
VivesDebate: A New Annotated Multilingual Corpus of Argumentation in a Debate Tournament


Abstract
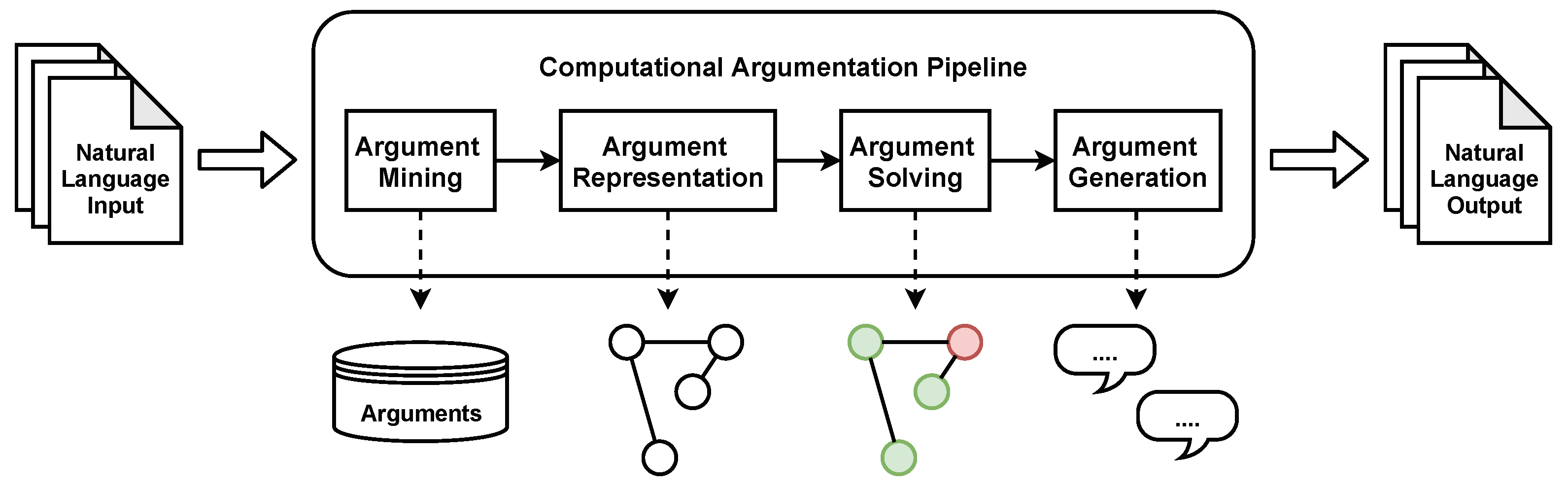
:1. Introduction
2. Argumentation in Professional Debate Tournaments
3. Annotation Methodology
3.1. Revision and Correction of Automatic Transcriptions
- To maintain the transcriptions of the different linguistic variants of the same language used in the original debates—Balearic, central and north-western Catalan and Valencian—as well as the use of words or expressions from other languages, but which are not normative, such as borrowings from Spanish and from English. It is worth noting that the eastern variants (Balearic and central Catalan) are the prevailing variants of the MLLP transcriber.
- To correct spelling errors, such as ‘*autonoma’ instead of ‘autònoma/autonomous’ (missing accent), ‘*penalitzar vos’ instead of ‘penalitzar-vos/penalize you’ (missing hyphen).
- To amend those words that were not correctly interpreted by the automatic transcriber, especially wrongly segmented words. For instance, ‘*debatre/to debate’ instead of ‘debatrà/he or she will debate’, or ‘*desig de separa/the desire to (he/she) separates’ instead of ‘desig de ser pare/the desire to be a father’. In the first example, the automatic transcription does not correctly interpret the tense and person of the verb, and in the second example it wrongly interprets as a single word (‘separa’) two different words ‘ser pare’, probably due to the elision of ‘r’ when we pronounce ‘ser’ and due to the confusion that can be caused by the Catalan unstressed vowels ‘a’ and ‘e’, which in some linguistic variants are pronounced the same way. Most of these errors are related to homophonous words or segments, which the automatic transcriber cannot distinguish correctly, and are also probably due to the different linguistic variants of the same language used in the debates (Balearic, central and north-western Catalan and Valencian).
- To follow the criteria established by the linguistic portal of the Catalan Audiovisual Media Corporation (http://esadir.cat/, accessed on 2 August 2021) for spelling the names of persons, places, demonyms, and so forth.
- To capture and write down the main ideas in those cases in which the quality of the audio does not allow us to understand part of the message conveyed.
