1. Introduction
Multicore systems usually operate in a shared resource environment. They must cooperate in order to process sharable resources, especially the cache. Caches in multicore systems are private as well as shared. Task scheduling in heterogeneous multicore systems is mainly dependent on how the various tasks are distributed among all available cores [
1]. The processing power of each core in a heterogeneous system is different, so distributing the workload according to each core’s maximum capacity or efficiency is essential. Thus, the computing power of each core has to be considered. Shared caches play a vital role in increasing the throughput of the overall system, but dependent tasks need to be scheduled concurrently [
2].
The prime objective of multicore systems is to execute many tasks in considerably less time. In such circumstances, the role of the cache memory is vital and, if tasks are scheduled on a non-affinity basis, the cache miss rate will increase significantly [
3]. When a higher priority task requests use of the CPU, the system grants that task processing priority over the currently running lower priority task. In granting this priority, the higher priority task wipes the data of the previously running lower priority task from the cache resulting in wastage of time as the system will have to bring back the same data into the cache from off chip memory when processing of the lower priority task resumes [
4]. The affinity-based scheduling of tasks maximizes the cache hit rate which reduces the overall execution time of the total volume of tasks [
5,
6]. The slower nature of some cores in a heterogeneous multicore system negatively affects the overall performance of the system. The cores in heterogeneous systems operate at different computing speeds, thus, even after equal distribution of the workload, the slowest core might end up being overloaded while, at the same time, the fastest core remains idle, doing nothing [
7].
Heuristics have been proposed for affinity-based scheduling of tasks using task migration in NUMA (non-uniform memory access) multicore systems [
8]. The identical or dependent tasks in a multicore system are scheduled on the same core, thereby reducing the cache thrashing while maximizing the cache hit rate [
9]. In multicore systems, shared caches operate between the CPU and the off-chip memory, mainly random access memory (RAM). Gollapudi et al. [
10] proposed a completely fair scheduler (CFS) that uses classification to allocate the tasks on the cores in a way that tasks scheduled on the same core use the core’s shared cache without thrashing the data of other tasks in the cache. Several heuristics are proposed for the concurrent scheduling of tasks that share the same cache content and cooperate to improve cache performance [
11,
12]. The overhead of shared caches in multicore systems has been considered in the context of WCET (worst case execution time) analysis [
13]. Several shared cache partitioning mechanisms have been proposed to reduce cache interference and thrashing [
14,
15].
Classifying the dependent tasks together into a same cluster using different algorithmic approaches is proposed [
16,
17]. Algorithms have been proposed to predict the possible dependency ratios among the tasks that are to be processed [
18,
19,
20]. Some tasks have read or write dependencies on other tasks for certain memory locations; in such cases, the task waits for a certain memory location to be written which is later read by that task and then carries on with its execution [
21,
22]. The total number of interactions between certain tasks indicates the level of dependency the tasks are having [
23]. The affinity relations between multiple queries is checked and closely related queries are assigned to the same cache structure [
24]. Affinity scheduling allows multiple tasks to execute more quickly due to locality of the data, cache utilization or interaction with other tasks [
25]. Certain approaches are proposed where the conditions are defined on the basis of which the affinity-based tasks are grouped into a cluster, making sure the grouped data have some kind of dependency [
26,
27,
28,
29]. To ensure load balancing in heterogeneous systems, imbalance between scheduling domains NUMA and SMT (simultaneous multithreading) NUMA is identified and load balancing is performed by the balancing interval of scheduling domains [
30]. Static and dynamic load balancing techniques are proposed. In static load balancing, the load is distributed according to the computation speed of processors. In dynamic load balancing, the load is distributed after the computation starts [
31]. Tasks in the same cluster are allocated together to the processing cores taking their dependency advantages [
32]. Dependent data clustered together is beneficial as all the data can be processed using the same resources at once [
33,
34].
