1. Introduction
Although industrial robots have long been used for various manufacturing tasks, their role has mostly been limited to repetitive high-volume tasks as robot deployment has typically required task-specific fixtures, end effectors and hand-programmed motion sequences [
1,
2]. The introduction of human-safe, quickly programmable collaborative robots has broadened the robot deployment to high-mix, low-volume works. Thanks to the recent advances of sensor technology and major breakthrough in the machine learning field, we are now expecting a widespread adoption of intelligent robots that can perceive the environment and make decisions by itself.
In this work, we present an integrated system, which, given individual components and their assembled shape, perceives their positions, orientations and assembled configuration using sensors; generates the optimal assembly plan to build the target shape from components while avoiding a collision; and rapidly executes the assembly motions using a robotic manipulator and gripper. The suggested system was validated in both simulated and real environments using multiple combinations of sensor, manipulator and gripper systems and was successfully used to rapidly solve a number of assembly tasks autonomously in a public competitive demonstration with outstanding results.
The remainder of the paper proceeds as follows.
Section 2 introduces the related works and highlights how the suggested work differs from each of them.
Section 3 presents the overview of the hardware and software used for the system.
Section 4 explains how the robot system processes the sensor data to perceive the environment.
Section 5 presents how the system finds the optimal motion plan that rapidly assembles the components while avoiding a collision.
Section 6 describes the simulation setup we used to test the system with different hardware configurations.
Section 7 shows the experimental results acquired from the laboratory experiment and public demonstration. Finally, we conclude with a discussion of potential future directions arising from this work.
2. Related Work
In this work, we present an integrated robotic assembly system that can perceive the environment, plan for the assembly sequence, feasible grasps and manipulator motion and control the hardware in real time. The system is deployed and tested for reliability and performance beyond controlled laboratory environment. As such a system requires multiple components to work together reliably, previous works mostly focus on individual components rather than an integrated system. In [
3], the authors provided a summary of recent robot manipulation research topics, which include robotic hand design, perception for manipulation, grasping, manipulation and approaches to utilize machine learning for manipulation, but most of the works presented are focused on individual components. For example, in [
4], the authors focused on assembly sequence and grasp planning for assembly tasks, and, in [
5,
6], the authors used deep learning based approach to learn grasp planning strategy from data acquired by repeated trials.
There have been a few works that address an integrated system that can perceive, plan and control its manipulators for assembly tasks. In [
7], the authors presented an integrated system for autonomous robotic manipulation that integrates 3D perception, motion planning and real-time motion control. In [
8], the authors presented a robot system that has 2D stereo vision camera to detect target objects and uses two 7 DOF arms for a simple assembly task. In [
9], the authors presented an integrated robotic system for autonomous bin picking task, which integrates the 3D perception, grasp and arm motion planning and motion control of the hardware. The system has been validated in public competition, the Amazon Robotics Challenge, and has shown exceptional performance in terms of reliability, accuracy and speed.
Recently, there have been a number of works using the Soma cube assembly task as a demonstration [
10,
11,
12,
13,
14]. The Soma cube assembly task is a good benchmark task for robotic assembly as it has nontrivial number of possible assembly solutions and grasp plans, yet most of the assembly can be realized using a single robotic manipulator. In [
14], the authors focused on finding robust grasping strategies by 2-D form closure with cylindrical fingers for arbitrarily shaped objects. The suggested algorithm has been demonstrated by assembling Soma cube blocks into a cube.
In [
10], the authors proposed an integrated planning system that plans for the assembly sequence and motion to stack a Soma cube block on another. Although the suggested work is close to this work as it integrates the assembly sequence planning, motion planning and re-grasping required for the Soma cube assembly task, the suggested system is largely limited as it relies upon full information of the blocks and the assembly is limited for only two blocks. The authors extended the suggested system in [
11], which allows for stacking up to five blocks. In [
13], the authors proposed a planner that plans the optimal assembly sequence of Soma cube blocks for a dual armed robot. Given the mesh model of objects and the final assembly configuration, the suggested algorithm finds an optimal assembly sequence for dual armed robot considering the stability, graspability and assemblability. Finally, recently, in [
12], the authors proposed the single-arm motion planner for Soma cube block assembly, which, given the initial and final pose of a Soma cube block, automatically generates the collision free arm motion plan with optional re-grasping to assemble the blocks incrementally.
3. System Overview
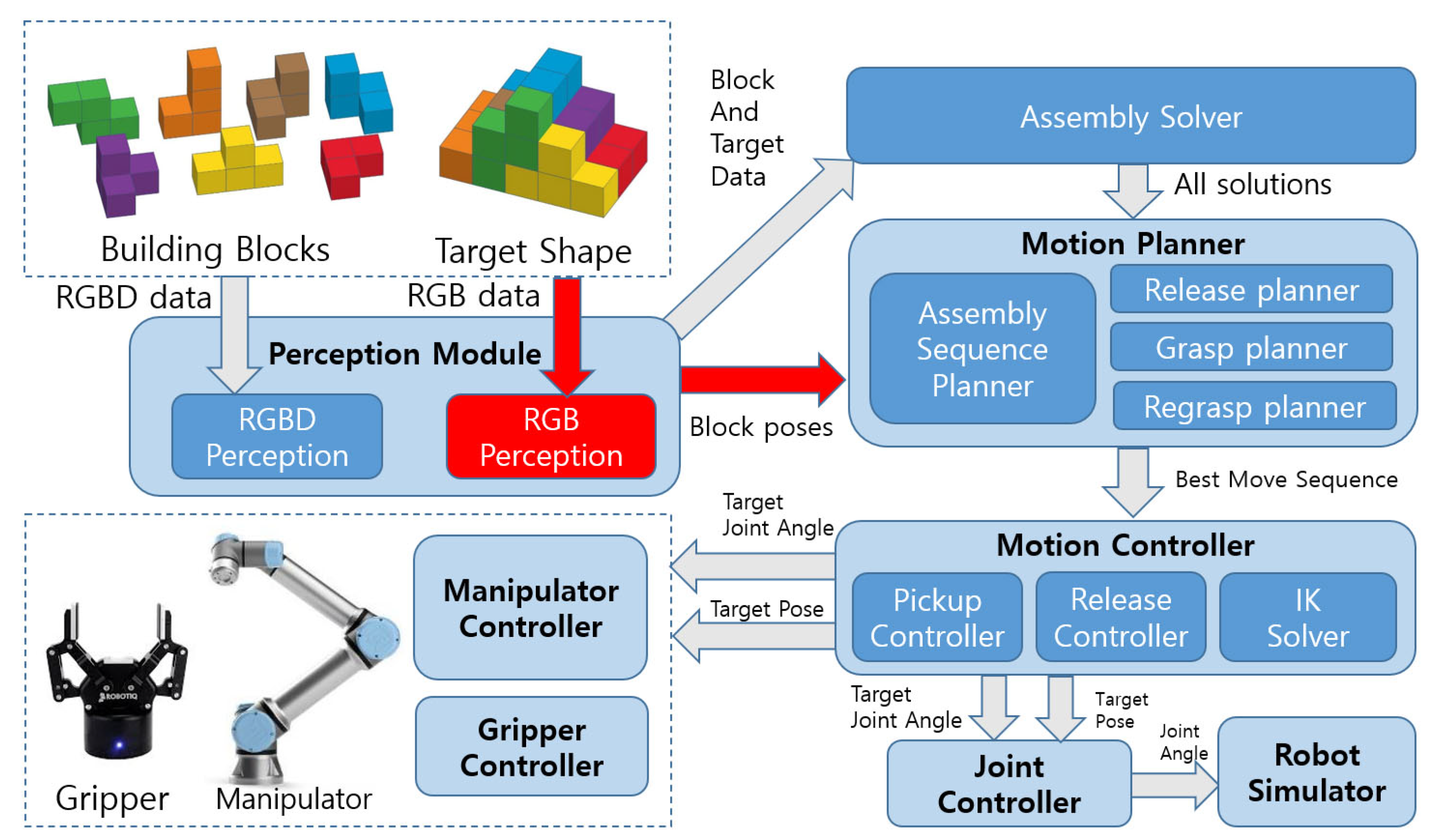
Figure 1 shows the overall system architecture. The only inputs to the system are the target shape provided as blocks assembled by human operator and individual building blocks needed for the assembly. The robot observes the target shape and individual building blocks, calculates all possible block configurations for the target shape and plans the assembly sequences and grasp strategy for moving each block while satisfying multiple constraints. If there exists no manipulation sequence that can move each block to the target pose in a single manipulation, the planner performs additional re-grasp planning to move the block in multiple steps. The suggested system is modular and platform agonistic, and it can accept different sensors, manipulators and gripper hardware with little effort.
