
Adversarial Attack and Defense on Deep Neural Network-Based Voice Processing Systems: An Overview

Abstract
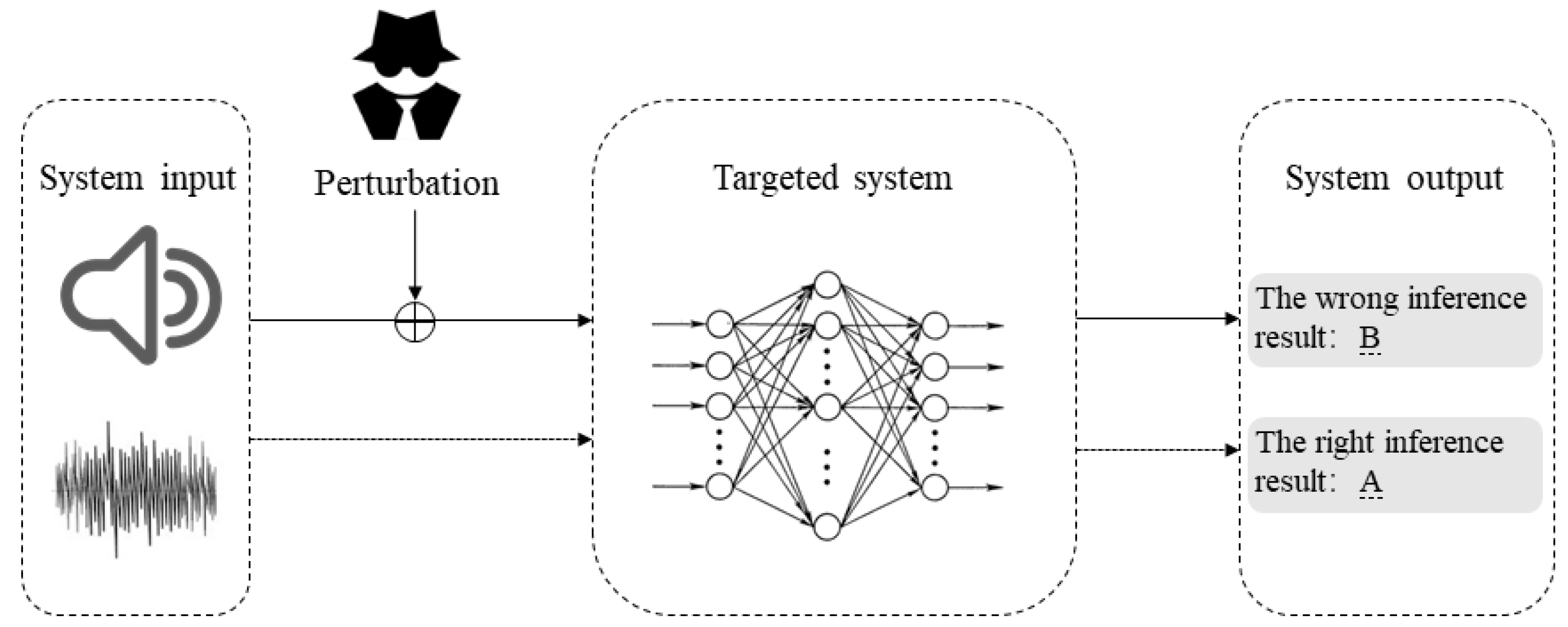
:1. Introduction
- In order to better illustrate the application of adversarial attacks and defenses in sound processing systems, we introduce in detail the contents of adversarial attacks, including methods for generating adversarial examples and metrics for adversarial attacks. At the same time, we summarize the main methods of adversarial aggression and defense in speaker recognition and speech recognition, respectively.
- Based on the above research methods, we systematically categorize the methods of adversarial attack and defense.
