
Semantic Fusion with Deep Learning and Formal Ontologies for Evaluation of Policies and Initiatives in the Smart City Domain

Abstract
:1. Introduction
2. Related Work
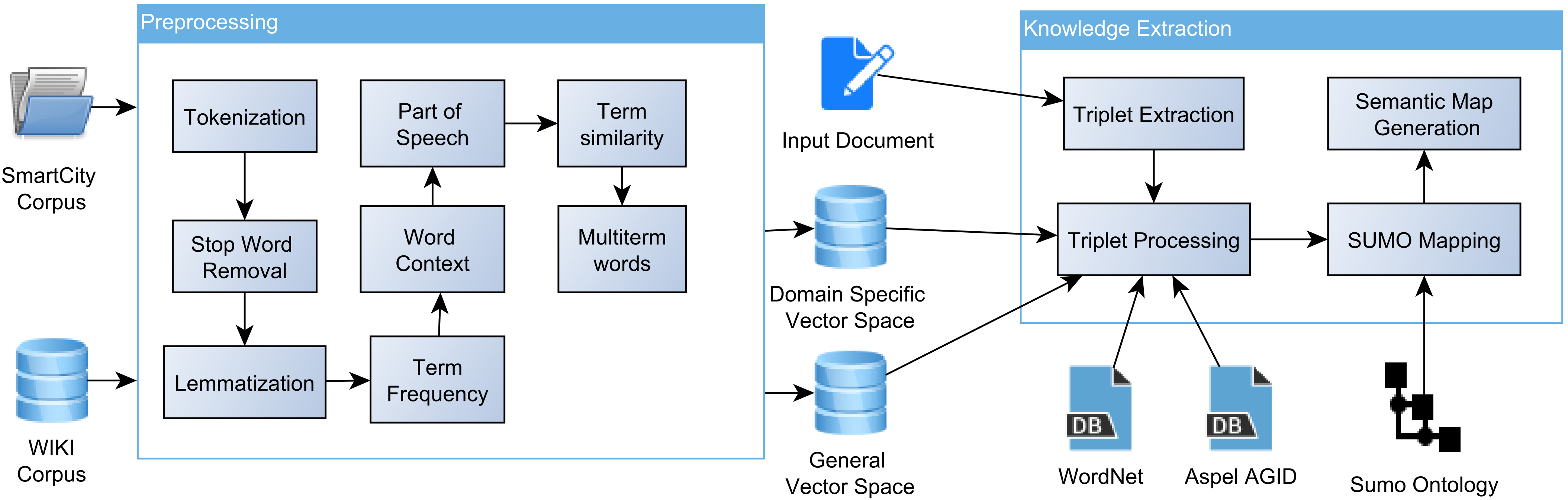
3. Methodology
3.1. Preprocessing
3.2. Knowledge Extraction
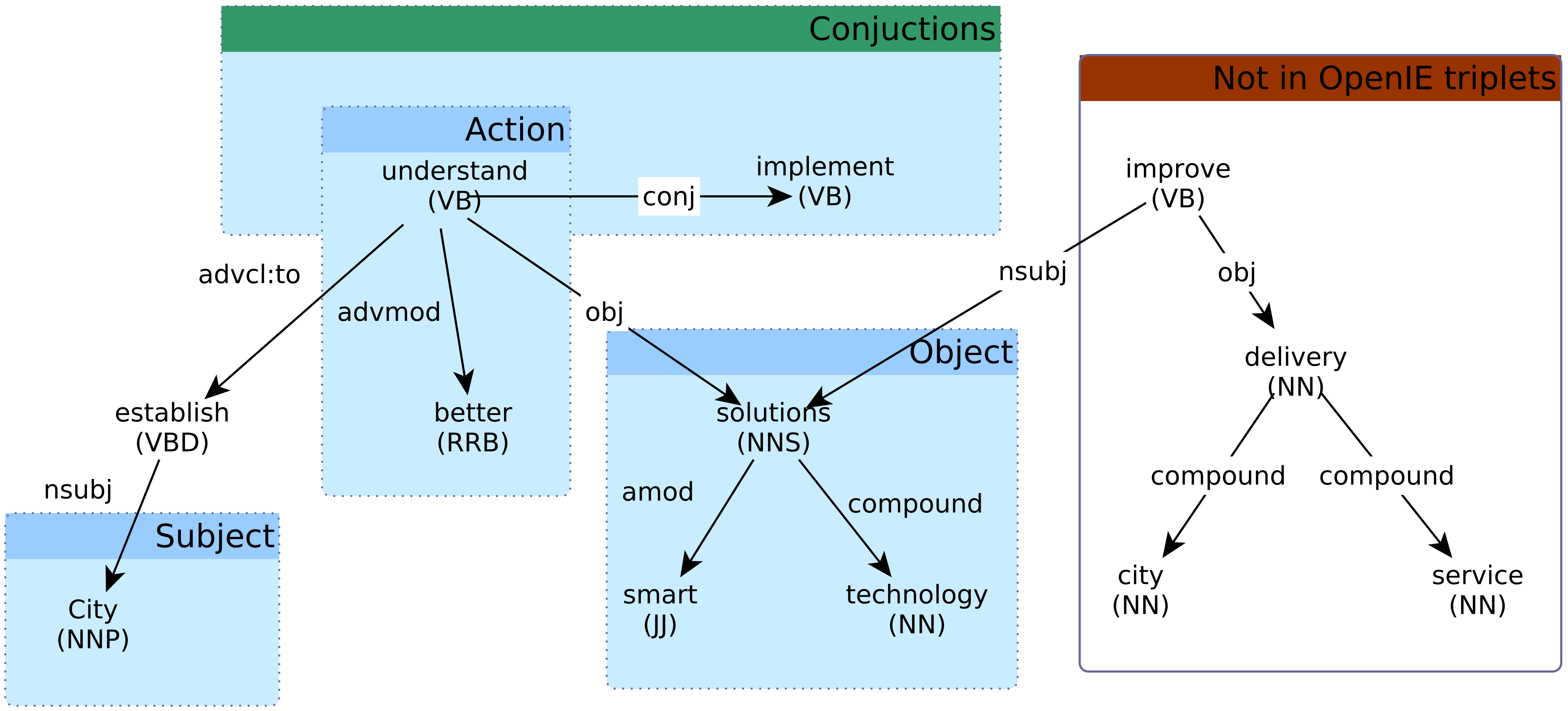
3.2.1. Triplet Extraction
3.2.2. Triplet Preprocessing
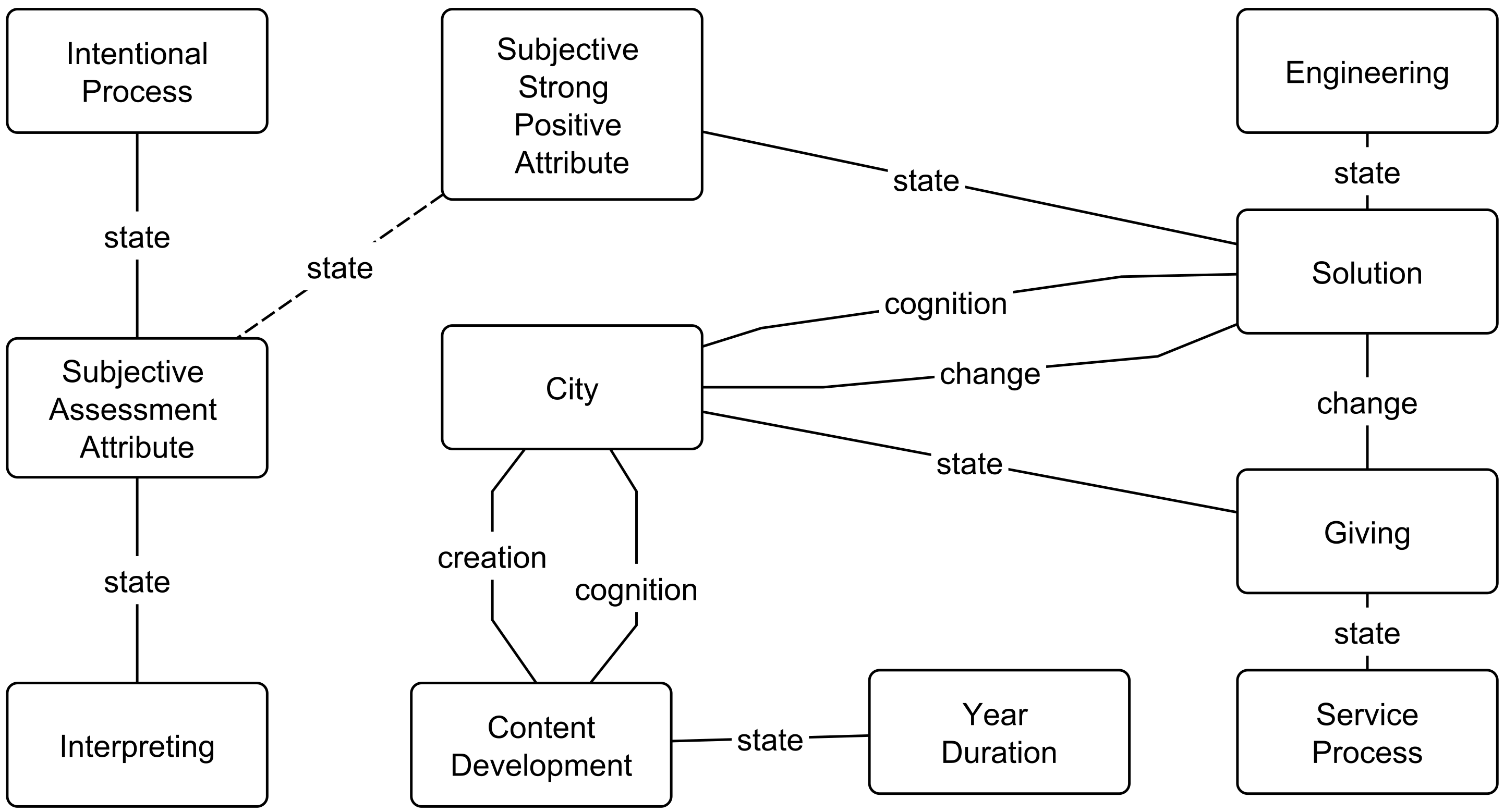
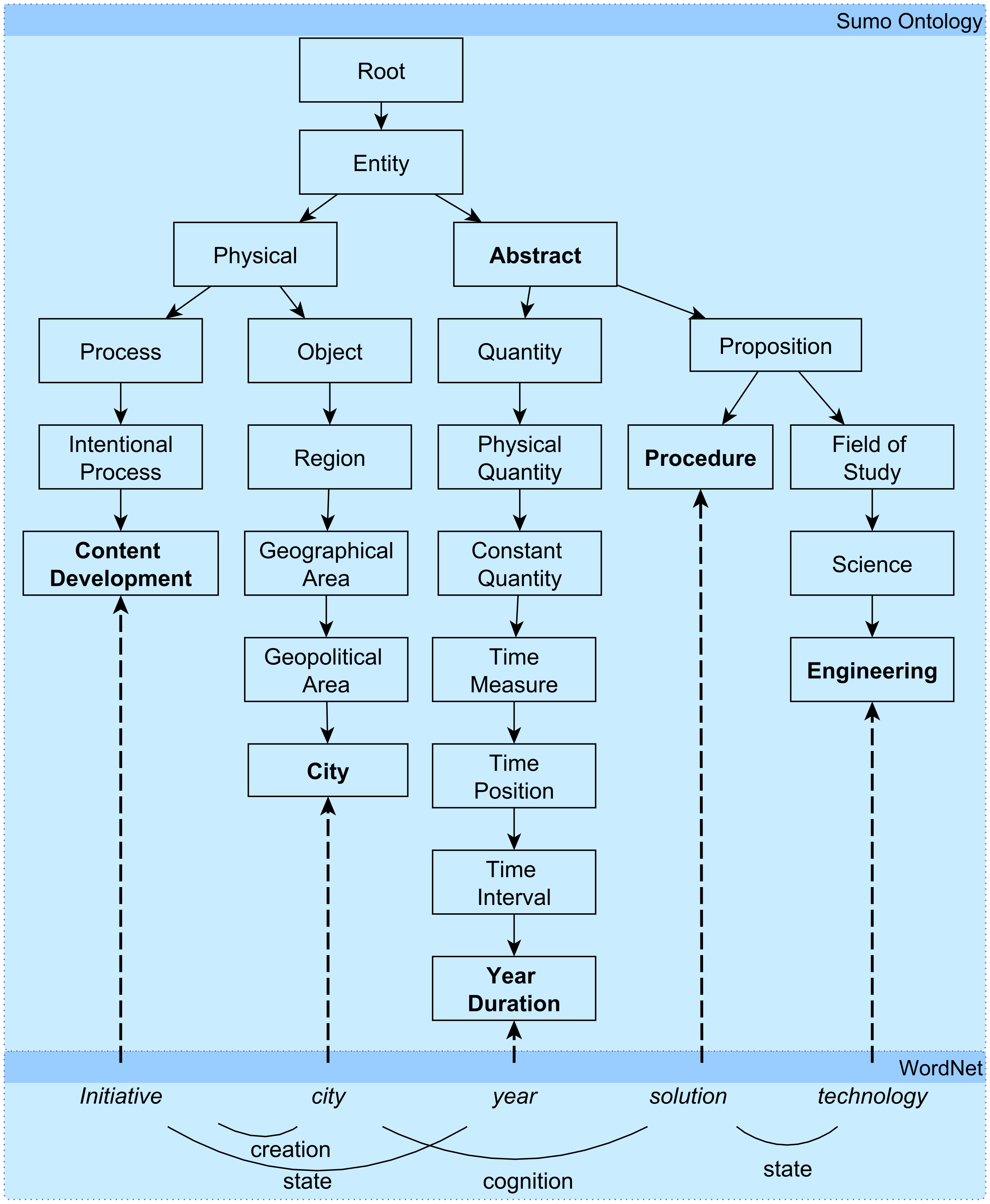
3.2.3. Concept Mapping into the SUMO Ontology
3.2.4. Semantic Map Generation, Aggregation, and Reduction
4. Experiments
4.1. Experimental Setup
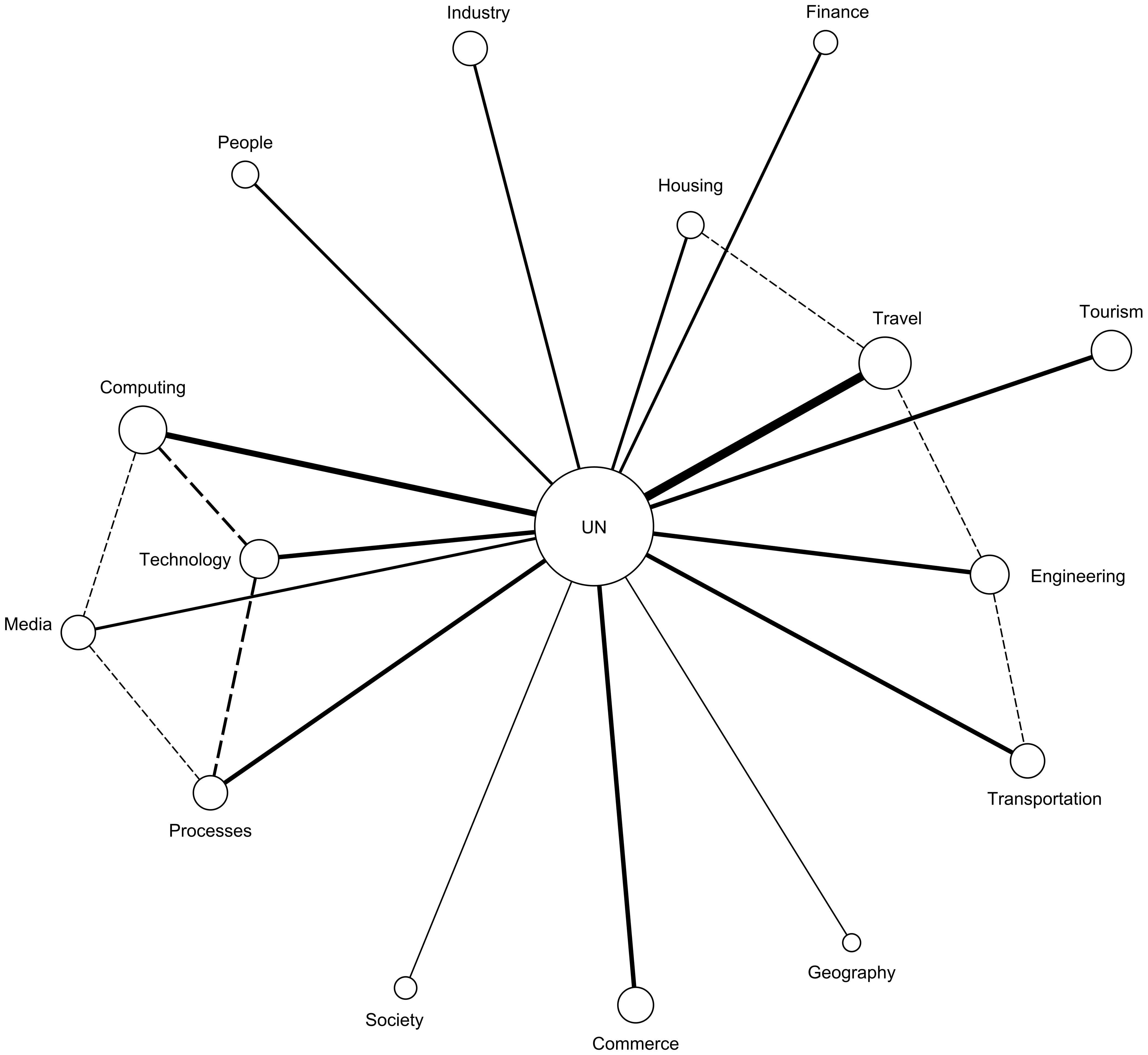
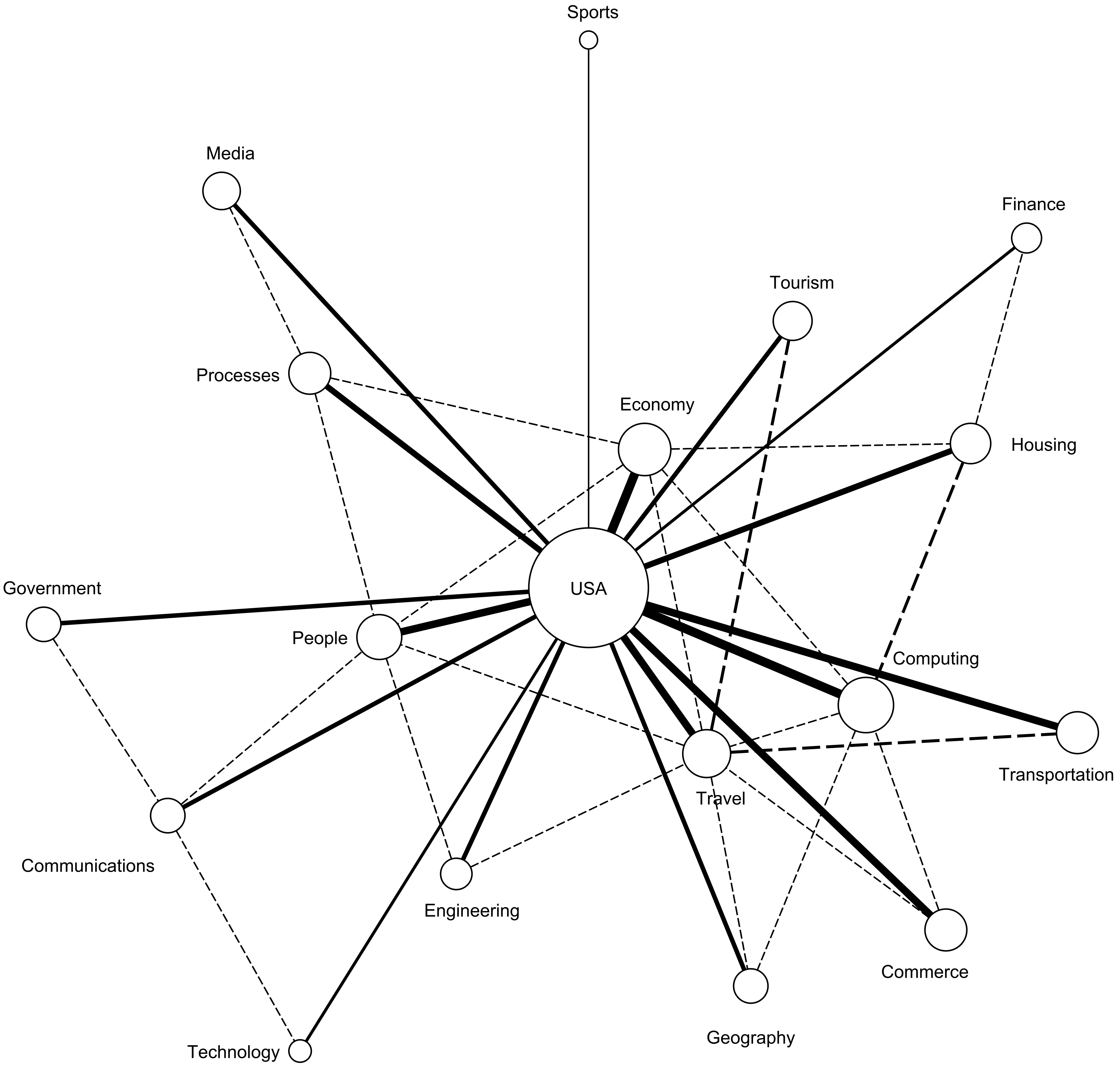
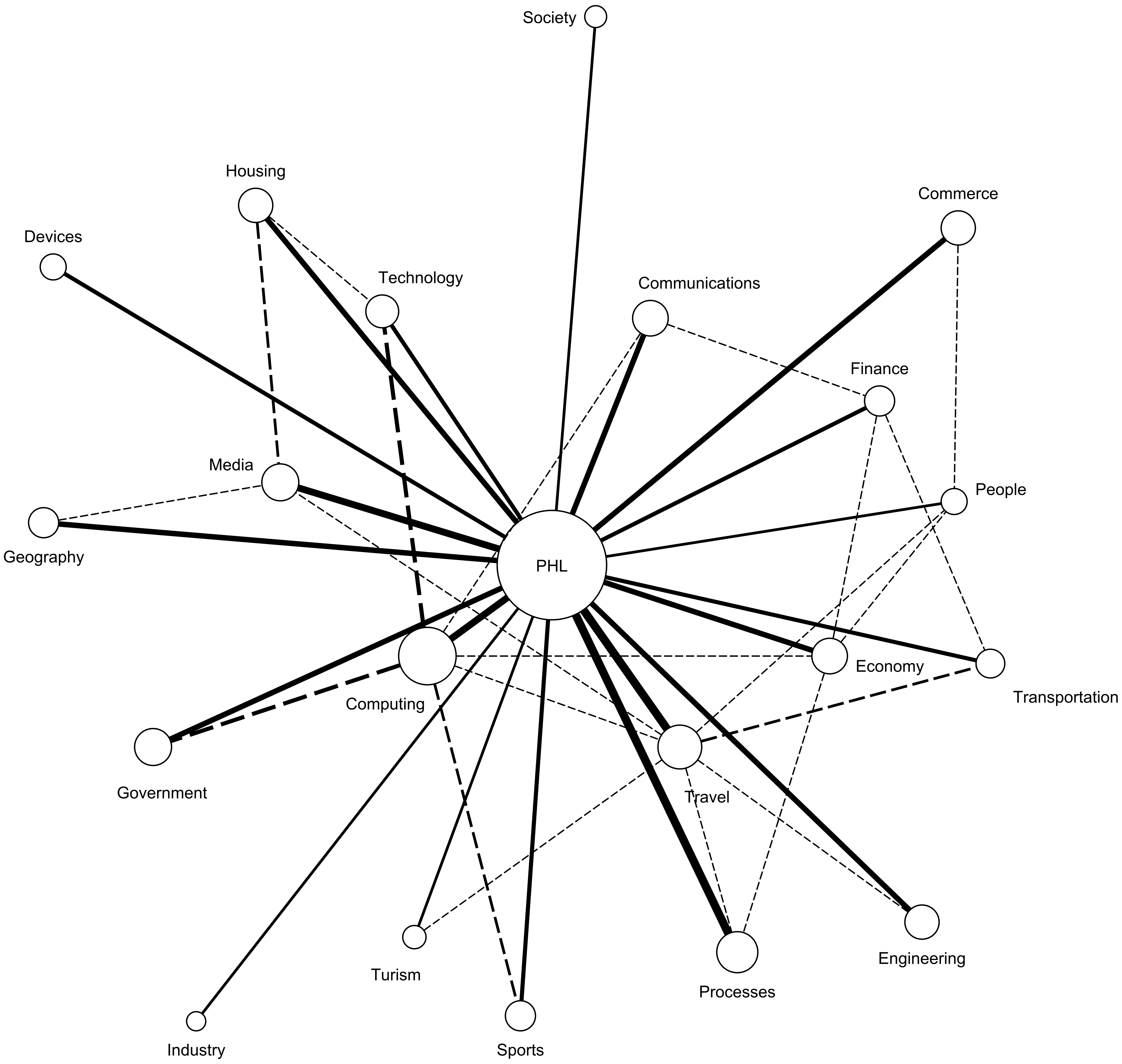
4.2. Results
4.3. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Neirotti, P.; De Marco, A.; Cagliano, A.C.; Mangano, G.; Scorrano, F. Current Trends in Smart City Initiatives: Some Stylised Facts. Cities 2014, 38, 25–36. [Google Scholar] [CrossRef] [Green Version]
- Bakici, T.; Almirall, E.; Wareham, J. A Smart City Initiative: The Case of Barcelona. J. Knowl. Econ. 2012, 4, 135–148. [Google Scholar] [CrossRef]
