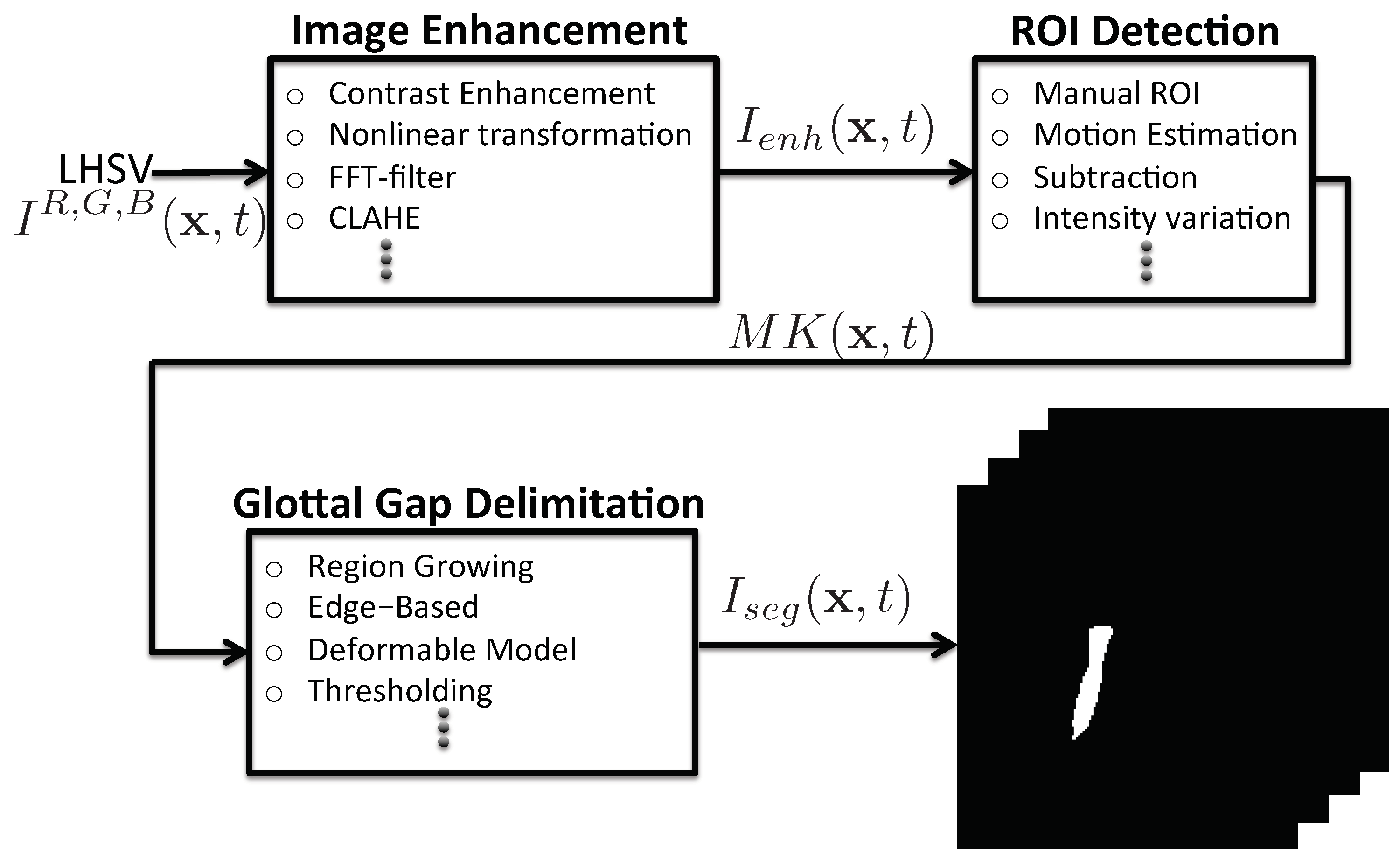
3.1. Image-Processing Methods
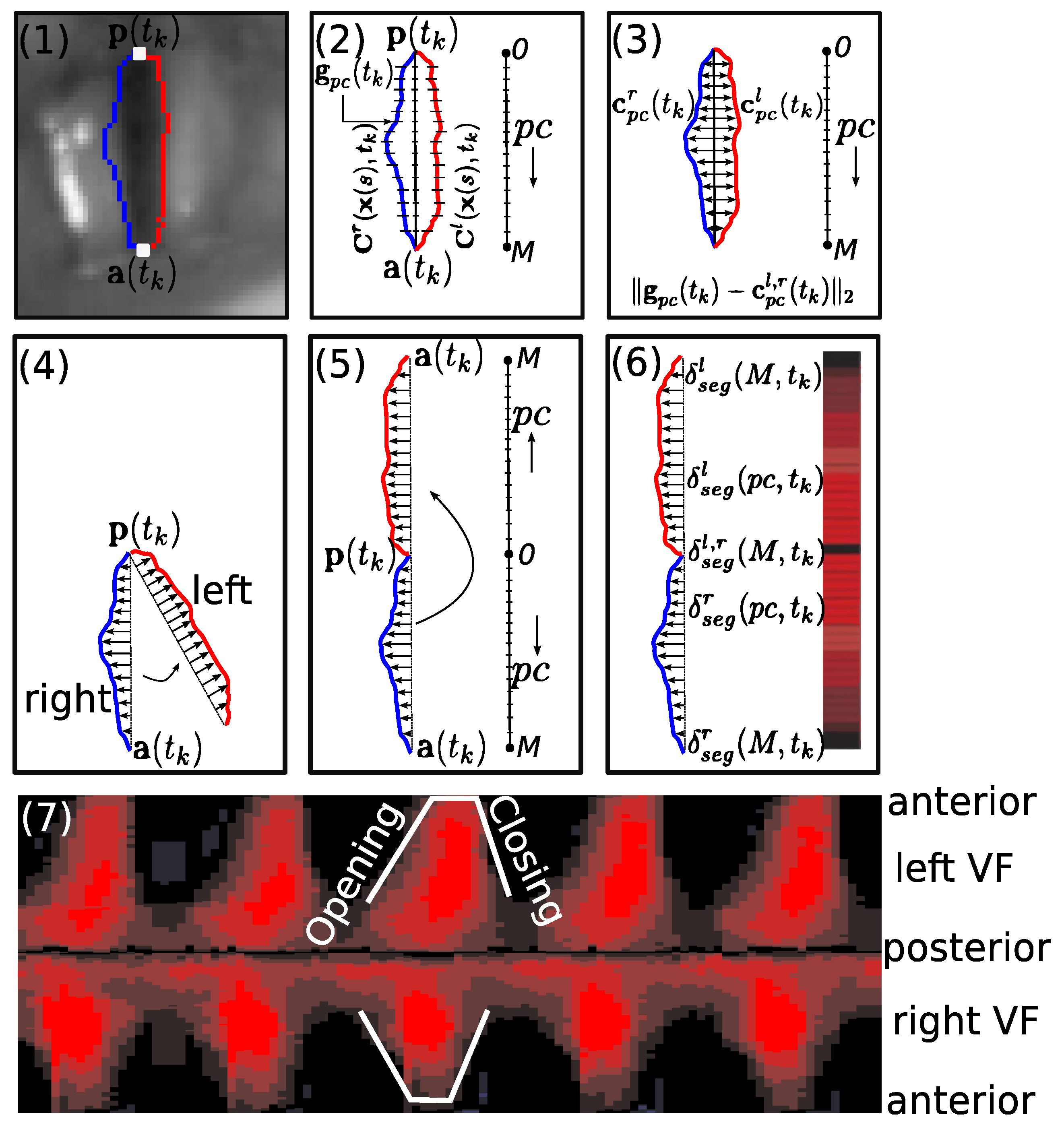
3.2. Glottal Gap Segmentation Techniques
3.2.1. Image Enhancement
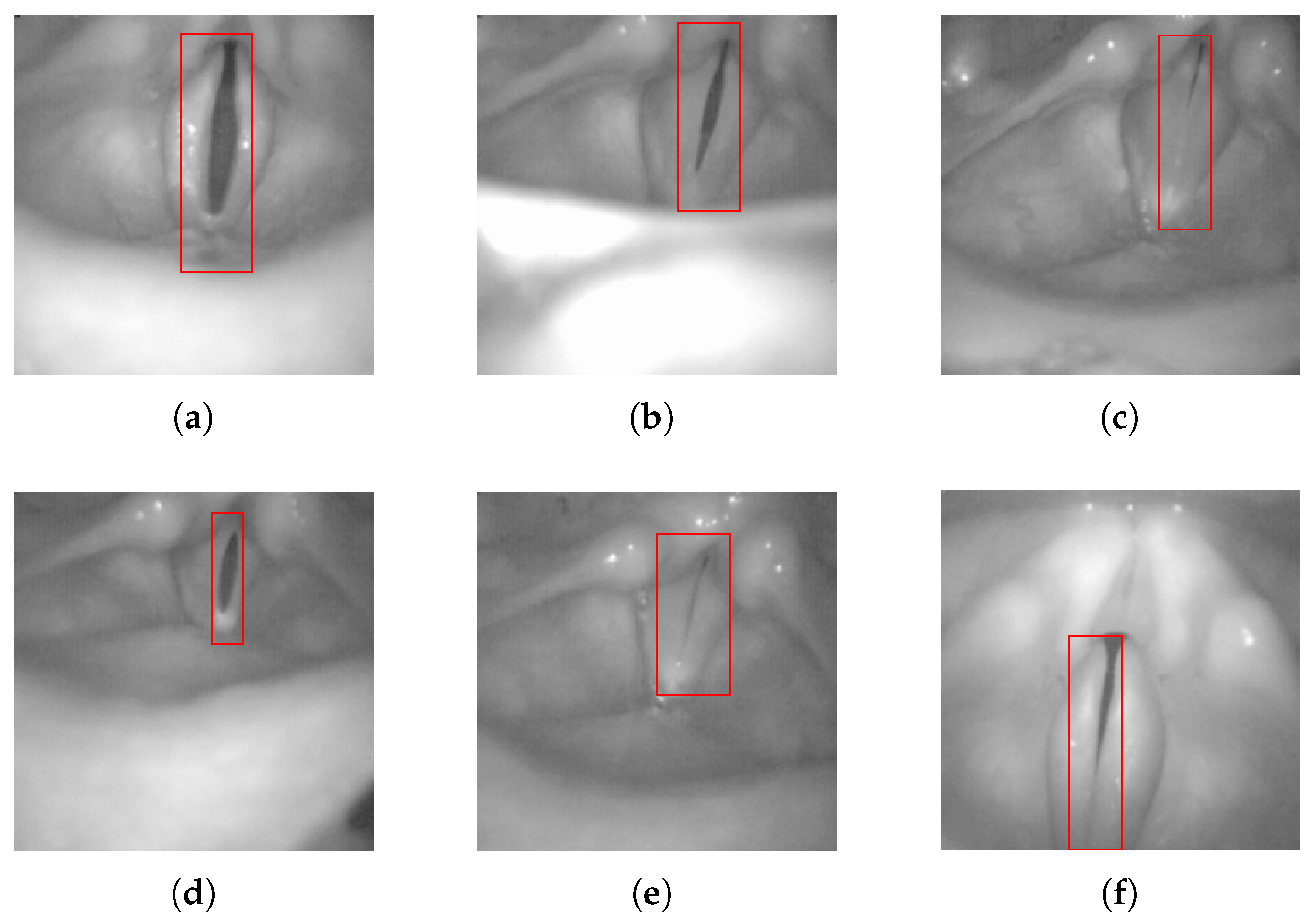
3.2.2. Region of Interest
3.2.3. Glottal Gap Delimitation
3.2.4. Assessment of Vocal Folds Segmentation
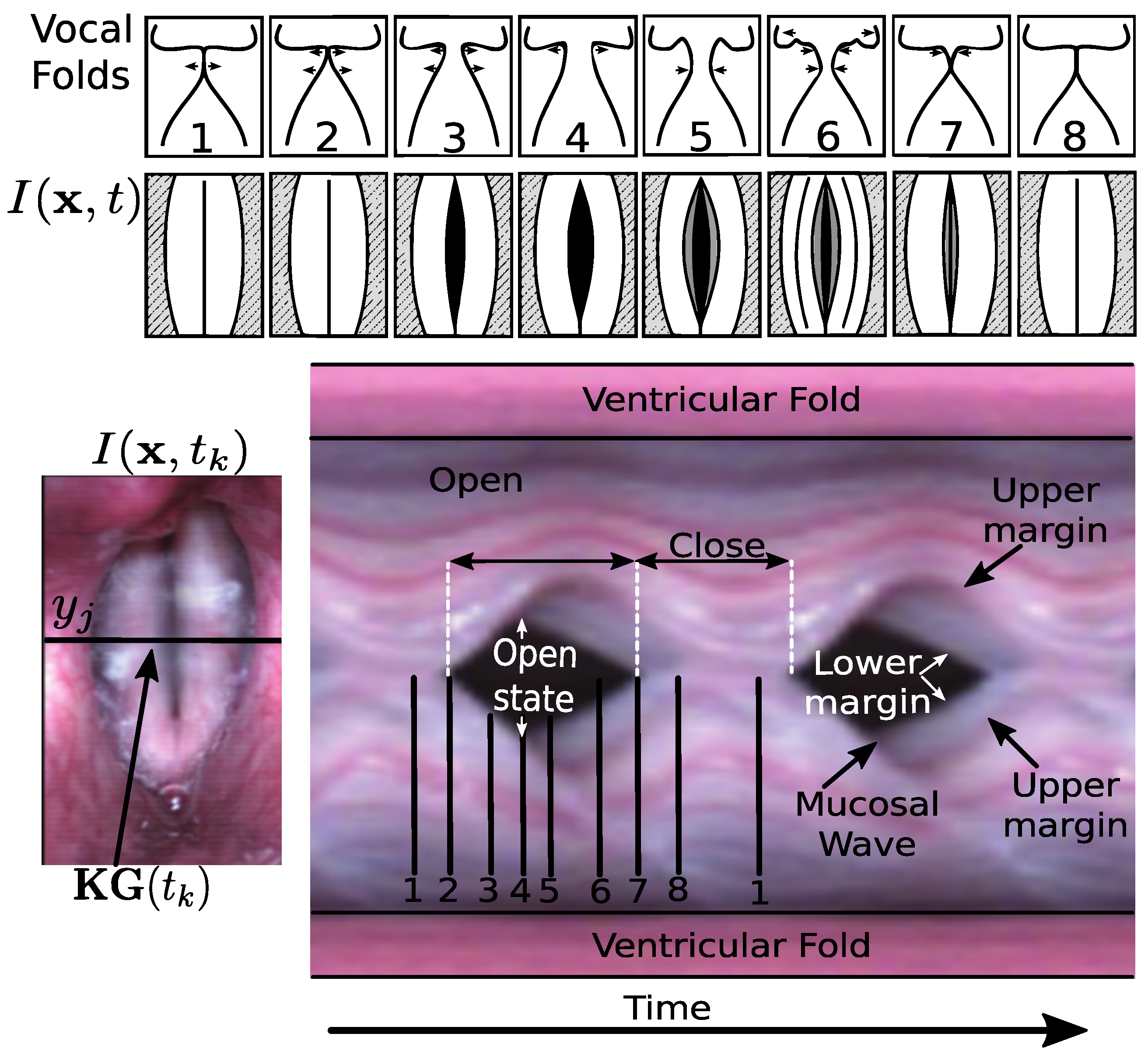
3.3. Facilitative Playbacks Representation
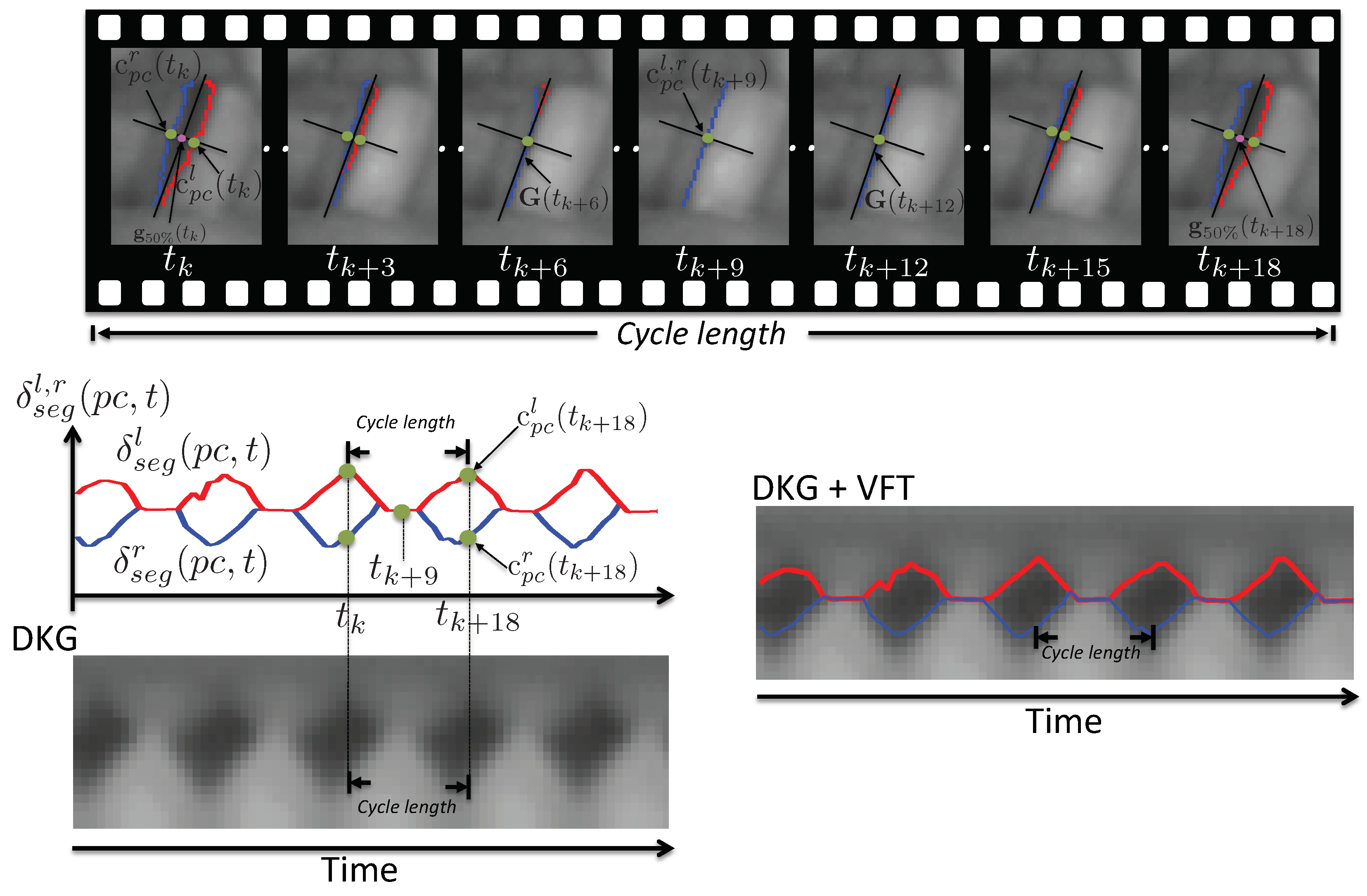
3.3.1. Local-Dynamics Facilitative Playbacks
3.3.2. Global-Dynamics Facilitative Playbacks
4. Challenges in Glottal Gap Segmentation and Facilitative Playbacks
5. Voice Research and Clinical Applications
6. Discussions and Future Directions
Author Contributions
Funding
Conflicts of Interest
References
- Henrich, N. La Voix Humaine: Vibrations, Résonances, Interactions Pneumo-Phono-Résonantielles; Accreditation to supervise research; Université Grenoble Alpes: Grenoble, France, 2015. [Google Scholar]
- Patel, R.R.; Awan, S.N.; Barkmeier-Kraemer, J.; Courey, M.; Deliyski, D.; Eadie, T.; Paul, D.; Švec, J.G.; Hillman, R. Recommended Protocols for Instrumental Assessment of Voice: American Speech-Language-Hearing Association Expert Panel to Develop a Protocol for Instrumental Assessment of Vocal Function. Am. J. Speech Lang. Pathol. 2018, 27, 887–905. [Google Scholar] [CrossRef]
- Yan, Y.; Damrose, E.; Bless, D. Functional analysis of voice using simultaneous high-speed imaging and acoustic recordings. J. Voice 2007, 21, 604–616. [Google Scholar] [CrossRef] [PubMed]
- Deliyski, D.; Petrushev, P.; Bonilha, H.; Gerlach, T.; Martin-Harris, B.; Hillman, R. Clinical Implementation of Laryngeal High-Speed Videoendoscopy: Challenges and Evolution. Folia Phoniatr. Logop. 2008, 60, 33–44. [Google Scholar] [CrossRef] [PubMed]
- Zacharias, S.; Deliyski, D.; Gerlach, T. Utility of Laryngeal High-speed Videoendoscopy in Clinical Voice Assessment. J. Voice 2018, 32 2, 216–220. [Google Scholar] [CrossRef]
- Tao, C.; Zhang, Y.; Jiang, J. Extracting Physiologically Relevant Parameters of Vocal Folds From High-Speed Video Image Series. IEEE Trans. Biomed. Eng. 2007, 54, 794–801. [Google Scholar] [PubMed]
- Lohscheller, J.; Švec, J.; Döllinger, M. Vocal fold vibration amplitude, open quotient, speed quotient and their variability along glottal length: Kymographic data from normal subjects. Logoped. Phoniatr. Vocol. 2013, 38, 182–192. [Google Scholar] [CrossRef] [PubMed]
- Woo, P. Objective Measures of Laryngeal Imaging: What Have We Learned Since Dr. Paul Moore. J. Voice 2014, 28, 69–81. [Google Scholar] [CrossRef] [PubMed]
- Rammage, L. Disorders of voice. In The Cambridge Handbook of Communication Disorders; Cummings, L., Ed.; Cambridge University Press: Cambridge, UK, 2013; Chapter 25; pp. 457–483. [Google Scholar]
- Dejonckere, P.H. Assessment of Voice and Respiratory Function. In Surgery of Larynx and Trachea; Remacle, M., Eckel, H.E., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Chapter 2; pp. 11–26. [Google Scholar]
- Larsson, H.; Stellan, H.; Lindestad, P.A.; Hammarberg, B. Vocal Fold Vibrations: High-Speed Imaging, Kymography, and Acoustic Analysis: A Preliminary Report. Laryngoscope 2000, 110, 2117–2122. [Google Scholar] [CrossRef]
- Yumoto, E. Aerodynamics, voice quality, and laryngeal image analysis of normal and pathologic voices. Curr. Opin. Otolaryngol. Head Neck Surg. 2004, 12, 166–173. [Google Scholar] [CrossRef]
- Heman-Ackah, Y.D. Diagnostic tools in laryngology. Curr. Opin. Otolaryngol. Head Neck Surg. 2004, 12, 549–552. [Google Scholar] [CrossRef]
- Hertegȧrd, S. What have we learned about laryngeal physiology from high-speed digital videoendoscopy? Curr. Opin. Otolaryngol. Head Neck Surg. 2005, 13, 152–156. [Google Scholar] [CrossRef] [PubMed]
- Verikas, A.; Uloza, V.; Bacauskiene, M.; Gelzinis, A.; Kelertas, E. Advances in laryngeal imaging. Eur. Arch. Oto-Rhino-Laryngol. 2009, 266, 1509–1520. [Google Scholar] [CrossRef] [PubMed]
- Deliyski, D.; Hillman, R. State of the Art Laryngeal Imaging: Research and Clinical Implications. Curr. Opin. Otolaryngol. Head Neck Surg. 2010, 18, 147–152. [Google Scholar] [CrossRef] [PubMed]
- Mehta, D.D.; Hillman, R.E. The Evolution of Methods for Imaging Vocal Fold Phonatory Function. SIG 5 Perspect. Speech Sci. Orofac. Disord. 2012, 22, 5–13. [Google Scholar] [CrossRef] [Green Version]
- Mehta, D.; Hillman, R. Current role of stroboscopy in laryngeal imaging. Curr. Opin. Otolaryngol. Head Neck Surg. 2012, 20, 429–436. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kendall, K.A. High-speed digital imaging of the larynx: Recent advances. Curr. Opin. Otolaryngol. Head Neck Surg. 2012, 20, 466–471. [Google Scholar] [CrossRef] [PubMed]
- Hawkshaw, M.J.; Sataloff, J.B.; Sataloff, R.T. New Concepts in Vocal Fold Imaging: A Review. J. Voice 2013, 27, 738–743. [Google Scholar] [CrossRef]
- Deliyski, D.; Hillman, R.; Mehta, D. Laryngeal High-Speed Videoendoscopy: Rationale and Recommendation for Accurate and Consistent Terminology. J. Speech Lang. Hear. Res. 2015, 58, 1488–1492. [Google Scholar] [CrossRef]
- Bailly, L.; Cochereau, T.; Orgéas, L.; Henrich Bernardoni, N.; Rolland du Roscoat, S.; McLeer-Florin, A.; Robert, Y.; Laval, X.; Laurencin, T.; Chaffanjon, P.; et al. 3D multiscale imaging of human vocal folds using synchrotron X-ray microtomography in phase retrieval mode. Sci. Rep. 2018, 8, 14003. [Google Scholar] [CrossRef]
- Semmler, M.; Kniesburges, S.; Parchent, J.; Jakubaß, B.; Zimmermann, M.; Bohr, C.; Schützenberger, A.; Döllinger, M. Endoscopic Laser-Based 3D Imaging for Functional Voice Diagnostics. Appl. Sci. 2017, 7, 600. [Google Scholar] [CrossRef] [Green Version]
- Semmler, M.; Döllinger, M.; Patel, R.R.; Ziethe, A.; Schützenberger, A. Clinical relevance of endoscopic three-dimensional imaging for quantitative assessment of phonation. Laryngoscope 2018, 128, 2367–2374. [Google Scholar] [CrossRef] [PubMed]
