
Improving Transformer Based End-to-End Code-Switching Speech Recognition Using Language Identification


Abstract
:1. Introduction
2. Related Work
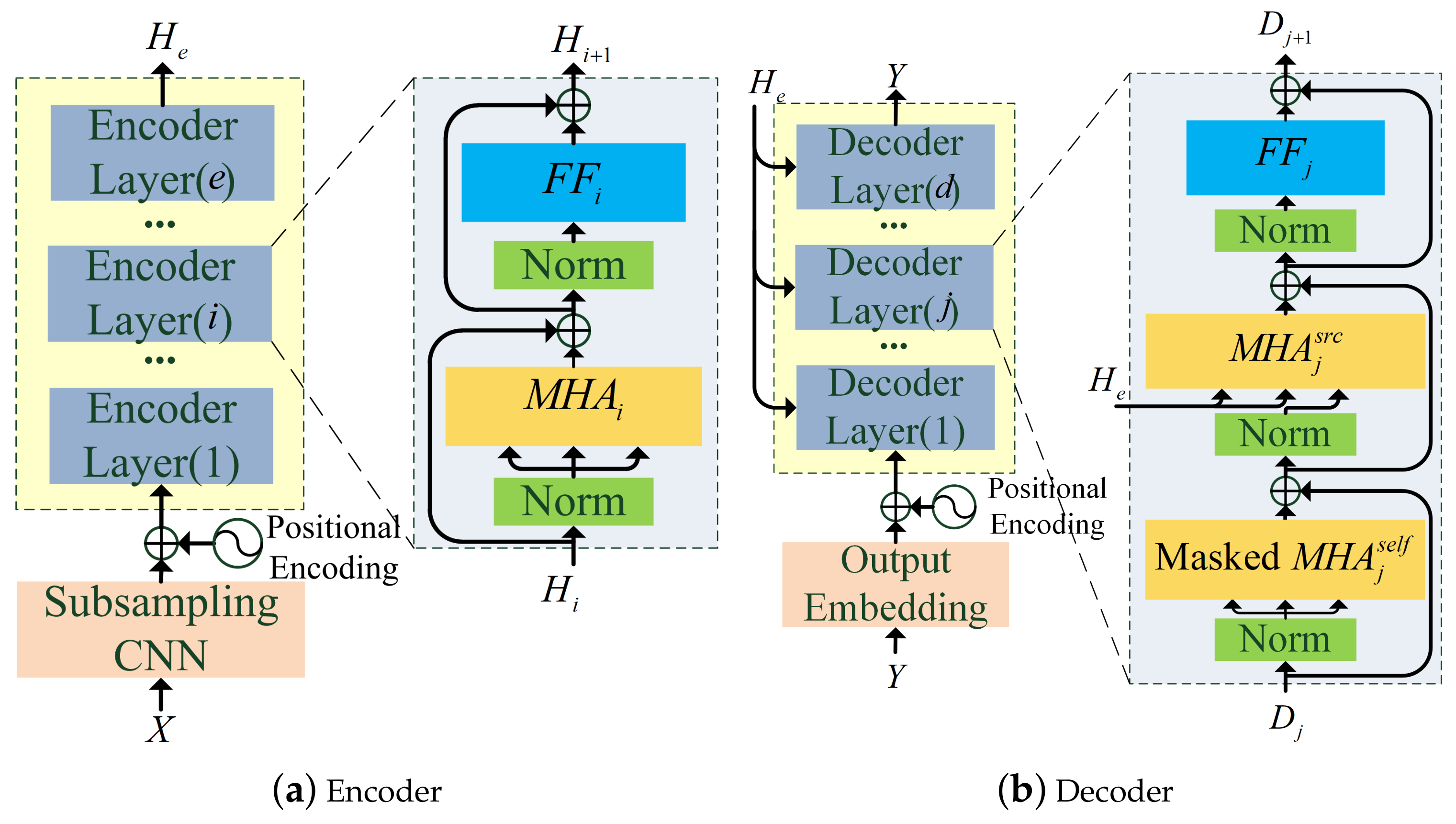
2.1. Transformer Based E2E Architecture
2.2. Self-Attention