2. Background
2.1. Attack
2.1.1. Adversarial Examples
- L-BFGS: Szegedy et al. [2] first introduced adversarial examples against a deep neural network in 2014. They model the problem as a constrained minimization problem called L-BFGS:In general, the exact computation of is a hard problem, so they use the addition of the minimized loss function:where, is a loss function of a deep neural network. One common loss function to use is cross-entropy. A line search is performed to find the constant that yields an adversarial example of minimum distance: in other words, we repeatedly solve this optimization problem for multiple values of c, adaptively updating c using bisection search or any other method for one-dimensional optimization. This generation algorithm has the characteristics of fast generation speed and low memory footprint, but there is still a lot of room for improvement in terms of confrontation.
- The fast gradient sign method (FGSM): The fast gradient sign method [6] has two key difference from the L-BFGS method: first, it has been optimized for distance measurement, and second, its main purpose is to quickly generate the adversarial examples rather than generate very close examples. Given an input x the fast gradient sign method sets:where the perturbation is ; is chosen to be sufficiently small so as to be undetectable; is the parameter of the classification model; y satisfies and is the correct output of x; is the loss function used in this deep neural network. It is worth noting that this method is mainly focused on quickly generating adversarial examples rather than getting the smallest disturbance.
- Basic iterative method (BIM): Although FGSM is simple and computationally efficient compared to other methods, it has a lower success rate with a nonlinear model. The reason that leads to this phenomenon is that, for the linear model, the direction in which the loss decreases is clear, and even if you iterate multiple times, the direction of the disturbance will not change. However, for a non-linear model, the direction may not be completely correct if you only perform one iteration, so multiple iterations are needed to determine the optimal situation. The BIM [9] method has been improved on FGSM, and one step is divided into many small steps to iteratively obtain adversarial examples:where the denotes element-wise clipping A. This method can generate the adversarial examples in nonlinear model, while at the cost of expensive computation.
- Deepfool: Moosavi–Dezfooli et al. [10] proposed DeepFool to compute a minimal norm adversarial perturbation by the basic ideal of the distance from the input x to the boundaries of the classifier. That is, they assume , where f is an binary classification function and satisfies . It can be easily seen that its affine plane is . When a disturbance is added to a point and perpendicular to the plane , the disturbance added is the smallest and can meet the iteration requirements, as in the formula:Furthermore, in the overall iterative process, the generation of adversarial examples can be expressed as:DeepFool uses iteration to generate the minimum norm to counter the disturbance. At each step, the data values located within the classification boundary are modified step by step to outside the boundary until a classification error occurs. This method maintains almost the same resistance as FGSM, while the disturbances generated are smaller.
- Jacobian-based Saliency Map Attack (JSMA): JSMA [11] was proposed by Nicolas et al. It is a method for generating adversarial examples for the type of deep neural network. It uses the forward guide number to implement it. The generation of the forward guide number uses the Jacobian matrix of the function function in the trained network. Given the function of network F, we can obtain the forward derivative by this formula:
- Universal adversarial examples: Methods such as FGSM, and DeepFool can only generate a single audio against perturbations, while universal adversarial examples [12] can generate perturbations almost imperceptible that attack any voice processing systems, and these perturbations are also harmful to humans. The method used in this paper [12] is similar to DeepFool, which uses anti-disturbance to push the image out of the classification boundary, but the same disturbance is for all. Although this article only targets a single network, ResNet, it has been proven that this malicious perturbation can be generalized to other networks.
2.1.2. Psychoacoustics
- Frequency Masking. Frequency masking implies masking between two sounds of close frequency, where a low-level maskee is inaudible by a simultaneously occurring louder masker. In simple terms, the masker can be seen as creating a “masking threshold” in the frequency domain. Any signals which fall under this threshold are effectively imperceptible. Figure 2 gives a vivid example of simultaneous masking, where sound is the masker. Because of the presence of , the threshold in quiet is elevated to produce a new hearing threshold named the masking threshold; in this example, the weaker signal and are entirely inaudible, as their sound pressure level is below the masking threshold.
- Temporal Masking. In addition to frequency masking, auditory masking can also occur when the maskee is present immediately preceding or following the masker. This is called temporal masking or non-simultaneous masking. There are two kinds of non-simultaneous masking: (1) pre-masking or backward masking, occurring just before the onset of the masker, and (2) post-masking or forward masking, occurring after the removal of the masker. In general, the physiological basis of non-simultaneous masking is that the auditory system requires a particular integration time to build the perception of sound, where louder sounds require longer integration intervals than softer ones.
