
Two-Pass Technique for Clone Detection and Type Classification Using Tree-Based Convolution Neural Network †


Abstract
:1. Introduction
- We present a novel approach for classifying the clone types, exceptionally well suited to T3 and T4 clones.
- Our technique uses the AST to capture characteristics that reflect common code patterns, which are both scalable and easily generated from code, which saves efforts for preprocessing process.
- We present a two-pass technique consisting of steps in clone detection and clone classification order to improve the performance of clone type classification.
2. Background
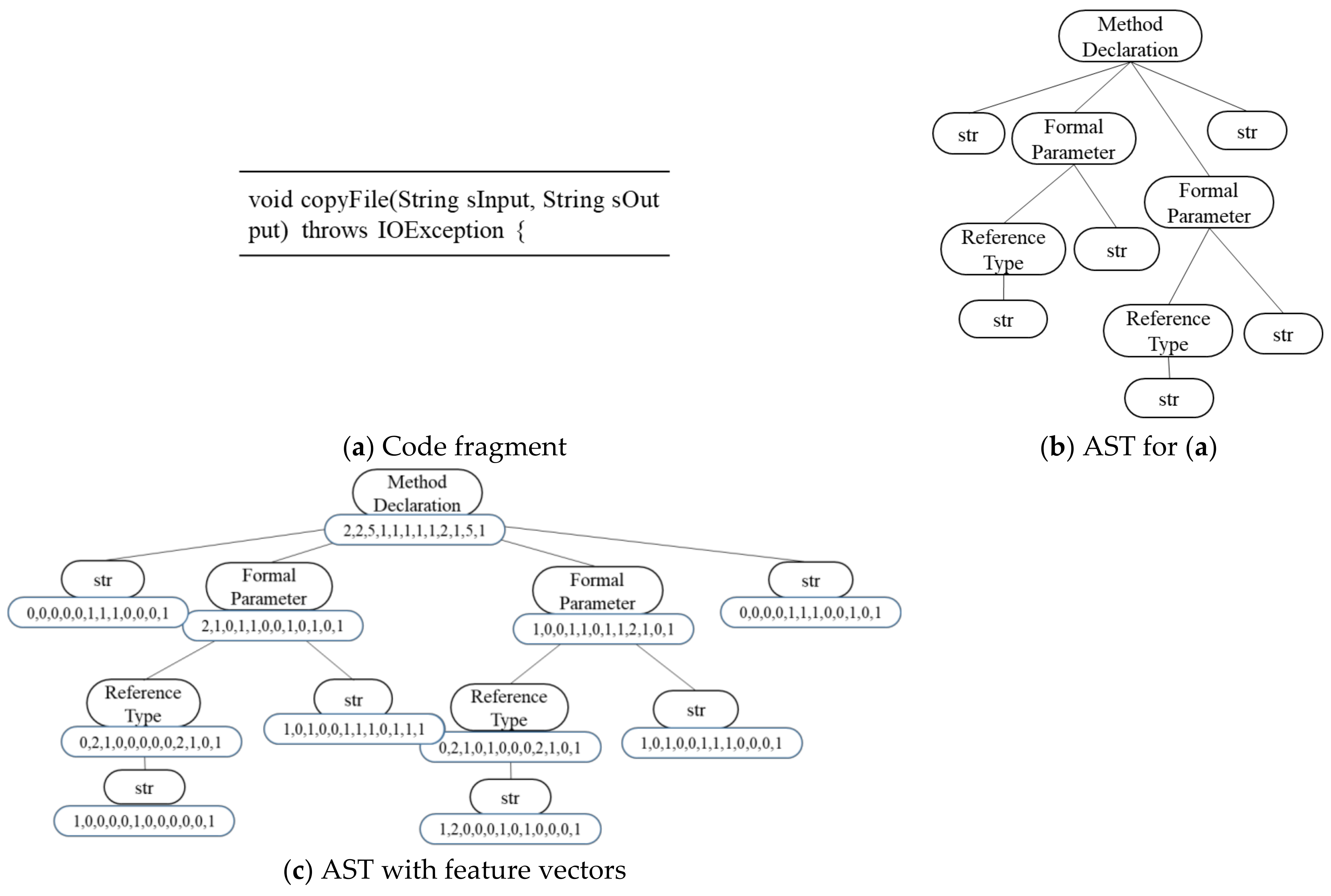
2.1. Abstract Syntax Tree
2.2. Vector Representation of the AST
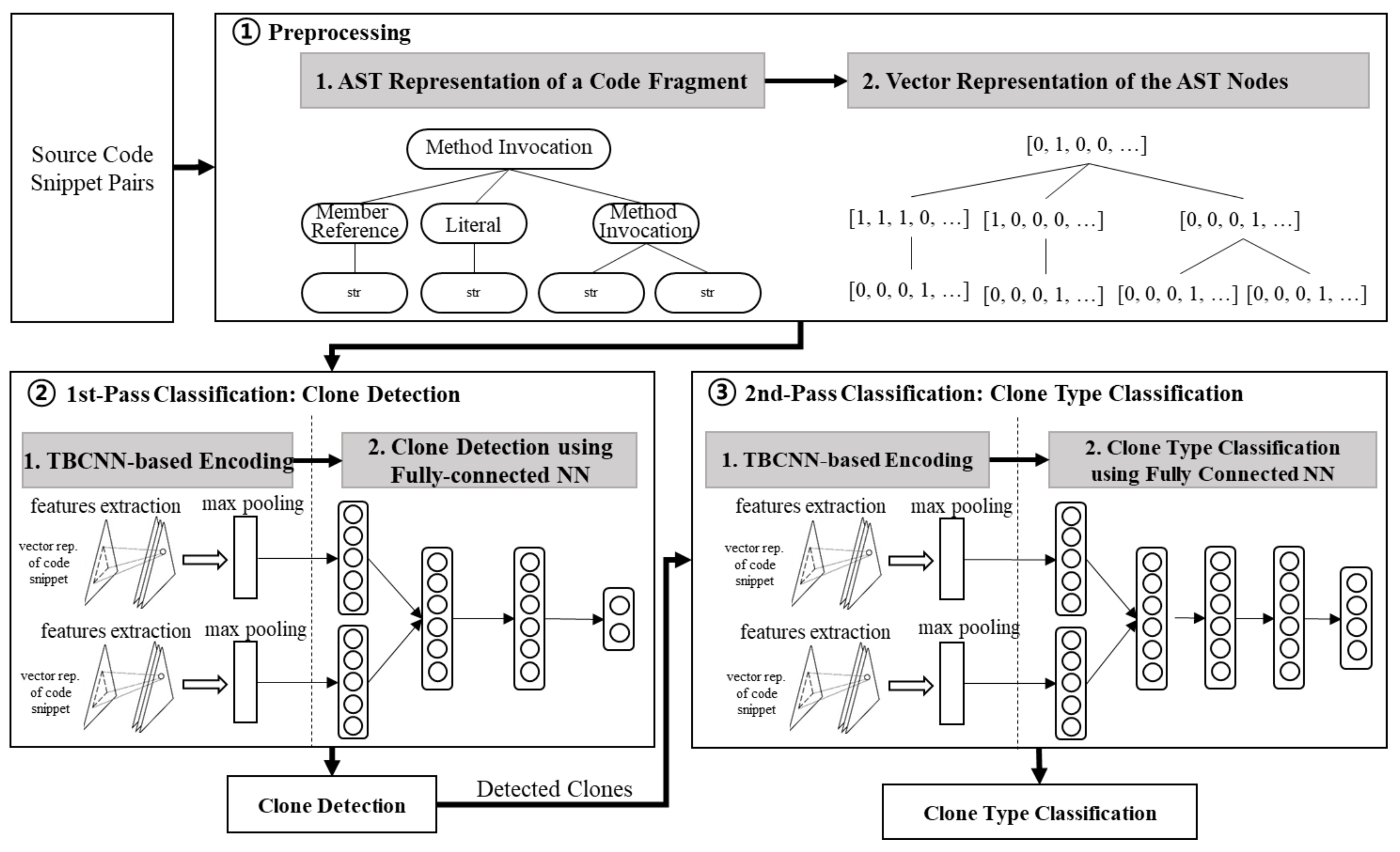
3. TBCNN-Based Two-Pass Clone Type Classification
- The 1st-pass classification (clone detection) determines whether a given piece of code is a clone. This pass detects structural features of a code fragment represented with an AST via TBCNN and applies max pooling to gather information over different parts of the tree. After pooling, the features that are aggregated into a fixed-size vector are fed to a fully-connected hidden layer before introducing the final output layer. For supervised classification, softmax is used as the output layer (see clone detection in Figure 2). The output layer consists of two neurons, clone or non-clone.
- The 2nd-pass classification (clone type classification) classifies the clone code. This pass targets only the code fragments classified as clones during the first pass. This pass again uses TBCNN and max pooling to detect and aggregate features of a clone code fragment. The features are fully connected to a hidden layer and then fed to the output layer (see clone type classification in Figure 2). In this step, the number of neurons of the output layer refers to the number of clone types.