Several affinity techniques on a number of realistic applications are presented in [
35]. Jia et al. [
36] presented a task scheduling mechanism where dependent tasks are scheduled concurrently on the same core ensuring memory affinity, while reducing task switching overhead. Regueira et al. [
37] presented a technique which enables efficient utilization of NUMA systems by assigning tasks to a set of cores taking into account the communication and synchronization times between tasks. The proposed scheme calculated the communication cost and the synchronization cost between the tasks. Johari et al. [
38] performed load balancing and scheduling tasks on cores by maintaining a queue (sequential search, random search, random search with spatial locality, average method) and without maintaining the queue (sequential, random and random search with spatial locality). Muneeswari [
39] proposed a technique in which critical and non-critical tasks are classified, where the critical tasks are scheduled, such that re-utilization of the cache is minimized while, for non-critical tasks, round robin scheduling is used. Holmbacka et al. and Gantel et al. [
40,
41] proposed a task replication mechanism in which tasks are migrated between different cores. When a task is created on one core, a replica of the same task is created on other available cores. This enables a task’s replica to become active on a certain core when a task is migrated to that core. However, existing work does not clearly address the load balancing issue in heterogeneous systems, or, if it intended to do so, the way in which tasks are scheduled onto the cores where the computing power of each core is different is not clearly defined. Although all the cores in a multicore system are given a fairly equal number of jobs to process, still the best potential performance of the system cannot be exploited because some cores perform slowly by comparison with the fastest cores.
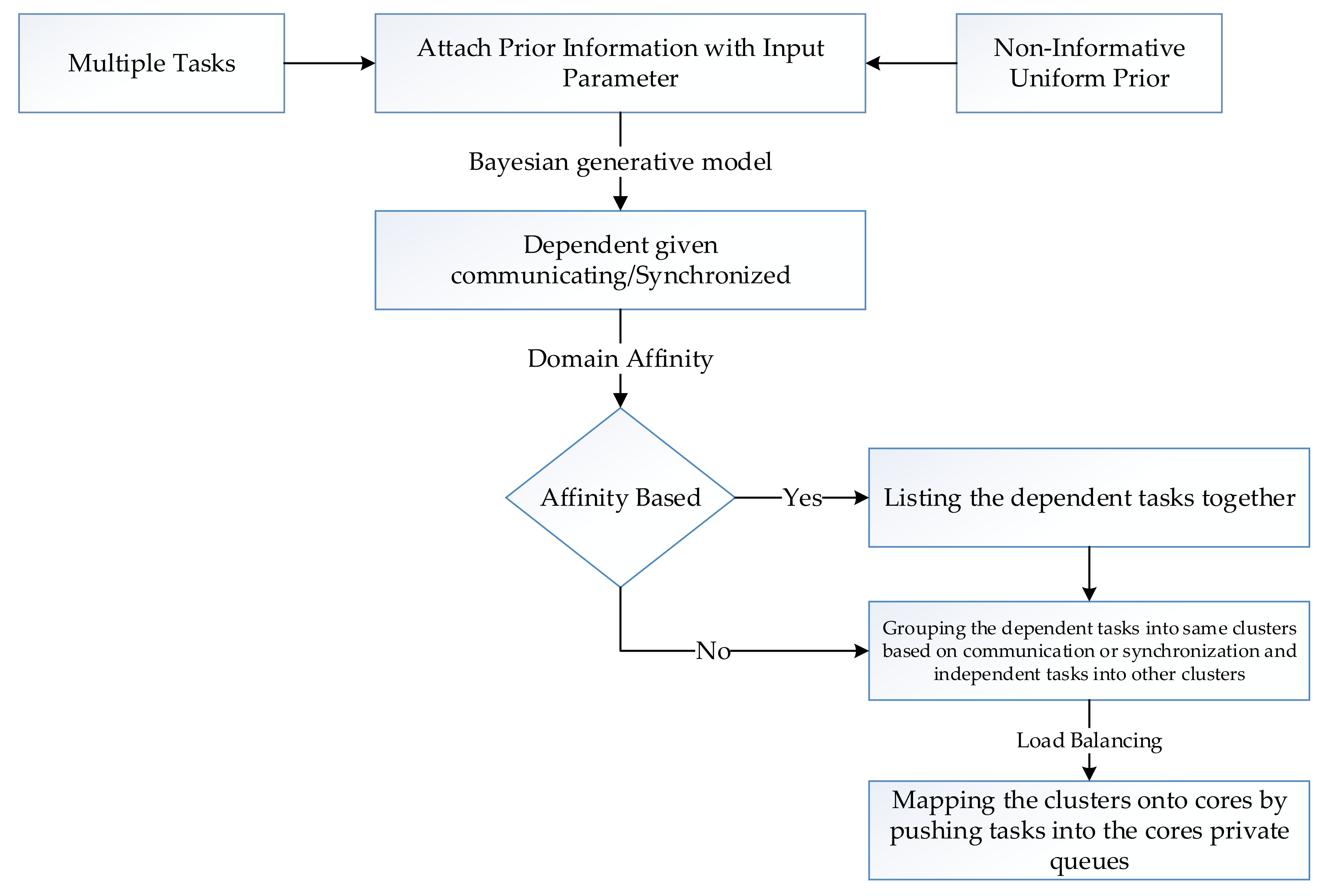
In this paper, we propose two task scheduling techniques, named CBS (chunk-based scheduler) and QBICTM (quantum-based intra core task migration) based on even load balancing by considering the processing speed of all the cores. The main contributions of our work are as follows.