- Deliyski, D.D.; Shishkov, M.; Mehta, D.D.; Ghasemzadeh, H.; Bouma, B.; Zañartu, M.; de Alarcon, A.; Hillman, R.E. Laser-Calibrated System for Transnasal Fiberoptic Laryngeal High-Speed Videoendoscopy. J. Voice 2019. [Google Scholar] [CrossRef] [PubMed]
- Ghasemzadeh, H.; Deliyski, D.D.; Ford, D.S.; Kobler, J.B.; Hillman, R.E.; Mehta, D.D. Method for Vertical Calibration of Laser-Projection Transnasal Fiberoptic High-Speed Videoendoscopy. J. Voice 2019. [Google Scholar] [CrossRef] [PubMed]
- Kendall, K.; Leonard, R. Laryngeal High-speed Videoendoscopy, In Laryngeal Evaluation: Indirect Laryngoscopy to High-Speed Digital Imaging; Thieme: New York, NY, USA, 2010; Chapter 28; pp. 245–270. [Google Scholar]
- Kawaida, M.; Fukuda, H.; Kohno, N. Electronic Videoendoscopic Laryngostroboscopy. ORL J. Otorhinolaryngol. Relat. Spec. 2004, 66, 267–274. [Google Scholar] [CrossRef]
- Eller, R.; Ginsburg, M.; Lurie, D.; Heman-Ackah, Y.; Lyons, K.; Sataloff, R. Flexible Laryngoscopy: A Comparison of Fiber Optic and Distal Chip Technologies. Part 1: Vocal Fold Masses. J. Voice 2008, 22, 746–750. [Google Scholar] [CrossRef] [Green Version]
- Eller, R.; Ginsburg, M.; Lurie, D.; Heman-Ackah, Y.; Lyons, K.; Sataloff, R. Flexible Laryngoscopy: A Comparison of Fiber Optic and Distal Chip Technologies-Part 2: Laryngopharyngeal Reflux. J. Voice 2009, 23, 389–395. [Google Scholar] [CrossRef] [Green Version]
- Woo, P. 4K Video-Laryngoscopy and Video-Stroboscopy: Preliminary Findings. Ann. Otol. Rhinol. Laryngol. 2016, 125, 77–81. [Google Scholar] [CrossRef]
- Patel, R.; Dailey, S.; Bless, D. Comparison of High-Speed Digital Imaging with Stroboscopy for Laryngeal Imaging of Glottal Disorders. Ann. Otol. Rhinol. Laryngol. 2008, 117, 413–424. [Google Scholar] [CrossRef]
- Kendall, K.; Leonard, R. Introduction to Videostroboscopy. In Laryngeal Evaluation: Indirect Laryngoscopy to High-Speed Digital Imaging; Thieme: New York, NY, USA, 2010; Chapter 10; pp. 92–100. [Google Scholar]
- Kendall, K.; Leonard, R. The Science of Stroboscopic Imaging. In Laryngeal Evaluation: Indirect Laryngoscopy to High-Speed Digital Imaging; Thieme: New York, NY, USA, 2010; Chapter 11; pp. 101–109. [Google Scholar]
- Deliyski, D.; Powell, M.E.; Zacharias, S.R.; Gerlach, T.T.; de Alarcon, A. Experimental investigation on minimum frame rate requirements of high-speed videoendoscopy for clinical voice assessment. Biomed. Signal Process. Control 2015, 17, 21–28. [Google Scholar] [CrossRef] [Green Version]
- Schlegel, P.; Semmler, M.; Kunduk, M.; Döllinger, M.; Bohr, C.; Schützenberger, A. Influence of Analyzed Sequence Length on Parameters in Laryngeal High-Speed Videoendoscopy. Appl. Sci. 2018, 8, 2666. [Google Scholar] [CrossRef] [Green Version]
- Hertegȧrd, S.; Larsson, H.; Wittenberg, T. High-speed imaging: Applications and development. Logoped. Phoniatr. Vocol. 2003, 28, 133–139. [Google Scholar] [CrossRef] [PubMed]
- Qin, X.; Wang, S.; Wan, M. Improving Reliability and Accuracy of Vibration Parameters of Vocal Folds Based on High-Speed Video and Electroglottography. IEEE Trans. Biomed. Eng. 2009, 56, 1744–1754. [Google Scholar] [PubMed]
- Herbst, C.; Lohscheller, J.; Švec, J.; Henrich, N.; Weissengruber, G.; Fitch, W. Glottal opening and closing events investigated by electroglottography and super-high-speed video recordings. J. Exp. Biol. 2014, 217, 955–963. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Leppävuori, M.; Andrade-Miranda, G.; Henrich Bernardoni, N.; Laukkanen, A.M.; Geneid, A. Characterizing vocal-fold dynamics in singing vocal modes from Complete Vocal Technique using high-speed laryngeal imaging and electroglottographic analysis. In Proceedings of the Pan-European Voice Conference, Copenhagen, Denmark, 27–30 August 2019. [Google Scholar]
- Echternach, M.; Burk, F.; Köberlein, M.; Herbst, C.T.; Döllinger, M.; Burdumy, M.; Richter, B. Oscillatory Characteristics of the Vocal Folds Across the Tenor Passaggio. J. Voice 2017, 31, 381.e5–381.e14. [Google Scholar] [CrossRef]
- Echternach, M.; Burk, F.; Köberlein, M.; Selamtzis, A.; Döllinger, M.; Burdumy, M.; Richter, B.; Herbst, C.T. Laryngeal evidence for the first and second passaggio in professionally trained sopranos. PLoS ONE 2017, 12, e0175865. [Google Scholar] [CrossRef]
- Díaz-Cádiz, M.E.; Peterson, S.D.; Galindo, G.E.; Espinoza, V.M.; Motie-Shirazi, M.; Erath, B.D.; Zañartu, M. Estimating Vocal Fold Contact Pressure from Raw Laryngeal High-Speed Videoendoscopy Using a Hertz Contact Model. Appl. Sci. 2019, 9. [Google Scholar] [CrossRef] [Green Version]
- Bohr, C.; Kräck, A.; Dubrovskiy, D.; Eysholdt, U.; Švec, J.; Psychogios, G.; Ziethe, A.; Döllinger, M. Spatiotemporal Analysis of High-Speed Videolaryngoscopic Imaging of Organic Pathologies in Males. J. Speech Lang. Hear. Res. 2014, 57, 1148–1161. [Google Scholar] [CrossRef]
- Wang, J.S.; Olszewski, E.; Devine, E.E.; Hoffman, M.R.; Zhang, Y.; Shao, J.; Jiang, J.J. Extension and Application of High-Speed Digital Imaging Analysis Via Spatiotemporal Correlation and Eigenmode Analysis of Vocal Fold Vibration Before and After Polyp Excision. Ann. Otol. Rhinol. & Laryngol. 2016, 125, 660–666. [Google Scholar] [CrossRef]
- Voigt, D.; Döllinger, M.; Braunschweig, T.; Yang, A.; Eysholdt, U.; Lohscheller, J. Classification of functional voice disorders based on phonovibrograms. Artif. Intell. Med. 2010, 49, 51–59. [Google Scholar] [CrossRef]
- Phadke, K.V.; Vydrová, J.; Domagalská, R.; G, Š.J. Evaluation of clinical value of videokymography for diagnosis and treatment of voice disorders. Eur. Arch. Oto-Rhino-Laryngol. 2017, 274, 3941–3949. [Google Scholar] [CrossRef]
- Lohscheller, J.; Eysholdt, U. Phonovibrogram visualization of entire vocal fold dynamics. Laryngoscope 2008, 118, 753–758. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.G.; Park, H.J.; Lee, B.J.; Lee, S.M.; Ko, B.; Lee, S.M.; Park, Y.M. A new videokymography system for evaluation of the vibration pattern of entire vocal folds. Auris Nasus Larynx 2016, 43, 315–321. [Google Scholar] [CrossRef]
