
CT-Video Matching for Retrograde Intrarenal Surgery Based on Depth Prediction and Style Transfer

 , ,
, ,
Abstract
:1. Introduction
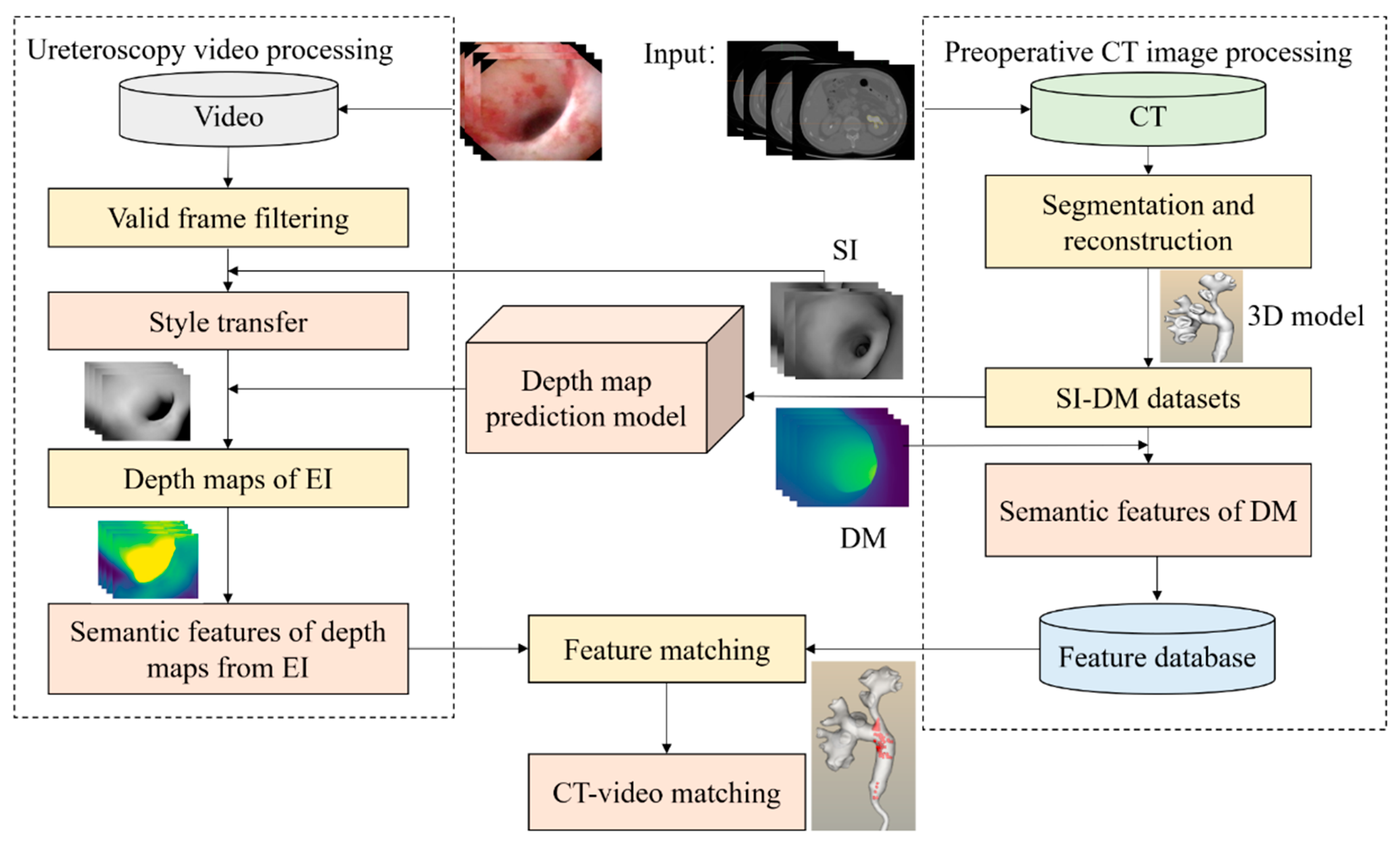
2. Materials and Methods
- (1)
- We first reconstructed a 3D model of the kidney based on CT images.
- (2)
- We used a virtual camera to simulate the movement path of the real ureteroscope to generate pairs of images. Each image pair consists of one simulated image (SI) taken by a virtual camera and its corresponding depth map (DM). We call these pairwise images datasets (simulated images and depth maps) as SI-DM. Based on the SI-DM dataset, we trained a model to predict the depth of simulated images.
