
Multi-Destination Path Planning Method Research of Mobile Robots Based on Goal of Passing through the Fewest Obstacles


Abstract
:1. Introduction
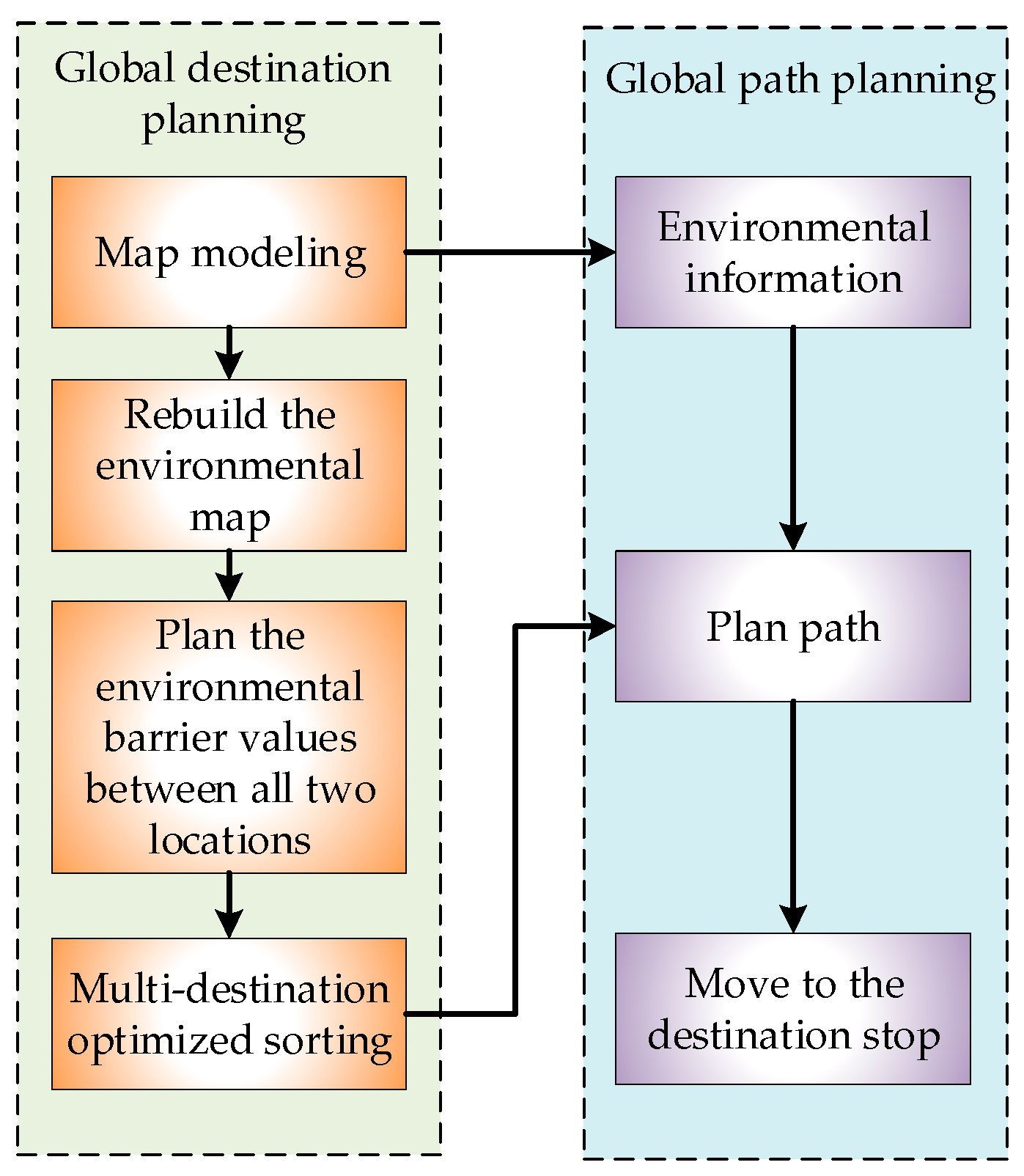
2. Global Destination Arrival Sequence Planning
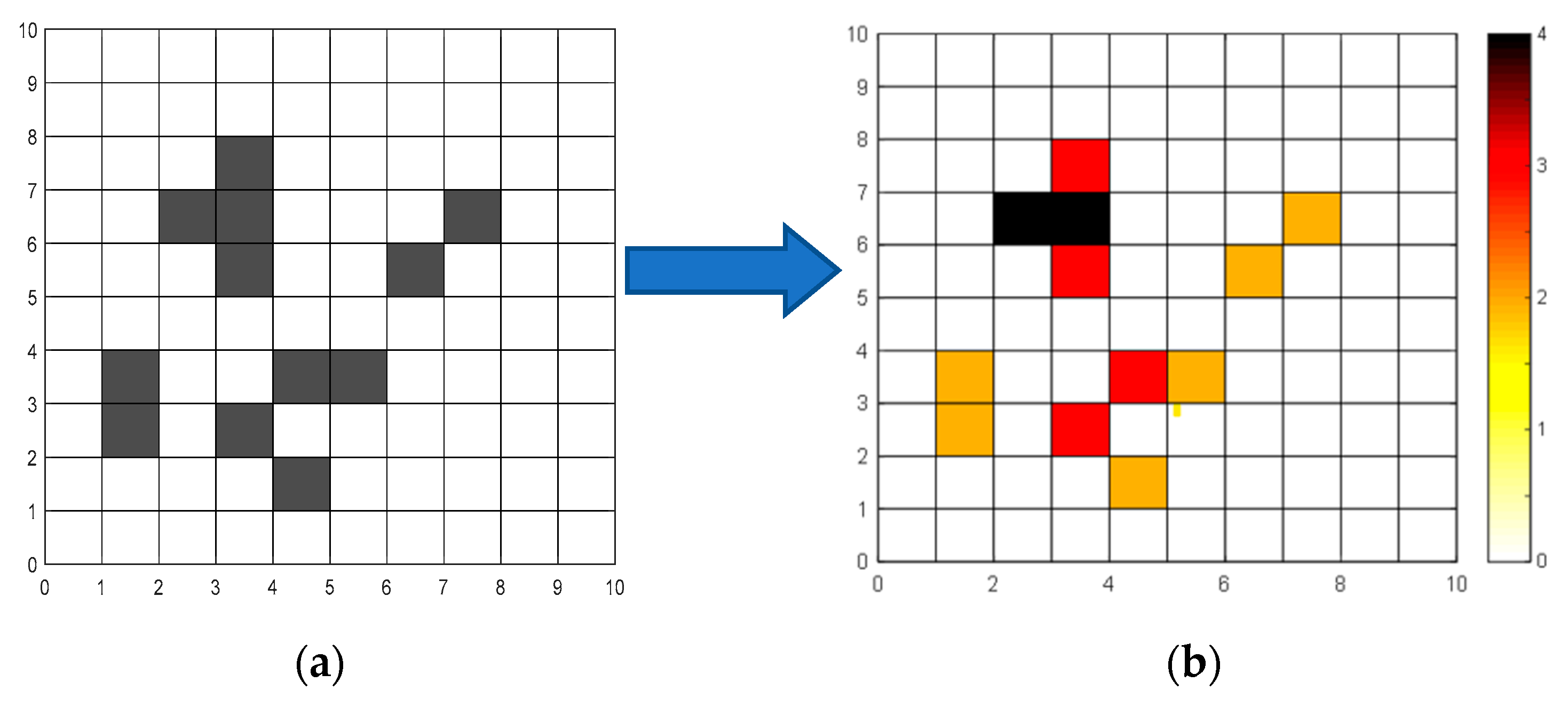
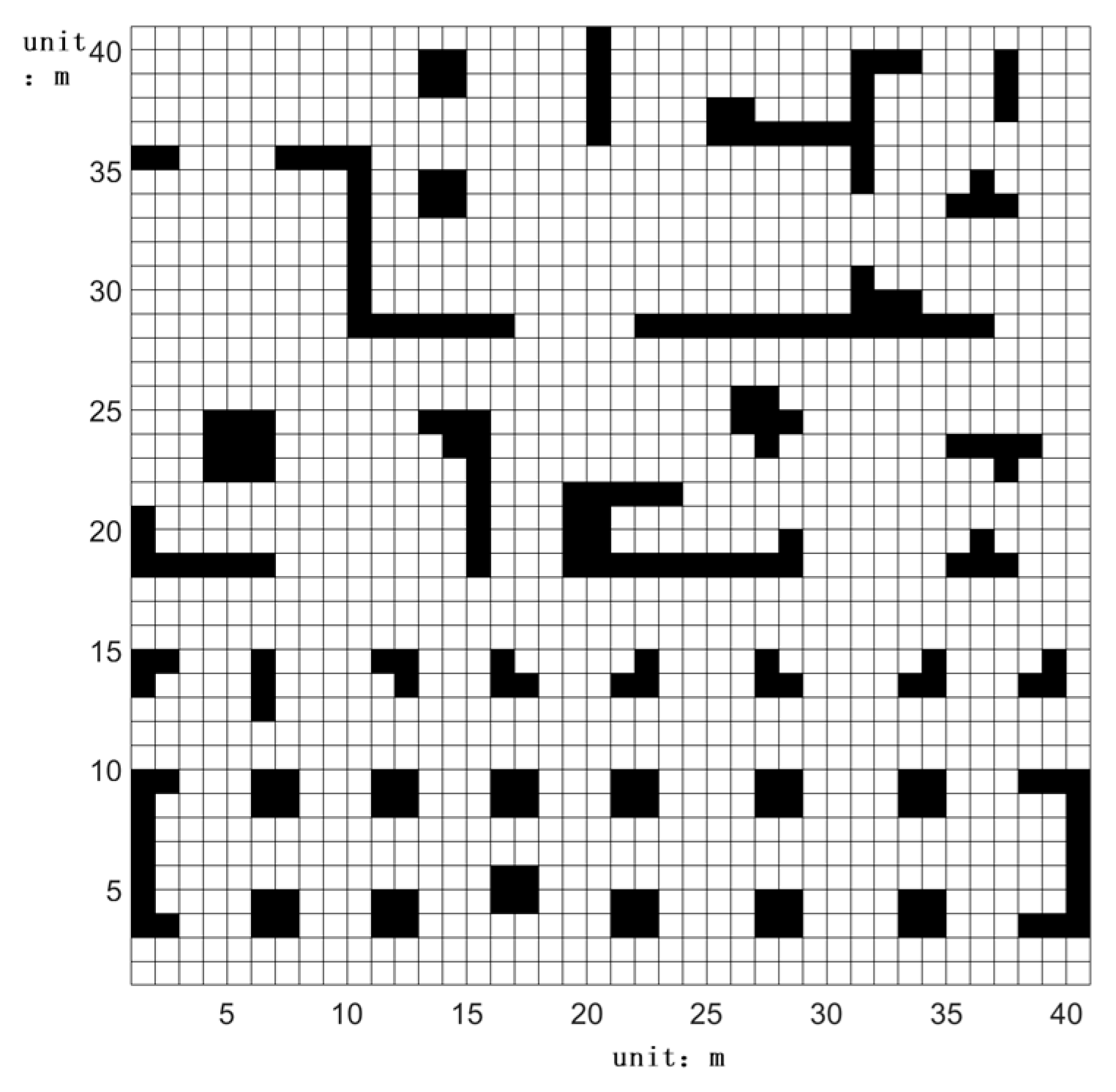
2.1. Grid Map Optimization Based on the Rules of the Chess Lively Game of Go
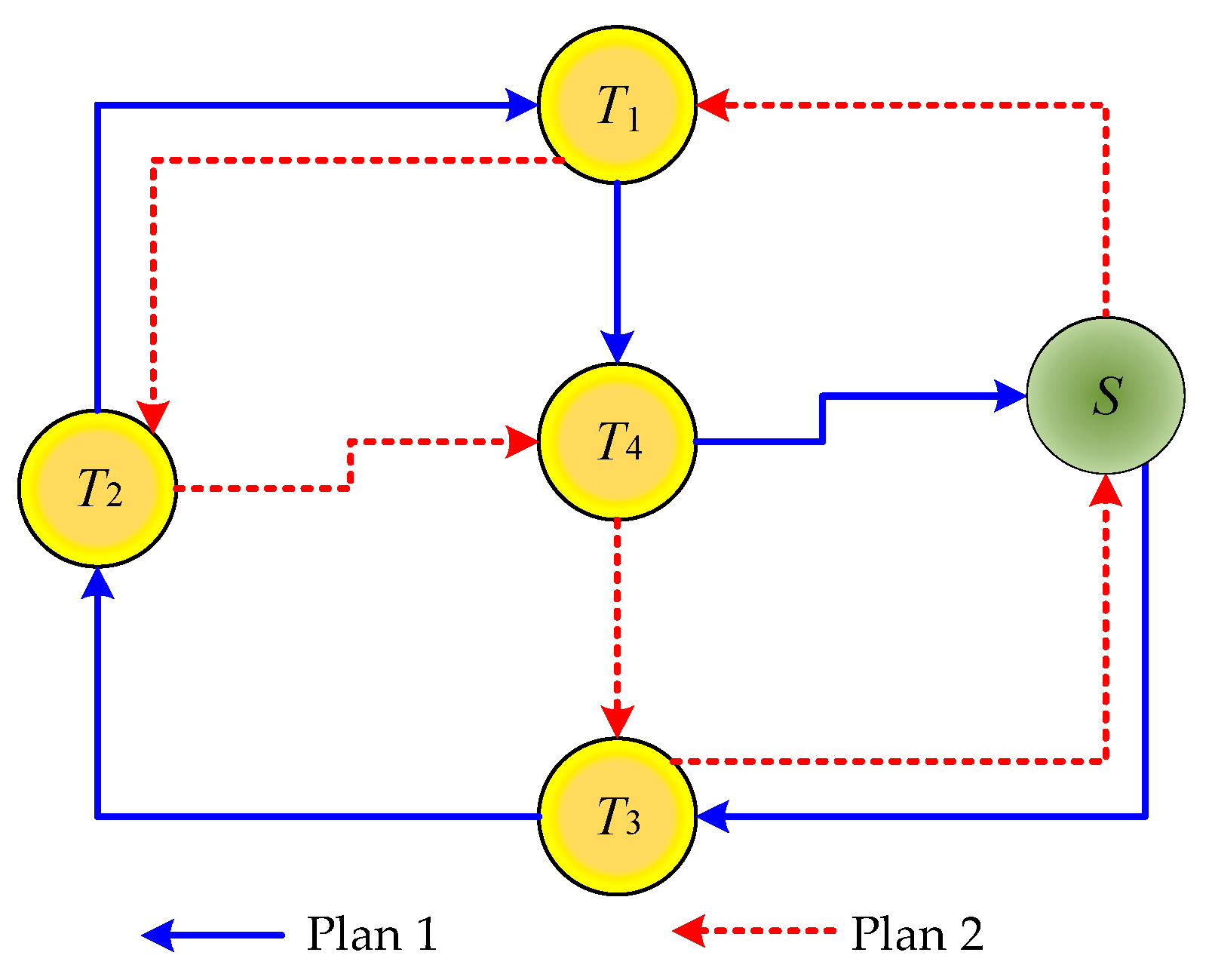
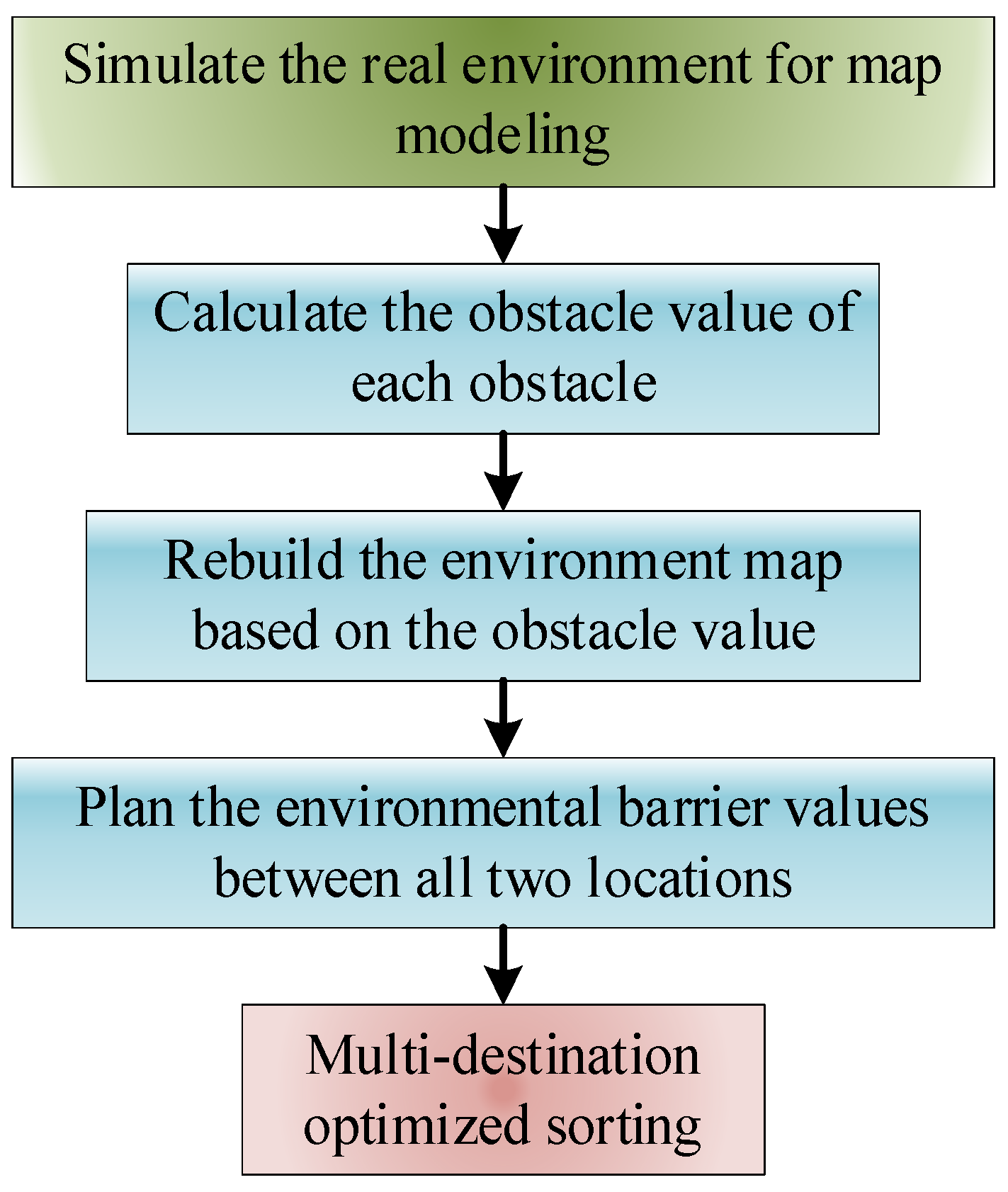
2.2. Multi-Destination Ranking Method Based on Environmental Obstacle Value
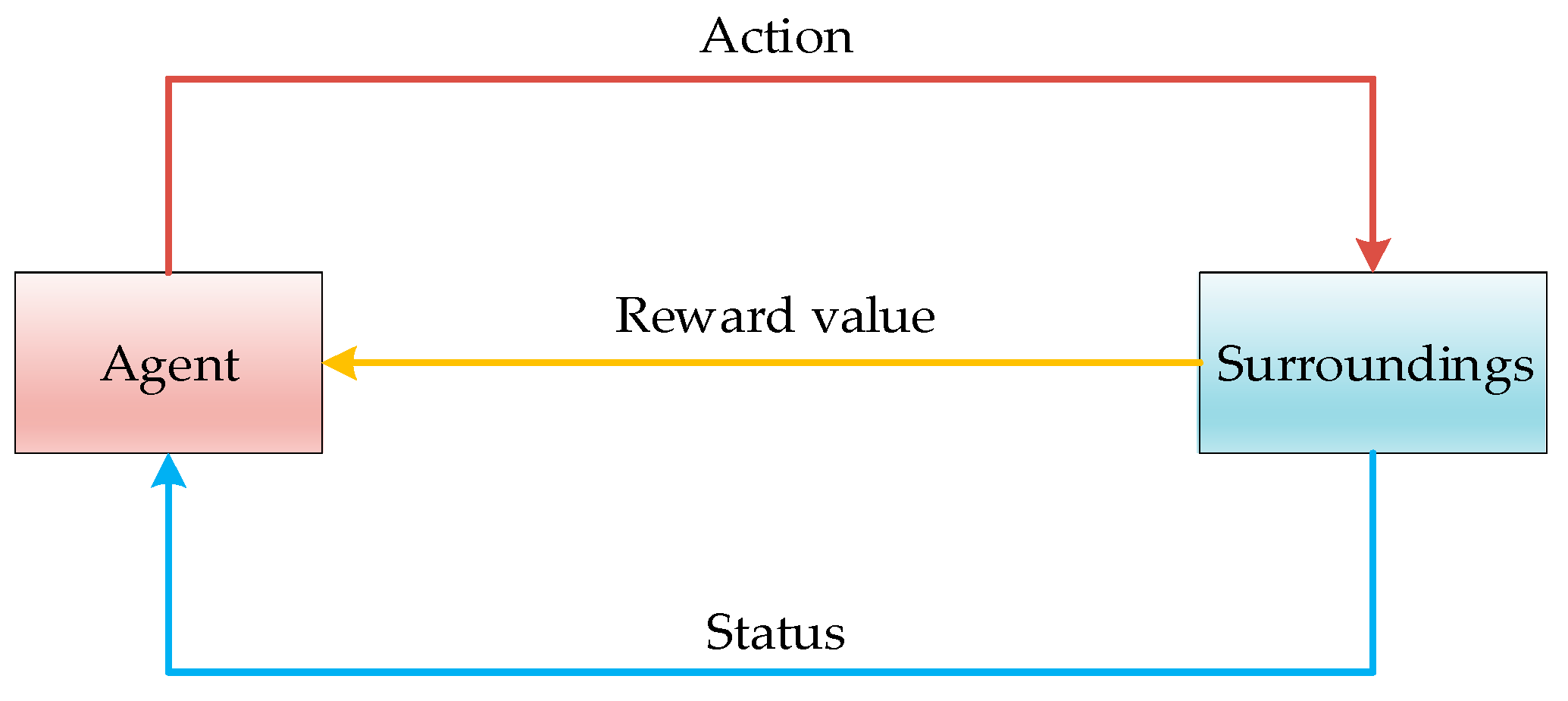
3. Multiple Destination Global Path Planning Strategy Based on Improved Q-Learning Algorithm
3.1. Q-Learning Algorithm Optimization
3.2. Path Planning Based on Improved Q-Learning Algorithm
4. Multiple Destination Path Planning Simulation
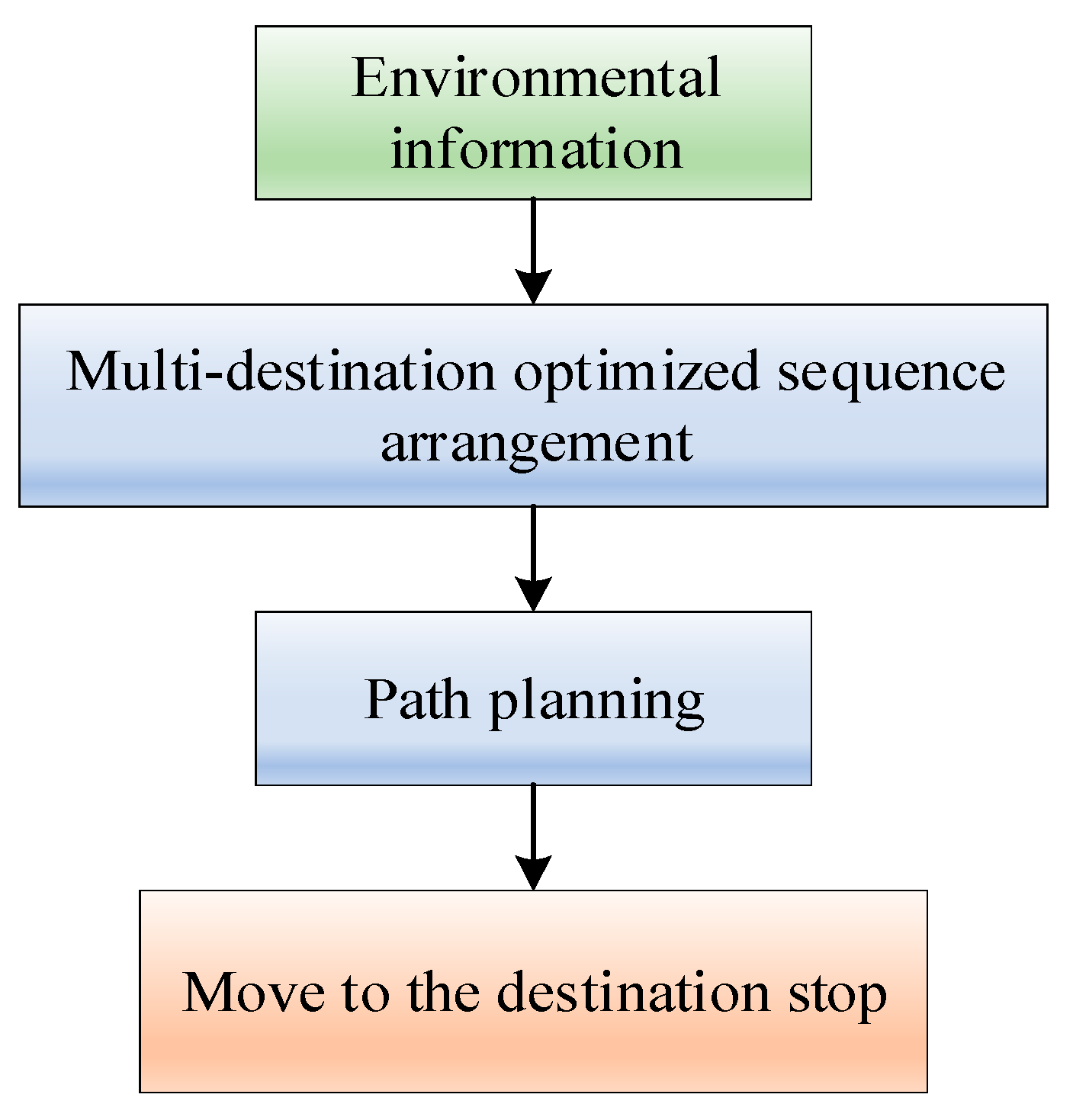
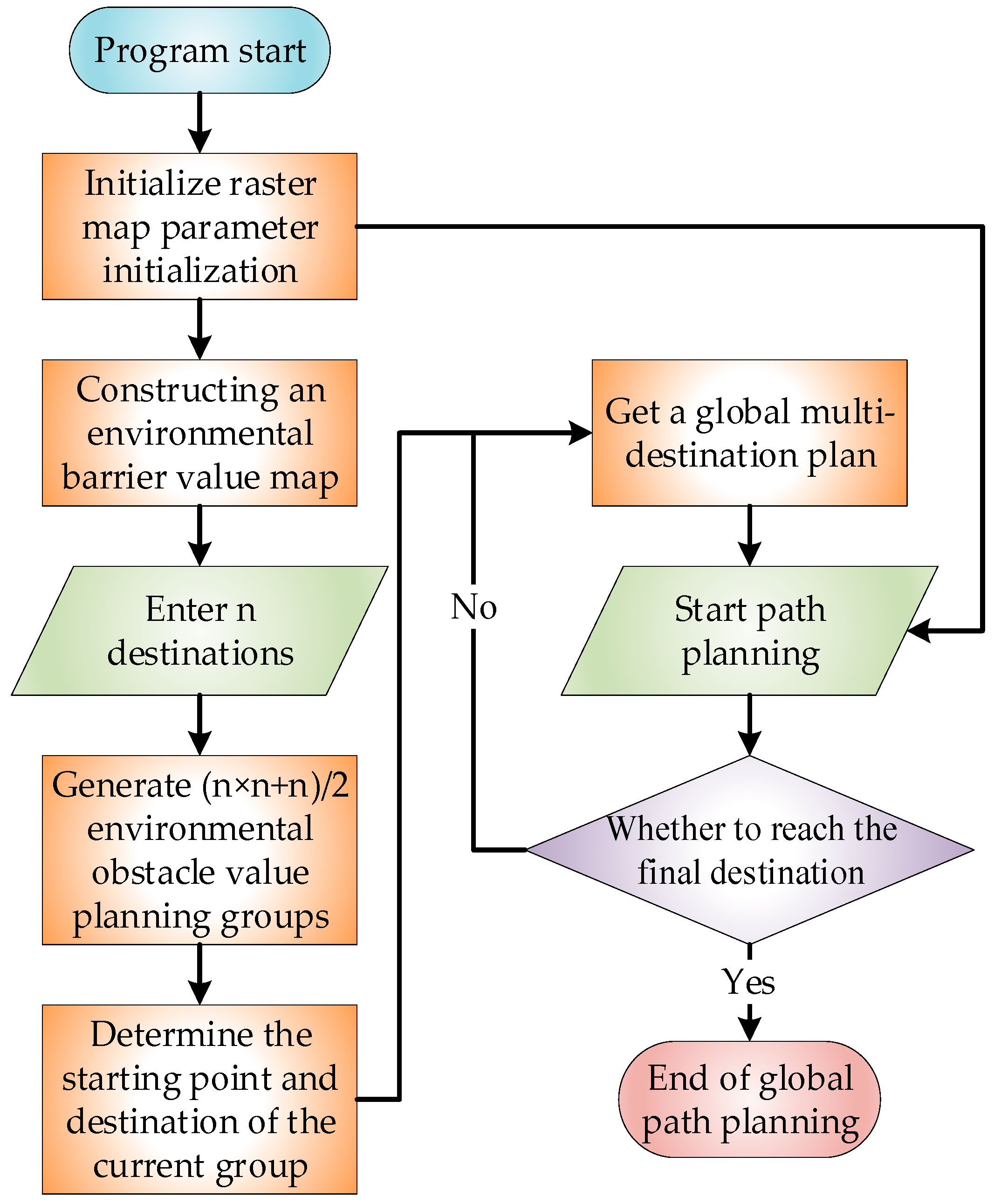
4.1. Multi-Destination Path Planning Algorithm Simulation Steps
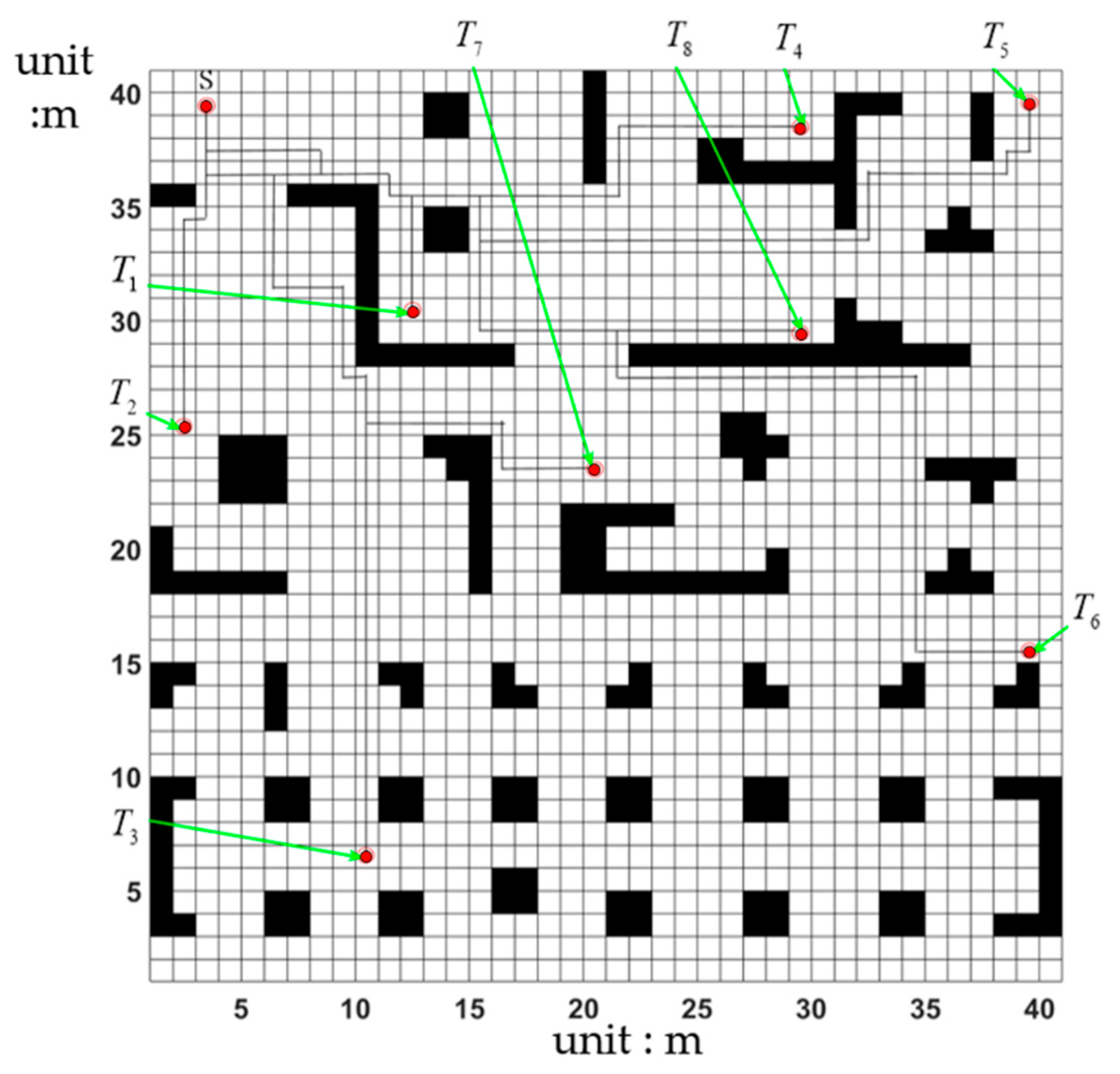