2.1.3. Metrics
2.2. Attack on ASRs
2.3. Attack on Speaker Recognition System
2.4. Defence against Adversarial Attack
3. Attack Threat Model Taxonomy
3.1. Adversarial Knowledge
3.2. Adversarial Goal
3.3. Adversarial Perturbation Scope
3.4. Real or Simulated World
4. Defense
4.1. Defensive Result
4.2. Classification from the Content of Defense

{kind=link}
{kind=link}
{kind=link}
| Work | Year | Defense Method | Task | System | Adversarial Example |
|---|---|---|---|---|---|
| [59] | 2018 | Temporal dependency | Detecting | ASR | Genetic algorithm [13]/FGSM/ Commander Song [19] |
| [46] | 2019 | Adversarial regularization | Defense | ASV | FGSM/LDS |
| [61] | 2019 | MVP- | Detecting | ASR | FGSM |
| [62] | 2019 | Audio modification | Detecting | ASR | Carlini and Wagner Attacks [4] |
| [90] | 2020 | Adversarial training/Spatial smoothing | Defense | ASV | Projected Gradient Descent Method [91] |
| [92] | 2020 | Self-attention U-Net | Defense | ASR | FGSM/Evolutionary optimization [93] |
| [94] | 2021 | Hybrid adversarial training | Defense | SRS | FGSM |
| [95] | 2021 | Audio transformation | Detecting | ASR | Adaptive attack algorithm [95] |
| [96] | 2021 | Self-supervised learning model [97] | Defense | ASV | BIM |
4.3. From Different Areas of Defense Methods
5. Future Working
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, S. Forensic and automatic speaker recognition system. Int. J. Electr. Comput. Eng. 2018, 8, 2804. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Sarkar, S.; Bansal, A.; Mahbub, U.; Chellappa, R. UPSET and ANGRI: Breaking high performance image classifiers. arXiv 2017, arXiv:1707.01159. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Xiao, Q.; Chen, Y.; Shen, C.; Chen, Y.; Li, K. Seeing is not believing: Camouflage attacks on image scaling algorithms. In Proceedings of the 28th {USENIX} Security Symposium ({USENIX} Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 443–460. [Google Scholar]
- Lin, Y.; Abdulla, W.H. Principles of Psychoacoustics; Springer: Berlin/Heidelberg, Germany, 2015; pp. 15–49. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Saarbrücken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Alzantot, M.; Balaji, B.; Srivastava, M. Did you hear that? adversarial examples against automatic speech recognition. arXiv 2018, arXiv:1801.00554. [Google Scholar]
- Taori, R.; Kamsetty, A.; Chu, B.; Vemuri, N. Targeted adversarial examples for black box audio systems. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), Francisco, CA, USA, 19–23 May 2019; pp. 15–20. [Google Scholar]
- Wu, Y.; Liu, J.; Chen, Y.; Cheng, J. Semi-black-box attacks against speech recognition systems using adversarial samples. In Proceedings of the IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Newark, NJ, USA, 11–14 November 2019; pp. 1–5. [Google Scholar]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Abdullah, H.; Garcia, W.; Peeters, C.; Traynor, P.; Butler, K.R.; Wilson, J. Practical hidden voice attacks against speech and speaker recognition systems. arXiv 2019, arXiv:1904.05734. [Google Scholar]
- Cherry, E.C. Some experiments on the recognition of speech, with one and with two ears. J. Acoust. Soc. Am. 1953, 25, 975–979. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, Y.; Zhao, Y.; Long, Y.; Liu, X.; Chen, K.; Zhang, S.; Huang, H.; Wang, X.; Gunter, C.A. Commandersong: A systematic approach for practical adversarial voice recognition. In Proceedings of the 27th {USENIX} Security Symposium ({USENIX} Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 49–64. [Google Scholar]
- Navarro, G. A guided tour to approximate string matching. ACM Comput. Surv. (CSUR) 2001, 33, 31–88. [Google Scholar] [CrossRef]