As the system is designed primarily to handle the Soma cube assembly task, which is described in
Section 7 in detail, we use following assumptions while designing the system:
Seven standard Soma blocks are used as building components.
Each block is separated from others with distance larger than the unit block size.
The assembly sequence does not require peg-in-hole assembly or screwing.
The assembly sequence can be realized using a single robotic manipulator.
The first two assumptions allow simplifying the perception modules, while the last two allow using simple placement to assemble the blocks. However, the suggested system can be easily extended for more general tasks by adding new software and hardware modules, which we discuss more in detail in
Section 7.
3.1. Manipulator and Gripper
We used a commercial UR5e 6 DOF manipulator for the task. To manipulate the blocks, we iterated through multiple different gripper systems during the development. First, we tried using a commercial Robotiq 2F-85 adaptive gripper without modification, and found its long, center located fingers are not ideal for lateral block release. We replaced its fingers with a pair of short, off-center custom made fingers, as shown in
Figure 2a. Based on the experience from using the commercial gripper for the task, we developed a custom designed parallel gripper with an additional degree of freedom at the fingers, which is shown in
Figure 2b. This gripper allows the pickup and placement motions to be simplified thanks to its short finger length, parallel actuation and the ability of rotating the grasped object without a wrist movement. We present the Soma cube assembly process using various manipulator and gripper setups in the following sections.
3.2. Sensors
For perception, we prepared a dual-sensor setup that consists of a ceiling-mounted high-resolution RGB camera and a wrist-mounted RGBD camera. To achieve the very high pose accuracy required for the assembly task, we used a Sony A7R Mark II commercial mirrorless camera paired with Zeiss Sonnar T* 55 mm 1.8 lens as the RGB camera, which can output 7952 × 5304 resolution image with low noise even under indoor lighting. The camera uses stock firmware and is connected to control PC via USB-C cable and remotely controlled by
