
Using Data Augmentation and Time-Scale Modification to Improve ASR of Children’s Speech in Noisy Environments


Abstract
:1. Introduction
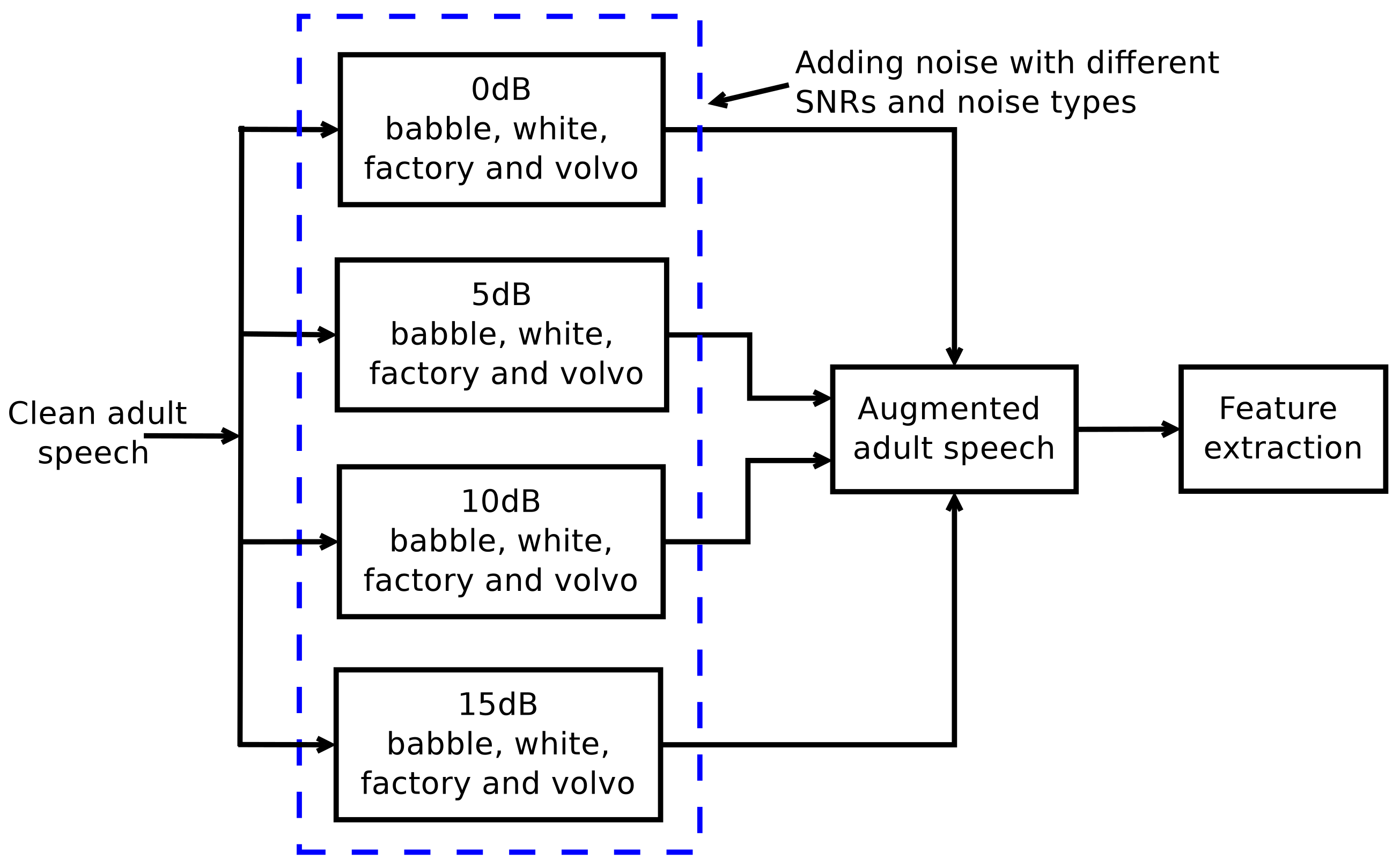
2. Data Augmentation
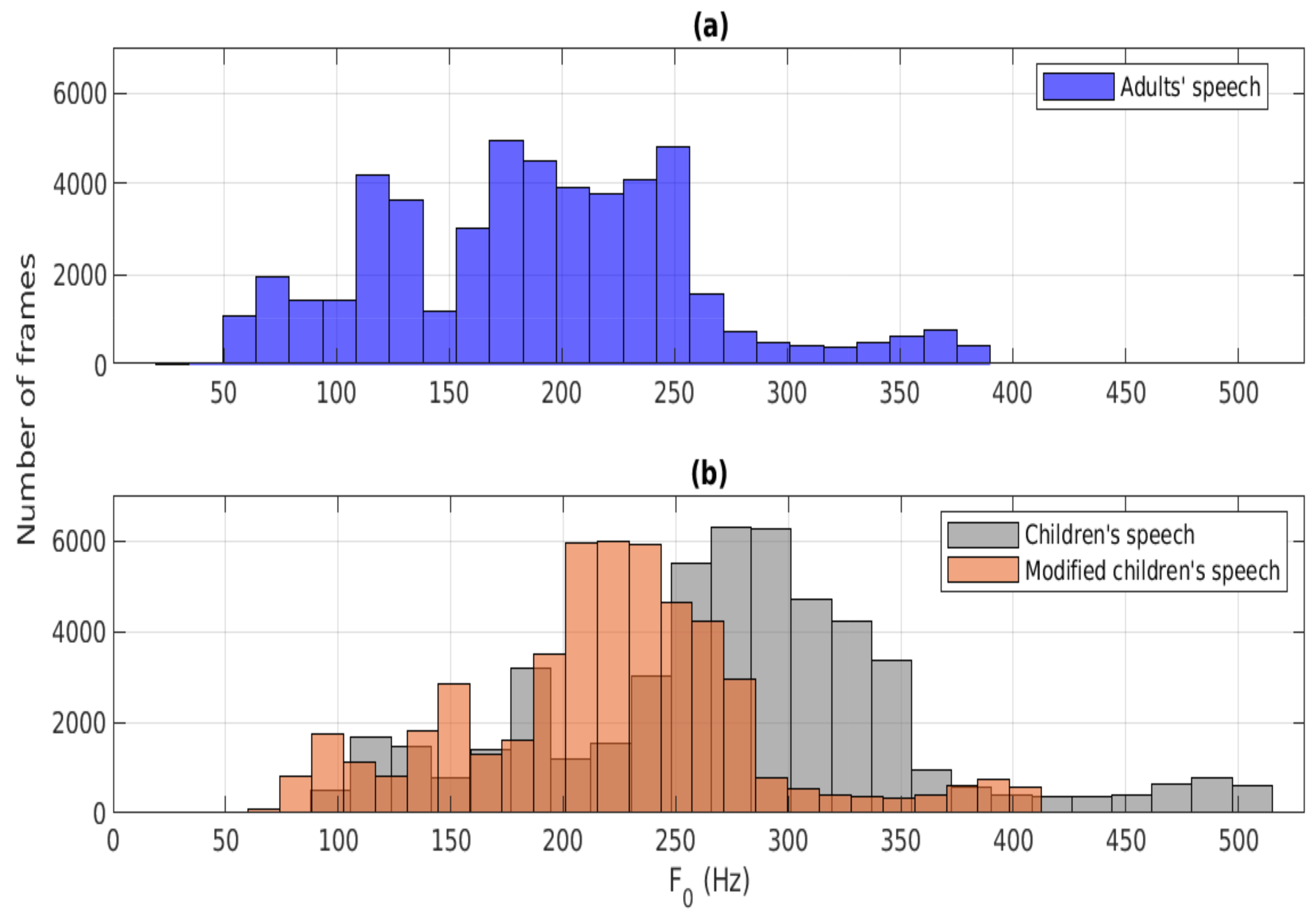
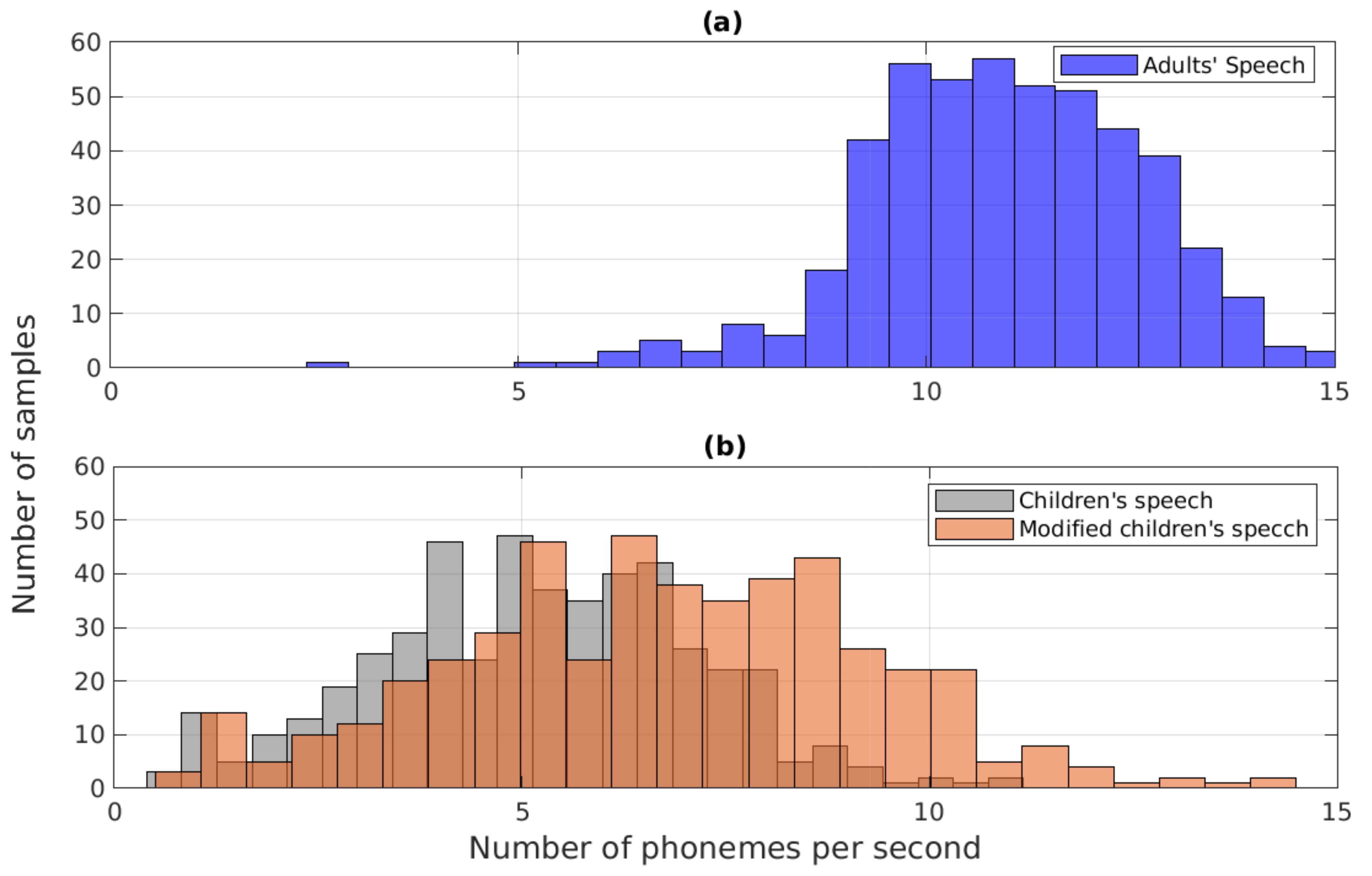
3. Time-Scale Modification
- The speech signal is processed in frames of L samples by computing the short-time Fourier transform magnitude (STFTM) spectrum using the FFT with the Hamming window. The frame shift (S) is selected as S = L/4 so that each frame overlaps with three previous and three following frames. In the following, the frame index is denoted by m and the window function by .
- To reconstruct the speech signal from its STFTM, an iterative frame-by-frame signal estimation process is applied. Let us suppose that the first frames of the speech signal have already been reconstructed from STFTM, and let us denote this signal by . The task is to synthesize .
- In order to estimate the mth frame, a partial analysis frame is created using overlap-adding (OLA) for the ()th, ()th, and ()th frame of considering an overlap of . The fourth quarter of this partially filled frame is filled with zeros. Let the partial frame be denoted by . In RTISI-LA, the future k frames influence the reconstruction of the mth frame. After the mth frame is generated, it is kept uncommitted until the (m + k)th frame is generated.
- Next, the Fourier transform of the partial frame is computed using a scaled Hamming window.
- The phase information computed from the Fourier transform of the partial frame is then combined with the STFTM for the mth frame.
- The inverse Fourier transform of the derived frequency-domain signal produces a new estimate for the mth frame. In each iteration, the estimation of is updated.