- (3)
- We trained a model to transfer the style of endoscopic images (EI) into the style of simulated images mentioned in (2). Then we could indirectly obtain endoscopic images’ depth maps.
- (4)
- Finally, by extracting features of the depth maps from SI and EI and calculating their similarity, we realized CT-video matching to avoid kidney stone misdiagnosis based on the depth maps from (2) and the depth maps from (3).
- We established a corresponding mapping relationship based on the depth map between the white-light ureteroscopic image and the virtual endoscopic image. In other words, we achieved depth prediction based on a single white-light endoscopic image.
- We extract abstract semantic features of the depth map from ureteroscopic images and simulated images captured by the virtual camera for CT-video matching. This approach achieves effective matching and significantly reduces the computational time consumption.
- The results show that our method achieved a 26% improvement in top 10 matching accuracy with a five times improvement in time performance.
2.1. Depth Prediction
2.1.1. Datasets
2.1.2. Loss Function
2.1.3. Implementation Details
2.2. Style Transfer
2.2.1. Datasets
2.2.2. Implementation Details
2.3. Semantic Feature Matching
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Merritt, S.A.; Khare, R.; Bascom, R.; Higgins, W.E. Interactive CT-video registration for the continuous guidance of bronchoscopy. IEEE Trans. Med. Imaging 2013, 32, 1376–1396. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wan, Y.; Wu, Q.; He, X. Dense Feature Correspondence for Video-Based Endoscope Three-Dimensional Motion Tracking. In Proceedings of the IEEE-EMBS International Conference on Biomedical and Health Informatics (BHI 2014), Valencia, Spain, 1–4 June 2014; pp. 49–52. [Google Scholar]
- Luo, X.; Takabatake, H.; Natori, H.; Mori, K. Robust Real-Time Image-Guided Endoscopy: A New Discriminative Structural Similarity Measure for Video to Volume Registration. In Proceedings of the International Conference on Information Processing in Computer-Assisted Interventions (IPCAI 2013), Heidelberg, Germany, 26 June 2013; pp. 91–100. [Google Scholar]
- Billings, S.D.; Sinha, A.; Reiter, A.; Leonard, S.; Ishii, M.; Hager, G.D.; Taylor, R.H. Anatomically Constrained Video-CT Registration via the V-IMLOP Algorithm. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2016), Athens, Greece, 17–21 June 2016; pp. 133–141. [Google Scholar]
- Mirota, D.J.; Wang, H.; Taylor, R.H.; Ishii, M.; Gallia, G.L.; Hager, G.D. A system for video-based navigation for endoscopic endonasal skull base surgery. IEEE Trans. Med. Imaging 2011, 31, 963–976. [Google Scholar] [CrossRef] [PubMed]
- Leonard, S.; Reiter, A.; Sinha, A.; Ishii, M.; Taylor, R.H.; Hager, G.D. Image-Based Navigation for Functional Endoscopic Sinus Surgery Using Structure from Motion. In Proceedings of the Medical Imaging 2016: Image Processing, San Diego, CA, USA, 1–3 March 2016; p. 97840V. [Google Scholar]
- Leonard, S.; Sinha, A.; Reiter, A.; Ishii, M.; Gallia, G.L.; Taylor, R.H.; Hager, G.D. Evaluation and stability analysis of video-based navigation system for functional endoscopic sinus surgery on in vivo clinical data. IEEE Trans. Med. Imaging 2018, 37, 2185–2195. [Google Scholar] [CrossRef] [PubMed]
- Visentini-Scarzanella, M.; Sugiura, T.; Kaneko, T.; Koto, S. Deep monocular 3D reconstruction for assisted navigation in bronchoscopy. Int. J. Comput. Assist. Radiol. Surg. 2017, 12, 1089–1099. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Zeng, H.-Q.; Du, Y.-P.; Cheng, X. Towards Multiple Instance Learning and Hermann Weyl’s Discrepancy for Robust Image-Guided Bronchoscopic Intervention. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2019), Shenzhen, China, 13–17 October 2019; pp. 403–411. [Google Scholar]
- Atapour-Abarghouei, A.; Breckon, T.P. Real-time monocular depth estimation using synthetic data with domain adaptation via image style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2800–2810. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth Map Prediction from a Single Image Using a Multi-Scale Deep Network. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; pp. 2366–2374. [Google Scholar]