3. Methods
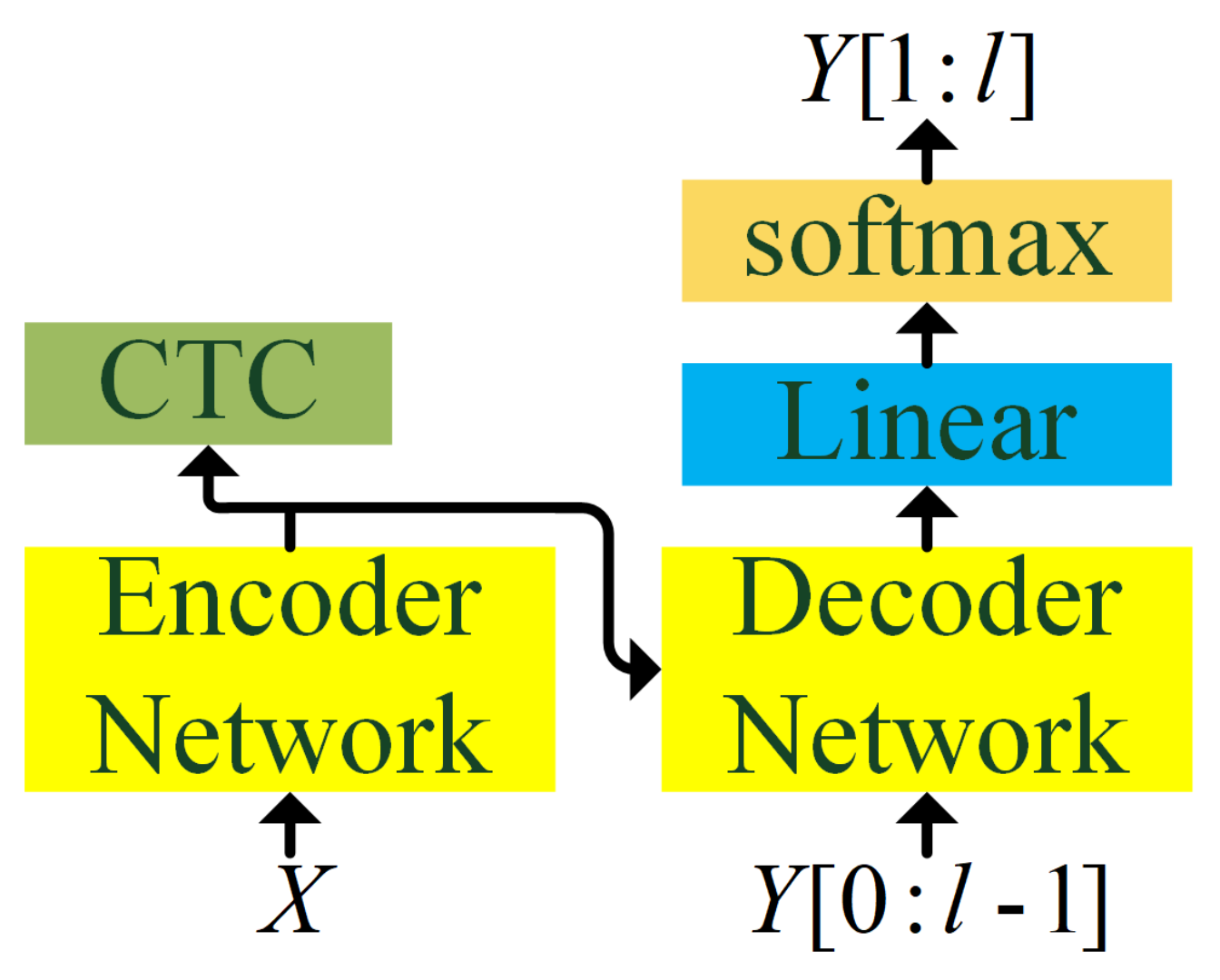
3.1. CTC-Transformer Based CSSR Baseline System
3.2. CSSR Multi-Task Learning with LID
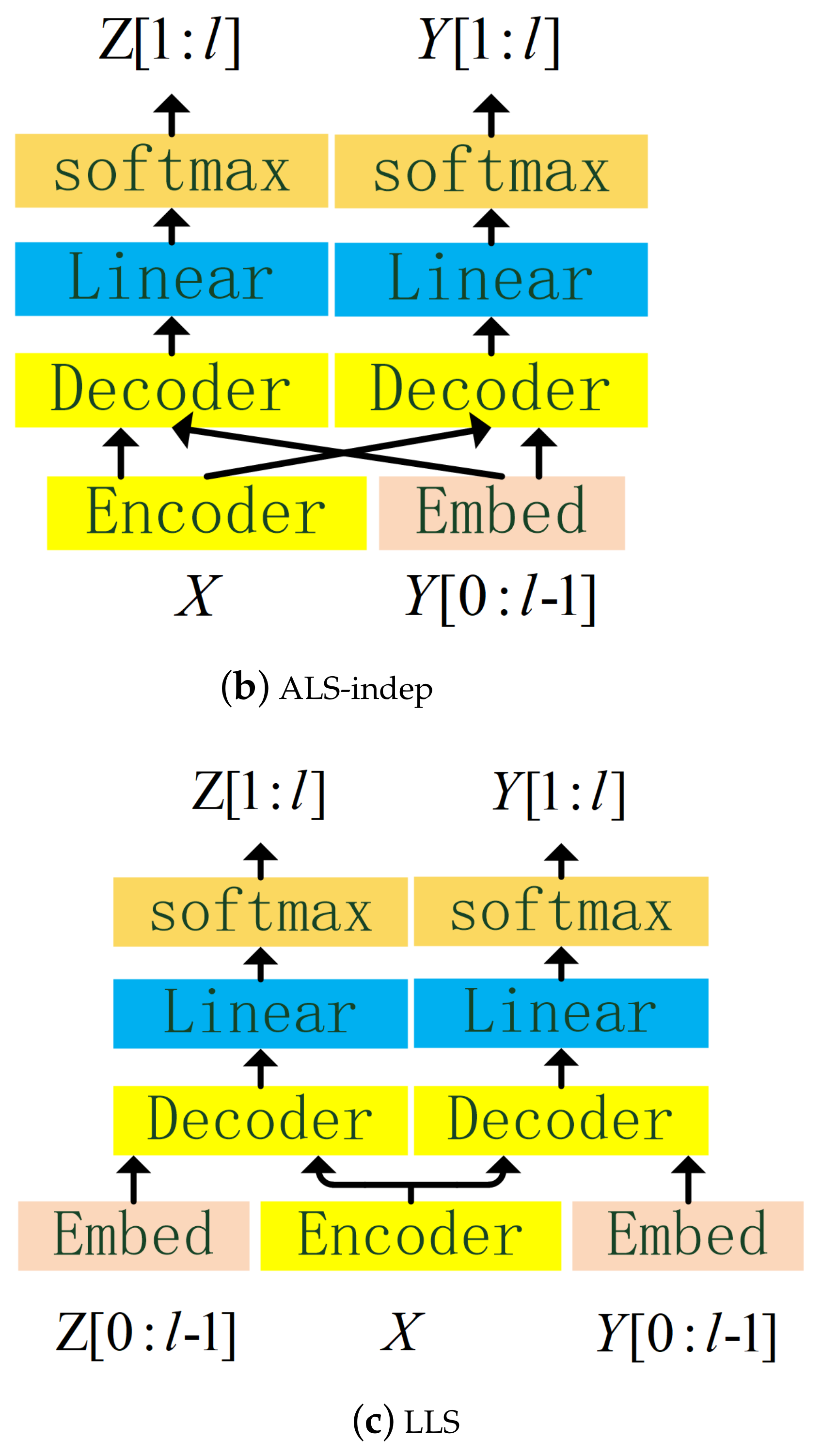
- LID label sequence (LLS): as indicated in Figure 4a, the LID predictor receives the encoded features and the LID label sequence to predict . The LID predictor does not share the embedding layer with ASR predictor, and it has its own embedding layer:transforms a sequence of labels into a sequence of learnable vectors .
