1. Introduction
Many Side Channel Analysis attacks have succeeded in breaking the secret keys analyzing power trace(s) generated from devices. However, there are many assumptions and limitations on these attacks. Some of them exploit as many power traces as needed to recover secrets. In addition, others have proposed methods to recover secrets from overall power trace(s) but not their exact location on the power trace from which each bit of secrets have been recovered.
One of the well known approaches is to find the reference window and apply a peak detecting algorithm [
1,
2]. However, the success of this approach heavily depends on the selection of a “good” reference window and the performance of peak detecting algorithms since we cannot search for all the windows in polynomial time. Therefore we need an automated approach that is feasible in polynomial time and does not require human intervention to succeed. Side channel analysis with machine learning has gained much interest [
3,
4,
5,
6].
Our work suggests a new approach to finding keys in a Bayesian approach. Our contributions on Side channel analysis and signal processing are as follows:
We exploit only one single power trace and recover the secret.
We suggest the methods to compute the probability of locations from which the secret came and find out global optimal solutions in a Monte Carlo approach.
We suggest the methodology that is more robust than ad-hoc attacks in the presence of noise.
In correlation analysis [
2,
7,
8,
9,
10,
11], a set of power traces is used to find a correlation between the power trace and the key guess. Our method assumes weaker power of an attacker where a chance of acquiring more than one power trace is slight. Analyses with clustering methods [
12,
13,
14] are researched. Recently, horizontal attacks [
7] have been succeeding with clustering algorithms [
15,
16]. These attacks exploiting clustering algorithms and horizontal attacks have so far fixed the dimension (length) of the segment/subsignal of power trace as
when treating segments. However, when treating time series, dimension of data segments have to be chosen with careful concern. There is no guarantee that operations are executed with an exact period of
. Our work does not assume the operations are executed periodically but rather estimates the start and end points of the operation executions. Moreover, we suggest method to extract feature from time series segments in different lengths.
2. Notation and Problem Definition
2.1. Notations
: The t-th signal (time location). Total signal length is T, so we simplify .
: The
t-th random variable which indicates whether
t-th point is change point or not. That is,
K: The number of change points. That is,
: The kth change point. As is the number of total change points, and trivially = 1 and .
: The hyperparameter that controls the number of change points
: The hyperparameter that controls the shape of probability density function
: The hyperparameter that controls the mean of segments.
V: The hyperparameter that controls the variance of segments.
: The set of parameters. That is, = {}.
D: The dimension of feature.
: The feature extracted from the kth segment with dimension of D.
: The cluster assigned to kth segment.
2.2. Problem Definition
Our goal is to divide the power trace into operation-relevant segments and assign clusters to each segment so that we can figure out which operation was executed. In
Figure 1 is shown whole process. Formally, we can define our goal as:
We defined each step, rather than one whole global model that segments time series and searches cluster (i.e., some function ) due to the high complexity of that model, if it exists.
2.2.1. Change Point Detection
We have found from the power trace that there is an idle period or a piece-wise constant between operations of binary exponentiation, square and multiplication. Exploring this period is the most important part of whole work since segments divided only by the exact locations of operations will have similar patterns. We can model solving change point detection problem (with their number unknown) [
17]. However we do not adopt reversible jump MCMC [
18,
19]. In this subproblem embedding the change point detection algorithm, we only find idle periods and incomplete segments are made. We then make complete(operation-relevant) segments by combining the incomplete segments in
Section 2.2.2. Reason behind dividing two steps is that first, we do not have any information about the key or the shape of power trace of each operation and change point detecting problem whose number of change points are not known is already complex enough to avoid putting detection of constants and unknown shapes together into model. For detecting piece-wise constants, we can define by Bayes’ theorem the posterior distribution of change points
,
and our goal as:
2.2.2. Merging Segments
As mentioned above, in this subproblem, we merge incomplete segments to complete segments whose start and end points indicate the start and end points of the operation. The goal here is building the merging function
as
Only merging but not splitting is allowed in function
, so
and
holds.