- Trindade, E.P.; Hinnig, M.P.F.; Da Costa, E.M.; Marques, J.S.; Bastos, R.C.; Yigitcanlar, T. Sustainable Development of Smart Cities: A Systematic Review of the Literature. J. Open Innov. Technol. Mark. Complex. 2017, 3, 11. [Google Scholar] [CrossRef] [Green Version]
- Magro, E.; Wilson, J.R. Complex Innovation Policy Systems: Towards an Evaluation Mix. Res. Policy 2013, 42, 1647–1656. [Google Scholar] [CrossRef]
- Tompson, T. Understanding the Contextual Development of Smart City Initiatives: A Pragmatist Methodology. J. Des. Econ. Innov. 2017, 3, 210–228. [Google Scholar] [CrossRef]
- Gruber, T.R. A Translation Approach to Portable Ontology Specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Giunchiglia, F.; Villafiorita, A.; Walsh, T. Theories of Abstraction. AI Commun. 1997, 10, 167–176. [Google Scholar] [CrossRef]
- Hertz, T.; Mancilla Garcia, M.; Schlüter, M. From Nouns to Verbs: How process ontologies Enhance our Understanding of Social-Ecological Systems Understood as Complex Adaptive Systems. People Nat. 2020, 2, 328–338. [Google Scholar] [CrossRef]
- Resnik, P. Semantic Similarity in a Taxonomy: An Information-Based Measure and its Application to Problems of Ambiguity in Natural Language. J. Artif. Intell. Res. 1999, 11, 95–130. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.S.