Abstract
An efficient scheduling reduces the time required to process the jobs, and energy management decreases the service cost as well as increases the lifetime of a battery. A balanced trade-off between the energy consumed and processing time gives an ideal objective for scheduling jobs in data centers and battery based devices. An online multiprocessor scheduling multiprocessor with bounded speed (MBS) is proposed in this paper. The objective of MBS is to minimize the importance-based flow time plus energy (IbFt+E), wherein the jobs arrive over time and the job’s sizes are known only at completion time. Every processor can execute at a different speed, to reduce the energy consumption. MBS is using the tradition power function and bounded speed model. The functioning of MBS is evaluated by utilizing potential function analysis against an offline adversary. For processors m ≥ 2, MBS is O(1)-competitive. The working of a set of jobs is simulated to compare MBS with the best known non-clairvoyant scheduling. The comparative analysis shows that the MBS outperforms other algorithms. The competitiveness of MBS is the least to date.
1. Introduction
There are number of server farms equipped with hundreds of processors. The cost of energy used for cooling and running a machine for around three years surpasses the hardware cost of the machine [1]. Consequently, the major integrated chips manufacturers such as Intel and AMD are producing the dynamic speed scaling (DSS) enabled multiprocessor/multi-core machine and software such as Intel’s SpeedStep [2], which support the operating system in managing the energy by varying the execution speed of processors. A founder chip maker Tilera forecasted that the numbers of processors/cores will be doubled every eighteen months [3], which will increase the energy demand to a great extent. Data centers consume 1.5% of total electricity usage in United States [4]. To avoid such critical circumstances, the current issue in the scheduling is to attain the good quality of service by generating an optimal schedule of jobs and to save the energy consumption, which is a conflicting and complicated problem [5].
The power P consumed by a processor running at speed s is , where V is a voltage [6]. The traditional power function is ( for CMOS based chips [7,8]). There are two types of speed models: the first unbounded speed model, in which the processor’s speed range is, i.e., ; the second bounded speed model, in which the speed of a processor can range from zero to some maximum speed, i.e., . This DSS plays a vital role in energy management, where in a processor can regulate its speed to save energy. A few qualities of service metrics are slowdown, throughput, makespan, flow time and weighted flow time. At low speed, the processor finishes jobs slower and save energy, whereas at high speed, the processor finishes jobs faster but consumes more energy, as shown in Figure 1. To get a better quality of service and low energy consumption the objective should be to minimize the sum of flow time and energy; in case, if the importance or priority is attached, the objective should be to minimize the sum of importance-based flow time and energy. The objective of minimizing the IbFt+Ehas a natural explanation, as it can be considered in monetary terms [9].
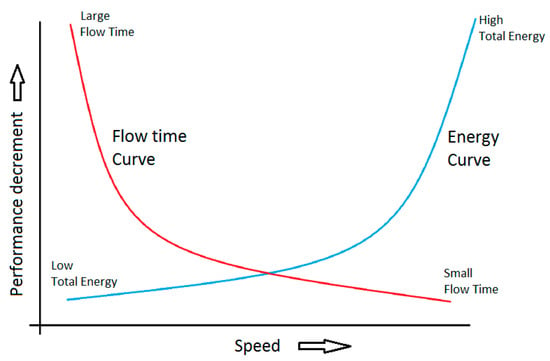
Figure 1.
Performance and speed curve.
In the multiprocessor systems, there is a requirement of three different policies: the first policy is job selection, which decides the next job to be executed on every processor; the second policy is speed scaling, which decides every processor’s execution speed at all time; the third policy is job assignment, which indicates that to which processor the new job should be assigned. In the c-competitive online scheduling algorithm, for each input the cost received is less than or equal to c times the cost of optimal offline algorithm [9]. Unlike non-clairvoyant scheduling, the size of job is unknown at arrival time, such as in UNIX operating system where jobs arrive with no information of processing requirement. Unlike online modes, in the offline mode, the whole job progression is known in advance. No online algorithm can attain a constant competitiveness with equal maximum speed to optimal offline algorithm [10].
Motwani et al. [10] commenced the study of the non-clairvoyant scheduling algorithms. Yao et al. inducted the theoretical study of speed scaling scheduling algorithm [11]. Yao et al. proposed an algorithm average rate heuristic (AVR) with a competitive ratio at most using the traditional power function. Koren et al. [12] presented an optimal online scheduling algorithm for a overloaded uniprocessor system with competitive ratio- for the objective of minimizing the throughput, where k is the importance ratio. The competitiveness of shortest remaining processing time (SRPT) for multiprocessor system is , where m is number of processors, n is total number of jobs and represents the ratio of minimum to maximum job size [13]. Kalyanasundaram et al. [14] presented the idea of resource augmentation. If the resources are augmented and, -speed p processors are used then the competitive ratio of Equi-partition lies between and [15]. Multilevel feedback queue, a randomized algorithm with n jobs is -competitive [16,17]. The first algorithm with non trivial guarantee is -competitive [18], where is the ratio of minimum to maximum job size. There are different algorithms proposed with different objectives over a span of time [19,20,21,22,23,24,25,26,27].
Chen et al. [19] proposed algorithms with different approximation bounds for processors with/without constraints on the maximum processor speed. The concept of merging dual objective of energy used and total flow time into single objective of energy used plus total flow time is proposed by Albers et al. [20]. Bansal et al. [21] proposed an algorithm, which uses highest density first (HDF) for the job selection with a traditional power function. Lam et al. [22] proposed a multiprocessor algorithm for homogeneous processors in which job assignment policy is a variant of round robin, the job selection. Random dispatching can provide -speed -competitive non-migratory algorithm [23]. Chan et al. [24] proposed an -competitive algorithm using sleep management for the objective of minimizing the flow time plus energy. Albers et al. [25] studied an offline problem in polynomial time and proposed a fully combitorial algorithm that relies on repeated maximum flow computation. Gupta et al. [26] proved that highest density first, weighted shortest elapsed time first and weighted late arrival processor sharing are not -speed -competitive for the objective of minimizing the weighted flow time even in fixed variable speed processors for heterogeneous multiprocessor setting. Chan et al. [27] studied an online clairvoyant sleep management algorithm scheduling with arrival-time-alignment (SATA) which is -speed -competitive for the objective of minimizing the flow time plus energy. For a detailed survey refer to [28,29,30,31,32,33,34].
