Hessian with Mini-Batches for Electrical Demand Prediction


 , ,
, ,  ,
, 
Abstract
:1. Introduction
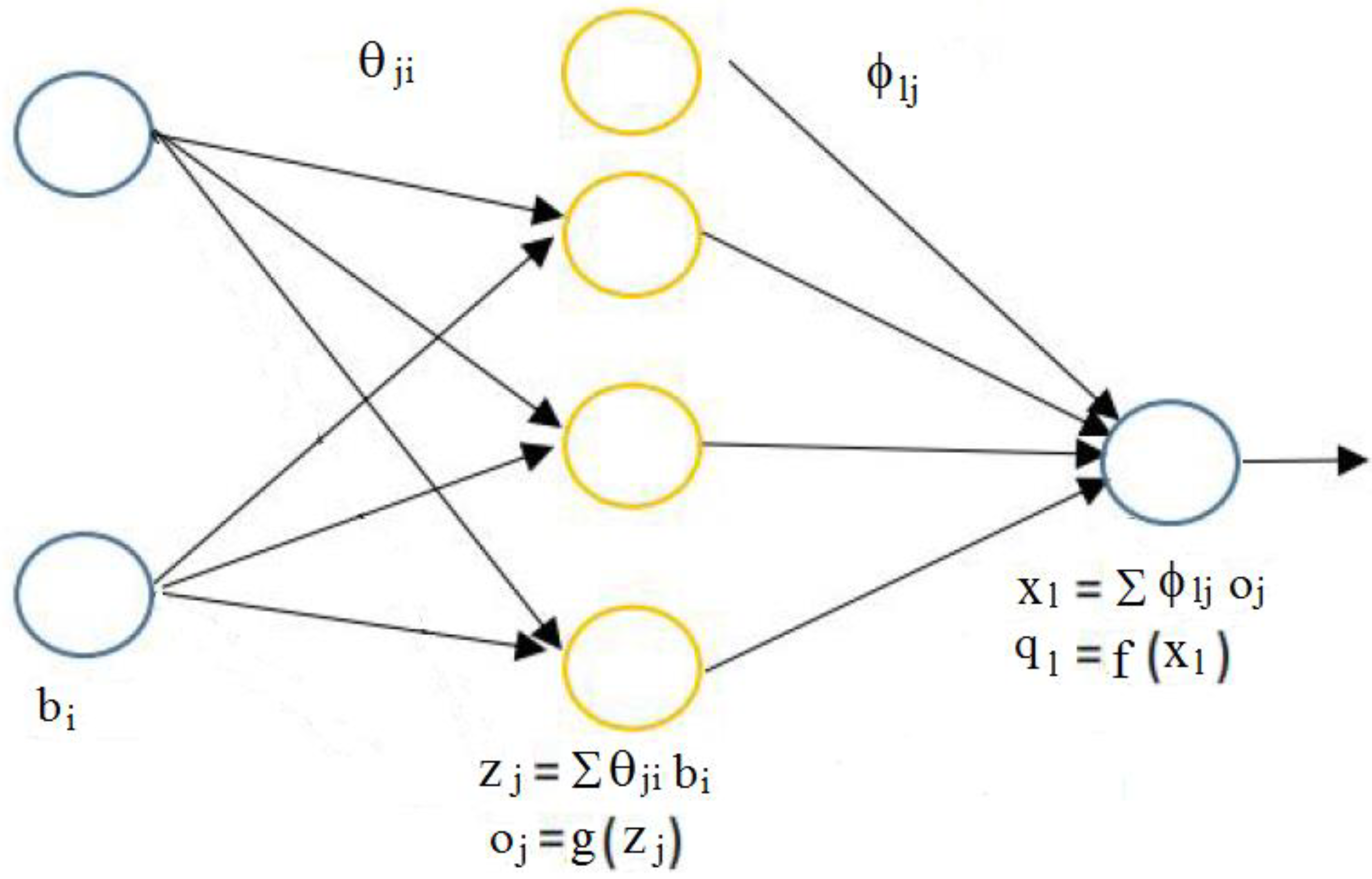
2. The Hessian for Neural Network Tuning
2.1. Design of the Hessian
2.2. Design of the Newton Method
3. Mini-Batches to Get Better Tuning of the Hessian
Design of the Mini-Batches
- (1)
- For each epoch.
- (2)
- Evaluate the mini-batches and tune each of the mini-batches with (24). These values are expressed in (15), (18).
- (3)
- Repeat for the next epoch.