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Chourabi, H.; Nam, T.; Walker, S.; Gil-Garcia, J.R.; Mellouli, S.; Nahon, K.P.T.A.; Scholl, H.J. Understanding Smart City Initiatives: An Integrative and Comprehensive Theoretical Framework. In Proceedings of the 45th Hawaii International Conference on System Sciences, Maui, HI, USA, 4–7 January 2012. [Google Scholar]
- Alawadhi, S.; Aldama-Nalda, A.; Chourabi, H.; Gil-Garcia, J.R.; Leung, S.; Mellouli, S.; Nam, T.; Pardo, T.; Scholl, H.J.; Walker, S. Building Understanding of Smart City Initiatives. In International Conference on Electronic Government; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7443, pp. 40–53. [Google Scholar]
- Hu, Q.; Zheng, Y. Smart City Initiatives: A Comparative Study of American and Chinese Cities. J. Urban Aff. 2020, 43, 504–525. [Google Scholar] [CrossRef]
- Albino, V.; Berardi, U.; Dangelico, R.M. Smart Cities: Definitions, Dimensions, Performance, and Initiatives. J. Urban Technol. 2015, 22, 3–11. [Google Scholar] [CrossRef]
- Manville, C.; Cochrane, G.; Cave, J.; Millard, J.; Pederson, J.K.; Thaarup, R.K.; Liebe, A.; Wik, A.L.; Wik, M.W.; Massink, R.; et al. Mapping Smart Cities in the EU; Publication Office of the European Union: Brussels, Belgium, 2014. [Google Scholar]
