
Context-Based Structure Mining Methodology for Static Object Re-Identification in Broadcast Content


Abstract
:1. Introduction
- We propose a flexible pipeline that can derive high-level features from detection algorithms and semantically enrich a video by performing automatic video structure mining. This pipeline consolidates the frame-level place and object tags using time-efficient deep neural networks in such a way that it could be used for further enrichment tasks, such as re-ID.
- Within the pipeline, we have implemented a novel boundary-detection algorithm to cluster the temporally coherent, semantically closer segments into shots and LSUs.
- We also propose a novel multi-object re-ID algorithm-based on context similarity in SOAP and broadcast content to generate object timelines.
2. Related Work
2.1. Semantic Extraction
2.1.1. Image Classification and Localization
2.1.2. Video Annotation
2.2. Boundary Detection
3. Methodology
- Semantic Extraction
- Structure Mining
- Similarity Estimation
- Object Re-Identification
3.1. Semantic Extraction: Recognizing Objects, Places and Their Relations
Feature Extraction
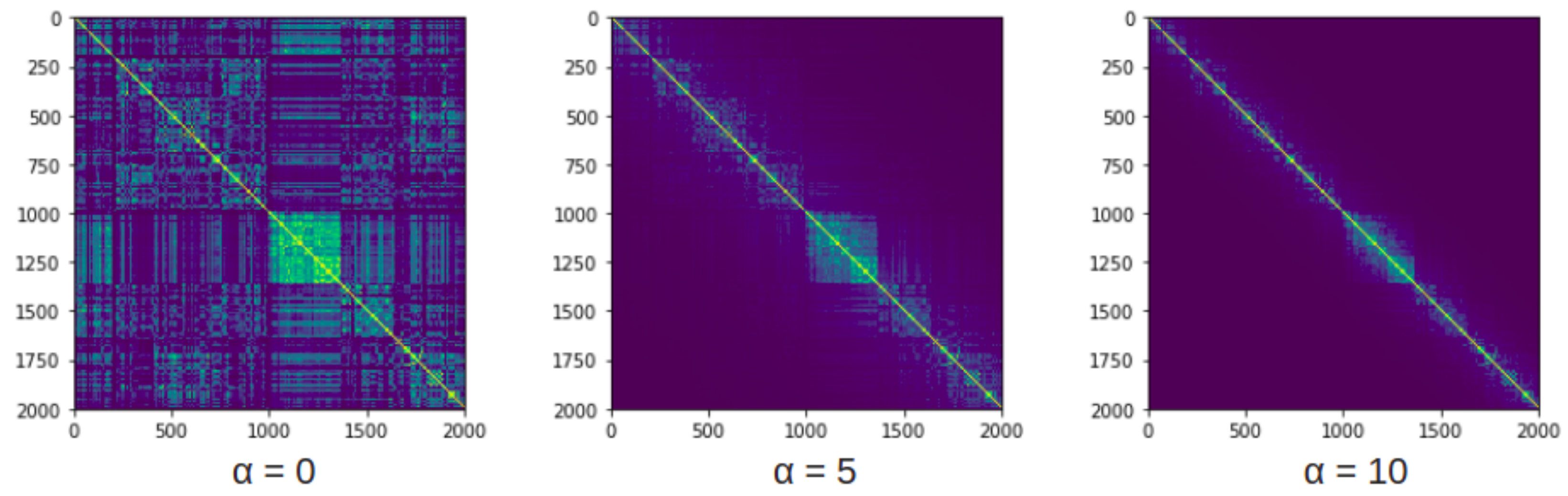
3.2. Structure Mining: Shot Boundary Detection
- Spatio-Temporal Visual Similarity Modelling
- Semantic similarity scoring scheme
- Temporal model analysis
3.2.1. Semantic Similarity Scoring Scheme
3.2.2. Temporal Model Analysis
3.2.3. Boundary Prediction
| Algorithm 1: Shot boundary detection |
 |
3.3. Similarity Estimation: Context Based Logical Story Unit Detection
3.4. Object Re-Identification
3.4.1. Explanation
- Single instance
- Multiple instance
3.4.2. Single Instance
3.4.3. Multiple Instance
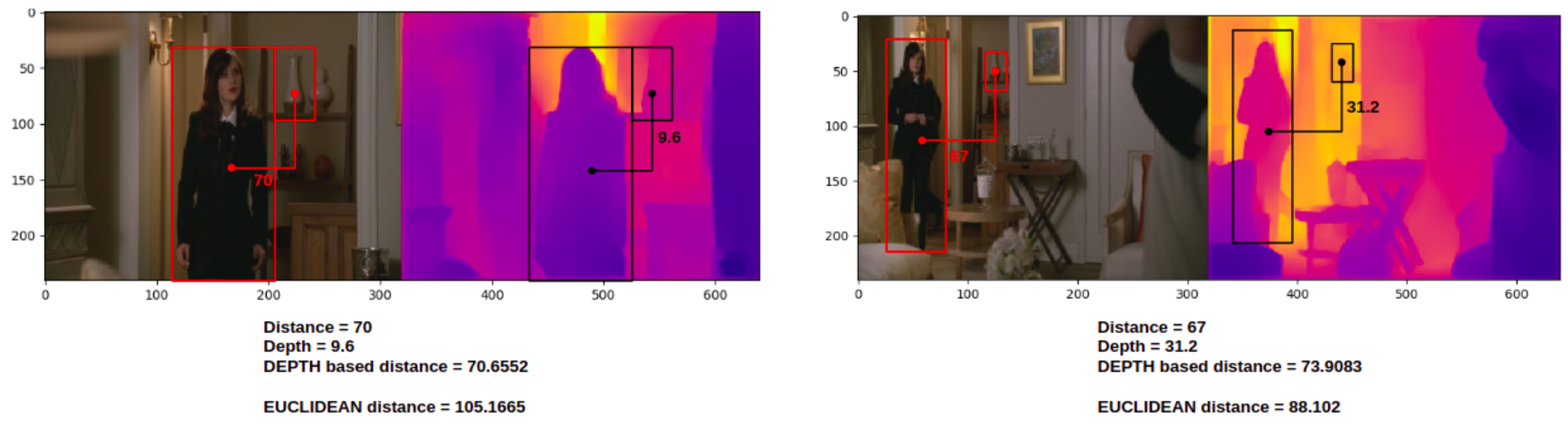
- Spatial Distance Estimation
- Spatial Location Graph
| Algorithm 2: Multi–object re–ID. |
 |
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
5. Results and Discussion
5.1. Quantitative Results
5.1.1. Shot Boundary Detection
5.1.2. LSU Boundary Detection
5.1.3. Object re-ID
5.2. Ablation Study
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bagdanov, A.D.; Bertini, M.; Bimbo, A.D.; Serra, G.; Torniai, C. Semantic annotation and retrieval of video events using multimedia ontologies. In Proceedings of the International Conference on Semantic Computing (ICSC 2007), Irvine, CA, USA, 17–19 September 2007; pp. 713–720. [Google Scholar] [CrossRef]
- Lu, Z.; Grauman, K. Story-driven summarization for egocentric video. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2714–2721. [Google Scholar] [CrossRef] [Green Version]
