
Auxiliary Information-Enhanced Recommendations


Abstract
:1. Introduction
- We propose a memory fusion network for recommendation (MFN4Rec) to effectively model auxiliary multi-modal information for accurate sequential recommendations.
- A multi-GRU layer is designed to effectively model the sequential dependencies with each modality.
- A multi-view gated memory network (MGMN) is particularly devised to effectively model the complex interaction relations across different modalities.
2. Related Work
2.1. Sequential Recommendation Algorithms
2.2. Auxiliary Information-Enhanced Sequential Recommendations
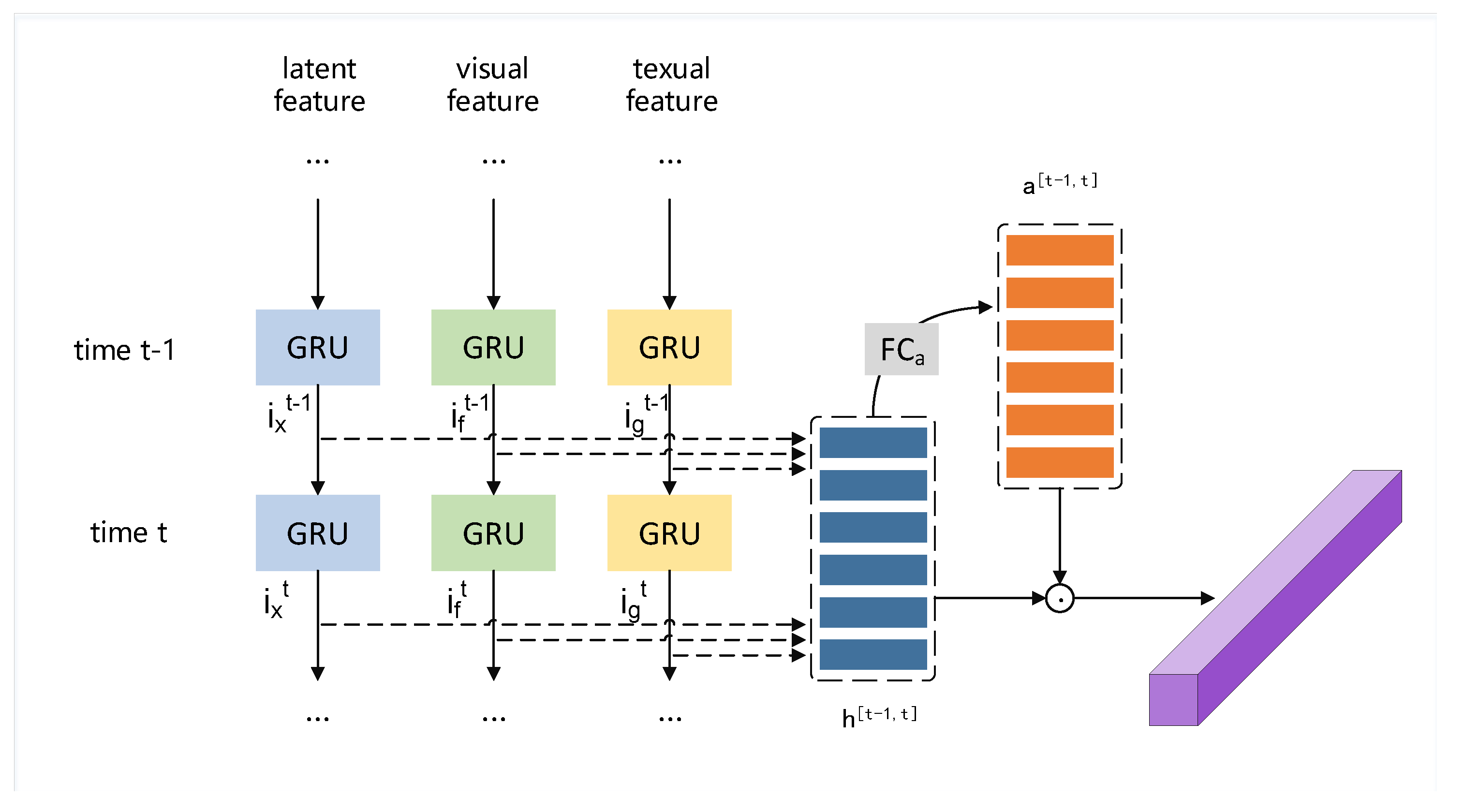
3. The Proposed SRS Algorithm
3.1. Multi-GRU Layer
3.2. Differentiated Attention Layer
3.3. Gated Multi-Modal Memory Network
3.4. Prediction and Optimization
4. Experiments
4.1. Data Preparation and Experiment Set Up
4.2. Performance Comparison with Baselines
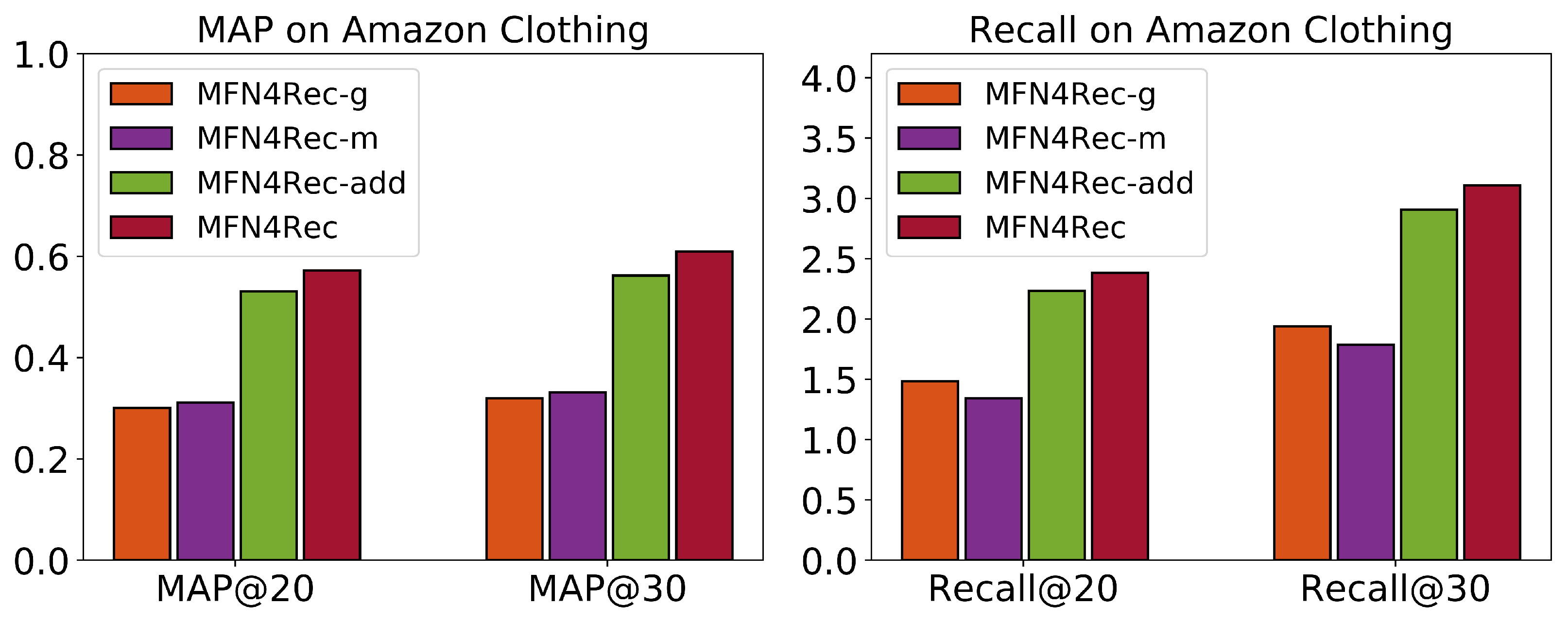
4.3. Ablation Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qu, T.; Wan, W.; Wang, S. Visual content-enhanced sequential recommendation with feature-level attention. Neurocomputing 2021, 443, 262–271. [Google Scholar] [CrossRef]
- Hidasi, B.; Quadrana, M.; Karatzoglou, A.; Tikk, D. Parallel recurrent neural network architectures for feature-rich session-based recommendations. In Proceedings of the Tenth ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 241–248. [Google Scholar]
- Cui, Q.; Wu, S.; Liu, Q.; Zhong, W.; Wang, L. MV-RNN: A multi-view recurrent neural network for sequential recommendation. IEEE Trans. Knowl. Data Eng. 2020, 32, 317–331. [Google Scholar] [CrossRef] [Green Version]
- Zadeh, A.; Liang, P.P.; Mazumder, N.; Poria, S.; Cambria, E.; Morency, L.P. Memory fusion network for multi-view sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Yap, G.E.; Li, X.L.; Philip, S.Y. Effective next-items recommendation via personalized sequential pattern mining. In Proceedings of the Seventeenth International Conference on Database Systems for Advanced Applications, Busan, Korea, 15–19 April 2012; pp. 48–64. [Google Scholar]