libgphoto2 library. For the wrist RGBD camera, we tested Intel Realsense D435 and SR305 cameras and decided to use the SR305 camera, which we found to be better optimized for close-range subjects. Two sensors setups are shown in
Figure 3.
3.3. Computation
As our software modules are fairly lightweight and do not require a powerful computer for processing, we used a single laptop with core i7 CPU and GTX 1080 GPU to process all CPU and GPU bound computational tasks, which includes the RGB and depth based perception, assembly and grasp planning and finally real-time control of the robotic arm and gripper. We did not use the preemptive real-time kernel on the control PC as the UR5E manipulator has low external control rate of 500 Hz and has internal motion planner and controller that ensure smooth arm motion.
4. Perception
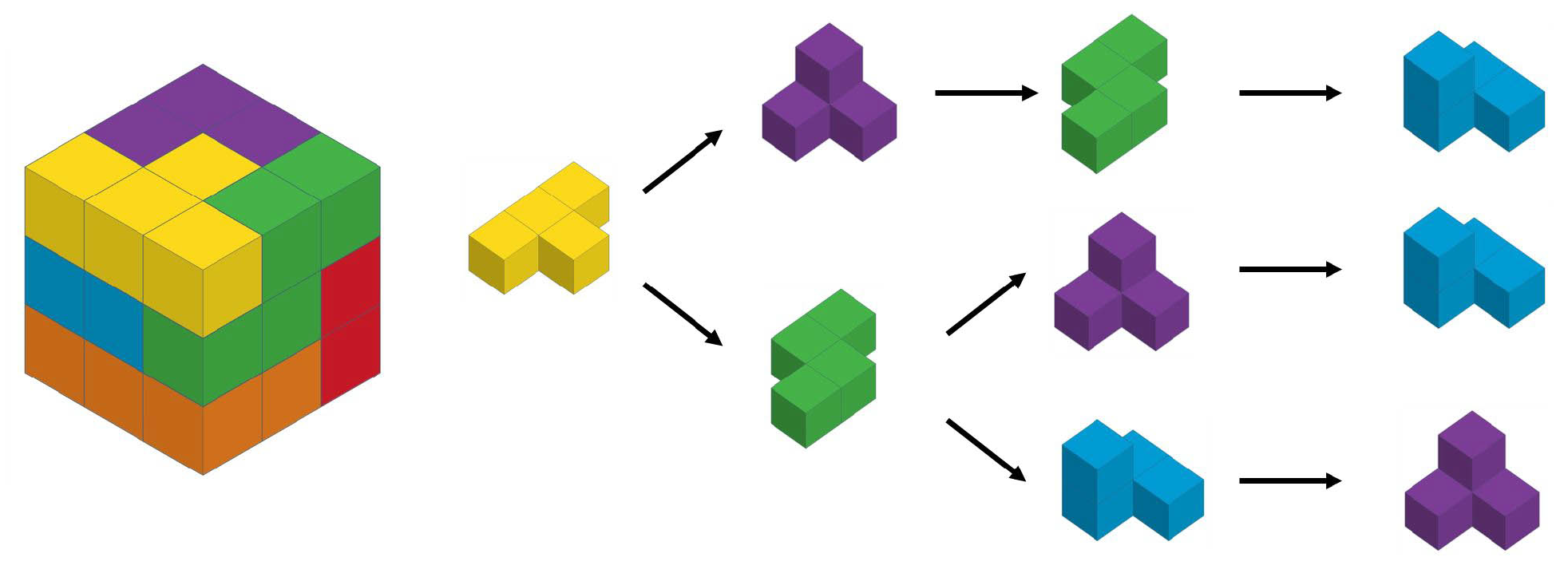
To assemble arbitrarily positioned blocks into the target shape, the system needs to perceive the type, position and orientation of each block first. Standard seven colored Soma cube blocks are used, which are shown in
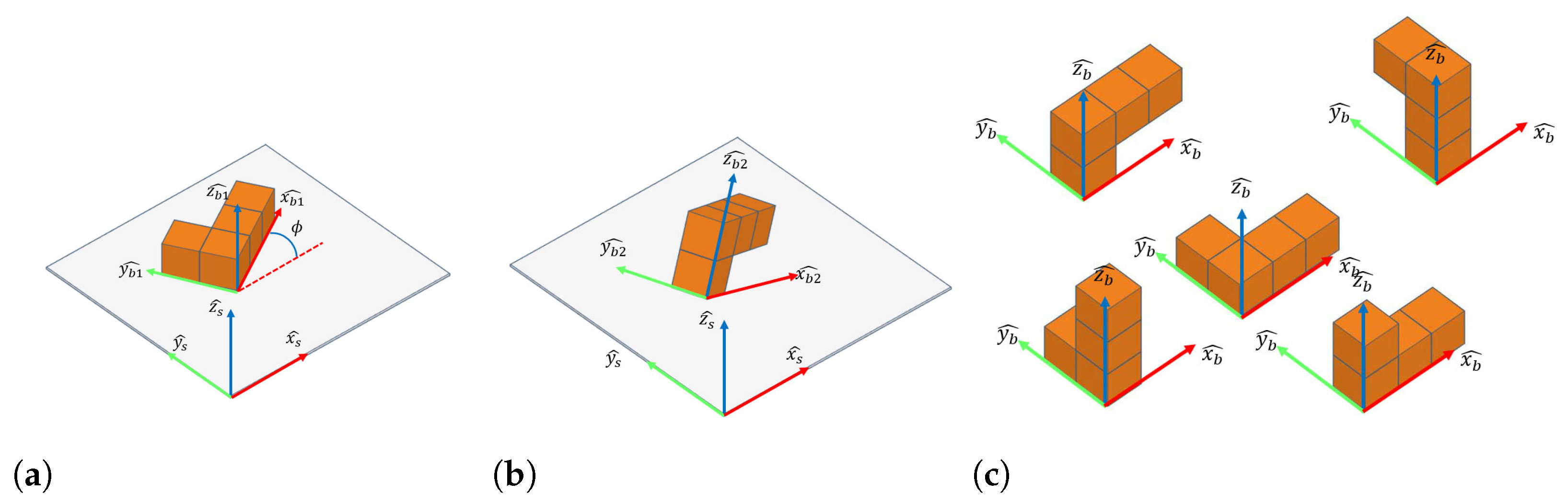
Figure 4, and we label them Blocks 1–7 according to their shapes. To make planning easier, we define the pose and the orientation of blocks separately. As there are 24 3D orientations resulting from multiple applications of 90
rotations about X-axis, Y-axis and Z-axis, we enumerate all 24 orientations and label each block’s orientation as a number from 1 to 24. We define the pose of a block as the position and orientation of the bounding cuboid of the block. For a general block in 3D space, we denote its pose by a tuple
where
is the 3D center position of the bounding cuboid and
) is its Euler angle. To remove the duplicate cases, we limit Euler angles as
. For blocks that lie flat on the surface, we use a simpler 2D pose
where
is the center position of the bounding box and
is the yaw angle. Examples of 2D and 3D block pose, as well as blocks with the same pose but different orientations, are shown in
Figure 5.
4.1. RGB-Based Block Detection
