Region Pixel Voting Network (RPVNet) for 6D Pose Estimation from Monocular Image

Abstract
:1. Introduction
2. Materials and Methods
2.1. Model of the Problem
2.1.1. Pose of an Object
2.1.2. Equivalence between Pose and Camera External Parameter
2.1.3. PnP Based Pose Estimation
2.2. Proposed Method
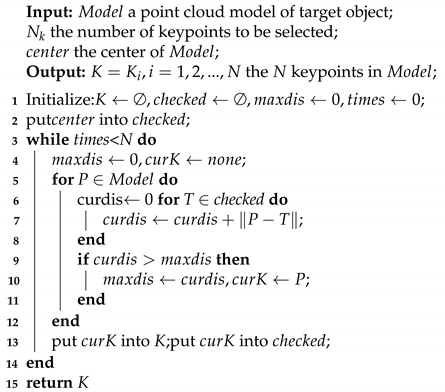
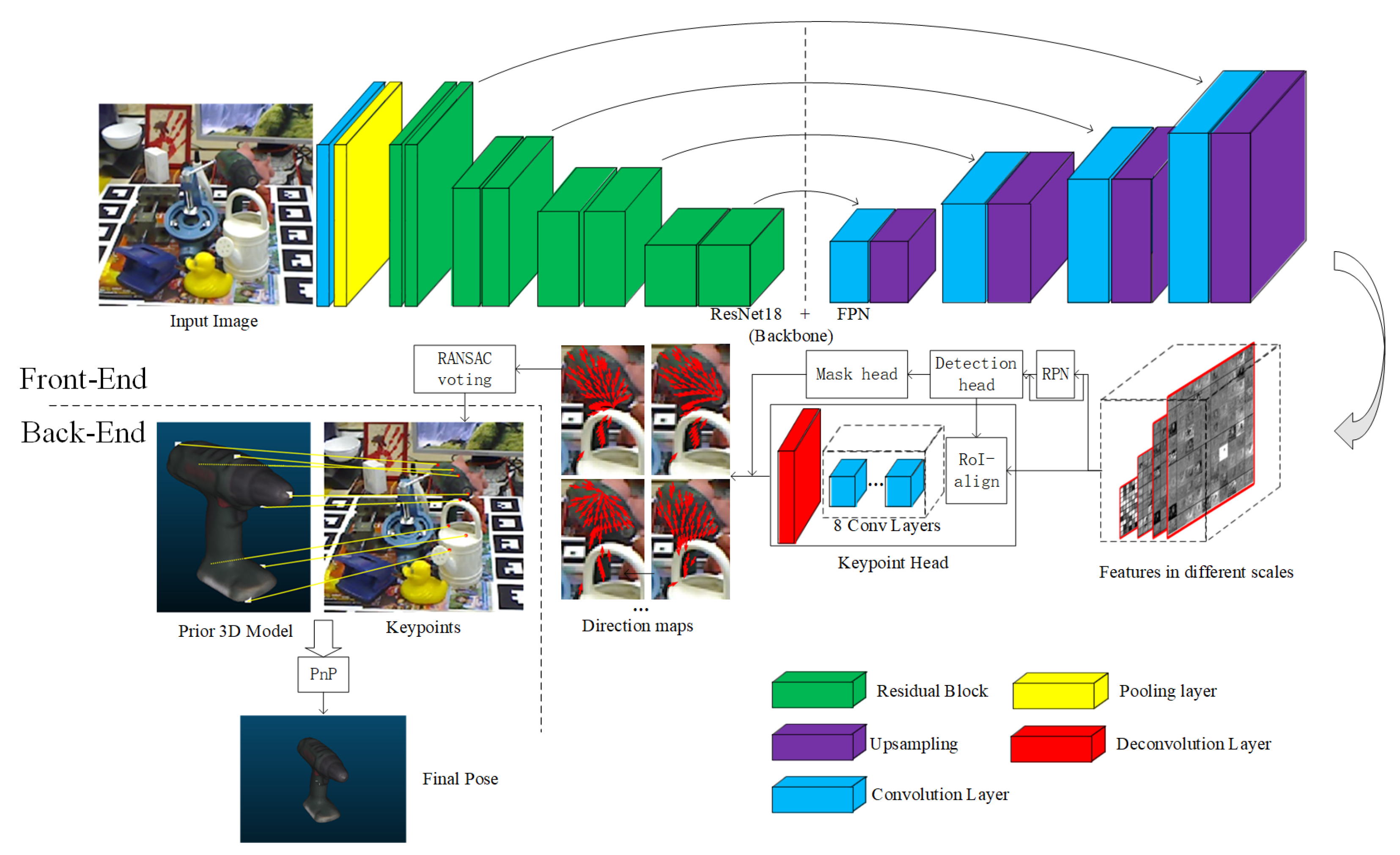
2.2.1. Network Structure
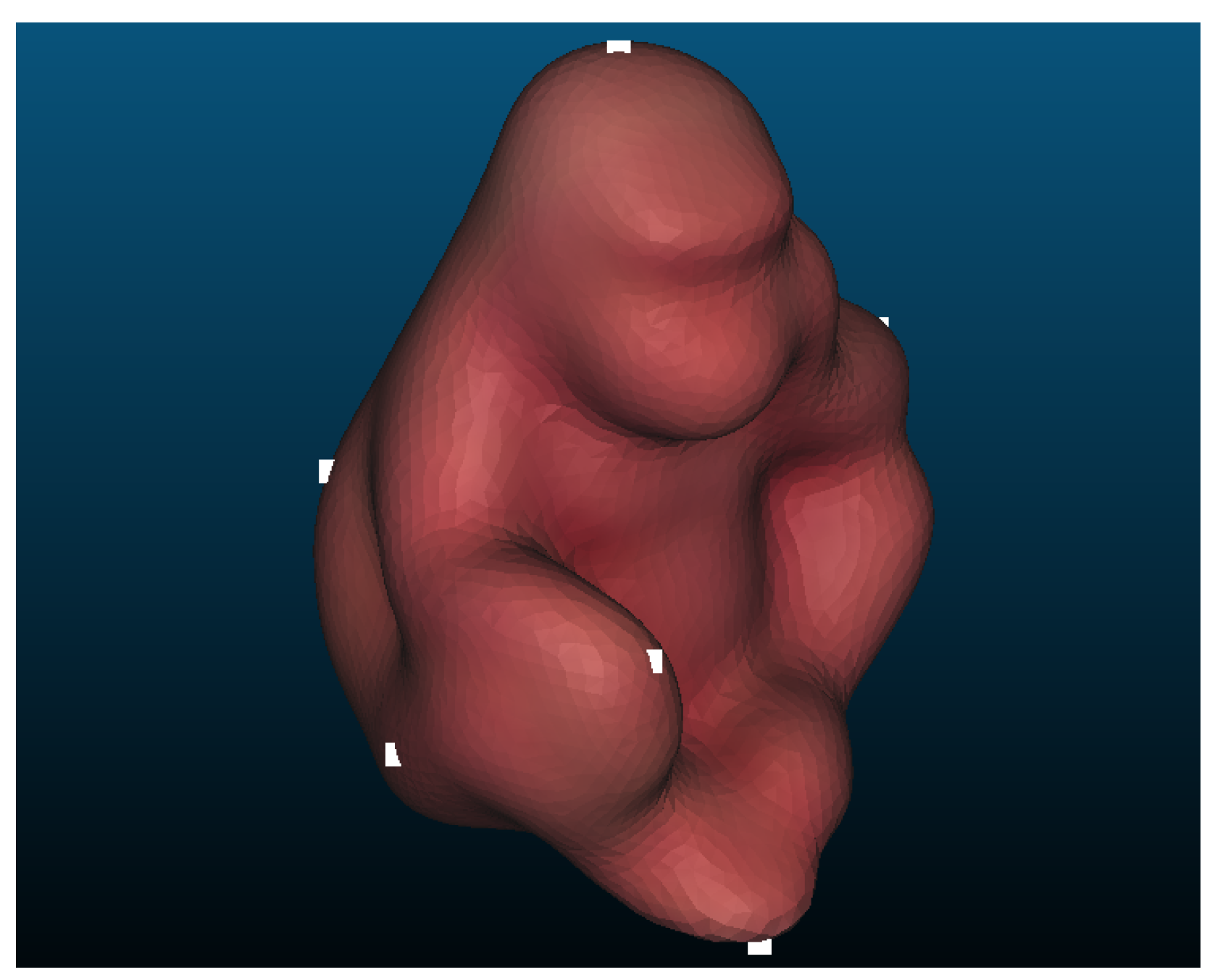
2.2.2. Keypoints Selection
| Algorithm 1: Farthest Sampling |
 |
2.2.3. Direction Map
| Algorithm 2: RANSAC voting for a keypoint |
 |
2.2.4. Using RoI for Detection
2.2.5. Alignment of Direction Map
3. Results
3.1. Datasets
3.2. Evaluation Metrics
3.3. Training Strategy
3.4. Test Results
4. Discussion
4.1. Comparison between Heatmap and Direction Map
4.2. Comparison with Other Methods
4.3. Running Time
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zeng, A.; Yu, K.; Song, S.; Suo, D.; Walker, E., Jr.; Rodriguez, A.; Xiao, J. Multi-view self-supervised deep learning for 6D pose estimation in the Amazon Picking Challenge. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation, ICRA 2017, Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1383–1386. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPNP: Accurate O(n) Solut. PnP Probl. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef] [Green Version]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the International Conference on Computer Vision, Kerkyra, Corfu, Greece, 20–25 September 1999; IEEE Computer Society: Washington, DC, USA, 1999; pp. 1150–1157. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G.R. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011; Metaxas, D.N., Quan, L., Sanfeliu, A., Gool, L.V., Eds.; IEEE Computer Society: Washington, DC, USA, 2011; pp. 2564–2571. [Google Scholar]
- Rothganger, F.; Lazebnik, S.; Schmid, C.; Ponce, J. 3D Object Modeling and Recognition Using Local Affine-Invariant Image Descriptors and Multi-View Spatial Constraints. Int. J. Comput. Vis. 2006, 66, 231–259. [Google Scholar] [CrossRef] [Green Version]