- Noisy sounds and hesitations (e.g., ‘mmm’, ‘eeeeh’), self-corrections (e.g., ‘mètode arlt alternatiu/arlt alternative method’) and repetitions (‘el que fa el que fa és ajudar/what it does it does is to help)’ are not included because they do not provide relevant information for computational tasks focused on argumentation.
3.2. Segmentation of Debates in Argumentative Discourse Units (ADUs)
Segmentation Criteria
- Punctuation marks must not be added to the content of the ADUs. The annotators could view the debate recording to solve ambiguous interpretations and avoid a misinterpretation of the message.
- Anaphoric references are left as they are, there is no need to reconstruct them, that is, the antecedent of the anaphora is not retrieved.
- (1a)
- [és una forma d’explotació de la dona][és una forma de cosificar-la][i és una forma que fa que vulneri la seva dignitat]
- (1b)
- [it is a way of exploiting women][it is a way of objectifying them][and it is a way of violating their dignity]
In example (1), the text contains three different ADUs and two anaphoric elements appear in the second and third ADUs, ‘-la/her’ in ADU2 and ‘seva/her’ in ADU3, which refer to the same entity (‘dona/woman’), but we did not retrieve their antecedent in the corresponding ADUs. - Discourse markers (2) must be removed from the content of the ADUs, but the discourse connectors (3) will be kept. Discourse connectors are relevant because they introduce propositions indicating cause, consequence, conditional relations, purpose, contrast, opposition, objection, and so forth, whereas discourse markers are used to introduce a topic to order, to emphasize, to exemplify, to conclude, and so forth. We followed the distinction between discourse connectors and markers established in the list provided by the Language and Services and Resources at UPC (https://www.upc.edu/slt/ca/recursos-redaccio/criteris-linguistics/frases-lexic-paragraf/marcadors-i-connectors, accessed on 2 August 2021).
- (2)
- Examples of discourse markers: ‘Respecte de/ regarding’; ‘en primer lloc/first or firstly’; ‘per exemple/for instance’; ‘en d’altres paraules/in a nutshell’; ‘per concloure/in conclusion’.
- (3)
- Examples of discourse connectors?: ‘per culpa de/due to’; ‘a causa de/because of’; ‘ja que/since’; ‘en conseqüència/consequently’; ‘per tant/therefore’; ‘si/if’; ‘per tal de/in order to’; ‘tanmateix/however’; ‘encara que/although’; ‘a continuació/then’.
- Regarding coordination and juxtaposition, we segmented coordinated sentences differently from coordinated phrases and words: (a) In coordinated sentences, each sentence was analysed as an independent ADU and the coordinating conjunction (e.g., copulative, disjunctive, adversative, distributive) was included at the beginning of the second sentence (4). The type of conjunction can be used to assign the argumentative relation in the following task; (b) In coordinated phrases and words, each of the joined elements are included in the same single ADU (5).
- (4a)
- [l’adopció s’està quedant obsoleta][i per això hem de legislar]
- (4b)
- [adoption is becoming obsolete][and that’s why we have to legislate]
- (5a)
- [justícia i gratuïtat per evitar la desigualtat social]
- (5b)
- [justice and gratuity to avoid social inequality]
- Regarding subordinated sentences, the subordinated (or dependent) clause is analysed as an ADU that is independent from the main (or independent) clause, and includes the subordinating conjunction (6). The type of subordinating conjunction (e.g., causal, conditional, temporal, etc.) can be used to assign the argumentative relation.
- (6a)
- [si s’acaba el xou] [s’acaba la publicitat]
- (6b)
- [if the show is over] [advertising is over]
In example 6, two different ADUs are created, in which the second clause (ADU2) will then be annotated as an inference argumentative relation from the first clause (ADU1). In this way, if later, there a proposition appears that is only related to one of the two previous clauses, this proposition can be related to the corresponding ADU. - Regarding relative clauses, the relative clause is included in the same ADU as the main clause, because these clauses function syntactically as adjectives. However, they can be treated as a subsegment of the ADU if the relative clause acts as an argument (7).
- (7a)
- [suposa un desig de les persones que fa perpetuar un rol històric de la dona][que fa perpetuar un rol històric de la dona][afirma i legitima que les dones han de patir]
- (7b)
- [this presupposes a desire by people to perpetuate a historical role for a woman][to perpetuate a historical role for a woman][this asserts and legitimatizes the idea that women must suffer]
In (7), the relative clause is segmented as an independent ADU2, because it is the argument to which ADU3 refers. - In reported speech or epistemic expressions, we distinguish whether the epistemic expression is generated by one of the participants in the debate (8) or is generated by another (usually well-known or renowned) person (9). In the former, the subordinate clause is only analysed as an ADU while, in the latter, the whole sentence is included in the same ADU.
