Innovatively Fused Deep Learning with Limited Noisy Data for Evaluating Translations from Poor into Rich Morphology




Abstract
:1. Introduction
- two different forms of text structure (an informal (noisy) corpus (C1), and a formal, well-structured corpus (C2)) will be experimented with;
- a comparative analysis of two different ways of calculating embeddings (the straightforwardly mathematically calculated layer embeddings and the use of pre-trained embeddings) will be conducted
- the application of the SMOTE [10] oversampling technique during training will be investigated in order to overcome data imbalance phenomena;
- the use of two string-based linguistic features (hand-crafted), that capture the similarity between the MT outputs and the reference translation (Sr).
- a novel deep learning architecture with innovative feeding structure that involves features of various linguistic levels and sources;
- a qualitative linguistic analysis that aims to reveal linguistic phenomena linked to poor/rich morphology, that impact on translation performance;
- the exploration of two different validation options (k-fold cross validation (CV) and Percentage split);
- the application of feature selection and dimensionality reduction methods;
- the application of the proposed multi-input, multi-level learning schema on text data from very different genres.
2. Related Work
3. Materials and Methods
3.1. Dataset
3.2. Features
3.3. Embedding Layers
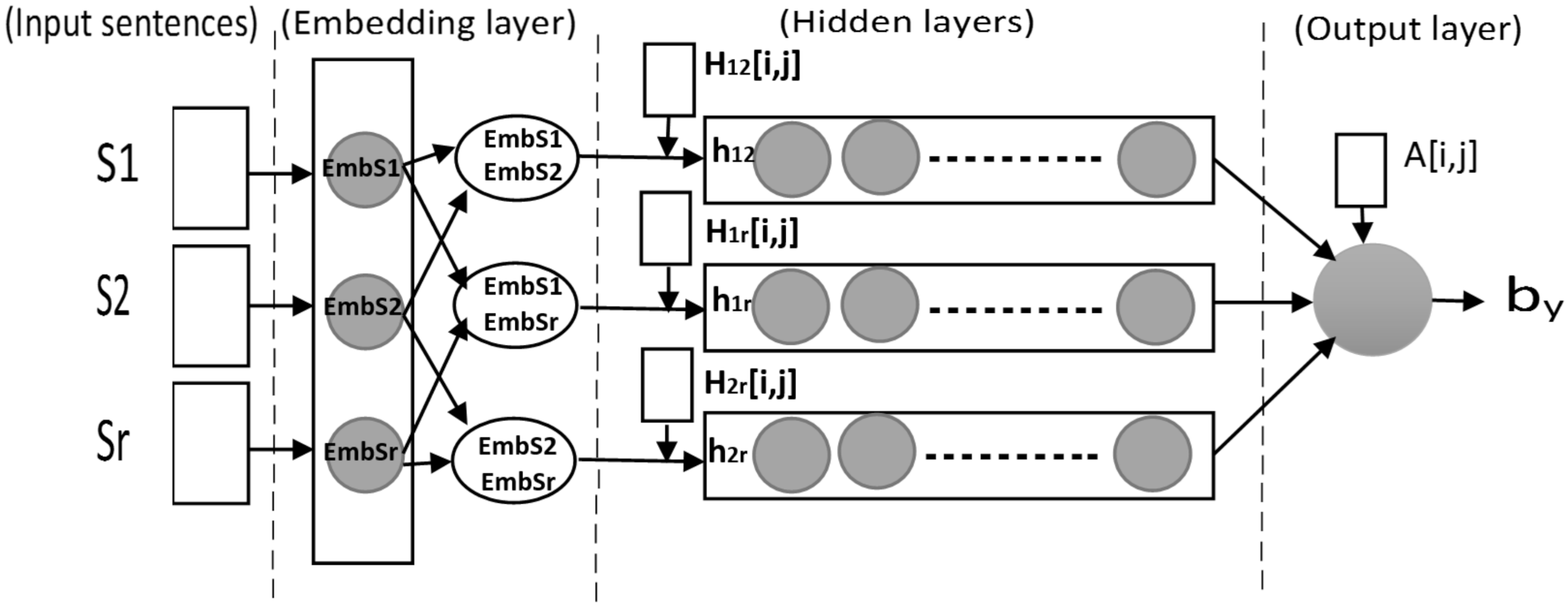
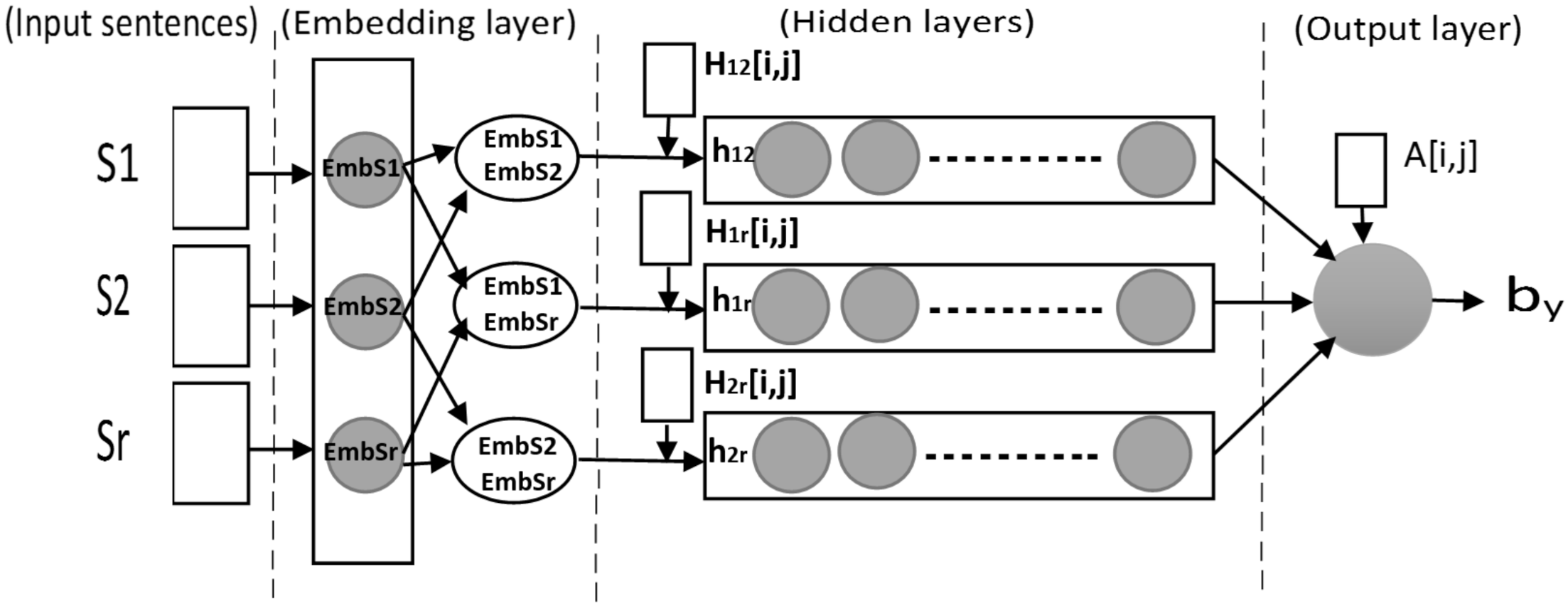
3.4. NN Architecture
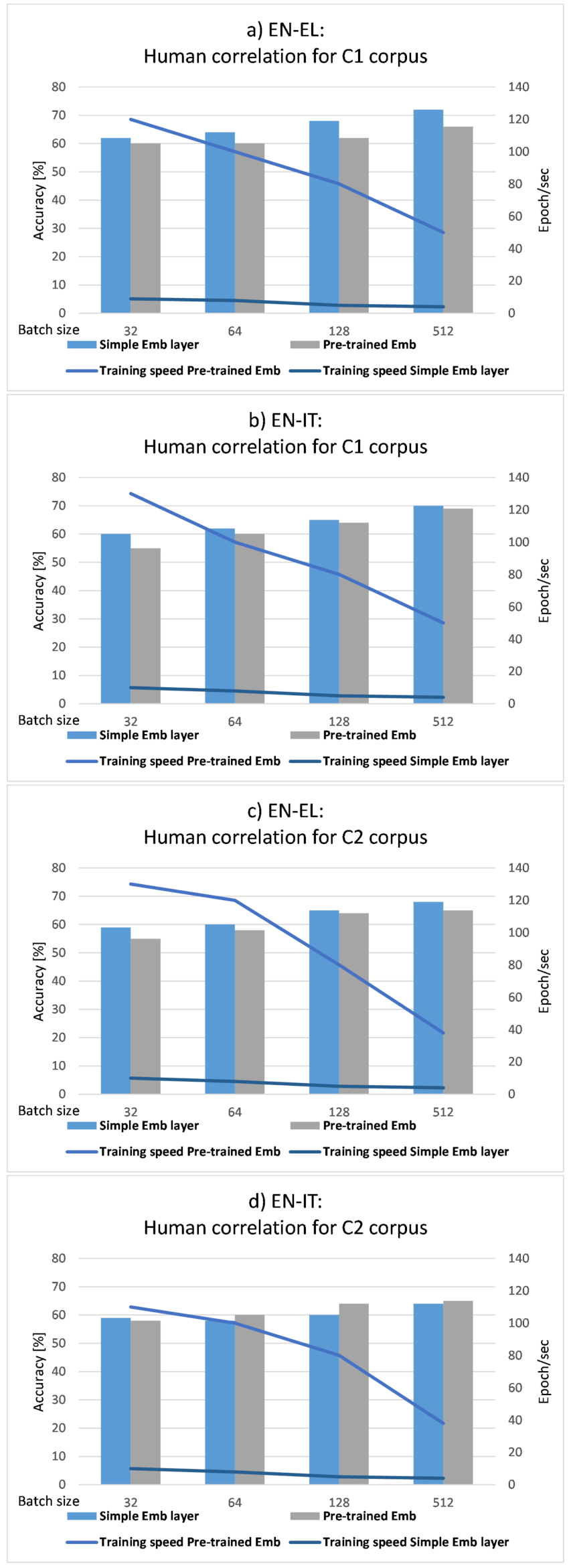
3.5. Network Settings
4. Results
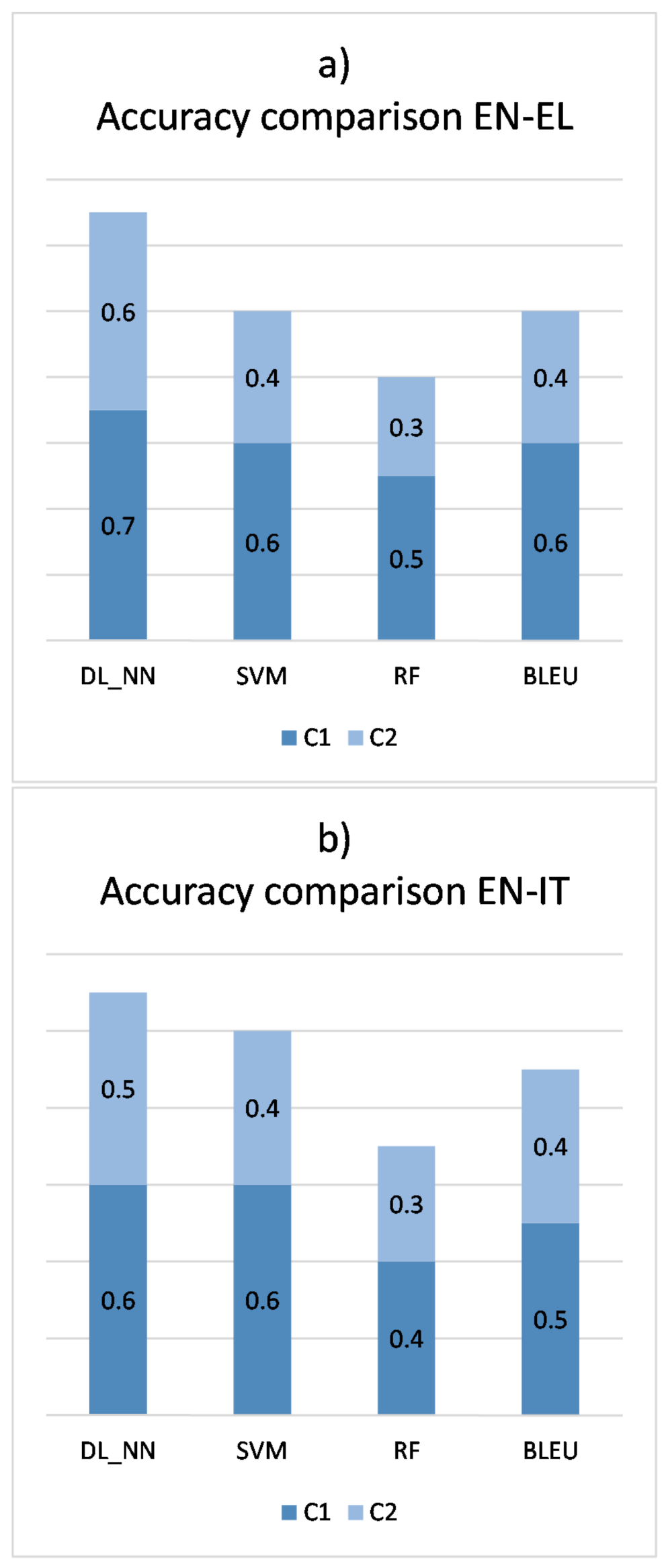
4.1. Performance Evaluation
4.1.1. Comparison to Related Work
4.1.2. Feature Selection and Dimensionality Reduction
4.2. Linguistic Analysis
- The verb to deploy means: to develop, to emplace, to set up. Both S1 and S2 erroneously translated that verb as to use. Nevertheless, the verb to use is one of the secondary meanings of the verb to deploy.