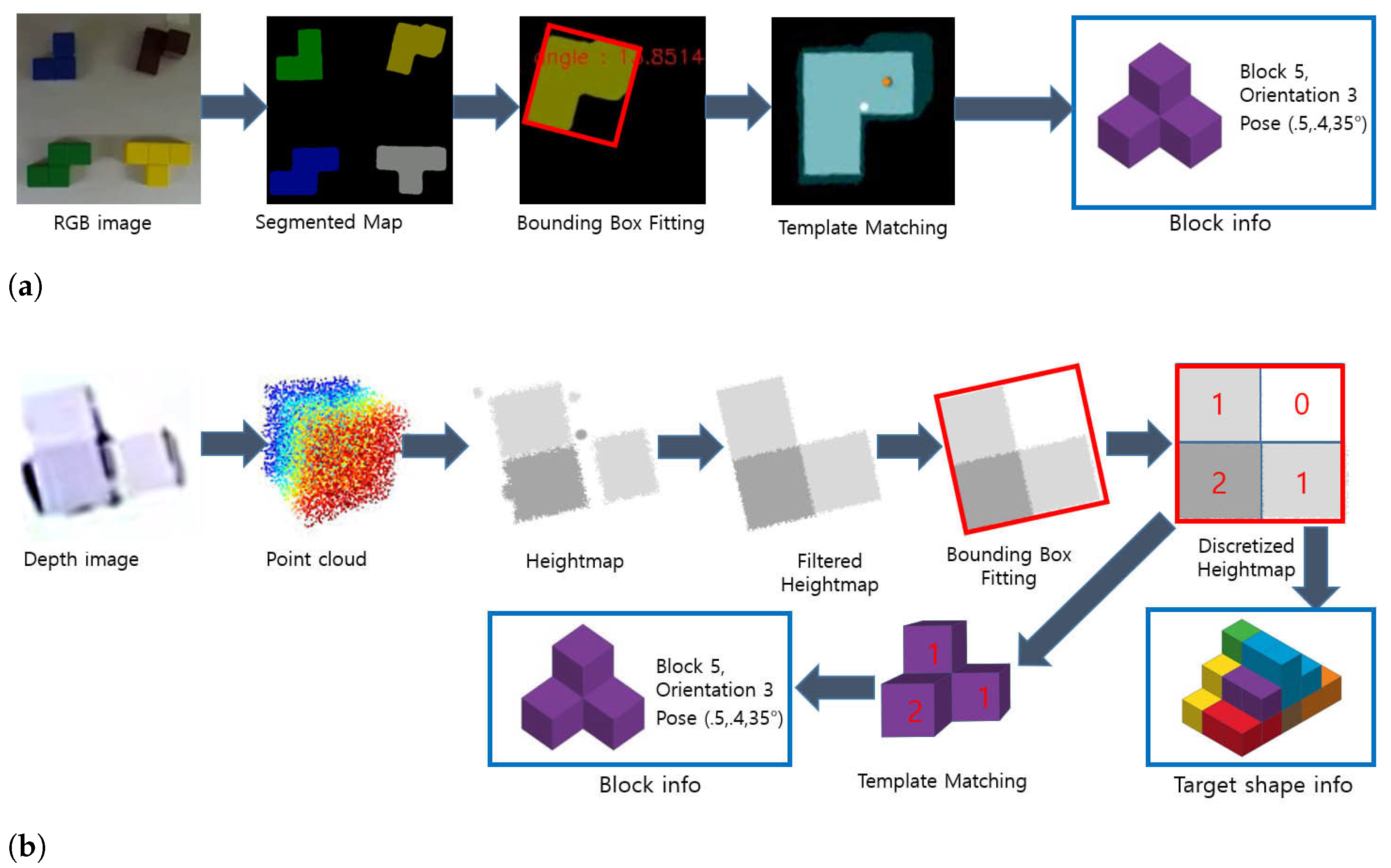
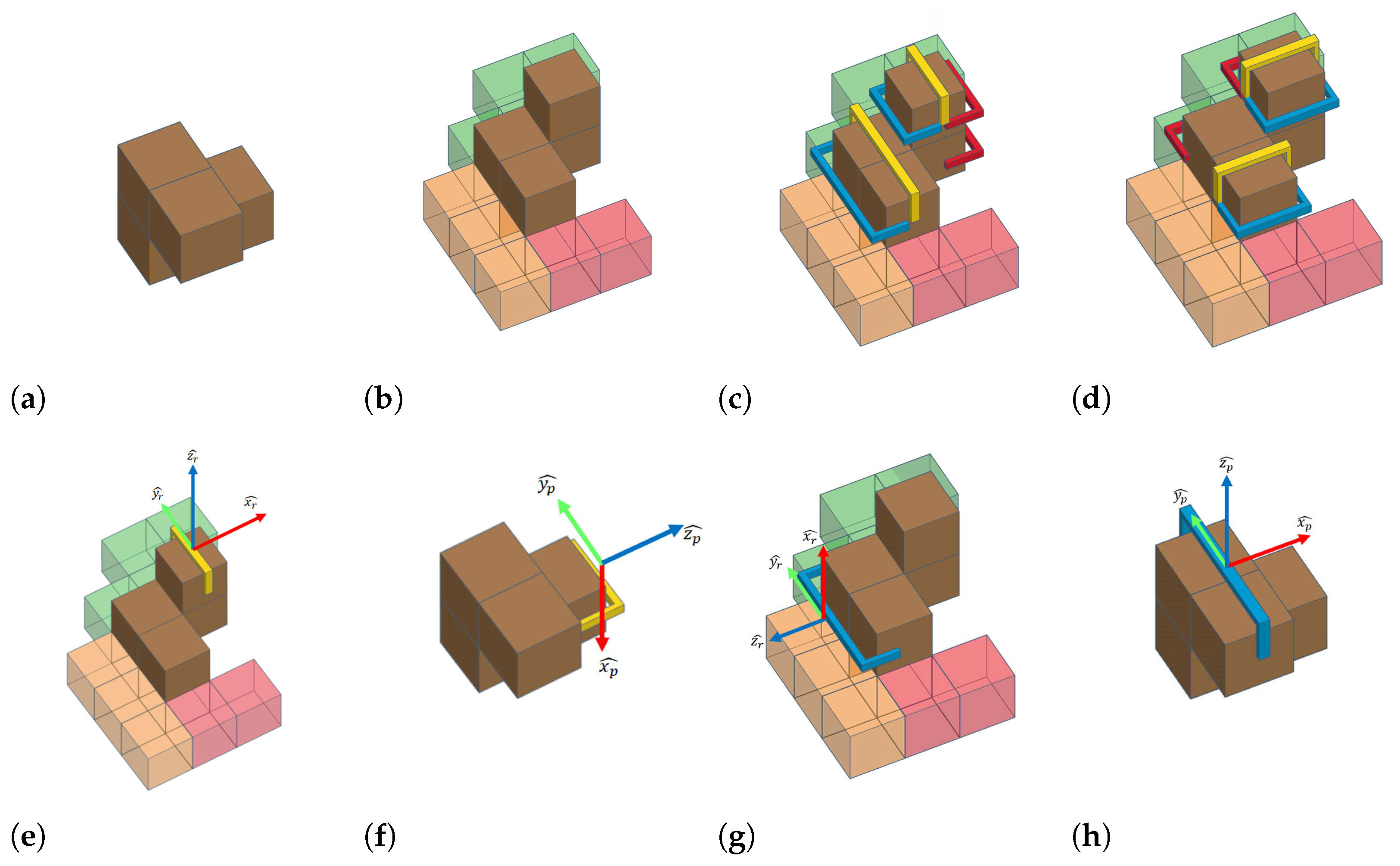
We implemented a RGB-based block detection module to get accurate 2D poses of building blocks required for the assembly task. When a RGB image is requested, the ceiling camera is triggered and the recorded high-resolution
jpeg image is transferred to control PC and rectified using the calibration parameters. Then, the Deeplab-v3 [
15] deep learning-based semantic segmentation algorithm is used to segment the image it into separate blocks, which we found to be better at preserving outlines of blocks than Mask R-CNN [
16] algorithm we also tested. Once each block is segmented from the image, their type is classified using the average RGB value, and rotated bounding boxes are fitted to each block. Then, the segmented block images are rotated to be aligned with the
X-
Y axis of the image space. Finally, they are compared to the standard Soma cube blocks to determine their orientation. have found that the resulting RGB-based block detecting algorithm is reliable against lighting changes, takes less than 200 ms for processing on the core i7 laptop with GTX 1080 GPU and has less than 1 mm positional error and 1.5 degree of orientation error in the worst case compared to the ground truth data. The RGB-based block detection pipeline is shown in
Figure 6a.
4.2. Depth-Based Block and Target Shape Detection
In addition to the RGB-based block detection, we also implemented a perception module based on the wrist-mounted RGBD camera. Recently, several studies have focused on detecting and estimating 6D pose of known objects from RGBD data [
17]. Although such general RGBD-based object detection algorithms can robustly detect and estimate poses of complex-shaped objects even under heavy occlusion, we decided not to use them as the Soma cube assembly task requires a very high positional accuracy to reliably assemble the blocks using a single robotic manipulator, 1 mm or less for Soma cube blocks with 25 mm unit size we used. Instead, we devised a custom cube perception pipeline based on the 2D heightmap generated from the depth image, exploiting the specific shapes of Soma cube blocks.