2.2.3. Extracting Features from Time Series Segments
It is known that previous correlation power analysis attacks have used power traces or parts of power traces that are cut in the same length. However, the lengths of power traces (or their parts) are not guaranteed to have the same length. Therefore, the model or algorithm for extracting information relevant to each operation must be capable of treating subsignals in different length. In this part, given the segments in different lengths, we extract the features that will be the input to the clustering part which needs fixed dimension.
where each row
is a feature vector of
k-th segment. The goal of this subproblem is building the feature extractor
that is capable of coping with the segments in different lengths
2.2.4. Clustering Features
The last step is clustering all the segments with features extracted. Clustering is an unsupervised machine learning approach that assigns each data point a cluster based on similarity (or distance). After all the segments are assigned the clusters, we can find the key exponent. Our goal is identifying three clusters of features. In general, if the number of clusters is not known, optimizing the number of clusters is required. From this point of view, the number of clusters should be carefully considered to obtain highly accurate performance, but we can easily put three on it since there are only three patterns we look for, which are square, multiplication and the idle period between operations. After we identify the clusters, it becomes a trivial problem to decide which operation or period is related to one of clusters.
3. Proposed Approach
3.1. Preprocessing
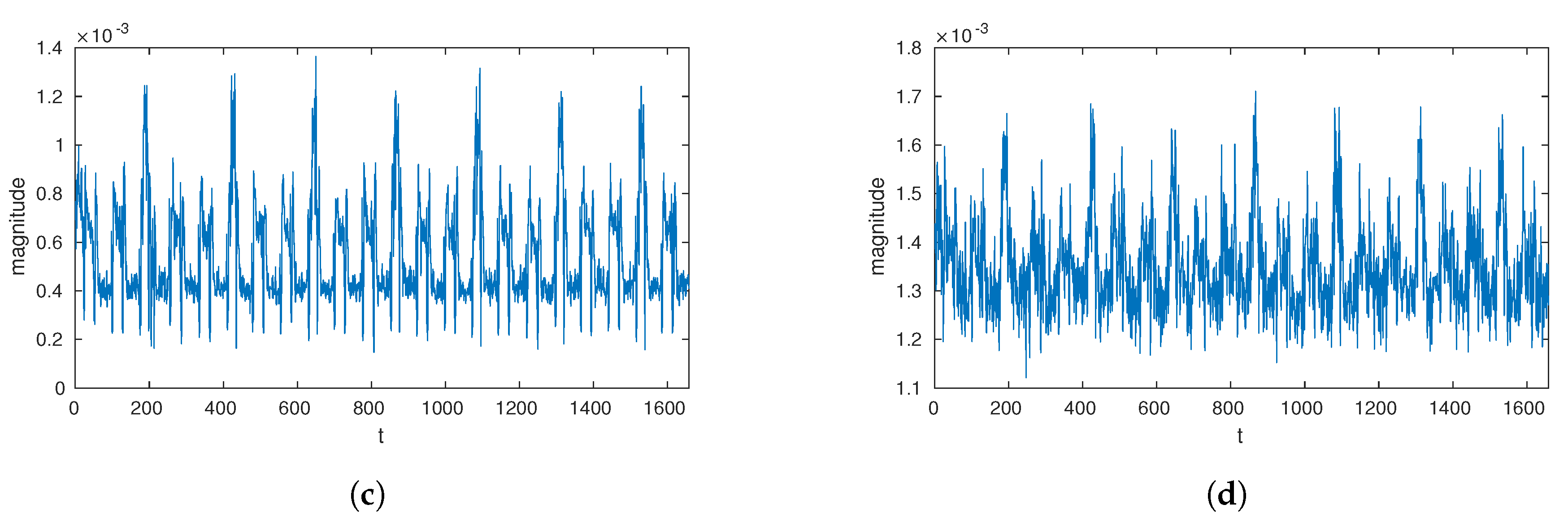
There are many countermeasures to side channel analysis including the random noise addition. In order to deal with the random noise addition, we sample each power trace with the median filter. The median filter will decrease the effect of noise and reflect the trend of power signal. We apply the median filter to the power trace. We use the stride size equal to the window length. As a result, we reduce the length of power trace to analyze. Since the magnitude of power trace is a positive value, we use the absolute value of the power trace:
where
is a length of the original power trace and
is window size.
Figure 2 shows the effect of preprocessing the power traces.
3.2. Change Point Detection
3.2.1. Posterior Distribution
As mentioned above, the model here detects the piecewise constant part from the time series.
where random variable
is a mean of time series between
and
and
. The likelihood that
is observed given
,
and
is
By conjugacy of the exponential family [
20], posterior distribution of
is also Gaussian.
, where
and
. If we plug the probability of
into Equation (10), we get by identification,
Therefore, we can get from Equation (11),
The trivial solution for this problem is to make every point as a change point, so that the sum of errors becomes least. In order to avoid this situation we have to model the number of change points
. We modelled the prior distribution to control the number of change points as Bernoulli distribution.