- Angelidou, M. Smart City Policies: A Spatial Approach. Cities 2014, 41, S3–S11. [Google Scholar] [CrossRef]
- Mayangsari, L.; Novani, S. Multi-Stakeholder Co-creation Analysis in Smart City Management: An Experience from Bandung, Indonesia. Procedia Manuf. 2015, 4, 315–321. [Google Scholar] [CrossRef] [Green Version]
- Rodick, D.W. Process Re-engineering and Formal Ontology: A Deweyan Perspective. Philos. Soc. Crit. 2015, 41, 557–576. [Google Scholar] [CrossRef]
- Miller, B. When is Consensus Knowledge Based? Distinguishing Shared Knowledge from mere Agreement. Synthese 2013, 190, 1293–1316. [Google Scholar] [CrossRef] [Green Version]
- Woelert, P. Governing Knowledge: The Formalization Dilemma in the Governance of the Public Sciences. Minerva 2015, 53, 1–19. [Google Scholar] [CrossRef]
- Reed, S.K. A Taxonomic Analysis of Abstraction. Perspect. Psychol. Sci. 2016, 11, 817–837. [Google Scholar] [CrossRef]
- Valaski, J.; Malucelli, A.; Reinehr, S. Ontologies Application in Organizational Learning: A Literature Review. Expert Syst. Appl. 2012, 39, 7555–7561. [Google Scholar] [CrossRef]
- Levin, B. English Verb Classes and Alternations: A Preliminary Investigation; University of Chicago Press: Chicago, IL, USA, 1993. [Google Scholar]