- Most of the time, we do not need to utilize all data to reach an acceptable descent direction. A small number of mini-batches could be sufficient to estimate the target.
- Obtaining the Hessian using all the training data could have high computational cost.
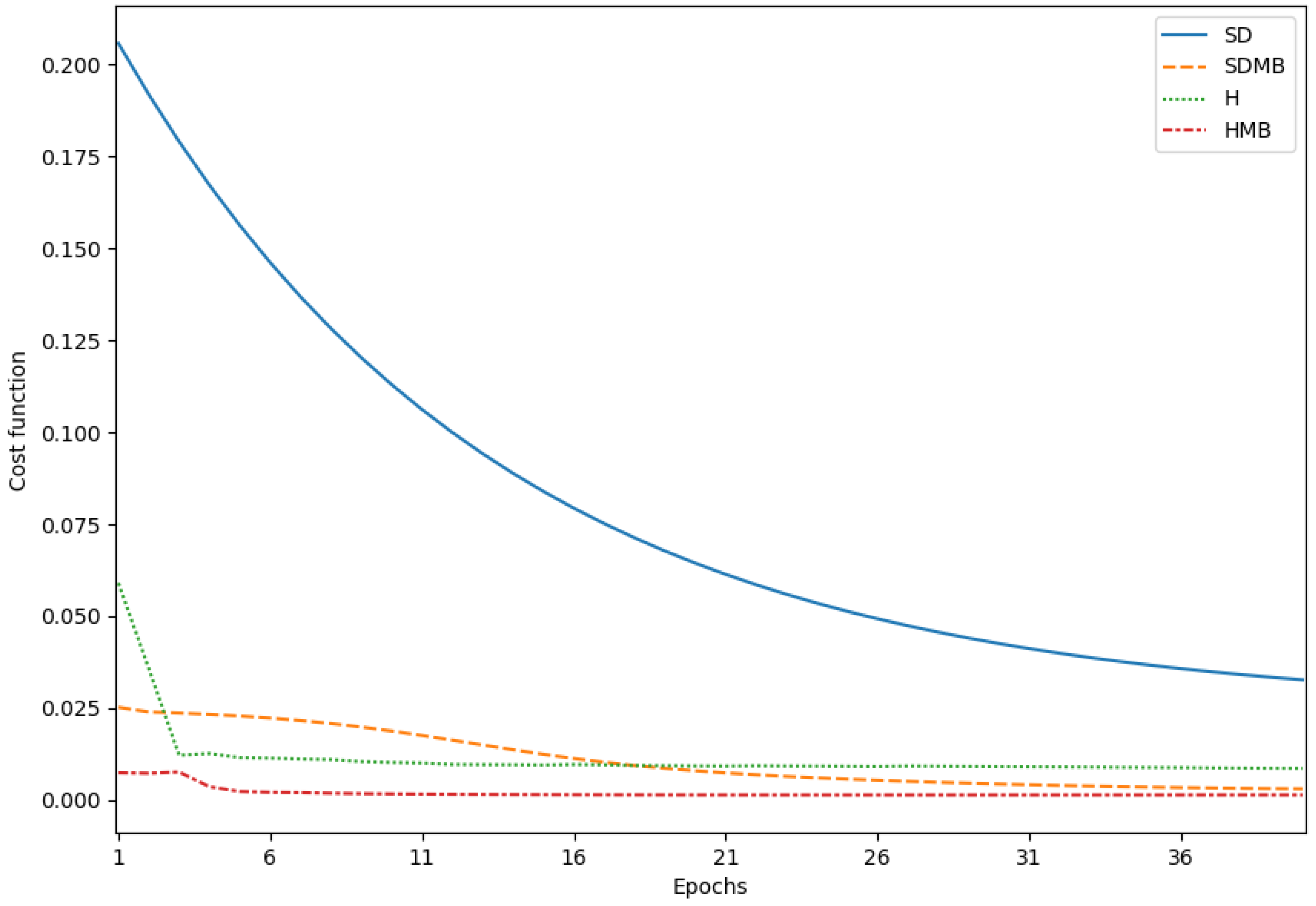
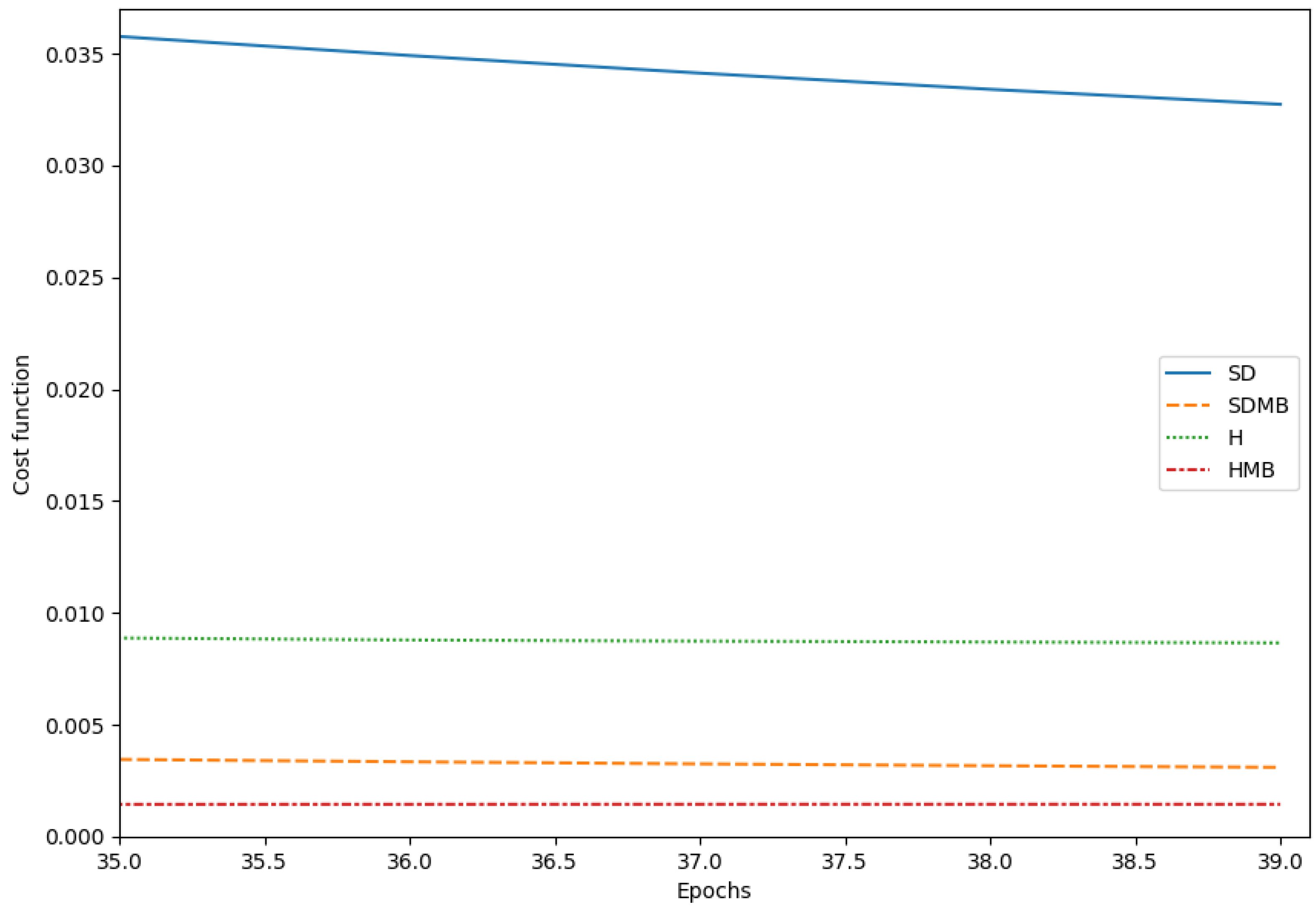
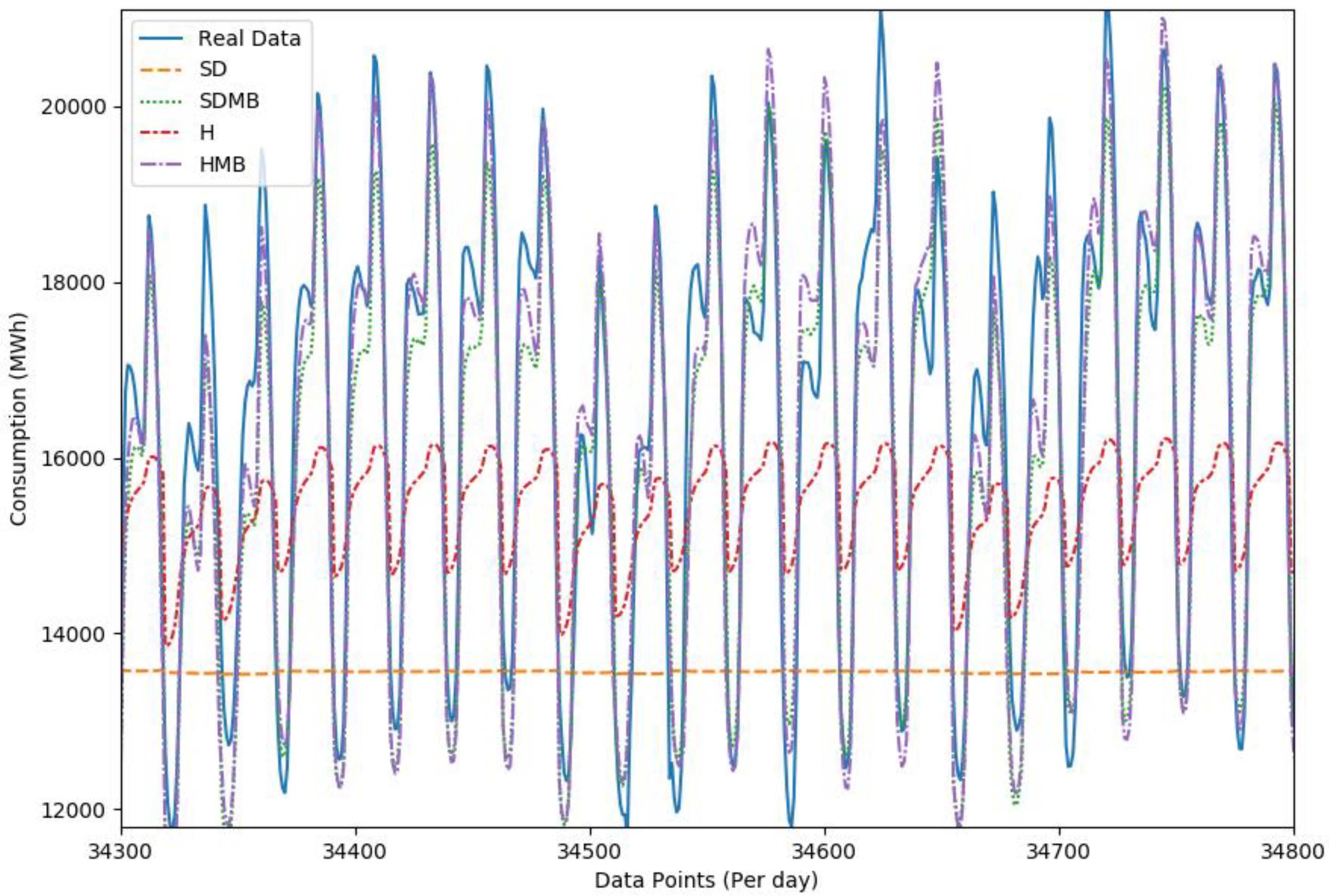
4. Comparisons
- The dry bulb temperature;
- The dew point;
- Hour of the day;
- Day of the week;
- A mark indicating if this is a free or a weekend day;
- Medium load of the past day;
- The load of the same hour, in the past day;
- Load of the same hour, the same day of the past week.
- Using the training data (), we trained the neural network for electrical demand prediction. After the training stage of the neural network, we used datapoints for the testing for each characteristic, yielding a matrix with dimensions ()
- The neural network had three layers—one input layer, one hidden layer, and one output layer. The input layer had eight neurons, the hidden layer had six neurons, and the output layer had one neuron.
- We initialized the scale parameters with random values between and ;
- We obtained the forward propagation;
- We obtained the cost map;
- We obtained the back propagation;
- We utilized the Hessian tuning.