By Bayes’ theorem we can model the posterior distribution of random variable
by putting Equation (11) and (13) together as follows:
Joint distribution of
,
is needed since the evidence of the observation
is intractable to compute.
where energy function of
,
,
,
and
is an intractable normalizing constant.
3.2.2. Markov Chain Monte Carlo
We use Markov Chain Monte Carlo(MCMC) to find the global optimal solution [
21,
22] for the model we designed. In Reference [
19],
was also the random variable to infer and apply reversible jump MCMC to cope with changing dimension (the number of
s to estimate), but our work considers only
and replace
with
and simulate only for change points.
We detect the piecewise constants by computing the expectation of random variable
,
where
is a true mean of
and
is an Monte Carlo estimate of
when
The last part holds when
Instead of generating samples from the intractable posterior distribution
, we propose a function from which is easy to draw samples, namely proposal function(Metropolis-Hastings, Algorithm 1). We can think of two proposal functions regarding the property of change point detection problem. Given one sample, one of change points can be popped and two segments are merged or one change point is born and segment is split. Either case, this is reverting
,
, or
. The other proposal function is a swap between
.
| Algorithm 1 Metroplis Hastings |
procedureMH() ▹ posterior, proposal and initial sample, number of samples for n do if then else return
|
The proposal function for MCMC is succession of reverting and swapping with probability of
This proposal probability is reducible, when calculated in Metropolis-Hastings, to
since in reverting case the probability only depends on the length of the sample and in swapping case the number of change points does not change (
).
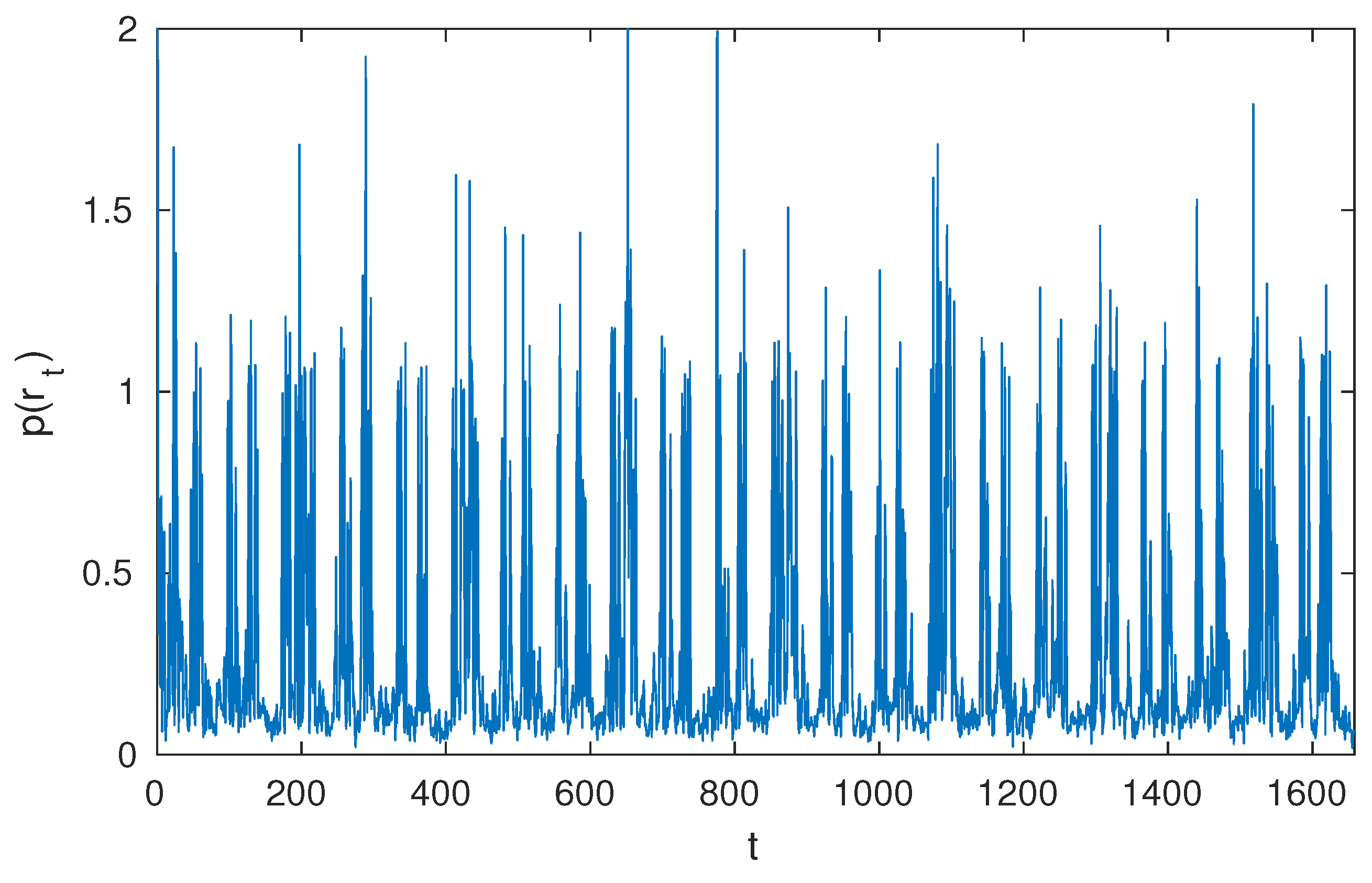
Figure 3 shows the
obtained from MCMC section. However this model only detects the piecewise constants, so non-constant parts (i.e., drastic changes) are all high in probability of being change points.