4. Speech Databases and the ASR System
5. Results
5.1. Results Obtained by Using Data Augmentation
5.2. Results Obtained by Using Modification
5.3. Results Obtained by Using Speaking Rate Modification
5.4. Results Obtained by Using the Combined System
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schalkwyk, J.; Beeferman, D.; Beaufays, F.; Byrne, B.; Chelba, C.; Cohen, M.; Kamvar, M.; Strope, B. Your Word is my Command: Google Search by Voice: A Case Study. In Advances in Speech Recognition: Mobile Environments, Call Centers and Clinics; Springer: Boston, MA, USA, 2010; Chapter 4; pp. 61–90. [Google Scholar]
- Li, J.; Deng, L.; Gong, Y.; Haeb-Umbach, R. An Overview of Noise-Robust Automatic Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 745–777. [Google Scholar] [CrossRef]
- Chetoni, M.; Ascari, E.; Bianco, F.; Fredianelli, L.; Licitra, G.; Cori, L. Global Noise Score Indicator for Classroom Evaluation of Acoustic Performances in LIFE GIOCONDA Project. Noise Mapp. 2016, 3, 157–171. [Google Scholar] [CrossRef]
- Zacarías, F.; Molina, R.H.; Ancela, J.L.C.; López, S.L.; Ojembarrena, A. Noise Exposure in Preterm Infants Treated with Respiratory Support Using Neonatal Helmets. Acta Acust. United Acust. 2013, 99, 590–597. [Google Scholar] [CrossRef]
- Minichilli, F.; Gorini, F.; Ascari, E.; Bianchi, F.; Coi, A.; Fredianelli, L.; Licitra, G.; Manzoli, F.; Mezzasalma, L.; Cori, L. Annoyance Judgment and Measurements of Environmental Noise: A Focus on Italian Secondary Schools. Int. J. Environ. Res. Public Health 2018, 15, 208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Erickson, L.; Newman, R. Influences of Background Noise on Infants and Children. Curr. Dir. Psychol. Sci. 2017, 26, 096372141770908. [Google Scholar] [CrossRef]
- Potamianos, A.; Narayanan, S. Robust Recognition of Children’s Speech. IEEE Trans. Speech Audio Process. 2003, 11, 603–616. [Google Scholar] [CrossRef] [Green Version]
- Cosi, P. On the Development of Matched and Mismatched Italian Children’s Speech Recognition System. In Proceedings of the Interspeech, Brighton, UK, 6–10 September 2009; pp. 540–543. [Google Scholar]
- Narayanan, S.; Potamianos, A. Creating Conversational Interfaces for Children. IEEE Trans. Speech Audio Process. 2002, 10, 65–78. [Google Scholar] [CrossRef]
- Sunil, Y.; Prasanna, S.; Sinha, R. Children’s Speech Recognition Under Mismatched Condition: A Review. IETE J. Educ. 2016, 57, 96–108. [Google Scholar] [CrossRef]
- Kathania, H.K.; Kadiri, S.R.; Alku, P.; Kurimo, M. Spectral Modification for Recognition of Children’s Speech Under Mismatched Conditions. In Proceedings of the 23rd Nordic Conference on Computational Linguistics (NoDaLiDa), Reykjavik, Iceland, 31 May–2 June 2021; Linköping University Electronic Press: Linköping, Sweden, 2021; pp. 94–100. [Google Scholar]
- Gowda, D.; Kadiri, S.R.; Story, B.; Alku, P. Time-varying Quasi-closed-phase Analysis for Accurate Formant Tracking in Speech Signals. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1901–1914. [Google Scholar]
- Chavan, K.; Gawande, U. Speech Recognition in Noisy Environment, Issues and Challenges: A Review. In Proceedings of the 2015 International Conference on Soft-Computing and Networks Security (ICSNS), Coimbatore, India, 25–27 February 2015; pp. 1–5. [Google Scholar] [CrossRef]
- Fernando, S.; Moore, R.K.; Cameron, D.; Collins, E.C.; Millings, A.; Sharkey, A.J.C.; Prescott, T.J. Automatic Recognition of Child Speech for Robotic Applications in Noisy Environments. arXiv 2016, arXiv:1611.02695. [Google Scholar]
- Martinek, R.; Vanus, J.; Nedoma, J.; Fridrich, M.; Frnda, J.; Kawala-Sterniuk, A. Voice Communication in Noisy Environments in a Smart House Using Hybrid LMS + ICA Algorithm. Sensors 2020, 20, 6022. [Google Scholar] [CrossRef]