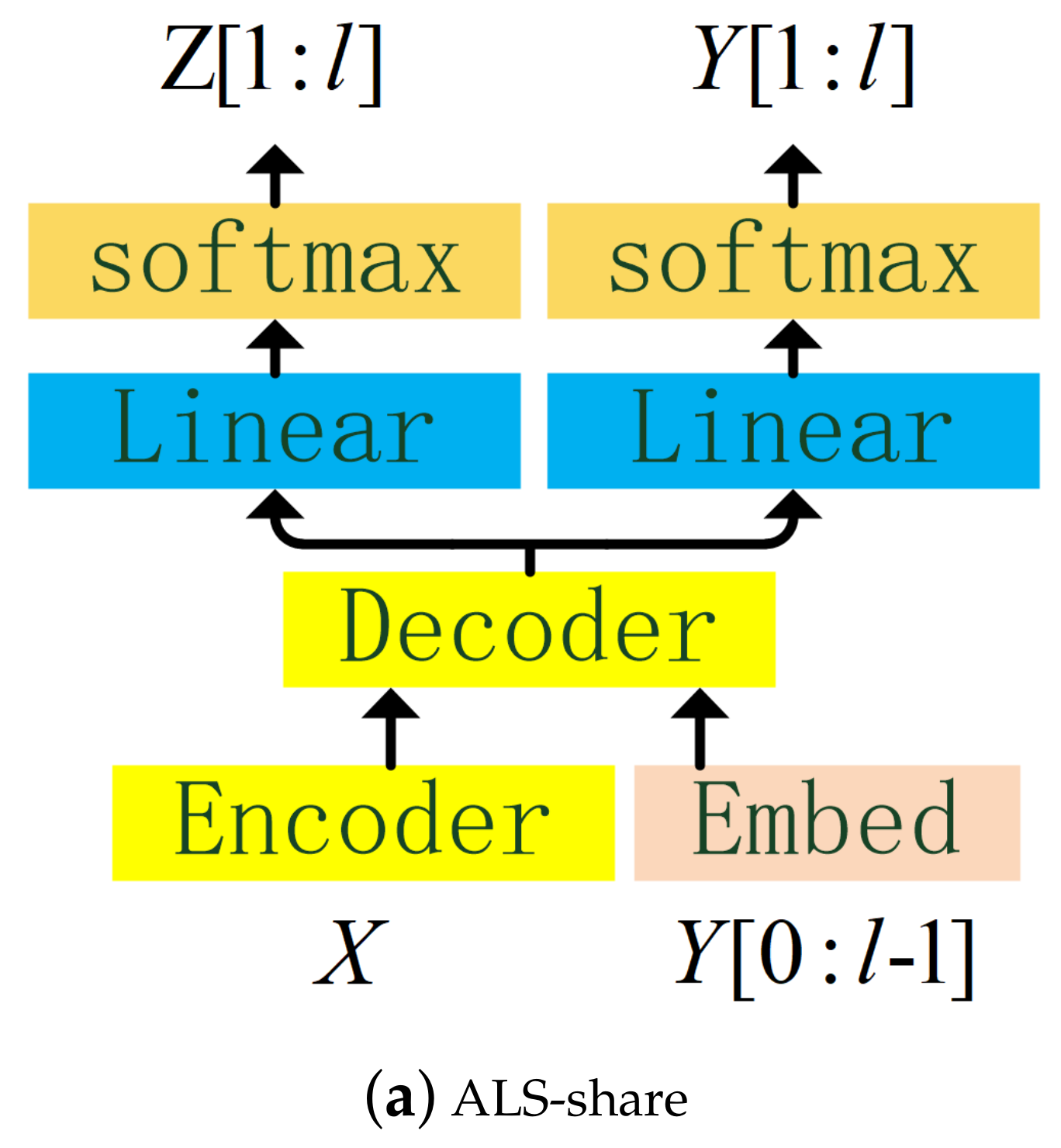
- ASR label sequence (ALS): just like LLS, except that the LID predictor does not receive the LID label sequence, but the ASR label sequence , and in fact, the LID predictor shares the embedding layer with the ASR predictor. ALS can be implemented in two structures, one is the LID task sharing the decoder with the ASR task (ALS-share), the other is not sharing (ALS-indep), as indicated in Figure 4b,c, respectively.