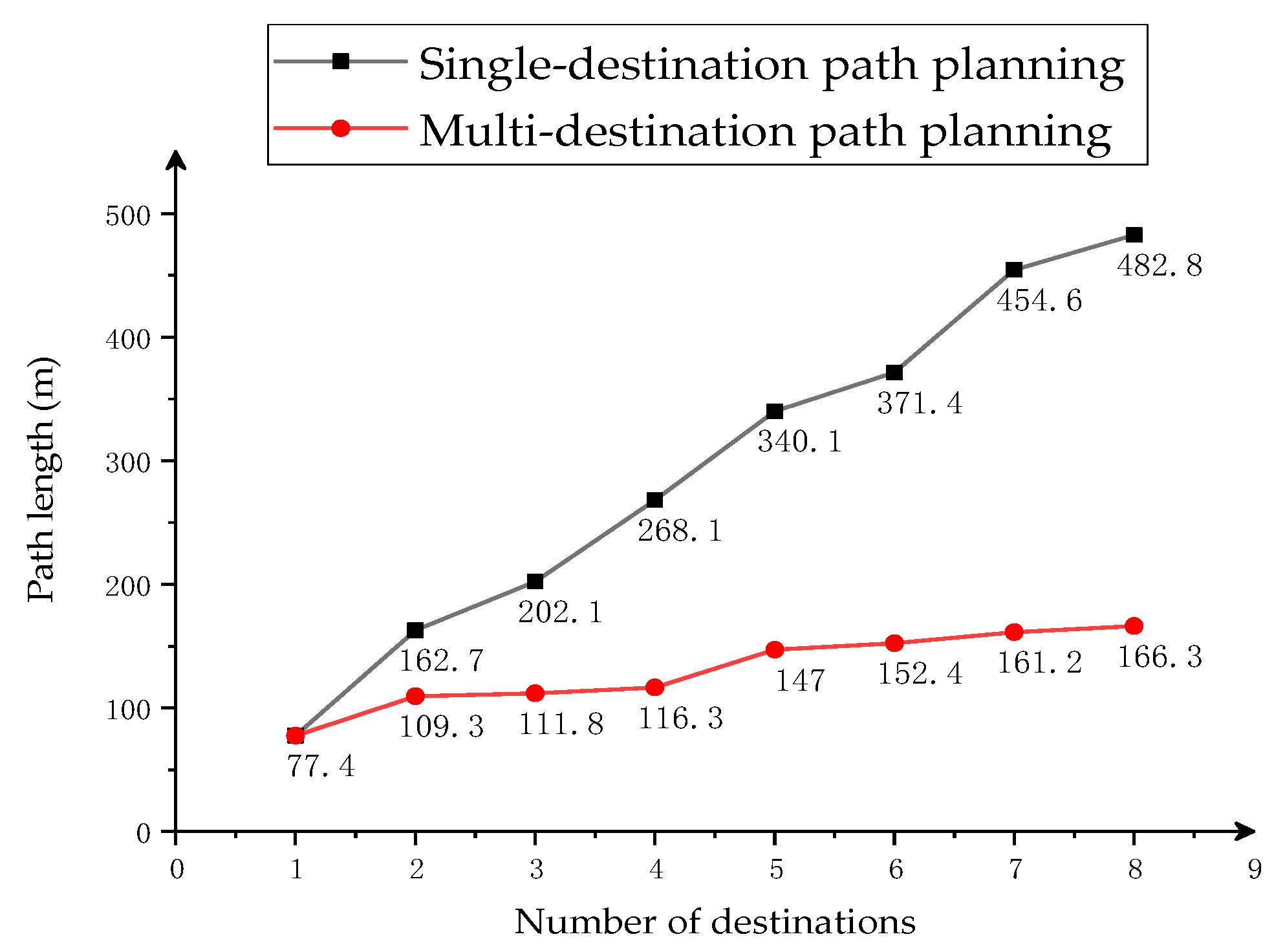
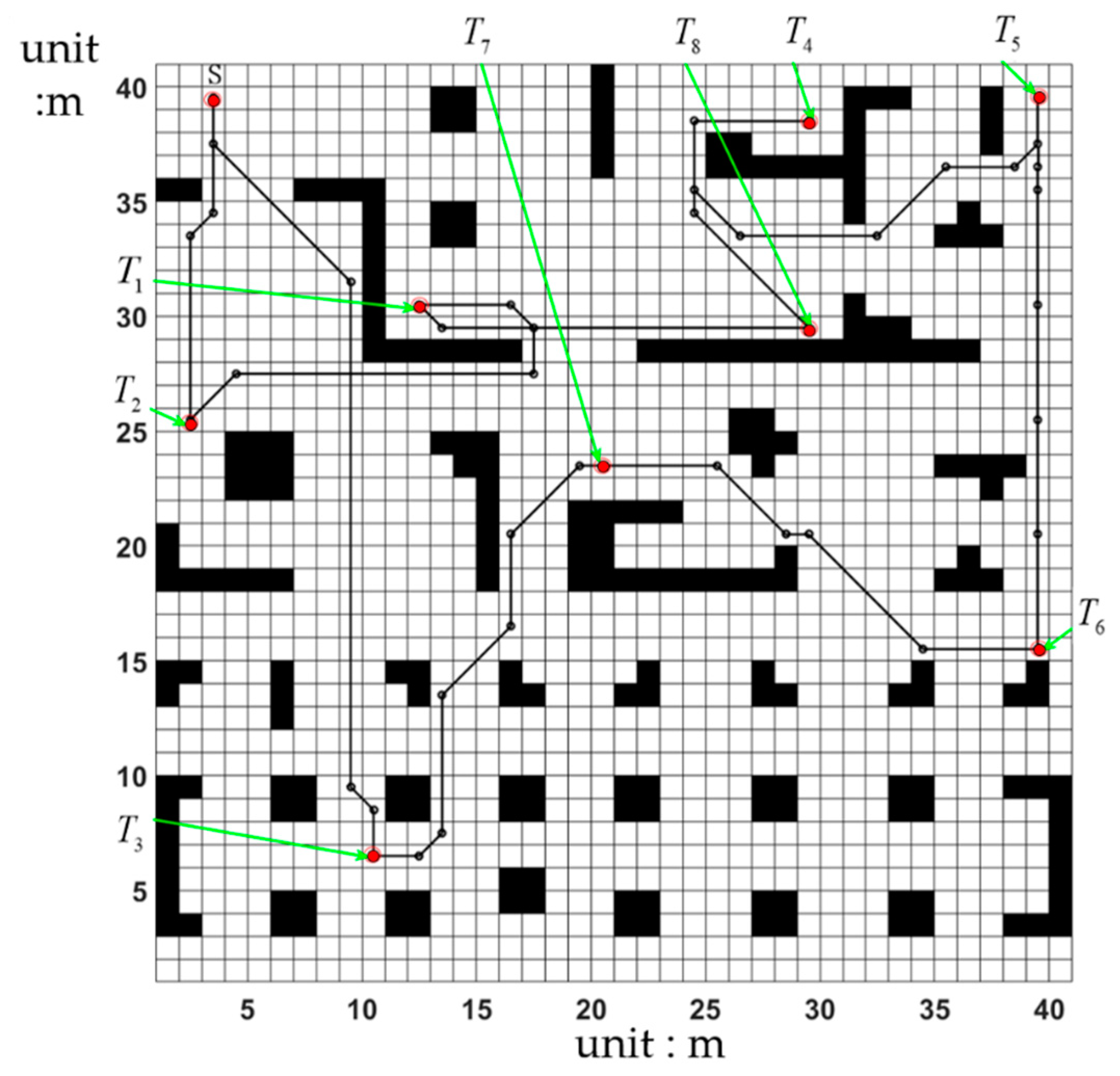
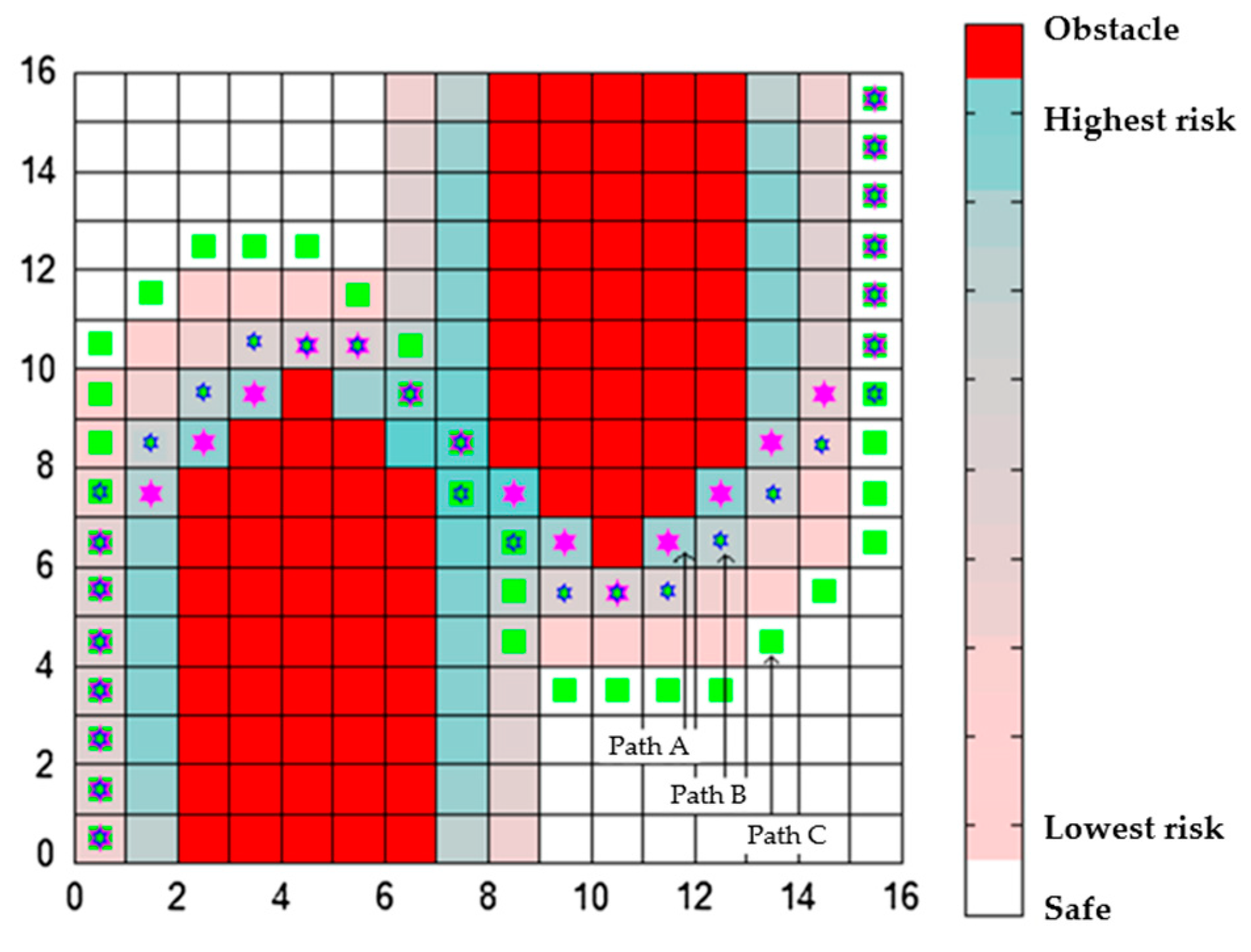
4.2. Multi-Destination Simulation Experiment
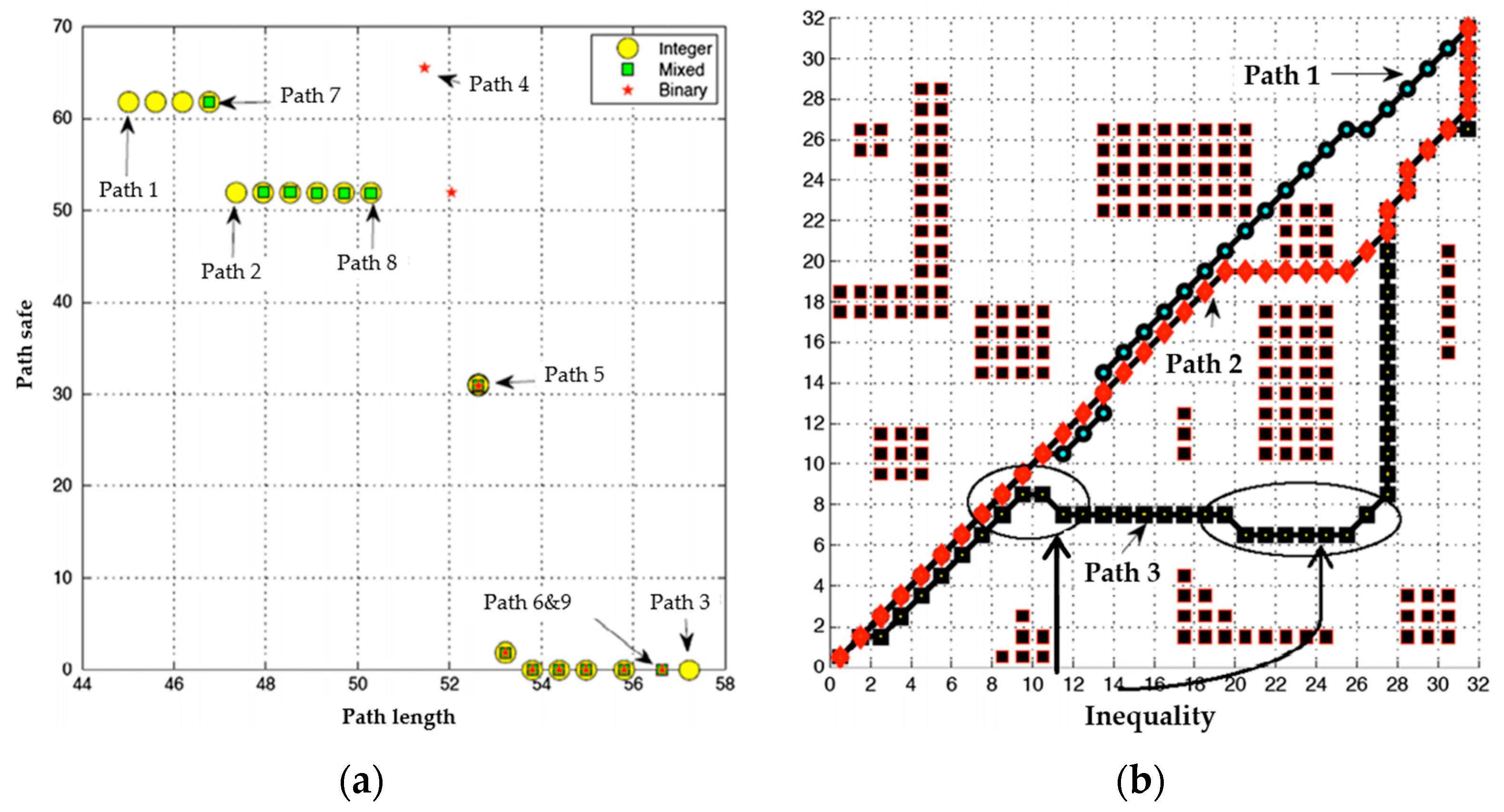
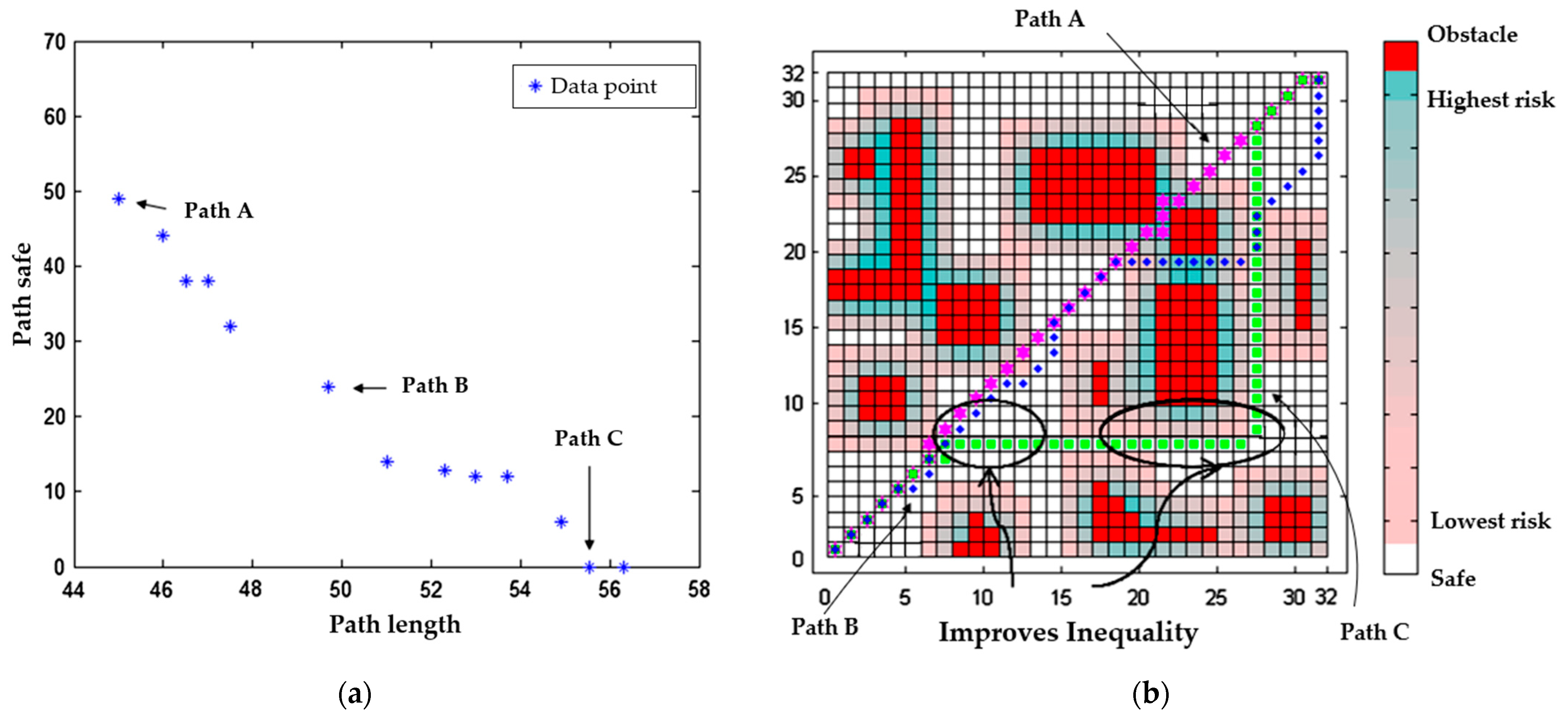
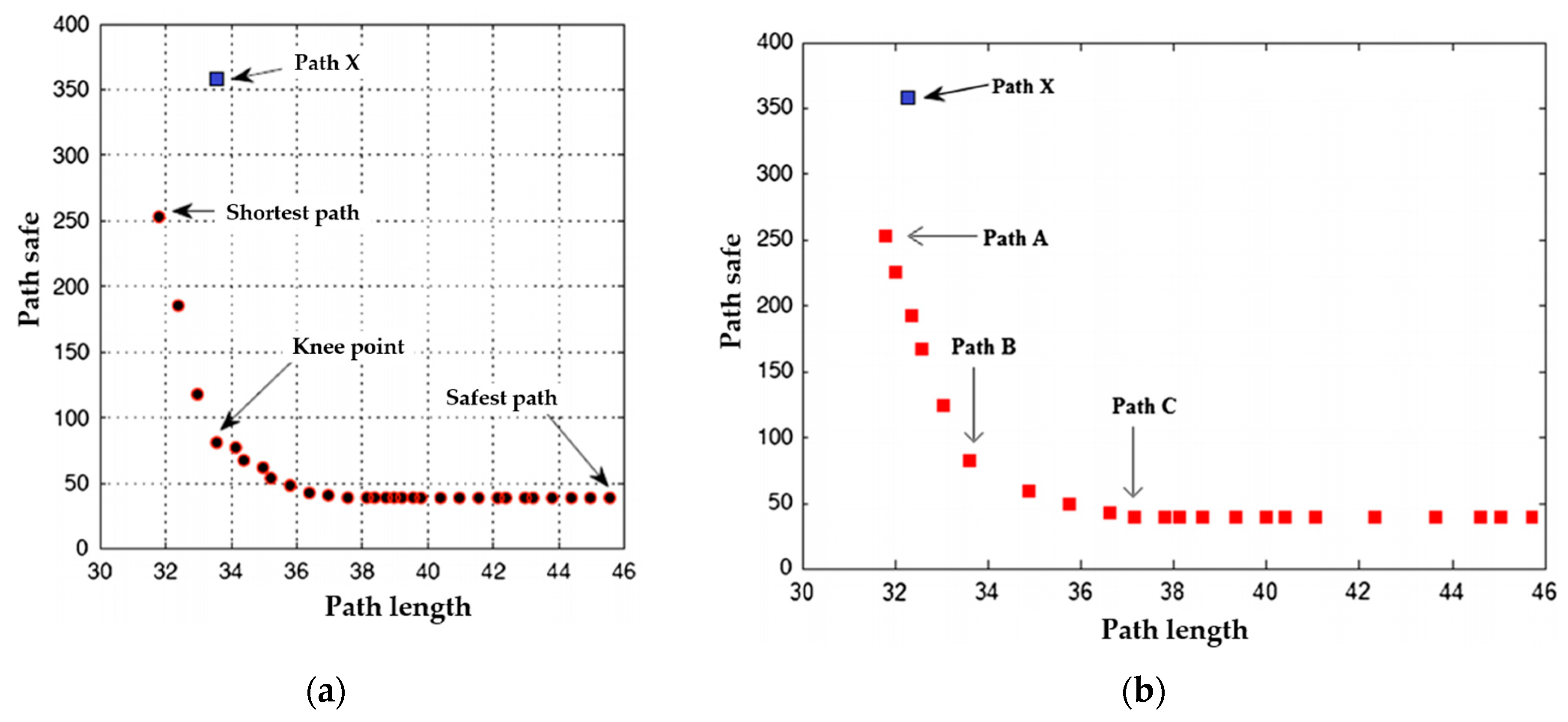
4.3. Comparison of MD-Q-Learning (Multi-Destination-Q-Learning) Based on the Fewest Obstacles and NSGA_II
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tao, Y.; Gao, H.; Ren, F.; Chen, C.; Wang, T.; Xiong, H.; Jiang, S. A Mobile Service Robot Global Path Planning Method Based on Ant Colony Optimization and Fuzzy Control. Appl. Sci. 2021, 11, 3605. [Google Scholar] [CrossRef]
- Hakeem, A.; Gehani, N.; Ding, X.; Curtmola, R.; Borcea, C. Multi-destination vehicular route planning with parking and traffic constraints. In Proceedings of the 16th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, Houston, TX, USA, 12–14 November 2019; pp. 298–307. [Google Scholar]
