
Inferring Long-Term Demand of Newly Established Stations for Expansion Areas in Bike Sharing System


Abstract
:1. Introduction
- To the best of our knowledge, this is the first work to predict long-term bike demand in batches for expansion areas.
- A G-clustering algorithm, a hierarchical POI clustering method to cluster POI categories, is proposed in this work, and it is shown to be effective. Experiments carried out on real-world datasets prove that our LDA framework outperforms baseline approaches.
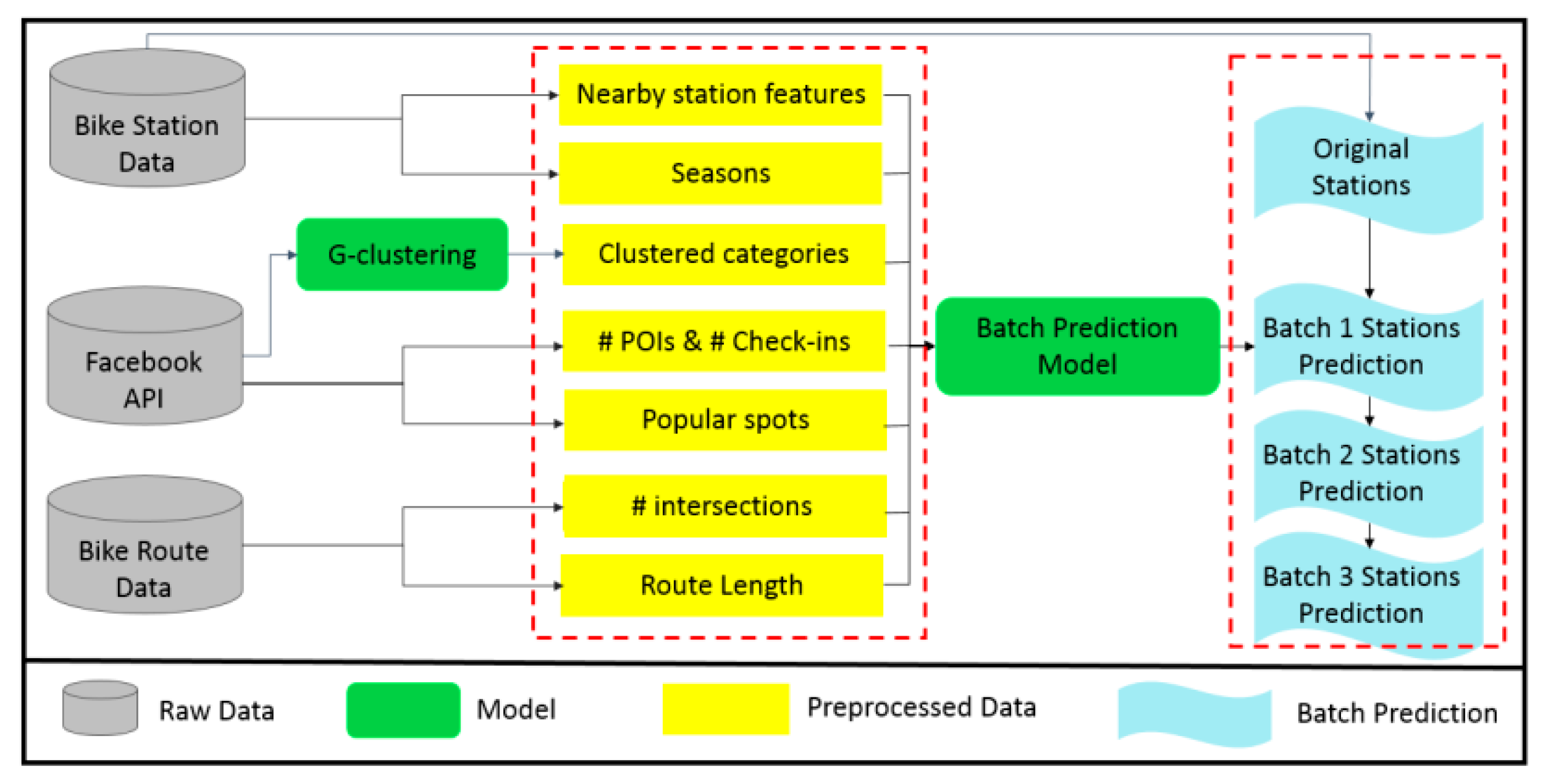
2. Overview
3. Methodology
3.1. Preliminary and Problem Definition
3.2. G-Clustering
| Algorithm 1 G-Clustering Algorithm |
|
Input: C, POI, ; Output:; 1. Cluster POI into clusters: by DBSCAN according to POI geographical locations; 2. Initialize ; 3. for i = 1 : do 4. for j = 1: do 5. if == 1 then 6. += 1; 7. end for 8. Initialize ; 9. for k = 1: m do 10. Category_point = CVF (); 11. idx = [10* Category_point] − 2; 12. append category k; 13. end for 14. function CVF (array A) 15. A_norm = normalized(A); 16. category_value_point = (1 − gini(A_norm)) + ; 17. return category_value_point |
3.3. Feature Extraction
3.4. Batches Prediction
4. Experiments
4.1. Experimental Settings
4.1.1. Baselines
4.1.2. Evaluation Metric
4.2. Batch Prediction Results
4.2.1. Overall Comparison
4.2.2. Region Size Setting for Extracted Features
4.2.3. Feature Importance (FI)
4.2.4. Prediction of Different Periods
4.3. Random Prediction Results
5. Discussion of the Results
6. Related Work
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, S.-Y. Using the Sustainable Modified Tam and Tpb to Analyze the Effects of Perceived Green Value on Loyalty to a Public Bike System. Transp. Res. Part A Policy Pract. 2016, 88, 58–72. [Google Scholar] [CrossRef]
- Cohen, B.; Kietzmann, J. Ride On! Mobility Business Models for the Sharing Economy. Organ. Environ. 2014, 27, 279–296. [Google Scholar] [CrossRef]
- Eckhardt, G.M.; Bardhi, F. The Sharing Economy Isn’t About Sharing at All. Harv. Bus. Rev. 2015, 28, 881–898. [Google Scholar]
- Schor, J.B.; Fitzmaurice, C.J. Collaborating and Connecting: The Emergence of the Sharing Economy. Handb. Res. Sustain. Consum. 2015, 26, 410–425. [Google Scholar]
- Alvarez-Valdes, R.; Belenguer, J.M.; Benavent, E.; Bermudez, J.D.; Muñoz, F.; Vercher, E.; Verdejo, F. Optimizing the level of service quality of a bike-sharing system. Omega 2016, 62, 163–175. [Google Scholar] [CrossRef]
- Kalvapalli, S.P.K.; Chelliah, M. Analysis and Prediction of City-Scale Transportation System Using XGBOOST Technique. In Recent Developments in Machine Learning and Data Analytics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 341–348. [Google Scholar]
- Li, Y.; Zheng, Y.; Zhang, H.; Chen, L. Traffic prediction in a bike-sharing system. In Proceedings of the 23rd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; pp. 1–10. [Google Scholar]
