
Outlier Detection Based Feature Selection Exploiting Bio-Inspired Optimization Algorithms


Abstract
:1. Introduction
2. Contributions and Research Objectives
- Suggesting a new FS method based on PP, a well-known outlier detection technique.
- Providing a one-stage approach based on detecting and removing outliers that correspond to the irrelevant features.
- Discovering relevant features using optimization methods based on common bio-inspired algorithms, algorithms (GA) and a variant of PSO (Tribes).
- Providing a software-based outlier-detection method to determine and remove the non-relevant features.
- Investigate the limitations of the existing FS techniques.
- Develop a new model for FS based on PP (called PPFS) to enhance the classification accuracy.
- Propose four different PPFS methods based on two optimization methods (GA and Tribes) and two PP indices (Kurtosis and Friedman).
- Suggest the use of EPP-Lab to select the non-relevant features.
- Investigate a statistical analysis to show that the four PPFS methods are equivalent and their results are statistically significant compared to the state-of-the-art methods.
- Perform a comparison study with the state-of-the-art methods to confirm the efficiency of the proposed model.
3. Review of Related Literature
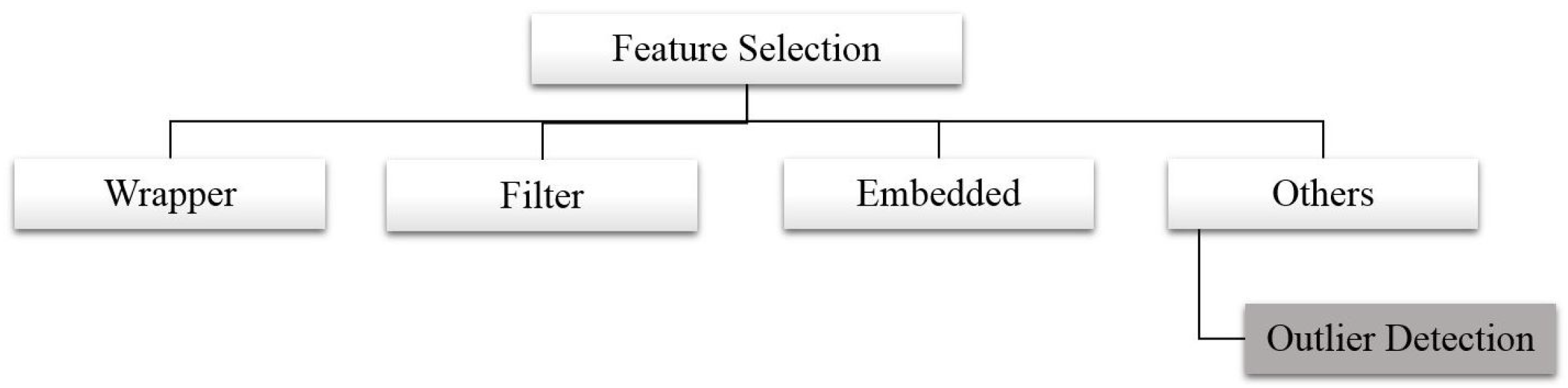
3.1. Wrapper Feature Selection Methods
3.2. Filter Feature Selection Methods
3.3. Embedded Feature Selection Methods
3.4. Outlier Feature Selection Methods
3.5. Discussion
- The embedded FS methods are not well investigated due to their complex structure.
- The combination of wrapper FS with outlier detection [21,29] is a two-stage approach that works by reducing the features and then removing the outliers. This approach is time consuming due to the limitation of wrapper FS. In addition, the knowledge of wrapper FS and outlier detection are both required.