We use the Bayesian data analysis model to cluster dependent tasks. All similar tasks based on whether they are communicating or they have any kind of dependency are grouped into a single cluster. Using the Bayesian analysis model, we found the dependencies between tasks, given they are communicating or synchronized.
Clusters are then allocated to the cores in a heterogeneous multicore architecture ensuring fair load distribution. We propose a chunk-based scheduler (CBS), where the computing speed of each core is determined. All the tasks that are to be processed are divided into variable size chunks equal to the number of cores available. Each chunk contains a number of tasks depending on and commensurate with the processing frequencies of the respective cores. The largest chunk of tasks is allocated to the fastest core while the smallest chunk is given to the slowest core.
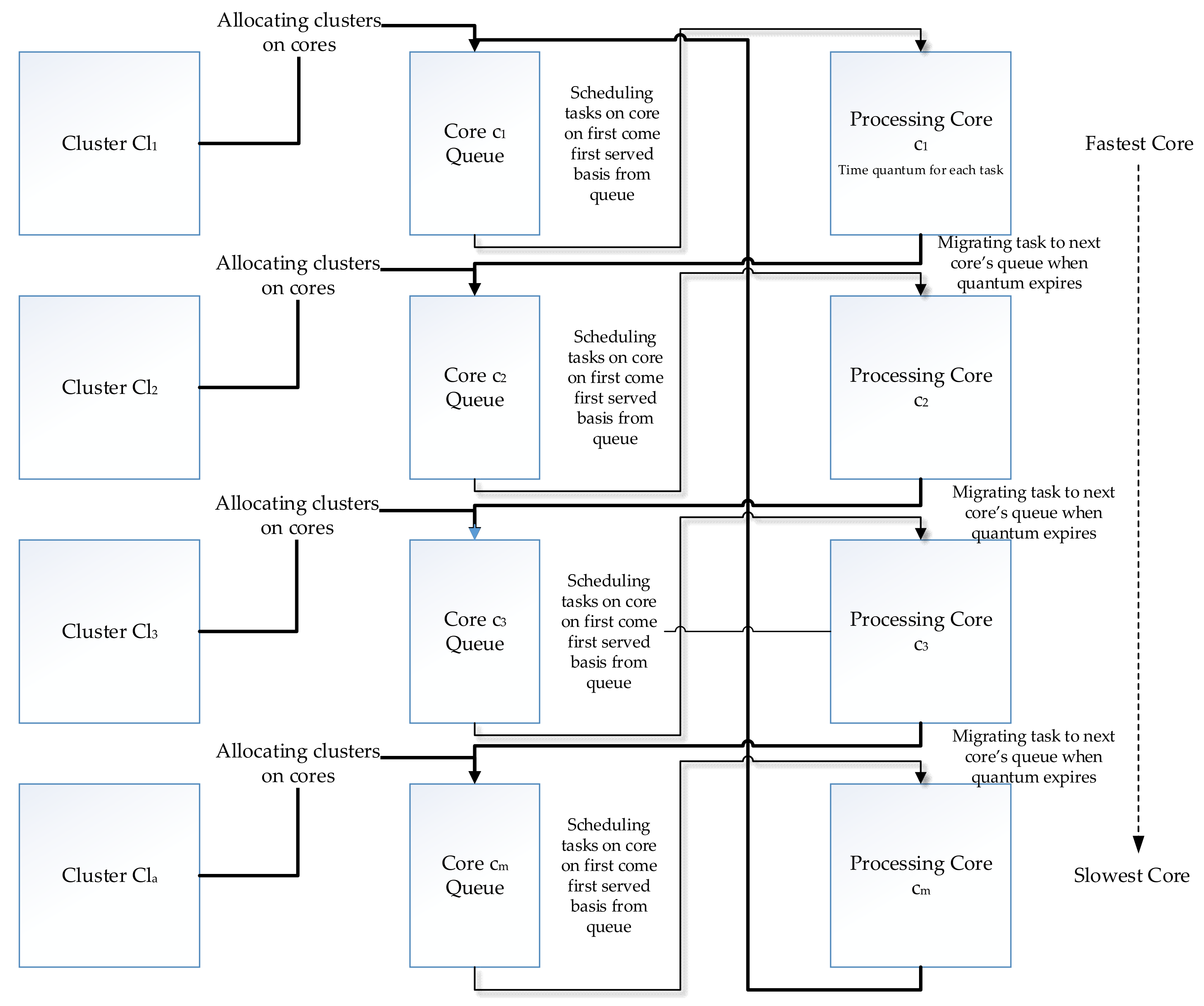
The second scheduler we propose in our work is the quantum-based intra-core task migration (QBICTM). All the tasks are divided into equal size chunks equal to the number of cores available. We introduced a time quantum at the fastest core giving each task a fair and equal chance to execute at the fastest core. Fastest core in a multicore architecture is the one which operates at a greater maximum frequency than the other available cores. As soon as the quantum expires, the migration of tasks between the cores takes place in a heterogeneous multicore architecture.
We used the Pycharm community IDE development tool to obtain the results. The Python multiprocessing module is used to implement our proposed schedulers. All the results that are explained in detail in the later part of this paper were obtained on the core i5 7th generation multicore system with 8 GB