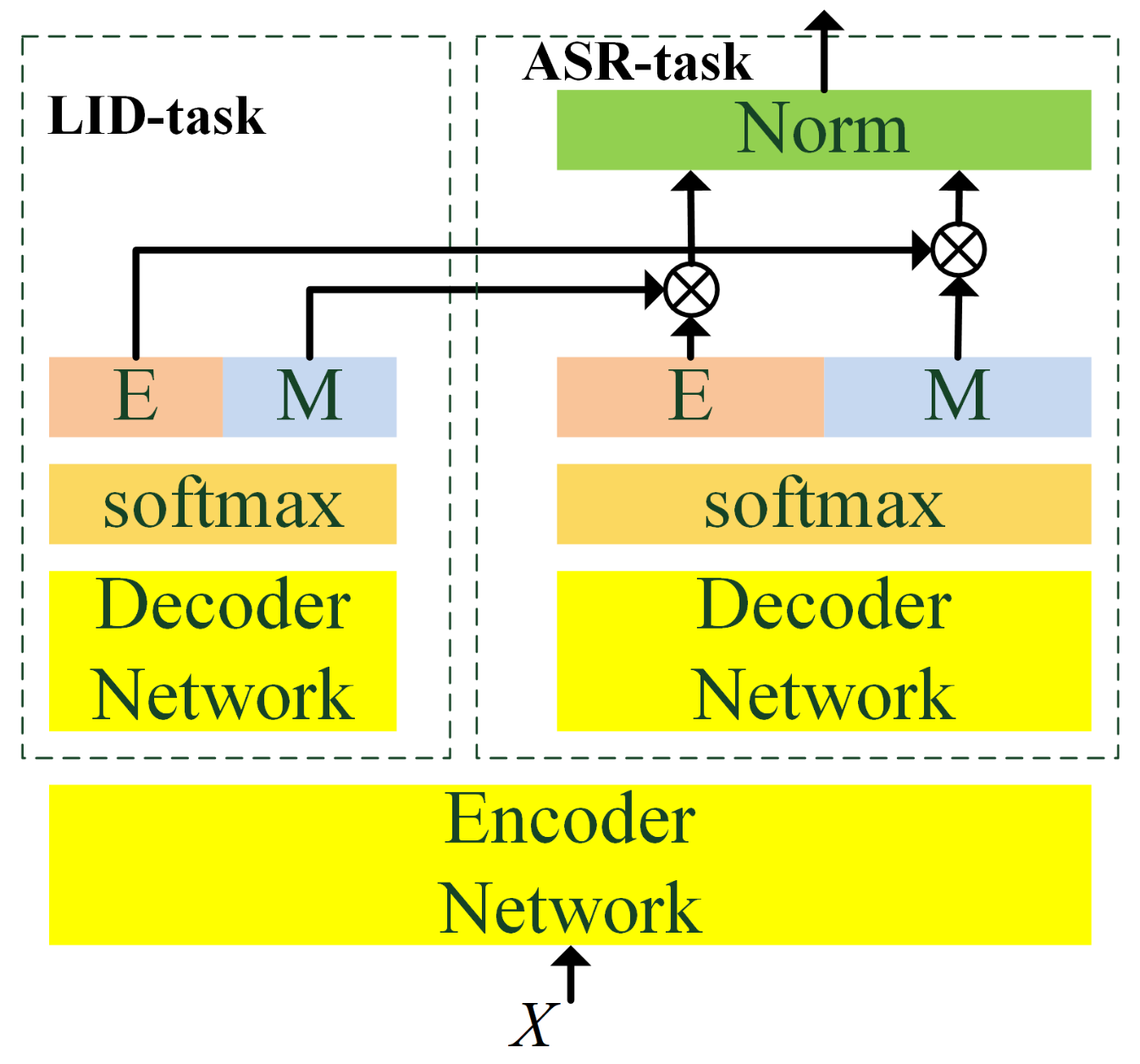
3.3. CSSR Joint Decoding with LID
- Firstly, ASR branch decoding and LID branch decoding are carried out simultaneously to obtain the ASR label and the LID label of the l-th step;
- can be uniquely mapped to , since there is no intersection between the Chinese modeling unit set and the English modeling unit set;
- If is not in {‘E’,‘M’} or is not in {‘E’,‘M’}, will not be modified.
