
Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid


Abstract
:1. Introduction
- A lightweight pyramid-structured object detection network with few parameters is proposed. Although it uses fewer channels than the existing pyramid structure, it is possible to efficiently extract features with a structure that repeats the number of times. In addition, it is designed to suppress unnecessary feature information by adding a feature refining process in the pyramid structure.
- The one-stage detection method uses a prior box because it detects each feature map grid. In this paper, we redesigned the prior box to be robust to small and large objects.
- Based on the ESDet-baseline, the experiment was conducted by expanding and reducing the network. It proves that the proposed network architecture can be used universally. It can be extended and used for tasks that require accuracy. When applied to mobile applications, it reports the efficiency that can be scaled down.
2. Related Works
2.1. Lightweight Backbone Networks
2.2. Weight Quantization
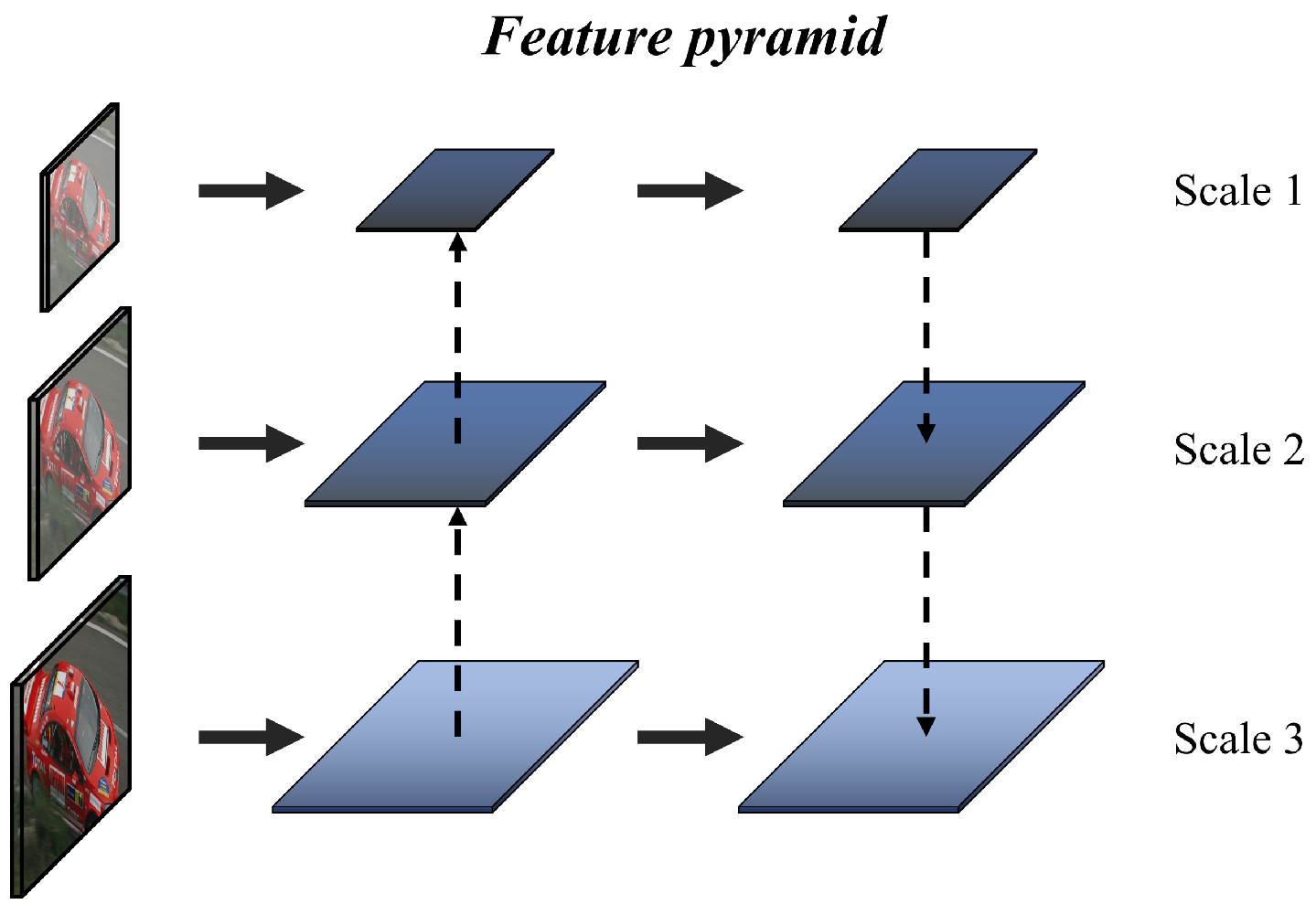
2.3. Feature Pyramid
3. Proposed Method
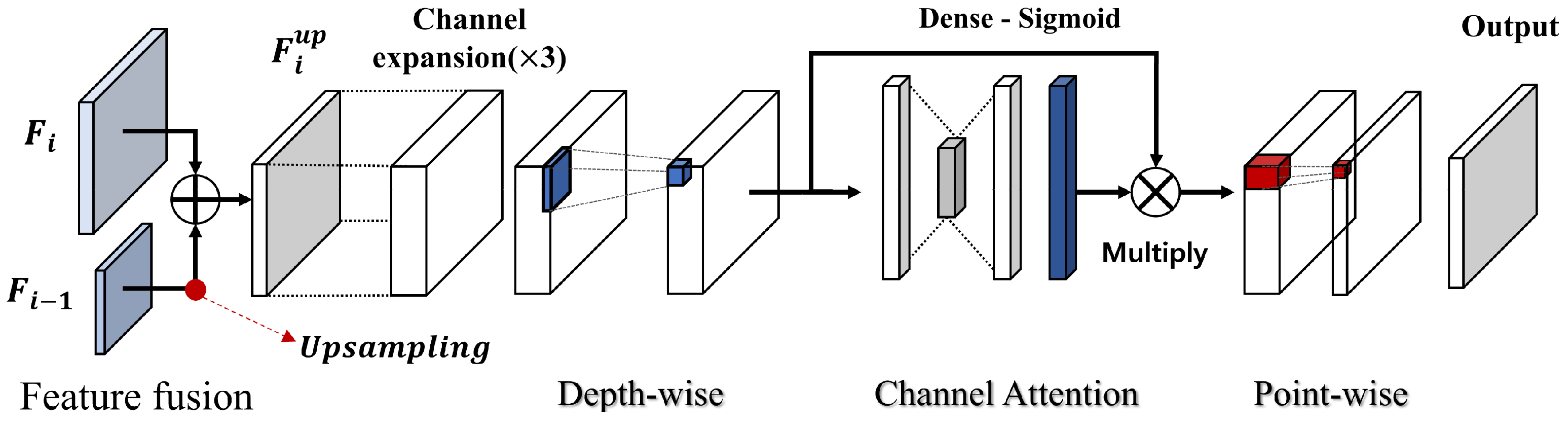
3.1. Network Architecture
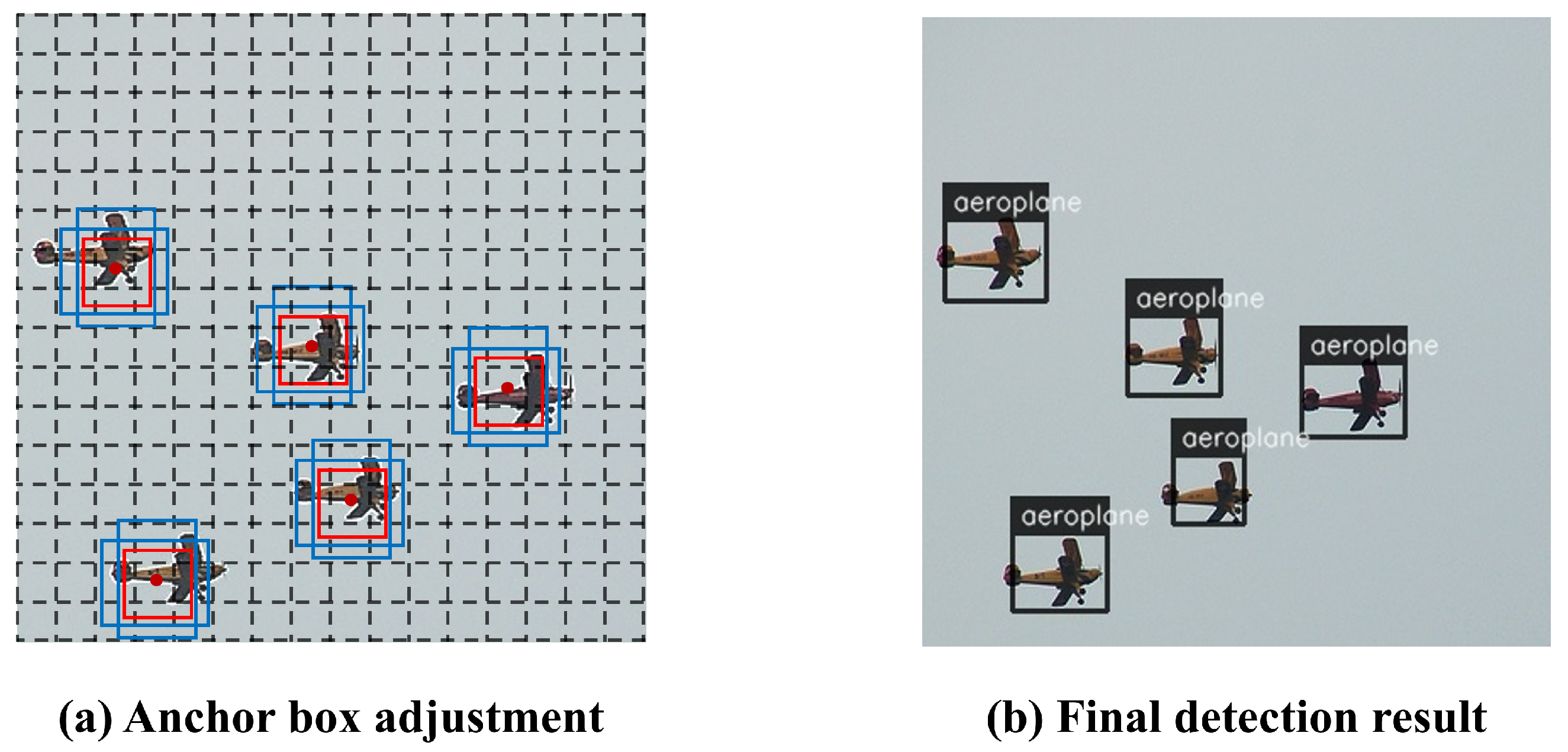
3.2. Prior Anchor Box Design
3.3. Loss Function
4. Experiment Results
4.1. Data Sets
4.2. Evaluation Metrics
