
Outlier Recognition via Linguistic Aggregation of Graph Databases


Abstract
:1. Introduction
2. Fuzzy Sets and Linguistic Quantification of Statements
3. Detecting and Recognizing Outliers with Linguistic Information
3.1. Outliers in Terms of Linguistically Aggregated Information
- , , …, , —a non-empty finite dataset,
- —linguistic labels for properties of d’s in , represented by fuzzy sets,
- , —relative regular monotonically non-increasing linguistic quantifiers, as in Definition 1, given as fuzzy sets in ,
- Two possible results are produced: = ”THERE EXIST OUTLIERS IN ”, = ”NO OUTLIERS IN ”.
| Algorithm 1 Detecting outliers via the first form of linguistically quantified statement. |
|
| Algorithm 2 Detecting outliers via the second form of linguistically quantified statement. |
|
3.2. Recognizing Outliers via Linguistic Information
| Algorithm 3 Recognizing outliers detected with Algorithm 1. |
|
| Algorithm 4 Recognizing outliers detected with Algorithm 2. |
|
4. Preprocessing Graph Databases to Use Linguistically Aggregated Information
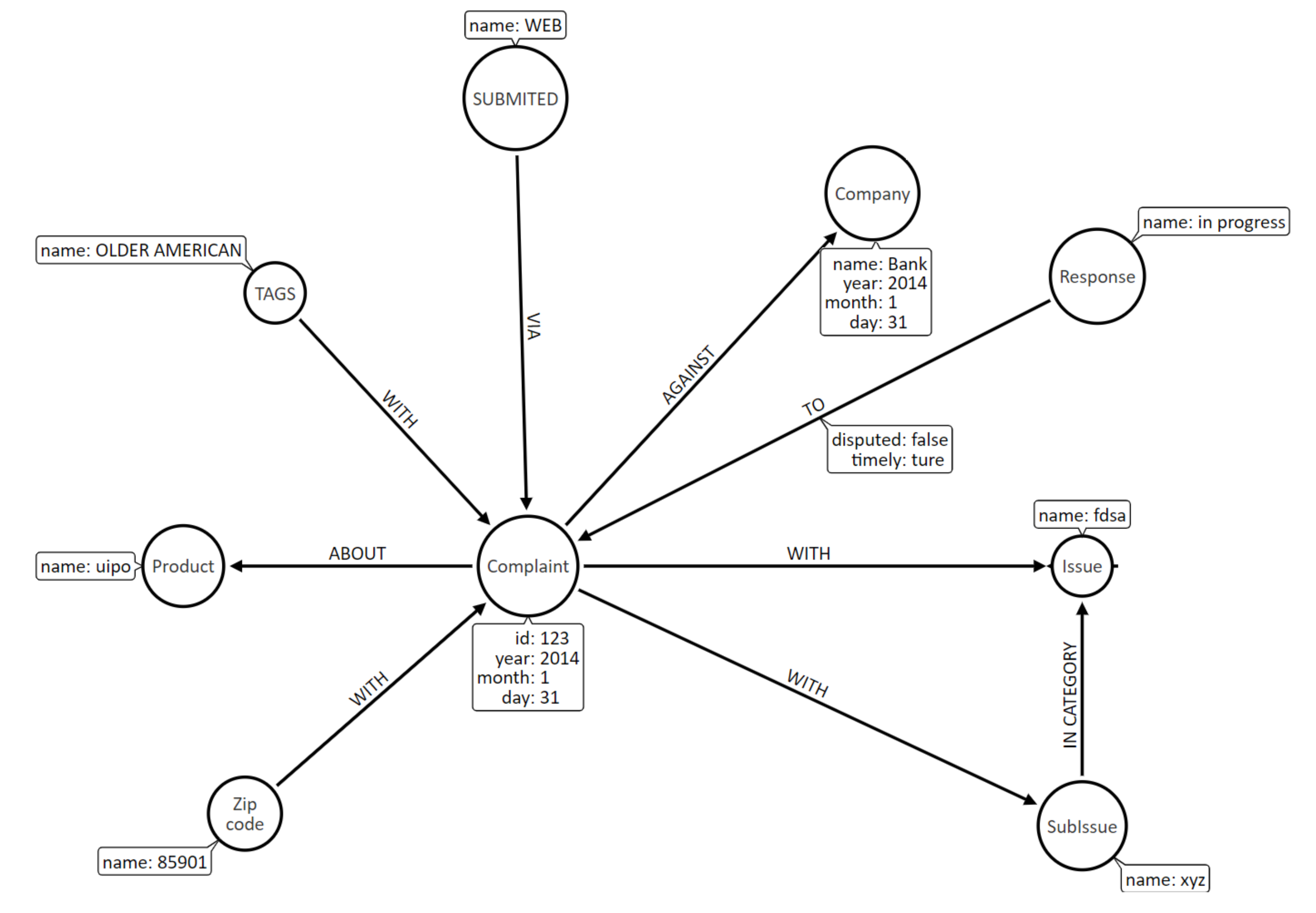
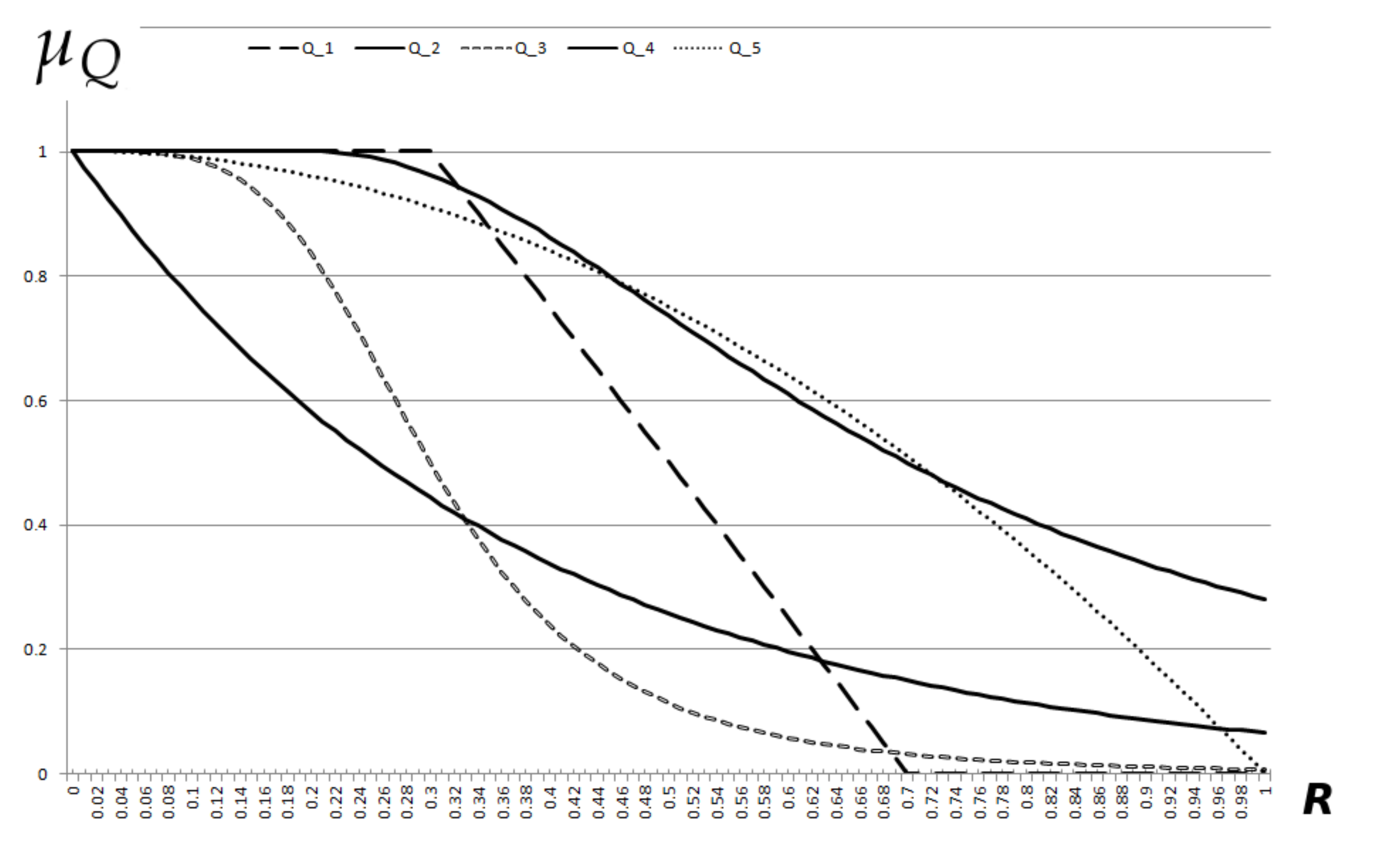
5. Application Example
A Comparison to the LOF Algorithm