- If both and are in {‘E’,‘M’}, and is different from , then, modification and normalization will be added to .where , is the number of ASR decoder output units, and is the k-th output unit of l-th step, and is the k-th ASR task output units mapping to the LID task output units; therefore, is the -th output unit of l-th step of the LID task, is the probability of the k-thASR output unit of the l-th step, is the probability of the -th LID output unit of the l-th step.
4. Experiments and Results
4.1. Data
4.2. Baseline Setup
4.3. Effects of Different MTL Strategies for Combination of LID and ASR
4.4. Effects of Joint Decoding with LID
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Auer, P. Code-Switching in Conversation: Language, Interaction and Identity; Routledge: London, UK, 1998. [Google Scholar]
- Yilmaz, E.; Heuvel, H.V.D.; van Leeuwen, D.A. Acoustic and Textual Data Augmentation for Improved ASR of Code-Switching Speech; INTERSPEECH: Hyderabad, India, 2–6 September 2018; pp. 1933–1937. [Google Scholar]
- Guo, P.; Xu, H.; Lei, X.; Chng, E.S. Study of Semi-Supervised Approaches to Improving English-Mandarin Code-Switching Speech Recognition; INTERSPEECH: Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Vu, N.T.; Lyu, D.C.; Weiner, J.; Telaar, D.; Schlippe, T.; Blaicher, F.; Chng, E.S.; Schultz, T.; Li, H. A first speech recognition system for Mandarin-English code-switch conversational speech. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Kyoto, Japan, 25–30 March 2012; pp. 4889–4892. [Google Scholar]
- Adel, H.; Vu, N.T.; Kirchhoff, K.; Telaar, D.; Schultz, T. Syntactic and Semantic Features For Code-Switching Factored Language Models. IEEE Trans. Audio Speech Lang. Process. 2015, 23, 431–440. [Google Scholar] [CrossRef] [Green Version]
- Adel, H.; Vu, N.T.; Schultz, T. Combination of Recurrent Neural Networks and Factored Language Models for Code-Switching Language Modeling. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4–10 August 2013; Volume 2, pp. 206–211. [Google Scholar]
- Adel, H.; Kirchhoff, K.; Telaar, D.; Vu, N.T.; Schlippe, T.; Schultz, T. Features for factored language models for code-Switching speech. In Proceedings of the Spoken Language Technologies for Under-Resourced Languages, St. Petersburg, Russia, 14–16 May 2014; pp. 32–38. [Google Scholar]
- Lu, Y.; Huang, M.; Li, H.; Jiaqi, G.; Qian, Y. Bi-encoder Transformer Network for Mandarin-English Code-Switching Speech Recognition Using Mixture of Experts; INTERSPEECH: Shanghai, China, 25–29 October 2020; pp. 4766–4770. [Google Scholar]
- Metilda Sagaya Mary, N.J.; Shetty, V.M.; Umesh, S. Investigation of methods to improve the recognition performance of tamil-english code-switched data in transformer framework. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Virtual Conference, 4–9 May 2020; pp. 7889–7893. [Google Scholar]
- Dalmia, S.; Liu, Y.; Ronanki, S.; Kirchhoff, K. Transformer-transducers for code-switched speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 5859–5863. [Google Scholar]
- Tan, Z.; Fan, X.; Zhu, H.; Lin, E. Addressing accent mismatch In Mandarin-English code-switching speech recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 8259–8263. [Google Scholar]
- Kim, S.; Hori, T.; Watanabe, S. Joint CTC-attention based end-to-end speech recognition using multi-task learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, New Orleans, LA, USA, 5–9 March 2017; pp. 4835–4839. [Google Scholar]
- Prabhavalkar, R.; Rao, K.; Sainath, T.N.; Bo, L.; Johnson, L.; Jaitly, N. A Comparison of Sequence-to-Sequence Models for Speech Recognition; INTERSPEECH: Hyderabad, India, 2017; pp. 939–943. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-Based Models for Speech Recognition. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 577–585. [Google Scholar]