- Feng, S.; Li, X.; Zeng, Y.; Cong, G.; Chee, Y.M.; Yuan, Q. Personalized ranking metric embedding for next new POI recommendation. In Proceedings of the Twenty Fourth International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2069–2075. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the Nineteenth International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. In Proceedings of the Fourth International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; pp. 1–10. [Google Scholar]
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Turin, Italy, 22–26 October 2018; pp. 843–852. [Google Scholar]
- Wu, C.Y.; Ahmed, A.; Beutel, A.; Smola, A.J.; Jing, H. Recurrent recommender networks. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 495–503. [Google Scholar]
- Quadrana, M.; Karatzoglou, A.; Hidasi, B.; Cremonesi, P. Personalizing session-based recommendations with hierarchical recurrent neural networks. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 130–137. [Google Scholar]
- Wang, S.; Hu, L.; Cao, L.; Huang, X.; Lian, D.; Liu, W. Attention-based transactional context embedding for next-item recommendation. In Proceedings of the Thirty Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 2532–2539. [Google Scholar]
- Tang, J.; Wang, K. Personalized top-n sequential recommendation via convolutional sequence embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; pp. 565–573. [Google Scholar]
- Tuan, T.X.; Phuong, T.M. 3D convolutional networks for session-based recommendation with content features. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 138–146. [Google Scholar]
- Ma, C.; Ma, L.; Zhang, Y.; Sun, J.; Liu, X.; Coates, M. Memory augmented graph neural networks for sequential recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5045–5052. [Google Scholar]
- Hsu, C.; Li, C.T. RetaGNN: Relational Temporal Attentive Graph Neural Networks for Holistic Sequential Recommendation. In Proceedings of the Web Conference 2021, Virtual, 19–23 April 2021; pp. 2968–2979. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar]