3.1. Preprocessing
3.2. Encoding Using TBCNN
3.3. The 1st-Pass Classification: Clone Detection
3.4. The 2nd-Pass Classification: Clone Type Classification
4. Experimental Evaluation
4.1. Dataset
4.2. Implementation
4.2.1. Training and Test Datasets
4.2.2. Parameter Settings
4.3. Results
5. Discussion
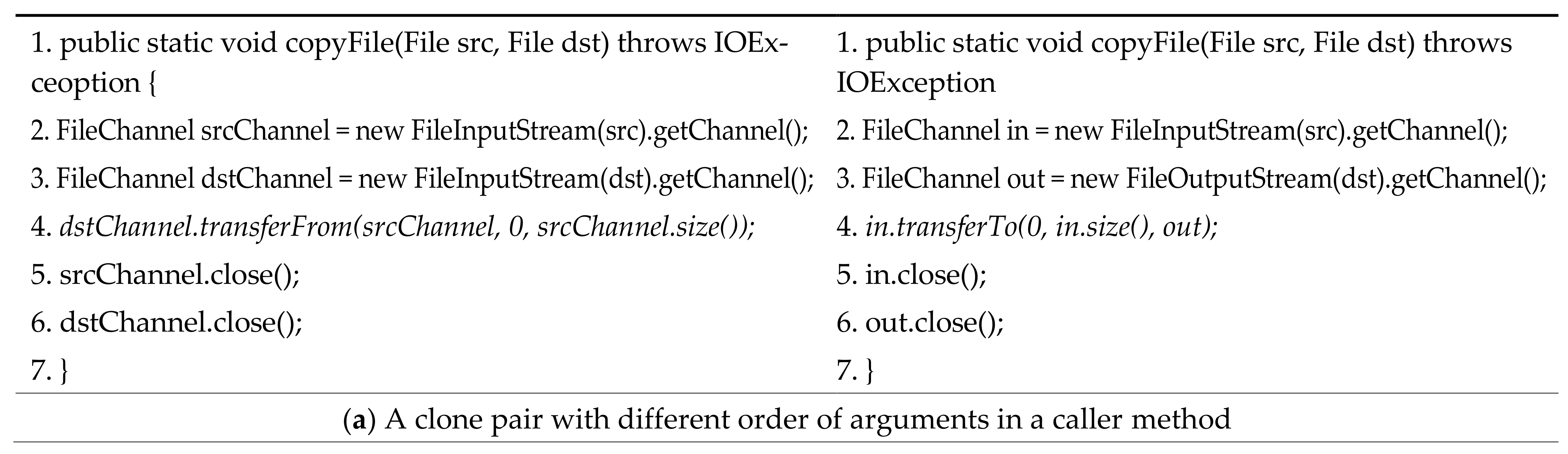
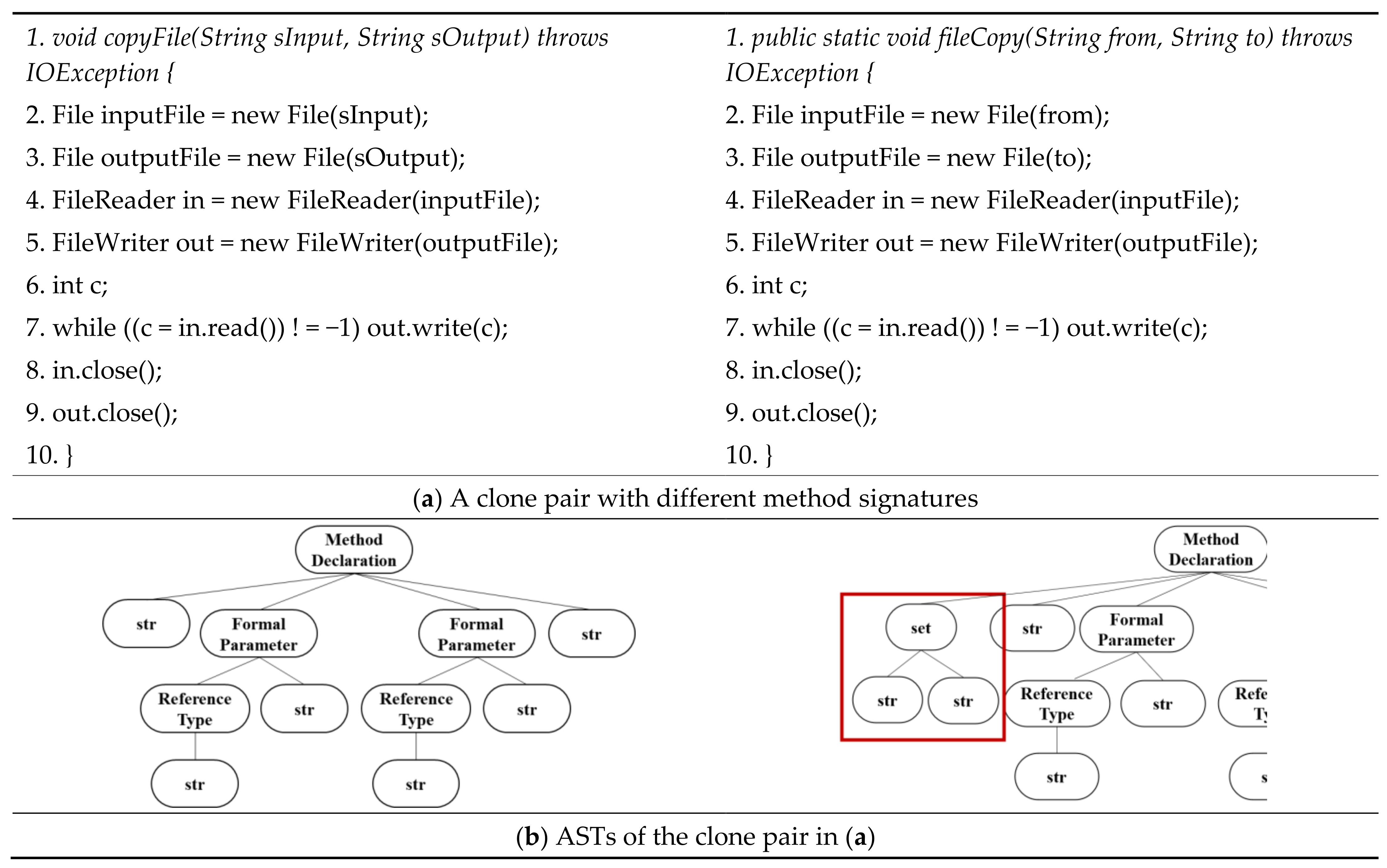
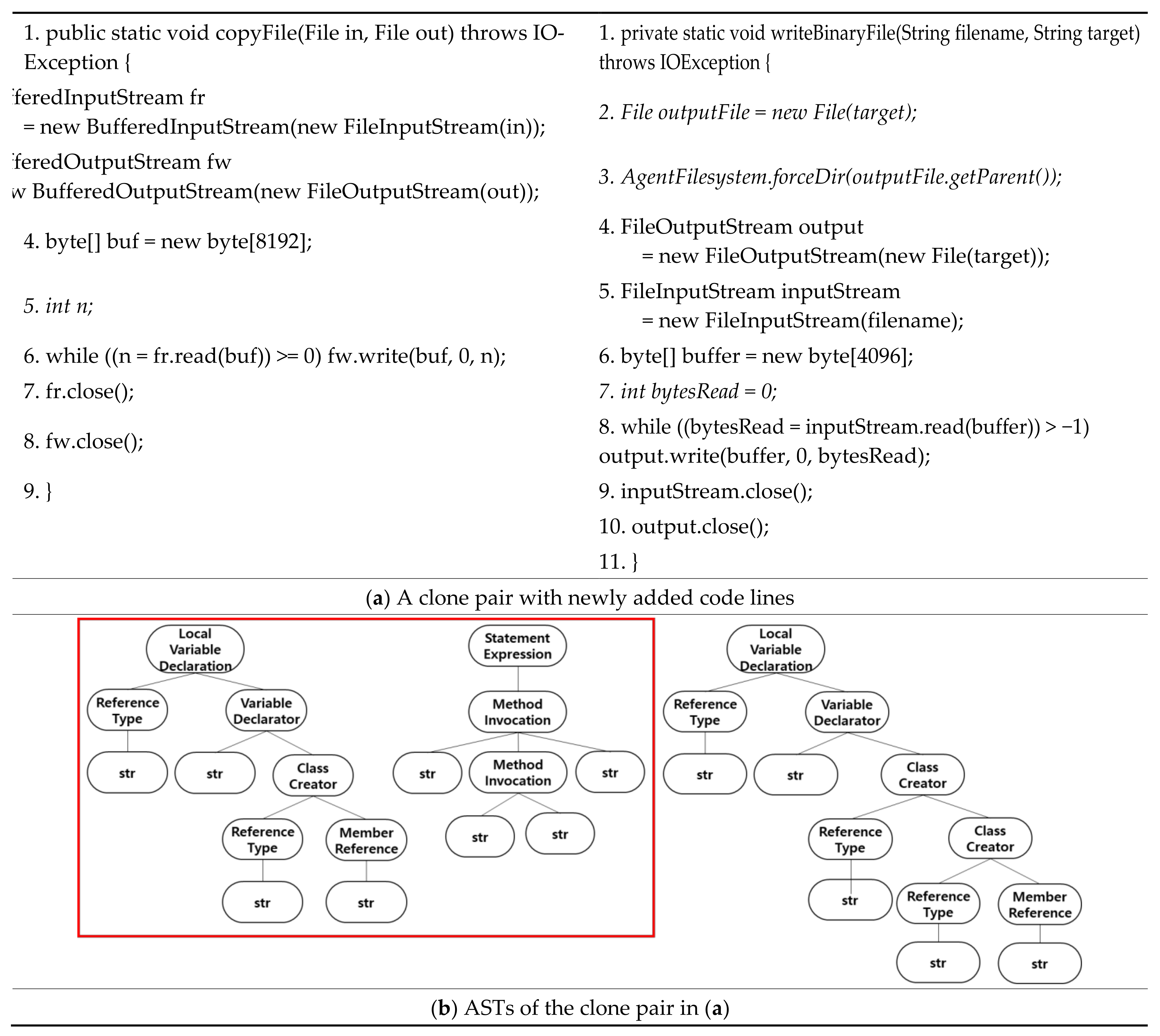
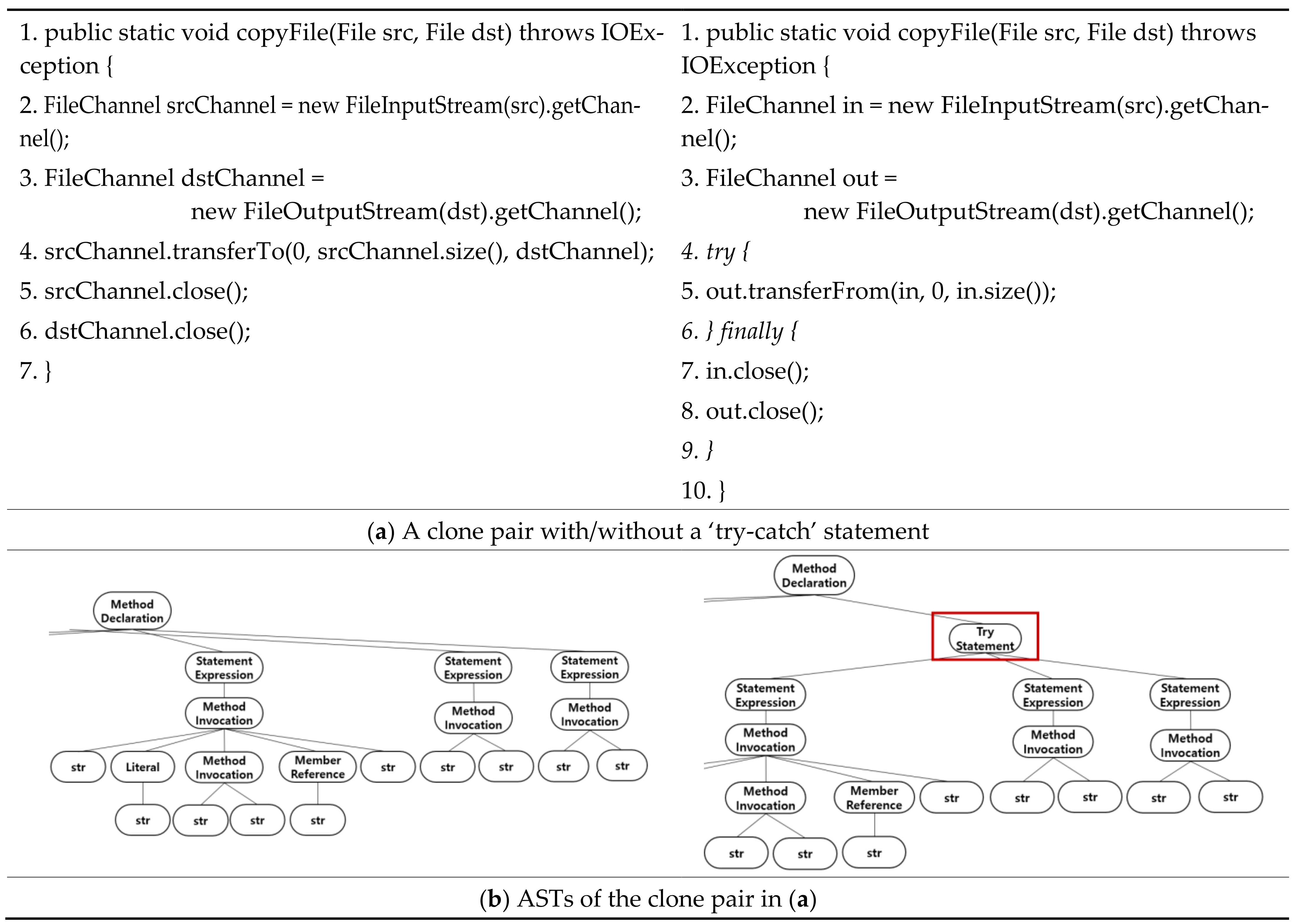
5.1. Clone Pairs Misclassified into T2 Clones
5.2. Clone Pairs Misclassified into ST3 Clones
5.3. Clone Pairs Misclassified into MT3 Clones
5.4. Threats to Validity
6. Related Work
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bellon, S.; Koschke, R.; Antoniol, G.; Krinke, J.; Merlo, E. Comparison and evaluation of clone detection tools. IEEE Trans. Softw. Eng. 2007, 33, 577–591. [Google Scholar] [CrossRef] [Green Version]
- Roy, C.K.; Cordy, J.R.; Koschke, R. Comparison and evaluation of code clone detection techniques and tools: A qualitative approach. Sci. Comput. Program. 2009, 74, 470–495. [Google Scholar] [CrossRef] [Green Version]
- Baker, B. On finding duplication and near-duplication in large software system. In Proceedings of the 2nd IEEE Working Conference on Reverse Engineering, Toronto, ON, Canada, 14–16 July 1995; pp. 86–95. [Google Scholar]
- Kontogiannis, K.; Demori, R.; Merlo, E.; Galler, M.; Bernstein, M. Pattern matching for clone and concept detection. Autom. Softw. Eng. 1996, 3, 76–108. [Google Scholar] [CrossRef]
- Lague, B.; Proulx, D.; Mayrand, J.; Merlo, E.; Hudepohl, J. Assessing the benefits of incorporating function clone detection in a development process. In Proceedings of the 1st IEEE International Conference on Software Maintenance, Bari, Italy, 1–3 October 1997; pp. 314–321. [Google Scholar]
- Chou, A.; Yang, J.; Chelf, B.; Hallem, S.; Engler, D.R. An empirical study of operating system errors. In Proceedings of the 18th ACM Symposium on Operating Systems Principles, Banff, AB, Canada, 21–24 October 2001; pp. 73–88. [Google Scholar]
- Li, Z.; Lu, S.; Myagmar, S.; Zhou, Y. CP-Miner: Finding copy-paste and related bugs in operating system code. IEEE Trans. Softw. Eng. 2006, 32, 289–302. [Google Scholar] [CrossRef]