4. Projection Pursuit
4.1. Friedman Index
4.2. Kurtosis Index
5. Optimization Methods
5.1. Genetic Algorithms
5.2. Particle Swarm Optimization
5.3. Tribes
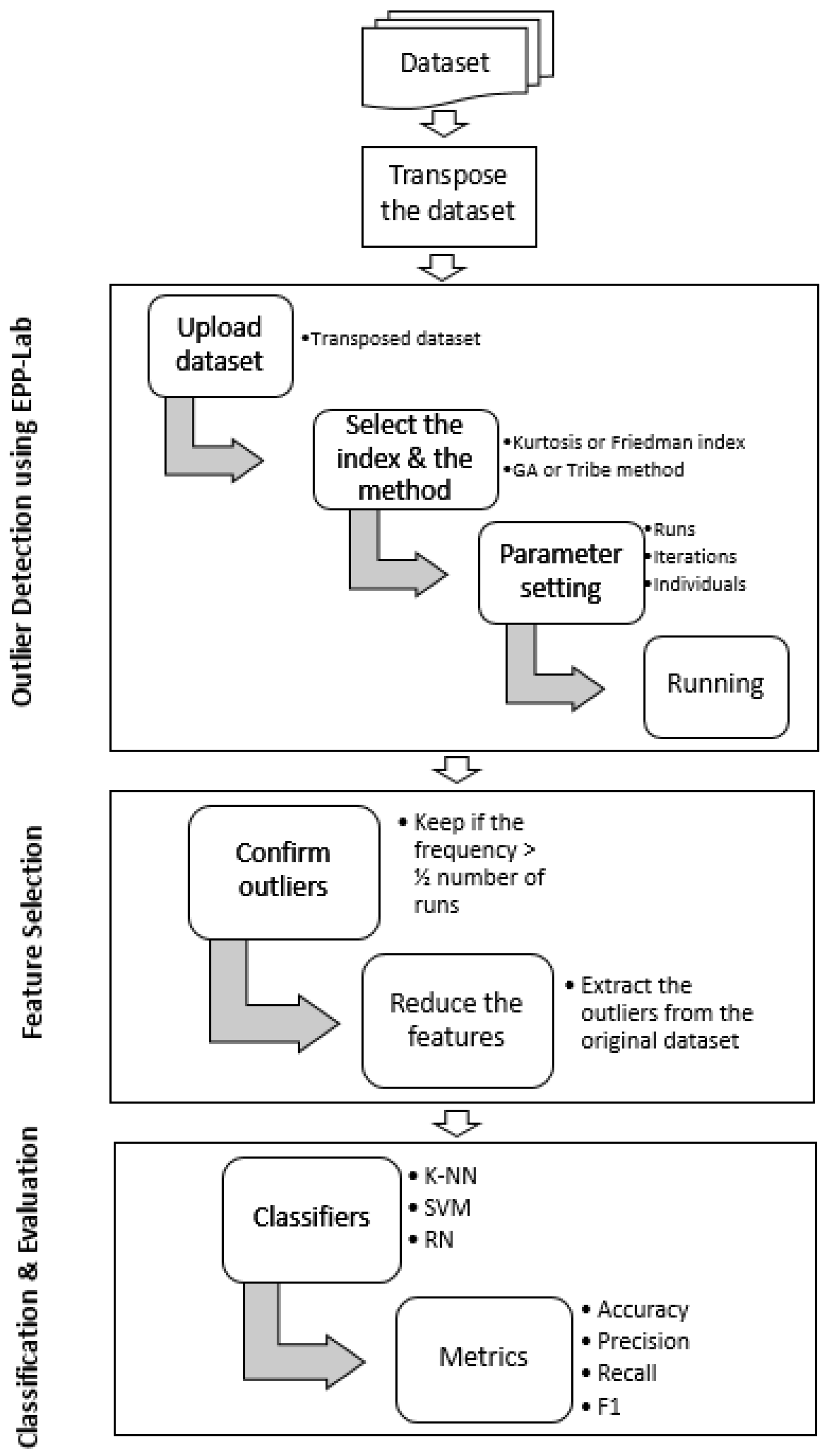
6. Methodology
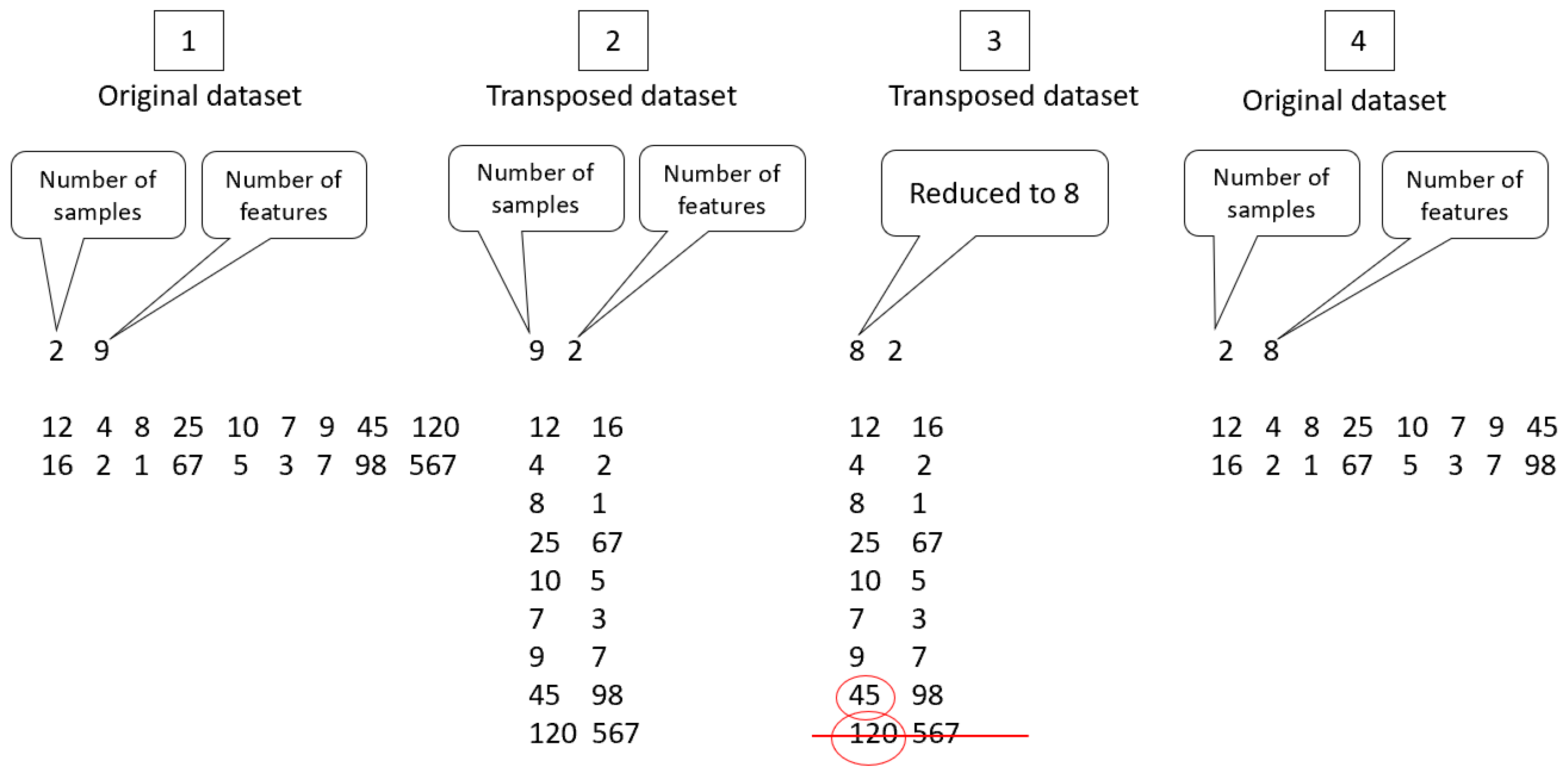
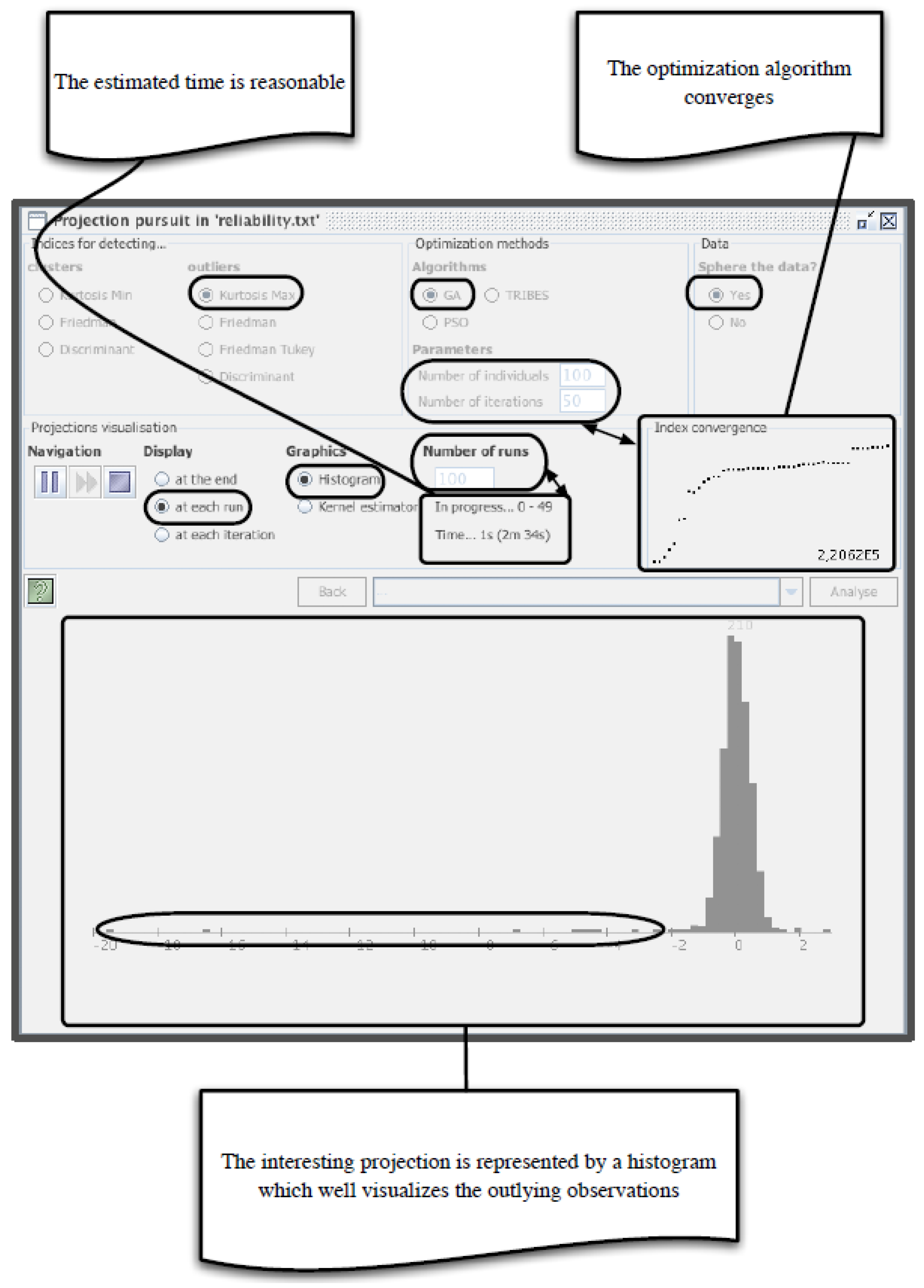
6.1. Outlier Detection
Outlier Detection Using EPP-Lab
6.2. Feature Selection
6.3. Classification
6.4. Validation
7. Experimentation Results
7.1. Projection-Pursuit-Based Feature-Selection Techniques
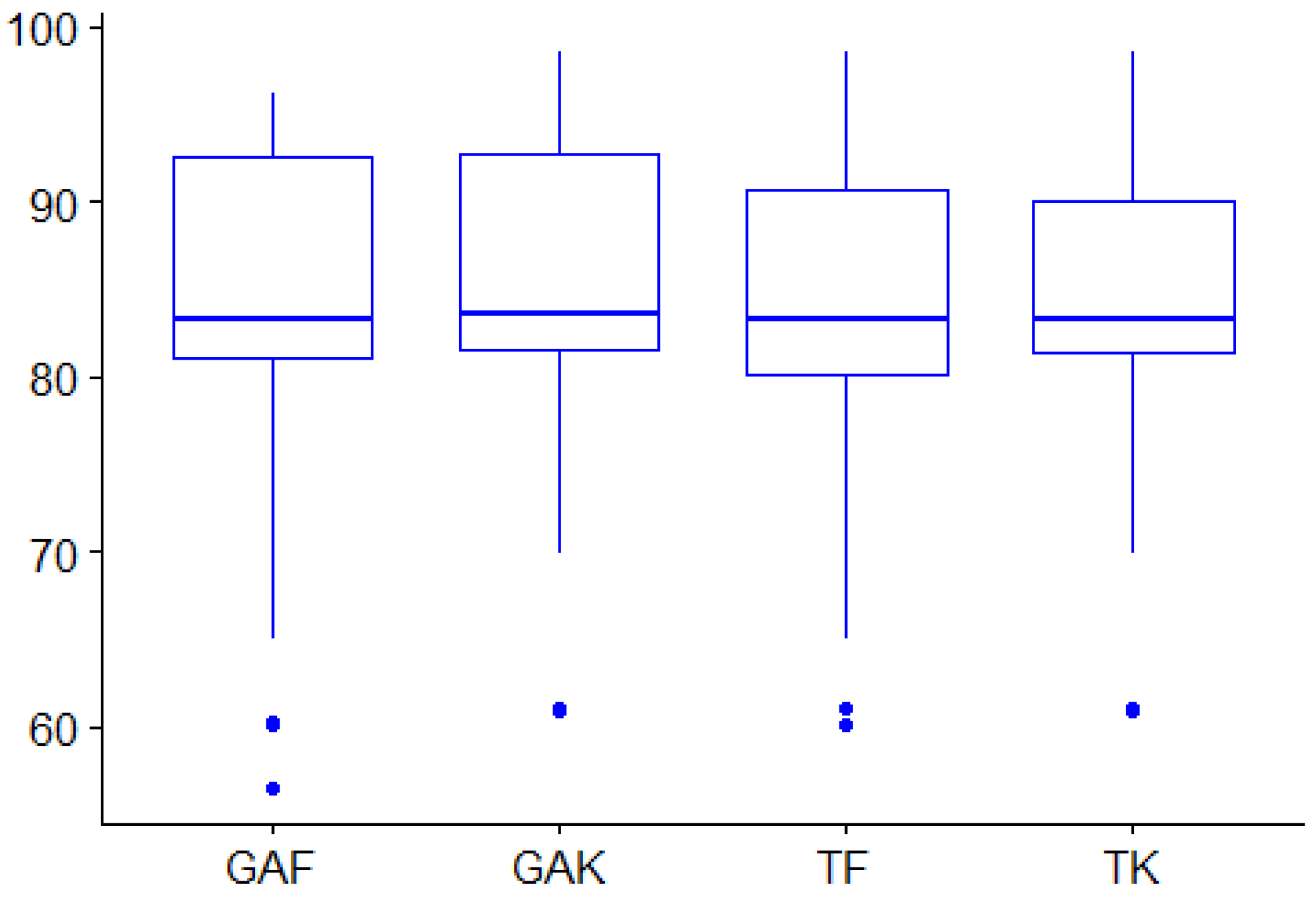
7.2. What Is the Best PPFS Technique?
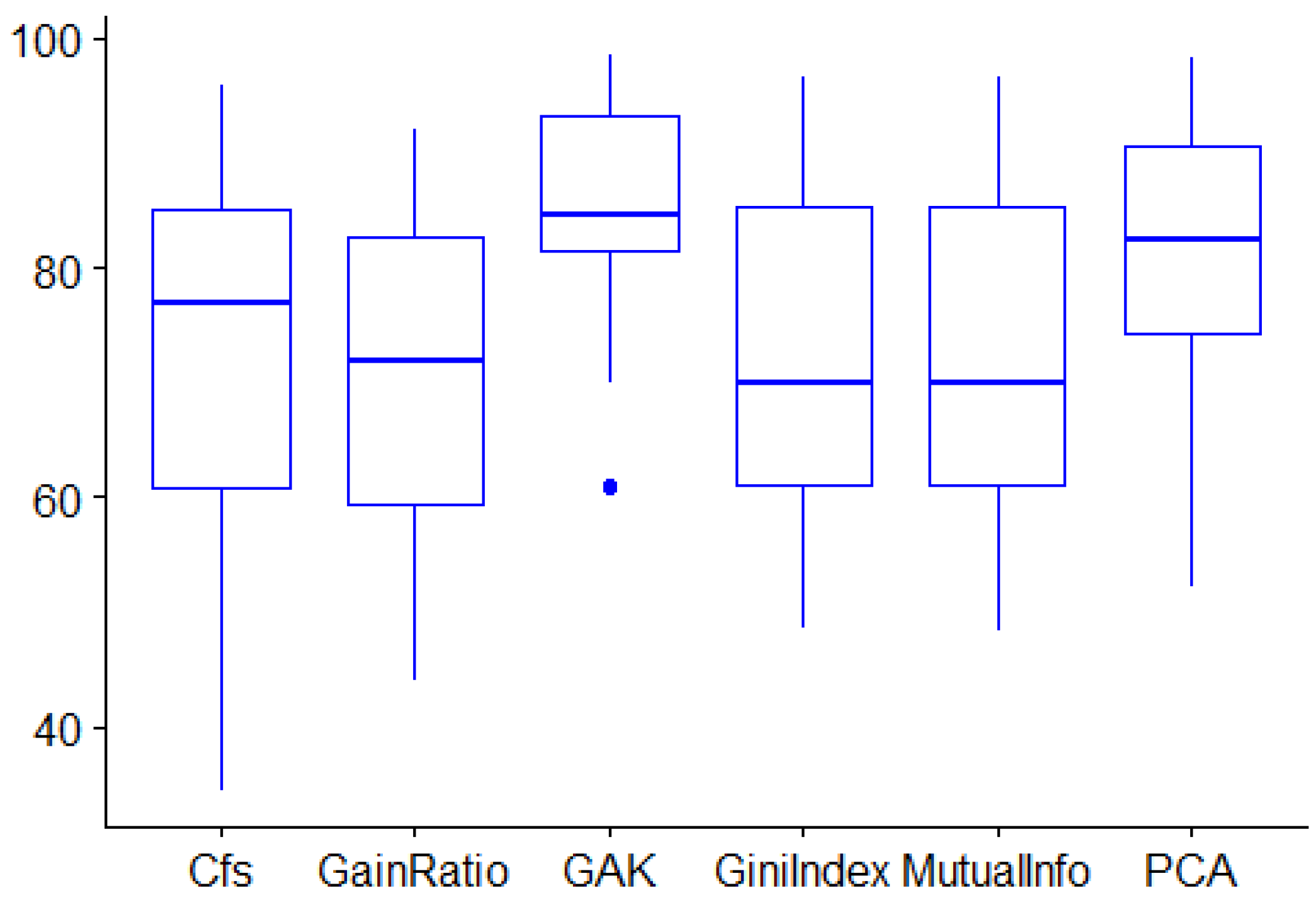
7.3. Comparison Study
7.4. Discussion
7.4.1. Research Impacts
- They contribute to the scientific society by providing a new PPFS model that overcomes the limitations of the existing FS methods.
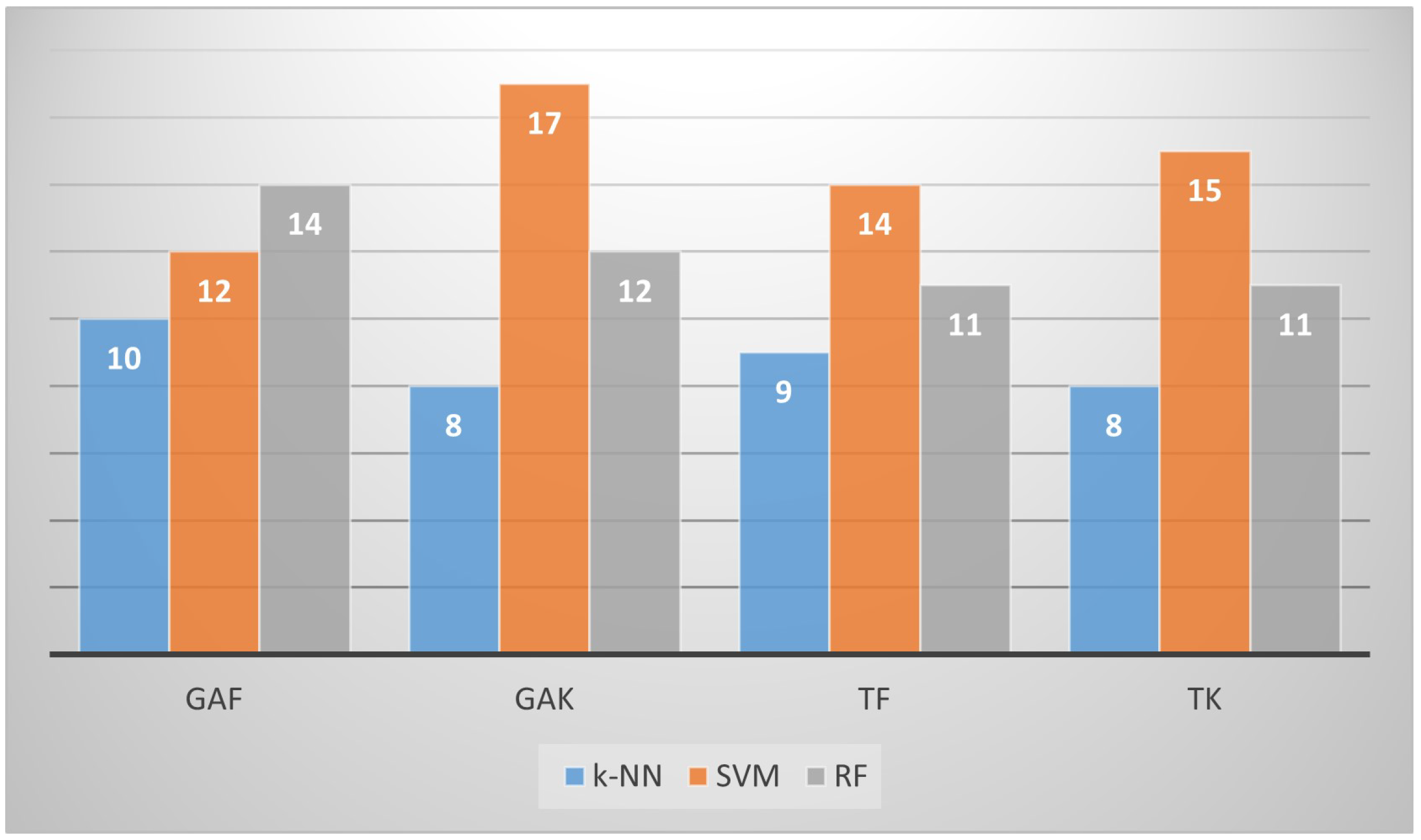
- They provide four FS techniques that enhance the classification accuracy by an average of 6.64%.
- They contribute to technological development by providing EPP-Lab software handling FS.
- They contribute to decision making by providing four PPFS methods yielding different but equivalent results.
7.4.2. Advantages and Liminations of PPFS
- PPFS methods are competitive and efficient FS methods.
- The four PPFS methods are different but provide similar results. The user can either apply all of them and choose the suitable result or use only one of them.
- PPFS methods can be used directly through EPP-Lab software.
- The EPP-Lab can be used to avoid the parameter setting of the optimization methods.
- PPFS methods provide a list of outliers, and their frequency allows validating the non-relevant features.
- EPP-Lab is an open-source desktop application, downloadable in any environment.
- PPFS failed to find the non-significant features when most of the features are highly correlated or include noise.
- PPFS methods do not work well when the dataset is binary (the values of features’ vectors are either 0 or 1).
8. Conclusions
- Make the dataset spherical before seeking the outliers [27] to reduce the noise.
- Use another optimization method such as PSO, which is already available in EPP-Lab.
- Use large datasets reaching 30,000 features to test the extent of PPFS in enhancing accuracy.
- Explore other PP indices such as Friedman Turkey and Discriminant indices.