3.3. Merging Segments
In Reference [
23], it is shown that by controlling parameter and adopting various models, various goals can be achieved more than just detecting piecewise constants. However, we assume the least about the data that adopted merging segments part. The change points obtained from
Section 3.2 indicate the locations where mean of each segment is changed. Therefore, when operations are executed, it is likely that the operation part is split into many segments and there are more than one change points. We detect whether segments are from the operation part or the idle part and merge segments from the operation part. We consider the following two properties of the idle part.
Details for merging segments are on Algorithm 2 below.
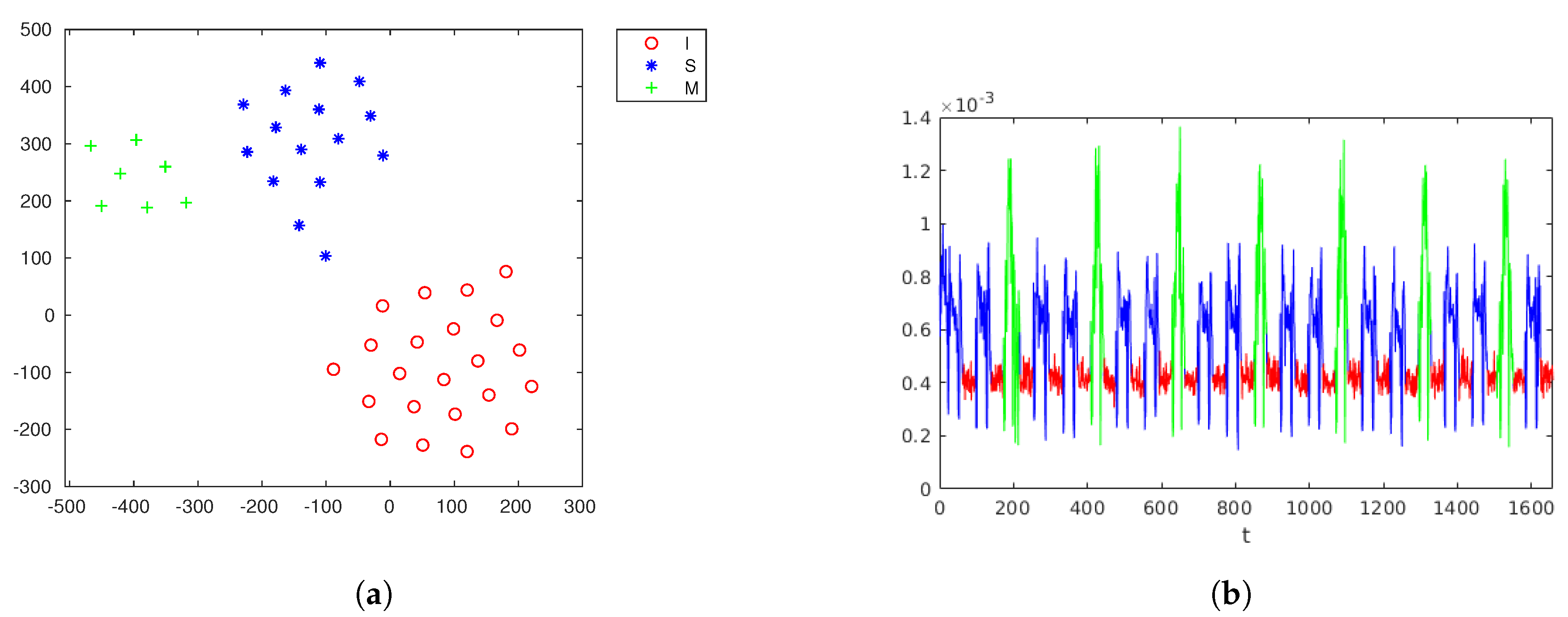
Figure 4 shows merged segments.