- Roy, G.K.; Cordy, J.R. A Survey on Software Clone Detection Research. Technical Report No. 2007-541; School of Computing, Queen’s University at Kingston: Kingston, ON, Canada, 2007. [Google Scholar]
- Gautam, P.; Saini, H. Various code clone detection techniques and tools: A comprehensive survey. In Proceedings of the International Conference on Smart Trends for Information Technology and Computer Communications, Jaipur, India, 6–7 August 2016; pp. 665–667. [Google Scholar]
- Staron, M.; Meding, W.; Eriksson, P.; Nilsson, J.; Lövgren, N.; Österström, P. Classifying obstructive and nonobstructive code clones of type I using simplified classification scheme: A case study. Adv. Softw. Eng. 2015, 1–18. [Google Scholar] [CrossRef]
- Murphy, G. An empirical study of code clone genealogies. In Proceedings of the 10th European Software Engineering Conference Held Jointly with 13th ACM SIGSOFT international symposium on Foundations of software engineering, Lisbon, Portugal, 5–9 September 2005; pp. 187–196. [Google Scholar]
- Rattan, D.; Bhatia, R.; Signh, M. Software clone detection: A systematic review. Inf. Softw. Technol. 2003, 55, 1165–1199. [Google Scholar] [CrossRef]
- Mou, L.; Jin, Z. Tree-Based Convolutional Neural Networks Principles and Applications; Springer: Singapore, 2018. [Google Scholar]
- Mou, L.; Li, G.; Zhang, L.; Wang, T.; Jin, Z. Convolution neural networks over tree structures for programming language processing. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 1287–1293. [Google Scholar]
- Svajlenko, J.; Roy, C.K. Evaluating clone detection tools with BigCloneBench. In Proceedings of the IEEE International Conference on Software Maintenance and Evolution, Bremen, Germany, 29 September–1 October 2015; pp. 131–140. [Google Scholar]
- Jiang, L.; Misherghi, G.; Su, Z.; Glondu, S. DECKARD: Scalable and accurate tree-based detection of code clones. In Proceedings of the 29th International Conference on Software Engineering, Minneapolis, MN, USA, 20–26 May 2007; pp. 96–105. [Google Scholar]