Using the camera transform calculated from manipulator forward kinematics, the depth image is projected into 3D space to form the point cloud of the blocks. Then, a 2D heightmap is generated based on the distance of each point in point cloud from the supporting surface, and a 2D detection pipeline similar to the RGB-based detection is used afterward. As we can arbitrarily move the RGBD camera using the robotic manipulator, we use multiple different camera positions, which includes the whole block observation position, individual block observation positions and target shape observation position, to overcome the limitation of lower resolution of the RGBD camera compared to the high-resolution ceiling camera. We found that the RGBD camera used at a close range provides accuracy excelling that of high-resolution ceiling camera, while having two issues: (a) close camera position makes some area of the blocks occluded with no registered point on it, and as a result single block tends to show up as separate blocks instead of a single connected one in heightmap image; and (b) depth readings have noise at the edge of the blocks, which shows up as spike-shaped artifacts in the point cloud. We used multi-stage filtering to handle those issues, which includes k-nearest neighbors filtering in the depth space and erosion/dilation of the heightmap image. After filtering, each connected block is segmented and a rotated bounding box is fitted for each block. Then, each segmented heightmap is rotated to be aligned with the X-Y axis of the image space and discretized into a small 2D height array. This discretized target array can be directly used for target shape or further matched with individual building blocks with all possible orientations to detect each block type, orientation and pose. We found this depth based block detection algorithm, while not using the GPU, takes less than 20 ms for processing on the core i7 laptop with GTX 1080 GPU, is lighting independent and has superior accuracy to the RGB-based detection algorithm. The depth-based block detection pipeline is shown in
Figure 6b.
6. Simulation Results
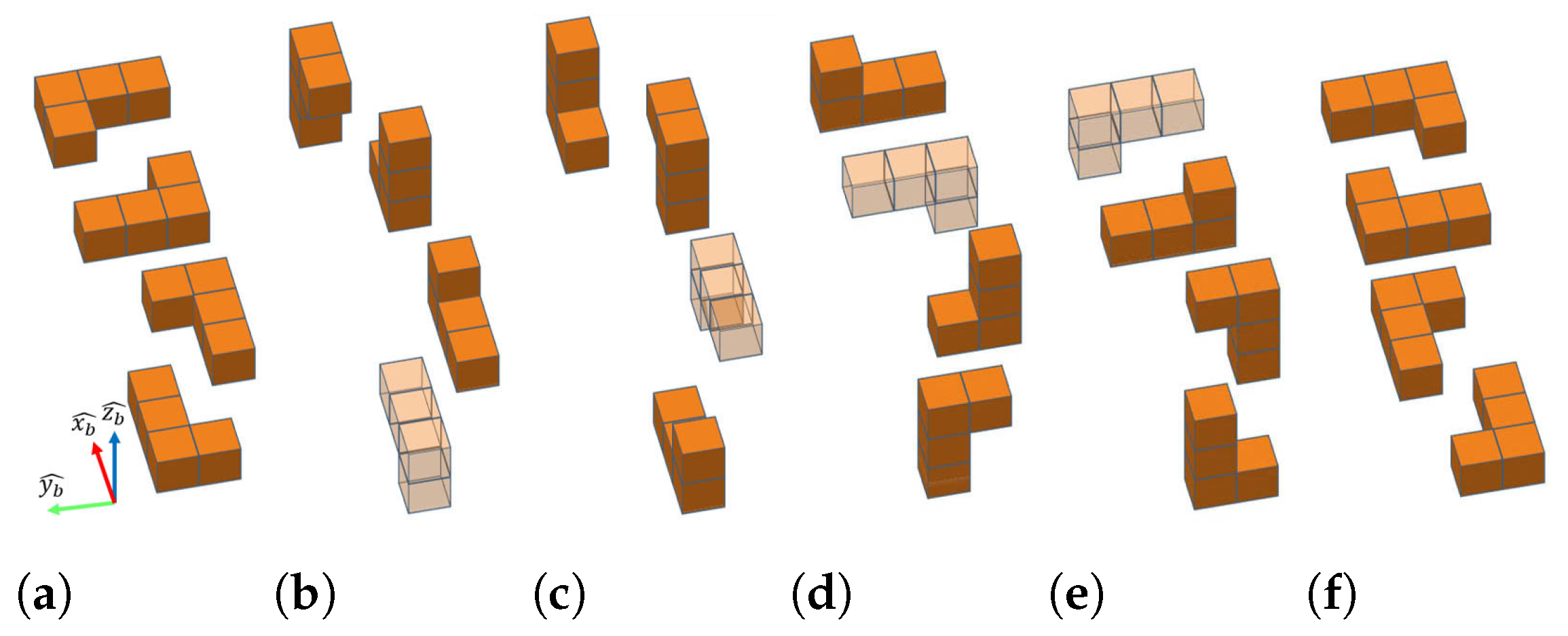
We set up a simulation environment using the Webots open-source robotic simulator [
27] to test the feasibility of the assembly task using different combinations of sensors, manipulators and grippers. We first used the PUMA 560 manipulator model with three wrist joint axes all intersecting at a common point, which eliminates the need for wrist collision-avoidance steps. The block poses were provided by the ground truth data from the simulator, and the 3D pose representation was used.