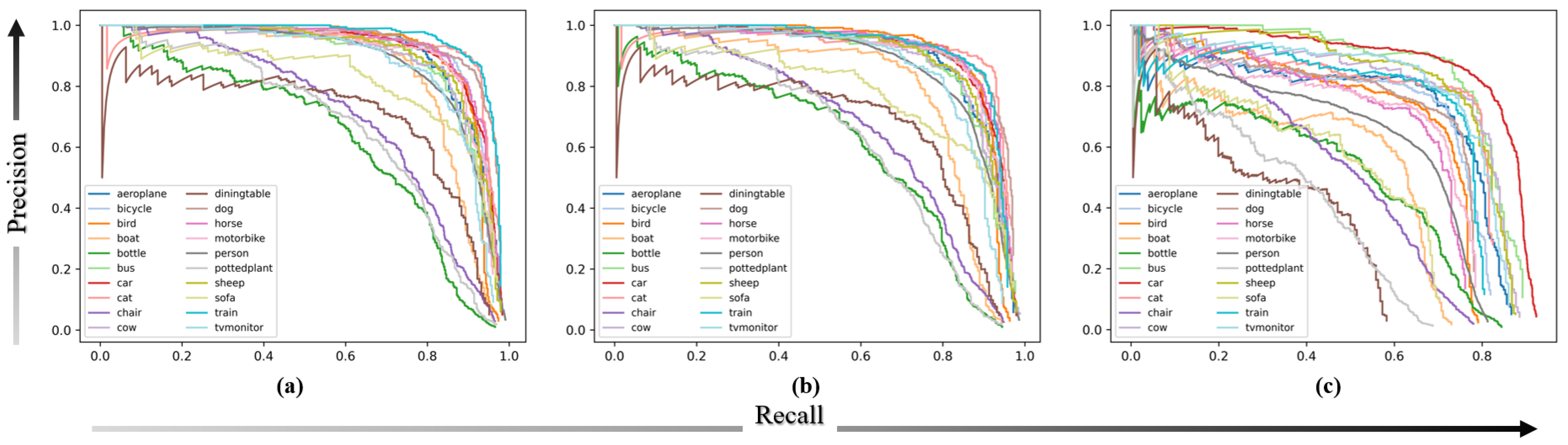
4.3. Comparison to Other Networks
4.4. PASCAL VOC and MS COCO Datasets Detections Results
4.5. Ablation Study
4.5.1. Network Extension
4.5.2. Network Compression
4.5.3. Refining Process Test
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lee, Y.; Park, S. A deep learning-based perception algorithm using 3d lidar for autonomous driving: Simultaneous segmentation and detection network (SSADNet). Appl. Sci. 2020, 10, 4486. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, Y.; Zheng, Z.; Ma, A.; Zhang, L. RSNet: The Search for Remote Sensing Deep Neural Networks in Recognition Tasks. IEEE Trans. Geosci. Remote Sens. 2021, 59, 2520–2534. [Google Scholar] [CrossRef]
- Shao, L.; Zhang, E.; Li, M. An efficient convolutional neural network model combined with attention mechanism for inverse halftoning. Electronics 2021, 10, 1574. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Juan, PR, USA , 17–19 June 1997 ; pp. 1251–1258. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A Survey of the State-of-the-Art. 2019. Available online: https://arxiv.org/abs/1908.00709 (accessed on 2 August 2019). [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. 2020. Available online: https://link.springer.com/chapter/10.1007/978-3-030-58452-8_13 (accessed on 26 May 2020).