- Gu, C.; Ren, X. Discriminative Mixture-of-Templates for Viewpoint Classification. In Computer Vision—ECCV 2010, Proceedings of the 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Daniilidis, K., Maragos, P., Paragios, N., Eds.; Lecture Notes in Computer Science; Proceedings, Part V; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6315, pp. 408–421. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. PoseNet: A Convolutional Network for Real-Time 6-DOF Camera Relocalization. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 2938–2946. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 2980–2988. [Google Scholar]
- Do, T.T.; Cai, M.; Pham, T.; Reid, I. Deep-6dpose: Recovering 6d object pose from a single rgb image. arXiv 2018, arXiv:1802.10367. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. In Proceedings of the Robotics: Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N. SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 1530–1538. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Proceedings, Part I; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Su, H.; Qi, C.R.; Li, Y.; Guibas, L.J. Render for CNN: Viewpoint Estimation in Images Using CNNs Trained with Rendered 3D Model Views. In Proceedings of the 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, 7–13 December 2015; IEEE Computer Society: Washington, DC, USA, 2015; pp. 2686–2694. [Google Scholar]
- Sundermeyer, M.; Marton, Z.; Durner, M.; Brucker, M.; Triebel, R. Implicit 3D Orientation Learning for 6D Object Detection from RGB Images. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Proceedings, Part VI; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11210, pp. 712–729. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 292–301. [Google Scholar]
- Gupta, K.; Petersson, L.; Hartley, R. CullNet: Calibrated and Pose Aware Confidence Scores for Object Pose Estimation. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Seoul, Korea, 27 October–2 November 2019; pp. 2758–2766. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 6517–6525. [Google Scholar]