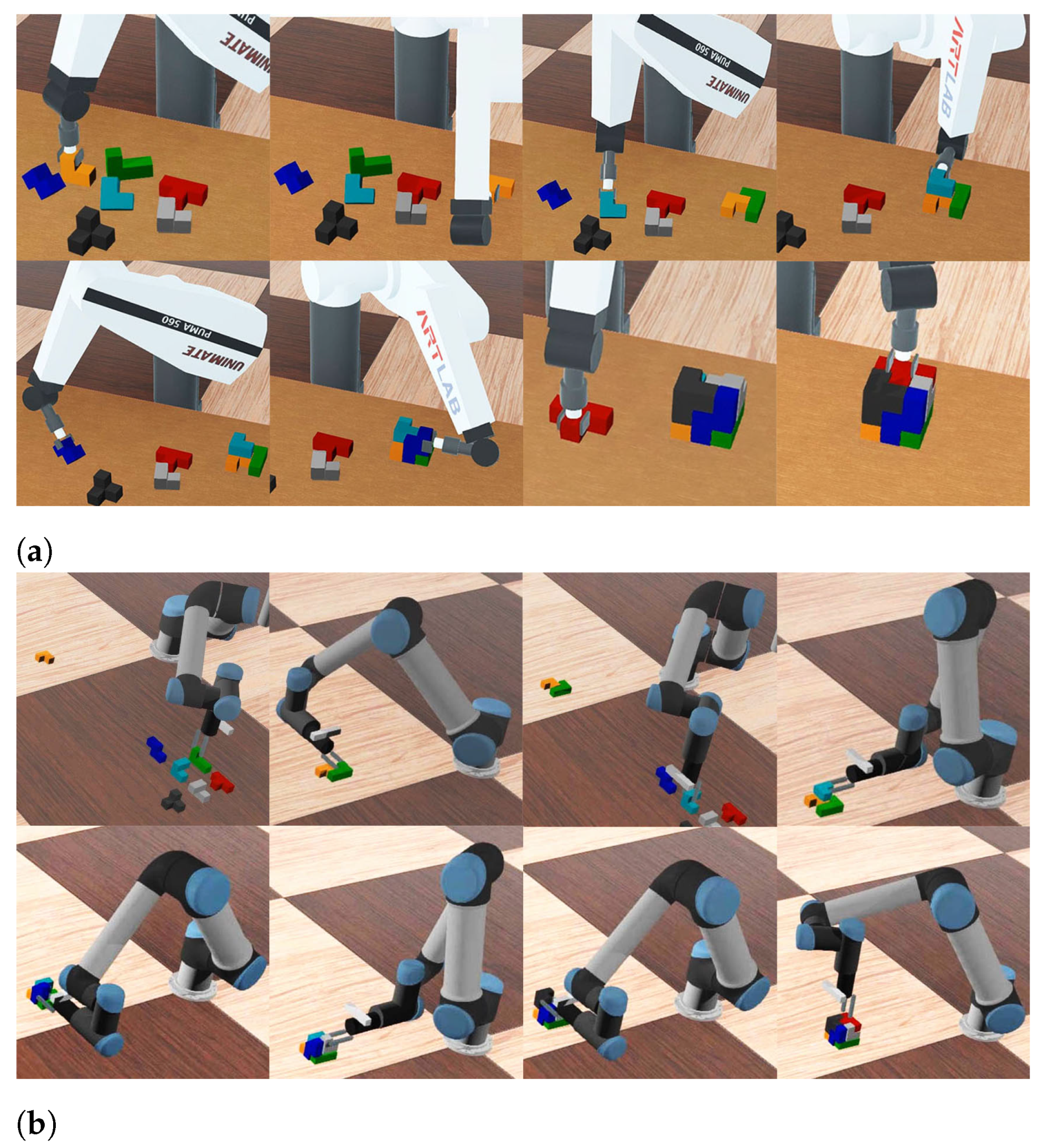
Figure 14a shows the assembly process under such a simulation setup, where the motion planning algorithm successfully finds proper move sequence, grasp poses and arm motions to assemble the given blocks from blocks with arbitrary poses.
Figure 14b shows a more realistic simulation setup, where the UR5e manipulator model is used and block information is acquired using the depth-based perception module from a simulated depth camera mounted at the wrist of the manipulator. Collision-avoiding arm motion planning is used to prevent the self collision of the wrist actuators. We found that the depth-based block detection and the collision avoiding motion planning algorithm successfully let the system assemble target shape from individual blocks.
7. Experimental Results
The suggested software system was implemented for physical UR5e robotic manipulator and custom 2 DOF gripper and tested with a number of block poses and target shapes in both lab environment and public demonstration.
7.1. Lab Environment
We first evaluated the system performance in the lab environment using multiple combinations of different initial block poses and target shapes.
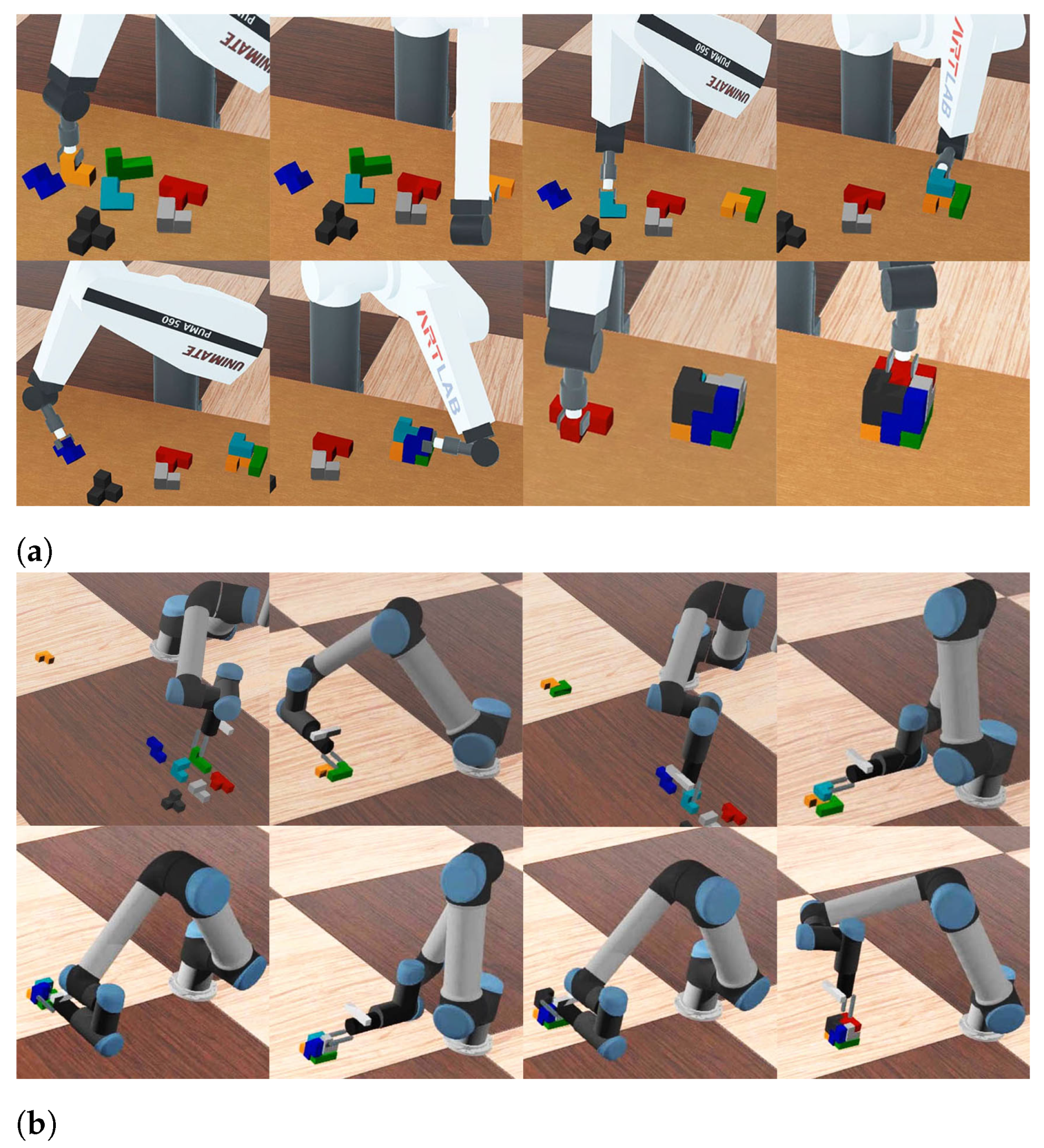
Figure 15 shows the building sequences for some of the standard shapes we tested and
Table 1 shows the analysis of the result. For all target shapes we tested, the assembly solutions can be found very quickly, taking 1.64 ms on average for four target shapes tested. Checking feasible grasp for all the solutions takes significantly longer, 400 ms on average. As many solutions can have feasible grasps for all its blocks, we tried the faster but suboptimal planning strategy that stops at the first feasible solution and immediately executes the best move sequence found for that solution. We found that, at least for the three shapes that have feasible solutions, this strategy succeeds to find optimal solutions while reducing the planning time by more than a factor of 10. Thanks to an exhaustive grasp pose search considering block symmetries, only one of four target shapes has no feasible solution and requires re-grasping, which adds 14 s to the total time for additional perception, pickup and release movements. Overall, we found that assembly takes approximately 1 min on average.