- The most common meaning of the word bug is insect, virus, but it also means: error. The word fix means repair, determine, nominate. In this sentence, bug fix is used as a noun phrase, where the first word functions as a subjective genitive, and the phrase means: error correction. S1 commits two errors when translating “fix” (φτιάξουμε), i. Fix is erroneously considered to have a verb function. ii. It is difficult to explain why the same verb is translated in the first person of plural of the simple past-subjunctive. As a consequence, S1, S2’s translations for the verbal phrase (deploys a bug fix) are both nonsensical: S1: “χρησιμοποιεί ένα έντομο φτιάξουμε” (“uses an insect” + simple past-subjunctive of “repair”), S2: χρησιμοποιεί “ένα σφάλμα για τα έντομα” (uses an error for the insects).
- In addition, it is important to notice that S2 has translated the same phrase (bug fix) at the end of the sentence in a different way. S2 tried to improve the translation and it certainly succeeded, but only for the word fix (διόρθωση). S2 also “spotted” that bug is a subjective genitive (the correction of the error), but it still identified bug as an insect and it has erroneously translated it: ζουζιού. In Greek, this is a nonexistent word, but it is strongly reminiscent of the word ζουζούνι (insect), which is an onomatopoeic word (the buzz of a bug) and especially of its genitive case: ζουζουνιού, with some letters missing.
- S1 has correctly “identified” the meaning of the verb to list (to enumerate), but not in the correct grammatical number—third-person plural, instead of third-person singular. S2 chose the correct grammatical inflectional morphemes for the number and the person, but not the correct meaning, for this context: referred, instead of enumerated, indexed or set out. So, the proposed NN model has correctly chosen S2, as S2 “recognized” the correct grammatical morphemes of number and person features.
- Regarding the passive future verb: will be updated: In S1, the preceding particle of future tense in Greek θα (According to the Cambridge Dictionary, a particle is a word or a part of a word that has a grammatical purpose but often has little or no meaning. https://dictionary.cambridge.org/dictionary/english/particle) (will) is separated from the subjunctive (επικαιροποιηθεί), which is wrong.
- Both S1 and S2 have erroneously translated the noun phrase: cache manifest. As they failed to identify the multi-word expression, they have translated them separately. The word cache means: crypt, hideout, cache memory, and, in this sentence, it has the last meaning (κρυφή μνήμη). However, S1 “chose” the first meaning (κρύπτη) (crypt), whereas S2 left the word untranslated. Manifest means obvious, apparent. Both S1 and S2 “chose” from these synonyms. Nevertheless, the cache manifest in HTML5 is a software storage feature which provides the ability to access a web application even without a network connection (https://en.wikipedia.org/wiki/Cache_manifest_in_HTML5). So, the best translation would be: κρυφή μνήμη ιστότοπου (website cache memory), a translation that was not even produced in the reference.
- Sit: Both S1 and S2 have erroneously translated this verb (κάτσετε, καθήσετε). In this sentence, the verb to sit is transitive and means: to place, to put, requiring an inanimate object, whereas the very common meaning of this verb, that is to have a seat, presupposes that the verb is intransitive (+animate subject) or transitive (but:+animate object: I make someone sit down). Both S1 and S2 have erroneously adopted the second meaning, without “noticing” that its object (spheroids) is an inanimate noun. Even more, the form chosen by S1 belongs to oral speech (κάτσετε) (to sit), while S2’s form is misspelled (καθήσετε (to sit), instead of the correct: καθίσετε).
- Kind of is an informal expression modifying and especially attenuating (It is the opposite of really. In the UK, it is considered quite informal. https://english.stackexchange.com/questions/296634/kind-of-like-is-a-verb) the meaning of the verb plonk. S1 has erroneously “identified” that word as a noun and so mistranslated it as: form, genre, species(είδους). Nevertheless, S1 “identified” the inflectional grammatical morpheme of the genitive case:-ους for of.
- Plonk down: This phrasal verb has a lot of meanings: drop heavily, place down, impale, attract and so forth (https://glosbe.com/en/el/plonk%20down) S1 has erroneously translated this verb in the meaning of impale, which is not the case. S1 has separately translated the whole sentence (they kind of plonk down: είδους παλουκώσει τους κάτω), which is completely nonsensical in Greek. In addition, the verb object them has been erroneously placed after the verb (in Greek, the clitic form of the personal pronoun is placed before the verb) and has been translated by a wrong grammatical morpheme (masculine plural (τους) instead of neutral plural (τα)). On the other hand, S2 has correctly “found” the connection of those words (kind of plonk down), but it translated them in a wrong and, at first sight, non-understandable way: συναρπάζουν (fascinate).
- S1 incorrectly translated the phrase: will get us accustomed to, considering that the two verbs are independent of each other (θα δώσει (wiil give), συνηθίσει (will get used)),without taking into account that the verb get has a metaphorical meaning: cause something to happen, and not the literal one: take. The verb get, in this sentence, forms a multi-word expression with the verb accustomed and the preposition to, which, as a past participle, depends on the first. S2 correctly translated the phrase as: θα μας κάνει συνηθισμένους (it will make us get used), left the word untranslated.