- (8a)
- Jo pense que es deurien prohibir les festes amb bous ja que impliquen maltractament animal[es deurien prohibir les festes amb bous][ja que impliquen maltractament animal]
- (8b)
- I think bullfights should be banned as they involve animal abuse[bullfights should be banned as they involve animal abuse][as they involve animal abuse]
- (9a)
- [Descartes pensa que cos i ànima són dues entitats totalment separades]
- (9b)
- [Descartes thinks that body and soul are two totally separate entities]
In example (8), the ADU already indicates which specific participant uttered this argument in the STANCE and ARGUMENT_NUMBER tags associated, as we describe in more detail below (Section 4.2). Therefore, including this information would be redundant. However, in example (9), it would not be redundant and could be used in further proposals to identify, for instance, arguments from popular, well-known or expert opinion and arguments from witness testimony. - With regard to interruptions within the argumentative speech produced by the same participant, the inserted text will be deleted (10), whereas if the interruption is made by a participant of the opposing group, it will be added to another ADU (11).
- (10a)
- el que estan fent vostès, i aquest és l’últim punt, és culpabilitzar a la víctima[el que estan fent vostès és culpabilitzar a la víctima]
- (10b)
- what you are doing, and this is my last point, is to blame the victim[what you are doing is to blame the victim]
- (11a)
- centenars de dones han firmat un manifest per tal de garantir d’adherir-se a la seua voluntat de ser solidàries, que passa si els pares d’intenció rebutgen el nen i on quedaria la protecció del menor en el seu model, completament garantida per l’estat[centenars de dones han firmat un manifest per tal de garantir d’adherir-se a la seua voluntat de ser solidàries completament garantida per l’estat][que passa si els pares d’intenció rebutgen el nen i on quedaría la protecció del menor en el seu model]
- (11b)
- hundreds of women have signed a manifesto to ensure that they adhere to their willingness to be in solidarity, what happens if the intended parents reject the child and where would the protection of the child be in your model, fully guaranteed by the state[hundreds of women have signed a manifesto to ensure that they adhere to the to their willingness to be in solidarity fully guaranteed by the state][what happens if the intended parents reject the child and where would the protection of the child be in your model]
In (11), the initial fragment of text is segmented into two different ADUs. The interruption (in italics) is segmented separately and tagged as ADU2. If an argumentative relation is observed in an interruption made by the same participant, this part of the text will be analysed as a new ADU and, therefore, will not be removed since it establishes the relationship between arguments. - Interrogative sentences are analysed as ADUs because they can be used to support an argument (12), except when they are generic questions (13).
- (12a)
- [Això fa que no necessàriament ho valori econòmicament?] [No]
- (12b)
- [Does that necessarily mean that I do not value it economically?] [No]
- (13a)
- Què en penses d’això?
- (13b)
- What do you think about that?
It should be noted that tag questions are not annotated as ADUs. In (14) ‘oi?/right?’ is not tagged as an ADU.- (14a)
- [Això fa que no necessàriament ho valori econòmicament] oi?
- (14a)
- [Does that necessarily mean that I do not value it economically] right?
- In the case of emphatic expressions (15), only the main segment is included in the ADU.
- (15a)
- sí que [hi ha la possibilitat]
- (15b)
- yes [there is the possibility]
- Examples and metaphoric expressions are annotated as a single ADU, because the relationship with another ADU is usually established with the whole example or the whole metaphor (16). In cases in which the relationship with another ADU only occurs with a part of the metaphorical expression or example, a subsegment can be created with its corresponding identity ADU.
- (16a)
- [aquest mateix any una dona es va haver de suïcidar just abans del seu desnonament o per exemple una mare va saltar per un pont amb el seu fill perquè no podia fer-se càrrec d’un crèdit bancari][si la gent és capaç de suïcidar-se per l’opressió dels diners com no es vendran a la gestació subrogada]
- (16a)
- [this same year a woman had to commit suicide just before her eviction or for example a mother jumped off a bridge with her child because she could not pay back a bank loan][if people are able to commit suicide because of the oppression of money why shouldn’t they sell themselves in surrogacy]
The ADU2, in (16), which includes an example, is related to the previous ADU1. - Expressions including desideratum verbs (17) are not considered ADUs.
- (17a)
- A mi m’agradaria anar a l’ONU i explicar els mateixos arguments per a que aquesta prohibició no sigui només a Espanya.
- (17b)
- I would like to go to the UN and present the same arguments so that this prohibition is not only in Spain.
