
Generating Scenery Images with Larger Variety According to User Descriptions



Abstract
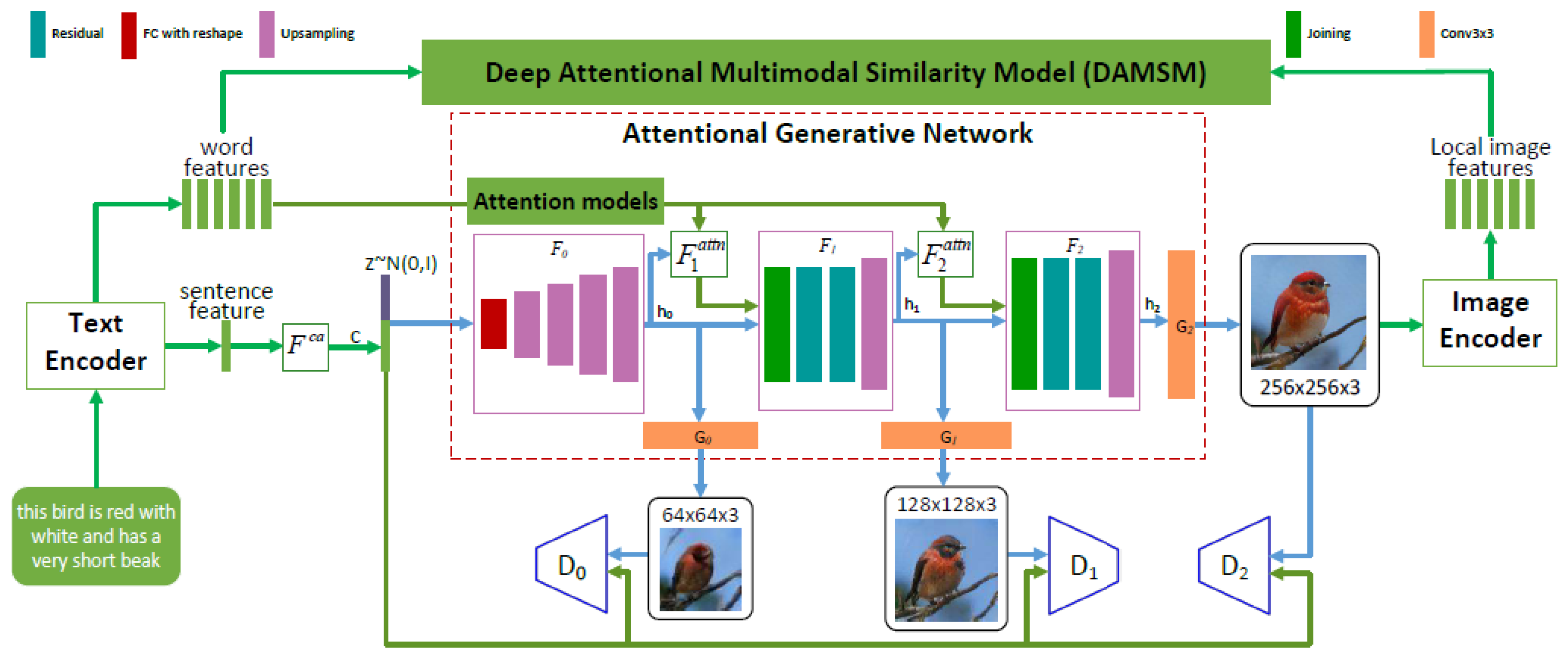
:1. Introduction
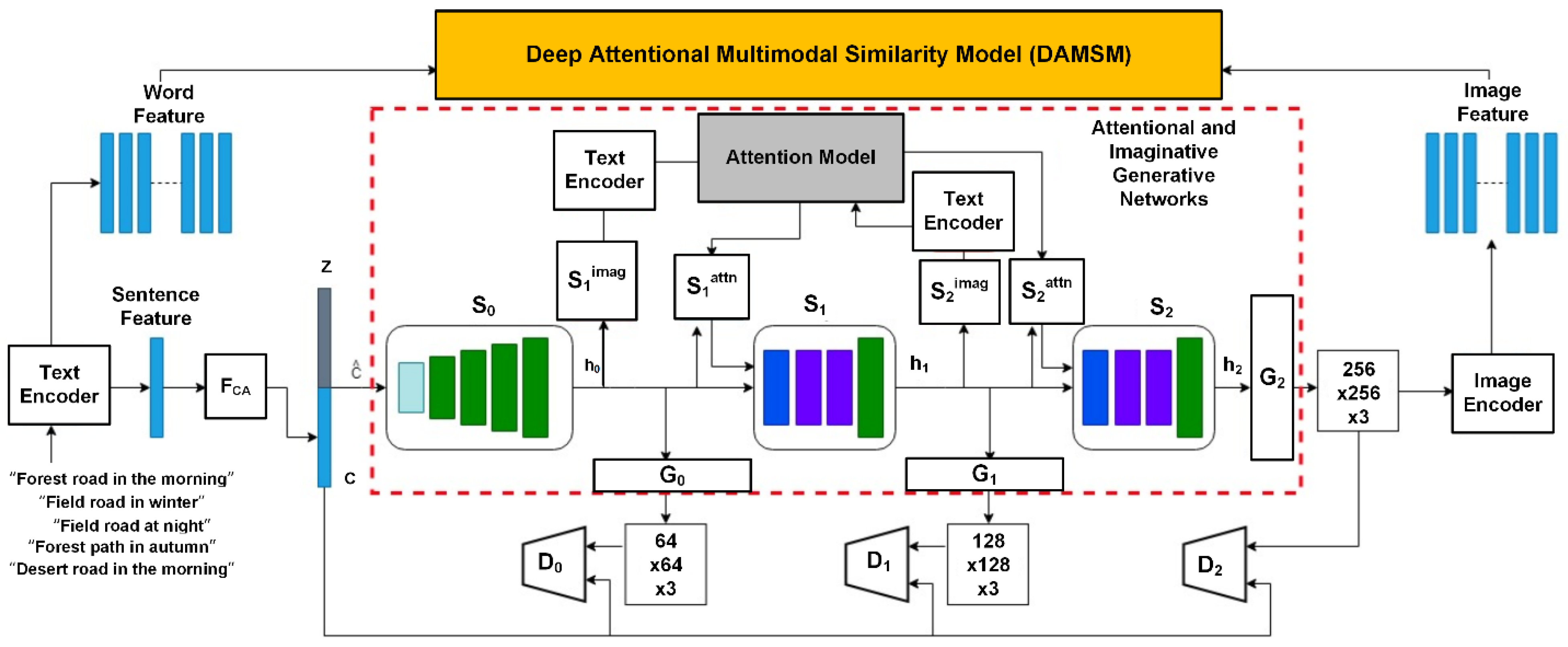
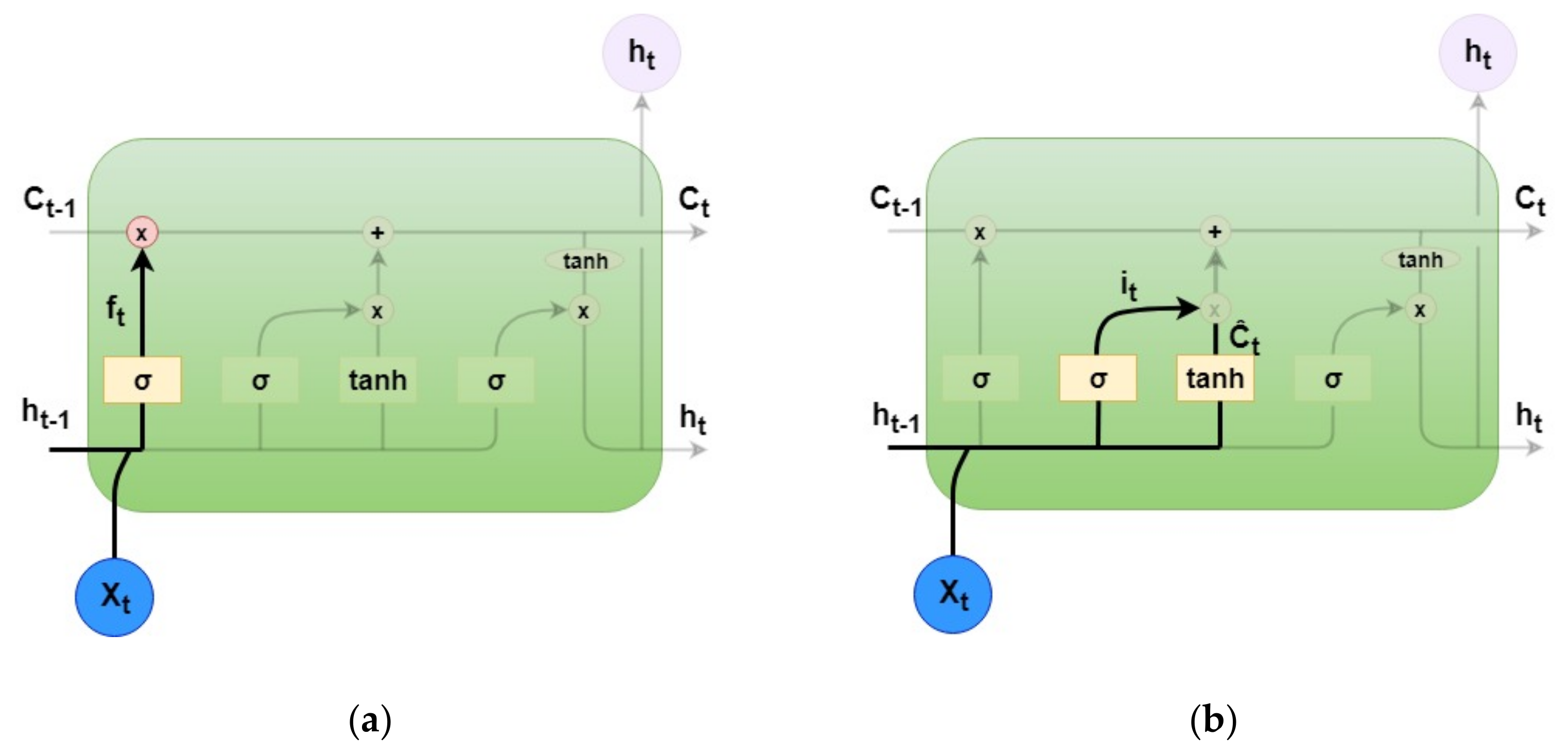
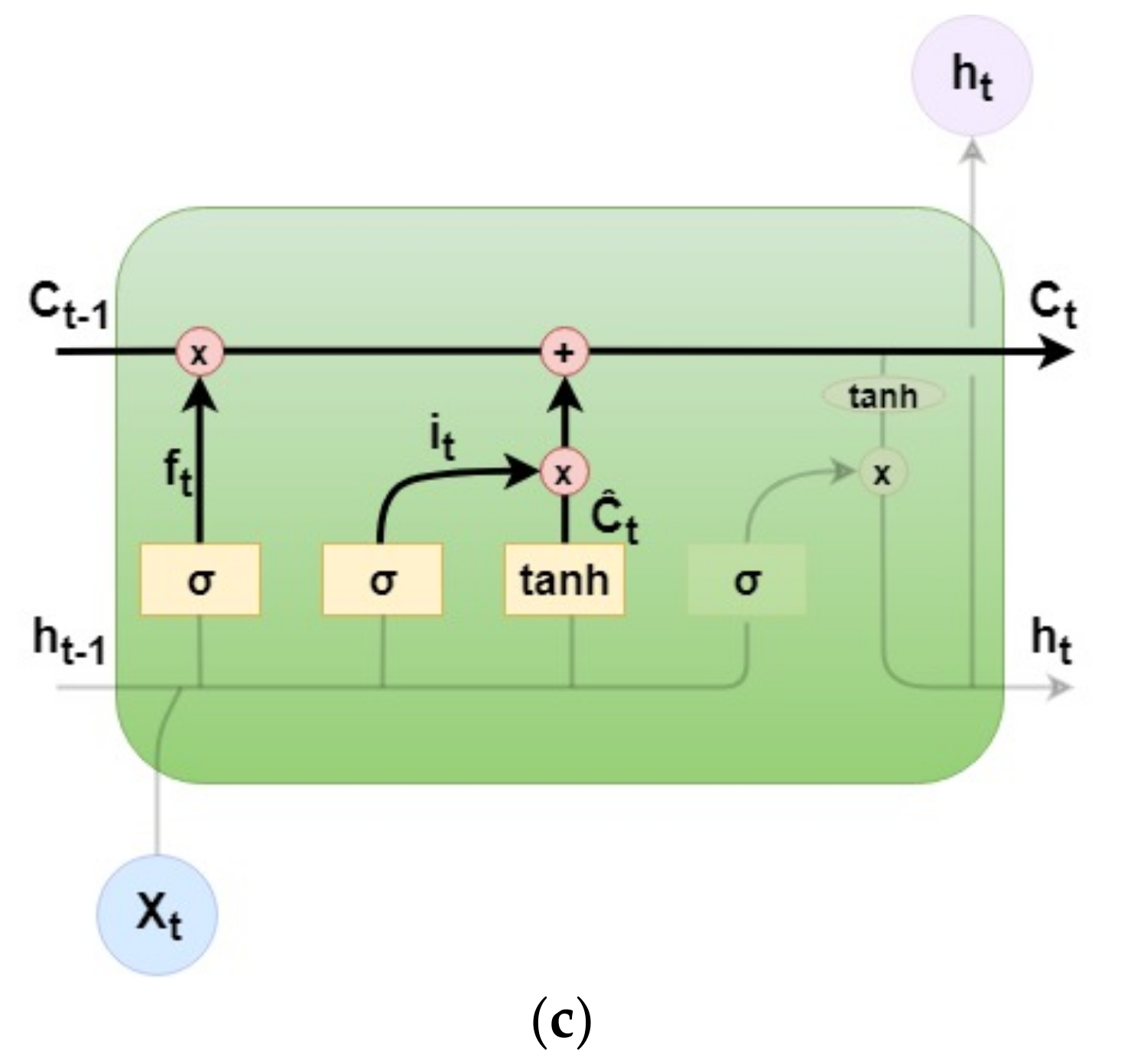
2. Attentional and Imaginative Generative Networks for Scenery Image Generation
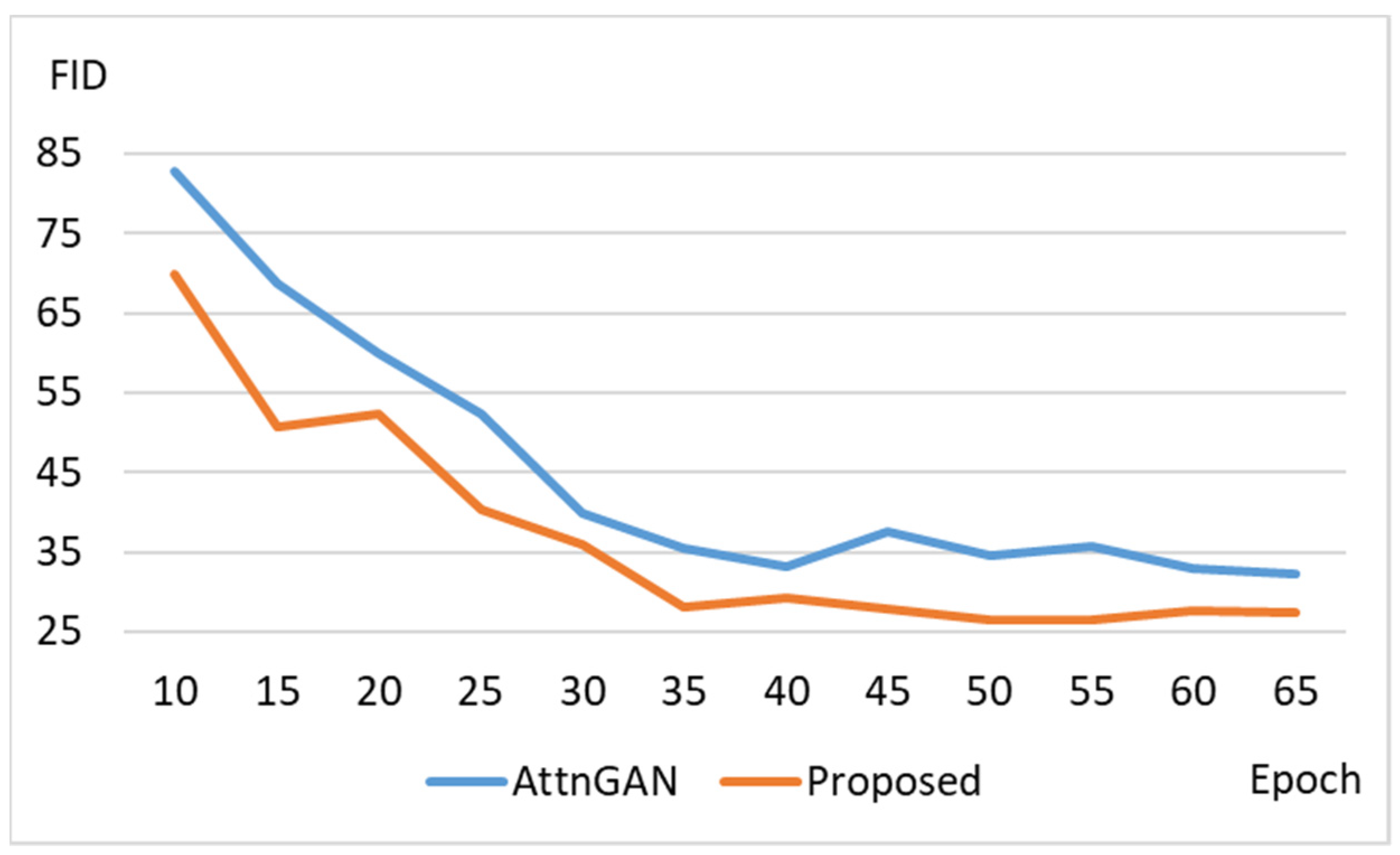
3. Experimental Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Acknowledgments