- Walker, E.A.; Sapp, C.; Oleson, J.J.; McCreery, R.W. Longitudinal Speech Recognition in Noise in Children: Effects of Hearing Status and Vocabulary. Front. Psychol. 2019, 10, 2421. [Google Scholar] [CrossRef] [Green Version]
- Claus, F.; Gamboa-Rosales, H.; Petrick, R.; Hain, H.U.; Hoffmann, R. A Survey About Databases of Children’s Speech. In Proceedings of the 14th Annual Conference of the International Speech Communication, Lyon, France, 25–29 August 2013; pp. 2410–2414. [Google Scholar]
- Fainberg, J.; Bell, P.; Lincoln, M.; Renals, S. Improving Children’s Speech Recognition Through Out-of-Domain Data Augmentation. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 1598–1602. [Google Scholar] [CrossRef] [Green Version]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR Corpus Based on Public Domain Audio Books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Battenberg, E.; Chen, J.; Child, R.; Coates, A.; Gaur, Y.; Li, Y.; Liu, H.; Satheesh, S.; Seetapun, D.; Sriram, A.; et al. Exploring Neural Transducers for End-to-End Speech Recognition. arXiv 2017, arXiv:1707.07413. [Google Scholar]
- Shahnawazuddin, S.; Deepak, K.T.; Pradhan, G.; Sinha, R. Enhancing Noise and Pitch Robustness of Children’s ASR. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5225–5229. [Google Scholar]
- Yadav, I.C.; Shahnawazuddin, S.; Govind, D.; Pradhan, G. Spectral Smoothing by Variationalmode Decomposition and its Effect on Noise and Pitch Robustness of ASR System. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5629–5633. [Google Scholar]
- Mitra, V.; Franco, H.; Bartels, C.; van Hout, J.; Graciarena, M.; Vergyri, D. Speech Recognition in Unseen and Noisy Channel Conditions. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5215–5219. [Google Scholar]
- Roffo, G.; Melzi, S.; Castellani, U.; Vinciarelli, A.; Cristani, M. Infinite Feature Selection: A Graph-based Feature Filtering Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 1. [Google Scholar] [CrossRef] [PubMed]
- Xia, S.; Chen, B.; Wang, G.; Zheng, Y.; Gao, X.; Giem, E.; Chen, Z. mCRF and mRD: Two Classification Methods Based on a Novel Multiclass Label Noise Filtering Learning Framework. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, S. Bayesian Joint Matrix Decomposition for Data Integration with Heterogeneous Noise. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 1184–1196. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dubagunta, S.P.; Kabil, S.H.; Doss, M.M. Improving Children Speech Recognition through Feature Learning from Raw Speech Signal. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5736–5740. [Google Scholar]
- Shahnawazuddin, S.; Kathania, H.; Dey, A.; Sinha, R. Improving Children’s Mismatched ASR Using Structured Low-rank Feature Projection. Speech Commun. 2018, 105, 103–113. [Google Scholar] [CrossRef]
- Kathania, H.K.; Shahnawazuddin, S.; Adiga, N.; Ahmad, W. Role of Prosodic Features on Children’s Speech Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5519–5523. [Google Scholar]
- Kathania, H.K.; Shahnawazuddin, S.; Ahmad, W.; Adiga, N. Role of Linear, Mel and Inverse-Mel Filterbanks in Automatic Recognition of Speech from High-Pitched Speakers. Circuits Syst. Signal Process. 2019, 38, 4667–4682. [Google Scholar] [CrossRef]
- Shahnawazuddin, S.; Dey, A.; Sinha, R. Pitch-Adaptive Front-End Features for Robust Children’s ASR. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Gurunath Shivakumar, P.; Georgiou, P. Transfer Learning From Adult to Children for Speech Recognition: Evaluation, Analysis and Recommendations. Comput. Speech Lang. 2020, 63, 101077. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ahmad, W.; Shahnawazuddin, S.; Kathania, H.; Pradhan, G.; Samaddar, A. Improving Children’s Speech Recognition Through Explicit Pitch Scaling Based on Iterative Spectrogram Inversion. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 2391–2395. [Google Scholar] [CrossRef] [Green Version]