- Rad, M.; Lepetit, V. BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 3848–3856. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Proceedings, Part VIII; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9912, pp. 483–499. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Chan, A.; Derpanis, K.G.; Daniilidis, K. 6-DoF object pose from semantic keypoints. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation, ICRA 2017, Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2011–2018. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Oberweger, M.; Rad, M.; Lepetit, V. Making Deep Heatmaps Robust to Partial Occlusions for 3D Object Pose Estimation. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Proceedings, Part XV; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11219, pp. 125–141. [Google Scholar]
- Glasner, D.; Galun, M.; Alpert, S.; Basri, R.; Shakhnarovich, G. Viewpoint-aware object detection and pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011; Metaxas, D.N., Quan, L., Sanfeliu, A., Gool, L.V., Eds.; IEEE Computer Society: Washington, DC, USA, 2011; pp. 1275–1282. [Google Scholar]
- Michel, F.; Kirillov, A.; Brachmann, E.; Krull, A.; Gumhold, S.; Savchynskyy, B.; Rother, C. Global Hypothesis Generation for 6D Object Pose Estimation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 115–124. [Google Scholar]
- Brachmann, E.; Michel, F.; Krull, A.; Yang, M.Y.; Gumhold, S.; Rother, C. Uncertainty-Driven 6D Pose Estimation of Objects and Scenes from a Single RGB Image. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; pp. 3364–3372. [Google Scholar]
- Peng, S.; Liu, Y.; Huang, Q.; Zhou, X.; Bao, H. PVNet: Pixel-Wise Voting Network for 6DoF Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 16–20 June 2019; IEEE Computer Society: Los Alamitos, CA, USA, 2019; pp. 4556–4565. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Gao, X.S.; Hou, X.R.; Tang, J.; Cheng, H.F. Complete solution classification for the perspective-three-point problem. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 930–943. [Google Scholar]