- Fellbaum, C. WordNet. In Theory and Applications of Ontology: Computer Applications; Springer: Dordrecht, The Netherlands, 2010; pp. 231–243. [Google Scholar]
- Gangemi, A.; Guarino, N.; Masolo, C.; Oltramari, A.; Schneider, L. Sweetening Ontologies with DOLCE. In Knowledge Engineering and Knowledge Management: Ontologies and the Semantic Web; Gómez-Pérez, A., Benjamins, V.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2002; pp. 166–181. [Google Scholar]
- Smith, B.; Spear, A.D. Building Ontologies with Basic Formal Ontology; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Pease, A.; Niles, I. IEEE Standard Upper Ontology: A Progress Report. Spec. Issue Ontol. Agents 2002, 17, 65–70. [Google Scholar] [CrossRef]
- Pease, A. Ontology; Articulate Software Press: Angwin, CA, USA, 2011. [Google Scholar]
- Bellini, P.; Benigni, M.; Billero, R.; Nesi, P.; Rauch, N. Km4City Ontology Building vs. Data Harvesting and Cleaning for Smart-City Services. J. Vis. Lang. Comput. 2014, 25, 827–839. [Google Scholar] [CrossRef] [Green Version]
- Qiu, J.; Chai, Y.; Liu, Y.; Gu, Z.; Li, S.; Tian, Z. Automatic Non-Taxonomic Relation Extraction from Big Data in Smart City. IEEE Access 2018, 6, 74854–74864. [Google Scholar] [CrossRef]