- Zhang, T.; Zhao, P.; Liu, Y.; Sheng, V.S.; Xu, J.; Wang, D.; Liu, G.; Zhou, X. Feature-level Deeper Self-Attention Network for Sequential Recommendation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4320–4326. [Google Scholar]
- Ren, R.; Liu, Z.; Li, Y.; Zhao, W.X.; Wang, H.; Ding, B.; Wen, J.R. Sequential recommendation with self-attentive multi-adversarial network. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 89–98. [Google Scholar]
- Wang, S.; Hu, L.; Cao, L. Perceiving the next choice with comprehensive transaction embeddings for online recommendation. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Skopje, Macedonia, 18–22 September 2017; pp. 285–302. [Google Scholar]
- Garg, D.; Gupta, P.; Malhotra, P.; Vig, L.; Shroff, G. Sequence and time aware neighborhood for session-based recommendations: Stan. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 1069–1072. [Google Scholar]
- Li, J.; Wang, Y.; McAuley, J. Time interval aware self-attention for sequential recommendation. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 322–330. [Google Scholar]
- Ye, W.; Wang, S.; Chen, X.; Wang, X.; Qin, Z.; Yin, D. Time Matters: Sequential Recommendation with Complex Temporal Information. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 1459–1468. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the Twenty Eighth IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2414–2423. [Google Scholar]
- Tang, J.; Belletti, F.; Jain, S.; Chen, M.; Beutel, A.; Xu, C.; Chi, E.H. Towards neural mixture recommender for long range dependent user sequences. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 1782–1793. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 28, 649–657. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian personalized ranking from implicit feedback. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; pp. 452–461. [Google Scholar]
- Yu, F.; Liu, Q.; Wu, S.; Wang, L.; Tan, T. A dynamic recurrent model for next basket recommendation. In Proceedings of the Thirty Ninth International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 729–732. [Google Scholar]
- He, R.; McAuley, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 144–150. [Google Scholar]



{kind=link}