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Steen, M.; Downe, S.; Bamford, N.; Edozien, L. DenseNet:Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993v5. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. 2017. Available online: https://arxiv.org/abs/1704.04861 (accessed on 17 April 2017).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. Ieee Cvpr 2017. pp. 770–778. Available online: https://arxiv.org/abs/1703.06870 (accessed on 20 March 2017).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. 2018. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. 2015, pp. 21–37. Available online: https://arxiv.org/abs/1512.02325 (accessed on 8 December 2015). [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2019. Available online: https://arxiv.org/abs/1905.11946 (accessed on 28 May 2019).
- Li, X.; Lai, T.; Wang, S.; Chen, Q.; Yang, C.; Chen, R. Feature Pyramid Network. In Proceedings of the 2019 IEEE International Conference Parallel Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; pp. 1500–1504. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Zurich, Switzerland, 6–12 September 2014; pp. 3686–3693. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-end training of object class detectors for mean average precision. Encycl. Database Syst. 2016, 1703. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Biol. Conserv. 2015, 158, 196–204. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-based Object Detectors with Online Hard Example Mining. 2016. Available online: https://arxiv.org/abs/1604.03540 (accessed on 12 April 2016).
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. HyperNet: Towards Accurate Region Proposal Generation and Joint Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; Volume 2016, pp. 845–853. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. Neural Netw. Stat. Learn. 2015, 8, 337–353. [Google Scholar]
- Gidaris, S.; Komodakis, N. Object detection via a multi-region & semantic segmentation-aware CNN model. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1134–1142. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. Adv. Neural Inf. Process. Syst. 2016. Available online: https://arxiv.org/abs/1605.06409 (accessed on 20 May 2016).
- Zhu, Y.; Zhao, C.; Wang, J.; Zhao, X.; Wu, Y.; Lu, H. CoupleNet: Coupling Global Structure with Local Parts for Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4146–4154. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. RON: Reverse connection with objectness prior networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5936–5944. [Google Scholar] [CrossRef] [Green Version]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. 2017. Available online: https://arxiv.org/abs/1701.06659 (accessed on 23 January 2017).