of DDR4 RAM. The multicore system contains four logical and two physical cores. Each physical core is operating at a maximum frequency of 2700 MHz which can be boosted up to 3100 MHz. The maximum operating frequency for each physical core is changed to a different value ensuring that all the cores are now heterogeneous in nature. All the cores in a multicore architecture are utilized to their full capacity, i.e., 100% utilization.
The rest of the paper is organized as follows.
Section 2 introduces the methods used in this study.
Section 3 and
Section 4 describe the experimental results and provide a discussion, respectively.
Section 5 concludes our work.
3. Results
In this section, we evaluate the performance of our proposed methodology. The chunk-based scheduling technique and quantum based intra core task migration scheduler are applied to two programs, namely, a factorial program and a real-life working example (ingredients ratio for baking a cake). For the factorial program we calculated execution time for an individual number, as well as for a process (a range of numbers). Real-life working example is a linear program for baking a cake with four ingredients, which are flour, butter, eggs and sugar. The scenario for the execution of a program is as follows
All the ingredients weigh exactly 700 g in total.
Amount of butter was half that of sugar.
Combined weight of flour and eggs was at most 450 g.
Weight of eggs and butter combined was at most 300 g.
The combined weight of eggs and butter was at most that of flour plus sugar.
The program calculates the weight of each individual ingredient after processing multiple tasks, which have read-write our write-read dependencies. The characteristics of the system on which we have performed experiments are given in
Table 2.