- Liu, J.; Sun, L.; Chen, W.; Xiong, H. Rebalancing bike sharing systems: A multi-source data smart optimization. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1005–1014. [Google Scholar]
- Feng, Y.; Affonso, R.C.; Zolghadri, M. Analysis of bike sharing system by clustering: The Vélib’case. IFAC-PapersOnLine 2017, 50, 12422–12427. [Google Scholar] [CrossRef]
- Lin, L.; He, Z.; Peeta, S. Predicting station-level hourly demand in a large-scale bike-sharing network: A graph convolutional neural network approach. Transp. Res. Part C Emerg. Technol. 2018, 97, 258–276. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Sun, L.; Li, Q.; Ming, J.; Liu, Y.; Xiong, H. Functional zone based hierarchical demand prediction for bike system expansion. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 957–966. [Google Scholar]
- Long, Y.; Shen, Z. Discovering functional zones using bus smart card data and points of interest in Beijing. In Geospatial Analysis to Support Urban Planning in Beijing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 193–217. [Google Scholar]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering urban functional zones using latent activity trajectories. IEEE Trans. Knowl. Data Eng. 2014, 27, 712–725. [Google Scholar] [CrossRef]
- Gini, C. Measurement of Inequality of Incomes. Econ. J. 1921, 31, 124–126. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acmsigkdd, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Qiu, L.-Y.; He, L.-Y. Bike Sharing and the Economy, the Environment, and Health-Related Externalities. Sustainability 2018, 10, 1145. [Google Scholar] [CrossRef] [Green Version]
- Brunner, H.; Hirz, M.; Hirshberg, W.; Fallast, K. Evaluation of various means of transport for urban areas. Energy Sustain. Soc. 2018, 8, 9. [Google Scholar] [CrossRef] [Green Version]
- Lu, M.; Hsu, S.-C.; Chen, P.-C.; Lee, W.-Y. Improving the sustainability of integrated transportation system with bike-sharing: A spatial agent-based approach. Sustain. Cities Soc. 2018, 41, 44–51. [Google Scholar] [CrossRef]
- Jia, L.; Liu, X.; Liu, Y. Impact of Different Stakeholders of Bike-Sharing Industry on Users’ Intention of Civilized Use of Bike-Sharing. Sustainability 2018, 10, 1437. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Lierop, D.V.; Ettema, D. Dockless bike-sharing systems: What are the implications? Transp. Rev. 2020, 40, 333–353. [Google Scholar] [CrossRef]
- Bieliński, T.; Ważna, A. New Generation of Bike-Sharing Systems in China: Lessons for European Cities. J. Manag. Financ. Sci. 2018, 11, 25–42. [Google Scholar]
- Tang, T.; Guo, Y.; Zhou, X.; Labi, S.; Zhu, S. Understanding electric bike riders’ intention to violate traffic rules and accident proneness in China. Travel Behav. Soc. 2021, 23, 25–38. [Google Scholar] [CrossRef]