3.3. Annotation of Argumentative Relationships between ADUs
- Inference (RA) indicates that the meaning of an ADU can be inferred, entailed or deduced from a previous ADU (18). As already indicated, the direction of the inference almost always goes from one ADU to a previous ADU, but we have also found cases in which the direction is the opposite, that is, the inference goes from a previous ADU to a following one, although there are fewer cases (19). Therefore, inference is a meaning relation in which the direction of the relationship between ADUs is relevant, and this direction is represented by the REL_ID tag.
- (18a)
- [la gestació subrogada és una pràctica patriarcal]ADU1[ja que el major beneficiari d’aquesta pràctica ésl’home]ADU2 REL_ID=1 REL_TYPE=RA
- (18b)
- [surrogacy is a patriarchal practice]ADU1[since the main beneficiary of this practice is the man]ADU2 REL_ID=1 REL_TYPE=RA
- (19a)
- [no tot progrés científic implica un progrés social]ADU1 REL_ID=2;3 REL_TYPE=RA[l’energia nuclear és la mare de la bomba atòmica][Els pesticides que multiplicaven les collites han estat prohibits per convertir el aliments en insalubres]
- (19b)
- [not all scientific progress implies social progress]ADU1 REL_ID=2;3 REL_TYPE=RA[nuclear energy is the mother of the atomic bomb][pesticides that multiplied crops have been bannedfor making food unhealthy]
In example (18), REL_TYPE=RA and REL_ID=1 indicate that ADU2 is an inference of ADU1, whereas in example (19) the REL_TYPE=RA and REL_ID=2;3 are annotated in ADU1 because it is an inference of ADU2 and ADU3, which appear in the original text below ADU1. - Conflict is the argumentative relationship assigned when two ADUs present contradictory information or when these ADUs contain conflicting or divergent arguments (20). We consider that two ADUs are contradictory ‘if they are extremely unlikely to be considered true simultaneously’ [27].
- (20a)
- [vol tenir és dret a formar una família][formar famílies no és un dret]ADU2 REL_ID=1 REL_TYPE=CA
- (20b)
- [she wants to have the right to form a familiy][to form families is not a righty]ADU2 REL_ID=1 REL_TYPE=CA
- Reformulation is the argumentative relationship in which two ADUs have approximately the same or a similar meaning, that is, an ADU reformulates or paraphrases the same discourse argument as that of another ADU (21). The reformulation or paraphrase involves changes at different linguistic levels, for instance, morphological, lexical, syntactic and discourse-based changes [28].
- (21a)
- [ja n’hi ha prou de paternalism][ja n’hi ha prou que ens tracten com a xiquetes]ADU2 REL_ID=1 REL_TYPE=MA
- (21b)
- [enough of paternalism][enough of treating us like children]ADU2 REL_ID=1 REL_TYPE=MA
It should be noted that repetitions are not considered reformulations. A repetition contains a claim or statement with the same content as a previous one, that is, the same argument. We consider an ADU to be a repetition only if it is exactly the same as a previous one and we do not therefore segment them and they are not annotated as ADUs.It is worth noting that, when a team mentions the opposing team’s argument, that mention is not considered an argument. When their reasoning is referred to, the reference will be ascribed directly to the opposing team’s argument.
3.4. Annotation Process
Inter-Annotator Agreement Tests
- In the case of the PHASE, STANCE and argument REL_TYPE tags, we considered agreement to be reached when the annotators assigned the same value to each tag, while disagreement was considered to be when the value was different.
- In the case of the ADU tag, we considered agreement to exist when the span of the ADUs matched exactly, and disagreement to exist when the span did not match at all or coincided partially. We have also conducted a third Inter-Annotator Agreement test for evaluating the ADU tag considering partial agreement. In this case, we considered agreement to exist when the span of the ADUs coincided partially (22)–(25).