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 6517–6525. [Google Scholar]
- Cao, J.; Pang, Y.; Han, J.; Li, X. Hierarchical Shot Detector. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; Volume 2019, pp. 9704–9713. [Google Scholar]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Freebies for Training Object Detection Neural Networks. 2019. Available online: https://arxiv.org/abs/1902.04103 (accessed on 11 February 2019).
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. 2017. Available online: https://arxiv.org/abs/1711.06897 (accessed on 18 November 2017).
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Con-ference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10778–10787. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. Adv. Neural Inf. Process. Syst. 2018, 2018, 9310–9320. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.-Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation. 2020. Available online: https://arxiv.org/abs/2012.07177 (accessed on 13 December 2020).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Head | Input Resolution | Channels | Filter Size/Times |
|---|---|---|---|
| S1 | 40 | ||
| S2 | 80 | ||
| S3 | 112 | ||
| S4 | 64 | ||
| S5 | 64 |
| Index | Feature Size | Shrinkage | ||
|---|---|---|---|---|
| 1 | 64 | 15 | 31 | 8 |
| 2 | 32 | 40 | 82 | 16 |
| 3 | 16 | 92 | 184 | 32 |
| 4 | 8 | 194 | 228 | 64 |
| 5 | 4 | 310 | 386 | 128 |
| Detector | Input Resolution | Proposals | Pyramid Times/Channel | Params (M) |
|---|---|---|---|---|
| ESDet-Baseline | 16,368 | 3/64 | 3.81 M | |
| ESDet-B1 | 18,447 | 4/88 | 6.64 M | |
| ESDet-B2 | 20,652 | 5/112 | 8.08 M | |
| ESDet-B3 | 23,061 | 6/160 | 11.91 M | |
| ESDet-B4 | 25,518 | 7/224 | 20.42 M | |
| ESDet-B5 | 28,158 | 7/288 | 33.10 M | |
| ESDet-B6 | 30,867 | 7/288 | 45.34 M | |
| ESDet-B7 | 33,798 | 7/288 | 68.24 M |
| Detector | Backbone | Input Resolution | Proposals | FPS | mAP (%) |
|---|---|---|---|---|---|
| Two-stage | |||||
| Fast R-CNN [20] | VGG-16 | ∼1000 × 600 | 2000 | 0.5 | 70.0 |
| Faster R-CNN [21] | VGG-16 | ∼1000 × 600 | 300 | 7 | 73.2 |
| OHEM [22] | VGG-16 | ∼1000 × 600 | 300 | 7 | 74.6 |
| HyperNet [23] | VGG-16 | ∼1000 × 600 | 100 | 0.88 | 76.3 |
| Faster R-CNN [21] | ResNet-101 | ∼1000 × 600 | 300 | 2.4 | 76.4 |
| ION [24] | VGG-16 | ∼1000 × 600 | 4000 | 1.25 | 76.5 |
| MR-CNN [25] | VGG-16 | ∼1000 × 600 | 250 | 0.03 | 78.2 |
| R-FCN [26] | ResNet-101 | ∼1000 × 600 | 300 | 9 | 80.5 |
| CoupleNet [27] | ResNet-101 | ∼1000 × 600 | 300 | 8.2 | 82.7 |
| One-stage | |||||
| YOLO [28] | GoogleNet | 448 × 448 | 98 | 45 | 63.4 |
| RON [29] | VGG-16 | 384 × 384 | 30,600 | 15 | 75.4 |
| SSD321 [30] | Resnet-101 | 321 × 321 | 17,080 | 11.2 | 77.1 |
| SSD300 [12] | VGG-16 | 300 × 300 | 8732 | 46 | 77.2 |
| YOLOv2 [31] | Darknet-19 | 544 × 544 | 845 | 40 | 78.6 |