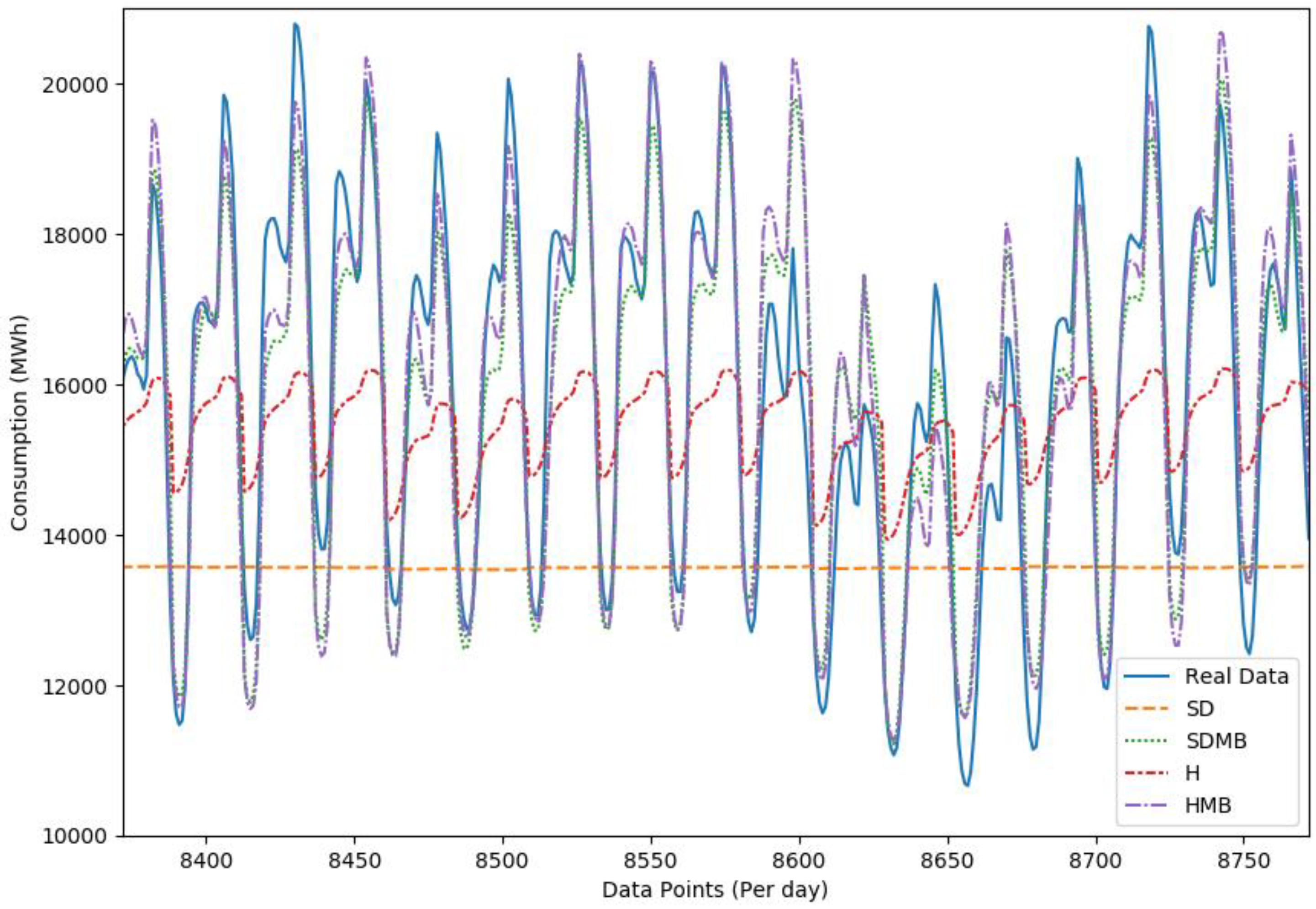
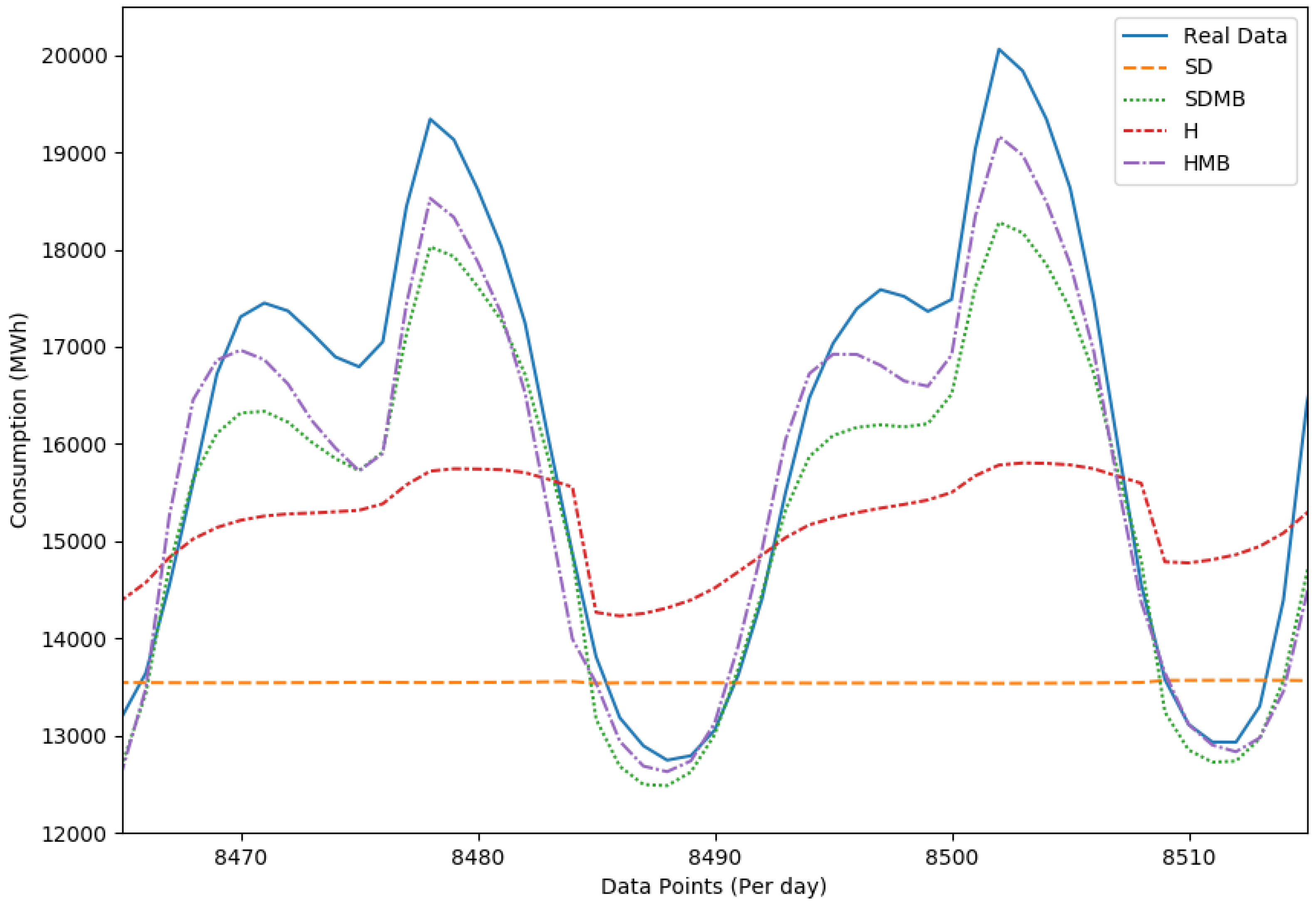
Results of the Comparison
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sadiq, M.; Shi, D.; Guo, M.; Cheng, X. Facial Landmark Detection via Attention-Adaptive Deep Network. IEEE Access 2019, 7, 181041–181050. [Google Scholar] [CrossRef]
- Wang, C.; Yao, H.; Liu, Z. An efficient DDoS detection based on SU-Genetic feature selection. Clust. Comput. 2019, 22, S2505–S2515. [Google Scholar] [CrossRef]
- Dinculeana, D.; Cheng, X. Vulnerabilities and Limitations of MQTT Protocol Used between IoT Devices. Appl. Sci. 2019, 9, 848. [Google Scholar] [CrossRef] [Green Version]
- Shi, F.; Chen, Z.; Cheng, X. Behavior Modeling and Individual Recognition of Sonar Transmitter for Secure Communication in UASNs. IEEE Access 2020, 8, 2447–2454. [Google Scholar] [CrossRef]
- Jia, B.; Hao, L.; Zhang, C.; Chen, D. A Dynamic Estimation of Service Level Based on Fuzzy Logic for Robustness in the Internet of Things. Sensors 2018, 18, 2190. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, C.; Yang, L.; Wu, Y.; Wu, Y.; Cheng, X.; Li, Z.; Liu, Z. Behavior Data Provenance with Retention of Reference Relations. IEEE Access 2018, 6, 77033–77042. [Google Scholar] [CrossRef]
- Chen, Y.; Luo, F.; Li, T.; Xiang, T.; Liu, Z.; Li, J. A Training-integrity Privacy-preserving Federated Learning Scheme with Trusted Execution Environment. Inf. Sci. 2020, 522, 69–79. [Google Scholar] [CrossRef]
- Jia, B.; Xu, H.; Liu, S.; Li, W. A High Quality Task Assignment Mechanism in Vehicle-Based Crowdsourcing Using Predictable Mobility Based on Markov. IEEE Access 2018, 6, 64920–64926. [Google Scholar] [CrossRef]
- Cheng, F.; Zhang, X.; Zhang, C.; Qiu, J.; Zhang, L. An adaptive mini-batch stochastic gradient method for AUC maximization. Neurocomputing 2018, 318, 137–150. [Google Scholar] [CrossRef]
- Konecny, J.; Liu, J.; Richtarik, P.; Takac, M. Mini-Batch Semi-Stochastic Gradient Descent in the Proximal Setting. IEEE J. Sel. Top. Signal Process. 2016, 10, 242–255. [Google Scholar] [CrossRef]
- Vakhitov, A.; Lempitsky, V. Learnable Line Segment Descriptor for Visual SLAM. IEEE Access 2019, 7, 39923–39934. [Google Scholar] [CrossRef]