- Wang, S.F.; Zhang, J.X.; Zhang, J.Y. Artificial potential field algorithm for path control of unmanned ground vehicles formation in highway. Electron. Lett. 2018, 54, 1166–1167. [Google Scholar] [CrossRef]
- Tian, W.J.; Zhou, H.; Gao, M.J. A path planning algorithm for mobile robot based on combined fuzzy and Artificial Potential Field. In Advanced Computer Technology, New Education, Proceedings; Xiamen Univ. Press: Wuhan, China, 2007; pp. 55–58. [Google Scholar]
- Sun, Y.; Zhang, R.B. Research on Global Path Planning for AUV Based on GA. Mech. Eng. Technol. 2012, 125, 311–318. [Google Scholar]
- Ahmed, N.; Pawase, C.J.; Chang, K. Distributed 3-D Path Planning for Multi-UAVs with Full Area Surveillance Based on Particle Swarm Optimization. Appl. Sci. 2021, 11, 3417. [Google Scholar] [CrossRef]
- Ajeil, F.H.; Ibraheem, I.K.; Azar, A.T.; Humaidi, A.J. Grid-Based Mobile Robot Path Planning Using Aging-Based Ant Colony Optimization Algorithm in Static and Dynamic Environments. Sensors 2020, 20, 1880. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hu, W.