In this paper, the problem of online non-clairvoyant (ON-C) DSS scheduling is studied and an algorithm multiprocessor with bounded speed (MBS) is proposed with an objective to minimize the IbFt+E. On the basis of potential function analysis MBS is O(1)- competitive. The notations used in this paper are mentioned in the Table 1.

Table 1.
Notations used.
The organization of the paper is as follows. In Section 2, some related non-clairvoyant algorithms are explained and their competitive values are compared to the proposed algorithm MBS. Section 3 presents the preliminary definition and information for the proposed work. In Section 4, the proposed algorithm, its flow chart and potential function analysis is presented. The processing of a set of jobs are simulated using MBS and the best identified algorithm to observe the working of MBS. Section 6 provides the conclusion and future scope of the work.
2. Related Work
Gupta et al. [35] gave an online clairvoyant scheduling algorithm GKP (proposed by Gupta, Krishnaswamy and Pruhs) for the objective of minimizing the weighted flow time plus energy. Under the traditional power function, GKP is -competitive without a resource augmentation for power heterogeneous processors. GKP uses highest density first (HDF) for the selection of jobs on each processor; the speed of any processor scales such that the power of a processor is the fractional weight of unfinished jobs; jobs are assigned in such a way that it gives the least increase in the projected future weighted flow time. Gupta et al. [35] used a local competitiveness analysis to prove their work. Fox et al. [36] considered the problem of scheduling the parallelizable jobs in the non-clairvoyant speed scaling settings for the objective of minimizing the weighted flow time plus energy and they used the potential function analysis to prove it. Fox et al. presented weighted latest arrival processor sharing with energy (WLAPS+E), which schedules the late arrival jobs and every job use the same number of machines proportioned by the job weight. WLAPS+E spares some machines to save the energy. WLAPS+E is -speed -competitive, where . Thang [37] studied the online clairvoyant scheduling problem for the objective of minimizing the weighted flow time plus energy in the unbounded speed model and using the traditional power function. Thang gave an algorithm (ALGThang) on unrelated machines and proved that ALGThang is -competitive. In AlGThang, the speed of any processor depends on the total weight of pending jobs on that machine, and any new job is assigned to a processor that minimizes the total weighted flow time.
Im et al. [38] proposed an ON-C scheduling algorithm SelfishMigrate-Energy (SM-E) for the objective of minimizing the weighted flow time plus energy for the unrelated machines. Using the traditional power function SM-E is -competitive. In SM-E, a virtual queue is maintained on every processor where the new or migrated jobs are added at tail; the jobs migrate selfishly until equilibrium is gained. Im et al. simulates sequential best response (SBR) dynamics and they migrates each job to the machine that is provided by the Nash equilibrium. The scheduling policy applied on every processor is a variant of weighted round robin (WRR), wherein the larger speed is allotted to jobs residing at the tail of the queue (like Latest Arrival Processor Sharing (LAPS) and Weighted Latest Arrival Processor Sharing (WLAPS)). Bell et al. [39] proposed an online deterministic clairvoyant algorithm dual-classified round robin (DCRR) for the multiprocessor system using the traditional power function. The motive of -competitive DCRR is to schedule the jobs so that they can be completed within deadlines using minimum energy, i.e., the objective is to maximize the throughput and energy consumption. In DCRR, the sizes and the maximum densities (= size/(deadline – release time)) of jobs are known and the classification of jobs depends on the size and the maximum density both. The competitive ratio of DCRR is high, as it considers the jobs with deadlines and using a variation of round robin with the speed scaling.
Azar et al. [40] gave an ON-C scheduling algorithm NC-PAR (Non-Clairvoyant for Parallel Machine) for the identical parallel machines, wherein the job migration is not permitted. Using traditional function NC-PAR is -competitive for the objective of minimizing the weighted flow time plus energy in unbounded speed model. In NC-PAR a global queue of unassigned jobs is maintained in First In First Out (FIFO) order. A new job is assigned to a machine, when a machine becomes free. In NC-PAR jobs are having uniform density (i.e., ) and the jobs are not immediately allotted to the processors at release time. The speed of a processor using NC-PAR is based on the total remaining weight of the active jobs. In non-clairvoyant model with known arbitrary weights no results are known [40].
An ON-C multiprocessor speed scaling scheduling algorithm MBS is proposed and studied against an offline adversary with an objective of minimizing IbFt+E. The speed of a processor using MBS is proportional to the sum of importance of all active jobs on that processor. In MBS, the processor’s maximum speed can be (i.e., the range of speed is from zero to ), whereas the processor’s maximum speed using Opt (Optimal algorithm) is , where m is number of processors and a constant. In MBS, a new job is assigned to an idle processor (if available) or to a processor having the minimum sum of the ratio of importance and executed size for all jobs on that processor; the policy for job selection is weighted/importance-based round robin, and each active job receives the processor speed equal to the ratio of its importance to the total importance of jobs on that processor. In this paper, the performance of MBS is analysed using a competitive analysis, i.e., the worst-case comparison of MBS and optimal offline scheduling algorithm. MBS is -speed, competitive, i.e., the value for competitive ratio c for , is 2.442; for , is 2.399; the detailed results for different values of m, and is shown in Table 2. The comparison of results is given along with the summary of results in Table 3.
Table 2.
Results of multiprocessor with bounded speed (MBS).
Table 3.
Summary of Results.
On the basis of the values mentioned in the Table 2, it can be observed that in proposed algorithm MBS if the number of processor increases then the speed ratio and competitive ratio increases. The data mentioned in Table 3 describe the competitive values of different scheduling algorithm. Some clairvoyant and non-clairvoyant algorithms competitive ratio are considered at , . The lower competitive value represents the better algorithm. The value of competitiveness is least for the proposed algorithm MBS.