- Mahasseni, B.; Lam, M.; Todorovic, S. Unsupervised Video Summarization with Adversarial LSTM Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2982–2991. [Google Scholar] [CrossRef]
- Goyal, P.; Hu, Z.; Liang, X.; Wang, C.; Xing, E.P. Nonparametric Variational Auto-encoders for Hierarchical Representation Learning. arXiv 2017, arXiv:1703.07027. [Google Scholar]
- Han, J.; Yang, L.; Zhang, D.; Chang, X.; Liang, X. Reinforcement Cutting-Agent Learning for Video Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Meng, J.; Wang, H.; Yuan, J.; Tan, Y. From Keyframes to Key Objects: Video Summarization by Representative Object Proposal Selection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1039–1048. [Google Scholar] [CrossRef]
- Plummer, B.A.; Brown, M.; Lazebnik, S. Enhancing Video Summarization via Vision-Language Embedding. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1052–1060. [Google Scholar] [CrossRef]
- Minerva, M.; Yeung, B.L.Y. Video content characterization and compaction for digital library applications. In Storage and Retrieval for Image and Video Databases V; International Society for Optics and Photonics: San Jose, CA, USA, 1997; Volume 3022, pp. 45–58. [Google Scholar] [CrossRef]
- Vendrig, J.; Worring, M. Systematic evaluation of logical story unit segmentation. IEEE Trans. Multimed. 2002, 4, 492–499. [Google Scholar] [CrossRef]
- Petersohn, C. Temporal Video Segmentation; Jörg Vogt Verlag: Dresden, Germany, 2010. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Altadmri, A.; Ahmed, A. Automatic semantic video annotation in wide domain videos based on similarity and commonsense knowledgebases. In Proceedings of the 2009 IEEE International Conference on Signal and Image Processing Applications, Kuala Lumpur, Malaysia, 18–19 November 2009; pp. 74–79. [Google Scholar] [CrossRef] [Green Version]
- Protasov, S.; Khan, A.M.; Sozykin, K.; Ahmad, M. Using deep features for video scene detection and annotation. Signal Image Video Process. 2018, 12, 991–999. [Google Scholar] [CrossRef]
- Ji, H.; Hooshyar, D.; Kim, K.; Lim, H. A semantic-based video scene segmentation using a deep neural network. J. Inf. Sci. 2019, 45, 833–844. [Google Scholar] [CrossRef]
- Torralba, A.; Murphy, K.P.; Freeman, W.T.; Rubin, M.A. Context-based Vision System for Place and Object Recognition. In Proceedings of the Ninth IEEE International Conference on Computer Vision, Nice, France, 13–16 October 2003; Volume 2, p. 273. [Google Scholar]