- Investigate other Machine Learning classifiers.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FS | Feature Selection |
| PP | Projection Pursuit |
| PPFS | Project Pursuit based Feature Selection |
| AI | Artificial Intelligence |
| GA | Genetic Algorithms |
| PSO | Particle Swarm Optimization |
| EPP-Lab | Exploratory Projection Pursuit Laboratory |
| PPFS-GAF | Projection-Pursuit-based Feature Selection |
| using Genetic Algorithm and Friedman index | |
| PPFS-GAK | Projection-Pursuit-based Feature Selection |
| using Genetic Algorithm and Kurtosis index | |
| PPFS-TF | Projection-Pursuit-based Feature Selection |
| using Tribes and Friedman index | |
| PPFS-TK | Projection-Pursuit-based Feature Selection |
| using Tribes and Kurtosis index | |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| LR | Linear Regression |
| CV | Cross Validation |
| k-NN | K-Nearest Neighbor |
| SVM | Support Vector Machine |
| RF | Random Forest |
| PCA | Principal Component Analysis |
| CFS | Correlation Feature Selection |
| WOA | Whale Optimization Algorithm |
| Accu | Accuracy |
| Prec | Precision |
| Rec | Recall |
| mutualInfo | Mutual Information |
References
- Fukumizu, K.; Bach, F.R.; Jordan, M.I. Dimensionality reduction for supervised learning with reproducing kernel hilbert spaces. J. Mach. Learn. Res. 2004, 5, 73–99. [Google Scholar]
- Sophian, A.; Tian, G.Y.; Taylor, D.; Rudlin, J. A feature extraction technique based on principal component analysis for pulsed Eddy current NDT. NDT E Int. J. 2003, 36, 37–41. [Google Scholar] [CrossRef]
- Scholkopf, B.; Smola, A.; Muller, K.-R. Nonlinear component analysis as a kernel eigenvalue problem. Neural Comput. J. 1998, 10, 1299–1319. [Google Scholar] [CrossRef] [Green Version]
- Chandrashekar, G.; Sahin, F. Survey on feature selection methods. J. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 57–82. [Google Scholar]
- Taminau, J.L.; Meganck, S.; Steenhoff, D.; Coletta, A.; Molter, C. A survey on filter techniques for feature selection in gene expression microarray analysis. IEEE/ACM Trans. Comput. Biol. Bioinform. 2012, 9, 6–19. [Google Scholar]
- Eom, J.; Zhang, B. PubMiner: Machine learning-based text mining for biomedical information analysis. Lect. Notes Artif. Intell. 2000, 3192, 216–225. [Google Scholar]
- Larabi-Marie-Sainte, S.; Ghouzali, S. Multi-Objective Particle Swarm Optimization-based Feature Selection for Face Recognition. Stud. Inform. Control. J. 2020, 29, 99–109. [Google Scholar] [CrossRef]
- Larabi-Marie-Sainte, S.; Alayani, N. Firefly Algorithm based Feature Selection for Arabic Text Classification. J. King Saud Univ. Comput. Inf. Sci. (JKSUCIS) 2020, 32, 320–328. [Google Scholar] [CrossRef]
- Wen, J.; Canbing, L.; Rui, L. A Heuristic Feature Selection Approach for Text Categorization by Using Chaos Optimization and Genetic Algorithm. Math. Probl. Eng. 2013, 2013. [Google Scholar] [CrossRef] [Green Version]
- Aragon-Royon, F.; Jimenez-Vilchez, A.; Arauzo-Azofra, A.; Benitez, J.M. FSINR: An exhaustive package for feature selection. arXiv 2020, arXiv:2002.10330v1. [Google Scholar]
- Rattanawadee, P.; Anongnart, S. Wrapper Feature Subset Selection for Dimension Reduction Based on Ensemble Learning Algorithm. Procedia Comput. Sci. 2015, 72, 162–169. [Google Scholar]
- Agrawala, R.K.; Kaur, B.; Sharma, S. Quantum based Whale Optimization Algorithm for wrapper feature selection. Appl. Soft Comput. J. 2020, 89, 106092. [Google Scholar] [CrossRef]
- Mafarja, M.; Mirjalili, S. Whale optimization approaches for wrapper feature selection. Appl. Soft Comput. J. 2018, 62, 441–453. [Google Scholar] [CrossRef]
- Gokalp, O.; Tasci, E.; Ugur, A. A novel wrapper feature selection algorithm based on iterated greedy metaheuristic for sentiment classification. Expert Syst. Appl. 2020, 146, 113–176. [Google Scholar] [CrossRef]
- Xu, T.; Feng, Z.H.; Wu, X.J.; Kittler, J. Learning Adaptive Discriminative Correlation Filters via Temporal Consistency Preserving Spatial Feature Selection for Robust Visual Object Tracking. IEEE Trans. Image Process. J. 2019, 28, 5596–5609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bommerta, A.; Sun, X.; Bischl, B.; Rahnenführer, J.; Lang, M. Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal. J. 2020, 143. [Google Scholar] [CrossRef]
- Wang, Y.; Tao, L. Local feature selection based on artificial immune system for classification. Appl. Soft Comput. J. 2020, 87, 105989. [Google Scholar] [CrossRef]
- Cai, J.; Hu, L.; Liu, Z.; Zhou, K.; Zhang, H. An Embedded Feature Selection and Multi-Class Classification Method for Detection of the Progression from Mild Cognitive Impairment to Alzheimer’s Disease. J. Med. Imaging Health Inform. 2020, 10, 370–379. [Google Scholar] [CrossRef]
- Guo, Y.; Chung, F.-L.; Li, G.; Zhang, L. Multi-Label Bioinformatics Data Classification With Ensemble Embedded Feature Selection. IEEE Access J. 2019, 7, 103863–103875. [Google Scholar] [CrossRef]
- Azmandian, F.; Dy, J.G.; Aslam, J.A.; Kaeli, D.R. Local Kernel Density Ratio-Based Feature Selection for Outlier Detection. In Proceedings of the Asian Conference on Machine Learning, Singapore, 4–6 November 2012; Volume 25, pp. 49–64. [Google Scholar]
- Suresh, M.S.S.; Narayanan, A. Improving Classification Accuracy Using Combined Filter+Wrapper Feature Selection Technique. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Coimbatore, India, 20–22 February 2019; pp. 1–6. [Google Scholar]
- Hallac, D.; Leskovec, J.; Boyd, S. Network lasso: Clustering and optimization in large graphs. In Proceedings of the KDD, Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Osanaiy, O.; Cai, H.; Raymond-Choo, K.K.; Dehghantanha, A.; Xu, Z.; Dlodlo, M. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. EURASIP J. Wirel. Commun. Netw. 2016, 130, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Hadi, S.; Imon, A.H.M.R.; Werner, M. Detection of outliers. Wiley Interdiscip. Rev. Comput. Stat. 2009, 1, 57–70. [Google Scholar] [CrossRef]
- Ruiz-Gazen, A.; Larabi-Marie-Sainte, S.; Berro, A. Detecting Multivariate Outliers Using Projection Pursuit with Particle Swarm Optimization. In Proceedings of the 19th International Conference on Computational Statistics (Book Chapter), Paris, France, 22–27 August 2010; pp. 89–98. [Google Scholar]
- Berro, A.; Larabi-Marie-Sainte, S.; Ruiz-Gazen, A. Genetic Algorithms and Particle rm Optimization for Exploratory Projection Pursuit. Ann. Math. Artiffitial Intell. J. 2010, 60, 153–178. [Google Scholar] [CrossRef]
- Yang, Q.; Singh, J.; Lee, J. Isolation-based feature Selection for Unsupervised Outlier Detection. In Proceedings of the Annual Conference of the PHM Society, Scottsdale, AZ, USA, 21–22 September 2019; Volume 11. [Google Scholar]
- Kovarasan, R.K.; Rajkumar, M. An Effective Intrusion Detection System Using Flawless Feature Selection, Outlier Detection and Classification. In Progress in Advanced Computing and Intelligent Engineering. Advances in Intelligent Systems and Computing; Pati, B., Panigrahi, C., Misra, S., Pujari, A., Bakshi, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; p. 713. [Google Scholar]
- Karthikeyan, G.; Balasubramanie, P. Robust Feature Selection Model for Outlier Detection Using Fuzzy Clustering and Rule Mining. Int. J. Appl. Eng. Res. 2017, 12, 7019–7028. [Google Scholar]
- Pang, G.; Cao, L.; Chen, L. Learning Homophily Couplings from Non-IID Data for Joint Feature Selection and Noise-Resilient Outlier Detection. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Solorio-Fernández, S.; Carrasco-Ochoa, J.A.; Martínez-Trinidad, J.F. A new hybrid filter–wrapper feature selection method for clustering based on ranking. Neurocomput. J. 2016, 214, 866–880. [Google Scholar] [CrossRef]
- Zhen, L.; Xin, L.; Jin, M.; Hui, G. An Optimized Computational Framework for Isolation Forest. Math. Probl. Eng. 2018, 2018. [Google Scholar] [CrossRef] [Green Version]
- Koupaie, H.M.; Suhaimi, I.; Hosseinkhani, J. Outlier Detection in Stream Data by Machine Learning and Feature Selection Methods. Int. J. Adv. Comput. Sci. Inf. Technol. (IJACSIT) 2013, 2, 17–24. [Google Scholar]
- Huber, P. Projection pursuit. Ann. Stat. 1985, 13, 435–475. [Google Scholar] [CrossRef]
- Jones, M.; Sibson, R. What is projection pursuit? (With discussion). J. R. Stat. Soc. A 1987, 150, 1–36. [Google Scholar] [CrossRef]
- Larabi-Marie-Sainte, S. Biologically Inspired Algorithms for Exploratory Projection Pursuit. Ph.D. Thesis, Toulouse 1 University (Tolbiac), Toulouse, France, 2011. Available online: https://scanr.enseignementsup-recherche.gouv.fr/publication/these2011TOU10021 (accessed on 20 July 2021).