3. Definitions and Notations
An ON-C job scheduling on a multiprocessor using speed bounded setting is considered, where the jobs arrive over time, the job’s importance/weight are known at release time and the size of a job is revealed only after the job’s completion. Processor’s speed using Opt can vary dynamically from 0 to the maximum speed i.e., . The nature of jobs is sequential as well as unrestricted pre-emption is permitted without penalty. The traditional power function is considered, where a fixed constant. If s is the processor’s speed then a processor executes s unit of work per unit time. An active job j has release time lesser than the current time t, and it is not completely executed. The flow time of job j is the time duration since j released and until it is completed. The total importance-based flow time F is . Amortized analysis is used for algorithms where an occasional operation is very slow, but most of the other operations are faster. In amortized analysis, we analyse a sequence of operations and guarantee a worst case average time which is lower than the worst case time of a particular expensive operation.
4. Methodology
In this study, the amortized potential function analysis of the objective is used to examine the performance of the proposed algorithm. Amortized analysis is a worst-case analysis of a sequence of operations—to obtain a tighter bound on the overall or average cost per operation in the sequence than is obtained by separately analyzing each operation in the sequence. The amortized potential method, in which we derive a potential function characterizing the amount of extra work we can do in each step. This potential either increases or decreases with each successive operation, but cannot be negative. The objective of study is to minimize the total IbFt+E, denoted by G = F + E. It reflects that the target is to minimize the quality of service and energy consumed. The input to the problem is the set of jobs I. A scheduler generates the schedule S of jobs in I. The total energy consumption E for the scheduling is . Let Opt be an optimal offline algorithm such that for any job sequence I, IbFt+E of Opt is minimized among all schedule of I. The notations used in MBS are mentioned in the Table 1. Any online algorithm ALG is said to be c-competitive for c ≥ 1, if for all job sequences I and any input the cost incurred is never greater than c times the cost of optimal offline algorithm Opt, and the following inequality is satisfied:
The traditional power function is utilized to simulate the working of the proposed algorithm and compare the effectiveness by comparing with the available best known algorithm. The jobs are taken of different sizes and the arrival of jobs is considered in different scenario to critically examine the performance of the proposed algorithm. Different parameters (such as IbFt, IbFt+E, speed of processor and speed growth) are considered to evaluate the algorithm.
5. An -Competitive Algorithm
An ON-C multiprocessor scheduling algorithm multiprocessor with bounded speed (MBS) is explained in this section. The performance of MBS is observed by using potential function analysis, i.e., the worst-case comparison of MBS with an offline adversary Opt. The competitiveness of MBS is with an objective to minimize the IbFt+E for m processors with the highest speed .
5.1. Multiprocessor with Bounded Speed Algorithm: MBS
At time t, the processing speed of u adjusts to , where , and are constants. The importance of a job is uninformed and acknowledged only at release time . The policies considered for the multiprocessor scheduling MBS are as follows:
Job selection policy: The importance-based/weighted round robin is used on every processor.
Job assignment policy: a newly arrived job is allotted to an idle processor (if available) or to a processor having the minimum sum of the ratio of importance to the executed size for all jobs on that processor (i.e., ).
Speed scaling policy: The speed of every processor is scaled on the bases of the total importance of active jobs on that processor. Every active job on u obtains the fraction of speed:
i.e., or . The speed of any processor gets adjusted (re-evaluated) on alteration in total importance of active jobs on that processor. MBS is compared against an optimal offline algorithm Opt, using potential function analysis. The principal result of this study is stated in Theorem 1. The Algorithm 1 of MBS is given next and the flow chart for MBS is given in Figure 2.
| Algorithm 1: MBS (Multiprocessor with Bounded Speed) |
| Input: total m number of processors , NoAJ and the importance of all active jobs . Output: number of jobs allocated to every processor, the speed of all processors, at any time and execution speed share of each active job. Repeat until all processors become idle: 1. If any job arrives 2. if 3. allocate job to a idle processor u 4. otherwise, when 5. allocate job to a processor u with 6. 7. , where and is a constant value 8. Otherwise, if any job completes on any processor u and other active jobs are available for execution on that processor then 9. 10. , where and is a constant value 11. the speed received by any job , which is executing on a processor u, is 12. otherwise, processors continue to execute remaining jobs |
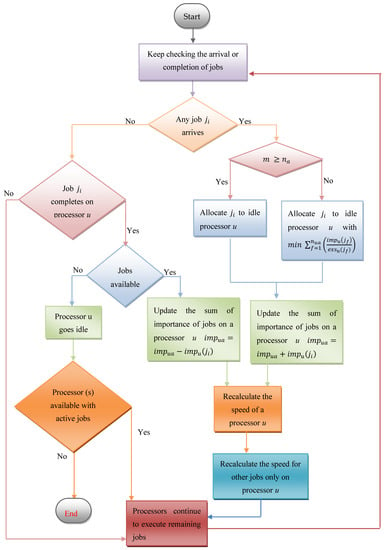
Figure 2.
Flow chart of the MBS scheduling algorithm.
Theorem 1.
When using more than two processors and each processor has the permitted maximum speed , MBS is c-competitive for the objective of minimizing the IbFt+E, where and .
5.2. Necessary Conditions to be Fulfilled
A potential function is needed to calculate the c-competitiveness of an algorithm. An algorithm is called c-competitive if at any time t, the sum of augmentation in the objective cost of algorithm and the modification in the value of potential is at the most c times the augmentation in the objective cost of the optimal adversary algorithm. A potential function is required to demonstrate that MBS is c-competitive. A c-competitive algorithm should satisfy the conditions:
Boundary Condition: The value of potential function is zero before the release of any job and after the completion of all jobs.
Job Arrival and Completion Condition: The value of potential function remains same on arrival or completion of a job.
Running Condition: At time when the above condition do not exist, the sum of the (rate of change) RoC of and the RoC of is at the most c times the RoC of .