- Yook, S.; Nam, K.W.; Kim, H.; Kwon, S.Y.; Kim, D.; Lee, S.; Hong, S.H.; Jang, D.P.; Kim, I.Y. Modified segmental signal-to-noise ratio reflecting spectral masking effect for evaluating the performance of hearing aid algorithms. Speech Commun. 2013, 55, 1003–1010. [Google Scholar] [CrossRef]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)—A new method for speech quality assessment of telephone networks and codecs. In Proceedings of the IEEE-ICASSP, Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5884–5888. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 4835–4839. [Google Scholar]
- Carlini, N.; Wagner, D. Audio adversarial examples: Targeted attacks on speech-to-text. In Proceedings of the IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018; pp. 1–7. [Google Scholar]
- Schönherr, L.; Kohls, K.; Zeiler, S.; Holz, T.; Kolossa, D. Adversarial attacks against automatic speech recognition systems via psychoacoustic hiding. arXiv 2018, arXiv:1808.05665. [Google Scholar]
- Qin, Y.; Carlini, N.; Cottrell, G.; Goodfellow, I.; Raffel, C. Imperceptible, robust, and targeted adversarial examples for automatic speech recognition. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 5231–5240. [Google Scholar]
- Muda, L.; Begam, M.; Elamvazuthi, I. Voice recognition algorithms using mel frequency cepstral coefficient (MFCC) and dynamic time warping (DTW) techniques. arXiv 2010, arXiv:1003.4083. [Google Scholar]
- Yakura, H.; Sakuma, J. Robust audio adversarial example for a physical attack. arXiv 2018, arXiv:1810.11793. [Google Scholar]
- Chen, Y.; Yuan, X.; Zhang, J.; Zhao, Y.; Zhang, S.; Chen, K.; Wang, X. Devil’s whisper: A general approach for physical adversarial attacks against commercial black-box speech recognition devices. In Proceedings of the 29th {USENIX} Security Symposium ({USENIX} Security 20), Santa Clara, CA, USA, 12–14 August 2020; pp. 2667–2684. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Gong, Y.; Li, B.; Poellabauer, C.; Shi, Y. Real-time adversarial attacks. arXiv 2019, arXiv:1905.13399. [Google Scholar]
- Shen, J.; Nguyen, P.; Wu, Y.; Chen, Z.; Chen, M.X.; Jia, Y.; Kannan, A.; Sainath, T.; Cao, Y.; Chiu, C.C.; et al. Lingvo: A modular and scalable framework for sequence-to-sequence modeling. arXiv 2019, arXiv:1902.08295. [Google Scholar]
- Gong, T.; Ramos, A.G.C.; Bhattacharya, S.; Mathur, A.; Kawsar, F. AudiDoS: Real-Time Denial-of-Service Adversarial Attacks on Deep Audio Models. In Proceedings of the IEEE International Conference On Machine Learning And Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 978–985. [Google Scholar]
- Ishida, S.; Ono, S. Adjust-free adversarial example generation in speech recognition using evolutionary multi-objective optimization under black-box condition. Artif. Life Robot. 2021, 26, 243–249. [Google Scholar] [CrossRef]
- Heigold, G.; Moreno, I.; Bengio, S.; Shazeer, N. End-to-end text-dependent speaker verification. In Proceedings of the IEEE-ICASSP, Shanghai, China, 20–25 March 2016; pp. 5115–5119. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. X-Vectors: Robust DNN Embeddings for Speaker Recognition. In Proceedings of the IEEE-ICASSP, Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Chung, J.S.; Nagrani, A.; Zisserman, A. Voxceleb2: Deep speaker recognition. arXiv 2018, arXiv:1806.05622. [Google Scholar]
- Hansen, J.H.; Hasan, T. Speaker Recognition by Machines and Humans: A tutorial review. IEEE Signal Process. Mag. 2015, 32, 74–99. [Google Scholar] [CrossRef]
- Jati, A.; Georgiou, P. Neural predictive coding using convolutional neural networks toward unsupervised learning of speaker characteristics. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1577–1589. [Google Scholar] [CrossRef]