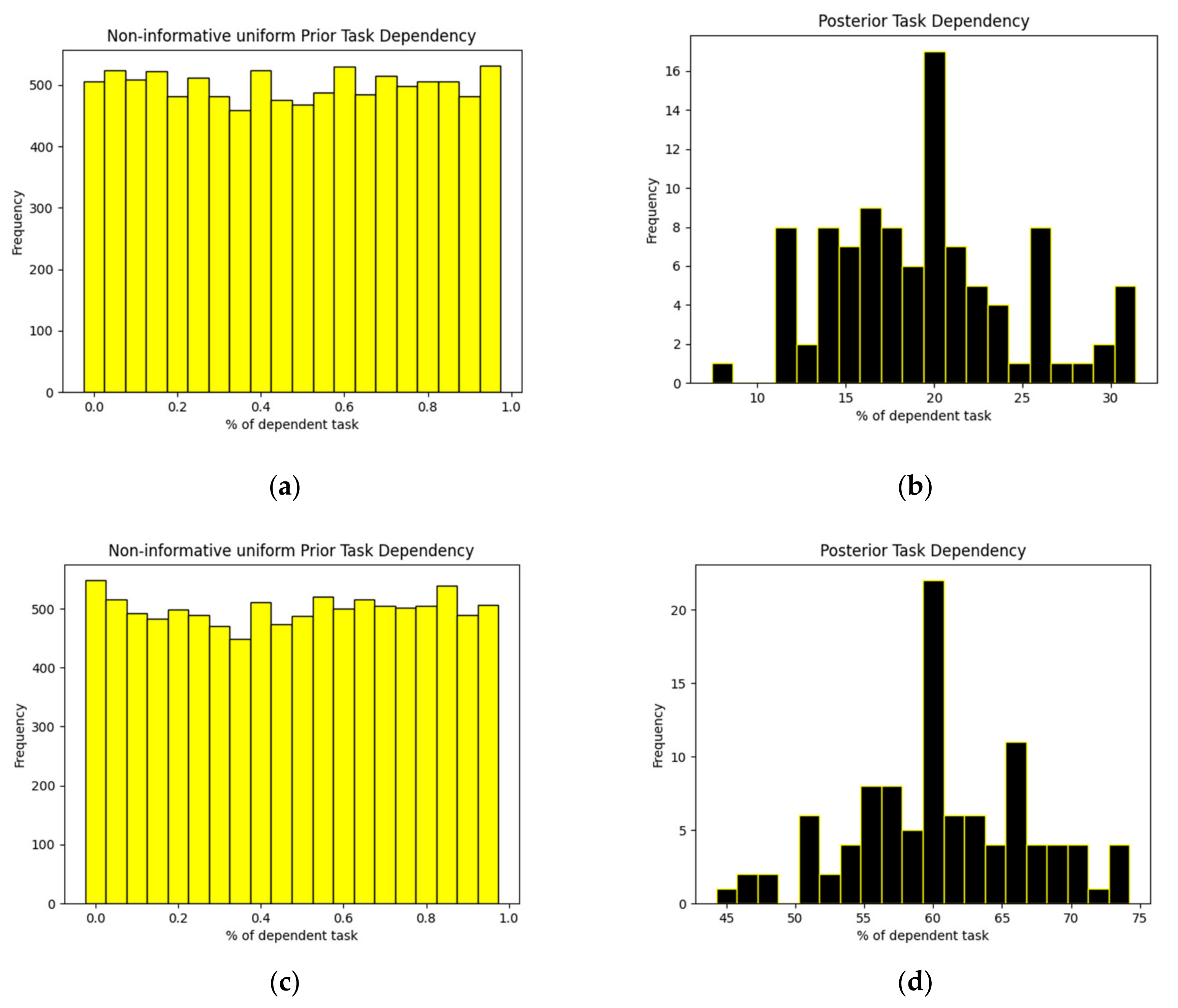
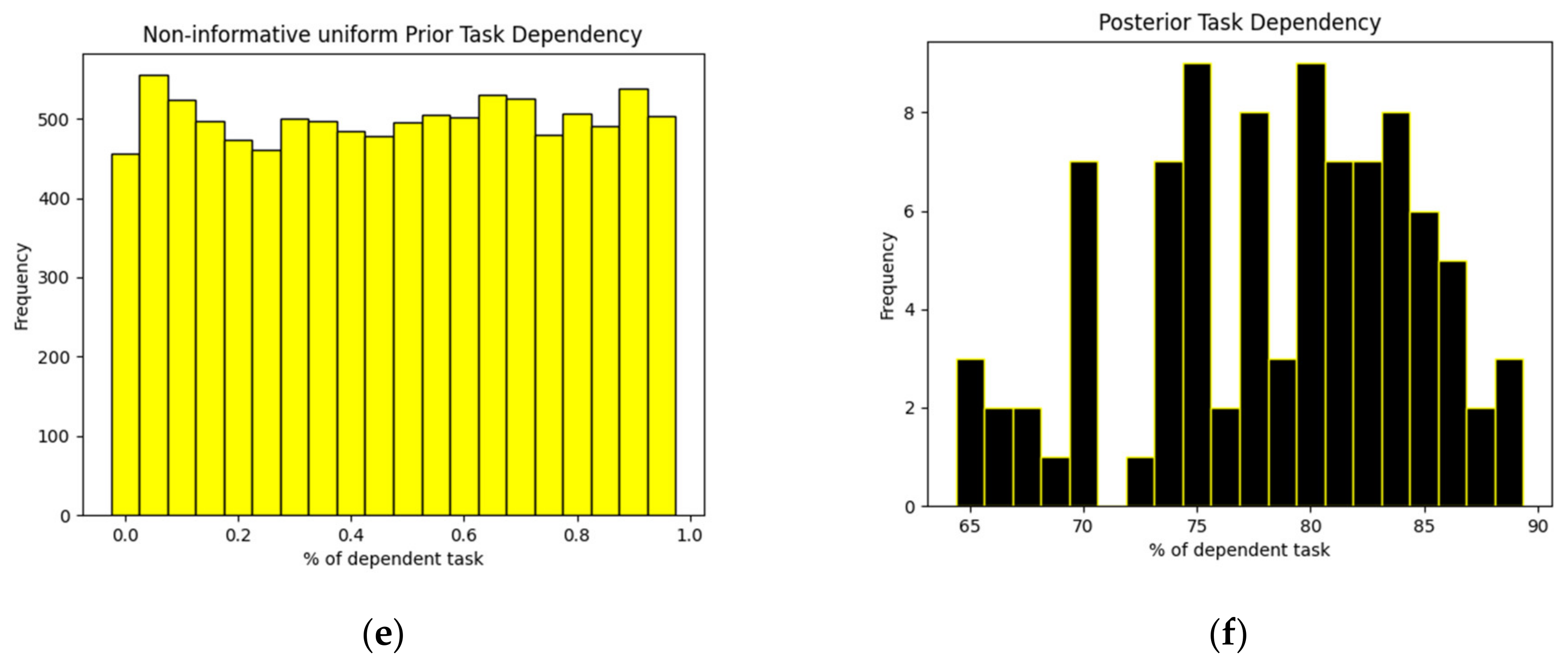
We have applied Bayesian data analysis on a factorial program. The input values for the factorial program contain different ranges. We have taken different parameter values based on assumptions for, e.g., if there are 100 tasks to be processed, we assumed 30 of those are dependent while 70 tasks have no dependencies. We find the probability based on the task dependencies given they are communicating or synchronized or both out of those 30 dependent tasks based on the assumptions. The posterior data generated as an output by the Bayesian model show different ranges, as shown in
Figure 5. We set the non-informative prior for task dependency as uniform where the dependency ratio of the tasks can be any value between 0 and 1. There might be 100% task dependency or it can also be 0%. The different parameters are given as an input to the Bayesian generative model. The total of 100 iterations were run because we took each value in the range of 1 to 100 as an input parameter.
Table 3 shows the results for six different parameter values. Different parameter values are given as an input to the Bayesian generative model along with non-informative uniform priors.
The Bayesian generative model takes different parameter values as inputs and calculates the probability of the task’s dependency based on the parameter value. The dependent tasks based on the communication or synchronization are listed together by the generative model, which are later grouped together in single or multiple clusters.
