1. Introduction
Automatic speech recognition (ASR) has many potential applications for children in areas such as education (learning new languages and other skills), games, and entertainment. Building ASR systems for child users is, however, challenging for several reasons. First, ASR applications are typically used by children in noisy environments, and the data collection to cover different noise conditions is particularly difficult. Second, due to general problems in recording child speech (e.g., it is difficult to control recording conditions for children, and talkers are not always collaborative), it is difficult to collect enough training data to build ASR systems for children. Therefore, the performance of ASR systems in recognition of children’s speech degrades due to the mismatch caused by training and testing under different noise conditions and due to the mismatch caused by training the system with adults’ speech and testing with children’s speech.
While the majority of publicly available ASR systems work effectively for adults’ speech in noise-free environments, their performance degrades considerably when used in noisy environments and particularly when recognizing children’s speech in noisy environments [
1,
2]. Classrooms are an example of environments where children are subject to noise exposure [
3,
4,
5,
6] and where ASR technology is increasingly used in education. The degradation of ASR systems in recognition of noisy children’s speech depends on many issues such as noise type, signal-to-noise ratio (SNR), acoustic and linguistic differences in fundamental frequency (
), speaking rate, and formant frequencies between adult and child speech [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. Decreased ASR performance of children’s speech compared to adults’ speech is also explained by the fact that the number of publicly available training data for children’s speech (tens of hours) [
17,
18] is much smaller compared to that of adults’ speech (thousands of hours) [
19,
20]. Overall, new research is needed to develop ASR systems capable of recognizing children’s speech in noisy environments. In order to develop such a system, the following two techniques are taken advantage of in the current study: (1) using data augmentation based on noise addition to tackle the mismatch induced by having different noise conditions in training and testing and (2) using time-scale modification to tackle the mismatch induced by having adults’ speech in training and children’s speech in testing.
There are a few existing ASR studies that have addressed both the mismatch induced by having clean speech in training and noisy speech in testing as well as by having adult speech in training vs. child speech in testing. These research questions were studied, for example, in [
21] by investigating the use of spectral moments and spectral smoothing-based features, and the results showed that the spectral moment time-frequency distribution augmented by low-order cepstral (SMAC) features were found to improve the recognition performance. In [
22], variational mode decomposition (VMD)-based spectral smoothing was found to improve ASR for children’s speech in noise. In [
23,
24,
25,
26], the feature-space maximum likelihood linear regression (fMLLR) transform, deep convolutional neural networks (CNNs), graph-based feature filtering, and Bayes methods were investigated to address the problems caused by different channel and noise conditions. The effect of feature learning using a CNN-based end-to-end acoustic modeling approach was studied in [
27], and the method was shown to give a reduction in WER. Principal component analysis and heteroscedastic linear discriminant analysis based on a low-rank feature projection were explored in [
28]. In [
29], prosodic features including loudness, intensity, and voice probability were investigated, and it was found that combining the prosodic features with mel-frequency cepstral coefficients (MFCCs) improved ASR performance. The effect of the filter bank on ASR of children’s speech was studied in [
30], and it was found that the linear-frequency filter bank was better compared to the mel and inverse-mel filter banks.
The effects of acoustic and linguistic differences between adults’ and children’s speech have been investigated widely [
22,
29,
31,
32], and these differences have been observed to degrade ASR performance considerably. Modifying prosodic features (
and speaking rate) was found to reduce the effect of mismatch induced by having adults’ (clean) speech in training and children’s (clean) speech in testing in [
33,
34,
35]. The effect of modifying formants in ASR of children’s speech in clean and noisy conditions was explored recently in [
36], and the results showed a reduction in WER when formants of children’s speech were modified towards those in adults’ speech. The performance of the formant modification method proposed in [
36] is, however, limited due to the use of all-pole spectral modeling methods whose accuracy deteriorates in low SNR levels below 5 dB. In [
37], generative adversarial network (GAN)-based data augmentation was explored, and an improvement in WER was reported. A data augmentation strategy based on modifying prosody (
and speaking rate) by changing glottal closure instants was studied in [
38]. In [
18], data augmentation using stochastic feature mapping (SFM) to transform out-of-domain adult data was found to improve recognition of children’s speech.