- Unger, J.; Lohscheller, J.; Reiter, M.; Eder, K.; Betz, C.; Schuster, M. A Noninvasive Procedure for Early-Stage Discrimination of Malignant and Precancerous Vocal Fold Lesions Based on Laryngeal Dynamics Analysis. Cancer Res. 2015, 75, 31–39. [Google Scholar] [CrossRef] [Green Version]
- Roubeau, B.; Henrich, N.; Castellengo, M. Laryngeal Vibratory Mechanisms: The Notion of Vocal Register Revisited. J. Voice 2009, 23, 425–438. [Google Scholar] [CrossRef] [PubMed]
- Cveticanin, L. Review on Mathematical and Mechanical Models of the Vocal Cord. J. Appl. Math. 2012, 2012, 928591. [Google Scholar] [CrossRef]
- Ishikawa, C.C.; Pinheiro, T.G.; Hachiya, A.; Montagnoli, A.N.; Tsuji, D.H. Impact of Cricothyroid Muscle Contraction on Vocal Fold Vibration: Experimental Study with High-Speed Videoendoscopy. J. Voice 2017, 31, 300–306. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, J.; Rahn, D.A. Studying vocal fold vibrations in Parkinson’s disease with a nonlinear model. Chaos Interdiscip. J. Nonlinear Sci. 2005, 15, 033903. [Google Scholar] [CrossRef]
- Gonzalez, R.C.; Woods, R.E. Image Segmentation, 3rd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2006; Chapter 10. [Google Scholar]
- Sezgin, M.; Sankur, B. Survey over image thresholding techniques and quantitative performance evaluation. J. Electron. Imaging 2004, 13, 146–168. [Google Scholar]
- Park, J.M.; Murphey, Y.L. Edge Detection in Grayscale, Color, and Range Images. In Wiley Encyclopedia of Computer Science and Engineering; American Cancer Society: Atlanta, GA, USA, 2008; pp. 1–16. [Google Scholar] [CrossRef]
- Hanbury, A. Image Segmentation by Region Based and Watershed Algorithms. In Wiley Encyclopedia of Computer Science and Engineering; American Cancer Society: Atlanta, GA, USA, 2009; pp. 1543–1552. [Google Scholar] [CrossRef] [Green Version]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2000. [Google Scholar]
- Boykov, Y.; Veksler, O.; Zabih, R. Fast approximate energy minimization via graph cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 1222–1239. [Google Scholar] [CrossRef] [Green Version]
- Boykov, Y.; Kolmogorov, V. An Experimental Comparison of Min-Cut/Max-Flow Algorithms for Energy Minimization in Vision. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1124–1137. [Google Scholar] [CrossRef] [Green Version]
- Xu, C.; Pham, D.L.; Prince, J.L. Image segmentation using deformable models. In Handbook of Medical Imaging. Volume 2. Medical Image Processing and Analysis; Spie Press Book: Bellingham, WA, USA, 2000; Volume 2, pp. 175–272. [Google Scholar]
- Reddy, B.S.; Chatterji, B.N. An FFT-based technique for translation, rotation, and scale-invariant image registration. IEEE Trans. Image Process. 1996, 5, 1266–1271. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zitová, B.; Flusser, J. Image registration methods: A survey. Image Vis. Comput. 2003, 21, 977–1000. [Google Scholar] [CrossRef] [Green Version]
- Zhu, C.; Lin, X.; Chau, L.P. Hexagon-based search pattern for fast block motion estimation. IEEE Trans. Circuits Syst. Video Technol. 2002, 12, 349–355. [Google Scholar] [CrossRef] [Green Version]
- Changsoo, J.; Hyung-Min, P. Optimized hierarchical block matching for fast and accurate image registration. Signal Process. Image Commun. 2013, 28, 779–791. [Google Scholar]
- Biemond, J.; Looijenga, L.; Boekee, D.; Plompen, R. A pel-recursive Wiener-based displacement estimation algorithm. Signal Process. 1987, 13, 399–412. [Google Scholar] [CrossRef]
- Efstratiadis, S.N.; Katsaggelos, A.K. A model-based pel-recursive motion estimation algorithm. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Albuquerque, NM, USA, 3–6 April 1990; Volume 4, pp. 1973–1976. [Google Scholar]
- Fortun, D.; Bouthemy, P.; Kervrann, C. Optical flow modeling and computation: A survey. Comput. Vis. Image Underst. 2015, 134, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Yuen, J.; Torralba, A. SIFT Flow: Dense Correspondence Across Scenes and Its Applications. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 978–994. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehta, D.; Deliyski, D.; Quatieri, T.; Hillman, R. Automated measurement of vocal fold vibratory asymmetry from high-speed videoendoscopy recordings. J. Speech Lang. Hear. Res. 2013, 54, 47–54. [Google Scholar] [CrossRef]
- Blanco, M.; Chen, X.; Yan, Y. A Restricted, Adaptive Threshold Segmentation Approach for Processing High-Speed Image Sequences of the Glottis. Engineering 2013, 5, 357–362. [Google Scholar] [CrossRef] [Green Version]
- Lohscheller, J.; Toy, H.; Rosanowski, F.; Eysholdt, U.; Dollinger, M. Clinically evaluated procedure for the reconstruction of vocal fold vibrations from endoscopic digital high-speed videos. Med Image Anal. 2007, 11, 400–413. [Google Scholar] [CrossRef]
- Pinheiro, A.; Dajer, M.E.; Hachiya, A.; Montagnoli, A.N.; Tsuji, D. Graphical Evaluation of Vocal Fold Vibratory Patterns by High-Speed Videolaryngoscopy. J. Voice 2014, 28, 106–111. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Gunturk, B.K.; Kunduk, M. Glottis segmentation using dynamic programming. In Proceedings of the Medical Imaging 2013: Image Processing, Lake Buena Vista, FL, USA, 10–12 February 2013; Volume 8669, p. 86693L. [Google Scholar]
- Booth, J.R.; Childers, D.G. Automated Analysis of Ultra High-Speed Laryngeal Films. IEEE Trans. Biomed. Eng. 1979, 26, 185–192. [Google Scholar] [CrossRef] [PubMed]
- Moukalled, H.J.; Deliyski, D.D.; Schwarz, R.R.; Wang, S. Segmentation of laryngeal high-speed videondoscopy in temporal domain using paired active contours. In Proceedings of the 6th International Workshop, Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA), Firenze, Italy, 14–16 December 2009; pp. 137–140. [Google Scholar]