- S1 incorrectly translated the last link of the sentence: (να τις ιδιαιτερότητες (here the particularities)(!)), translating the preposition to as if it were before an infinitive, without taking into account that this is the second part of: accustomed to…and to. Related to the latter is that S1 incorrectly translated the word after to, that is, the possessive adjective their, as a definite article in plural: τις (the).
- Fee: the word has a lot of translations in italian language: tassa, retribuzione (salary), compenso (compensation), pagamento (payment), contributo (contribution) and so forth. Both S1 and S2 chose the most common meaning (tassa), but not the right one for this context: spesa (expenditure or charges).
- Both S1 and S2 erroneously put question marks for the accented morphemes: ? instead of è and attivit? instead of attività (activities).
- Atteggiamento: both S1 and S2 correctly translated the word (attitude), but they both did not put in to the right position, as in italian sentence structure (in contrast with the english language) the quotation, functioning as a title, follows the word atteggiamento (attitude), characterising and explaining it.
- Assets: Both S1 and S2 translated this word as attività. The most common meanings of the word attività are: activity, practice, action, operation etc, but it also means: business, assets, resources, occupation etc), whereas assets meanings are: property, benefit, resource, investment and so forth. Both S1 and S2 chose the closer meaning, but not the right one (risorse). The reason for this relatively successful choice may be the first word of the concordance (underused assets), in opposite meaning with the most of the other translations.
- Save: Both S1 and S2 erroneously translated the word as salvare and salvano, respectively, instead of risparmiano. Even though the English verb to save derives from the same Latin verb (salvare), in Italian the main meanings of salvare are rescue, salvage or safeguard.
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Goldberg, Y. A primer on neural network models for natural language processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef] [Green Version]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Guzmán, F.; Joty, S.; Màrquez, L.; Nakov, P. Pairwise neural machine translation evaluation. arXiv 2019, arXiv:1912.03135. [Google Scholar]
- Devlin, J.; Zbib, R.; Huang, Z.; Lamar, T.; Schwartz, R.; Makhoul, J. Fast and robust neural network joint models for statistical machine translation. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 1370–1380. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Gupta, S.; Agrawal, A.; Gopalakrishnan, K.; Narayanan, P. Deep learning with limited numerical precision. In Proceedings of the International Conference on Machine Learning 2015, Lille, France, 6–11 July 2015; pp. 1737–1746. [Google Scholar]
- Mouratidis, D.; Kermanidis, K.L. Automatic selection of parallel data for machine translation. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Rhodes, Greece, 25–27 May 2018; pp. 146–156. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Doddington, G. Automatic evaluation of machine translation quality using n-gram co-occurrence statistics. In Proceedings of the Second International Conference on Human Language Technology Research, San Diego, CA, USA, 24–27 March 2002; pp. 138–145. [Google Scholar]
- Su, K.Y.; Wu, M.W.; Chang, J.S. A new quantitative quality measure for machine translation systems. In Proceedings of the 15th International Conference on Computational Linguistics, Nantes, France, 23–28 August 1992. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor universal: Language specific translation evaluation for any target language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MD, USA, 26–27 June 2014; pp. 376–380. [Google Scholar]
- Snover, M.; Dorr, B.; Schwartz, R. Language and translation model adaptation using comparable corpora. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; pp. 857–866. [Google Scholar]