- Larabi-Marie-Sainte, S. Detection and visualization of non-linear structures in large datasets using Exploratory Projection Pursuit Laboratory (EPP-Lab) software. J. King Saud Univ. Comput. Inf. Sci. 2017, 29, 2–18. [Google Scholar]
- Penã, P.; Prieto, F. Cluster Identification using projections. J. Am. Stat. Assoc. 2001, 456, 1433–1445. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J. Exploratory Projection Pursuit. Am. Stat. Assoc. 1987, 82, 249–266. [Google Scholar] [CrossRef]
- Sun, J. Some practical aspects of exploratory projection pursuit. SIAM J. Sci. Comput. 1993, 14, 68–80. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Harbor, MI, USA, 1975. [Google Scholar]
- Kennedy, J.; Eberhart, R. Swarm Intelligence; Shi, Y., Ed.; Springer: Boston, MA, USA, 1995. [Google Scholar]
- Larabi-Marie-Sainte, S.; Berro, A.; Ruiz-Gazen, A. An efficient Optimization Method for Revealing Local optima of Projection Pursuit Indices. In Proceedings of the Swarm Intelligent, ANTS2010, Brussels, Belgium, 8–10 September 2010; pp. 60–71. [Google Scholar]
- Clerc, M. Particle swarm optimization. In International Scientific and Technical Encyclopaedia; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Tomar, A.; Nagpal, A. Comparing Accuracy of K-Nearest-Neighbor and Support-Vector-Machines for Age Estimation. Int. J. Eng. Trends Technol. (IJETT) 2016, 38, 326–329. [Google Scholar] [CrossRef]
- Huang, M.W.; Chen, C.W.; Lin, W.C.; Ke, S.W.; Tsai, C.F. SVM and SVM Ensembles in Breast Cancer Prediction. PLoS ONE 2017, 12. [Google Scholar] [CrossRef]
- Derrac, J.; Garcia, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. J. Swarm Evol. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | PPFS |
|---|---|
| [28] Outlier-based FS using | Outlier-based FS using PP |
| feature ranking and isolation forest | |
| [28] Outlier-based FS is a random- | based on PSO and GA |
| based approach | optimization methods |
| Filter FS based on specific measures | based on PP that finds interesting |
| (Distance, Correlation, ⋯) | projections by optimizing the PP index |
| Wrapper FS based on AI methods | Based on PP |
| or a combination of methods | |
| Embedded FS based on the Lasso | Based on PP and optimization methods |
| combined with the Linear Regression |
| Dataset | Features | Sample | Classes | |
|---|---|---|---|---|
| 1 | Breast cancer | 10 | 699 | 2 |
| 2 | Sonar | 60 | 208 | 2 |
| 3 | Waveform | 40 | 5000 | 3 |
| 4 | Wine | 13 | 178 | 3 |
| 5 | Liver Disorder | 6 | 345 | 2 |
| 6 | Spam | 57 | 4601 | 2 |
| 7 | Diabetes | 8 | 768 | 2 |
| 8 | Vehicle | 18 | 847 | 4 |
| 9 | Ionosphere | 34 | 351 | 2 |
| 10 | Climate | 20 | 540 | 2 |
| 11 | WDBC | 30 | 569 | 2 |
| 12 | Australian | 14 | 690 | 2 |
| 13 | Stock | 9 | 950 | 2 |
| 14 | Glass | 9 | 214 | 2 |
| 15 | Segment | 19 | 2310 | 7 |
| 16 | Heart | 13 | 270 | 2 |
| 17 | Colon | 2000 | 62 | 2 |
| 18 | August S.P | 10 | 595 | 3 |
| 19 | Fifa2019 | 80 | 13,000 | 2 |
| Parameter | Value |
|---|---|
| Population size | 50 |
| Number of individuals in the tournament selection | 3 |
| Crossover type | 2-points |
| Tournament Probability | 0.65 |
| Mutation Probability | 0.05 |
| Number of iterations | 100 |
| Number of runs | 100 |
| Cost | Accuracy | Kappa |
|---|---|---|
| 0.50 | 0.9658872 | 0.9248802 |
| 1.00 | 0.9652069 | 0.9233597 |
| 1.25 | 0.9645266 | 0.9218380 |
| 2.00 | 0.9645266 | 0.9218380 |
| Dataset | Proposed PPFS | Feature Number (Frequency) | Outliers Number | Time |
|---|---|---|---|---|
| Breast Cancer | PPFS-GAF | 1(97), 3(80), 6(81), 10(81) | 4 | 245 ms |
| PPFS-GAK | 1(97) | 1 | 130 ms | |
| PPFS-TF | 1(97) | 1 | 497 ms | |
| PPFS-TK | 1(97) | 1 | 401 ms | |
| Liver disorder | PPFS-GAF | 1(100), 2(78), 6(99) | 3 | 82 ms |
| PPFS-GAK | 1(100), 6(100) | 2 | 42 ms | |
| PPFS-TF | 1(98), 2(63), 6(87) | 3 | 164 ms | |
| PPFS-TK | 1(98), 6(98) | 2 | 115 ms | |
| Sonar | PPFS-GAF | 1(96), 2(94), 3(91), 19(75), 20(98), 21–29(100), 30(97), 49(84), 50–52(97), 53–55(98), 56–60(99) | 27 | 359 ms |
| PPFS-GAK | 1(100), 2(97), 3(72), 20(96), 21–29(100), 30(98), 50–60(100) | 24 | 115 ms | |
| PPFS-TF | 1(94), 2(90), 3(79), 4(51), 19(57), 20(79), 21(89), 22(91), 23(95), 24(96), 25(97), 26(99), 27(100), 28(100), 29(95), 30(89), 49(80), 50–60(98) | 23 | 510 ms | |
| PPFS-TK | 1(88), 2(73), 20(67), 21(90), 22(97), 23–25(100), 26(99), 27(100), 28(99), 29(98), 30(90), 50(91), 51(94), 52(95), 53–60(95) | 23 | 207 ms | |
| Wine | PPFS-GAF | 4(64), 5(64), 13(98) | 3 | 82 ms |
| PPFS-GAK | 13(100) | 1 | 32 ms | |
| PPFS-TF | 13(98) | 1 | 162 ms | |
| PPFS-TK | 13(100) | 1 | 79 ms | |
| Spam | PPFS-GAF | 5(60), 16(54), 21(52), 26(56), 46(52), 55(50) | 6 | 7 s 13 ms |
| PPFS-GAK | 57(100) | 1 | 3 s 259 ms | |
| PPFS-TF | 2(55), 19(53), 21(56), 27(67), 42(52), 45(61), 46(53), 55(53), 56(57), 57(60) | 10 | 8 s 14 ms | |
| PPFS-TK | 56(93), 57(100) | 2 | 3 s 241 ms | |
| Waveform | PPFS-GAF | 1(84), 2(75), 10(88), 11(88), 12(82), 20(80), 21(91) | 7 | 3 s 758 ms |
| PPFS-GAK | 1(76), 2(64), 10(63), 11(75), 12(63), 13(53), 20(59), 21(78) | 8 | 1 s 627 ms | |
| PPFS-TF | 1(79), 2(63), 10(83), 11(90), 12(71), 20(64), 21(79) | 7 | 5 s 1 ms | |
| PPFS-TK | 1(71), 10(52), 11(71), 12(55), 15(50), 21(74) | 6 | 2 s 759 ms | |
| Vehicle | PPFS-GAF | 6(100), 12(100), 15–16(100) | 4 | 95 ms |