7.2. Public Demonstration
The suggested system was validated by a competitive public demonstration held at COEX, Seoul, Korea in December 2019. The public demonstration was held as the one of the selection processes of competitive research funding provided by the Korean Ministry of Science, ICT and Future Planning. Out of four teams that submitted the proposals, two teams were selected for the first phase, and one team was selected after the public demonstration and funded for the second phase of the research.
The demonstration was divided into three stages with different difficulties, and at each stage the referees decided the target shape and initial block formation. Once the timer started, each team began assembling the blocks autonomously, and the total score was determined by whether the system provided correct assembly plans on display, how many blocks were successfully picked up and placed correctly, if the target shape was successfully assembled and the total time spent for the assembly. In the case of failure, each team could request the referee reset the block formation for restart, with a time penalty. Each stage used two different sets of target shapes and initial block formations, and the best score of the two runs was recorded as the stage score.
To make the system as reliable as possible, we used lower maximum acceleration and velocity parameters for the manipulator motion control, and added more delay for block pickup and perception transitions by s. In addition, we added the pre-positioning moves, which moved blocks with ambiguous orientation and tall blocks that could collide with gripper during pickup motion to the re-grasp position before motion planning. Finally, to handle the worst cases where the initial block formation was extremely close to the assembled target shape, we added an additional “plowing” motion that moved away the assembled blocks away from the blocks to be picked up. Even with those conservative settings, we achieved the official assembly time of 1 min 38 s at the third stage, which is more than three times faster than the other team’s third stage assembly time exceeding 5 min.
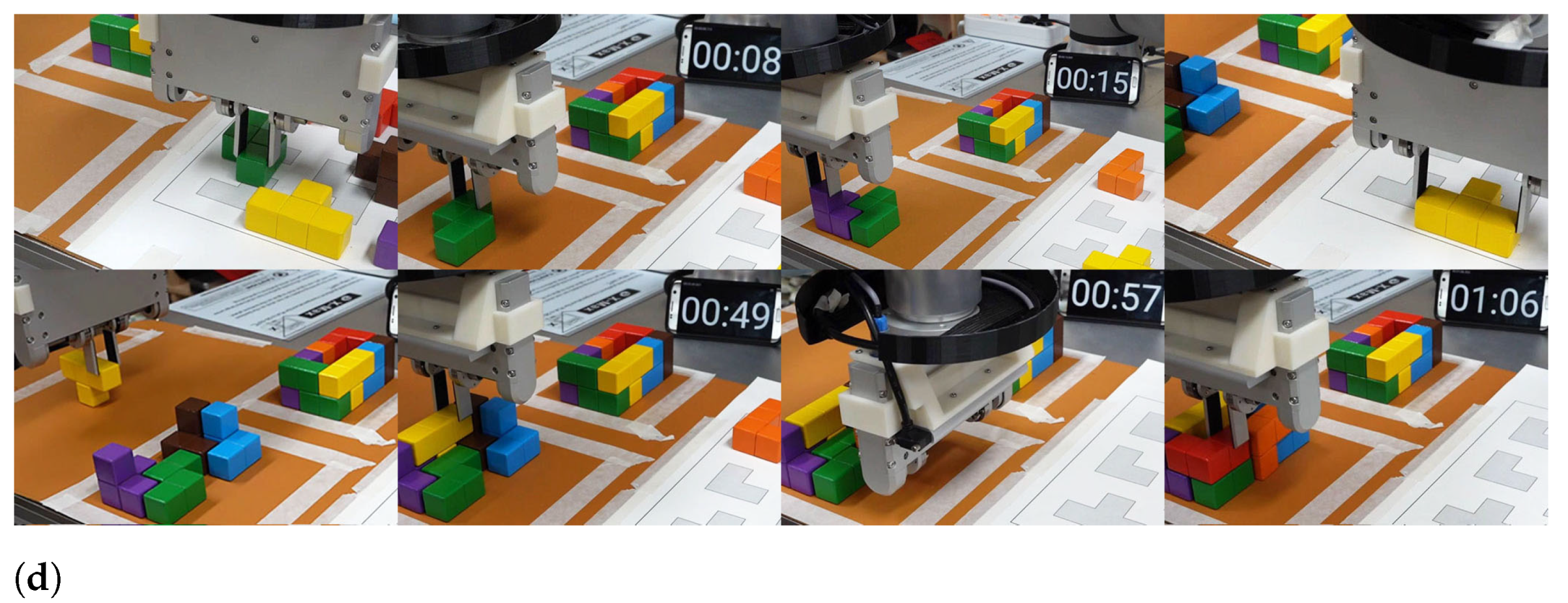
Figure 16 shows a number of block assembly sequences at the public demonstration setup for hard assembly cases with upright blocks and
Table 2 shows the detailed analysis of them. One of the four shapes, the tower shape, had a very large number of assembly solutions, which made the full grasp search take a fairly long 6497.59 ms to complete. Using the first feasible solution decreased the search time by more than a factor of 100 and made the total motion planning time less than 100 ms. In addition, due to the tricky initial block placements, all four target shapes required the initial repositioning of blocks, which was major cause of increasing the total assembly time compared to the lab experiments without one.
Figure 17 shows a detailed assembly sequence with multiple re-grasping of blocks.