{kind=link}
| Fully Connected Layer | Input Dimension | Hidden State Dimension | Output Dimension | Dropout Rate |
|---|---|---|---|---|
| no | 0.3 | |||
| 50 | 20 | 0.3 | ||
| 50 | 20 | 0.3 | ||
| 50 | 20 | 0.3 | ||
| no | 20 | 0.3 |
| Dataset | # Items | # Users | # Interactions | # Items per User on Average |
|---|---|---|---|---|
| Amazon Clothing | 38,840 | 22,586 | 272,949 | 12.08 |
| Amazon Phone | 27,879 | 10,429 | 175,645 | 16.84 |
| Algorithm | Recall@20 | MAP@20 | Recall@30 | MAP@30 |
|---|---|---|---|---|
| BPR | 0.641 | 0.168 | 0.812 | 0.176 |
| VBPR | 0.700 | 0.181 | 0.922 | 0.190 |
| LSTM | 1.443 | 0.283 | 1.982 | 0.301 |
| p-RNN | 1.484 | 0.301 | 1.939 | 0.320 |
| MV-RNN(Con) | 2.113 | 0.522 | 2.827 | 0.554 |
| MV-RNN(Fus) | 2.157 | 0.508 | 2.867 | 0.538 |
| MV-RNN(3mDAE) | 2.243 | 0.541 | 2.995 | 0.570 |
| VCSRS | 2.238 | 0.537 | 2.992 | 0.574 |
| MFN4Rec(ours) | 2.384 | 0.572 | 3.111 | 0.609 |
| Algorithm | Recall@20 | MAP@20 | Recall@30 | MAP@30 |
|---|---|---|---|---|
| BPR | 4.6398 | 1.5384 | 7.6127 | 1.7624 |
| VBPR | 4.6410 | 1.5438 | 7.6136 | 1.7723 |
| LSTM | 6.7616 | 1.7227 | 8.9707 | 1.8208 |
| p-RNN | 6.8645 | 1.9688 | 8.8463 | 1.8347 |
| MV-RNN(Con) | 6.5580 | 1.7509 | 8.0625 | 1.8739 |
| MV-RNN(Fus) | 6.8783 | 1.8133 | 8.2881 | 1.8764 |
| MV-RNN(3mDAE) | 6.1330 | 1.4085 | 8.0270 | 1.8469 |
| VCSRS | 6.8742 | 1.9904 | 9.0214 | 1.8726 |
| MFN4Rec(ours) | 7.6629 | 2.2697 | 9.7815 | 2.3709 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Wan, W.; Qu, T.; Dong, Y. Auxiliary Information-Enhanced Recommendations. Appl. Sci. 2021, 11, 8830. https://doi.org/10.3390/app11198830
Wang S, Wan W, Qu T, Dong Y. Auxiliary Information-Enhanced Recommendations. Applied Sciences. 2021; 11(19):8830. https://doi.org/10.3390/app11198830
Chicago/Turabian StyleWang, Shoujin, Wanggen Wan, Tong Qu, and Yanqiu Dong. 2021. "Auxiliary Information-Enhanced Recommendations" Applied Sciences 11, no. 19: 8830. https://doi.org/10.3390/app11198830
APA StyleWang, S., Wan, W., Qu, T., & Dong, Y. (2021). Auxiliary Information-Enhanced Recommendations. Applied Sciences, 11(19), 8830. https://doi.org/10.3390/app11198830