- Shimanaka, H.; Kajiwara, T.; Komachi, M. Ruse: Regressor using sentence embeddings for automatic machine translation evaluation. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Belgium, Brussels, 31 October–1 November 2018; pp. 751–758. [Google Scholar]
- Duh, K. Ranking vs. regression in machine translation evaluation. In Proceedings of the Third Workshop on Statistical Machine Translation, Columbus, OH, USA, 19 June 2008; pp. 191–194. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the NIPS 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Mouratidis, D.; Kermanidis, K.L.; Sosoni, V. Innovative Deep Neural Network Fusion for Pairwise Translation Evaluation. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Neos Marmaras, Greece, 5–7 June 2020; pp. 76–87. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. arXiv 2017, arXiv:1705.03122. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Bradbury, J.; Merity, S.; Xiong, C.; Socher, R. Quasi-recurrent neural networks. arXiv 2016, arXiv:1611.01576. [Google Scholar]
- Kalchbrenner, N.; Espeholt, L.; Simonyan, K.; Oord, A.V.d.; Graves, A.; Kavukcuoglu, K. Neural machine translation in linear time. arXiv 2016, arXiv:1610.10099. [Google Scholar]
- Kordoni, V.; Birch, L.; Buliga, I.; Cholakov, K.; Egg, M.; Gaspari, F.; Georgakopoulou, Y.; Gialama, M.; Hendrickx, I.; Jermol, M.; et al. TraMOOC (translation for massive open online courses): Providing reliable MT for MOOCs. In Proceedings of the Annual conference of the European Association for Machine Translation 2016, Riga, Latvia, 30 May–1 June 2016; p. 396. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions, Stroudsburg, PA, USA, 25–27 June 2007; pp. 177–180. [Google Scholar]
- Palmquist, R. Translation System. U.S. Patent 10/234,015, 4 March 2004. [Google Scholar]
- Sennrich, R.; Firat, O.; Cho, K.; Birch, A.; Haddow, B.; Hitschler, J.; Junczys-Dowmunt, M.; Läubli, S.; Barone, A.V.M.; Mokry, J.; et al. Nematus: A toolkit for neural machine translation. arXiv 2017, arXiv:1703.04357. [Google Scholar]
- Barone, A.V.M.; Haddow, B.; Germann, U.; Sennrich, R. Regularization techniques for fine-tuning in neural machine translation. arXiv 2017, arXiv:1707.09920. [Google Scholar]
- Rama, T.; Borin, L.; Mikros, G.; Macutek, J. Comparative evaluation of string similarity measures for automatic language classification. In Sequences in Language and Text; De Gruyter Mouton: Berlin, Germany, 2015. [Google Scholar]
- Pouliquen, B.; Steinberger, R.; Ignat, C. Automatic identification of document translations in large multilingual document collections. arXiv 2006, arXiv:cs/0609060. [Google Scholar]
- Barrón-Cedeño, A.; Màrquez Villodre, L.; Henríquez Quintana, C.A.; Formiga Fanals, L.; Romero Merino, E.; May, J. Identifying useful human correction feedback from an on-line machine translation service. In Proceedings of the 23rd Internacional Joint Conference on Artificial Intelligence, Beijing, China, 5–9 August 2013; pp. 2057–2063. [Google Scholar]
- Mouratidis, D.; Kermanidis, K.L. Ensemble and deep learning for language-independent automatic selection of parallel data. Algorithms 2019, 12, 26. [Google Scholar] [CrossRef] [Green Version]
- Loper, E.; Bird, S. NLTK: The natural language toolkit. arXiv 2002, arXiv:cs/0205028. [Google Scholar]
- Sergio, G.C. gcunhase/NLPMetrics: The Natural Language Processing Metrics Python Repository. Zenodo 2019. [Google Scholar] [CrossRef]
- Keras, K. Deep Learning Library for Theano and Tensorflow 2015. Available online: https://keras.io/k (accessed on 11 January 2021).
- Outsios, S.; Karatsalos, C.; Skianis, K.; Vazirgiannis, M. Evaluation of Greek Word Embeddings. arXiv 2019, arXiv:1904.04032. [Google Scholar]
- Yamada, I.; Asai, A.; Shindo, H.; Takeda, H.; Takefuji, Y. Wikipedia2Vec: An optimized tool for learning embeddings of words and entities from Wikipedia. arXiv 2018, arXiv:1812.06280. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. Int. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Guilford, J.P. Psychometric Methods; McGraw-Hill: New York, NY, USA, 1954. [Google Scholar]
- Soricut, R.; Brill, E. Automatic question answering: Beyond the factoid. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics: HLT-NAACL 2004, Boston, MA, USA, 2–7 May 2004; pp. 57–64. [Google Scholar]