- Shahnawazuddin, S.; Adiga, N.; Kathania, H.K. Effect of Prosody Modification on Children’s ASR. IEEE Signal Process. Lett. 2017, 24, 1749–1753. [Google Scholar] [CrossRef]
- Kathania, H.K.; Shahnawazuddin, S.; Ahmad, W.; Adiga, N.; Jana, S.K.; Samaddar, A.B. Improving Children’s Speech Recognition Through Time Scale Modification Based Speaking Rate Adaptation. In Proceedings of the 2018 International Conference on Signal Processing and Communications (SPCOM), Bangalore, India, 16–19 July 2018. [Google Scholar]
- Kathania, H.K.; Kadiri, S.R.; Alku, P.; Kurimo, M. Study of Formant Modification for Children ASR. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7429–7433. [Google Scholar]
- Sheng, P.; Yang, Z.; Qian, Y. GANs for Children: A Generative Data Augmentation Strategy for Children Speech Recognition. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 129–135. [Google Scholar]
- Shahnawazuddin, S.; Adiga, N.; Kathania, H.K.; Sai, B.T. Creating Speaker Independent ASR System Through Prosody Modification Based Data Augmentation. Pattern Recognit. Lett. 2020, 131, 213–218. [Google Scholar] [CrossRef]
- Knill, K.; Gales, M.; Kyriakopoulos, K.; Malinin, A.; Ragni, A.; Wang, Y.; Caines, A. Impact of ASR Performance on Free Speaking Language Assessment. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 1641–1645. [Google Scholar] [CrossRef] [Green Version]
- Siegler, M.A.; Stern, R.M. On the Effects of Speech Rate in Large Vocabulary Speech Recognition Systems. In Proceedings of the 1995 International Conference on Acoustics, Speech, and Signal Processing, Detroit, MI, USA, 9–12 May 1995; Volume 1, pp. 612–615. [Google Scholar] [CrossRef] [Green Version]
- Fosler-Lussier, E.; Morgan, N. Effects of Speaking Rate and Word Frequency on Pronunciations in Convertional Speech. Speech Commun. 1999, 29, 137–158. [Google Scholar] [CrossRef]
- Stollman, M.H.P.; Kapteyn, T.S.; Sleeswijk, B.W. Effect of Time-Scale Modification of Speech on the Speech Recognition Threshold in Noise for Hearing-Impaired and Language-Impaired Children. Scand. Audiol. 1994, 23, 39–46. [Google Scholar] [CrossRef]
- Yadav, I.C.; Pradhan, G. Significance of Pitch-Based Spectral Normalization for Children’s Speech Recognition. IEEE Signal Process. Lett. 2019, 26, 1822–1826. [Google Scholar] [CrossRef]
- Robinson, T.; Fransen, J.; Pye, D.; Foote, J.; Renals, S. WSJCAM0: A British English Speech Corpus For Large Vocabulary Continuous Speech Recognition. In Proceedings of the 1995 International Conference on Acoustics, Speech, and Signal Processing, Detroit, MI, USA, 9–12 May 1995; Volume 1, pp. 81–84. [Google Scholar]
- Varga, A.; Steeneken, H.J. Assessment for automatic speech recognition: II. NOISEX-92: A Database and an Experiment to Study the Effect of Additive Noise on Speech Recognition Systems. Speech Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Zhu, X.; Beauregard, G.T.; Wyse, L.L. Real-time Signal Estimation from Modified Short-time Fourier Transform Magnitude Spectra. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1645–1653. [Google Scholar] [CrossRef]
- Beauregard, G.T.; Zhu, X.; Wyse, L. An Efficient Algorithm for Real-Time Spectrogram Inversion. In Proceedings of the 8th International Conference on Digital Audio Effects, Madrid, Spain, 20–22 September 2005; pp. 116–118. [Google Scholar]
- Griffin, D.; Lim, J. Signal Estimation from Modified Short-time Fourier Transform. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 236–243. [Google Scholar] [CrossRef]