7.3. Discussions
7.3.1. Time Analysis
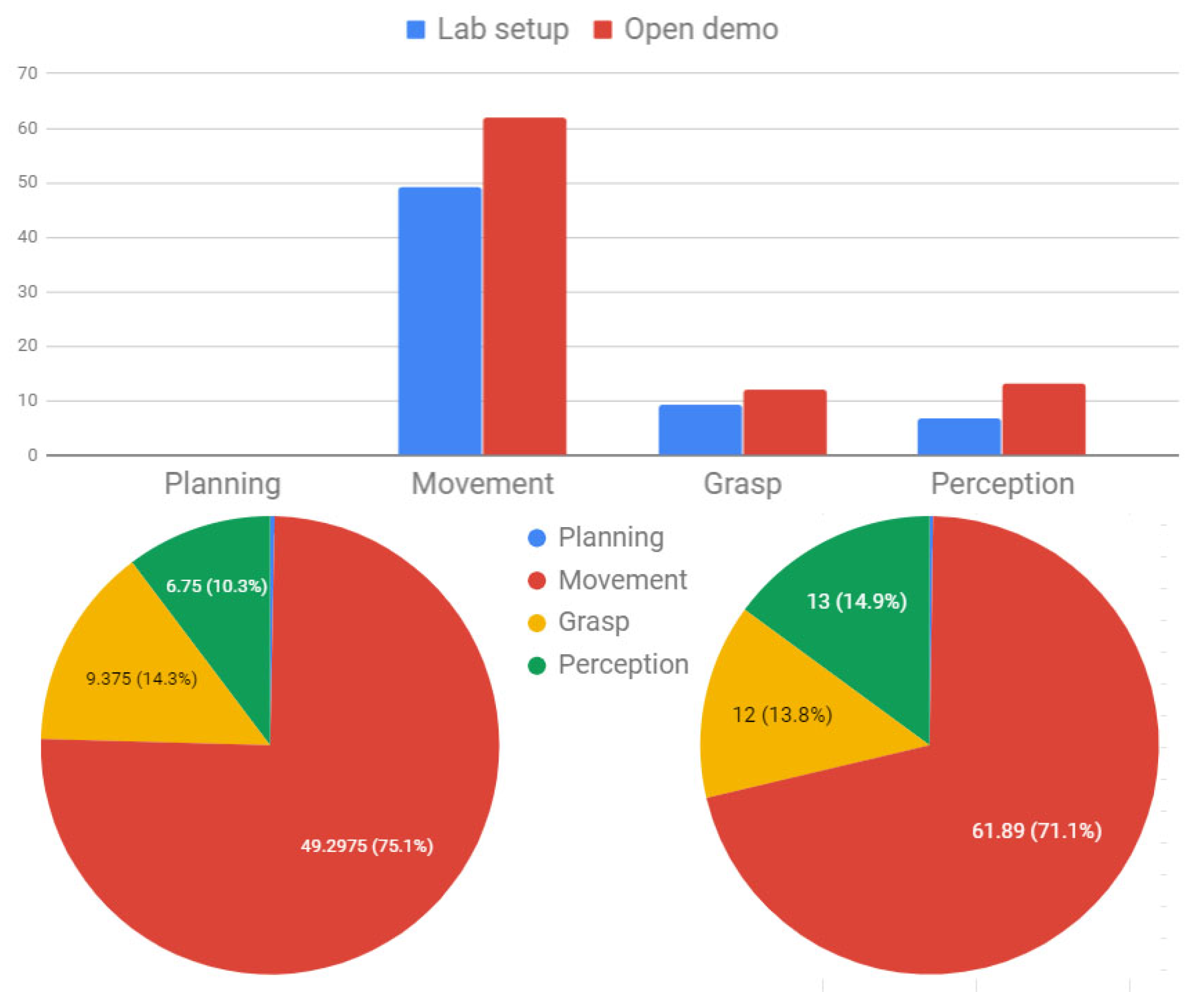
Figure 18 shows the average time decompositions from the data in
Table 1 and
Table 2. We found that the average time spent for motion planning is very short, occupying
of the total assembly time on average and
for the worst case. Although the perception itself is done very quickly, taking less than 20 ms, we added some delay to stabilize the camera before perceiving the block, which adds up to
of the total assembly time for the open demonstration case. We also used delays before and after the gripper actuation to reliably grasp and release blocks, which adds up to
of the total assembly time for the open demonstration case. Finally, the arm movement time takes more than
of the total assembly time, which differs by approximately
according to the acceleration and velocity parameters used. As each of these steps has room for improvement, we think the total assembly time can be further reduced in the future.
7.3.2. Effect of Additional DOF of Gripper
Although we used a custom 2 DOF gripper for the public demonstration, the suggested system does not rely upon one, and the system with 1 DOF gripper was tested in both simulation and real environments to have no workspace or self-collision issues. We did not measure the assembly time with 1 DOF gripper setup, but, even assuming the arm movement times triple due to the collision avoidance motion planning, we estimate the total assembly time will increase by approximately 60% based on the timing breakdown in
Table 1.
7.3.3. Generalization to More Tasks
In
Section 3, we list the assumptions that helped to keep the perception and motion control simpler for the Soma cube assembly problem. However, those assumptions can be removed to make the suggested system handle a wider range of tasks. For detection and 6D pose estimation of arbitrary building components, we can use deep learning-based approaches using RGB image [
16,
17] in addition to point cloud-based registration methods [
28] to further improve the accuracy. Reliable detection and grasping of cluttered objects is a hard problem, where a scattering-based technique can be used to separate each object [
29]. Finally, the assembly tasks that require peg-in-hole assembly or screwing can be realized by adding a second robotic arm for support during the assembly, as well as adding force or compliance based peg-in-hole motion controller (e.g., [
30]).
We further think that the suggested system, especially with the help of the interactive human–robot collaboration, which we discuss below, can play a big role in future industry environments, which need to quickly adapt to a fast changing market demand with a high variety of products in small quantities. Compared to typical industrial robot setup that requires pre-scripted motion sequences and custom designed fixtures for assembly parts, the suggested system is much more flexible as it can autonomously plan for pickup sequences and assembly motions without human programming, and custom fixtures for new parts are not required as the perception subsystem can detect arbitrarily placed parts.
7.3.4. Extension to Human-Robot Collaborative Tasks
While the suggested system is only tested in a fully autonomous setup, where a human sets up the target shape and the robot does the rest, the system can be straightforwardly extended for a semi-autonomous setup where human operators interact with the robot to help and guide the assembly process using voice-, gesture- or touch-based communication. For example, the robot may ask human operator to disambiguate visual perception or move or hold parts that exceed the capability of the robotic manipulator. To ensure a safe operation, the current setup already uses a collaborative robotic manipulator with a safety stop feature, and we can make the system safer and more robust by adding additional sensors to detect the presence of human operator inside its workspace before movements.
7.3.5. Distinctive Contribution of the Paper
As presented in
Section 2, the distinctive contributions of the software framework we suggest in this work are as follows: (a) full integration of various software modules required for accomplishing assembly task with full autonomy, which includes 3D perception, assembly planning, arm and gripper motion planning, re-grasp planning and real-time control; (b) platform agonistic modular software that accepts different sensors, manipulators and grippers with little effort; and (c) rigorously tested and proven to work reliably in a public competitive demonstration.
Compared to previous works addressing integrated robotic assembly system [
7,
8], the suggested system is applicable for much wider range of tasks as it includes explicit assembly sequence planning for complex tasks. Compared to recent works that use Soma cube assembly as a demonstration task [
10,
11,
12,
13,
14], this work is arguably more practical as it does not require a priori information of the block states and is much faster overall due to a more optimized motion planning stage.
We are currently working on the public release of our software framework, which we hope will help other researchers in the field.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