- Jati, A.; Hsu, C.C.; Pal, M.; Peri, R.; AbdAlmageed, W.; Narayanan, S. Adversarial attack and defense strategies for deep speaker recognition systems. Comput. Speech Lang. 2021, 68, 101199. [Google Scholar] [CrossRef]
- Kreuk, F.; Adi, Y.; Cisse, M.; Keshet, J. Fooling end-to-end speaker verification with adversarial examples. In Proceedings of the IEEE-ICASSP, Calgary, AB, Canada, 15–20 April 2018; pp. 1962–1966. [Google Scholar]
- Wang, Q.; Guo, P.; Sun, S.; Xie, L.; Hansen, J. Adversarial Regularization for End-to-End Robust Speaker Verification. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 4010–4014. [Google Scholar]
- Miyato, T.; Maeda, S.i.; Koyama, M.; Nakae, K.; Ishii, S. Distributional smoothing with virtual adversarial training. arXiv 2015, arXiv:1507.00677. [Google Scholar]
- Wang, Q.; Guo, P.; Xie, L. Inaudible adversarial perturbations for targeted attack in speaker recognition. arXiv 2020, arXiv:2005.10637. [Google Scholar]
- Li, X.; Zhong, J.; Wu, X.; Yu, J.; Liu, X.; Meng, H. Adversarial attacks on GMM i-vector based speaker verification systems. In Proceedings of the IEEE-ICASSP, Barcelona, Spain, 4–8 May 2020; pp. 6579–6583. [Google Scholar]
- Shamsabadi, A.S.; Teixeira, F.S.; Abad, A.; Raj, B.; Cavallaro, A.; Trancoso, I. FoolHD: Fooling Speaker Identification by Highly Imperceptible Adversarial Disturbances. In Proceedings of the IEEE-ICASSP, Toronto, ON, Canada, 6–11 June 2021; pp. 6159–6163. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Xie, Y.; Shi, C.; Li, Z.; Liu, J.; Chen, Y.; Yuan, B. Real-Time, Universal, and Robust Adversarial Attacks Against Speaker Recognition Systems. In Proceedings of the IEEE-ICASSP, Barcelona, Spain, 4–8 May 2020; pp. 1738–1742. [Google Scholar]
- Li, Z.; Shi, C.; Xie, Y.; Liu, J.; Yuan, B.; Chen, Y. Practical adversarial attacks against speaker recognition systems. In Proceedings of the International Workshop on Mobile Computing Systems and Applications, Austin, TX, USA, 3–4 March 2020; pp. 9–14. [Google Scholar]
- Chen, G.; Chen, S.; Fan, L.; Du, X.; Zhao, Z.; Song, F.; Liu, Y. Who is real bob? adversarial attacks on speaker recognition systems. arXiv 2019, arXiv:1911.01840. [Google Scholar]
- Zuo, F.; Luo, L.; Zeng, Q. Countermeasures Against L0 Adversarial Examples Using Image in Processing and Siamese Networks. arXiv 2018, arXiv:1812.09638. [Google Scholar]
- Raghunathan, A.; Steinhardt, J.; Liang, P. Certified defenses against adversarial examples. arXiv 2018, arXiv:1801.09344. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Yang, Z.; Li, B.; Chen, P.Y.; Song, D. Towards mitigating audio adversarial perturbations. In Proceedings of the ICLR 2018 Workshop Submission, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Yang, Z.; Li, B.; Chen, P.Y.; Song, D. Characterizing audio adversarial examples using temporal dependency. arXiv 2018, arXiv:1809.10875. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 274–283. [Google Scholar]
- Zeng, Q.; Su, J.; Fu, C.; Kayas, G.; Luo, L.; Du, X.; Tan, C.C.; Wu, J. A Multiversion Programming Inspired Approach to Detecting Audio Adversarial Examples. In Proceedings of the Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019. [Google Scholar]
- Kwon, H.; Yoon, H.; Park, K.W. POSTER: Detecting audio adversarial example through audio modification. In Proceedings of the ACM SIGSAC Conference on Computer and Communications Security, London, UK, 11–15 November 2019; pp. 2521–2523. [Google Scholar]
- Cisse, M.; Adi, Y.; Neverova, N.; Keshet, J. Houdini: Fooling deep structured prediction models. arXiv 2017, arXiv:1707.05373. [Google Scholar]
- Mozilla Common Voice (MVCD) Dataset2. Available online: https://commonvoice.mozilla.org/en/datasets (accessed on 16 May 2021).