| PPFS-GAK | 6(100), 12(100), 15–16(100) | 4 | 34 ms | |
| PPFS-TF | 6(100), 9(62), 12(100), 15–16(100) | 5 | 182 ms | |
| PPFS-TK | 6(100), 12(100), 15–16(100) | 4 | 114 ms | |
| Diabetes | PPFS-GAF | 1(90), 2(95), 5(84), 7(94) | 4 | 232 ms |
| PPFS-GAK | 2(100), 7(100) | 2 | 127 ms | |
| PPFS-TF | 1(93), 2(99), 5(68), 7(97) | 4 | 451 ms | |
| PPFS-TK | 2(98), 7(86) | 2 | 351 ms | |
| Ionosphere | PPFS-GAF | 1(98), 8(57), 13(50), 14(56), 15(60), 17(51), 18(71), 20(85), 24(65), 26(67), 27(52), 28(58) | 12 | 310 ms |
| PPFS-GAK | 1(98), 3(81), 5(84), 7(73), 9(58), 20(65), 24(66), 26(50), 28(67) | 9 | 133 ms | |
| PPFS-TF | 1(81), 8(51), 10(54), 13(59), 14(51), 15(65), 17(57), 18(62), 19(56), 20(63), 21(52), 24(65), 26(53), 28(55) | 14 | 420 ms | |
| PPFS-TK | 1(98), 3(86), 5(77), 7(57), 24(55), 28(62) | 6 | 206 ms | |
| Climate | PPFS-GAF | 1(81) | 1 | 257 ms |
| PPFS-GAK | 2(93), 3(100) | 2 | 112 ms | |
| PPFS-TF | 2(88), 3(92) | 2 | 398 ms | |
| PPFS-TK | 2(82), 3(100) | 2 | 398 ms | |
| WDBC | PPFS-GAF | 2(53), 3(73), 4(68), 14(70), 22(64), 23(74), 24(66) | 7 | 386 ms |
| PPFS-GAK | 4(100), 24(100) | 2 | 163 ms | |
| PPFS-TF | 4(85), 24(86) | 2 | 574 ms | |
| PPFS-TK | 4(100), 24(86) | 2 | 267 ms | |
| Australian | PPFS-GAF | 2(86), 3(81) | 2 | 247 ms |
| PPFS-GAK | 2(100), 3(60) | 2 | 136 ms | |
| PPFS-TF | 2(99) | 1 | 386 ms | |
| PPFS-TK | 2(98) | 1 | 229 ms | |
| Stock | PPFS-GAF | 3(91), 5(80), 7(88), 8(82) | 4 | 213 ms |
| PPFS-GAK | 3(100), 5(99), 6(94), 7(100), 8(100) | 5 | 114 ms | |
| PPFS-TF | 3(98), 5(97), 7(99), 8(95) | 4 | 339 ms | |
| PPFS-TK | 3(99), 5(83), 6(78), 7(100), 8(89) | 5 | 193 ms | |
| Glass | PPFS-GAF | 3(51), 7(51) | 2 | 121 ms |
| PPFS-GAK | 5(100) | 1 | 54 ms | |
| PPFS-TF | 5(100) | 1 | 203 ms | |
| PPFS-TK | 5(100) | 1 | 119 ms | |
| Segment | PPFS-GAF | 1(56), 2(56), 14(76), 16(62) | 4 | 937 ms |
| PPFS-GAK | 1(100), 2(100) | 2 | 470 ms | |
| PPFS-TF | 1(100), 2(99), 12(57), 14(98), 16(85), 17(60) | 6 | 1 s 622 ms | |
| PPFS-TK | 1(99), 2(100) | 2 | 901 ms | |
| Heart | PPFS-GAF | 4(98), 5(95), 8(94) | 3 | 96 ms |
| PPFS-GAK | 4(100), 5(100), 8(100) | 3 | 41 ms | |
| PPFS-TF | 4(100), 5(100), 8(99) | 3 | 161 ms | |
| PPFS-TK | 4(98), 5(100), 8(99) | 3 | 82 ms | |
| Colon | PPFS-GAF | 2(62), 6(52), 10(54), 16(55), 24(58), 30(55), 42(64), 46(64), 50(55), 58(52), 64(50), 236(67), 332(61), 610(79), 712(59), 1612(59), 1754(76) | 17 | 7 s 181 ms |
| PPFS-GAK | 1(100), 2(100), 4(100), 6(100), 8(100), 10(100), 12(100), 14(100), 16(100), 18(100), 20(100), 22(100), 24(100), 26(100), 28(100), 30(100), 32(100), 34(99), 36(100), 38(100), 40(100), 42(100), 44(100), 46(100), 48(99), 50(100), 54(100), 56(100), 58(100), 60(100), 64(100), 70(100), 72(92), 76(99), 78(99), 80(99), 82(99), 84(84), 86(100), 92(100), 98(57), 100(57), 102(57), 104(57), 206(99), 236(100), 332(100), 610(98), 712(100), 1612(85), 1754(99) | 51 | 839 ms | |
| PPFS-TF | 1(98), 2(96), 4(96), 6(95), 8(95), 10(96), 12(100), 14(94), 16(97), 18(93), 20(96), 22(92), 24(95), 26(95), 28(93), 30(96), 32(93), 34(88), 36(93), 38(94), 40(96), 42(95), 44(96), 46(94), 48(73), 50(97), 54(95), 56(87), 58(93), 60(92), 64(96), 70(75), 72(76), 76(86), 78(86), 80(86), 82(86), 84(73), 86(93), 92(93), 98(52), 100(52), 102(52), 104(52), 206(86), 236(97), 332(97), 610(87), 712(95), 1612(66), 1754(88) | 51 | 6 s 443 ms | |
| PPFS-TK | 1(100), 2(100), 4(100), 6(99), 8(99), 10(100), 12(100), 14(100), 16(99), 18(99), 20(100), 22(98), 24(100), 26(98), 28(99), 30(100), 32(98), 34(95), 36(98), 38(99), 40(98), 42(99), 44(98), 46(99), 48(85), 50(100), 54(100), 56(99), 58(97), 60(99), 64(99), 70(94), 72(81), 76(87), 78(87), 80(87), 82(87), 84(83), 86(99), 92(99), 98(51), 100(51), 102(51), 104(51), 206(88), 236(97), 332(98), 610(87), 712(97), 1612(72), 1754(91) | 51 | 1 s 654 ms | |
| August S.P | PPFS-GAF | 3–4(100) | 2 | 221 ms |
| PPFS-GAK | 1(100), 3–4(100) | 3 | 123 ms | |
| PPFS-TF | 1(100), 3–4(100) | 3 | 388 ms | |
| PPFS-TK | 1(100), 3–4(100) | 3 | 274 ms | |
| Fifa2019 | PPFS-GAF | 5(61), 6(76), 8(83), 9(86), 17(82), 18(84), 80(67) | 7 | 43 s 952 ms |
| PPFS-GAK | 1(100) | 1 | 21 s 483 ms | |
| PPFS-TF | 1(75), 5(65), 6(79), 8(72), 9(83), 17(75), 18(74), 80(70) | 8 | 44 s 143 ms | |
| PPFS-TK | 1(100) | 1 | 12 s 580 ms |
| Datasets | PPFS | k-NN | SVM | RF | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accu | Prec | Rec | F1 | Accu | Prec | Rec | F1 | Accu | Prec | Rec | F1 | ||
| Breast C. | Without | 95.22 | 95.68 | 97.08 | 96.38 | 98.09 | 99.26 | 97.81 | 98.53 | 94.64 | 97.73 | 94.16 | 95.91 |
| PPFS-GAF | 97.61 | 97.83 | 98.54 | 98.18 | 96.17 | 97.08 | 97.08 | 97.08 | 95.22 | 96.35 | 96.35 | 96.35 | |
| PPFS-GAK/PPFS-TF/PPFS-TK | 95.22 | 95.68 | 97.08 | 96.38 | 98.56 | 100 | 97.81 | 98.89 | 97.61 | 98.53 | 97.81 | 98.17 | |
| Sonar | Without | 70.97 | 70.27 | 59.09 | 54.20 | 69.35 | 66.67 | 84.85 | 74.67 | 82.26 | 84.38 | 81.82 | 83.08 |
| PPFS-GAF | 75.81 | 71.43 | 90.91 | 80.00 | 82.26 | 80.56 | 89.68 | 47.32 | 88.71 | 88.24 | 90.91 | 89.55 | |
| PPFS-GAK | 66.13 | 63.64 | 84.85 | 72.73 | 80.65 | 81.82 | 88.00 | 48.18 | 72.58 | 76.67 | 69.70 | 73.02 | |
| PPFS-TF | 75.81 | 71.43 | 90.91 | 80.00 | 80.65 | 83.87 | 85.64 | 49.48 | 80.65 | 80.00 | 84.85 | 82.35 | |