This study investigates ASR of children’s speech by focusing on two challenges: (1) recognition of speech in noisy conditions, which is a typical scenario for child users, and (2) recognition of children’s speech using an ASR system trained with adult speech due to the lack of training data from child speakers. In order to address these two challenges, the study combines data augmentation and time-scale modification. In the former, a straightforward data augmentation method is used by corrupting the training data of the ASR system with additive noise to obtain new speech data that correspond better with the testing data in noisy conditions. In the latter, two modification methods (
modification and speaking rate modification) are used to modify the prosodic characteristics of the children’s speech in the testing phase towards the prosodic characteristics of the adult speech that is used in the system training phase.
and speaking rate were selected as prosodic features to be modified because their modification is easy to implement and because their modification has shown promising results in previous studies [
33,
34,
39]. In addition, modification of these factors can be done in a more robust manner from noisy speech compared to factors such as formants, whose estimation deteriorates in noisy environments.
Figure 1 shows a flow diagram demonstrating how data augmentation and time-scale modification are used in the current investigation. Note that it would also be possible to modify the prosodic structure of adult speech in the training phase using time-scale modification, but this should be done separately for each noise condition and is therefore not feasible.
Data augmentation and time-scale modification have been investigated separately in previous ASR studies (e.g., [
40,
41,
42] for the former and [
33,
34,
39,
43] for the latter). However, the effect of