| Algorithm 2 Merge Segments |
procedureMerge() Initialize vector with kth element as Initialize vector with kth element as ▹ in descending order for do if then for do return
|
3.4. Extracting Features from Time Series Segments
In this part, we extract features of fixed dimension from the segments. That is, given the segment , we compute feature of fixed dimension . We applied two approaches to extract the features and this part is to be further researched.
3.4.1. Polynomial Least Square Coefficients
First approach we apply is polynomial fitting. Polynomial model has its form as below:
where
is a
dth parameter which describes the influence of
on
y and
. The solution to polynomial fitting with minimum least squared error exists in closed form:
where
n-by-
D matrix
is concatenation of
n data samples. Now that each segment is given, for segment
, let
and
. Then we can estimate
for each segment of time series and let it be a
D-by-1 feature of each segment as follows:
We visualize coefficients by reconstructing power traces in
Figure 5.
3.4.2. Histogram
The second approach is making a histogram out of each segment. Each histogram shares the same scale level of bins. The size of one bin is
. Once we normalize the histogram to sum up to 1, this gives a distribution of each segment.
3.5. Clustering Features
In this part, we finally make clusters of the features so that we can match each segment to the operation which has been executed when generating the segment. We apply K-means clustering algorithm. Based on the pre-defined distance measure and number of clusters, the K-means algorithm repeats until convergence assigning data points to cluster based on distance and computing the mean of each cluster [
20]. We assigned number of clusters K = 3 based on the number of operations (Square, Multiply and optionally idle period). For coefficients of
Section 3.4.1, Euclidean distance
is defined. For histogram coefficients of
Section 3.4.2, both Euclidean distance and symmertrized divergence
(only for normalized histogram) are defined as distance measures. The performance of K-means algorithm, however, is affected by the initial points. So we run K-means algorithm multiple times and evaluate each run [
24]. Only with data we used should we evaluate each run so that any other information is not reflected and result of K-means is evaluated fairly. We adopt Davies-Bouldin index(DB index) to evaluate each run and choose best performing clusters. Desirable clusters, with high inter-cluster distance and low intra-cluster distance, produce low DB index [
25].
Figure 6 shows recovering key exponent.
4. Experiments and Results
The experiments were conducted under the environment below:
The window size is 1000, is dependent on input data, which in our experiment is 1,657,401.
Hyperparameters were selected as follows:
Binary exponentiation of RSA 16-bit algorithm was executed on Samsung Galaxy S3 smartphone. Electromagnetic wave was sampled by oscilloscope. Sampling rate was 500 MS/s.
As mentioned, controls the number of change points. The best guess about the key exponents without any knowledge is a half of 1s and the other half of 0s. The number of change points will then be 48 (= 2×(16 + 8)) as bit of 0 leads to only square operation and bit of 1 leads to square and multiplication. The best guess for is the mean of the time series. Though and V should be optimized for the best inference, we have experimentally chosen the values of and V among the candidates that were sampled during MCMC process.
Our approach is evaluated with criteria below:
To which level of noise added and inserted to signal (Signal to Noise Ratio, SNR) does the approach work
The quality of clusters with external information
The first criterion shows the robustness of the approach to the noise whereas adding noise is often suggested as a countermeasure to the side channel analysis. For the second criterion, the external information (information not used for making clusters) we adopt is the very key exponent we want to estimate.
4.1. Comparison with Naive Peak Detection
This experiment focuses on comparing the proposed approach to naive correlation peak detecting method.
Figure 7a was obtained by computing covariance with the entire signal and sliding window size of 100. The most general sliding window is starting with the first part and sliding window size was selected as 100 in a ’naive’ way. As seen in
Figure 7b, peaks were found to satisfy two thresholds: covariance is positive and minimum distance between two nearest peaks is larger than 20 in time scale. Without these thresholds, too many irrelevant peaks were found. Our approach showed better performance in finding the locations of the executed operations and finding that of inserted noise.
Stems are drawn on
and peaks in
Figure 8a,b. Noise inserted are located on time series from
to
. The proposed method successfully finds out the location of noise as well as other operations whereas naive method does not successfully find out the location of operations nor the inserted noise.