- Gabel, M.; Jiang, L.; Su, Z. Scalable detection of semantic clones. In Proceedings of the 30th International Conference on Software Engineering, Leipzig, Germany, 10–18 May 2008; pp. 321–330. [Google Scholar]
- Fang, C.; Liu, Z.; Shi, Y.; Huang, J.; Shi, Q. Functional code clone detection with syntax and semantics fusion learning. In Proceedings of the 29th ACM SIGSOFT International Symposium on Software Testing and Analysis, Virtual Event. New York, NY, USA, 18–22 July 2020; pp. 516–527. [Google Scholar]
- Chen, K.; Liu, P.; Zhang, Y. Achieving accuracy and scalability simultaneously in detecting application clones on android markets. In Proceedings of the 36th International Conference on Software Engineering, Hyderabad, India, 31 May–7 June 2014; pp. 175–186. [Google Scholar]
- Zhao, G.; Huang, J. DeepSim: Deep learning code functional similarity. In Proceedings of the 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Lake Buena Vista, FL, USA, 4–9 November 2018; pp. 141–151. [Google Scholar]
- Alon, U.; Zilberstein, M.; Levy, O.; Yahav, E. code2vec: Learning distributed representations of code. In Proceedings of the ACM on Programming Languages; 2019; 3, pp. 1–29. [Google Scholar]
- Paaßen, B.; McBroom, J.; Jeffries, B.; Koprinska, I.; Yacef, K. ast2vec: Utilizing recursive neural encodings of python programs. In Proceedings of the Educational Data Mining, Paris, France, 29 June–2 July 2021; pp. 1–34. [Google Scholar]
- White, M.; Tufano, M.; Vendome, C.; Poshyvanyk, D. Deep learning code fragments for code clone detection. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering, Singapore, 3–7 September 2016; pp. 87–98. [Google Scholar]
- Wei, H.-H.; Li, M. Supervised deep features for software functional clone detection by exploiting lexical and syntactical information in source code. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, Melbourne, VIC, Australia, 19–25 August 2017; pp. 3034–3040. [Google Scholar]
- Johnson, J. Substring matching for clone detection and change tracking. In Proceedings of the 10th International Conference on Software Maintenance, Victoria, BC, Canada, 19–23 September 1994; pp. 120–126. [Google Scholar]
- Kamiya, T.; Kusumoto, S.; Inoue, K. CCFinder: A multilinguistic token-based code clone detection system for large scale source code. IEEE Trans. Softw. Eng. 2002, 28, 654–670. [Google Scholar] [CrossRef] [Green Version]