- Yu, Y.; Yi, W.; Feng, Y.; Liu, J. Understanding the Intention to Use Commercial Bike-sharing Systems: An Integration of TAM and TPB. The Sharing Economy. In Proceedings of the 51st Hawaii International Conference on System Sciences, Waikoloa, Big Island, HI, USA, 3–6 January 2018. [Google Scholar]
- Zhou, X.; Wang, M.; Li, D. Bike-sharing or taxi? Modeling the choices of travel mode in Chicago using machine learning. J. Transp. Geogr. 2019, 79, 102479. [Google Scholar] [CrossRef]
- Nikiforiadis, A.; Ayfantopoulou, G.; Stamelou, A. Assessing the Impact of COVID-19 on Bike-Sharing Usage: The Case of Thessaloniki, Greece. Sustainability 2020, 12, 8215. [Google Scholar] [CrossRef]
- Teixeria, J.F.; Lopes, M. The link between bike sharing and subway use during the COVID-19 pandemic: The case-study of New York’s Citi Bike. Transp. Res. Interdiscip. Perspect. 2016, 6, 100166. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wang, D.; Chen, K.; Zha, Y.; Bi, G. Optimal pricing and availability strategy of a bike-sharing firm with time-sensitive customers. J. Clean. Prod. 2019, 228, 208–221. [Google Scholar] [CrossRef]
- Liu, J.; Li, Q.; Qu, M.; Chen, W.; Yang, J.; Xiong, H.; Zhong, H.; Fu, Y. Station site optimization in bike sharing systems. In Proceedings of the 2015 IEEE International Conference on Data Mining, Atlantic City, NJ, USA, 15–17 November 2015; pp. 883–888. [Google Scholar]
- Martinez, L.M.; Caetano, L.; Eiró, T.; Cruz, F. An optimisation algorithm to establish the location of stations of a mixed fleet biking system: An application to the city of Lisbon. Procedia-Soc. Behav. Sci. 2012, 54, 513–524. [Google Scholar] [CrossRef] [Green Version]
- Cao, J.X.; Xue, C.C.; Jian, M.Y.; Yao, X.R. Research on the station location problem for public bicycle systems under dynamic demand. Comput. Ind. Eng. 2019, 127, 971–980. [Google Scholar] [CrossRef]
- Gast, N.; Massonnet, G.; Reijsbergen, D.; Tribastone, M. Probabilistic forecasts of bike-sharing systems for journey planning. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, Australia, 18–23 October 2015; pp. 703–712. [Google Scholar]
- Chen, L.; Zhang, D.; Wang, L.; Yang, D.; Ma, X.; Li, S.; Wu, Z.; Pan, G.; Nguyen, T.M.; Jakubowicz, J. Dynamic cluster-based over-demand prediction in bike sharing systems. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 841–852. [Google Scholar]
- Liu, Z.; Shen, Y.; Zhu, Y. Inferring dockless shared bike distribution in new cities. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 378–386. [Google Scholar]
- Singla, A.; Santoni, M.; Bartók, G.; Mukerji, P.; Meenen, M.; Krause, A. Incentivizing users for balancing bike sharing systems. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Vogel, P.; Greiser, T.; Mattfeld, D.C. Understanding bike-sharing systems using data mining: Exploring activity patterns. Procedia-Soc. Behav. Sci. 2011, 20, 514–523. [Google Scholar] [CrossRef] [Green Version]