- Smialowski, P.; Frishman, D.; Kramer, S. Pitfalls of supervised feature selection. Bioinformatics 2010, 26, 440–443. [Google Scholar] [CrossRef]
- Chandrashekar, G.; Sahin, F. A survey on feature selection methods. Comput. Electr. Eng. 2014, 40, 16–28. [Google Scholar] [CrossRef]
- Van Der Maaten, L.; Postma, E.; Van den Herik, J. Dimensionality reduction: A comparative. J. Mach. Learn. Res. 2009, 10, 13. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Koller, D.; Sahami, M. Toward Optimal Feature Selection; Technical Report; Stanford InfoLab: Stanford, CA, USA, 1996. [Google Scholar]
- Molina, L.C.; Belanche, L.; Nebot, À. Feature selection algorithms: A survey and experimental evaluation. In Proceedings of the 2002 IEEE International Conference on Data Mining, Maebashi, Japan, 9–12 December 2002; pp. 306–313. [Google Scholar]
- Liu, H.; Motoda, H. Feature Selection for Knowledge Discovery and Data Mining; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 454. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Corpus | Number of | Average of | Number of | Unique Words |
|---|---|---|---|---|
| Sentences | Sentences Length | Total Words | SSE/S1/S2/Sr | |
| SSE/S1/S2/Sr | SSE/S1/S2/Sr | |||
| EL_C1 | 2687 | 15.8/15.9/15.7/16.2 | 42518/42953/42216/43562 | 5167/7331/7424/7830 |
| EL_C2 | 2022 | 31.5/33.9/33.0/33.7 | 66425/68457/66773/68119 | 6022/8729/9022/9797 |
| IT_C1 | 2687 | 15.8/15./15.6/16.0 | 42894/43152/42001/42357 | 5167/6280/6059/6440 |
| IT_C2 | 2022 | 31.5/32.0/30.1/31.8 | 66425/67521/66982/68521 | 6022/6728/6556/7374 |
| Simple Embedding Layer | Pre-Trained | |||||||
|---|---|---|---|---|---|---|---|---|
| MT Model | 82 Features | 86 Features | 82 Features | 86 Features | ||||
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| Language pair: EN-EL | ||||||||
| NN model with 2687 segments for C1 and 2022 segments for C2 | ||||||||
| SMT C1 | 70% | 89% | 70% | 92% | 70% | 77% | 68% | 77% |
| NMT C1 | 67% | 37% | 69% | 31% | 54% | 40% | 50% | 45% |
| SMT C2 | 62% | 59% | 63% | 60% | 60% | 58% | 62% | 64% |
| NMT C2 | 58% | 60% | 55% | 59% | 56% | 59% | 57% | 62% |
| NN model_SMOTE with 3024 segments for C1 and 2276 segments for C2 | ||||||||
| SMT C1 | 68% | 72% | 68% | 78% | 65% | 67% | 65% | 75% |
| NMT C1 | 48% | 41% | 48% | 42% | 40% | 37% | 54% | 46% |
| SMT C2 | 58% | 49% | 60% | 52% | 66% | 45% | 65% | 73% |
| NMT C2 | 60% | 59% | 60% | 64% | 54% | 65% | 55% | 45% |
| Language pair: EN-IT | ||||||||
| NN model with 2687 segments for C1 and 2022 segments for C2 | ||||||||
| SMT C1 | 62% | 44% | 65% | 44% | 68% | 52% | 70% | 80% |
| NMT C1 | 70% | 87% | 60% | 80% | 65% | 75% | 82% | 60% |
| SMT C2 | 55% | 31% | 57% | 37% | 56% | 40% | 59% | 45% |
| NMT C2 | 54% | 76% | 55% | 76% | 60% | 81% | 62% | 80% |
| NN model_SMOTE with 3024 segments for C1 and 2276 segments for C2 | ||||||||
| SMT C1 | 50% | 63% | 58% | 38% | 70% | 55% | 68% | 77% |
| NMT C1 | 56% | 43% | 61% | 77% | 65% | 69% | 70% | 55% |
| SMT C2 | 51% | 51% | 57% | 45% | 56% | 40% | 58% | 40% |
| NMT C2 | 52% | 56% | 60% | 56% | 62% | 68% | 70% | 65% |
| MT Model | 10 Fold CV | 70% Per. Split | ||
|---|---|---|---|---|
| MCC/Corpus | C1 | C2 | C1 | C2 |
| EN-EL_simple emb layer | 0.32 | 0.17 | 0.29 | 0.22 |
| EN-IT_ simple emb layer | 0.10 | 0.12 | 0.10 | 0.15 |
| EN-EL_pre-trained emb | 0.20 | 0.15 | 0.18 | 0.17 |
| EN-IT_ pre-trained emb | 0.11 | 0.13 | 0.10 | 0.14 |
| Method | RFECV | IG | CHI2 | PCA | ||||
|---|---|---|---|---|---|---|---|---|
| No of Features | 23/86 | 49/86 | 70/86 | 54 new | ||||
| Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall | |
| Language pair: EN-EL_2687 segments for C1 and 2022 segments for C2 | ||||||||
| SMT C1 | 66% | 87% | 67% | 91% | 70% | 93% | 67% | 90% |
| NMT C1 | 54% | 26% | 63% | 26% | 68% | 31% | 61% | 25% |
| SMT C2 | 63% | 85% | 66% | 70% | 67% | 73% | 61% | 80% |
| NMT C2 | 74% | 46% | 62% | 60% | 68% | 61% | 68% | 45% |
| Language pair: EN-IT_2687 segments for C1 and 2022 segments for C2 | ||||||||
| SMT C1 | 59% | 40% | 62% | 40% | 65% | 39% | 58% | 32% |
| NMT C1 | 52% | 60% | 59% | 82% | 60% | 87% | 56% | 79% |