- Chan, W.; Lane, I. On Online Attention-Based Speech Recognition and Joint Mandarin Character-Pinyin Training; INTERSPEECH: San Francisco, CA, USA, 8–12 September 2016; pp. 3404–3408. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.J.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the Machine Learning, Proceedings of the 23rd International Conference, Pittsburgh, PA, USA, 25–29 June 2006; Volume 148, pp. 369–376. [Google Scholar]
- Luo, N.; Jiang, D.; Zhao, S.; Gong, C.; Zou, W.; Li, X. Towards End-to-End Code-Switching Speech Recognition. arXiv 2018, arXiv:1810.13091. [Google Scholar]
- Zeng, Z.; Khassanov, Y.; Pham, V.T.; Xu, H.; Chng, E.S.; Li, H. On the End-to-End Solution to Mandarin-English Code-switching Speech Recognition. arXiv 2018, arXiv:1811.00241. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 5884–5888. [Google Scholar]
- Karita, S.; Soplin, N.E.Y.; Watanabe, S.; Delcroix, M.; Ogawa, A.; Nakatani, T. Improving Transformer-Based End-to-End Speech Recognition with Connectionist Temporal Classification and Language Model Integration; INTERSPEECH: Graz, Austria, 15–19 September 2019; pp. 1408–1412. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 3–9 December 2017; pp. 5998–6008. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N. End-to-end object detection with transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Davis, J.; Sarlos, T.; Belanger, D.; Colwell, L.; Weller, A. Masked language modeling for proteins via linearly scalable long-context transformers. arXiv 2020, arXiv:2006.03555. [Google Scholar]
- Zou, W.; Jiang, D.; Zhao, S.; Li, X. A comparable study of modeling units for end-to-end Mandarin speech recognition. arXiv 2018, arXiv:1805.03832. [Google Scholar]
- Zhou, S.; Dong, L.; Xu, S.; Xu, B. A Comparison of Modeling Units in Sequence-to-Sequence Speech Recognition with the Transformer on Mandarin Chinese. arXiv 2018, arXiv:1805.06239. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Lyu, D.; Tan, T.P.; Chng, E.; Li, H. SEAME: A Mandarin-English Code-Switching Speech Corpus in South-East Asia; INTERSPEECH: Makuhari, Japan, 26–30 September 2010; pp. 1986–1989. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train Set | Dev Set | Test Set | Total | |
|---|---|---|---|---|
| speakers | 145 | 2 | 8 | 155 |
| Duration (h) | 107 | 1.86 | 6.38 | 115.23 |
| utterances | 100802 | 1596 | 6276 | 108674 |
| Baseline System | MER(%) |
|---|---|
| GMM-HMM | 39.6 |
| RNN-based CTC-Attention | 38.38 |
| CTC-Transformer | 33.96 |
| MTL Strategy | LID-CTC | MER(%) |
|---|---|---|
| no LID task | no | 33.96 |
| LLS | no | 32.24 |
| yes | 31.37 | |
| ALS-share | no | 32.79 |
| yes | 31.84 | |
| ALS-indep | no | 34.4 |
| MTL Strategy | LID-CTC | LID Joint Decoding | MER(%) |
|---|---|---|---|
| LLS | yes | no | 31.37 |
| LLS | yes | yes | 30.95 |
| ALS-share | yes | no | 31.84 |
| ALS-share | yes | yes | 31.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Z.; Wang, P.; Wang, J.; Miao, H.; Xu, J.; Zhang, P. Improving Transformer Based End-to-End Code-Switching Speech Recognition Using Language Identification. Appl. Sci. 2021, 11, 9106. https://doi.org/10.3390/app11199106
Huang Z, Wang P, Wang J, Miao H, Xu J, Zhang P. Improving Transformer Based End-to-End Code-Switching Speech Recognition Using Language Identification. Applied Sciences. 2021; 11(19):9106. https://doi.org/10.3390/app11199106
Chicago/Turabian StyleHuang, Zheying, Pei Wang, Jian Wang, Haoran Miao, Ji Xu, and Pengyuan Zhang. 2021. "Improving Transformer Based End-to-End Code-Switching Speech Recognition Using Language Identification" Applied Sciences 11, no. 19: 9106. https://doi.org/10.3390/app11199106