- (22a)
- [la cosificació que s’està fent de la dona]
- (22b)
- [the objectivation of women]
- (23a)
- [ens centrarem en la cosificació que s’està fent de la dona]
- (23b)
- [we will focus on the objectivation of women]
- (24a)
- [el vincle que es genera entre ella i el nadó que porta al seu ventre] [és trencat de manera miserable]
- (24b)
- [the bond between her and the baby she carries in her womb] [is broken in a miserable way]
- (25a)
- [el vincle que es genera entre ella i el nadó que porta al seu ventre és trencat de manera miserable]
- (25b)
- [the bond between her and the baby she carries in her womb is broken in a miserable way]
4. The VivesDebate Corpus
4.1. Data Collection
4.2. Structure and Properties
5. Related Work: Other Computational Argumentation Corpora
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aristotle. Prior Analytics; Hackett Publishing: Indianapolis, IN, USA, 1989. [Google Scholar]
- Van Eemeren, F.; Grootendorst, R.; van Eemeren, F.H. A Systematic Theory of Argumentation: The Pragma-Dialectical Approach; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Walton, D.; Reed, C.; Macagno, F. Argumentation Schemes; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Rahwan, I.; Simari, G.R. Argumentation Theory: A Very Short Introduction. In Argumentation in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; Volume 47, pp. 1–22. [Google Scholar]
- Ruiz-Dolz, R. Towards an Artificial Argumentation System. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI-20, Yokohama, Japan, 11–17 July 2020; pp. 5206–5207. [Google Scholar]
- Palau, R.M.; Moens, M.F. Argumentation mining: The detection, classification and structure of arguments in text. In Proceedings of the 12th International Conference on Artificial Intelligence and Law, Barcelona, Spain, 8–12 June 2009; pp. 98–107. [Google Scholar]
- Lawrence, J.; Reed, C. Argument mining: A survey. Comput. Linguist. 2020, 45, 765–818. [Google Scholar] [CrossRef]
- Dung, P.M. On the acceptability of arguments and its fundamental role in nonmonotonic reasoning, logic programming and n-person games. Artif. Intell. 1995, 77, 321–357. [Google Scholar] [CrossRef] [Green Version]
- Bench-Capon, T. Value based argumentation frameworks. arXiv 2002, arXiv:cs/0207059. [Google Scholar]
- Dung, P.M.; Kowalski, R.A.; Toni, F. Assumption-based argumentation. In Argumentation in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; pp. 199–218. [Google Scholar]
- Prakken, H. An abstract framework for argumentation with structured arguments. Argum. Comput. 2010, 1, 93–124. [Google Scholar] [CrossRef] [Green Version]
- Baroni, P.; Caminada, M.; Giacomin, M. An introduction to argumentation semantics. Knowl. Eng. Rev. 2011, 26, 365. [Google Scholar] [CrossRef]
- Rago, A.; Toni, F.; Aurisicchio, M.; Baroni, P. Discontinuity-Free Decision Support with Quantitative Argumentation Debates. In Proceedings of the Fifteenth International Conference on the Principles of Knowledge Representation and Reasoning, Cape Town, South Africa, 25–29 April 2016. [Google Scholar]
- Craandijk, D.; Bex, F. Deep learning for abstract argumentation semantics. arXiv 2020, arXiv:2007.07629. [Google Scholar]
- Stab, C.; Daxenberger, J.; Stahlhut, C.; Miller, T.; Schiller, B.; Tauchmann, C.; Eger, S.; Gurevych, I. Argumentext: Searching for arguments in heterogeneous sources. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations, Washington, DC, USA, 18–19 April 2018; pp. 21–25. [Google Scholar]
- Bilu, Y.; Gera, A.; Hershcovich, D.; Sznajder, B.; Lahav, D.; Moshkowich, G.; Malet, A.; Gavron, A.; Slonim, N. Argument invention from first principles. arXiv 2019, arXiv:1908.08336. [Google Scholar]
- Ruiz-Dolz, R.; Alemany, J.; Heras, S.; García-Fornes, A. Automatic Generation of Explanations to Prevent Privacy Violations. XAILA@ JURIX. 2019. Available online: http://ceur-ws.org/Vol-2681/xaila2019-paper3.pdf (accessed on 2 August 2021).