these techniques has not been investigated in recognition of noisy children’s speech before. Therefore, the main contribution of the current study is to investigate how the performance of a children’s speech ASR system that suffers from the two challenges described in the beginning of this section is affected when using data augmentation,
modification, and speaking rate modification either separately or by combining these techniques one by one. The study shows encouraging results, indicating that while none of the three previously studied methods alone gives an adequate improvement in the recognition performance, the combination of the three approaches as implemented in the current study results in a considerable improvement in recognition of children’s speech in noisy conditions.
The remainder of the paper is organized as follows. The two main techniques studied, data augmentation and time-scale modification, are first described in
Section 2 and
Section 3, respectively.
Section 4 describes the speech databases and the ASR system used in the study. The results of the ASR experiments are reported in
Section 5 by describing in separate sub-sections how data augmentation,
modification, speaking rate modification, and finally the combination of the three affect the recognition performance. The results are discussed in
Section 6, and the conclusions of the study are drawn in
Section 7.
The list of abbreviations used in this study are given in
Table 1.
2. Data Augmentation
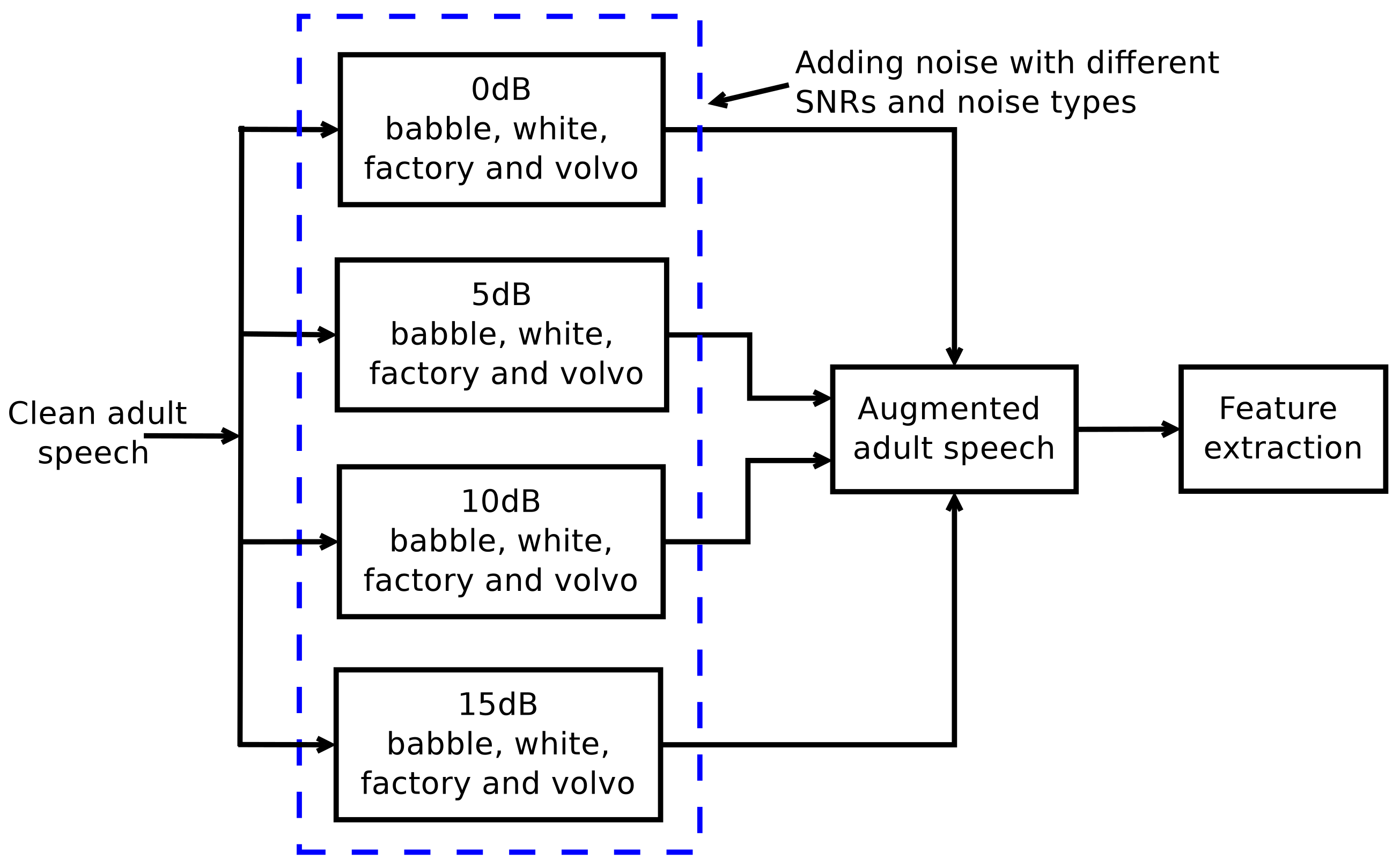
In this study, we used noise addition as the data augmentation strategy. The main motivation for this type of data augmentation is to capture more acoustic variability of the data to improve the ASR system performance in noisy environments. The proposed approach is demonstrated in the block diagram shown in
Figure 2. The input to the data augmentation procedure is clean adult speech taken from an existing large database, WSJCAM0 [
44], which will be described in
Section 4. Augmentation is conducted by corrupting the clean input signal with additive noise by varying the SNR from 0 dB to 15 dB with a step size of 5 dB and by using four different types of noise (babble, white, factory, and volvo) extracted from the NOISEX-92 database [