- Baxter, I.; Yahin, A.; Moura, L.; Anna, M.S. Clone detection using abstract syntax trees. In Proceedings of the 14th International Conference on Software Maintenance, Bethesda, MD, USA, 20 November 1998; pp. 368–377. [Google Scholar]
- Wahler, V.; Seipel, D.; von Gudenberg, J.W.; Fischer, G. Clone detection in source code by frequent itemset techniques. In Proceedings of the 4th IEEE International Workshop Source Code Analysis and Manipulation, Chicago, IL, USA, 16 September 2004; pp. 128–135. [Google Scholar]
- Evans, W.; Fraser, C. Clone detection via structural abstraction. Softw. Qual. J. 2009, 17, 309–330. [Google Scholar] [CrossRef]
- Komondoor, R.; Horwitz, S. Using slicing to identify duplication in source code. In Proceedings of the 8th International Symposium on Static Analysis, Paris, France, 16–18 July 2001; pp. 40–56. [Google Scholar]
- Krinke, J. Identifying similar code with program dependence graphs. In Proceedings of the 8th Working Conference on Reverse Engineering, Stuttgart, Germany, 2–5 October 2001; pp. 301–309. [Google Scholar]
- Mayrand, J.; Leblanc, C.; Merlo, E. Experiment on the automatic detection of function clones in a software system using metrics. In Proceedings of the 12th International Conference on Software Maintenance, Monterey, CA, USA, 4–8 November 1996; pp. 244–253. [Google Scholar]
- Li, L.; Feng, H.; Zhuang, W.; Meng, N.; Tyder, B. CCLearner: A deep learning-based clone detection approach. In Proceedings of the IEEE International Conference on Software Maintenance and Evolution, Shanghai, China, 17–24 September 2017; pp. 249–260. [Google Scholar]
- Bui, N.D.Q.; Jiang, L.; Yu, Y. Cross-language learning for program classification using bilateral tree-based convolution neural networks. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence Workshop on NLP for Software Engineering, New Orleans, LA, USA, 2–7 February 2018; pp. 758–761. [Google Scholar]
- Perez, D.; Chiba, S. Cross-language clone detection by learning over abstract syntax trees. In Proceedings of the IEEE/ACM 16th International Conference on Mining Software Repositories, Montreal Quebec, QC, Canada, 26–27 May 2019; pp. 518–528. [Google Scholar]