- El Baff, R.; Wachsmuth, H.; Al Khatib, K.; Stede, M.; Stein, B. Computational argumentation synthesis as a language modeling task. In Proceedings of the 12th International Conference on Natural Language Generation, Tokyo, Japan, 29 October–1 November 2019; pp. 54–64. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ye, Y.; Teufel, S. End-to-End argument mining as Biaffine Dependency Parsing. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Kyiv, Ukraine, 19–23 April 2021; pp. 669–678. [Google Scholar]
- Ruiz-Dolz, R.; Alemany, J.; Heras, S.; Garcia-Fornes, A. Transformer-Based Models for Automatic Identification of Argument Relations: A Cross-Domain Evaluation. IEEE Intell. Syst. 2021. [Google Scholar] [CrossRef]
- Schiller, B.; Daxenberger, J.; Gurevych, I. Aspect-controlled neural argument generation. arXiv 2020, arXiv:2005.00084. [Google Scholar]
- Jorge, J.; Giménez, A.; Iranzo-Sánchez, J.; Civera, J.; Sanchís, A.; Juan, A. Real-Time One-Pass Decoder for Speech Recognition Using LSTM Language Models. In Proceedings of the Interspeech 2019, 20th Annual Conference of the International Speech Communication Association, Graz, Austria, 15–19 September 2019; pp. 3820–3824. [Google Scholar] [CrossRef] [Green Version]
- Peldszus, A.; Stede, M. From argument diagrams to argumentation mining in texts: A survey. Int. J. Cogn. Inform. Nat. Intell. (IJCINI) 2013, 7, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Budzynska, K.; Reed, C. Whence Inference. In University of Dundee Technical Report; University of Dundee: Dundee, UK, 2011. [Google Scholar]
- De Marneffe, M.C.; Rafferty, A.N.; Manning, C.D. Finding contradictions in text. In Proceedings of ACL-08: HLT; Association for Computational Linguistics: Stroudsbur, PA, USA, 2008; pp. 1039–1047. [Google Scholar]
- Kovatchev, V.; Martí, M.A.; Salamó, M. Etpc-a paraphrase identification corpus annotated with extended paraphrase typology and negation. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to its Methodology; Sage Publications: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Forcada, M.L.; Ginestí-Rosell, M.; Nordfalk, J.; O’Regan, J.; Ortiz-Rojas, S.; Pérez-Ortiz, J.A.; Sánchez-Martínez, F.; Ramírez-Sánchez, G.; Tyers, F.M. Apertium: A free/open-source platform for rule-based machine translation. Mach. Transl. 2011, 25, 127–144. [Google Scholar] [CrossRef]
- Iranzo-Sánchez, J.; Baquero-Arnal, P.; Díaz-Munío, G.V.G.; Martínez-Villaronga, A.; Civera, J.; Juan, A. The MLLP-UPV german-english machine translation system for WMT18. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Belgium, Brussels, 31 October–1 November 2018; pp. 418–424. [Google Scholar]
- Visser, J.; Konat, B.; Duthie, R.; Koszowy, M.; Budzynska, K.; Reed, C. Argumentation in the 2016 US presidential elections: Annotated corpora of television debates and social media reaction. Lang. Resour. Eval. 2020, 54, 123–154. [Google Scholar] [CrossRef] [Green Version]
- Janier, M.; Reed, C. Corpus resources for dispute mediation discourse. In Proceedings of the Tenth International Conference on Language Resources and Evaluation. European Language Resources Association, Portorož, Slovenia, 23–28 May 2016; pp. 1014–1021. [Google Scholar]
- Stab, C.; Gurevych, I. Annotating argument components and relations in persuasive essays. In Proceedings of the COLING 2014—The 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 1501–1510. [Google Scholar]
- Peldszus, A.; Stede, M. An annotated corpus of argumentative microtexts. In Proceedings of the Argumentation and Reasoned Action: Proceedings of the 1st European Conference on Argumentation, Lisbon, Portugal, 9–12 June 2015; Volume 2, pp. 801–815. [Google Scholar]
- Park, J.; Cardie, C. A corpus of erulemaking user comments for measuring evaluability of arguments. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Orbach, M.; Bilu, Y.; Gera, A.; Kantor, Y.; Dankin, L.; Lavee, T.; Kotlerman, L.; Mirkin, S.; Jacovi, M.; Aharonov, R.; et al. A dataset of general-purpose rebuttal. arXiv 2019, arXiv:1909.00393. [Google Scholar]
- Roush, A.; Balaji, A. DebateSum: A large-scale argument mining and summarization dataset. arXiv 2020, arXiv:2011.07251. [Google Scholar]
- Dumani, L.; Biertz, M.; Witry, A.; Ludwig, A.K.; Lenz, M.; Ollinger, S.; Bergmann, R.; Schenkel, R. The ReCAP corpus: A corpus of complex argument graphs on german education politics. In Proceedings of the 2021 IEEE 15th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 27–29 January 2021; IEEE: New York, NY, USA, 2021; pp. 248–255. [Google Scholar]
- Mayer, T.; Cabrio, E.; Villata, S. Transformer-based argument mining for healthcare applications. In Proceedings of the ECAI 2020, 24th European Conference on Artificial Intelligence, Santiago de Compostela, Spain, 29 August–8 September 2020. [Google Scholar]
- Xu, H.; Šavelka, J.; Ashley, K.D. Using argument mining for Legal Text Summarization. In Legal Knowledge and Information Systems (JURIX); IOS Press: Amsterdam, The Netherlands, 2020; pp. 184–193. Available online: https://ebooks.iospress.nl/volume/legal-knowledge-and-information-systems-jurix-2020-the-thirty-third-annual-conference-brno-czech-republic-december-911-2020 (accessed on 2 August 2021).