45]. It should be noted that the data augmentation approach is used in this study to generate new, noise-corrupted data for training, but the original clean adult speech taken from the WSJCAM0 database is not included in the generated training data.
Data augmentation is performed in the ASR experiments of the current study using three scenarios: the “same” scenario, the “different” scenario, and the “all” scenario. The “same” scenario refers to testing the ASR system in circumstances where the test speech is corrupted by one type of noise (e.g., babble), and system training is based on using the same noise type in data augmentation. The “different” scenario refers to corrupting the test speech with one noise type and using the other three types in augmenting the training data (e.g., babble noise in testing, and factory, volvo as well as white noise in augmentation). The “all” scenario refers to testing with speech corrupted by one noise type (e.g., white) but using all four noise types in data augmentation.
3. Time-Scale Modification
In order to address the second challenge of ASR for children’s speech described in
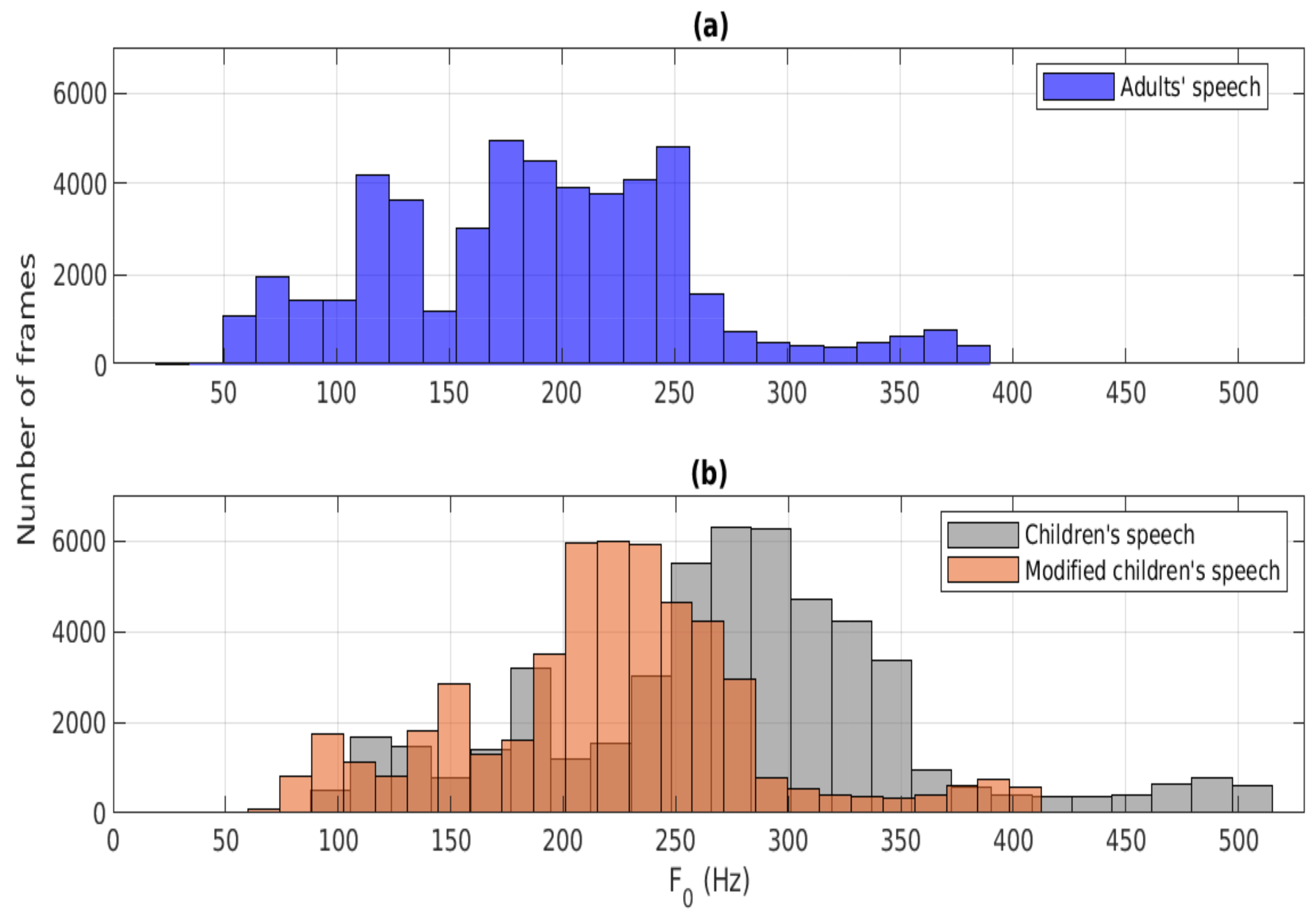
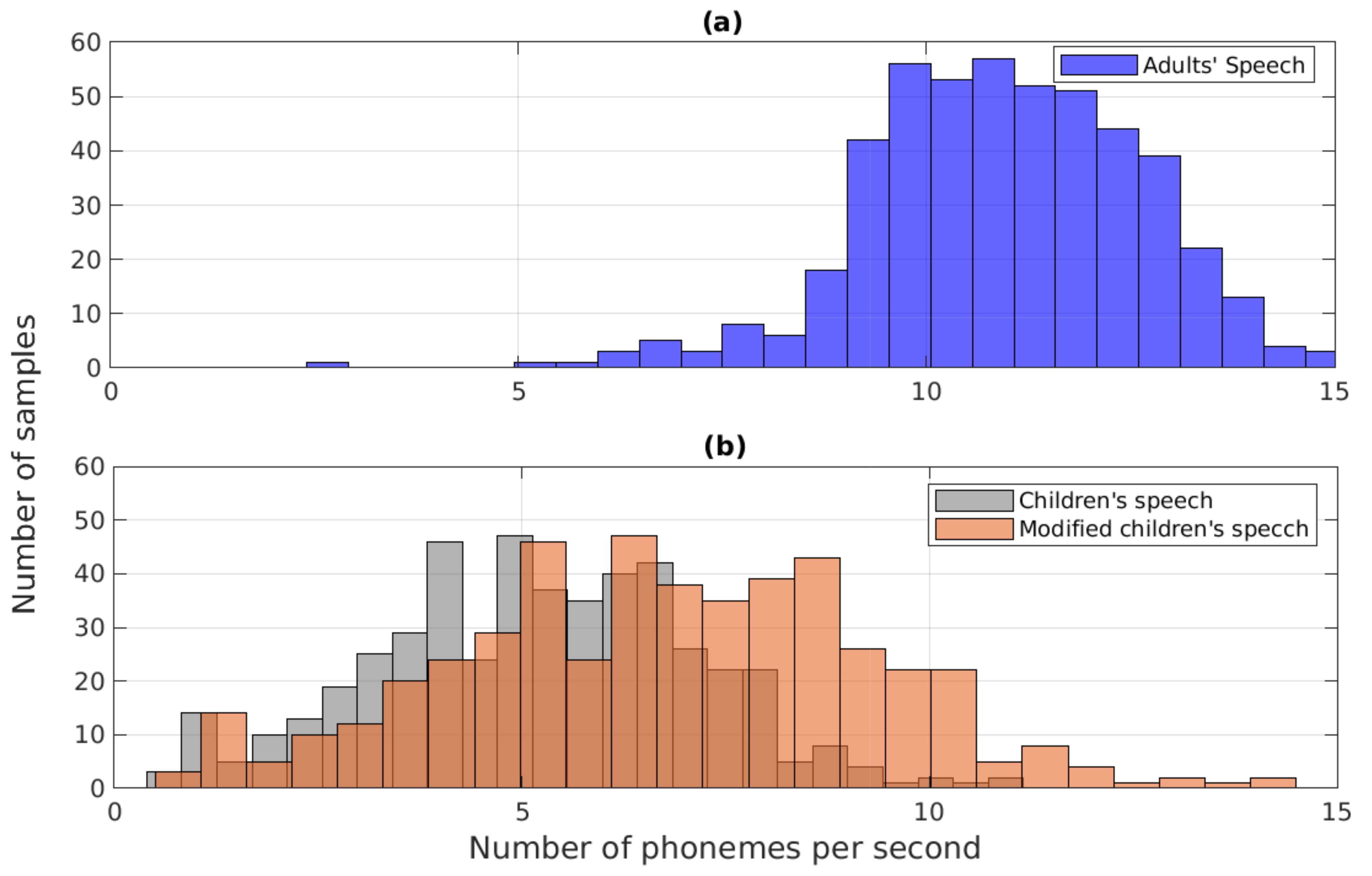
Section 1—the mismatch caused by the lack of adequate training data from child speakers—the present study investigates modifying the time-scale structure of children’s speech in the system testing phase. The goal of the time-scale modification is to make the testing data of child speakers more similar to the training data of adult speakers by modifying two prosodic features of speech,
and speaking rate. Both the
modification and the speaking rate modification were conducted using the same method, the real-time iterative spectrogram inversion with look-ahead (RTISI-LA) algorithm [
35,
46,
47]. RTISI-LA was originally developed as a method for estimating time-domain signals from overlapping magnitude spectra that have been computed frame by frame. RTISI-LA is a similar kind of phase recovery technique as the Griffin-Lim algorithm [