5.3. Potential Function
An active job j is lagging, if . Since t is the instantaneous time, this factor is dropped from the rest of the analysis. For any processor u, let be a group of lagging jobs using MBS and these jobs are managed in the ascending order of latest time (when any job gets changed into lagging job). is a set of all lagging jobs on all m processors. Further, is the sum of the importance of lagging jobs on a processor u. Following this, is the sum of the importance of lagging jobs on all m processors. Our potential function for IbFt+E is the addition of all potential values of m processors.
are the coefficients ci of ji on processor u
MBS is analyzed per machine basis. Firstly, the verification of boundary condition: the value of is zero after finishing of all jobs and prior to release of any job on any processor. There will be no active job on any processor in both situations. Therefore, the boundary condition is true. Secondly, the verification of arrival and completion condition: at time t, on release of a new job in I, without execution is appended at end of I. is zero as . The coefficient of all other jobs does not change and remains unchanged. At the time of completion of a job , becomes zero and other coefficients of lagging jobs either remains unchanged or decreases, so, does not increase. Thus the arrival and completion criteria holds true. The third and last criterion to confirm is running condition, with no job arrival or completion.
According to previous discussion, for any processor u, let and be the alteration of IbFt+E in an infinitesimal period of time by MBS and Opt, respectively. The alteration of because of Opt and MBS in an infinitesimal period of time by u is and , respectively. The whole alteration in because of Opt and MBS in infinitesimal period of time by u is . As this is multiprocessor system therefore to bound the RoC of by Opt and MBS, the analysis is divided in two cases based on and , and then every case is further divided in three sub cases depending on whether and , afterwards each sub case is further divided in two sub cases depending on and , where , . The potential analysis is done on individual processor basis, the reason behind it is that all the processors will not face the same case at the same time; rather different processors may face same or different cases.
Lemma 1.
For the positive real numbers x, y, A and B, if holds then [2]:
Lemma 2.
If and
(a) ; (b)
Proof.
If then every processor executes not more than one job, i.e., every job is processed on individual processor.
(a) It is required to upper-bound for a processor u. To calculate the upper-bound, the worst-case is considered which occurs if Opt executes a job on u with the largest coefficient . At this time, increases at the rate of (because of Opt on u). The count of lagging jobs on some u may be only one.
Using Young’s inequality, Lemma 1 (Equation (6)) in (7) such that A = , B = , x = and y = we have:
(b) Next, it is required to upper-bound for a processor u. To compute the upper-bound, consider that a lagging job on u is executed at the rate of or , therefore, the change in is at the rate of .
As only one job executes on a processor, therefore and ,
□
Lemma 3.
If and
(a) ; (b)
Proof.
If then every processor executes not more than one job, i.e., every job is processed on individual processor.
(a) It is required to upper-bound for a processor u. To calculate the upper-bound, the worst-case is considered which occurs if Opt executes a job on u with the largest coefficient . At this time, increases at the rate of (because of Opt on u) where . The count of lagging jobs on any u may be only one.
(b) Next, it is required to upper-bound for a processor u. To compute the upper-bound, consider that a lagging job on u is executed at the rate of or , therefore the change in is at the rate of . ,
As only one job executes on a processor, therefore and ,
□
Lemma 4.
If and
(a) ; (b)
Proof. If then:
(a) It is required to upper-bound for a processor u. To calculate the upper-bound, the worst-case is considered which occurs if Opt is executing a job on u with the largest coefficient . At this time, increases at the rate of (because of Opt on u).
Using Young’s inequality, Lemma 1 (Equation (6)) in (12) such that A = , B = , x = and y = we have:
(b) Next, it is required to upper-bound for a processor u, to compute the upper-bound consider that a lagging job on u is executed at the rate of or , therefore the change in is at the rate of . To make the discussion straightforward, let , , and . (by using Equation (3):
□
Lemma 5.
If and
(a) ; (b)
Proof.
If then:
(a) It is required to upper-bound for a processor u. To calculate the upper-bound, the worst-case is considered which occurs if Opt executes a job on u with the largest coefficient (as ). At this time, increases at the rate of (because of Opt on u).
(b) Next, it is required to upper-bound for a processor u. To compute the upper-bound, consider that a lagging job on u is executed at the rate of or , therefore the change in is at the rate of . To make the discussion uncomplicated, let , , , and . Let z < be the largest integer such that . (using Equation (3)):
□
Lemma 6. At all time t, when does not comprise discrete alteration , where . Assume that .
Proof.
The analysis is divided in two cases based on or , and then each case is again alienated in three sub-cases depending on whether or and or , afterwards each sub-case is again alienated in two sub-cases depending on whether or , where and . As a job in MBS which is not lagging must be an active job in Opt,
□
Case I: When and , since we have and .
(a) If then the total RoC of Φ because of Opt and MBS is .
(using Equations (8) and (9))
(by using Equations (1) and (21))
(by using Equation (19))
(by using Equation (17))
(by using Equation (18))
(by using Equation (20))
Since and , we have
(by using Equation (23) in Equation (22))
Hence the running condition is fulfilled for , , , , .
(b) If then the total RoC of Φ because of Opt and MBS depends on since .
(by using Equation (8))
(by using Equations (1) and (24))
(by using Equation (17))
(by using Equation (19))
(by using Equation (18))
(by using Equations (18) and (23))
Hence the running condition is satisfied for , , , , .
Case II: When , , and .
(a) If then the total RoC of Φ because of Opt and MBS is .
(by using Equations (8) and (9))
(by using Equations (1) and (25))
(by using Equations (17) and (19))
(by using Equation (18))
(by using Equations (20) and (23))
Hence the running condition is fulfilled for , , , , .
(b) If then the total RoC of Φ because of Opt and MBS depends on since . (by using Equation (7))
(by using Equations (1) and (26))
(by using Equation (17))
(by using Equation (19))
(by using Equation (18))
(by using Equations (20) and (23))
Hence the running condition is satisfied for , , , , .
Case III: When , , and .
(a) If then the total RoC of Φ because of Opt and MBS is .
(by using Equations (10) and (11))
(by using Equations (1) and (27))
(by using Equations (17) and (19))
(by using Equations (29) and (28))
Hence the running condition is fulfilled for , , , , .
(b) If then the total RoC of Φ because of Opt and MBS depends on since .
(by using Equation (10))
(by using Equations (1) and (30))
Hence the running condition is satisfied if , , , , for .
Case IV: When and , since we have and .
If then total RoC of Φ because of Opt and MBS is .