- Hinterstoisser, S.; Lepetit, V.; Ilic, S.; Holzer, S.; Bradski, G.R.; Konolige, K.; Navab, N. Model Based Training, Detection and Pose Estimation of Texture-Less 3D Objects in Heavily Cluttered Scenes. In Computer Vision—ACCV 2012, Proceedings of the 11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Lecture Notes in Computer Science; Revised Selected Papers, Part I; Lee, K.M., Matsushita, Y., Rehg, J.M., Hu, Z., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7724, pp. 548–562. [Google Scholar]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D Object Pose Estimation Using 3D Object Coordinates. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Xiao, J.; Ehinger, K.A.; Hays, J.; Torralba, A.; Oliva, A. SUN Database: Exploring a Large Collection of Scene Categories. Int. J. Comput. Vis. 2016, 119, 3–22. [Google Scholar] [CrossRef] [Green Version]
- Pratt, J.W. Remarks on Zeros and Ties in the Wilcoxon Signed Rank Procedures. Publ. Am. Stat. Assoc. 1959, 54, 655–667. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Two-Stage | End-to-End | |||||||
|---|---|---|---|---|---|---|---|---|
| RPVNet | Heatmap | Tekin [16] | BB8 [19] | Cull [17] | PVNet [29] | Deep6D [10] | SSD-6D [12] | |
| Ape | 55.6 | 42.0 | 21.6 | 40.4 | 55.1 | 43.6 | 38.8 | - |
| Benchvise | 98.7 | 92.7 | 81.8 | 91.8 | 89.0 | 99.9 | 71.2 | - |
| Cam | 83.6 | 82.2 | 36.6 | 55.7 | 66.2 | 86.8 | 52.5 | - |
| Can | 93.2 | 91.3 | 68.8 | 64.1 | 89.2 | 95.5 | 86.1 | - |
| Cat | 75.5 | 73.1 | 41.8 | 62.6 | 75.3 | 79.3 | 66.2 | - |
| Driller | 94.7 | 91.0 | 63.5 | 74.4 | 88.6 | 96.4 | 82.3 | - |
| Duck | 63.5 | 51.4 | 27.2 | 44.3 | 41.8 | 52.6 | 32.5 | - |
| Eggbox | 95.8 | 94.6 | 69.6 | 57.8 | 97.1 | 99.2 | 79.4 | - |
| Glue | 93.4 | 89.8 | 80.0 | 41.2 | 94.6 | 95.7 | 63.7 | - |
| Hole | 82.5 | 79.5 | 42.6 | 67.2 | 68.9 | 81.9 | 56.4 | - |
| Iron | 96.1 | 91.9 | 74.9 | 84.7 | 90.9 | 98.9 | 65.1 | - |
| Lamp | 96.8 | 94.7 | 71.1 | 76.5 | 94.2 | 99.3 | 89.4 | - |
| Phone | 91.5 | 88.5 | 47.7 | 54.0 | 67.6 | 92.4 | 65.0 | - |