46,
48]. RTISI-LA is, however, much faster than the Griffin-Lim algorithm and therefore justified to be used in applications like the current study, where large numbers of speech data need to be processed. The RTISI-LA method consists of the following steps.
The speech signal is processed in frames of L samples by computing the short-time Fourier transform magnitude (STFTM) spectrum using the FFT with the Hamming window. The frame shift (S) is selected as S = L/4 so that each frame overlaps with three previous and three following frames. In the following, the frame index is denoted by m and the window function by .
To reconstruct the speech signal from its STFTM, an iterative frame-by-frame signal estimation process is applied. Let us suppose that the first frames of the speech signal have already been reconstructed from STFTM, and let us denote this signal by . The task is to synthesize .
In order to estimate the mth frame, a partial analysis frame is created using overlap-adding (OLA) for the ()th, ()th, and ()th frame of considering an overlap of . The fourth quarter of this partially filled frame is filled with zeros. Let the partial frame be denoted by . In RTISI-LA, the future k frames influence the reconstruction of the mth frame. After the mth frame is generated, it is kept uncommitted until the (m + k)th frame is generated.
Next, the Fourier transform of the partial frame is computed using a scaled Hamming window.
The phase information computed from the Fourier transform of the partial frame is then combined with the STFTM for the mth frame.
The inverse Fourier transform of the derived frequency-domain signal produces a new estimate for the mth frame. In each iteration, the estimation of is updated.
As described in [
46], the RTISI-LA algorithm can be used to modify both the
and speaking rate of speech signals. By using the notations of [
46], these two modifications were conducted in the current study as follows by using child speech as input.