- Sheneamer, A.; Kalita, J. Semantic clone detection using machine learning. In Proceedings of the 15th IEEE International Conference on Machine Learning and Applications, Anaheim, CA, USA, 18–20 December 2016; pp. 1024–1028. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Statistics | Value |
|---|---|
| Number of code fragments | 59,618 |
| Number of code pairs | 97,535 |
| Number of false clone pairs | 20,000 |
| Number of T1 clones | 15,555 |
| Number of T2 clones | 3663 |
| Number of ST3 clones | 18,317 |
| Number of MT3 clones | 20,000 |
| Number of WT3/4 clones | 20,000 |
| Clone Types | True Clone Pairs | False Clone Pairs | |||||
|---|---|---|---|---|---|---|---|
| Dataset | T1 | T2 | ST3 | MT3 | WT3/4 | ||
| Training | 1099 | 1099 | 1099 | 1098 | 1099 | 5492 | |
| Test | 2564 | 2564 | 2564 | 2563 | 2564 | 12,823 | |
| Total | 3663 | 3663 | 3663 | 3661 | 3663 | 18,315 | |
| Classification Pass | Parameters | ||
|---|---|---|---|
| 1st pass | TBCNN-based encoding | Convolution: 1, Pooling layer: 1, Output size: 50 | Learning rate: 0.001, Epoch: 100, Batch size: 5 |
| Fully-connected NN | Input size: 100, Output size: 2, Hidden layer: 2, First hidden layer size: 100, Second hidden layer size: 150, Activation function: LRelu | ||
| 2nd pass | TBCNN-based encoding | Convolution: 4, Pooling layer: 1, Output size: 200 | Learning rate: 0.001, Epoch: 200, Batch size: 5 |
| Fully-connected NN | Input size: 400, Output size: 5, Hidden layer: 3, First hidden layer size: 400, Second hidden layer size: 400, Third hidden layer size: 300, Activation function: LRelu | ||
| Clone Detection Result of the 1st Pass | Clone Type Classification Result of the 2nd Pass | ||||||
|---|---|---|---|---|---|---|---|
| Clone Pairs | Recall | Precision | F1 Score | Clone Type | Recall | Precision | F1 Score |
| true clone | 0.94 | 0.96 | 0.95 | T1 | 0.75 | 0.94 | 0.84 |
| false clone | 0.97 | 0.95 | 0.96 | T2 | 0.93 | 0.77 | 0.84 |
| - | - | - | - | ST3 | 0.71 | 0.69 | 0.70 |
| - | - | - | - | MT3 | 0.58 | 0.67 | 0.62 |
| - | - | - | - | WT3/4 | 0.81 | 0.74 | 0.77 |