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
References
- Hawkins, D.M. Identification of Outliers; Springer: Cham, Switzerland, 1980; Volume 11. [Google Scholar]
- Aggarwal, C.C.; Yu, P.S. Outlier detection for high dimensional data. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Santa Barbara, CA, USA, 21–24 May 2001; Volume 30, pp. 37–46. [Google Scholar]
- Knorr, E.M.; Ng, R.T.; Tucakov, V. Distance-based outliers: Algorithms and applications. VLDB J. 2000, 8, 237–253. [Google Scholar] [CrossRef]
- Knox, E.M.; Ng, R.T. Algorithms for mining distancebased outliers in large datasets. In Proceedings of the International Conference on Very Large Data Bases, New York, NY, USA, 24–27 August 1998; pp. 392–403. [Google Scholar]
- Aggarwal, C.C. Outlier Analysis; Springer: New York, NY, USA, 2013. [Google Scholar]
- Barnett, V.; Lewis, T. Outliers in Statistical Data; Wiley: New York, NY, USA, 1994; Volume 3. [Google Scholar]
- Knorr, E.M.; Ng, R.T. A Unified Notion of Outliers: Properties and Computation. In Proceedings of the KDD’97: Proceedings of the Third International Conference on Knowledge Discovery and Data Mining; Newport Beach, CA, USA, 14–17 August 1997, pp. 219–222.