(by using Equations (13) and (14))
(by using Equations (1) and (31))
(by using Equations (32) and (33))
(by using Equations (17) and (19))
(by using Equation (18))
(by using Equations (20) and (23))
Hence the running condition is fulfilled for , , , , .
(a) If then total RoC of Φ because of Opt and MBS depends on since .
(by using Equation (13))
(by using Equations (1) and (34))
(by using Equations (17) and (19))
(by using Equation (18))
(by using Equations (20) and (23))
Hence the running condition is satisfied for , , , , .
Case V: When and , and .
(a) If then the total RoC of Φ because of Opt and MBS is .
(by using Equations (13) and (14))
(by using Equations (1) and (35))
(by using Equations (36) and (33))
(by using Equations (17) and (19))
(by using Equation (18))
(by using Equations (20) and (23))
Hence the running condition is fulfilled for , , , , .
(a) If then total RoC of Φ due to Opt and MBS depends on since .
(by using Equation (13))
(by using Equations (1) and (37))
(by using Equations (17) and (19))
(by using Equation (18))
(by using Equations (20) and (23))
Hence the running condition is satisfied for , , , , .
Case VI: When and , and .
(a) If then total RoC of Φ because of Opt and MBS is .
(by using Equations (15) and (16))
(by using Equations (1) and (38))
(by using Equations (29) and (33))
(by using Equations (17) and (19))
(by using Equation (18))
(by using Equation (20))
Hence the running condition is fulfilled for , , , , .
(a) If then total RoC of Φ due to Opt and MBS depends on since .
(by using Equations (15))
(by using Equations (1) and (39))
(by using Equations (17) and (29))
(by using Equation (19))
(by using Equation (18))
(by using Equation (20))
Hence the running condition is satisfied for , , , , .
The analysis of all cases and sub cases in Lemma 6 prove that the first condition, running condition is fulfilled. Aggregating the discourse about all conditions job arrival and completion condition, boundary condition and Lemma 6, it is concluded that Theorem 1 follows. The competitive values of related algorithms and MBS on are shown in Table 3. Among all online clairvoyant and ON-C scheduling algorithms, the competitiveness of MBS is least, which reflects that the MBS outperforms other algorithms.
6. Illustrative Example
To observe the performance of MBS, a group of four processors and a set of seven jobs are considered. The best known result in the online non-clairvoyant scheduling algorithms is provided by the Azar et al. [40] in NC-PAR. NC-PAR is a super-constant lower bound on the competitive ratio of any deterministic algorithm even for fractional flow-time in the case of uniform densities. The processing of jobs using algorithms MBS and NC-PAR [40] is simulated and the results are stated in Table 4 as well as in Figure 3, Figure 4, Figure 5, Figure 6, Figure 7, Figure 8, Figure 9, Figure 10 and Figure 11. The jobs arrived along with their importance but the size of jobs was computed on the completion of jobs. The response time (Rt) is the time interval between the starting time of execution and arrival time of a job. The turnaround time is the time duration between completion time and arrival time of a job. Most of the jobs using MBS have lesser turnaround time than using NC-PAR. The Rt of the jobs using MBS is better than NC-PAR. In Figure 3 and Figure 4, the allocation and execution sequence of jobs on four processors is depicted with the help of triangles and rectangles using NC-PAR and MBS, respectively. As per the Figure 3 and Figure 4, the importance of the jobs in NC-PAR increased with time where as in MBS the importance remains constant during the life time of the jobs. It is clearly evident from the Figure 3 and Figure 4 that on any processor using NC-PAR at a time only one job has been executed, whereas using MBS the processor has been shared by more than one job. The hardware specifications are mentioned in the Table 5.
Table 4.
Job details and execution data using MBS and NC-PAR.
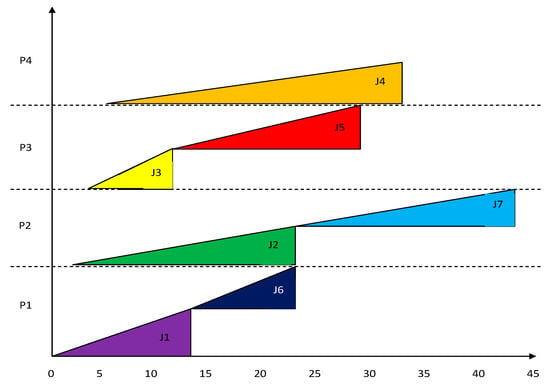
Figure 3.
Scheduling of jobs using NC-PAR.
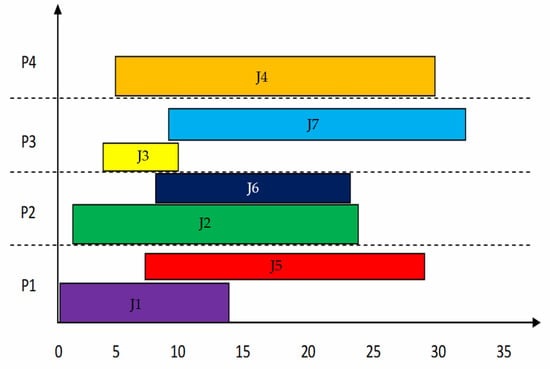
Figure 4.
Scheduling of jobs using MBS.
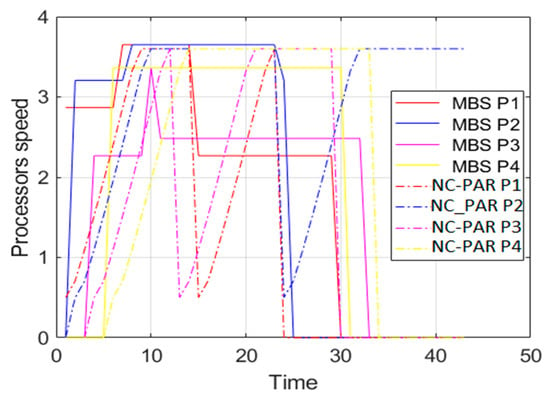
Figure 5.
Speed of processors using MBS and NC-PAR.