- Dusmanu, M.; Cabrio, E.; Villata, S. Argument mining on Twitter: Arguments, facts and sources. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 2317–2322. [Google Scholar]


{kind=link}
{kind=link}
| Tag | Observed Agreement % | Krippendorff’s Alpha |
|---|---|---|
| STANCE (AGAINST/FAVOUR) | 99.05 | 0.979 |
| PHASE (INTRO/ARG1,ARG2,ARG3/CONC) | 94.60 | 0.925 |
| REL_TYPE (RA/CA/MA) | 86.00 | 0.913 |
| ADU (1st IAA Test) | 70.80 | 0.392 |
| ADU (2nd IAA Test) | 76.60 | 0.777 |
| ADU (3rd IAA Test partial disagreements) | 91.20 | 0.917 |
| ID | Phase | Arg. Number (*) | Stance | ADU_CAT, ADU_ES, ADU_EN | Related ID | Relation Type |
|---|---|---|---|---|---|---|
| 1 | INTRO | FAVOUR | quan mireu aquí què veieu (cuando miráis aquí qué veis) (when you look here what do you see) | |||
| 2 | INTRO | FAVOUR | cinquanta euros (cincuenta euros) (fifty euros) | 1 | RA | |
| 3 | INTRO | FAVOUR | el nostre nou déu (nuestro dios) (our new god) | 2 | RA | |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| 43 | ARG1 | 1 | FAVOUR | vivim en un món on ha guanyat els valors del neoliberalisme (vivimos en un mundo dominado por los valores del neoliberalismo) (we live in a world dominated by the values of neoliberalism) | ||
| 44 | ARG1 | 1 | FAVOUR | uns valors que ens diuen que si tenim diners som guanyadors (valores que dicen que si tenemos dinero somos ganadores) (values that say that if we have money we are winners) | 43 | RA |
| 45 | ARG1 | 1 | FAVOUR | i si som guanyadors podem comprar tot allò que desitgem (y si somos ganadores podemos comprar lo que deseemos) (and if we are winners we can buy whatever we want) | 44 | RA |
| 46 | ARG1 | 1 | FAVOUR | és el model que està imperant en la gestació subrogada (es el modelo que impera en la gestación subrogada) (is the prevailing surrogacy model) | 43; 44; 45 | RA |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| 144 | ARG1 | 3 | AGAINST | per suposat que no (por supuesto que no) (of course not) | 143 | CA |
| 145 | ARG1 | 3 | AGAINST | no és que vullguem que hi haja més xiquets (no es que queramos que haya más niños) (not that we want there to be more children) | 140 | RA |
| 146 | ARG1 | 3 | AGAINST | sinó tot el contrari (sino todo lo contrario) (quite the contrary) | 145 | MA |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| Debate | Stance | Score | Thesis Solidity | Argument Quality | Adaptability |
|---|---|---|---|---|---|
| Debate1 | Favour | 3.32 | 3.25 | 3.37 | 3.33 |
| Debate1 | Against | 3.29 | 3.33 | 3.18 | 3.38 |
| Debate2 | Favour | 3.41 | 3.5 | 3.33 | 3.42 |
| Debate2 | Against | 3.43 | 3.17 | 3.58 | 3.58 |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| Debate28 | Favour | 2.75 | 3.25 | 2.75 | 2.17 |
| Debate28 | Against | 2.36 | 2.77 | 2.25 | 2.00 |
| File | Words | ADUs | Conflicts | Inferences | Rephrases | Score F | Score A |
|---|---|---|---|---|---|---|---|
| Debate1.csv | 3979 | 198 | 4 | 158 | 22 | 3.32 | 3.29 |
| Debate2.csv | 5178 | 371 | 60 | 310 | 32 | 3.41 | 3.43 |
| Debate3.csv | 4932 | 311 | 63 | 360 | 22 | 4.39 | 4.31 |
| Debate4.csv | 6243 | 308 | 8 | 229 | 37 | 4.01 | 4.15 |
| Debate5.csv | 5389 | 270 | 45 | 505 | 48 | 4.38 | 3.28 |
| Debate6.csv | 4387 | 324 | 45 | 219 | 42 | 2.94 | 3.02 |
| Debate7.csv | 4523 | 299 | 11 | 236 | 18 | 3.31 | 3.13 |
| Debate8.csv | 4933 | 220 | 5 | 185 | 15 | 3.31 | 3.92 |