| PPFS-TK | 67.74 | 64.44 | 87.88 | 74.36 | 69.35 | 68.42 | 94.61 | 41.97 | 80.65 | 86.21 | 75.76 | 80.65 | |
| Liver D. | Without | 63.11 | 64.86 | 80.00 | 71.64 | 76.70 | 75.00 | 90.00 | 81.82 | 63.11 | 67.74 | 70.00 | 68.85 |
| PPFS-GAF | 69.90 | 68.35 | 90.00 | 77.70 | 65.05 | 67.14 | 78.33 | 72.31 | 71.84 | 75.41 | 76.67 | 76.03 | |
| PPFS-GAK | 66.02 | 65.43 | 88.33 | 75.18 | 73.79 | 73.91 | 85.00 | 79.07 | 71.84 | 75.41 | 76.67 | 76.03 | |
| PPFS-TF | 69.90 | 68.35 | 90.00 | 77.70 | 65.05 | 67.14 | 78.33 | 72.31 | 71.84 | 75.41 | 76.67 | 76.03 | |
| PPFS-TK | 66.02 | 65.43 | 88.33 | 75.18 | 73.79 | 73.91 | 85.00 | 79.07 | 71.84 | 75.41 | 76.67 | 76.03 | |
| Wine | Without | 98.08 | 98.41 | 97.78 | 98.04 | 92.31 | 91.69 | 93.09 | 92.26 | 98.08 | 98.41 | 98.15 | 98.23 |
| PPFS-GAF | 98.08 | 98.41 | 98.15 | 98.23 | 96.15 | 95.24 | 97.10 | 95.92 | 100 | 100 | 100 | 100 | |
| PPFS-GAK/PPFS-TF/PPFS-TK | 96.15 | 96.83 | 96.49 | 96.48 | 96.15 | 96.03 | 96.49 | 96.10 | 100 | 100 | 100 | 100 | |
| Spam | Without | 90.72 | 92.45 | 92.22 | 92.34 | 92.68 | 93.49 | 94.50 | 93.99 | 96.01 | 95.89 | 97.61 | 96.74 |
| PPFS-GAF | 88.69 | 90.09 | 91.39 | 90.74 | 93.04 | 93.02 | 95.69 | 94.34 | 93.76 | 93.50 | 96.41 | 94.94 | |
| PPFS-GAK | 89.41 | 90.59 | 92.11 | 91.34 | 93.62 | 93.90 | 95.69 | 94.79 | 95.00 | 94.75 | 97.13 | 95.92 | |
| PPFS-TF | 90.72 | 90.78 | 94.26 | 92.49 | 93.04 | 94.71 | 94.26 | 94.48 | 95.43 | 95.52 | 97.01 | 96.26 | |
| PPFS-TK | 89.99 | 90.49 | 93.30 | 91.87 | 93.04 | 93.53 | 95.10 | 94.31 | 95.36 | 94.99 | 97.49 | 96.22 | |
| Waveform | Without | 86.06 | 83.95 | 84.52 | 83.77 | 86.39 | 86.39 | 86.38 | 86.37 | 85.46 | 85.41 | 85.54 | 85.35 |
| PPFS-GAF/PPFS-TF | 82.45 | 82.38 | 83.51 | 81.89 | 83.79 | 83.76 | 83.77 | 83.67 | 80.65 | 80.59 | 80.86 | 80.24 | |
| PPFS-GAK | 82.12 | 82.07 | 82.85 | 81.48 | 81.65 | 81.63 | 81.55 | 81.57 | 81.12 | 78.89 | 79.04 | 78.50 | |
| PPFS-TK | 81.99 | 81.90 | 83.80 | 81.32 | 81.45 | 81.42 | 81.36 | 81.35 | 81.78 | 81.72 | 81.98 | 81.49 | |
| Vehicle | Without | 67.46 | 67.84 | 65.92 | 66.73 | 79.76 | 80.10 | 79.74 | 79.75 | 73.02 | 73.41 | 71.57 | 72.35 |
| PPFS-GAF/PPFS-GAK/PPFS-TK | 70.24 | 70.61 | 69.73 | 70.13 | 83.33 | 83.52 | 83.10 | 83.27 | 74.60 | 74.98 | 73.67 | 74.10 | |
| PPFS-TF | 73.02 | 73.30 | 72.04 | 72.40 | 79.36 | 79.57 | 78.81 | 79.10 | 76.98 | 77.28 | 76.00 | 76.51 | |
| Diabetes | Without | 72.17 | 77.22 | 81.33 | 79.22 | 80.00 | 81.71 | 89.33 | 85.35 | 75.65 | 78.66 | 86.00 | 82.17 |
| PPFS-GAF/PPFS-TF | 67.39 | 70.72 | 85.33 | 77.34 | 81.30 | 82.42 | 90.67 | 86.35 | 76.96 | 82.55 | 82.00 | 82.27 | |
| PPFS-GAK/PPFS-TK | 65.65 | 69.83 | 83.33 | 75.99 | 81.30 | 82.42 | 90.67 | 86.35 | 76.52 | 81.17 | 83.33 | 82.24 | |
| Ionosphere | Without | 87.50 | 83.64 | 89.19 | 85.45 | 89.42 | 86.35 | 90.59 | 87.89 | 91.35 | 90.26 | 90.77 | 90.50 |
| PPFS-GAF | 87.50 | 84.25 | 88.24 | 85.69 | 80.77 | 77.81 | 79.43 | 78.47 | 94.23 | 93.71 | 93.71 | 93.71 | |
| PPFS-GAK | 81.73 | 76.14 | 83.75 | 77.96 | 90.38 | 87.70 | 91.29 | 89.08 | 93.27 | 92.96 | 92.46 | 92.70 | |
| PPFS-TF | 84.62 | 79.59 | 87.14 | 81.62 | 80.77 | 78.42 | 79.17 | 78.76 | 90.38 | 87.70 | 91.29 | 89.08 | |
| PPFS-TK | 84.62 | 79.59 | 87.14 | 81.62 | 81.73 | 74.93 | 86.79 | 77.04 | 91.35 | 90.86 | 90.39 | 90.62 | |
| Climate | Without | 91.92 | 50.00 | NaN | NaN | 87.58 | 58.16 | 58.16 | 58.16 | 91.92 | 50.00 | NaN | NaN |
| PPFS-GAF | 91.93 | 50.00 | NaN | NaN | 91.93 | 50.00 | NaN | NaN | 91.93 | 50.00 | NaN | NaN | |
| PPFS-GAK/PPFS-TF/PPFS-TK | 91.93 | 50.00 | NaN | NaN | 91.93 | 50.00 | NaN | NaN | 90.68 | 49.32 | 45.91 | 45.91 | |
| WDBC | Without | 92.94 | 91.13 | 93.83 | 92.21 | 94.71 | 93.18 | 95.60 | 94.18 | 94.71 | 93.84 | 94.77 | 94.27 |
| PPFS-GAF | 95.29 | 93.98 | 96.03 | 94.85 | 93.53 | 92.25 | 93.84 | 92.94 | 94.71 | 94.49 | 94.21 | 94.34 | |
| PPFS-GAK/PPFS-TF/PPFS-TK | 98.24 | 97.95 | 98.27 | 98.10 | 98.24 | 97.96 | 98.28 | 98.10 | 95.29 | 94.63 | 95.25 | 94.92 | |
| Australian | Without | 85.92 | 84.97 | 86.93 | 85.45 | 84.95 | 85.25 | 84.86 | 84.89 | 85.92 | 86.55 | 86.18 | 85.91 |
| PPFS-GAF/PPFS-GAK | 83.50 | 82.88 | 83.66 | 83.14 | 85.92 | 86.55 | 86.18 | 85.91 | 86.89 | 86.27 | 87.26 | 86.59 | |
| PPFS-TF/PPFS-TK | 83.50 | 82.88 | 83.66 | 83.14 | 85.92 | 86.55 | 86.18 | 85.91 | 86.89 | 86.27 | 87.26 | 86.59 | |
| Stock | Without | 91.90 | 92.02 | 92.16 | 91.90 | 81.69 | 81.85 | 82.14 | 81.66 | 95.07 | 95.17 | 95.21 | 95.07 |
| PPFS-GAF/PPFS-TF | 95.42 | 95.43 | 95.42 | 95.42 | 83.10 | 82.83 | 84.33 | 82.85 | 96.48 | 96.48 | 96.48 | 96.48 | |
| PPFS-GAK/PPFS-TK | 95.42 | 95.39 | 95.46 | 95.42 | 86.62 | 86.43 | 87.30 | 86.51 | 95.42 | 95.37 | 95.52 | 95.41 | |
| Glass | Without | 69.84 | 71.56 | 69.61 | 69,01 | 53.96 | 45.68 | 44.58 | 44.52 | 74.60 | 65.74 | 76.79 | 66.49 |
| PPFS-GAF | 57.14 | 54.43 | 54.21 | 54.19 | 60.32 | 52.66 | 53.33 | 52.17 | 69.84 | 65.24 | 66.45 | 65.65 | |
| PPFS-GAK/PPFS-TF/PPFS-TK | 60.32 | 61.09 | 60.08 | 59.29 | 69.84 | 63.14 | 66.46 | 63.65 | 87.30 | 88.14 | 85.76 | 86.54 | |
| Segment | Without | 94.81 | 94.81 | 94.78 | 94.75 | 94.66 | 94.66 | 94.77 | 94.68 | 97.83 | 97.84 | 97.86 | 97.84 |
| PPFS-GAF | 89.18 | 89.18 | 89.18 | 89.09 | 86.58 | 86.58 | 86.69 | 86.58 | 94.37 | 94.37 | 94.37 | 94.37 | |