- Batliner, A.; Blomberg, M.; D’Arcy, S.; Elenius, D.; Giuliani, D.; Gerosa, M.; Hacker, C.; Russell, M.; Wong, M. The PF_STAR Children’s Speech Corpus. In Proceedings of the Interspeech, Lisbon, Portugal, 4–8 September 2005; pp. 2761–2764. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi Speech Recognition Toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Big Island, HI, USA, 11–15 December 2011. [Google Scholar]
- Kathania, H.K.; Shahnawazuddin, S.; Pradhan, G.; Samaddar, A.B. Experiments on Children’s Speech Recognition Under Acoustically Mismatched Conditions. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; pp. 3014–3017. [Google Scholar] [CrossRef]
- Yildirim, S.; Narayanan, S.; Byrd, D.; Khurana, S. Acoustic Analysis of Preschool Children’s Speech. In Proceedings of the International Congresses of Phonetic Sciences (ICPhS), Barcelona, Spain, 3–9 August 2003. [Google Scholar]
- Tavares, E.L.M.; de Labio, R.B.; Martins, R.H.G. Normative Study of Vocal Acoustic Parameters From Children From 4 to 12 Years of Age Without Vocal Symptoms. A Pilot Study. Braz. J. Otorhinolaryngol. 2010, 76, 485–490. [Google Scholar] [CrossRef] [PubMed] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ASR | automatic speech recognition |
| TSM | time-scale modification |
| DA | data augmentation |
| M | modification |
| SRM | speaking rate modification |
| RTISI-LA | real-time iterative spectrogram inversion with look-ahead |
| LP | linear prediction |
| WER | word error rate |
| DNN | deep neural network |
| TDNN | time delay neural network |
| VTLN | vocal tract length modification |
| SRA | speaking rate adaptation |
| MFCCs | mel-frequency cepstral coefficients |
| GMM | Gaussian mixture model |
| HMM | hidden Markov model |
| fMLLR | feature-space maximum likelihood linear regression |
| LM | language model |
| LDA | linear discriminant analysis |
| MLLT | maximum likelihood linear transform |
| SAT | speaker adaptive training |
| SNR | signal-to-noise ratio |
| VMD | variational mode decomposition |
| SMAC | spectral moment time-frequency distribution augmented by low-order cepstral |
| CNN | convolutional neural network |
| SFM | stochastic feature mapping |
| GAN | generative adversarial network |
| STFTM | short-time Fourier transform magnitude |
| Database | WSJCAM0 | PF-STAR |
|---|---|---|
| Language | British English | British English |
| Use | training | testing |
| Speaker type | adult | child |
| No. of speakers | 92 | 60 |
| (males / females) | (53/39) | (32/28) |
| Age | >18 years | 4–13 years |
| No. of words | 132,778 | 5067 |
| Duration (h) | 15.5 | 1.1 |
| WER (%) | |||||
|---|---|---|---|---|---|
| Noise Type | SNR (dB) | Baseline | Data Augmentation Scenario | ||
| Same | Different | All | |||
| Babble | 0 dB | 53.35 | 47.05 | 76.35 | 50.90 |
| 5 dB | 36.43 | 34.37 | 55.42 | 33.68 | |
| 10 dB | 30.29 | 29.16 | 43.10 | 25.75 | |
| 15 dB | 26.46 | 25.18 | 35.76 | 23.64 | |
| White | 0 dB | 43.22 | 40.18 | 54.71 | 46.48 |
| 5 dB | 30.15 | 28.59 | 42.90 | 37.35 | |
| 10 dB | 26.11 | 24.86 | 36.05 | 31.83 | |
| 15 dB | 24.30 | 23.04 | 33.66 | 30.77 | |
| Factory | 0 dB | 65.51 | 54.75 | 81.05 | 58.46 |
| 5 dB | 42.47 | 38.01 | 59.23 | 34.59 | |
| 10 dB | 30.90 | 29.03 | 42.67 | 25.09 | |
| 15 dB | 26.30 | 25.18 | 33.23 | 20.65 | |
| Volvo | 0 dB | 21.09 | 18.95 | 38.85 | 23.48 |
| 5 dB | 20.20 | 18.44 | 36.62 | 22.59 | |
| 10 dB | 19.53 | 18.32 | 35.60 | 21.82 | |
| 15 dB | 18.92 | 18.11 | 32.36 | 21.54 | |
| WER (%) | |||
|---|---|---|---|
| Noise Type | SNR (dB) | Baseline | With Modification |
| Babble | 0 dB | 53.35 | 38.36 |
| 5 dB | 36.43 | 23.69 | |
| 10 dB | 30.29 | 18.28 | |