| Debate9.csv | 5574 | 352 | 45 | 309 | 18 | 4.12 | 4.21 |
| Debate10.csv | 4284 | 279 | 12 | 207 | 39 | 4.39 | 3.46 |
| Debate11.csv | 5720 | 239 | 5 | 202 | 16 | 3.60 | 3.64 |
| Debate12.csv | 5305 | 283 | 83 | 477 | 49 | 4.12 | 4.36 |
| Debate13.csv | 3646 | 138 | 10 | 106 | 6 | 2.94 | 2.60 |
| Debate14.csv | 4790 | 302 | 74 | 400 | 47 | 3.83 | 3.80 |
| Debate15.csv | 4550 | 173 | 23 | 113 | 13 | 3.95 | 3.94 |
| Debate16.csv | 4887 | 288 | 94 | 639 | 53 | 3.33 | 3.39 |
| Debate17.csv | 3891 | 164 | 8 | 123 | 8 | 3.00 | 3.26 |
| Debate18.csv | 3701 | 166 | 6 | 149 | 4 | 2.80 | 2.77 |
| Debate19.csv | 4645 | 186 | 13 | 159 | 1 | 4.24 | 4.34 |
| Debate20.csv | 5484 | 306 | 33 | 1306 | 55 | 3.53 | 3.49 |
| Debate21.csv | 5064 | 278 | 102 | 1076 | 42 | 3.17 | 3.18 |
| Debate22.csv | 4669 | 330 | 16 | 408 | 1 | 4.40 | 4.22 |
| Debate23.csv | 4420 | 266 | 136 | 917 | 26 | 2.74 | 2.69 |
| Debate24.csv | 5139 | 267 | 380 | 1002 | 39 | 4.41 | 4.37 |
| Debate25.csv | 4828 | 321 | 7 | 337 | 0 | 4.09 | 3.88 |
| Debate26.csv | 4440 | 290 | 16 | 328 | 5 | 4.16 | 3.93 |
| Debate27.csv | 5012 | 234 | 106 | 645 | 24 | 3.49 | 2.33 |
| Debate28.csv | 4254 | 310 | 21 | 344 | 2 | 2.75 | 2.36 |
| Debate29.csv | 5889 | 337 | 51 | 1203 | 72 | - | - |
| VivesDebate | 139,756 | 7810 | 1558 | 12,653 | 747 | - | - |
| Research | Identifier | Format | Source | Domain | Tasks | Language | Size | Annotation Ratio |
|---|---|---|---|---|---|---|---|---|
| [34] | Persuasive Essays | M | T | Online Forum | AM | EN | 34,917 (W) | 388 w/d |
| [35] | Microtexts | M | T | Controlled Experiment | AM | EN + DE | 576 (S) | 5 s/d |
| [33] | DMC | D | S | Academic + Online + Professional | AM + AA | EN | 18,628 (W) | 144 w/d |
| [36] | CDCP | D | T | Online Forum | AM + AE | EN | 4931 (S) | 6.7 s/d |
| [37] | GPR-KB-55 | D | S | Competitive Debate | AG | EN | 12,431 (S) | 41 w/d |
| [32] | US2016 | D | T + S | Political + Online | AM + AA | EN | 97,999 (W) | 189 w/d |
| [32] | US2016TV | D | S | Political | AM + AA | EN | 58,900 (W) | 492 w/d |
| [32] | US2016Reddit | D | T | Online Forum | AM + AA | EN | 39,099 (W) | 137 w/d |
| [38] | DebateSum | D | S | Competitive Debate | AS | EN | 101M (W) | 520 w/d |
| [39] | ReCAP | M | T | Political | AM + AA | DE + EN (*) | 16,700 (W) | 150 w/d |
| VivesDebate | D | S | Competitive Debate | AM + AA + AE + AG/AS | CAT + ES (*) + EN (*) | 139,756 (W) | 4819 w/d |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz-Dolz, R.; Nofre, M.; Taulé, M.; Heras, S.; García-Fornes, A. VivesDebate: A New Annotated Multilingual Corpus of Argumentation in a Debate Tournament. Appl. Sci. 2021, 11, 7160. https://doi.org/10.3390/app11157160
Ruiz-Dolz R, Nofre M, Taulé M, Heras S, García-Fornes A. VivesDebate: A New Annotated Multilingual Corpus of Argumentation in a Debate Tournament. Applied Sciences. 2021; 11(15):7160. https://doi.org/10.3390/app11157160
Chicago/Turabian StyleRuiz-Dolz, Ramon, Montserrat Nofre, Mariona Taulé, Stella Heras, and Ana García-Fornes. 2021. "VivesDebate: A New Annotated Multilingual Corpus of Argumentation in a Debate Tournament" Applied Sciences 11, no. 15: 7160. https://doi.org/10.3390/app11157160
APA StyleRuiz-Dolz, R., Nofre, M., Taulé, M., Heras, S., & García-Fornes, A. (2021). VivesDebate: A New Annotated Multilingual Corpus of Argumentation in a Debate Tournament. Applied Sciences, 11(15), 7160. https://doi.org/10.3390/app11157160