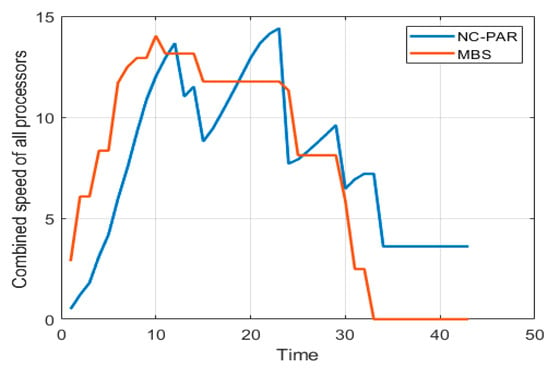
Figure 6.
Combined speed of all processors using MBS and NC-PAR.
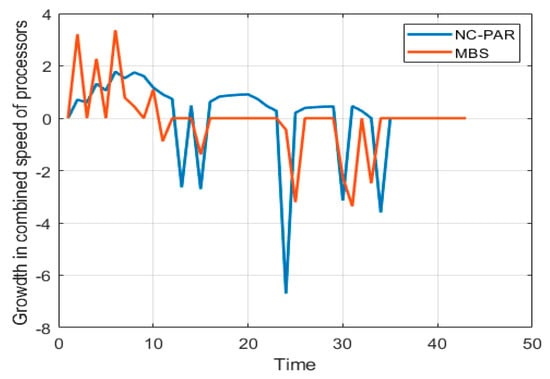
Figure 7.
Growth of combined speed of all processors using MBS and NC-PAR.
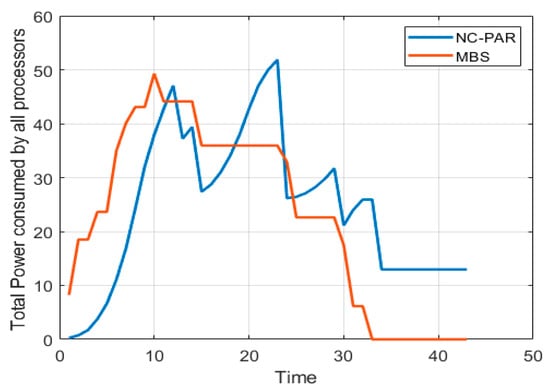
Figure 8.
Total power consumed by all processors using MBS and NC-PAR.
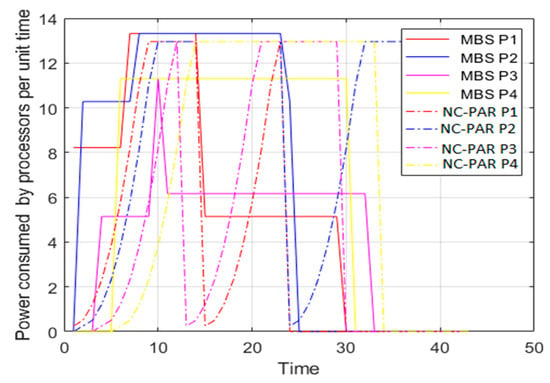
Figure 9.
Power consumed by processors using MBS and NC-PAR.
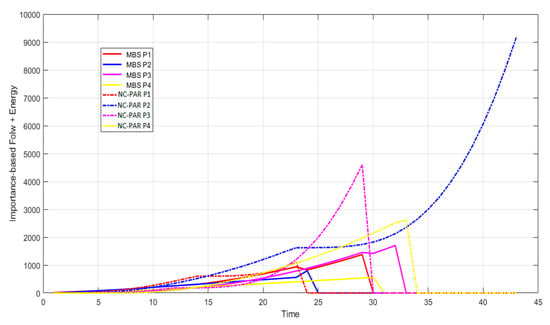
Figure 10.
Importance-based flow time + energy consumed using MBS and NC-PAR.
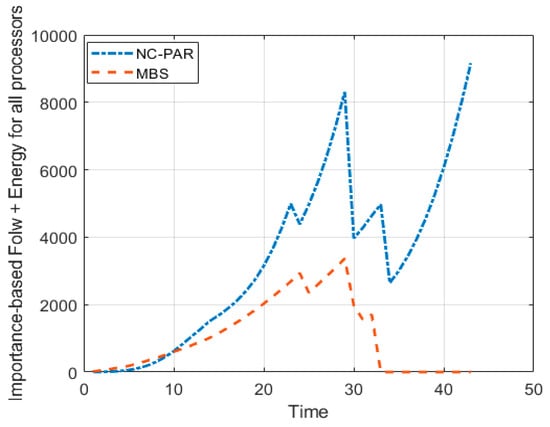
Figure 11.
Total importance-based flow time + energy consumed using MBS and NC-PAR.
Table 5.
Hardware specifications.
Figure 5 and Figure 6 present the speed of different processors and combined speed of all processors with respect to time using MBS and NC-PAR, respectively. As per the graphs of Figure 5, the speed of a processor using MBS goes high initially but later it reduces and most of the time the speed of processors using MBS is constant, but when processors executes jobs using NC-PAR the speed of processors have heavy fluctuations, which shows that some extra energy may be needed for such frequent fluctuation in NC-PAR. The graphs of the Figure 6 shows that the combined speed of processors using NC-PAR increased and decreased linearly whereas using MBS it increased and decreased stepwise. The count of local maxima and minima in the speed growth graphs (Figure 7) of NC-PAR is more than MBS. Therefore, not only individual processor’s speed but also the combined speed of all the processors is reflecting the heavy fluctuation in NC-PAR and varying-constant mixed behaviour of MBS.
In this simulation analysis the traditional power function is used and the value of α is 2. The processors are having the maximum limit of speed which is considered 3.6. The value of is considered for the analysis. The power consumed is square of the speed, i.e., proportional to the speed this fact can be viewed by comparing the graphs of Figure 5 and Figure 9. Figure 8, shows that initially MBS consumed more power but power consumption decreased with respect to increase in time, whereas in case of NC-PAR there is no fix pattern, but power consumption is higher most of the time than in MBS.