| PPFS-GAK/PPFS-TK | 90.33 | 90.33 | 90.46 | 90.37 | 89.47 | 89.47 | 89.80 | 89.45 | 92.50 | 92.50 | 92.78 | 92.50 | |
| PPFS-TF | 87.88 | 87.88 | 87.89 | 87.77 | 85.14 | 85.14 | 85.60 | 85.15 | 91.34 | 91.34 | 91.54 | 91.36 | |
| Heart | Without | 80.25 | 79.72 | 80.13 | 79.87 | 81.48 | 81.39 | 81.23 | 81.30 | 83.95 | 83.61 | 83.82 | 83.70 |
| PPFS-GAF/PPFS-GAK/PPFS-TF/PPFS-TK | 81.48 | 81.39 | 81.23 | 81.30 | 82.72 | 83.33 | 82.97 | 82.69 | 87.65 | 88.06 | 87.59 | 87.61 | |
| Colon | Without | 77.78 | 66.67 | 87.50 | 67.86 | 72.22 | 70.83 | 69.48 | 69.90 | 77.78 | 75.00 | 75.00 | 75.00 |
| PPFS-GAF | 72.22 | 66.67 | 68.46 | 67.27 | 83.33 | 87.50 | 83.33 | 82.86 | 83.33 | 83.33 | 81.17 | 81.93 | |
| PPFS-GAK/PPFS-TF/PPFS-TK | 77.78 | 75.00 | 75.00 | 75.00 | 83.33 | 79.17 | 82.31 | 80.36 | 77.78 | 70.83 | 76.78 | 72.31 | |
| August S.P | Without | 68.38 | 66.97 | 66.20 | 66.58 | 55.37 | 54.65 | 50.78 | 52.65 | 94.92 | 94.69 | 94.95 | 94.82 |
| PPFS-GAF | 65.54 | 64.65 | 62.48 | 63.54 | 56.5 | 52.20 | 50.96 | 51.57 | 97.18 | 97.07 | 96.87 | 96.97 | |
| PPFS-GAK/PPFS-TF/PPFS-TK | 62.71 | 60.40 | 58.84 | 59.61 | 61.02 | 57.68 | 56.70 | 57.18 | 95.48 | 95.82 | 94.68 | 95.25 | |
| Fifa2019 | Without | 60.04 | 50.03 | 51.93 | 37.93 | 60.09 | 50.00 | NAN | NAN | 59.43 | 50.07 | 50.48 | 40.49 |
| PPFS-GAF | 60.12 | 50.09 | 57.34 | 37.90 | 60.09 | 50.00 | NAN | NAN | 59.22 | 49.93 | 49.58 | 40.50 | |
| PPFS-GAK/PPFS-TK | 60.70 | 49.94 | 47.08 | 38.14 | 60.85 | 50.00 | NAN | NAN | 59.98 | 50.26 | 51.28 | 42.01 | |
| PPFS-TF | 60.10 | 50.09 | 56.98 | 37.91 | 60.08 | 50.00 | NAN | NAN | 60.08 | 50.00 | 31.38 | NAN | |
| SVM Accuracy | PPFS-GAF (%) | PPFS-GAK (%) | PPFS-TF (%) | PPFS-TK (%) | CFS (%) | PCA (%) | GainRatio (%) | MutualInfo (%) | GiniIndex (%) |
|---|---|---|---|---|---|---|---|---|---|
| Breast Cancer | 96.17 | 98.56 | 98.56 | 98.56 | 95.80 | 94.96 | 90.90 | 85.65 | 85.65 |
| Liver Disorder | 65.05 | 73.79 | 65.05 | 73.79 | 58.12 | 59.83 | 59.22 | 58.25 | 53.40 |
| Sonar | 82.26 | 85.58 | 86.06 | 87.98 | 90.76 | 93.28 | 53.23 | 77.42 | 77.42 |
| Wine | 96.15 | 96.15 | 96.15 | 96.15 | 63.38 | 78.87 | 80.77 | 88.46 | 88.46 |
| Spam | 93.04 | 93.6 | 93.04 | 93.62 | 85.76 | 86.41 | 83.47 | 96.61 | 96.61 |
| Waveform | 83.79 | 81.65 | 83.79 | 81.45 | 34.43 | 98.36 | 69.85 | 66.18 | 66.18 |
| Vehicle | 83.33 | 83.33 | 79.36 | 83.33 | 65.87 | 73.02 | 53.97 | 48.41 | 55.56 |
| Diabetes | 81.30 | 81.30 | 81.30 | 81.30 | 78.70 | 77.73 | 73.91 | 73.91 | 73.91 |
| Climate | 91.93 | 91.93 | 91.93 | 91.93 | 91.93 | 91.48 | 91.93 | 91.93 | 91.93 |
| WDBC | 95.29 | 98.24 | 98.24 | 98.24 | 95.29 | 93.67 | 90.59 | 91.18 | 91.18 |
| Autralian | 83.50 | 83.50 | 85.92 | 85.92 | 79.13 | 85.51 | 61.65 | 63.59 | 63.59 |
| Stock | 95.42 | 95.42 | 83.10 | 86.62 | 75.00 | 82.74 | 84.15 | 84.50 | 84.50 |
| Glass | 60.32 | 69.84 | 69.84 | 69.84 | 65.07 | 64.49 | 65.08 | 65.08 | 65.08 |
| Segment | 86.58 | 89.47 | 89.47 | 85.14 | 58.83 | 82.29 | 51.80 | 75.90 | 74.31 |
| Heart | 82.72 | 82.72 | 82.72 | 82.72 | 82.72 | 81.85 | 77.78 | 55.56 | 55.56 |
| Ionosphere | 80.77 | 90.38 | 80.77 | 81.73 | 82.69 | 88.03 | 75.00 | 64.42 | 64.42 |
| Colon | 83.33 | 83.33 | 83.33 | 83.33 | 81.73 | 80.65 | - | - | - |
| August S.P | 56.50 | 61.02 | 61.02 | 61.02 | 44.07 | 52.19 | 44.06 | 48.59 | 48.59 |
| Fifa2019 | 60.09 | 60.85 | 60.08 | 60.85 | 60.09 | 60.08 | 60.09 | 60.09 | 60.09 |
| PPFS-GAK | CFS | PCA | GainRatio | MutualInfo | GiniIndex | |
|---|---|---|---|---|---|---|
| - | 0.043 | 0.325 | 0.007 | 0.008 | 0.009 | |
| Median | 84.5 | 76.8 | 82.5 | 71.9 | 70.0 | 70.0 |
| Mean | 84.3 | 72.6 | 80.3 | 70.4 | 72.0 | 72.0 |
| kNN/PPFS | PPFS-GAF (%) | PPFS-GAK (%) | PPFS-TF (%) | PPFS-TK (%) | WOA (%) | PSO (%) | GA (%) |
|---|---|---|---|---|---|---|---|
| Breast Cancer | 97.61 | 96.85 | 96.85 | 96.85 | 96.83 | 95.4 | 95.5 |
| Sonar | 75.81 | 66.13 | 75.81 | 67.74 | 91.9 | 74.0 | 72.6 |
| Wave F. | 82.45 | 82.12 | 82.45 | 81.99 | 75.33 | 76.1 | 76.7 |
| Wine | 98.08 | 96.15 | 96.15 | 96.15 | 95.90 | 95.0 | 93.30 |
| WDBC | 95.29 | 98.24 | 98.24 | 98.24 | 97.10 | 94.10 | 93.80 |
| Heart | 81.48 | 81.48 | 81.48 | 81.48 | 80.70 | 78.40 | 82.20 |
| Ionosphere | 87.50 | 81.73 | 84.62 | 84.62 | 92.56 | 84.30 | 83.40 |
| Colon | 72.22 | 77.78 | 77.78 | 77.78 | 90.90 | 84.30 | 83.40 |
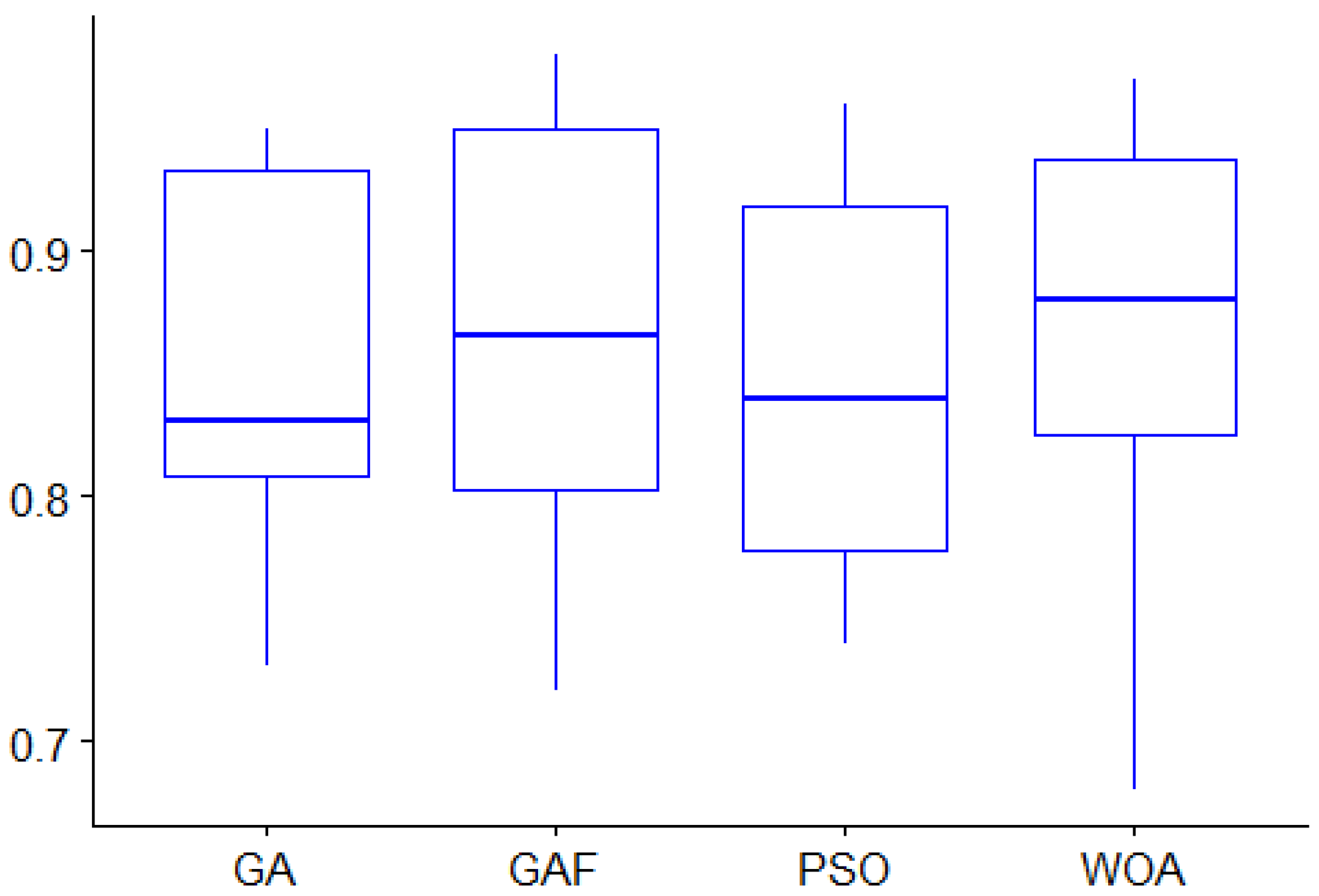
| PPFS-GAF | WOA | PSO | GA | |
|---|---|---|---|---|
| Median | 86.5 | 88 | 84 | 83 |
| Mean | 86.5 | 86.8 | 84.8 | 85 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larabi-Marie-Sainte, S. Outlier Detection Based Feature Selection Exploiting Bio-Inspired Optimization Algorithms. Appl. Sci. 2021, 11, 6769. https://doi.org/10.3390/app11156769
Larabi-Marie-Sainte S. Outlier Detection Based Feature Selection Exploiting Bio-Inspired Optimization Algorithms. Applied Sciences. 2021; 11(15):6769. https://doi.org/10.3390/app11156769
Chicago/Turabian StyleLarabi-Marie-Sainte, Souad. 2021. "Outlier Detection Based Feature Selection Exploiting Bio-Inspired Optimization Algorithms" Applied Sciences 11, no. 15: 6769. https://doi.org/10.3390/app11156769
APA StyleLarabi-Marie-Sainte, S. (2021). Outlier Detection Based Feature Selection Exploiting Bio-Inspired Optimization Algorithms. Applied Sciences, 11(15), 6769. https://doi.org/10.3390/app11156769