- Marendic, B.; Galatsanos, N.; Bless, D. A new active contour algorithm for tracking vibrating vocal fold. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Thessaloniki, Greece, 7–10 October 2001; pp. 397–400. [Google Scholar]
- Wittenberg, T.; Moser, M.; Tigges, M.; Eysholdt, U. Recording, processing, and analysis of digital high-speed sequences in glottography. Mach. Vis. Appl. 1995, 8, 399–404. [Google Scholar] [CrossRef]
- Palm, C.; Lehmann, T.; Bredno, J.; Neuschaefer-Rube, C.; Klajman, S.; Spitzer, K. Automated analysis of stroboscopic image sequences by vibration profile. In Proceedings of the 5th International Workshop on Advances in Quantitative Laryngology, Voice and Speech Research, Groningen, The Netherlands, 27–28 April 2001. [Google Scholar]
- Yan, Y.; Chen, X.; Bless, D. Automatic tracing of vocal-fold motion from high-speed digital images. IEEE Trans. Biomed. Eng. 2006, 53, 1394–1400. [Google Scholar] [CrossRef]
- Skalski, A.; Zielinki, T.; Deliyski, D. Analysis of vocal folds movement in high speed videoendoscopy based on level set segmentation and image registration. In Proceedings of the International Conference on Signals and Electronic Systems (ICSES), Kraków, Poland, 14–17 September 2008; pp. 223–226. [Google Scholar]
- Zhang, Y.; Bieging, E.; Tsui, H.; Jiang, J.J. Efficient and Effective Extraction of Vocal Fold Vibratory Patterns from High-Speed Digital Imaging. J. Voice 2010, 24, 21–29. [Google Scholar] [CrossRef] [Green Version]
- Elidan, G.; Elidan, J. Vocal folds analysis using global energy tracking. J. Voice 2012, 26, 760–768. [Google Scholar] [CrossRef]
- Yan, Y.; Du, G.; Zhu, C.; Marriott, G. Snake based automatic tracing of vocal-fold motion from high-speed digital images. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 593–596. [Google Scholar]
- Andrade-Miranda, G.; Godino-Llorente, J. Glottal Gap tracking by a continuous background modeling using inpainting. Med Biol. Eng. Comput. 2017, 55, 2123–2141. [Google Scholar] [CrossRef]
- Demeyer, J.; Dubuisson, T.; Gosselin, B.; Remacle, M. Glottis segmentation with a high-speed glottography: A fully automatic method. In Proceedings of the 3rd Advanced Voice Function Assessment International Workshop, Madrid, Spain, 18–20 May 2009. [Google Scholar]
- Osma-Ruiz, V.; Godino-Llorente, J.I.; Sáenz-Lechón, N.; Fraile, R. Segmentation of the glottal space from laryngeal images using the watershed transform. Comput. Med Imaging Graph. 2008, 32, 193–201. [Google Scholar] [CrossRef] [Green Version]
- Cerrolaza, J.J.; Osma, V.; Villanueva, A.; Godino, J.I.; Cabeza, R. Full-AutoMatic Glottis Segmentation with active shape Models. In Proceedings of the 7th international workshop, Models and Analysis of Vocal Emissions for Biomedical Applications (MAVEBA), Florence, Italy, 25–27 August 2011; Volume 9, pp. 35–38. [Google Scholar]
- Karakozoglou, S.Z.; Henrich, N.; D’Alessandro, C.; Stylianou, Y. Automatic glottal segmentation using local-based active contours and application to glottovibrography. Speech Commun. 2012, 54, 641–654. [Google Scholar] [CrossRef]
- Ko, T.; Ciloglu, T. Automatic segmentation of high speed video images of vocal folds. J. Appl. Math. 2014, 2014, 16. [Google Scholar]
- Schenk, F.; Urschler, M.; Aigner, C.; Roesner, I.; Aichinger, P.; Bischof, H. Automatic glottis segmentation from laryngeal high-speed videos using 3D active contours. In Proceedings of the Medical Image Understanding and Analysis (MIUA), Egham, UK, 9–11 July 2014; pp. 111–116. [Google Scholar]
- Schenk, F.; Aichinger, P.; Roesner, I.; Urschler, M. Automatic high-speed video glottis segmentation using salient regions and 3D geodesic active contours. Ann. BMVA 2015, 2015, 1–15. [Google Scholar]
- Andrade-Miranda, G.; Godino-Llorente, J.I.; Moro-Velázquez, L.; Gómez-García, J.A. An automatic method to detect and track the glottal gap from high speed videoendoscopic images. BioMed. Eng. OnLine 2015, 14, 100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gloger, O.; Lehnert, B.; Schrade, A.; Volzke, H. Fully Automated Glottis Segmentation in Endoscopic Videos Using Local Color and Shape Features of Glottal Regions. IEEE Trans. Biomed. Eng. 2015, 62, 795–806. [Google Scholar] [CrossRef] [PubMed]
- Rao MV, A.; Krishnamurthy, R.; Gopikishore, P.; Priyadharshini, V.; Ghosh, P.K. Automatic Glottis Localization and Segmentation in Stroboscopic Videos Using Deep Neural Network. In Proceedings of the 19th Annual Conference of the International Speech Communication Association (INTERSPEECH), Hyderabad, India, 2–6 September 2018; pp. 3007–3011. [Google Scholar] [CrossRef] [Green Version]
- Mendez, A.; Alaoui, E.I.; García, B.; Ibn-Elhaj, E.; Ruiz, I. Glottal space segmentation from motion estimation and gabor filtering. In Proceedings of the Engineering in Medicine and Biology Society, EMBC 2009, Minneapolis, MN, USA, 2–6 September 2009; pp. 1–4. [Google Scholar]
- Alaoui, E.I.; Mendez, A.; Ibn-Elhaj, E.; Garcia, B. Keyframes detection and analysis in vocal folds recordings using hierarchical motion techniques and texture information. In Proceedings of the 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 653–656. [Google Scholar]
- Aghlmandi, D.; Faez, K. Automatic Segmentation of Glottal Space from Video Images Based on Mathematical Morphology and the hough Transform. Int. J. Electr. Comput. Eng. (IJECE) 2012, 2, 223–230. [Google Scholar] [CrossRef]
- Andrade-Miranda, G.; Sáenz-Lechón, N.; Osma-Ruiz, V.; Godino-Llorente, J.I. A New Approach for the Glottis Segmentation using snakes. In Proceedings of the International Conference on Bio-inspired Systems and Signal Processing (BIOSIGNALS), Barcelona, Spain, 11–14 February 2013. [Google Scholar]
- Chen, X.; Marriott, E.; Yan, Y. Motion saliency based automatic delineation of glottis contour in high-speed digital images. In Proceedings of the 12th IEEE Conference on Industrial Electronics and Applications (ICIEA), Siem Reap, Cambodia, 18–20 June 2017. [Google Scholar]