- Yang, H.; Jia, J.; Wu, B.; Gao, J. Mini-batch optimized full waveform inversion with geological constrained gradient filtering. J. Appl. Geophys. 2018, 152, 9–16. [Google Scholar] [CrossRef]
- Peng, K.; Leung, V.C.M.; Huang, Q. Clustering Approach Based on Mini Batch Kmeans for Intrusion Detection System Over Big Data. IEEE Access 2018, 6, 11897–11906. [Google Scholar] [CrossRef]
- Tang, R.; Fong, S. Clustering big IoT data by metaheuristic optimized mini-batch and parallel partition-based DGC in Hadoop. Future Gener. Comput. Syst. 2018, 86, 1395–1412. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, C.; Zang, Y.; Li, J. Mini-batch algorithms with Barzilai-Borwein update step. Neurocomputing 2018, 314, 177–185. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, C.; Zhang, Z.; Li, J. Random Barzilai-Borwein step size for mini-batch algorithms. Eng. Appl. Artif. Intell. 2018, 72, 124–135. [Google Scholar] [CrossRef]
- Krishnasamy, G.; Paramesran, R. Hessian semi-supervised extreme learning machine. Neurocomputing 2016, 207, 560–567. [Google Scholar] [CrossRef]
- Liu, W.; Ma, T.; Tao, D.; You, J. HSAE: A Hessian regularized sparse auto-encoders. Neurocomputing 2016, 187, 59–65. [Google Scholar] [CrossRef]
- Liu, W.; Liu, H.; Tao, D. Hessian regularization by patch alignment framework. Neurocomputing 2016, 204, 183–188. [Google Scholar] [CrossRef]
- Xu, D.; Xia, Y.; Mandic, D.P. Optimization in Quaternion Dynamic Systems: Gradient, Hessian, and Learning Algorithms. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 249–261. [Google Scholar] [CrossRef] [Green Version]
- Annunziata, R.; Garzelli, A.; Ballerini, L.; Mecocci, A.; Trucco, E. Leveraging Multiscale Hessian-Based Enhancement with a Novel Exudate Inpainting Technique for Retinal Vessel Segmentation. IEEE J. Biomed. Health Inform. 2016, 20, 1129–1138. [Google Scholar] [CrossRef] [PubMed]
- Goncalves, L.; Novo, J.; Campilho, A. Hessian based approaches for 3D lung nodule segmentation. Expert Syst. Appl. 2016, 61, 1–15. [Google Scholar] [CrossRef]
- Rodrigues, L.C.; Marengoni, M. Segmentation of optic disc and blood vessels in retinal images using wavelets, mathematical morphology and Hessian-based multi-scalefiltering. Biomed. Signal Process. Control 2017, 36, 39–49. [Google Scholar] [CrossRef]