- Campbell, J.P. Testing with the YOHO CD-ROM voice verification corpus. Proc. Int. Conf. Acoust. Speech Signal Process. 1995, 1, 341–344. [Google Scholar]
- Sainath, T.N.; Parada, C. Convolutional neural networks for small-footprint keyword spotting. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Li, J.B.; Qu, S.; Li, X.; Szurley, J.; Kolter, J.Z.; Metze, F. Adversarial music: Real world audio adversary against wake-word detection system. arXiv 2019, arXiv:1911.00126. [Google Scholar]
- Amazon Alex. Available online: https://developer.amazon.com/en-US/alexa (accessed on 8 May 2021).
- The LJ Speech Dataset. Available online: https://keithito.com/LJ-Speech-Dataset/ (accessed on 16 May 2021).
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the IEEE-ICASSP, South Brisbane, QL, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- The Talentedsoft. Available online: http://www.talentedsoft.com (accessed on 16 May 2021).
- Nagrani, A.; Chung, J.S.; Zisserman, A. Voxceleb: A large-scale speaker identification dataset. arXiv 2017, arXiv:1706.08612. [Google Scholar]
- Wan, L.; Wang, Q.; Papir, A.; Moreno, I.L. Generalized end-to-end loss for speaker verification. In Proceedings of the IEEE-ICASSP, Calgary, AB, Canada, 15–20 April 2018; pp. 4879–4883. [Google Scholar]
- Jankowski, C.; Kalyanswamy, A.; Basson, S.; Spitz, J. NTIMIT: A phonetically balanced, continuous speech, telephone bandwidth speech database. In Proceedings of the International Conference on Acoustics, Speech, and Signal in Processing, Albuquerque, NM, USA, 3–6 April 1990; pp. 109–112. [Google Scholar]
- Marras, M.; Korus, P.; Memon, N.D.; Fenu, G. Adversarial Optimization for Dictionary Attacks on Speaker Verification. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 2913–2917. [Google Scholar]
- Liu, X.; Wan, K.; Ding, Y.; Zhang, X.; Zhu, Q. Weighted-sampling audio adversarial example attack. Proc. AAAI Conf. Artif. Intell. 2020, 34, 4908–4915. [Google Scholar]
- Warden, P. Speech commands: A dataset for limited-vocabulary speech recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- Bu, H.; Du, J.; Na, X.; Wu, B.; Zheng, H. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline. In Proceedings of the Conference of the Oriental Chapter of the International Coordinating Committee on Speech Databases and Speech I/O Systems and Assessment (O-COCOSDA), Seoul, Korea, 1–3 November 2017; pp. 1–5. [Google Scholar]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Yamagishi, J.; Veaux, C.; MacDonald, K. CSTR VCTK Corpus: English Multi-Speaker Corpus for CSTR Voice Cloning Toolkit (Version 0.92); University of Edinburgh: Edinburgh, UK, 2019. [Google Scholar]
- Li, J.; Zhang, X.; Jia, C.; Xu, J.; Zhang, L.; Wang, Y.; Ma, S.; Gao, W. Universal adversarial perturbations generative network for speaker recognition. In Proceedings of the IEEE-ICASSP, Barcelona, Spain, 4–8 May 2020; pp. 1–6. [Google Scholar]
- Ravanelli, M.; Bengio, Y. Speaker recognition from raw waveform with sincnet. In Proceedings of the IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 1021–1028. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Apple’s Siri. Available online: https://www.apple.com/in/siri/ (accessed on 8 May 2021).