| Average | 86.1 | 81.7 | 55.9 | 62.7 | 78.3 | 86.4 | 65.2 | 76.3 |
| Std-Dev | 15.6 | 18.9 | 20.5 | 16.1 | 17.3 | 18.3 | 17.2 | - |
| Wilcoxon | - | Yes | Yes | Yes | Yes | No | Yes | - |
| Two-Stage | End-to-End | |||||
|---|---|---|---|---|---|---|
| RPVNet | Heatmap | Tekin | Oberweger [25] | PVNet | PoseCNN [11] | |
| Ape | 17.9 | 9.8 | 2.48 | 17.6 | 15.8 | 9.6 |
| Can | 69.5 | 49.3 | 17.5 | 53.9 | 63.3 | 45.2 |
| Cat | 19.0 | 11.6 | 0.7 | 3.3 | 16.7 | 0.93 |
| Duck | 31.1 | 20.7 | 1.1 | 19.2 | 25.2 | 19.6 |
| Driller | 63.7 | 48.1 | 7.7 | 62.4 | 65.6 | 41.4 |
| Eggbox | 59.2 | 30.3 | - | 25.9 | 50.2 | 22.0 |
| Glue | 46.6 | 38.5 | 10.1 | 39.6 | 49.6 | 38.5 |
| Holepuncher | 42.8 | 28.7 | 5.45 | 21.3 | 39.6 | 22.1 |
| Average | 43.7 | 29.6 | 6.4 | 30.4 | 40.8 | 24.9 |
| Std-Dev | 19.8 | 15.1 | 5.99 | 19.9 | 19.7 | 15.7 |
| Wilcoxon | - | Yes | Yes | Yes | Yes | Yes |
| Ape | Benchivise | Cam | Can | Cat | Driller | Duck | Eggbox | |
| PVNet | 12.8 | 42.8 | 27.7 | 32.9 | 25.2 | 37.0 | 12.4 | 44.1 |
| RPVNet | 14.1 | 41.7 | 27.3 | 32.6 | 24.9 | 37.2 | 14.8 | 43.5 |
| Glue | Hole | Iron | lamp | Phone | Average | Std-Dev | Wilcoxon | |
| PVNet | 38.1 | 22.4 | 42.0 | 40.9 | 30.9 | 31.5 | 9.5 | No |
| RPVNet | 38.4 | 23.2 | 40.9 | 38.8 | 30.0 | 31.3 | 10.4 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, F.; Liu, C.; Chen, Q. Region Pixel Voting Network (RPVNet) for 6D Pose Estimation from Monocular Image. Appl. Sci. 2021, 11, 743. https://doi.org/10.3390/app11020743
Xiong F, Liu C, Chen Q. Region Pixel Voting Network (RPVNet) for 6D Pose Estimation from Monocular Image. Applied Sciences. 2021; 11(2):743. https://doi.org/10.3390/app11020743
Chicago/Turabian StyleXiong, Feng, Chengju Liu, and Qijun Chen. 2021. "Region Pixel Voting Network (RPVNet) for 6D Pose Estimation from Monocular Image" Applied Sciences 11, no. 2: 743. https://doi.org/10.3390/app11020743
APA StyleXiong, F., Liu, C., & Chen, Q. (2021). Region Pixel Voting Network (RPVNet) for 6D Pose Estimation from Monocular Image. Applied Sciences, 11(2), 743. https://doi.org/10.3390/app11020743