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; Volume 29, pp. 93–104. [Google Scholar]
- Kriegel, H.P.; Kröger, P.; Schubert, E.; Zimek, A. LoOP: Local outlier probabilities. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 1649–1652. [Google Scholar]
- Ramaswamy, S.; Rastogi, R.; Shim, K. Efficient algorithms for mining outliers from large data sets. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; Volume 29, pp. 427–438. [Google Scholar]
- Jiang, F.; Liu, G.; Du, J.; Sui, Y. Initialization of K-modes clustering using outlier detection techniques. Inf. Sci. 2016, 332, 167–183. [Google Scholar] [CrossRef]
- Flanagan, K.; Fallon, E.; Connolly, P.; Awad, A. Network anomaly detection in time series using distance based outlier detection with cluster density analysis. In Proceedings of the 2017 Internet Technologies and Applications (ITA), Wrexham, UK, 12–15 September 2017; pp. 116–121. [Google Scholar]
- Tran, L.; Fan, L.; Shahabi, C. Distance-based outlier detection in data streams. VLDB Endow. 2016, 9, 1089–1100. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. Outlier Detection in Categorical, Text, and Mixed Attribute Data. In Outlier Analysis; Springer: New York, NY, USA, 2017; pp. 249–272. [Google Scholar]
- Hodge, V.J.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef] [Green Version]
- Duraj, A. Outlier detection in medical data using linguistic summaries. In Proceedings of the 2017 IEEE International Conference on Innovations in Intelligent SysTems and Applications (INISTA), Gdynia, Poland, 3–5 July 2017; pp. 385–390. [Google Scholar]
- Duraj, A.; Niewiadomski, A.; Szczepaniak, P.S. Outlier detection using linguistically quantified statements. Int. J. Intell. Syst. 2018, 33, 1858–1868. [Google Scholar] [CrossRef]
- Duraj, A.; Niewiadomski, A.; Szczepaniak, P.S. Detection of outlier information by the use of linguistic summaries based on classic and interval-valued fuzzy sets. Int. J. Intell. Syst. 2019, 34, 415–438. [Google Scholar] [CrossRef]
- Niewiadomski, A.; Duraj, A. Detecting and Recognizing Outliers in Datasets via Linguistic Information and Type-2 Fuzzy Logic. Int. J. Fuzzy Syst. 2020, 23, 878–889. [Google Scholar] [CrossRef]
- Consumer Complaint Database. Available online: https://catalog.data.gov/dataset/consumer-complaint-database (accessed on 30 June 2020).
- Zadeh, L.A. A computational approach to fuzzy quantifiers in natural languages. Comput. Maths Appl. 1983, 9, 149–184. [Google Scholar] [CrossRef] [Green Version]
- De Luca, A.; Termini, S. A definition of the non-probabilistic entropy in the setting of fuzzy sets theory. Inf. Control 1972, 20, 301–312. [Google Scholar] [CrossRef] [Green Version]
- Niewiadomski, A. Methods for the Linguistic Summarization of Data: Applications of Fuzzy Sets and Their Extensions; Academic Publishing House EXIT: Warsaw, Poland, 2008. [Google Scholar]
- Niewiadomski, A. A Type-2 Fuzzy Approach to Linguistic Summarization of Data. IEEE Trans. Fuzzy Syst. 2008, 16, 198–212. [Google Scholar] [CrossRef]
- Neo4j: Graph Database Platform | Graph Database. Available online: https://neo4j.com (accessed on 30 June 2021).
- Schubert, E.; Zimek, A.; Kriegel, H.P. Local outlier detection reconsidered: A generalized view on locality with applications to spatial, video, and network outlier detection. Data Min. Knowl. Discov. 2012, 28, 190–237. [Google Scholar] [CrossRef]
- Scikit-Learn: Machine Learning in Python. Available online: https://scikit-learn.org (accessed on 20 July 2021).