-C.; Wu, H.-T.; Cho, H.-H.; Tseng, F.-H. Optimal Route Planning System for Logistics Vehicles Based on Artificial Intelligence. J. Internet Technol. 2020, 21, 757–764. [Google Scholar]
- Pae, D.-S.; Kim, G.-H.; Kang, T.-K.; Lim, M.-T. Path Planning Based on Obstacle-Dependent Gaussian Model Predictive Control for Autonomous Driving. Appl. Sci. 2021, 11, 3703. [Google Scholar] [CrossRef]
- Curiac, D.I.; Banias, O.; Volosencu, C.; Curiac, C.D. Novel Bioinspired Approach Based on Chaotic Dynamics for Robot Patrolling Missions with Adversaries. Entropy 2018, 20, 378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Curiac, D.-I.; Volosencu, C. Imparting protean behavior to mobile robots accomplishing patrolling tasks in the presence of adversaries. Bioinspiration Biomim. 2015, 056017. [Google Scholar] [CrossRef] [PubMed]
- Curiac, D.I.; Volosencu, C. Path Planning Algorithm based on Arnold Cat Map for Surveillance UAVs. Def. Sci. J. 2015, 65, 483–488. [Google Scholar] [CrossRef] [Green Version]
- Asaduzzaman, M.; Geok, T.K.; Hossain, F.; Sayeed, S. An Efficient Shortest Path Algorithm: Multi-Destinations in an Indoor Environment. Symmetry 2021, 13, 421. [Google Scholar] [CrossRef]
- Sangeetha, V.; Krishankumar, R.; Ravichandran, K.S.; Cavallaro, F. A Fuzzy Gain-Based Dynamic Ant Colony Optimization for Path Planning in Dynamic Environments. Symmetry 2021, 13, 280. [Google Scholar] [CrossRef]
- Yan, Z.; Li, J.; Wu, Y.; Zhang, G. A Real-Time Path Planning Algorithm for AUV in Unknown Underwater Environment Based on Combining PSO and Waypoint Guidance. Sensors 2019, 19, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, M.; Hua, G.; Huang, H. A Multi-Modal Route Choice Model with Ridesharing and Public Transit. Sustainability 2018, 10, 4275. [Google Scholar] [CrossRef] [Green Version]
- Zhu, D.; Qu, Y.; Yang, S.X. Multi-AUV SOM task allocation algorithm considering initial orientation and ocean current environment. Front. Inf. Technol. Electron. Eng. 2019, 20, 330–341. [Google Scholar] [CrossRef]