- Azure Speaker Identification API. Available online: https://azure.microsoft.com/en-us/services/cognitive-services/speaker-recognition/ (accessed on 8 May 2021).
- Samizade, S.; Tan, Z.H.; Shen, C.; Guan, X. Adversarial Example Detection by Classification for Deep Speech Recognition. In Proceedings of the IEEE-ICASSP, Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Jayashankar, T.; Roux, J.L.; Moulin, P. Detecting Audio Attacks on ASR Systems with Dropout Uncertainty. arXiv 2020, arXiv:2006.01906. [Google Scholar]
- Däubener, S.; Schönherr, L.; Fischer, A.; Kolossa, D. Detecting adversarial examples for speech recognition via uncertainty quantification. arXiv 2020, arXiv:2005.14611. [Google Scholar]
- Das, N.; Shanbhogue, M.; Chen, S.T.; Chen, L.; Kounavis, M.E.; Chau, D.H. Adagio: Interactive experimentation with adversarial attack and defense for audio. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; pp. 677–681. [Google Scholar]
- Wu, H.; Liu, S.; Meng, H.; Lee, H.y. Defense against adversarial attacks on spoofing countermeasures of ASV. In Proceedings of the IEEE-ICASSP, Barcelona, Spain, 4–8 May 2020; pp. 6564–6568. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Yang, C.H.; Qi, J.; Chen, P.Y.; Ma, X.; Lee, C.H. Characterizing speech adversarial examples using self-attention u-net enhancement. In Proceedings of the IEEE-ICASSP, Barcelona, Spain, 4–8 May 2020; pp. 3107–3111. [Google Scholar]
- Khare, S.; Aralikatte, R.; Mani, S. Adversarial black-box attacks on automatic speech recognition systems using multi-objective evolutionary optimization. arXiv 2018, arXiv:1811.01312. [Google Scholar]
- Pal, M.; Jati, A.; Peri, R.; Hsu, C.C.; AbdAlmageed, W.; Narayanan, S. Adversarial defense for deep speaker recognition using hybrid adversarial training. In Proceedings of the IEEE-ICASSP, Toronto, ON, Canada, 6–11 June 2021; pp. 6164–6168. [Google Scholar]
- Hussain, S.; Neekhara, P.; Dubnov, S.; McAuley, J.; Koushanfar, F. WaveGuard: Understanding and Mitigating Audio Adversarial Examples. In Proceedings of the 30th {USENIX} Security Symposium ({USENIX} Security 21), Virtual. 11–13 August 2021. [Google Scholar]
- Wu, H.; Li, X.; Liu, A.T.; Wu, Z.; Meng, H.; Lee, H.Y. Adversarial defense for automatic speaker verification by cascaded self-supervised learning models. In Proceedings of the IEEE-ICASSP, Toronto, ON, Canada, 6–11 June 2021; pp. 6718–6722. [Google Scholar]
- Liu, A.T.; Li, S.W.; Lee, H.y. Tera: Self-supervised learning of transformer encoder representation for speech. arXiv 2020, arXiv:2007.06028. [Google Scholar]
- Li, X.; Li, N.; Zhong, J.; Wu, X.; Liu, X.; Su, D.; Yu, D.; Meng, H. Investigating robustness of adversarial samples detection for automatic speaker verification. arXiv 2020, arXiv:2006.06186. [Google Scholar]
- Wang, X.; Sun, S.; Shan, C.; Hou, J.; Xie, L.; Li, S.; Lei, X. Adversarial Examples for Improving End-to-end Attention-based Small-footprint Keyword Spotting. In Proceedings of the IEEE-ICASSP, Brighton, UK, 12–17 May 2019; pp. 6366–6370. [Google Scholar]


| Work | Year | Box | Target | Platform | Corpus | System | Real/Simulated | Feature |
|---|---|---|---|---|---|---|---|---|