Modification The
modification was computed by first re-sampling the input speech signal in the time domain. To modify the
of the input speech signal downwards by factor
q, where
, the input frame of
samples was re-sampled to obtain a longer frame of
L samples (i.e.,
), which was then used in the STFTM computation. We used simple linear interpolation in re-sampling because it is computationally inexpensive and was reported in [
46] to provide reasonable sound quality. The value of
L was fixed to 160 samples. The STFMs of the overlapping frames (i.e., the magnitude spectrogram) were then processed using the RTISI-LA algorithm (steps 1–6 above) to obtain the
-modified time domain output signal. The value of the factor
q was selected by conducting ASR experiments and by searching for the value of
q, which yielded the lowest WER. More details about this will be given in
Section 5.2.
Speaking rate modification The modification of the speaking rate with RTISI-LA is based on the frequency-domain approach proposed in [
46]. In this approach, the STFTM of the input signal is computed in the analysis stage using a frame shift of
, and the signal is transformed to the time domain in the synthesis stage with RTISI-LA using a different value of the frame shift (denoted by
). The amount of modification is defined by the factor
, which is defined such that
=
/
. By using 0 <
< 1.0, the speaking rate of speech can be increased. In our experiments, the speaking rate modification was conducted using the frame size of
L = 256 samples and by fixing
=
L/4. The value of
was selected by searching for the value that yielded the lowest WER, as will be explained in
Section 5.3.
6. Discussion
Achieving high accuracy in recognition of children’s speech is difficult using state-of-the-art ASR systems because of two types of mismatch between the system training and testing. First, children typically use ASR applications in noisy environments such as when playing games and when taking part in education with other children. Therefore, when the system is trained with clean speech, there is mismatch between the testing and training stages. Second, due to practical problems in recording young child speakers, few training data are available from child speakers, and current ASR systems are mostly trained using adults’ speech only. Therefore, when these ASR systems are used to recognize children’ speech, another mismatch will be brought about between the system training and testing stages. The severity of these two mismatches was first demonstrated in the current study using a standard ASR system: a poor WER value (of about 20%) was obtained in recognizing clean children’s speech using the system trained using adults’ speech. Furthermore, when the children’s speech was contaminated with noise in order to simulate the use of children’s ASR in realistic environments, the recognition performance deteriorated severely to WER values larger than 80% in some noise conditions.
In order to tackle the effects caused by the two mismatches described above in recognition of children’s speech in noisy conditions, the current study investigated the utilization of data augmentation and time-scale modification. Furthermore, the time-scale modification technique consisted of two parts, modification of and modification of speaking rate, which were used to convert the prosodic structure of the children’s speech test data to become closer to that of the adults’ speech used in the system training. The experiments of the study were planned in order to first investigate how the recognition performance was affected when each of the modification techniques was utilized alone in building the recognizer, after which all the studied techniques were combined aiming at the best system. The experiments were conducted using an existing deep neural network (DNN)-based recognizer. Although CNNs are currently increasingly used in ASR, they call for larger numbers of training data compared to DNN-based systems. Therefore, choosing a DNN-based architecture was justified for the current investigation, and we leave the verification of the studied approach with big and complex systems as future work. The data augmentation involved corrupting the original clean training data of adults’ speech using additive noise of different types and SNR categories. Three augmentation scenarios (“same”, “different”, “all”) were generated, and these scenarios differ in the way the noise type in testing is seen by the data augmentation procedure. The recognition experiments indicated that data augmentation yielded a consistent improvement in WER only in the case when the noise type was the same in the augmentation and testing. However, when the noise type in testing was different from that used in data augmentation, the performance compared to the baseline decreased considerably, and this happened in all the noise conditions studied. Hence, the utilization of the straightforward data augmentation approach based on noise-corrupting the adult speech in the system training stage did not give an adequate improvement in recognition of noisy children’s speech. As the next steps, ASR experiments were conducted by time-scale modifying the prosodic structure of the children’s speech in the test stage. The experiments showed that both modification and speaking rate modification improved WER values compared to the baseline system and that this happened for all the noise conditions studied. From the two modification methods, modification yielded smaller WER values in all noise conditions. As the final step in our experiments, we combined data augmentation with modification, with speaking rate modification, and with both of them. The results indicated that combining data augmentation with both of the time-scale modification methods yielded the lowest WER in all noise conditions studied. For this combination, the WER values obtained in the three data augmentation scenarios were lowest in “all”, second lowest in “same”, and highest in “different”.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}