- Türkmen, H.I.; Albayrak, A.; Karsligil, M.E.; Kocak, I. Superpixel-based segmentation of glottal area from videolaryngoscopy images. J. Electron. Imaging 2017, 26, 61608. [Google Scholar]
- Naghibolhosseini, M.; Deliyski, D.; Zacharias, S.; Alarcon, A.; Orlikoff, R.F. Temporal Segmentation for Laryngeal High-Speed Videoendoscopy in Connected Speech. J. Voice 2018, 32, 256.e1–256.e12. [Google Scholar] [CrossRef]
- Kopczynski, B.; Strumillo, P.; Just, M.; Niebudek-Bogusz, E. Acoustic Based Method for Automatic Segmentation of Images of Objects in Periodic Motion: Detection of vocal folds edges case study. In Proceedings of the 2018 Eighth International Conference on Image Processing Theory, Tools and Applications (IPTA), Xi’an, China, 7–10 November 2018; pp. 1–6. [Google Scholar]
- Hamad, A.; Haney, M.; Lever, T.E.; Bunyak, F. Automated Segmentation of the Vocal Folds in Laryngeal Endoscopy Videos Using Deep Convolutional Regression Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Gómez, P.; Semmler, M.; Schützenberger, A.; Bohr, C.; Döllinger, M. Low-light image enhancement of high-speed endoscopic videos using a convolutional neural network. Med Biol. Eng. Comput. 2019, 57, 1451–1463. [Google Scholar] [CrossRef]
- Andrade-Miranda, G.; Godino-Llorente, J.I. ROI detection in high speed laryngeal images. In Proceedings of the 11th International Symposium on Biomedical Imaging (ISBI), Beijing, China, 29 April–2 May 2014; pp. 477–480. [Google Scholar]
- Birkholz, P. GlottalImageExplorer—An open source tool for glottis segmentation in endoscopic high-speed videos of the vocal folds. In Proceedings of the Studientexte zur Sprachkommunikation: Elektronische Sprachsignalverarbeitung, Leipzig, Germany, 2–4 March 2016. [Google Scholar]
- Andrade-Miranda, G. Analyzing of the Vocal Fold Dynamics Using Laryngeal Videos. Ph.D. Thesis, Universidad Politécnica de Madrid, Calle Ramiro de Maeztu, Madrid, Spain, 2017. [Google Scholar]
- Švec, J.G.; Šram, F.; Schutte, H.K. Videokymography in Voice Disorders: What to Look For? Ann. Otol. Rhinol. Laryngol. 2007, 116, 172–180. [Google Scholar] [CrossRef]
- Švec, J.G.; Schutte, H.K. Kymographic imaging of laryngeal vibrations. Curr. Opin. Otolaryngol. Head Neck Surg. 2012, 20, 458–465. [Google Scholar] [CrossRef]
- Kim, G.H.; Lee, Y.W.; Bae, I.H.; Park, H.J.; Wang, S.G.; Kwon, S.B. Usefulness of Two-Dimensional Digital Kymography in Patients with Vocal Fold Scarring. J. Voice 2018, 33, 906–914. [Google Scholar] [CrossRef]
- Powell, M.E.; Deliyski, D.D.; Zeitels, S.M.; Burns, J.A.; Hillman, R.E.; Gerlach, T.T.; Mehta, D.D. Efficacy of Videostroboscopy and High-Speed Videoendoscopy to Obtain Functional Outcomes From Perioperative Ratings in Patients With Vocal Fold Mass Lesions. J. Voice 2019. [Google Scholar] [CrossRef] [PubMed]
- Švec, J.G.; Schutte, H.K. Videokymography: High-speed line scanning of vocal fold vibration. J. Voice 1996, 10, 201–205. [Google Scholar] [CrossRef]
- Schutte, H.K.; Švec, J.G.; Sram, F. First results of clinical application of Videokymography. Laryngoscope 1998, 108, 1206–1210. [Google Scholar] [CrossRef] [PubMed]
- Švec, J.G.; Šram, F. Kymographic imaging of the vocal folds oscillations. In Proceedings of the 7th International Conference on Spoken Language Processing, Denver, CO, USA, 16–20 September 2002; Volume 2, pp. 957–960. [Google Scholar]
- Neubauer, J.; Mergell, P.; Eysholdt, U.; Herzel, H. Spatio-temporal analysis of irregular vocal fold oscillations: Biphonation due to desynchronization of spatial modes. J. Acoust. Soc. Am. 2001, 110, 3179–3192. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Westphal, L.; Childers, D. Representation of glottal shape data for signal processing. IEEE Trans. Acoust. Speech, Signal Process. 1983, 31, 766–769. [Google Scholar] [CrossRef]
- Lohscheller, J.; Eysholdt, U. Phonovibrography: Mapping high-speed movies of vocal fold vibrations into 2-D diagrams for visualizing and analyzing the underlying laryngeal dynamics. IEEE Trans. Med Imaging 2008, 27, 300–309. [Google Scholar] [CrossRef]
- Döllinger, M.; Lohscheller, J.; Švec, J.; McWhorter, A.; Kunduk, M. Support Vector Machine Classification of Vocal Fold Vibrations Based on Phonovibrogram Features. In Advances in Vibration Analysis Research; InTech: London, UK, 2011; Chapter 22; pp. 435–456. [Google Scholar]
- Li, L.; Galatsanos, N.P.; Bless, D. Eigenfolds: A new approach for analysis of vibrating vocal folds. In Proceedings of the 3rd International Symposium on Biomedical Imaging (ISBI), Washington, DC, USA, 7–10 June 2002. [Google Scholar]
- Yan, Y.; Ahmad, K.; Kunduk, M.; Bless, D. Analysis of Vocal-fold Vibrations from High-Speed Laryngeal Images Using a Hilbert Transform-Based Methodology. J. Voice 2005, 19, 161–175. [Google Scholar] [CrossRef]
- Zhang, Y.; Jiang, J.J.; Tao, C.; Bieging, E.; MacCallum, J.K. Quantifying the complexity of excised larynx vibrations from high-speed imaging using spatiotemporal and nonlinear dynamic analyses. Chaos Interdiscip. J. Nonlinear Sci. 2007, 17, 1–10. [Google Scholar] [CrossRef]
- Unger, J.; Meyer, T.; Herbst, C.; Fitch, W.; Döllinger, M.; Lohscheller, J. Phonovibrographic wavegrams: Visualizing vocal fold kinematics. J. Acoust. Soc. Am. 2013, 133, 1055–1064. [Google Scholar] [CrossRef]
- Sakakibara, K.I.; Imagawa, H.; Kimura, M.; Yokonishi, H.; Tayama, N. Modal analysis of vocal fold vibrations using laryngotopography. In Proceedings of the 11th Annual Conference of the International Speech Communication Association (INTERSPEECH), Makuhari, Japan, 26–30 September 2010; pp. 917–920. [Google Scholar]
- Chen, G.; Kreiman, J.; Alwan, A. The glottaltopogram: A method of analyzing high-speed images of the vocal folds. Comput. Speech Lang. 2014, 28, 1156–1169. [Google Scholar] [CrossRef]
- Andrade-Miranda, G.; Henrich, N.; Godino-llorente, J.I. Synthesizing the motion of the vocal folds using optical flow based techniques. Biomed. Signal Process. Control 2017, 34, 25–35. [Google Scholar] [CrossRef]