| SMT C2 | 56% | 30% | 56% | 30% | 57% | 30% | 53% | 25% |
| NMT C2 | 54% | 70% | 55% | 79% | 55% | 79% | 53% | 75% |
| ID | SSE | S1 | S2 | Sr |
|---|---|---|---|---|
| 1 | If an ARSnova developer deploys a bug fix which will modify a single file listed in the cache manifest, will the local file concerning the bug fix be updated in your browser? | Εάν ένας προγραμ- ματιστής ARSnova χρησιμοποιεί ένα έντομο φτιάξουμε το οποίο θα τροποποιήσουν ένα ενιαίο αρχείο που απαριθμούνται στην κρύπτη πρόδηλο, θα το τοπικό αρχείο σχετικά με το μικρόβιο φτιάξουμε επικαιροποιηθεί στον περιηγητή σας; | Aν ένας προγραμματιστής ARSnova χρησιμοποιεί ένα σφάλμα για τα έντομα, το οποίο θα τροποποιήσει ένα μόνο αρχείο που αναφέρεται στο δηλωτικό του cache, θα ενημερωθεί το τοπικό αρχείο σχετικά με την διόρθωση του ζουζιού στο πρόγραμμα περιήγησης; | Aν ένας προγραμματιστής ARSnova αναπτύξει μια διόρθωση για ένα σφάλμα του προγράμματος που θα τροποποιεί ένα μοναδικό αρχείο που εμφανίζεται στην κρυφή μνήμη, θα ενημερωθεί το τοπικό αρχείο σχετικά με τη διόρθωση του σφάλματος στον περιηγητή σας; |
| 2 | Then he’s made a structure where you can sit these spheroids, I think they kind of plonk them down on these metal pyramids. | Στη συνέχεια έκανε μια δομή όπου μπορείτε να κάτσετε αυτά τα σφαιρίδια, νομίζω ότι είδους παλουκώσει τους κάτω από αυτά τα μεταλλικά πυραμίδες. | Μετά έφτιαξε μια δομή όπου μπορείτε να καθήσετε αυτά τα σφαιρικά, νομίζω ότι τους συναρπάζουν σε αυτές τις μεταλλικές πυραμίδες. | Έπειτα αυτός έχει δημιουργήσει μια δομή όπου μπορείς να τοποθετήσεις αυτά τα σφαιροειδή, νομίζω ότι αυτοί κατά κάποιο τρόπο τα ρίχνουν σε αυτές τις μεταλλικές πυραμίδες. |
| 3 | Deductive vs Inductive, or Definitely vs Probably, will get us accustomed to the two main breeds of arguments and to their particularities. | Επαγωγικό έναντι επαγωγικά, ή Σίγουρα έναντι Πιθανόν, θα μας δώσει συνηθίσει τα δύο κύρια φυλών επιχειρήματα και να τις ιδιαιτερότητες. | Επαγωγικό εναντίον του Inductive, ή σίγουρα εναντίον πιθανόν, θα μας κάνει συνηθισμένους στις δύο κύριες φυλές των επιχειρημάτων και στις ιδιαιτερότητες τους. | Παραγωγική έναντι Επαγωγικής σκέψης ή Πιθανότητα έναντι Βεβαιότητας, θα μας εξοικειώσει με τα δυο βασικά είδη επιχειρημάτων και τις ιδιαιτερότητές τους. |
| 4 | “The what’s mine is yours, for a small fee” attitude helps owners make some money from underused assets and at the same time the collaborators save a huge percentage of their resources. | “Quello che ? mio ? tuo, per una piccola tassa” atteggiamento proprietari aiuta a fare dei soldi da attivit? sottoutilizzato e allo stesso tempo i collaboratori salvare una grande percentuale delle loro risorse. | “La mia ? la tua, per una piccola tassa” aiuta i proprietari a fare un po ’di soldi da attivit? sottoutilizzate e allo stesso tempo i collaboratori salvano un’enorme percentuale delle loro risorse. | L’atteggiamento “Quello che è mio è tuo con una piccola spesa” aiuta i proprietari a guadagnare qualcosa dalle risorse sottoutilizzate e allo stesso tempo i collaboratori risparmiano una percentuale enorme delle loro risorse. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mouratidis, D.; Kermanidis, K.L.; Sosoni, V. Innovatively Fused Deep Learning with Limited Noisy Data for Evaluating Translations from Poor into Rich Morphology. Appl. Sci. 2021, 11, 639. https://doi.org/10.3390/app11020639
Mouratidis D, Kermanidis KL, Sosoni V. Innovatively Fused Deep Learning with Limited Noisy Data for Evaluating Translations from Poor into Rich Morphology. Applied Sciences. 2021; 11(2):639. https://doi.org/10.3390/app11020639
Chicago/Turabian StyleMouratidis, Despoina, Katia Lida Kermanidis, and Vilelmini Sosoni. 2021. "Innovatively Fused Deep Learning with Limited Noisy Data for Evaluating Translations from Poor into Rich Morphology" Applied Sciences 11, no. 2: 639. https://doi.org/10.3390/app11020639
APA StyleMouratidis, D., Kermanidis, K. L., & Sosoni, V. (2021). Innovatively Fused Deep Learning with Limited Noisy Data for Evaluating Translations from Poor into Rich Morphology. Applied Sciences, 11(2), 639. https://doi.org/10.3390/app11020639