Once the dependent tasks are listed separately, we make the clusters of similar and independent tasks. The number of clusters equals the number of cores in a heterogeneous multicore architecture. Each output generated by the Bayesian analysis model for different parameters is listed and clusters are made one by one. Now, the mapping of the clusters onto the cores of the multicore architecture is initiated. Two different techniques are applied to ensure maximum load balancing on a heterogeneous system. The first technique used for load balancing puts the tasks from all clusters into a queue where similar or dependent tasks are listed in continuous order. We applied the technique on a factorial program by allocating a larger bunch of tasks to the fastest core based on its processing power. Results show an improvement in the execution time for each individual task and the process as a whole. The throughput of the overall system also increased whereas the waiting time for each task decreased significantly.
Table 4 shows the average execution time of the tasks for our chunk-based technique which is used to find the factorial for a given range of numbers by taking different input parameters from the Bayesian model.
We took each single output from the Bayesian model based on the input parameters and made clusters from identical tasks. We computed the execution time for the factorial of each individual number in the given range listed in the
Table 4 and computed the overall execution time for the whole program.
Figure 6 shows a comparison of the average execution time for the factorial program for the different range of numbers based on the input parameter value.
Results show an improvement in the overall average execution time by applying our chunk-based technique compared to the default operating system scheduler. The average execution time for the whole factorial program was reduced by 32–50% compared to the default OS scheduler. The CBS load balancing technique decreases the total execution time of the factorial program compared to the schedulers used by the operating system.