- Timcke, R.; Von Leden, H.; Moore, P. Laryngeal vibrations: Measurements of the glottic wave. I. The normal vibratory cycle. Arch. Otolaryngol. 1958, 68, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Herbst, C.; Unger, J.; Herzel, H.; Švec, J.; Lohscheller, J. Phasegram Analysis of Vocal Fold Vibration Documented With Laryngeal High-speed Video Endoscopy. J. Voice 2016, 30, 771.e1–771.e15. [Google Scholar] [CrossRef] [PubMed]
- Ammar, H. Optical flow based waveform for the assessment of the vocal fold vibrations. Australas. Phys. Eng. Sci. Med. 2018, 42, 91–119. [Google Scholar] [CrossRef]
- Ahmad, k.; Yan, Y.; Bless, D. Vocal fold vibratory characteristics in normal female speakers from high-speed digital imaging. J. Voice 2012, 26, 239–253. [Google Scholar] [CrossRef]
- Patel, R.R.; Forrest, K.; Hedges, D. Relationship Between Acoustic Voice Onset and Offset and Selected Instances of Oscillatory Onset and Offset in Young Healthy Men and Women. J. Voice 2017, 31, 389.e9–389.e17. [Google Scholar] [CrossRef] [Green Version]
- Petermann, S.; Kniesburges, S.; Ziethe, A.; Schützenberger, A.; Döllinger, M. Evaluation of Analytical Modeling Functions for the Phonation Onset Process. Comput. Math. Methods Med. 2016, 2016, 10. [Google Scholar] [CrossRef] [Green Version]
- Schlegel, P.; Stingl, M.; Kunduk, M.; Kniesburges, S.; Bohr, C.; Döllinger, M. Dependencies and Ill-designed Parameters Within High-speed Videoendoscopy and Acoustic Signal Analysis. J. Voice 2018, 33, 811-e1. [Google Scholar] [CrossRef]
- Wurzbacher, T.; Schwarz, R.; Döllinger, M.; Hoppe, U.; Eysholdt, U.; Lohscheller, J. Model-based classification of nonstationary vocal fold vibrations. Model-based classification of nonstationary vocal fold vibrations. J. Acoust. Soc. Am. 2006, 120, 1012–1027. [Google Scholar] [CrossRef]
- Tsutsumi, M.; Isotani, S.; Pimenta, R.; Dajer, M.; Hachiya, A.; Tsuji, H.; Tayama, N.; Yokonishi, H.; Imagawa, H.; Yamauchi, A.; et al. High-speed Videolaryngoscopy: Quantitative Parameters of Glottal Area Waveforms and High-speed Kymography in Healthy Individuals. J. Voice 2017, 31, 282–290. [Google Scholar] [CrossRef]
- Döllinger, M.; Hoppe, U.; Hettlich, F.; Lohscheller, J.; Schuberth, S.; Eysholdt, U. Vibration parameter extraction from endoscopic image series of the vocal folds. IEEE Trans. Biomed. Eng. 2002, 49, 773–781. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, A.P.; Stewart, D.E.; Maciel, C.D.; Pereira, J.C.; Oliveira, S. Analysis of nonlinear dynamics of vocal folds using high-speed video observation and biomechanical modeling. Digit. Signal Process. 2012, 22, 304–313. [Google Scholar] [CrossRef]
- Ishizaka, K.; Flanagan, J.L. Synthesis of Voiced Sounds From a Two-Mass Model of the Vocal Cords. Bell Labs Tech. J. 1972, 51, 1233–1268. [Google Scholar] [CrossRef]
- Schwarz, R.; Döllinger, M.; Wurzbacher, T.; Eysholdt, U.; Lohscheller, J. Spatio-temporal quantification of vocal fold vibrations using high-speed videoendoscopy and a biomechanical model. J. Acoust. Soc. Am. 2008, 123, 2717–2732. [Google Scholar] [CrossRef] [PubMed]
- Wong, D.; Ito, M.; Cox, N.; Titze, I.R. Observation of perturbations in a lumped-element model of the vocal folds with application to some pathological cases. J. Acoust. Soc. Am. 1991, 89, 383–394. [Google Scholar] [CrossRef] [PubMed]
- Döllinger, M.; Gómez, P.; Patel, R.R.; Alexiou, C.; Bohr, C.; Schützenberger, A. Biomechanical simulation of vocal fold dynamics in adults based on laryngeal high-speed videoendoscopy. PLoS ONE 2017, 12, e0187486. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gómez, P.; Schützenberger, A.; Semmler, M.; Döllinger, M. Laryngeal Pressure Estimation With a Recurrent Neural Network. IEEE J. Transl. Eng. Health Med. 2019, 7, 1–11. [Google Scholar] [CrossRef]
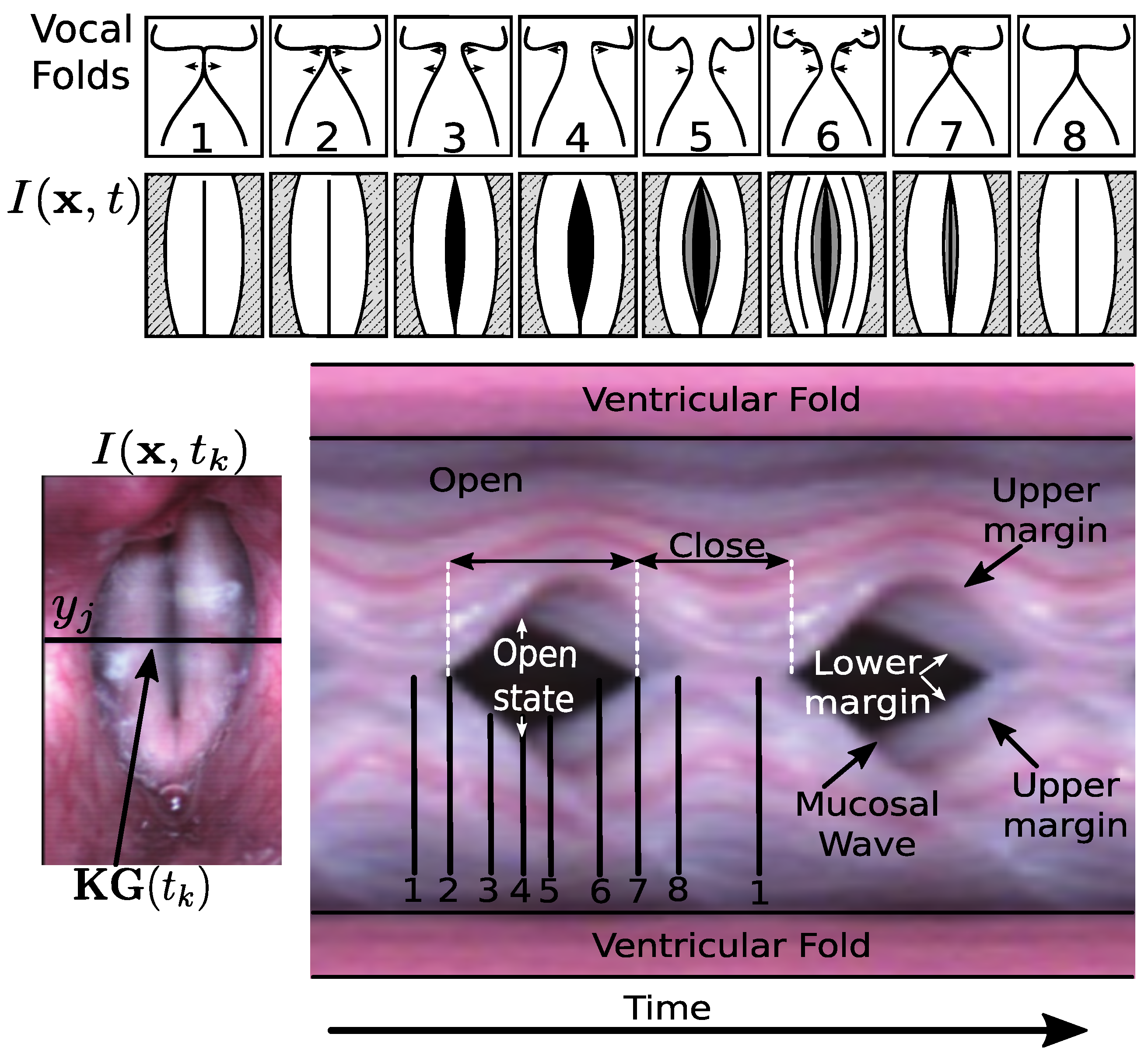
- Shaw, H.S.; Deliyski, D.D. Mucosal Wave: A Normophonic Study Across Visualization Techniques. J. Voice 2008, 22, 23–33. [Google Scholar] [CrossRef]
- Voigt, D.; Döllinger, M.; Eysholdt, U.; Yang, A.; Gürlen, E.; Lohscheller, J. Objective detection and quantification of mucosal wave propagation. J. Acoust. Soc. Am. 2010, 128, EL347–EL353. [Google Scholar] [CrossRef]
- Krausert, C.R.; Olszewski, A.E.; Taylor, L.N.; McMurray, J.S.; Dailey, S.H.; Jiang, J.J. Mucosal Wave Measurement and Visualization Techniques. J. Voice 2011, 25, 395–405. [Google Scholar] [CrossRef] [Green Version]
- Krasnodebska, P.; Szkielkowska, A.; Miaśkiewicz, B.; Wlodarczyk, E.; Domeracka-Kolodziej, A.; Skarżyński, H. Objective measurement of mucosal wave parameters in diagnosing benign lesions of the vocal folds. Logoped. Phoniatr. Vocol. 2018, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Kaneko, M.; Shiromoto, O.; Fujiu-Kurachi, M.; Kishimoto, Y.; Tateya, I.; Hirano, S. Optimal Duration for Voice Rest After Vocal Fold Surgery: Randomized Controlled Clinical Study. J. Voice 2017, 31, 97–103. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Zhang, Y.; Maytag, A.L.; Jiang, J.J. Quantitative Study for the Surface Dehydration of Vocal Folds Based on High-Speed Imaging. J. Voice 2015, 29, 403–409. [Google Scholar] [CrossRef] [PubMed]
- Regner, M.F.; Robitaille, M.J.; Jiang, J.J. Interspecies comparison of mucosal wave properties using high-speed digital imaging. Laryngoscope 2010, 120, 1188–1194. [Google Scholar] [CrossRef] [PubMed]
- Herbst, C.T.; Švec, J.G.; Lohscheller, J.; Frey, R.; Gumpenberger, M.; Stoeger, A.S.; Fitch, W.T. Complex vibratory patterns in an elephant larynx. J. Exp. Biol. 2013, 216, 4054–4064. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Elemans, C.P.H.; Rasmussen, J.H.; Herbst, C.T.; Düring, D.N.; Zollinger, S.A.; Brumm, H.; Srivastava, K.H.; Svane, N.; Ding, M.; Larsen, O.N.; et al. Universal mechanisms of sound production and control in birds and mammals. Nat. Commun. 2015, 6, 8978. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herbst, C.T. Biophysics of Vocal Production in Mammals. In Vertebrate Sound Production and Acoustic Communication; Springer International Publishing: Cham, Switzerland, 2016; pp. 159–189. [Google Scholar]