4.2. Noise Level
We have experimented on 16 levels of noise. We incremented the ratio of the standard deviation of noise and the raw signal linearly by 0.2 up to 3.0.
Table 1 shows how consistent our work is when a different level of noise is added. From the table, we see that when the ratio of standard deviation is 1.8,
has changed. From that, the number of change point keeps changing although with some level of noise it remained 44. When the noise is added, the change point changes and sometimes its number also changes.
For comparing
, we have chosen only a standard deviation ratio of 0.2–1.6 since besides those, the numbers of change points have already been changed. Average absolute error on
compared to signal without noise is computed as
.
Table 2 shows that average absolute error is no more than 3, and especially for noise level 0.2, 0.4 and 0.6, the average absolute error is less than 1.
4.3. External Information
Next we compared clusters with external information, the actual key exponent. This is not a part of our approach since the actual key exponent is used. This part rather evaluates our approach to compare our estimate with the label.
Table 3 shows the the average accuracy of 100 runs of the K-means algorithm. We used polynomial coefficients to 3rd degree (
) and for the histogram we used
. Clustering polynomial least square coefficient features are not affected much by the noise level whereas clustering histogram features are relatively more affected by noise. We made a confusion matrix of actual key exponents and clusters assigned to segments. Accuracy of the cluster is defined as
where
is element of the confusion matrix.
| | Cluster Idle | Cluster Square | Cluster Multiply |
| Idle | | | |
| Square | | | |
| Multiply | | | |
4.4. Recovering Key Exponent
Our approach should be feasible without the external information. That is, we should be able to distinguish more accurate runs of clustering from the others.
Figure 9 shows the examples of desirable and undesirable runs of clustering. We sorted 100 DB indices in ascending order and picked 5, 10, and 15 lowest DB indices and corresponding clusters.
Table 4 shows the the average accuracy of 5, 10 and 15 runs of the K-means algorithm. We can see huge improvement in most of the cases, especially in the histogram features. This means that even without the external information, we can distinguish the good and bad clusters and find the key exponents.
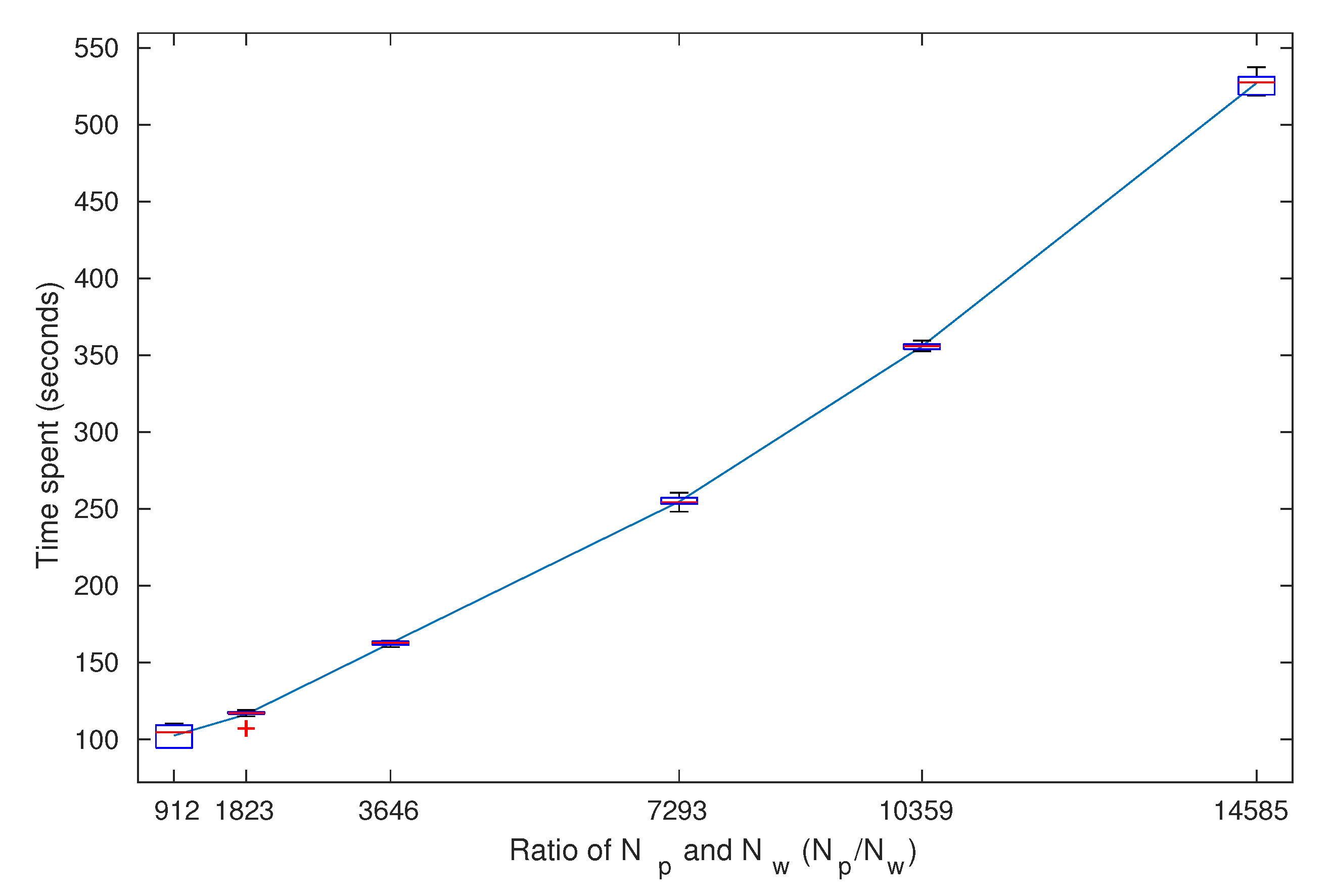
4.5. Data Scale
In this part, we empirically checked the time complexity of our approach. We have set the time series length
differently in each case. Then we checked each case 10 times and box plotted in
Figure 10. It shows that time spent in each case is linear to the time series length
T. So if the raw data are in a larger sampling rate or a larger key bit size, our approach takes longer to that ratio.
5. Discussion
For a longer key bit: If we can assume that the environment that generated the power trace is consistent during the whole time so that there exist certain patterns, we can apply our methods to the first part and extract some patterns from that part. For the rest, using the patterns we can find the key exponents faster. In this manner, we can solve the rest part of the problem in a supervised way, whereas our approach is a totally unsupervised way for finding a key. This will reduce the time spent on analysis even when the key length is relatively long.