| 15 dB | 26.46 | 16.25 | |
| White | 0 dB | 43.22 | 33..85 |
| 5 dB | 30.15 | 20.34 | |
| 10 dB | 26.11 | 17.77 | |
| 15 dB | 24.30 | 16.38 | |
| Factory | 0 dB | 65.51 | 47.50 |
| 5 dB | 42.47 | 31.59 | |
| 10 dB | 30.90 | 17.89 | |
| 15 dB | 26.30 | 15.87 | |
| Volvo | 0 dB | 21.09 | 13.83 |
| 5 dB | 20.20 | 13.16 | |
| 10 dB | 19.53 | 12.82 | |
| 15 dB | 18.92 | 12.61 | |
| WER (%) | |||
|---|---|---|---|
| Noise Type | SNR (dB) | Baseline | With Speaking Rate Modification |
| Babble | 0 dB | 53.35 | 40.32 |
| 5 dB | 36.43 | 28.64 | |
| 10 dB | 30.29 | 25.73 | |
| 15 dB | 26.46 | 23.32 | |
| White | 0 dB | 43.22 | 38.65 |
| 5 dB | 30.15 | 26.53 | |
| 10 dB | 26.11 | 23.12 | |
| 15 dB | 24.30 | 22.76 | |
| Factory | 0 dB | 65.51 | 51.34 |
| 5 dB | 42.47 | 26.37 | |
| 10 dB | 30.90 | 25.65 | |
| 15 dB | 26.30 | 24.87 | |
| Volvo | 0 dB | 21.09 | 18.65 |
| 5 dB | 20.20 | 17.43 | |
| 10 dB | 19.53 | 17.17 | |
| 15 dB | 18.92 | 16.34 | |
| Noise Type | SNR (dB) | WER (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | Combined System | ||||||||||
| Same | Different | All | |||||||||
| DA + M | DA + SRM | DA + M + SRM | DA + M | DA + SRM | DA + M + SRM | DA + M | DA + SRM | DA + M + SRM | |||
| Babble | 0 dB | 53.35 | 28.47 | 37.82 | 25.21 | 47.36 | 66.95 | 38.34 | 26.59 | 40.73 | 21.15 |
| 5 dB | 36.43 | 19.57 | 26.97 | 17.83 | 29.44 | 31.14 | 21.52 | 16.25 | 25.11 | 12.85 | |
| 10 dB | 30.29 | 16.80 | 23.26 | 15.44 | 23.32 | 28.14 | 15.54 | 13.45 | 17.33 | 10.29 | |
| 15 dB | 26.46 | 14.81 | 21.62 | 13.76 | 18.56 | 24.66 | 13.84 | 12.66 | 15.74 | 9.65 | |
| White | 0 dB | 43.22 | 32.54 | 34.27 | 28.69 | 29.60 | 45.92 | 23.53 | 31.22 | 34.83 | 17.95 |
| 5 dB | 30.15 | 19.55 | 23.67 | 18.80 | 17.87 | 32.77 | 14.12 | 23.71 | 23.79 | 12.34 | |
| 10 dB | 26.11 | 15.10 | 19.98 | 14.99 | 14.12 | 26.63 | 10.94 | 15.66 | 20.02 | 10.54 | |
| 15 dB | 24.30 | 13.95 | 19.27 | 13.70 | 13.94 | 21.80 | 10.56 | 13.41 | 18.56 | 10.27 | |
| Factory | 0 dB | 65.51 | 35.64 | 46.28 | 33.25 | 69.65 | 75.81 | 60.81 | 34.33 | 46.14 | 26.59 |
| 5 dB | 42.47 | 22.49 | 29.18 | 20.75 | 42.17 | 49.73 | 32.30 | 18.80 | 22.65 | 13.94 | |
| 10 dB | 30.90 | 16.84 | 23.32 | 16.13 | 27.13 | 30.42 | 16.13 | 13.07 | 15.76 | 10.07 | |
| 15 dB | 26.30 | 14.99 | 22.90 | 14.37 | 19.57 | 23.47 | 14.20 | 12.20 | 13.39 | 8.92 | |
| Volvo | 0 dB | 21.09 | 13.11 | 16.59 | 11.87 | 15.52 | 22.11 | 11.92 | 12.24 | 14.92 | 9.38 |
| 5 dB | 20.20 | 12.62 | 15.08 | 11.47 | 15.30 | 21.87 | 11.33 | 12.18 | 14.67 | 9.24 | |
| 10 dB | 19.53 | 12.28 | 15.00 | 11.45 | 15.12 | 21.32 | 11.12 | 12.04 | 14.32 | 9.18 | |
| 15 dB | 18.92 | 12.10 | 14.89 | 11.43 | 14.89 | 20.96 | 10.94 | 11.86 | 14.13 | 8.76 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kathania, H.K.; Kadiri, S.R.; Alku, P.; Kurimo, M. Using Data Augmentation and Time-Scale Modification to Improve ASR of Children’s Speech in Noisy Environments. Appl. Sci. 2021, 11, 8420. https://doi.org/10.3390/app11188420
Kathania HK, Kadiri SR, Alku P, Kurimo M. Using Data Augmentation and Time-Scale Modification to Improve ASR of Children’s Speech in Noisy Environments. Applied Sciences. 2021; 11(18):8420. https://doi.org/10.3390/app11188420
Chicago/Turabian StyleKathania, Hemant Kumar, Sudarsana Reddy Kadiri, Paavo Alku, and Mikko Kurimo. 2021. "Using Data Augmentation and Time-Scale Modification to Improve ASR of Children’s Speech in Noisy Environments" Applied Sciences 11, no. 18: 8420. https://doi.org/10.3390/app11188420
APA StyleKathania, H. K., Kadiri, S. R., Alku, P., & Kurimo, M. (2021). Using Data Augmentation and Time-Scale Modification to Improve ASR of Children’s Speech in Noisy Environments. Applied Sciences, 11(18), 8420. https://doi.org/10.3390/app11188420