- Lindestad, P.A.; Södersten, M.; Merker, B.; Granqvist, S. Voice Source Characteristics in Mongolian “Throat Singing” Studied with High-Speed Imaging Technique, Acoustic Spectra, and Inverse Filtering. J. Voice 2001, 15, 78–85. [Google Scholar] [CrossRef]
- Borch, D.Z.; Sundberg, J.; Lindestad, P.A.; Thalén, M. Vocal fold vibration and voice source aperiodicity in ‘dist’ tones: A study of a timbral ornament in rock singing. Logoped. Phoniatr. Vocol. 2004, 29, 147–153. [Google Scholar] [CrossRef]
- Andrade-Miranda, G.; Bernardoni, N.H.; Godino-Llorente, J.I. A new technique for assessing glottal dynamics in speech and singing by means of optical-flow computation. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015; pp. 2182–2186. [Google Scholar]
- Gelin, L.; Haiqing, L.; Qian, H.; Zhen, J. Distinct Acoustic Features and Glottal Changes Define Two Modes of Singing in Peking Opera. J. Voice 2018, 33, 583-e9. [Google Scholar]
- Garnier, M.; Henrich, N.; Crevier-Buchman, L.; Vincent, C.; Smith, J.; Wolfe, J. Glottal behavior in the high soprano range and the transition to the whistle register. J. Acoust. Soc. Am. 2012, 131, 951–962. [Google Scholar] [CrossRef] [Green Version]
- Echternach, M.; Döllinger, M.; Sundberg, J.; Traser, L.; Richter, B. Vocal fold vibrations at high soprano fundamental frequencies. J. Acoust. Soc. Am. 2013, 133, EL82–EL87. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Echternach, M.; Dippold, S.; Richter, B. High-speed imaging using rigid laryngoscopy for the analysis of register transitions in professional operatic tenors. Logoped. Phoniatr. Vocol. 2014, 41, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Echternach, M.; Högerle, C.; Köberlein, M.; Schlegel, P.; Döllinger, M.; Richter, B.; Kainz, M.A. The Effect of Nasalance on Vocal Fold Oscillation Patterns During the Male Passaggio. J. Voice 2019. [Google Scholar] [CrossRef] [PubMed]
- Herbst, C.T.; Ternström, S.; Švec, J.G. Investigation of four distinct glottal configurations in classical singing—A pilot study. J. Acoust. Soc. Am. 2009, 125, EL104–EL109. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Herbst, C.T.; Hess, M.; Müller, F.; Švec, J.G.; Sundberg, J. Glottal Adduction and Subglottal Pressure in Singing. J. Voice 2015, 29, 391–402. [Google Scholar] [CrossRef] [PubMed]
- Braunschweig, T.; Flaschka, J.; Schelhorn-Neise, P.; Döllinger, M. High-speed video analysis of the phonation onset, with an application to the diagnosis of functional dysphonias. Med. Eng. Phys. 2008, 30, 59–66. [Google Scholar] [CrossRef] [PubMed]
- Volgger, V.; Felicio, A.; Lohscheller, J.; Englhard, A.S.; Al-Muzaini, H.; Betz, C.S.; Schuster, M.E. Evaluation of the combined use of narrow band imaging and high-speed imaging to discriminate laryngeal lesions. Lasers Surg. Med. 2017, 49, 609–618. [Google Scholar] [CrossRef]
- Kim, G.H.; Wang, S.G.; Lee, B.J.; Park, H.J.; Kim, Y.C.; Kim, H.S.; Sohn, K.T.; Kwon, S.B. Real-time dual visualization of two different modalities for the evaluation of vocal fold vibration–Laryngeal videoendoscopy and 2D scanning videokymography: Preliminary report. Auris Nasus Larynx 2017, 44, 174–181. [Google Scholar] [CrossRef]
- Sommer, D.E.; Tokuda, I.T.; Peterson, S.D.; Sakakibara, K.I.; Imagawa, H.; Yamauchi, A.; Nito, T.; Yamasoba, T. Estimation of inferior-superior vocal fold kinematics from high-speed stereo endoscopic data in vivo. J. Acoust. Soc. Am. 2014, 136, 3290–3300. [Google Scholar] [CrossRef]
- Luegmair, G.; Mehta, D.D.; Kobler, J.B.; Döllinger, M. Three-Dimensional Optical Reconstruction of Vocal Fold Kinematics Using High-Speed Video with a Laser Projection System. IEEE Trans. Med Imaging 2015, 34, 2572–2582. [Google Scholar] [CrossRef] [Green Version]
- Semmler, M.; Kniesburges, S.; Birk, V.; Ziethe, A.; Patel, R.; Döllinger, M. 3D Reconstruction of Human Laryngeal Dynamics Based on Endoscopic High-Speed Recordings. IEEE Trans. Med Imaging 2016, 35, 1615–1624. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.P.; Švec, J.G. Kinematic model for simulating mucosal wave phenomena on vocal folds. Biomed. Signal Process. Control 2019, 49, 328–337. [Google Scholar] [CrossRef]
- Salzmann, M.; Hartley, R.; Fua, P. Convex Optimization for Deformable Surface 3-D Tracking. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–20 October 2007; pp. 1–8. [Google Scholar] [CrossRef]
- Wedel, A.; Cremers, D. Stereo Scene Flow for 3D Motion Analysis, 1st ed.; Springer Publishing Company, Incorporated: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Munder, S.; Gavrila, D.M. An Experimental Study on Pedestrian Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1863–1868. [Google Scholar] [CrossRef] [PubMed]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Liang, C.W.; Juang, C.F. Moving object classification using local shape and HOG features in wavelet-transformed space with hierarchical SVM classifiers. Appl. Soft Comput. 2015, 28, 483–497. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Year | Enhancement | ROI | Glottal Gap Delimitation | Modalities |
|---|---|---|---|---|---|
| Booth and Childers [76] | 1979 | - | - | Subtraction and adaptive window | HSV |
| Wittenberg et al. [79] | 1995 | - | - | Region Growing | HSV |
| Larsson et al. [11] | 2000 | Contrast enhancement | Motion Estimation and manual ROI | Edge-Based | HSV |
| Palm et al. [80] | 2001 | - | Manual ROI | Parametric and Deformable Shape | SV |
| Marendic et al. [78] | 2001 | - | Manual ROI | Parametric Models | HSV |
| Yan et al. [81] | 2006 | - | Manual ROI | Thresholding Region Growing | HSV |
| Lohscheller et al. [73] | 2007 | - | Seed points | Region Growing | SV HSV |