Weakness: One major weakness is that our approach is based on finding piece-wise constant parts. If the idle part changes drastically with a magnitude bigger than or the idle part has another specific shape, we shall adopt a different model.
Further application: the proposed approach of ours can be applied to other related applications. A discrete power system is one of the examples [
26,
27]. Problems of systems with different power generation models and different assumptions can be solved with the proposed approach.
6. Conclusions
In this work, we suggested a probabilistic model-based side channel analysis. We modelled a change point detection problem to detect piecewise constants which are not directly related to finding keys, and merged incomplete segments to key-relevant complete segments. We solved this problem with an MCMC approach to find a global optimal solution. From each segment, we extracted features of a fixed dimension and assigned a cluster to each segment. We showed that this cluster is highly related to key exponent of power trace and this approach consistently works even in the presence of the noise. We evaluated our approach with criteria of noise-level-robustness and accuracy of the key. The source code for our work is available at
github.com/JeonghwanH/binEXP_CPD.
Author Contributions
Writing—original draft, J.H.; writing—review and editing, J.W.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Acknowledgments
This work was supported as part of Military Crypto Research Center(UD170109ED) funded by Defense Acquisition Program Administration(DAPA) and Agency for Defense Development(ADD).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Messerges, T.S.; Dabbish, E.A.; Sloan, R.H. Power analysis attacks of modular exponentiation in smartcards. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Worcester, MA, USA, 12–13 August 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 144–157. [Google Scholar]
- Witteman, M.F.; van Woudenberg, J.G.; Menarini, F. Defeating RSA multiply-always and message blinding countermeasures. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 14–18 February 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 77–88. [Google Scholar]
- Picek, S.; Heuser, A.; Jovic, A.; Ludwig, S.A.; Guilley, S.; Jakobovic, D.; Mentens, N. Side-channel analysis and machine learning: A practical perspective. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 4095–4102. [Google Scholar]
- Lerman, L.; Bontempi, G.; Markowitch, O. Power analysis attack: An approach based on machine learning. IJACT 2014, 3, 97–115. [Google Scholar] [CrossRef] [Green Version]
- Benadjila, R.; Prouff, E.; Strullu, R.; Cagli, E.; Dumas, C. Study of deep learning techniques for side-channel analysis and introduction to ASCAD database. In ANSSI, France & CEA, LETI, MINATEC Campus, France; 2018; Volume 22, Available online: https://eprint.iacr.org/2018/053.pdf (accessed on 20 February 2020).