| [63] | 2017 | Black/White | Both | DeepSpeech2 | Librispeech | ASR | Simulated | STFT |
| [28] | 2018 | White | Targeted | DeepSpeech | MCVD [64] | ASR | Simulated | Waveform |
| [19] | 2018 | White | non-target | Kaldi | Random choice | ASR | Both | Waveform |
| [45] | 2018 | White | Targeted | ASV | YOHO [65] | ASV | Simulated | MFCC |
| [32] | 2018 | White | Targeted | Deepspeech | Music Clips | ASR | Real | waveform |
| [13] | 2018 | Black | non-target | CNNs [66] | Speech commands | ASR | Simulated | Waveform |
| [29] | 2018 | White | Targeted | Kaldi | WSJ | ASR | Simulated | STFT |
| [45] | 2018 | White | non-target | SVs [39] | YOHO [65] | ASV | Simulated | MFCC/Mel-Spectrum |
| [14] | 2019 | Black | targeted | DeepSpeech | MCVD | ASR | Simulated | Waveform |
| [15] | 2019 | Grey | non-target | Kaldi | TTSREADER | ASR | Simulated | Waveform |
| [67] | 2019 | Grey | Both | Alexa [68] | LJ [69] | VAs | Both | Waveform |
| [30] | 2019 | White | Targeted | Lingvo [36] | Librispeech [70] | ASR | Simulated | Waveform |
| [37] | 2019 | White | non-target | DeepSpeech | Librispeech | ASR | Simulated | Waveform |
| [54] | 2019 | Black | Targeted | Talentedsoft [71] | Voxceleb1 [70,72] | SRS | Real | Waveform |
| [46] | 2019 | White | non-target | SVs [73] | NTIMIT [74] | ASV | Simulated | feature |
| [75] | 2019 | White | Targeted | VGGVox [72] | Voxceleb | SRS | Simulated | Spectrogram |
| [76] | 2020 | White | non-target | CTC-based [66] | MCVD | ASR | Simulated | MFCC |
| [52] | 2020 | Grey | non-target | VCs [66] | Speech commands [77] | VCs | Simulated | Waveform |
| [33] | 2020 | Black | Targeted | Alex, Google, Cortana | CommanderSong [19] | ASR | Real | Spectrum |
| [48] | 2020 | White | Targeted | DNNs [40] | Aishell-1 [78] | SRS | Simulated | Waveform |
| [49] | 2020 | Both | non-target | SVs [79] | Voxceleb1 | ASV | Simulated | MFCC |
| [53] | 2020 | White | Both | Kaldi | CSTR VCTK [80] | SRS | Both | MFCC |
| [52] | 2020 | White | non-target | DNNs [40] | CSTR VCTK | SRS | Simulated | MFCC |
| [81] | 2020 | Gray | Targeted | SincNet [82] | NTIMIT/Librispeech | SRS | Simulated | Waveform |
| [50] | 2021 | White | Both | DNNs [40] | Voxceleb | SRS | Simulated | Waveform |
| [38] | 2021 | Black | Targeted | CNNs | Speech Command [66] | VCs | Simulated | MFCC |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Li, S.; Huang, H. Adversarial Attack and Defense on Deep Neural Network-Based Voice Processing Systems: An Overview. Appl. Sci. 2021, 11, 8450. https://doi.org/10.3390/app11188450
Chen X, Li S, Huang H. Adversarial Attack and Defense on Deep Neural Network-Based Voice Processing Systems: An Overview. Applied Sciences. 2021; 11(18):8450. https://doi.org/10.3390/app11188450
Chicago/Turabian StyleChen, Xiaojiao, Sheng Li, and Hao Huang. 2021. "Adversarial Attack and Defense on Deep Neural Network-Based Voice Processing Systems: An Overview" Applied Sciences 11, no. 18: 8450. https://doi.org/10.3390/app11188450
APA StyleChen, X., Li, S., & Huang, H. (2021). Adversarial Attack and Defense on Deep Neural Network-Based Voice Processing Systems: An Overview. Applied Sciences, 11(18), 8450. https://doi.org/10.3390/app11188450