- Eren, E.; Uz, V.E. A review on bike-sharing: The factors affecting bike-sharing demand. Sustain. Cities Soc. 2020, 54, 101882. [Google Scholar] [CrossRef]
- Schuijbroek, J.; Hampshire, R.C.; van Hoeve, W.-J. Inventory rebalancing and vehicle routing in bike sharing systems. Eur. J. Oper. Res. 2017, 257, 992–1004. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Wu, E.; Tan, A.-H. Analysis of Public Transportation Patterns in a Densely Populated City with Station-based Shared Bikes. In Proceedings of the 3rd International Conference on Crowd Science and Engineering, Singapore, 28–31 July 2018; pp. 1–8. [Google Scholar]
- Hoang, M.X.; Zheng, Y.; Singh, A.K. FCCF: Forecasting citywide crowd flows based on big data. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, 31 October–3 November 2016; pp. 1–10. [Google Scholar]
- Yang, Z.; Hu, J.; Shu, Y.; Cheng, P.; Chen, J.; Moscibroda, T. Mobility modeling and prediction in bike-sharing systems. In Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services, Singapore, 26–30 June 2016; pp. 165–178. [Google Scholar]
- Etienne, C.; Latifa, O. Model-based count series clustering for bike sharing system usage mining: A case study with the Vélib’system of Paris. ACM Trans. Intell. Syst. Technol. (TIST) 2014, 5, 1–21. [Google Scholar] [CrossRef]
- Liu, L.; Hu, Z.; Zhou, C.; Xu, G. Research on the clustering algorithm of the bicycle stations based on OPTICS. Concurr. Comput. Pract. Exp. 2019, 31, e4876. [Google Scholar] [CrossRef]
- Hulot, P.; Aloise, D.; Jena, S.D. Towards station-level demand prediction for effective rebalancing in bike-sharing systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 378–386. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| S | The station set S = {S1, S2, …Sn} |
| C | The category set C = {CT1, CT2, …CTm} |
| POI | The POI set POI = {P1, P2, …Pl} |
| R | The bike route set R = {R1, R2, …Rk} |
| n, m, l, k | Number of stations/categories/POIs/bike routes |
| Si | The feature set of ith station |
| Si·rent | Rental demand for Si six months after the establishment |
| Si·drop | Drop-off demand for Si six months after the establishment |
| Si·lat | Latitude of Si |
| Si·long | Longitude of Si |
| Si·date | The established date (e.g., operating date) of Si |
| CS (Si, Sj) | Cosine similarity between Si and Sj |
| Pl×m | Category matrix corresponding to POIs |
| POI Categories | ||
|---|---|---|
| DBSCAN | K-Means | |
| Cluster 1 | Reptile Per Store, Boat/Sailing, Instructor, Night Market | Archery Shop, Night Market, Squash Court |
| Cluster 2 | Art Gallery, Local Business, Arts and Entertainment | Consulate and Embassy |
| Cluster 3 | Elementary School, Language School, Lawyer and Law Firm | Art Gallery, Airport Lounge, Airport Terminal, Cruise Line |