- Odobez, J.M.; Gatica-Perez, D.; Guillemot, M. Spectral structuring of home videos. In International Conference on Image and Video Retrieval; Springer: Berlin/Heidelberg, Germany, 2003; pp. 310–320. [Google Scholar]
- Kwon, Y.M.; Song, C.J.; Kim, I.J. A new approach for high level video structuring. In Proceedings of the 2000 IEEE International Conference on Multimedia and Expo. ICME2000 Proceedings, Latest Advances in the Fast Changing World of Multimedia (Cat. No.00TH8532), New York, NY, USA, 30 July–2 August 2000; Volume 2, pp. 773–776. [Google Scholar]
- Mitrović, D.; Hartlieb, S.; Zeppelzauer, M.; Zaharieva, M. Scene segmentation in artistic archive documentaries. In Symposium of the Austrian HCI and Usability Engineering Group; Springer: Berlin/Heidelberg, Germany, 2010; pp. 400–410. [Google Scholar]
- Gygli, M. Ridiculously Fast Shot Boundary Detection with Fully Convolutional Neural Networks. arXiv 2017, arXiv:1705.08214. [Google Scholar]
- Del Fabro, M.; Böszörmenyi, L. State-of-the-art and future challenges in video scene detection: A survey. Multimed. Syst. 2013, 19, 427–454. [Google Scholar] [CrossRef]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alhashim, I.; Wonka, P. High Quality Monocular Depth Estimation via Transfer Learning. arXiv 2019, arXiv:1812.11941. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Sidiropoulos, P.; Mezaris, V.; Kompatsiaris, I.; Meinedo, H.; Bugalho, M.; Trancoso, I. Temporal Video Segmentation to Scenes Using High-Level Audiovisual Features. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 1163–1177. [Google Scholar] [CrossRef]
- Baraldi, L.; Grana, C.; Cucchiara, R. A Deep Siamese Network for Scene Detection in Broadcast Videos. arXiv 2015, arXiv:1510.08893. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gygli et al. [20] | Our Approach | |||||
|---|---|---|---|---|---|---|
| Video | Precision | Recall | Fshot | Precision | Recall | Fshot |
| 23353 | 0.95 | 0.99 | 0.96 | 0.877 | 0.99 | 0.945 |
| 23357 | 0.91 | 0.97 | 0.939 | 0.874 | 0.99 | 0.940 |
| 23358 | 0.92 | 0.99 | 0.954 | 0.775 | 0.99 | 0.873 |
| 25008 | 0.94 | 0.94 | 0.94 | 0.849 | 0.99 | 0.918 |
| 25009 | 0.97 | 0.96 | 0.965 | 0.726 | 0.98 | 0.841 |
| 25010 | 0.93 | 0.94 | 0.935 | 0.955 | 0.99 | 0.977 |
| 25011 | 0.62 | 0.9 | 0.734 | 0.863 | 0.99 | 0.927 |
| 25012 | 0.66 | 0.89 | 0.758 | 0.890 | 0.890 | 0.89 |