- Abideen, Z.U.; Sun, H.; Yang, Z.; Ahmad, R.Z.; Iftekhar, A.; Ali, A. Deep Wide Spatial-Temporal Based Transformer Networks Modeling for the Next Destination According to the Taxi Driver Behavior Prediction. Appl. Sci. 2021, 11, 17. [Google Scholar] [CrossRef]
- Ganeshan, K.; Panneerselvam, A.; Nandhagopal, N. Robust Hybrid Artificial Fish Swarm Simulated Annealing Optimization Algorithm for Secured Free Scale Networks against Malicious Attacks. Comput. Mater. Contin. 2021, 66, 903–917. [Google Scholar]
- Yanes Luis, S.; Gutiérrez-Reina, D.; Toral Marín, S. A Dimensional Comparison between Evolutionary Algorithm and Deep Reinforcement Learning Methodologies for Autonomous Surface Vehicles with Water Quality Sensors. Sensors 2021, 21, 2862. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | NSGA_II | CSD Based MD-Q-Learning |
|---|---|---|
| Size of population | 500 | 50 |
| Number of iterations | 800 | 100 |
| Number of heuristic operations | pc = 0.9 and pm = 0.032 | NLocalSearch = between 10 and 60 |
| Fitness values of safest path/(length, safety) | 53.75, 0 | 55.54, 0 |
| Fitness values of shortest paths | 45, 61.25 | 45, 49.12 |
| Number of fitness function calls | 772,800 | 218,893 |
| Coefficient of variation in safety objective | 2.47 | 1.41 |
| Coefficient of variation in length objective | 2.71 | 0.437 |
| Run time of algorithm (s) | 2.99 | 3.04 |
| Algorithm | NSGA_II | CSD Based MD-Q-Learning |
|---|---|---|
| Size of population | 50 | 50 |
| Number of iterations | 100 | 100 |
| Number of heuristic operations | pc = 0.9 and pm = 0.032 and NLocalSearch = 30 | NLocalSearch = between 10 and 60 |
| Fitness values of safest path/(length, safety) | 53.75, 0 | 55.54, 0 |
| Fitness values of shortest paths | 45, 61.25 | 45, 49.12 |
| Number of fitness function calls | 275,645 | 218,893 |
| Coefficient of variation in safety objective | 2.03 | 1.41 |
| Coefficient of variation in length objective | 1.92 | 0.437 |