- Pandas—Python Data Analysis Library. Available online: https://pandas.pydata.org (accessed on 20 July 2021).
- Niewiadomski, A.; Superson, I. Multi-Subject Type-2 Linguistic Summaries of Relational Databases. In Frontiers of Higher Order Fuzzy Sets; Sadeghian, A., Tahayori, H., Eds.; Springer: New York, NY, USA, 2015; pp. 167–181. [Google Scholar]



{kind=link}
{kind=link}
| ID | Company | Date Received | Sent by CFPB | Per Capita Income | Product | Zipcode |
|---|---|---|---|---|---|---|
| 801691 | STONELEIGH RECOVERY ASSOCIATES, LLC | 11.04.2014 | 09.04.2014 | debt collection | 94930 | |
| 801371 | NATIONSTAR mortgage | 11.04.2014 | 09.04.2014 | mortgage | 94947 | |
| 305167 | WELLS FARGO & COMPANY | 07.02.2013 | 05.02.2013 | mortgage | 22206 | |
| 716577 | WELLS FARGO & COMPANY | 20.02.2014 | 15.02.2014 | mortgage | 22203 | |
| 809768 | BARCLAYS BANK DELAWARE | 15.04.2014 | 15.04.2014 | credit card | 87124 | |
| 941562 | COMERICA | 17.07.2014 | 17.07.2014 | bank account or service | 48653 | |
| 720703 | Vision Financial Corp. | 21.05.2012 | 21.05.2012 | debt collection | 75089 | |
| … | … | … | … | … | … | … |
| No. | Linguistically Quantified Statement | T | ||
|---|---|---|---|---|
| 1. | Almost no complaints submitted in early spring come from rich county | 0.75 | 0 | 0.33 |
| 2. | Almost no complaints submitted in middle spring come from rich county | 0.19 | 0 | 0.33 |
| 42. | Almost none complaints submitted in winter are sent by CFPB in short time | 0.58 | 0 | 0.33 |
| 60. | Very few complaints submitted in winter come from poor county | 0.63 | 0.3 | 0.5 |
| 97. | Close to 0 complaints submitted in summer come from rich county | 0.32 | 0 | 0.40 |
| 125. | Close to 0 complaints are submitted by Older American and Servicemember AND come from average county | 0.25 | 0 | 0.40 |
| … | … | … | … | … |
| 144. | Close to 0 complaints submitted in early winter are sent by CFPB in long time | 0.14 | 0 | 0.40 |
| 145. | Almost no complaints submitted in early spring come from rich county AND are sent by CFPB in an average time | 0.94 | 0 | 0.33 |
| 146. | Close to 0 complaints submitted in early spring come from rich county AND are sent by CFPB in an average time | 0.43 | 0 | 0.40 |
| 147. | Very few complaints submitted in winter come from rich county AND are sent by CFPB in an average time | 0.92 | 0.3 | 0.5 |
| No. | Neighbors | Leafsize | Metric | Contamination | Number of Outliers |
|---|---|---|---|---|---|
| 1. | 20 | 30 | Minkovsky | auto | 3206 |
| 2. | 50 | 30 | Minkovsky | auto | 2989 |
| 3. | 50 | 100 | Jaccard | auto | 0 |
| 4. | 20 | 30 | dice | auto | 0 |
| 5. | 20 | 30 | correlation | 0.0050 | 132 |
| 6. | 20 | 30 | correlation | 0.0012 | 33 |
| 7. | 20 | 30 | correlation | 0.0004 | 11 |
| 8. | 20 | 30 | correlation | 0.0002 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Niewiadomski, A.; Duraj, A.; Bartczak, M. Outlier Recognition via Linguistic Aggregation of Graph Databases. Appl. Sci. 2021, 11, 7434. https://doi.org/10.3390/app11167434
Niewiadomski A, Duraj A, Bartczak M. Outlier Recognition via Linguistic Aggregation of Graph Databases. Applied Sciences. 2021; 11(16):7434. https://doi.org/10.3390/app11167434
Chicago/Turabian StyleNiewiadomski, Adam, Agnieszka Duraj, and Monika Bartczak. 2021. "Outlier Recognition via Linguistic Aggregation of Graph Databases" Applied Sciences 11, no. 16: 7434. https://doi.org/10.3390/app11167434
APA StyleNiewiadomski, A., Duraj, A., & Bartczak, M. (2021). Outlier Recognition via Linguistic Aggregation of Graph Databases. Applied Sciences, 11(16), 7434. https://doi.org/10.3390/app11167434