- Hettwer, B.; Gehrer, S.; Güneysu, T. Applications of machine learning techniques in side-channel attacks: A survey. J. Cryptogr. Eng. 2019, 1–28. [Google Scholar] [CrossRef]
- Clavier, C.; Feix, B.; Gagnerot, G.; Roussellet, M.; Verneuil, V. Horizontal correlation analysis on exponentiation. In Proceedings of the International Conference on Information and Communications Security, Barcelona, Spain, 15–17 December 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 46–61. [Google Scholar]
- Bauer, A.; Jaulmes, E.; Prouff, E.; Wild, J. Horizontal and vertical side-channel attacks against secure RSA implementations. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 25 February–1 March 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1–17. [Google Scholar]
- Bauer, A.; Jaulmes, É. Correlation analysis against protected SFM implementations of RSA. In Proceedings of the International Conference on Cryptology in India, Mumbai, India, 7–10 December 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 98–115. [Google Scholar]
- Clavier, C.; Feix, B.; Gagnerot, G.; Giraud, C.; Roussellet, M.; Verneuil, V. ROSETTA for single trace analysis. In Proceedings of the International Conference on Cryptology in India, Kolkata, India, 9–12 December 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 140–155. [Google Scholar]
- Walter, C.D. Sliding windows succumbs to Big Mac attack. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Paris, France, 14–16 May 2001; Springer: Berlin/Heidelberg, Germany, 2001; pp. 286–299. [Google Scholar]
- Specht, R.; Heyszl, J.; Kleinsteuber, M.; Sigl, G. Improving non-profiled attacks on exponentiations based on clustering and extracting leakage from multi-channel high-resolution EM measurements. In Proceedings of the International Workshop on Constructive Side-Channel Analysis and Secure Design, Berlin, Germany, 13–14 April 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 3–19. [Google Scholar]
- Heyszl, J.; Ibing, A.; Mangard, S.; De Santis, F.; Sigl, G. Clustering algorithms for non-profiled single-execution attacks on exponentiations. In Proceedings of the International Conference on Smart Card Research and Advanced Applications, Berlin, Germany, 27–29 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 79–93. [Google Scholar]
- Batina, L.; Gierlichs, B.; Lemke-Rust, K. Differential cluster analysis. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems, Lausanne, Switzerland, 6–9 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 112–127. [Google Scholar]
- Nascimento, E.; Chmielewski, Ł. Applying horizontal clustering side-channel attacks on embedded ECC implementations. In Proceedings of the International Conference on Smart Card Research and Advanced Applications, Lugano, Switzerland, 13–15 November 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 213–231. [Google Scholar]
- Perin, G.; Chmielewski, Ł. A semi-parametric approach for side-channel attacks on protected RSA implementations. In Proceedings of the International Conference on Smart Card Research and Advanced Applications, Bochum, Germany, 4–6 November 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 34–53. [Google Scholar]
- Lavielle, M.; Moulines, E. Least-squares estimation of an unknown number of shifts in a time series. J. Time Ser. Anal. 2000, 21, 33–59. [Google Scholar] [CrossRef]
- Green, P.J. Reversible jump Markov chain Monte Carlo computation and Bayesian model determination. Biometrika 1995, 82, 711–732. [Google Scholar] [CrossRef]
- Lavielle, M.; Lebarbier, E. An application of MCMC methods for the multiple change-points problem. Signal Process. 2001, 81, 39–53. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer Science+ Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef] [Green Version]
- Hastings, W.K. Monte Carlo Sampling Methods Using Markov Chains and Their Applications; Oxford University Press: Oxford, UK, 1970. [Google Scholar]
- Lavielle, M. Optimal segmentation of random processes. IEEE Trans. Signal Process. 1998, 46, 1365–1373. [Google Scholar] [CrossRef] [Green Version]
- Arthur, D.; Vassilvitskii, S. k-means++: The advantages of careful seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2007; pp. 1027–1035. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Dassios, I.K.; Szajowski, K.J. A non-autonomous stochastic discrete time system with uniform disturbances. In Proceedings of the IFIP Conference on System Modeling and Optimization, Sophia Antipolis, France, 29 June–3 July 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 220–229. [Google Scholar]
- Dassios, I.K.; Szajowski, K.J. Bayesian optimal control for a non-autonomous stochastic discrete time system. Appl. Math. Comput. 2016, 274, 556–564. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}