| Run time of algorithm (s) | 3.21 | 3.04 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, H.; Dong, K.; Qi, Y.; Wang, N.; Dong, L. Multi-Destination Path Planning Method Research of Mobile Robots Based on Goal of Passing through the Fewest Obstacles. Appl. Sci. 2021, 11, 7378. https://doi.org/10.3390/app11167378
Zhuang H, Dong K, Qi Y, Wang N, Dong L. Multi-Destination Path Planning Method Research of Mobile Robots Based on Goal of Passing through the Fewest Obstacles. Applied Sciences. 2021; 11(16):7378. https://doi.org/10.3390/app11167378
Chicago/Turabian StyleZhuang, Hongchao, Kailun Dong, Yuming Qi, Ning Wang, and Lei Dong. 2021. "Multi-Destination Path Planning Method Research of Mobile Robots Based on Goal of Passing through the Fewest Obstacles" Applied Sciences 11, no. 16: 7378. https://doi.org/10.3390/app11167378
APA StyleZhuang, H., Dong, K., Qi, Y., Wang, N., & Dong, L. (2021). Multi-Destination Path Planning Method Research of Mobile Robots Based on Goal of Passing through the Fewest Obstacles. Applied Sciences, 11(16), 7378. https://doi.org/10.3390/app11167378