The graphs of Figure 10 demonstrate the objective of the algorithm (important based flow time plus energy). It reveals that except one processor P1, all other processor have lesser objective value, when these processors executed jobs by using MBS than NC-PAR. The combined objective of all processor is given in the Figure 11, which strengthen the previous observation of Figure 10 (the objective values using MBS is lesser than using NC-PAR). It can be concluded from the different observations and the Figure 11, that the algorithm MBS performs better than NC-PAR.
7. Conclusions and Future Work
To date, the problem of ON-C scheduling algorithms with an objective to minimize the IbFt+E for multiprocessor setting is studied less extensively. A scheduling algorithm multiprocessor with bounded speed (MBS) is proposed, which uses importance-based/weighted round robin (WRR) for job selection. MBS extends the theoretical study of an ON-C multiprocessor DSS scheduling problem with an objective to minimize the IbFt+E using the bounded speed model, where every processor’s maximum speed using MBS is and using offline adversary Opt is . The speed of any processor changes if there is a variation in the total importance of jobs on that processor. The competitiveness of MBS is against an offline adversary, using the potential function analysis and traditional power function. The performance of MBS is compared with best known algorithm NC-PAR [40]. A set of jobs and processors are used to simulate the working of MBS and NC-PAR. The average turnaround and response time of jobs, when they are executed by using MBS is lesser than NC-PAR. The speed scaling strategy and power consumption in MBS is better than NC-PAR. For all processors at any time, MBS provides the lesser value of the sum of important-based flow time and energy consumed than NC-PAR. Competitiveness of NC-PAR is 3 for and 3.5 for , whereas the value of competitive ratio c of MBS for , and is 2.442; for , and is 2.399; for , is ; for , , is . These results demonstrate that the scheduling algorithm MBS outperforms other algorithms. The competitive value of MBS is least to date. Before these outcomes, there were no results acknowledged for the multi-processor machines in the ON-C model with identified importance, even for unit importance jobs [40]. The further enhancement of this study will be to implement the MBS in real environment. One open problem is to achieve a reasonably less competitive algorithm than MBS. In this study, author considers non-migratory and sequential jobs and this work may be extended to find a scheduling for migratory and non-sequential jobs. Other factors (such as memory requirement) may also be considered for analysis in future extension.
Author Contributions
All authors have worked on this manuscript together. Writing—original draft, P.S.; writing—review and editing, B.K., O.P.M., H.H.A. and G.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Belady, C. In the Data Center, Power and Cooling Costs More Than the IT Equipment It Supports, Electronics Cooling Magazine. Available online: http://www.electronics-cooling.com/2007/02/in-the-data-center-power-and-cooling-costs-more-than-the-it-equipment-it-supports/ (accessed on 10 January 2020).
- Chan, H.L.; Edmonds, J.; Lam, T.W.; Lee, L.K.; Marchetti-Spaccamela, A.; Prush, K. Non-clairvoyant speed scaling for flow and energy. Algorithmica 2011, 61, 507–517. [Google Scholar] [CrossRef]
- Merritt, R. CPU Designers’ Debate Multi-Core Future, EE Times. 2 June 2008. Available online: http://www.eetimes.com/document.asp?doc_id=1167932 (accessed on 15 January 2020).
- U.S. Environmental Protection Agency, EPA Report on Server and Data Center Energy Efficiency. Available online: https://www.energystar.gov/ia/partners/prod_development/downloads/EPA_Report_Exec_Summary_Final.pdf (accessed on 14 January 2020).
- Singh, P.; Wolde-Gabriel, B. Executed-time Round Robin: EtRR an online non-clairvoyant scheduling on speed bounded processor with energy management. J. King Saud Univ. Comput. Inf. Sci. 2016, 29, 74–84. [Google Scholar] [CrossRef]
- Bansal, N.; Chan, H.L.; Pruhs, K. Speed scaling with an arbitrary power function. In Proceedings of the Annual ACM-SIAM Symposium on Discrete Algorithms, New York, NY, USA, 4–6 January 2009; pp. 693–701. [Google Scholar]
- Bansal, N.; Kimbrel, T.; Pruhs, K. Dynamic speed scaling to manage energy and temperature. J. ACM 2007, 54, 1–39. [Google Scholar] [CrossRef]
- Singh, P.; Khan, B.; Vidyarthi, A.; Haes Alhelou, H.; Siano, P. Energy-aware online non-clairvoyant scheduling using speed scaling with arbitrary power function. Appl. Sci. 2019, 9, 1467. [Google Scholar] [CrossRef]
- Lam, T.W.; Lee, L.K.; To, I.K.K.; Wong, P.W.H. Nonmigratory multiprocessor scheduling for response time and energy. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 1–13. [Google Scholar]
- Motwani, R.; Phillips, S.; Torng, E. Nonclairvoyant scheduling. Theor. Comput. Sci. 1994, 30, 17–47. [Google Scholar] [CrossRef]
- Yao, F.; Demers, A.; Shenker, S. A scheduling model for reduced CPU energy. In Proceedings of the Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 23–25 October 1995; pp. 374–382. [Google Scholar]
- Koren, G.; Shasha, D. Dover: An optimal on-line scheduling algorithm for overloaded uniprocessor real-time systems. SIAM J. Comput. 1995, 24, 318–339. [Google Scholar] [CrossRef]
- Leonardi, S.; Raz, D. Approximating total flow time on parallel machines. In Proceedings of the ACM Symposium on Theory of Computing, El Paso, TX, USA, 4–6 May 1997; pp. 110–119. [Google Scholar]
- Kalyanasundaram, B.; Pruhs, K. Speed is as powerful as clairvoyant. J. ACM 2000, 47, 617–643. [Google Scholar] [CrossRef]