| DSSD321 [30] | Resnet-101 | 321 × 321 | 17,080 | 9.5 | 78.6 |
| SSD512 [12] | VGG-16 | 512 × 512 | 24,564 | 19 | 79.8 |
| SSD512 [30] | Resnet-101 | 513 × 513 | 43,688 | 6.8 | 80.6 |
| DSSD513 [30] | Resnet-101 | 513 × 513 | 43,688 | 5.5 | 81.5 |
| HSD512 [32] | VGG-16 | 512 × 512 | - | - | 83.0 |
| YOLOv3 + mixup [33] | Darknet-53 | 416 × 416 | 10,647 | 34.5 | 83.6 |
| RefineDet512+ [34] | VGG-16 | 512 × 512 | 16,320 | 24.1 | 83.8 |
| ESDet-baseline | EfficientNet-B0 | 512 × 512 | 16,368 | 99 | 81.9 |
| Detector | Backbone | Input Resolution | AP | AP50 | AP75 | FPS | Params (M) |
|---|---|---|---|---|---|---|---|
| YOLOv3 [11] | Darknet-53 | 608 × 608 | 33.0 | 57.9 | 34.4 | 20 | 65.2 |
| EfficientDet-D0 [35] | EfficientNet-B0 | 512 × 512 | 34.6 | 53.0 | 37.1 | 97 | 3.9 |
| ESDet-baseline | EfficientNet-B0 | 512 × 512 | 35.1 | 55.2 | 38.2 | 99 | 3.81 |
| aero | bike | bird | boat | bottle | bus | car | cat | chair | cow |
|---|---|---|---|---|---|---|---|---|---|
| 86.5 | 87.5 | 87.8 | 80.9 | 62.3 | 85.4 | 87.2 | 88.4 | 68.8 | 84.5 |
| table | dog | horse | mbike | person | plant | sheep | sofa | train | tv |
| 69.0 | 88.3 | 87.9 | 86.2 | 83.8 | 66.1 | 85.9 | 78.2 | 89.5 | 83.8 |
| Detector | Input Resolution | mAP (%) |
|---|---|---|
| ESDet-B1 (with EfficientNet-B1) | 512 × 512 | 83.6 |
| ESDet-B2 (with EfficientNet-B2) | 576 × 576 | 84.2 |
| ESDet-B3 (with EfficientNet-B3) | 608 × 608 | 85.1 |
| ESDet-B4 (with EfficientNet-B4) | 640 × 640 | 85.6 |
| ESDet-B5 (with EfficientNet-B5) | 672 × 672 | 86.1 |
| ESDet-B6 (with EfficientNet-B6) | 704 × 704 | 86.4 |
| SNIPER [36] * | ∼1000 × 600 | 86.9 |
| ESDet-B7 (with EfficientNet-B7) | 736 × 736 | 87.1 |
| Cascade Eff-B7 NAS-FPN [37] * | - | 89.3 |
| Detector | Input Resolution | Proposals | Params (M) | mAP (%) |
|---|---|---|---|---|
| ESDet-baseline | 512 × 512 | 16,368 | 3.81 | 81.9 |
| SSD | 300 × 300 | 8732 | 36.1 | 77.2 |
| Tiny SSD | 300 × 300 | - | 1.13 | 61.3 |
| ESDet-tiny | 300 × 300 | 5817 | 3.59 | 76.9 |
| Method | mAP (%) |
|---|---|
| w/o refining | 80.1 |
| apply to S2 scale | 80.8 |
| apply to S2 and S3 scales | 81.3 |
| apply all scales | 81.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, C.; Lee, S.; Han, H. Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid. Appl. Sci. 2021, 11, 8692. https://doi.org/10.3390/app11188692
Park C, Lee S, Han H. Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid. Applied Sciences. 2021; 11(18):8692. https://doi.org/10.3390/app11188692
Chicago/Turabian StylePark, Chansoo, Sanghun Lee, and Hyunho Han. 2021. "Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid" Applied Sciences 11, no. 18: 8692. https://doi.org/10.3390/app11188692
APA StylePark, C., Lee, S., & Han, H. (2021). Efficient Shot Detector: Lightweight Network Based on Deep Learning Using Feature Pyramid. Applied Sciences, 11(18), 8692. https://doi.org/10.3390/app11188692