- Miguel-Rodríguez, J.D.; Galán-Páez, J.; Aranda-Corral, G.A.; Borrego-Díaz, J. Urban Knowledge Extraction, Representation and Reasoning as a Bridge from Data City towards Smart City. In Proceedings of the International IEEE Conferences on Ubiquitous Intelligence Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016; pp. 968–974. [Google Scholar]
- Jenkins, H.; Ford, S.; Green, J. Spreadable Media: Creating Value and Meaning in a Networked Culture; NYU Press: New York, NY, USA, 2018; Volume 15. [Google Scholar]
- Davies, M. The Corpus of Contemporary American English (COCA): 600 Million Words, 1990-Present. Available online: https://www.english-corpora.org/coca/ (accessed on 5 October 2020).
- Levy, O.; Goldberg, Y.; Dagan, I. Improving Distributional Similarity with Lessons Learned from Word Embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Boleda, G.; Herbelot, A. Formal Distributional Semantics: Introduction to the Special Issue. Comput. Linguist. 2016, 42, 619–635. [Google Scholar] [CrossRef]
- Li, M.; Chen, X.; Li, X.; Ma, B.; Vitanyi, P. The similarity metric. IEEE Trans. Inf. Theory 2004, 50, 3250–3264. [Google Scholar] [CrossRef]
- Atkinson, K. Aspell 0.60.8 Released. 2019. Available online: https://aspell.net/ (accessed on 5 October 2020).