- Zhang, J.; Wan, Y.; Chen, Z.; Meng, X. Non-negative and local sparse coding based on l 2 -norm and Hessian regularization. Inf. Sci. 2019, 486, 88–100. [Google Scholar] [CrossRef]
- Attouch, H.; Peypouquet, J.; Redont, P. Fast convex optimization via inertial dynamics with Hessian driven damping. J. Differ. Equ. 2016, 261, 5734–5783. [Google Scholar] [CrossRef] [Green Version]
- Mesri, Y.; Khalloufi, M.; Hachem, E. On optimal simplicial 3D meshes for minimizing the Hessian-based errors. Appl. Numer. Math. 2016, 109, 235–249. [Google Scholar] [CrossRef]
- Petra, C.G.; Qiang, F.; Lubin, M.; Huchette, J. On efficient Hessian computation using the edge pushing algorithm in Julia. Optim. Methods Softw. 2018, 33, 1010–1029. [Google Scholar] [CrossRef]
- Xu, P.; Roosta, F.; Mahoney, M.W. Newton-typemethods for non-convex optimization under inexact Hessian information. Math. Program. 2019. [Google Scholar] [CrossRef] [Green Version]
- Feng, G.; Liu, W.; Li, S.; Tao, D.; Zhou, Y. Hessian-Regularized Multitask Dictionary Learning for Remote Sensing Image Recognition. IEEE Geosci. Remote Sens. Lett. 2019, 16, 821–825. [Google Scholar] [CrossRef]
- Liu, W.; Liu, H.; Tao, D.; Wang, Y.; Lu, K. Multiview Hessian regularized logistic regression for action recognition. Signal Process. 2015, 110, 101–107. [Google Scholar] [CrossRef] [Green Version]
- Ng, C.C.; Yap, M.H.; Costen, N.; Li, B. Wrinkle Detection Using Hessian Line Tracking. IEEE Access 2015, 3, 1079–1088. [Google Scholar] [CrossRef] [Green Version]
- Shi, C.; An, G.; Zhao, R.; Ruan, Q.; Tian, Q. Multiview Hessian Semisupervised Sparse Feature Selection for Multimedia Analysis. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1947–1961. [Google Scholar] [CrossRef]
- Liu, P.; Xiao, L. A Novel Generalized Intensity-Hue-Saturation (GIHS) Based Pan-Sharpening Method with Variational Hessian Transferring. IEEE Access 2019, 7, 39923–39934. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, N.; Sun, D.; Toh, K.C. An efficient Hessian based algorithm for solving large-scale sparse group Lasso problems. Math. Program. 2018, 179, 223–263. [Google Scholar] [CrossRef] [Green Version]