| Clone Type | Recall | Precision | F1 Score | |||
|---|---|---|---|---|---|---|
| Without the 1st Pass | With the 1st Pass | Without the 1st Pass | With the 1st Pass | Without the 1st Pass | With the 1st Pass | |
| False clone | 0.73 | 0.97 | 0.78 | 0.77 | 0.76 | 0.86 |
| T1 | 0.76 | 0.75 | 0.90 | 0.95 | 0.82 | 0.84 |
| T2 | 0.89 | 0.93 | 0.77 | 0.78 | 0.73 | 0.85 |
| ST3 | 0.68 | 0.73 | 0.67 | 0.72 | 0.67 | 0.72 |
| MT3 | 0.54 | 0.57 | 0.63 | 0.71 | 0.58 | 0.63 |
| WT3/4 | 0.77 | 0.72 | 0.64 | 0.77 | 0.70 | 0.74 |
| Tools | Clone Detection | Clone Type Classification | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F1 Score | Recall | Precision | F1 Score | |
| DECKARD [16] | 0.02 | 0.93 | 0.3 | - | - | - |
| RtvNN [23] | 0.01 | 0.95 | 0.01 | - | - | - |
| CDLH [24] | 0.74 | 0.92 | 0.82 | - | - | - |
| DeepSim [20] | 0.98 | 0.97 | 0.98 | - | - | - |
| Our Technique | 0.96 | 0.96 | 0.96 | 0.78 | 0.78 | 0.75 |
| Clone Type | False Clone | T1 | T2 | ST3 | MT3 | WT3/4 |
|---|---|---|---|---|---|---|
| false clone | - | 2 | 1 | 138 | 165 | 330 |
| T1 | 7 | - | 2903 | 160 | 13 | 11 |
| T2 | 1 | 61 | - | 160 | 13 | 11 |
| ST3 | 922 | 318 | 1283 | - | 2205 | 407 |
| MT3 | 1687 | 69 | 68 | 3452 | - | 3495 |
| WT3/4 | 2962 | 71 | 15 | 465 | 1841 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jo, Y.-B.; Lee, J.; Yoo, C.-J. Two-Pass Technique for Clone Detection and Type Classification Using Tree-Based Convolution Neural Network. Appl. Sci. 2021, 11, 6613. https://doi.org/10.3390/app11146613
Jo Y-B, Lee J, Yoo C-J. Two-Pass Technique for Clone Detection and Type Classification Using Tree-Based Convolution Neural Network. Applied Sciences. 2021; 11(14):6613. https://doi.org/10.3390/app11146613
Chicago/Turabian StyleJo, Young-Bin, Jihyun Lee, and Cheol-Jung Yoo. 2021. "Two-Pass Technique for Clone Detection and Type Classification Using Tree-Based Convolution Neural Network" Applied Sciences 11, no. 14: 6613. https://doi.org/10.3390/app11146613
APA StyleJo, Y.-B., Lee, J., & Yoo, C.-J. (2021). Two-Pass Technique for Clone Detection and Type Classification Using Tree-Based Convolution Neural Network. Applied Sciences, 11(14), 6613. https://doi.org/10.3390/app11146613