The results for the average execution time for the factorial program by scheduling the clusters on cores and applying the QBICTM scheduling mechanism by introducing a quantum at the fastest core are presented in
Table 5.
We took different values for the time quantum and found the factorial for a different range of numbers. The quantum based intra-core migration technique is applied on each task generated as output by the Bayesian generative model based on the input parameter values. A time quantum is introduced at the fastest core and each single task gets a fair and equal chance to be processed at the fastest core. When the quantum expires, the intra core migration of tasks takes place as discussed earlier in
Section 2.3. Our load balancing technique outperformed the default OS scheduler in terms of the execution time for the factorial program as it processed the whole program in significantly less time. The reduction in overall execution time for different ranges of numbers is between 30–55%.
Smaller values for the quantum benefit tasks that require to be processed for shorter amounts of time but they increase the average waiting time for tasks that require larger amounts of time on the CPU. As we increase the quantum, the larger tasks benefit and waiting time is reduced. The quantum-based technique increased the context switching of the tasks and it thereby under-performed for some tasks when the quantum value was smaller compared to the chunk-based technique, but execution time slightly improved as compared to the chunk-based scheduler when the quantum value was increased. As shown in
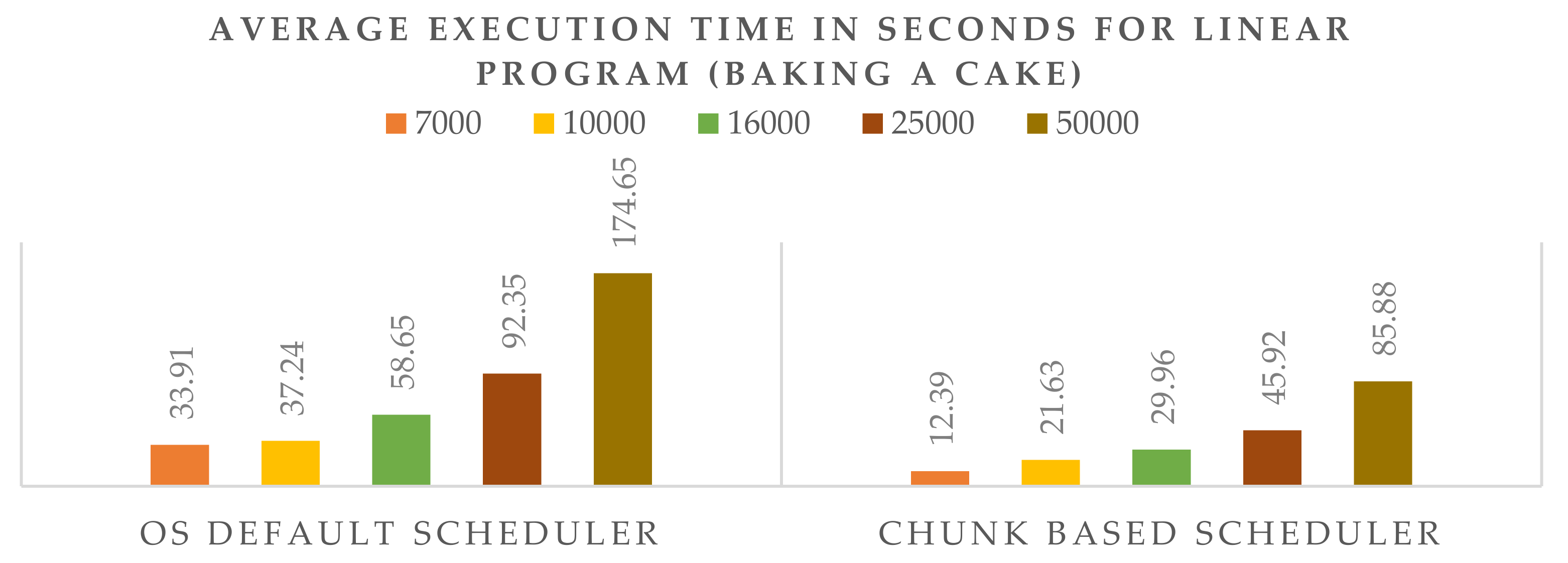
Table 6, we have executed different numbers of tasks for a real-life working example, namely, the ingredients ratio for baking a cake where there are multiple dependent and independent tasks.