| Skalski et al. [82] | 2008 | Nonlinear transformation | Subtraction | Geometric Models | HSV |
| Moukalled et al. [77] | 2009 | Histogram Thresholding | Manual , commissure | Parametric Models | HSV |
| Zhang et al. [83] | 2010 | Lagrange interpolation | Manual ROI | Differentiation Edge-Based | HSV |
| Elidan and Elidan [84] | 2012 | - | - | Parametric Models | SV |
| Yan et al. [85] | 2012 | - | Manual ROI | Parametric Models | HSV |
| Mehta et al. [71] | 2013 | - | Manual , commissure | Thresholding | HSV |
| Blanco et al. [72] | 2013 | - | Subtraction | Thresholding | HSV |
| Chen et al. [75] | 2013 | Reflection removal | Manual , commissure | Simplified Dynamic Programming | HSV |
| Pinheiro et al. [74] | 2014 | - | Seed points | Region Growing | HSV |
| Andrade-Miranda et al. [86] | 2017 | Specularity removal | Total intensity variation | Background modeling | HSV |
| Author | Year | Enhancement | ROI | Glottal Gap Delimitation | Modalities |
|---|---|---|---|---|---|
| Osma-Ruiz et al. [88] | 2008 | - | - | Watershed | SV |
| Mendez et al. [97] | 2009 | Anisotropic FFT-filter | Motion Estimation | Motion Estimation | SV |
| Alaoui et al. [98] | 2009 | - | Motion Estimation | Motion Estimation | SV |
| Cerrolaza et al. [89] | 2011 | - | - | Deformable Shape Models | SV |
| Aghlmandi and Faez [99] | 2012 | Nonlinear transformation | - | Morphological Operators | HSV |
| Karakozoglou et al. [90] | 2012 | CLAHE | Morphological ROI | Geometric Models | HSV |
| Andrade-Miranda et al. [100] | 2013 | Anisotropic Thresholding | - | Parametric Models | SV |
| Ko and Ciloglu [91] | 2014 | Reflectance modeling | Intensity variation | Gaussin Mixture Models | HSV |
| Andrade-Miranda et al. [94] | 2015 | Nonlinear transformation | Total intensity variation | Watershed and Geometric Models | HSV |
| Gloger et al. [95] | 2015 | - | - | Training clasification | SV HSV |
| Schenk et al. [93] | 2015 | Color contrast stretching | Salient region | Geometric Models | HSV |
| Chen et al. [101] | Chen2017 | - | - | Saliency network | HSV |
| Türkmen et al. [102] | 2017 | Contrast enhancement | - | Superpixel-Based algorithm | HSV |
| Naghibolhosseini et al. [103] | 2018 | - | - | Gradient-based algorithm | HSV |
| Rao MV et al. [96] | 2018 | - | - | Deep Neural Network | SV |
| Kopczynski et al. [104] | 2018 | - | - | Adaptive thresholding GVG Spectrum | HSV |
| Hamad et al. [105] | 2019 | - | - | Deep Neural Network | SV |
| Author | Objective Assessment | Subjective Assessment | |
|---|---|---|---|
| Metrics | Baseline | ||
| Lohscheller et al. [73] | Tracking points | GT | 5 point-scale |
| Osma-Ruiz et al. [88] | Pratt | GT | - |
| Cerrolaza et al. [89] | PER | GT | - |
| Karakozoglou et al. [90] | PER | GT | 5 point-scale |
| Andrade-Miranda et al. [100] | Pratt | GT | - |
| Ko and Ciloglu [91] | MSE | GT, [81] | - |
| Pinheiro et al. [74] | GAW difference | GT | - |
| Andrade-Miranda et al. [94] | Pratt OCE | GT | 5 point-scale |
| Glover et al. [95] | DICE MAE | GT | - |
| Schenk et al. [92] | DICE | [73] | - |
| Turkmen et al. [102] | F-M, TNR, DICE MI, RI, OR | Active contours Region Growing | - |
| Andrade-Miranda et al. [86] | ARI, DICE, KAP, Pratt | GT, [73] [94] | 5 point-scale playback-based |
| Rao MV et al. [96] | DICE | GT | - |
| Hamad et al. [105] | IOU, RI, ACC DICE, HAD | GT | - |
| Author | Year | Playback | Dynamics |
|---|---|---|---|
| Timcke et al. | 1958 | Glottal Area Waveform (GAW) | Global |
| Westphal and Childers | 1983 | Glottal shape Data Representation (GSD) | Global |
| Švec and Schutte | 1996 | Videokymography (VKG) | Local |
| Palm et al. | 2001 | Vibration Profiles (VP) | Global |
| Neubauer et al. | 2001 | Empirical Orthogonal Eigenfunctions Analysis (EOF) | Global |
| Li et al. | 2002 | Eigenfolds Analysis (EFA) | Global |
| Yan et al. | 2005 | Hilbert Transform Analysis (HTA) | Global |
| Zhang et al. | 2007 | Two-Dimension Spatiotemporal Series Analysis (2D-STSA) | Global |
| Lohscheller et al. | 2007 | Vocal Folds Trajectories (VFT) | Local |
| Deliyski et al. | 2008 | Mucosal Wave Kymography (MKG) | Local |
| Lohscheller and Eysholdt | 2008 | Phonovibrogram (PVG) | Global |
| Sakakibara et al. | 2010 | Laryngotopography (LGT) | Global |
| Karakozoglou et al. | 2012 | Glottovibrogram (GVG) | Global |
| Unger et al. | 2013 | Phonovibrographic Wavegram (PVG-wavegram) | Global |
| Ikuma et al. | 2013 | Waveform Decomposition Analysis (WDA) | Global |
| Chen et al. | 2014 | Glottaltopogram (GTG) | Global |
| Herbst et al. | 2016 | Phasegram Analysis (PGAW) | Global |
| Andrade-Miranda et al. | 2017 | Glottal Optical Flow Waveform (GOFW) | Global |
| Andrade-Miranda et al. | 2017 | Optical Flow Kymogram (OFKG) | Local |
| Andrade-Miranda et al. | 2017 | Optical Flow Glottovibrogram (OFGVG) | Global |
| Kopczynski et al. | 2018 | Glottocorrelogram (GCG) | Global |
| Ammar | 2018 | Optical Flow Based Waveform (OFW) | Local |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andrade-Miranda, G.; Stylianou, Y.; Deliyski, D.D.; Godino-Llorente, J.I.; Henrich Bernardoni, N. Laryngeal Image Processing of Vocal Folds Motion. Appl. Sci. 2020, 10, 1556. https://doi.org/10.3390/app10051556
Andrade-Miranda G, Stylianou Y, Deliyski DD, Godino-Llorente JI, Henrich Bernardoni N. Laryngeal Image Processing of Vocal Folds Motion. Applied Sciences. 2020; 10(5):1556. https://doi.org/10.3390/app10051556
Chicago/Turabian StyleAndrade-Miranda, Gustavo, Yannis Stylianou, Dimitar D. Deliyski, Juan Ignacio Godino-Llorente, and Nathalie Henrich Bernardoni. 2020. "Laryngeal Image Processing of Vocal Folds Motion" Applied Sciences 10, no. 5: 1556. https://doi.org/10.3390/app10051556
APA StyleAndrade-Miranda, G., Stylianou, Y., Deliyski, D. D., Godino-Llorente, J. I., & Henrich Bernardoni, N. (2020). Laryngeal Image Processing of Vocal Folds Motion. Applied Sciences, 10(5), 1556. https://doi.org/10.3390/app10051556