| Average | 0.853 | 0.948 | 0.899 | 0.861 | 0.986 | 0.912 |
| Lorenzo et al. [27] | Sidiropoulos et al. [26] | Our Approach | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Video | Coverage | Overflow | Fscene | Coverage | Overflow | Fscene | Coverage | Overflow | Fscene |
| 23553 | 0.82 | 0.40 | 0.69 | 0.63 | 0.20 | 0.70 | 0.66 | 0.0083 | 0.79 |
| 23557 | 0.77 | 0.24 | 0.76 | 0.73 | 0.47 | 0.61 | 0.65 | 0.2016 | 0.72 |
| 23558 | 0.77 | 0.37 | 0.69 | 0.89 | 0.64 | 0.51 | 0.73 | 0.1346 | 0.80 |
| 25008 | 0.42 | 0.06 | 0.58 | 0.72 | 0.24 | 0.74 | 0.41 | 0.0100 | 0.58 |
| 25009 | 0.95 | 0.76 | 0.39 | 0.69 | 0.53 | 0.56 | 0.67 | 0.124 | 0.76 |
| 25010 | 0.66 | 0.40 | 0.63 | 0.89 | 0.92 | 0.15 | 0.66 | 0.012 | 0.79 |
| 25011 | 0.70 | 0.14 | 0.77 | 0.94 | 0.92 | 0.15 | 0.61 | 0.048 | 0.74 |
| 25012 | 0.53 | 0.15 | 0.65 | 0.93 | 0.94 | 0.11 | 0.63 | 0.0400 | 0.76 |
| Average | 0.70 | 0.30 | 0.66 | 0.8 | 0.63 | 0.43 | 0.63 | 0.074 | 0.74 |
| New Girl (10 episodes) | Friends (10 episodes) | |||
|---|---|---|---|---|
| Class | True | False | True | False |
| bed | 29 | 0 | 152 | 0 |
| bottle | 604 | 153 | 51 | 14 |
| refrigerator | 23 | 0 | 56 | 0 |
| sofa | 76 | 0 | 306 | 13 |
| dining table | 202 | 11 | 87 | 12 |
| vase | 43 | 8 | 143 | 45 |
| bowl | 59 | 0 | 78 | 39 |
| tv | - | - | 51 | 0 |
| cup | - | - | 69 | 20 |
| car | 74 | 13 | - | - |
| handbag | 61 | 0 | - | - |
| potted plant | 20 | 0 | - | - |
| Count | 1212 | 187 | 993 | 143 |
| Accuracy | 0.866 | 0.874 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thirukokaranam Chandrasekar, K.K.; Verstockt, S. Context-Based Structure Mining Methodology for Static Object Re-Identification in Broadcast Content. Appl. Sci. 2021, 11, 7266. https://doi.org/10.3390/app11167266
Thirukokaranam Chandrasekar KK, Verstockt S. Context-Based Structure Mining Methodology for Static Object Re-Identification in Broadcast Content. Applied Sciences. 2021; 11(16):7266. https://doi.org/10.3390/app11167266
Chicago/Turabian StyleThirukokaranam Chandrasekar, Krishna Kumar, and Steven Verstockt. 2021. "Context-Based Structure Mining Methodology for Static Object Re-Identification in Broadcast Content" Applied Sciences 11, no. 16: 7266. https://doi.org/10.3390/app11167266
APA StyleThirukokaranam Chandrasekar, K. K., & Verstockt, S. (2021). Context-Based Structure Mining Methodology for Static Object Re-Identification in Broadcast Content. Applied Sciences, 11(16), 7266. https://doi.org/10.3390/app11167266