- Edmonds, J. Scheduling in the dark. Theor. Comput. Sci. 2000, 235, 109–141. [Google Scholar] [CrossRef]
- Kalyanasundaram, B.; Pruhs, K. Minimizing flow time nonclairvoyantly. J. ACM 2003, 50, 551–567. [Google Scholar] [CrossRef]
- Becchetti, L.; Leonardi, S. Nonclairvoyant scheduling to minimize the total flow time on single and parallel machines. J. ACM 2004, 51, 517–539. [Google Scholar] [CrossRef]
- Chekuri, C.; Goel, A.; Khanna, S.; Kumar, A. Multiprocessor scheduling to minimize flow time with epsilon resource augmentation. In Proceedings of the 36th Annual ACM Symposium on Theory of Computing, Chicago, IL, USA, 13–15 June 2004; pp. 363–372. [Google Scholar]
- Chen, J.J.; Hsu, H.R.; Chuang, K.H.; Yang, C.L.; Pang, A.C.; Kuo, T.W. Multiprocessor energy efficient scheduling with task migration considerations. In Proceedings of the 16th Euromicro Conference on Real-Time Systems, Catania, Italy, 2 July 2004; pp. 101–108. [Google Scholar]
- Albers, S.; Fujiwara, H. Energy-efficient algorithms for flow time minimization. ACM Trans. Algorithms 2007, 3, 49. [Google Scholar] [CrossRef]
- Bansal, N.; Pruhs, K.; Stein, C. Speed scaling for weighted flow time. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2007; pp. 805–813. [Google Scholar]
- Lam, T.W.; Lee, L.K.; To, I.K.K.; Wong, P.W.H. Competitive non-migratory scheduling for flow time and energy. In Proceedings of the 20th ACM Symposium on Parallelism in Algorithms and Architectures, Munich, Germany, 14–16 June 2008; pp. 256–264. [Google Scholar]
- Chadha, J.; Garg, N.; Kumar, A.; Muralidhara, V. A competitive algorithm for minimizing weighted flow time on unrelated processors with speed augmentation. In Proceedings of the Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 679–684. [Google Scholar]
- Chan, S.H.; Lam, T.W.; Lee, L.K.; Liu, C.M.; Ting, H.F. Sleep management on multiple processors for energy and flow time. In Proceedings of the 38th International Colloquium on Automata, Languages and Programming, Zurich, Switzerland, 4–8 July 2011; pp. 219–231. [Google Scholar]
- Albers, S.; Antoniadis, A.; Greiner, G. On multi-processor speed scaling with migration. In Proceedings of the 23rd Annual ACM Symposium on Parallelism in Algorithms and Architectures, San Jose, CA, USA, 4–6 June 2011; pp. 279–288. [Google Scholar]
- Gupta, A.; Im, S.; Krishnaswamy, R.; Moseley, B.; Pruhs, K. Scheduling heterogeneous processors isn’t as easy as you think. In Proceedings of the 23rd Annual ACM-SIAM Symposium on Discrete Algorithms, Kyoto, Japan, 17–19 January 2012; pp. 1242–1253. [Google Scholar]
- Chan, S.H.; Lam, T.W.; Lee, L.K.; Zhu, J. Nonclairvoyant sleep management and flow-time scheduling on multiple processors. In Proceedings of the 25th Annual ACM Symposium on Parallelism in Algorithms and Architectures, Montreal, QC, Canada, 23–25 July 2013; pp. 261–270. [Google Scholar]
- Lawler, E.L.; Lenstra, J.K.; Kan, A.R.; Shmoys, D.B. Sequencing and Scheduling: Algorithms and Complexity. In Handbooks in Operations Research and Management Science; Elsevier: Amsterdam, The Netherlands, 1993; Volume 4, pp. 445–522. [Google Scholar]
- Hall, H. Approximation algorithm for scheduling. In Approximation Algorithm for NP-Hard Problems; Hochbaum, D.S., Ed.; PWS Publishing Company: Boston, MA, USA, 1997; pp. 1–45. [Google Scholar]
- Sgall, J. On-line scheduling. In Online Algorithms, The State of the Art; Fiat, A., Woeginger, G.J., Eds.; Springer: Berlin/Heidelberg, Germany, 1998; pp. 196–231. [Google Scholar]
- Karger, D.; Stein, C.; Wein, J. Scheduling Algorithms, CRC Handbook of Theoretical Computer Science; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Irani, S.; Pruhs, K. Algorithmic problems in power management. ACM SIGACT News 2005, 36, 63–76. [Google Scholar] [CrossRef]
- Albers, S. Energy efficient algorithms. Commun. ACM 2010, 53, 86–96. [Google Scholar] [CrossRef]
- Albers, S. Algorithms for dynamic speed scaling. In Proceedings of the 28th International Symposium of Theoretical Aspects of Computer Science, Dortmund, Germany, 10–12 March 2011; pp. 1–11. [Google Scholar]
- Gupta, A.; Krishnaswamy, R.; Pruhs, K. Scalably scheduling power-heterogeneous processors. In Proceedings of the 37th International Colloquium on Automata, Languages and Programming, Bordeaux, France, 5–10 July 2010; pp. 312–323. [Google Scholar]
- Fox, K.; Im, S.; Moseley, B. Energy efficient scheduling of parallelizable jobs. In Proceedings of the 24th Annual Symposium on Discrete Algorithms, New Orleans, LA, USA, 6–8 January 2013; pp. 948–957. [Google Scholar]
- Thang, N.K. Lagrangian duality in online scheduling with resource augmentation and speed scaling. In Proceedings of the 21st European Symposium on Algorithms, Sophia Antipolis, France, 2–4 September 2013; pp. 755–766. [Google Scholar]
- Im, S.; Kulkarni, J.; Munagala, K.; Pruhs, K. SelfishMigrate: A scalable algorithm for non-clairvoyantly scheduling heterogeneous processors. In Proceedings of the 55th IEEE Annual Symposium on Foundations of Computer Science, Philadelphia, PA, USA, 18–21 October 2014; pp. 531–540. [Google Scholar]
- Bell, P.C.; Wong, P.W.H. Multiprocessor speed scaling for jobs with arbitrary sizes and deadlines. J. Comb. Optim. 2015, 29, 739–749. [Google Scholar] [CrossRef][Green Version]
- Azar, Y.; Devanue, N.R.; Huang, Z.; Panighari, D. Speed scaling in the non-clairvoyant model. In Proceedings of the 27th Annual ACM Symposium on Parallelism in Algorithms and Architectures, Portland, OR, USA, 13–15 June 2015; pp. 133–142. [Google Scholar]











© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).