| Cluster 4 | Travel Service, Video Game, Junior High School, Public Swimming Pool | Surfing Spot, Landmark and Historical Place, College and University |
| Cluster 5 | Music Video, Skate Shop, Football Stadium Education Company | Junior High School, Lawyer and Law Firm, Taxi Service |
| Cluster 6 | Aquarium, Diagnostic Center, Drive-In Movie Theater | Public Swimming Pool, Bus Station, Supermarket, Pizza Place |
| Cluster 7 | Fitness Venue, Hockey Arena, Retail Bank | Gas Station, Catholic Church |
| Features | |
| Feature Name | Description |
| POIs | #POIs in Facebook |
| check-ins | # check-ins in Facebook |
| Nearby station features | The difference of establishing dates, the number of cumulative demands, and the Euclidean distance between the target location and their nearby stations |
| G-clustering (DBSCAN) | Category clustering results by applying DBSCAN |
| G-clustering(K-means) | Category clustering results by applying K-means |
| Bike route structure | Sum of total route length and the number of intersections of bike routes in the reachable region of the station |
| Season | Operating seasons |
| New York Citi Bike System | ||||
|---|---|---|---|---|
| Time Span | Origin | Batch 1 | Batch 2 | Batch 3 |
| June 2013~June 2015 | August 2015~September 2015 | August 2016~September 2016 | September 2017~October 2017 | |
| # Stations | 329 | 121 | 127 | 97 |
| Facebook Place API | ||||
| # Check-ins | 175+ billion | |||
| # POI Categories | 1279 | |||
| New York Bike Route | ||||
| # Intersections | 26,868 | |||
| Total Length | 1300+ km | |||
| Feature Set | Features | |||||
|---|---|---|---|---|---|---|
| I + II | III | IV-D | IV-K | V | VI | |
| A | ■ | ■ | ||||
| B | ■ | ■ | ||||
| C | ■ | ■ | ■ | ■ | ||
| D | ■ | ■ | ■ | |||
| E | ■ | ■ | ■ | ■ | ||
| F | ■ | ■ | ■ | ■ | ■ | |
| G | ■ | ■ | ■ | ■ | ■ | |
| CC-XGB | ■ | ■ | ■ | ■ | ■ | ■ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsieh, H.-P.; Lin, F.; Jiang, J.; Kuo, T.-Y.; Chang, Y.-E. Inferring Long-Term Demand of Newly Established Stations for Expansion Areas in Bike Sharing System. Appl. Sci. 2021, 11, 6748. https://doi.org/10.3390/app11156748
Hsieh H-P, Lin F, Jiang J, Kuo T-Y, Chang Y-E. Inferring Long-Term Demand of Newly Established Stations for Expansion Areas in Bike Sharing System. Applied Sciences. 2021; 11(15):6748. https://doi.org/10.3390/app11156748
Chicago/Turabian StyleHsieh, Hsun-Ping, Fandel Lin, Jiawei Jiang, Tzu-Ying Kuo, and Yu-En Chang. 2021. "Inferring Long-Term Demand of Newly Established Stations for Expansion Areas in Bike Sharing System" Applied Sciences 11, no. 15: 6748. https://doi.org/10.3390/app11156748
APA StyleHsieh, H.-P., Lin, F., Jiang, J., Kuo, T.-Y., & Chang, Y.-E. (2021). Inferring Long-Term Demand of Newly Established Stations for Expansion Areas in Bike Sharing System. Applied Sciences, 11(15), 6748. https://doi.org/10.3390/app11156748