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Inc, P.; Bethard, S.J.; Mcclosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, ML, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Angeli, G.; Johnson Premkumar, M.J.; Manning, C.D. Leveraging Linguistic Structure For Open Domain Information Extraction. In Proceedings of the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 344–354. [Google Scholar]
- Finkel, J.R.; Grenager, T.; Manning, C. Incorporating Non-Local Information into Information Extraction Systems by Gibbs Sampling. In ACL 2005, Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; Association for Computational Linguistics: Stroudsburg, PA, USA, 2005; pp. 363–370. [Google Scholar]
- De Boer, M.; Schutte, K.; Kraaij, W. Knowledge based query expansion in complex multimedia event detection. Multimed. Tools Appl. 2016, 75, 9025–9043. [Google Scholar] [CrossRef] [Green Version]
- Kilicay-Ergin, N.; Barb, A.S. Smart City Document Evaluationto Support Policy Analysis. In Proceedings of the IEEE International System Conference SYSCON2020, Montreal, QC, Canada, 24 August–20 September 2020. [Google Scholar]
- Schvaneveldt, R.W. Pathfinder Associative Networks; Ablex Series in Computational Sciences; Ablex Publishing Corporation: New York, NY, USA, 1990. [Google Scholar]
- United Nations. United Smart Cities (USC)—United Nations Partnership for SDGs Platform. 2015. Available online: https://sustainabledevelopment.un.org/partnership/?p=10009 (accessed on 5 November 2020).
- The White House. FACT SHEET: Administration Announces New Smart Cities Initiative to Help Communities Tackle Local Challenges and Improve City Services. 2015. Available online: https://obamawhitehouse.archives.gov/the-press-office/2015/09/14/fact-sheet-administration-announces-new-smart-cities-initiative-help (accessed on 5 November 2020).
- City of Philadelphia. SmartCityPHL Roadmap. 2019. Available online: https://www.phila.gov/media/20190204121858/SmartCityPHL-Roadmap.pdf (accessed on 5 November 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
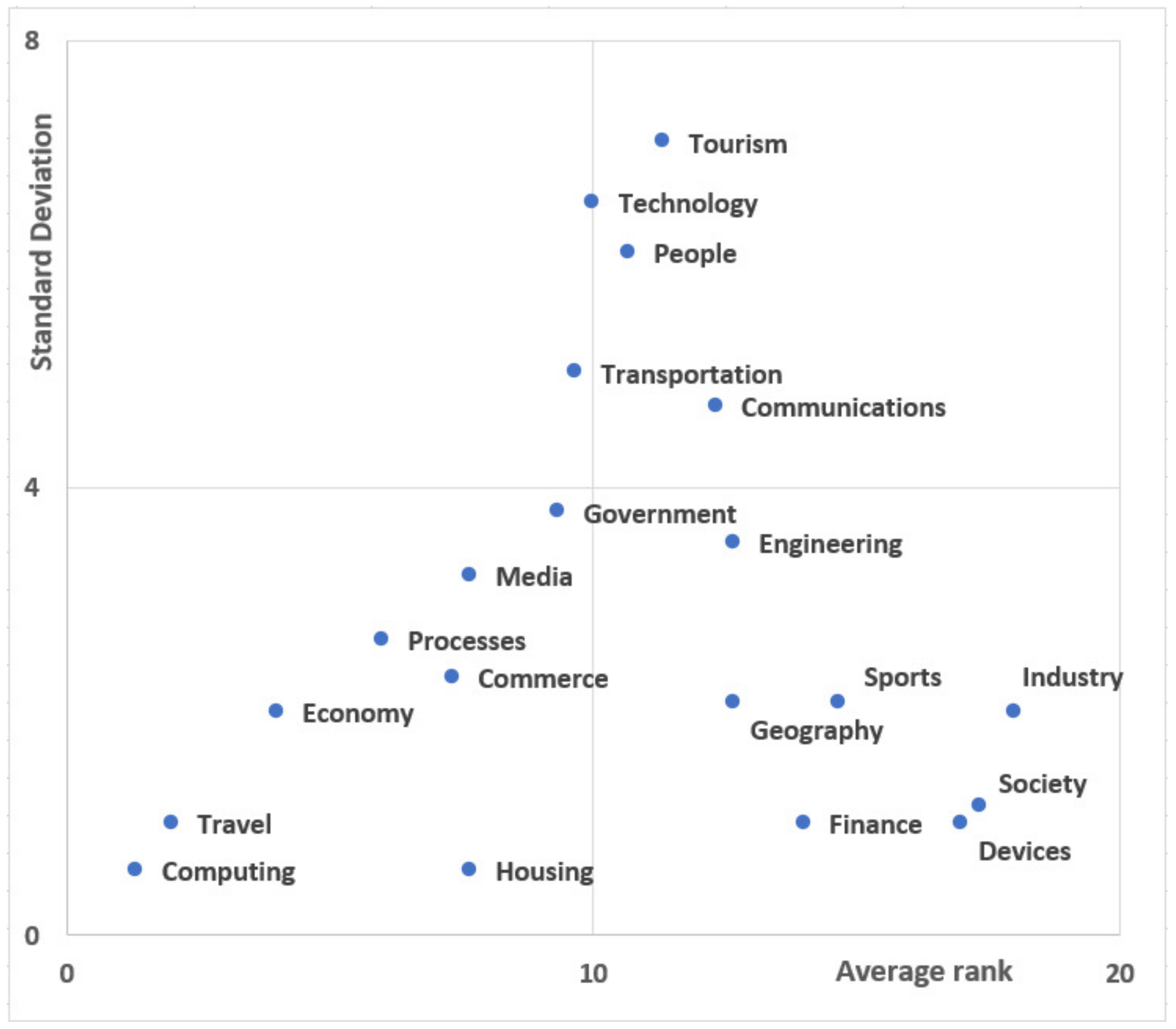{kind=link}
| Cnt | Subject | Action | Object |
|---|---|---|---|
| 1 | City | established initiative in | year |
| 2 | City | understand | technology solutions |
| 3 | City | better understand | smart technology solutions |
| 4 | City | established | initiative |
| 5 | City | understand | smart technology solutions |
| 6 | City | better understands | technology solutions |
| Cnt | Subject | Action | Object |
|---|---|---|---|
| 1.1 | city | establish | initiative |
| 1.2 | initiative | relate to | year |
| 2.1 | city | understand | solution |
| 2.2 | solutions | relate to | technology |
| 2.3 | city | implement | solution |
| 3.2 | understand | has property | better |
| 3.3 | solution | has property | smart |
| 3.2 | implements | has property | better |
| 4 | city | establish | initiative |
| 7 | solution | improve | delivery |
| 8 | delivery | relate to | city |
| 9 | delivery | relate to | service |
| Cnt | Type | Term | SUMO Concept |
|---|---|---|---|
| 1.1 | Subject | city | City |
| Action | creation | ||
| Object | initiative | Content Development | |
| 1.1 | Subject | city | City |
| Action | creation | ||
| Object | initiative | Content Development | |
| 1.2 | Subject | initiative | Content Development |