- Feng, G.; Liu, W.; Tao, D.; Zhou, Y. Hessian Regularized Distance Metric Learning for People Re-Identification. Neural Process. Lett. 2019, 50, 2087–2100. [Google Scholar] [CrossRef]
- Zhu, C.; Gates, D.A.; Hudson, S.R.; Liu, H.; Xu, Y.; Shimizu, A.; Okamura, S. Identification of important error fields in stellarators using the Hessian matrix method. Nucl. Fusion 2019, 59, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Quirynena, R.; Houska, B.; Diehl, M. Efficient symmetric Hessian propagation for direct optimal control. J. Process Control 2017, 50, 19–28. [Google Scholar] [CrossRef] [Green Version]
- Sun, T.; Yang, S. An Approach to Formulate the Hessian Matrix for Dynamic Control of Parallel Robots. IEEE/ASME Trans. Mechatron. 2019, 24, 271–281. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (Training) | (Testing) | (Training) | |
|---|---|---|---|
| SD | 0.306 | 0.107 | 0.032 |
| SDMB | 0.875 | 0.891 | 0.0031 |
| H | 0.298 | 0.257 | 0.0086 |
| HMB | 0.882 | 0.897 | 0.0014 |
| (Testing) | (Testing) | |
|---|---|---|
| SD | 2396.78 MWh | 16.54% |
| SDMB | 699.39 MWh | 4.85% |
| H | 1888.61 MWh | 14.50% |
| HMB | 681.42 MWh | 4.77% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elias, I.; Rubio, J.d.J.; Cruz, D.R.; Ochoa, G.; Novoa, J.F.; Martinez, D.I.; Muñiz, S.; Balcazar, R.; Garcia, E.; Juarez, C.F. Hessian with Mini-Batches for Electrical Demand Prediction. Appl. Sci. 2020, 10, 2036. https://doi.org/10.3390/app10062036
Elias I, Rubio JdJ, Cruz DR, Ochoa G, Novoa JF, Martinez DI, Muñiz S, Balcazar R, Garcia E, Juarez CF. Hessian with Mini-Batches for Electrical Demand Prediction. Applied Sciences. 2020; 10(6):2036. https://doi.org/10.3390/app10062036
Chicago/Turabian StyleElias, Israel, José de Jesús Rubio, David Ricardo Cruz, Genaro Ochoa, Juan Francisco Novoa, Dany Ivan Martinez, Samantha Muñiz, Ricardo Balcazar, Enrique Garcia, and Cesar Felipe Juarez. 2020. "Hessian with Mini-Batches for Electrical Demand Prediction" Applied Sciences 10, no. 6: 2036. https://doi.org/10.3390/app10062036
APA StyleElias, I., Rubio, J. d. J., Cruz, D. R., Ochoa, G., Novoa, J. F., Martinez, D. I., Muñiz, S., Balcazar, R., Garcia, E., & Juarez, C. F. (2020). Hessian with Mini-Batches for Electrical Demand Prediction. Applied Sciences, 10(6), 2036. https://doi.org/10.3390/app10062036