We first list the dependent tasks into a group by using the Bayesian model so that, while making chunks, all the dependent tasks are listed serially in contiguous manner. Results show that by using a chunk-based scheduling technique, we are able to reduce the overall execution time of the tasks by an average of 45–51% compared to the scheduler used by the operating system.
Figure 7 shows the average execution time comparison between the CBS and the OS schedulers.
Quantum based scheduling is applied on a real-life working example and the results are shown in
Table 7.
We computed the execution time for different numbers of tasks in a process. Results show an improvement of 44–51% in the overall execution time compared to the traditional operating system scheduler.
Figure 8 shows the average improvement rate in the execution time. We applied the chunk-based scheduling and quantum-based scheduling by comparison with the traditional scheduler used by the operating system. The overall execution time of the tasks improved quite significantly.
Table 8 shows a comparison for average improvement in throughput using different task scheduling techniques in comparison with the schedulers used by the running operating system.
Results show the effectiveness of our proposed schedulers in comparison with other existing state-of-the-art schedulers. The average improvement in the throughput using our proposed schedulers can further be improved if the proposed technique is applied on a multicore machine having a higher core count.
4. Discussion
The proposed schedulers in this study aim to distribute the workload according to each core’s maximum capacity or efficiency. As the cores in the heterogeneous systems usually have different computing speeds, the equal division of the workload might not be as effective as in homogeneous systems. Most of the previous works focus on distributing equal and even workloads among cores but they do not clearly address the load balancing mechanism on heterogeneous systems.
The experimental results conducted in
Section 3 prove the effectiveness of our proposed schedulers. We have presented two different scheduling techniques to ensure load balancing on a heterogeneous system. The load balancing mechanism is based on fair distribution of workload by keeping the processing power of multiple cores in consideration rather than just equal distribution of tasks.
By comparison with other proposed techniques, our affinity-based schedulers have several limitations which direct the future study of our work. The affinity-based scheduling of tasks maximizes the data reuse potential in shared caches. In future work, we will focus on improving the cache hit ratio thus reducing the cache miss penalty. In the QBICTM scheduling technique, the context switching rate significantly increases whenever a quantum at the fastest core expires and the migration of tasks between the cores takes place. We will focus on minimizing the context switching of tasks, which will further improve the average execution time of an overall program.
Despite the mentioned limitations, our proposed schedulers applied load balancing fairly on the heterogeneous system. With the aim of achieving the maximum performance of the system on offer, our proposed schedulers focus on maximizing the utilization of all the processing cores in multicore architectures.
5. Conclusions
We proposed two techniques for scheduling tasks on heterogeneous multicore systems. All the dependent tasks are listed together using a Bayesian analysis model in which the non-informative uniform prior is used. All the input parameters are attached with the prior and passed onto the generative model as an input. The posterior data generated by the Bayesian model contains all the dependent tasks in a list in a contiguous manner and those tasks are passed on to the schedulers. Our CBS lists all the tasks together where dependent tasks are present in a contiguous manner. We then create a number of chunks of tasks of variable sizes, equal to the number of cores available. The largest chunk is assigned to the fastest core and the smallest chunk is allocated to the slowest core in the heterogeneous architecture.
QBICTM is the second proposed load balancing scheduler in our study. Here we have introduced a time quantum at the fastest core which enables each task to have a fair and equal chance of being processed at the fastest core. The migration of tasks is performed by defining a minimum threshold in each core’s queue. When the total number of tasks in a certain queue falls below the defined minimum threshold, the tasks currently being processed are migrated to the queue of the next corresponding core. The only problem with the quantum based intra-core migration of tasks is that it increases the number of context switches, however, it still significantly out-performs the traditional operating system scheduler in terms of the execution and task waiting times.
Our load balancing schedulers outperformed the default OS scheduler in terms of execution time for the factorial program as it processed the whole program in significantly shorter time. The reduction in overall execution time for a process containing different range of numbers is between 30–55% while for an individual task the execution time is reduced by an average of 45–51% using our proposed affinity-based schedulers compared to the scheduler used by the operating system for the real-life example of baking a cake. For future work in this regard, the cache hit rate can be maximized while reducing the cache miss penalty by grouping the tasks into clusters on the basis of the maximum interactions between them.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}