- Liu, F.; Shen, C.; Lin, G.; Reid, I. earning Depth from Single Monocular Images Using Deep Convolutional Neural Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2024–2039. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, Y.; Wu, Z.; Shen, C. Estimating Depth from Monocular Images as Classification Using Deep Fully Convolutional Residual Networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 3174–3182. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Shen, C.; Dai, Y.; Hengel, A.V.D.; He, M. Depth and Surface Normal Estimation from Monocular Images Using Regression on Deep Features and Hierarchical CRFs. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 July 2015; pp. 1119–1127. [Google Scholar]
- Wang, P.; Shen, X.; Lin, Z.; Cohen, S.; Price, B.; Yuille, A.L. Towards Unified Depth and Semantic Prediction from a Single Image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2800–2809. [Google Scholar]
- Zhang, Z.; Schwing, A.G.; Fidler, S.; Urtasun, R. Monocular Object Instance Segmentation and Depth Ordering with Cnns. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2614–2622. [Google Scholar]
- Alhashim, I.; Wonka, P. High quality monocular depth estimation via transfer learning. arXiv 2018, arXiv:1812.11941. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2012; pp. 746–760. [Google Scholar]
- Saxena, A.; Sun, M.; Ng, A.Y. Make3D: Learning 3D scene structure from a single still image. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 824–840. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Lorensen, W.E.; Cline, H.E. Marching cubes: A high resolution 3D surface construction algorithm. ACM Siggraph Comput. Graph. 1987, 21, 163–169. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in PyTorch. In Proceedings of the 2017 Neural Information Processing Systems, Long Bench, CA, USA, 4–9 December 2017. [Google Scholar]
- Iandola, F.; Moskewicz, M.; Karayev, S.; Girshick, R.; Darrell, T.; Keutzer, K. Densenet: Implementing Efficient Convnet Descriptor Pyramids. arXiv 2014, arXiv:1404.1869. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Pan, S.J.; Tsang, I.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2010, 22, 199–210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar] [CrossRef] [Green Version]
- Shen, F.; Yan, S.; Zeng, G. Neural Style Transfer via Meta Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8061–8069. [Google Scholar]
- Li, Y.; Wang, N.; Liu, J.; Hou, X. Demystifying Neural Style Transfer. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence; International Joint Conferences on Artificial Intelligence Organization, Melbourne, Australia, 19–25 August 2017; pp. 2230–2236. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Datasets | Training Sets | Test Sets |
|---|---|---|
| 29,608 | 21,429 | 8179 |
| Total Datasets | Source Domain Images | Target Domain Images |
|---|---|---|
| 4514 | 1747 | 2767 |
| Loss Function | Error↓ | Threshold Accuracy↑ | |||||
|---|---|---|---|---|---|---|---|
| RMSE | RMSE (log) | log10 | Rel | δ1 | δ2 | δ3 | |
| L1 | 0.088 | 0.223 | 0.197 | 0.256 | 0.730 | 0.870 | 0.933 |
| L2 | 0.095 | 0.235 | 0.208 | 0.269 | 0.701 | 0.856 | 0.928 |
| SSIM | 0.102 | 0.258 | 0.227 | 0.304 | 0.675 | 0.844 | 0.917 |
| L1 + SSIM | 0.098 | 0.239 | 0.210 | 0.271 | 0.689 | 0.869 | 0.936 |
| L2 + SSIM | 0.091 | 0.223 | 0.198 | 0.256 | 0.721 | 0.881 | 0.941 |
| 2D-2D | Our Approach | ||
|---|---|---|---|
| accuracy | Top1 | 42.92% | 42.31% |
| Top5 | 47.06% | 63.26% | |
| Top10 | 50.43% | 76.54% | |
| time (per picture) | 6.23 s | 1.26 s | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, H.; Pan, Y.; Yu, T.; Fu, Z.; Zhang, C.; Zhang, X.; Wang, P.; Liu, J.; Ye, X.; Duan, H. CT-Video Matching for Retrograde Intrarenal Surgery Based on Depth Prediction and Style Transfer. Appl. Sci. 2021, 11, 9585. https://doi.org/10.3390/app11209585
Lei H, Pan Y, Yu T, Fu Z, Zhang C, Zhang X, Wang P, Liu J, Ye X, Duan H. CT-Video Matching for Retrograde Intrarenal Surgery Based on Depth Prediction and Style Transfer. Applied Sciences. 2021; 11(20):9585. https://doi.org/10.3390/app11209585
Chicago/Turabian StyleLei, Honglin, Yanqi Pan, Tao Yu, Zuoming Fu, Chongan Zhang, Xinsen Zhang, Peng Wang, Jiquan Liu, Xuesong Ye, and Huilong Duan. 2021. "CT-Video Matching for Retrograde Intrarenal Surgery Based on Depth Prediction and Style Transfer" Applied Sciences 11, no. 20: 9585. https://doi.org/10.3390/app11209585