| Action | state | ||
| Object | year | Year Duration | |
| 2.1 | Subject | city | City |
| Action | cognition | ||
| Object | solution | Procedure | |
| 2.2 | Subject | solution | Procedure |
| Action | state | ||
| Object | technology | Engineering | |
| 2.3 | Subject | city | City |
| Action | change | ||
| Object | solution | Procedure | |
| 3.2 | Subject | understanding | Interpreting |
| Action | state | ||
| Object | quality | Subjective Assessment Attribute | |
| 3.3 | Subject | solution | Procedure |
| Action | state | ||
| Object | smart | Subjective Strong Positive Attribute | |
| 3.2 | Subject | implementation | Intentional Process |
| Action | state | ||
| Object | quality | Subjective Assessment Attribute | |
| 4 | Subject | city | City |
| Action | cognition | ||
| Object | initiative | Content Development | |
| 7 | Subject | solution | Procedure |
| Action | change | ||
| Object | delivery | Giving | |
| 8 | Subject | delivery | Giving |
| Action | state | ||
| Object | city | City | |
| 9 | Subject | delivery | Giving |
| Action | state | ||
| Object | service | Service Process |
| Stage | United Nations | United States | Philadelphia | |||
|---|---|---|---|---|---|---|
| Concepts | Triplets | Concepts | Triplets | Concepts | Triplets | |
| Original | 183 | 301 | 425 | 820 | 496 | 893 |
| Inflected | 161 | 285 | 339 | 802 | 406 | 862 |
| Replace Action | 161 | 269 | 339 | 767 | 406 | 819 |
| SUMO | 167 | 967 | 297 | 2177 | 327 | 2501 |
| SUMO Level 5 | 88 | 997 | 140 | 1820 | 150 | 2066 |
| SUMO Files | 16 | 63 | 18 | 137 | 21 | 174 |
| United Nations | United States | Philadelphia | |
|---|---|---|---|
| United Nations | 0.40 | 0.46 | |
| United States | 0.43 | 0.67 | |
| Philadelphia | 0.32 | 0.42 |
| Goal | U.N. | U.S.A. | PHL. | |||
|---|---|---|---|---|---|---|
| Act | Pred | Act | Pred | Act | Pred | |
| City Services | x | 3 | x | 1 | x | 1 |
| Clean Energy | x | 7 | 11 | 11 | ||
| Climate Change | x | 4 | x | 6 | 4 | |
| Demographic Changes | x | 2 | 9 | 9 | ||
| Economic Growth | 10 | x | 3 | 8 | ||
| Energy Consumption | 9 | 4 | x | 3 | ||
| Public–Private Partnership | x | 8 | 7 | x | 5 | |
| Public Safety | 11 | x | 10 | 10 | ||
| Quality of Life | x | 5 | x | 2 | x | 2 |
| Traffic management | 6 | x | 5 | 6 | ||
| Urban Migration | x | 1 | 8 | 7 | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kilicay-Ergin, N.; Barb, A.S. Semantic Fusion with Deep Learning and Formal Ontologies for Evaluation of Policies and Initiatives in the Smart City Domain. Appl. Sci. 2021, 11, 10037. https://doi.org/10.3390/app112110037
Kilicay-Ergin N, Barb AS. Semantic Fusion with Deep Learning and Formal Ontologies for Evaluation of Policies and Initiatives in the Smart City Domain. Applied Sciences. 2021; 11(21):10037. https://doi.org/10.3390/app112110037
Chicago/Turabian StyleKilicay-Ergin, Nil, and Adrian S. Barb. 2021. "Semantic Fusion with Deep Learning and Formal Ontologies for Evaluation of Policies and Initiatives in the Smart City Domain" Applied Sciences 11, no. 21: 10037. https://doi.org/10.3390/app112110037
APA StyleKilicay-Ergin, N., & Barb, A. S. (2021). Semantic Fusion with Deep Learning and Formal Ontologies for Evaluation of Policies and Initiatives in the Smart City Domain. Applied Sciences, 11(21), 10037. https://doi.org/10.3390/app112110037