Conflicts of Interest
Appendix A
References
- Ian, J.G.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networksvol. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS); MIT Press: Cambridge, MA, USA, 2014; pp. 2672–2680. [Google Scholar]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent Progress on Generative Adversarial Networks (GANs): A Survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016; Volume 1511, p. 06434. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. Available online: https://arxiv.org/abs/1411.1784 (accessed on 2 March 2021).
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. arXiv 2016, arXiv:1606.03657. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classier GANs. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2642–2651. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 214–223. [Google Scholar]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled generative adversarial networks. In Proceedings of the Proceedings International Conference on Learning Representations, Toulon, France, 24–26 April 2017; pp. 1–25. [Google Scholar]
- Nguyen, T.D.; Le, T.; Vu, H.; Phung, D. Dual Discriminator Generative Adversarial Nets. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 2672–2680. [Google Scholar]
- Chen, Q.; Koltun, V. Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1520–1529. [Google Scholar]
- Ozkan, S.; Ozkan, A. Kinshipgan: Synthesizing of Kinship Faces from Family Photos by Regularizing a Deep Face Network. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 2142–2146. [Google Scholar]
- Chen, W.; Hays, J. SketchyGAN: Towards Diverse and Realistic Sketch to Image Synthesis. In Proceedings of the IEEE Con-ference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 9416–9425. [Google Scholar]
- Chen, Y.S.; Wang, Y.C.; Kao, M.H.; Chuang, Y.Y. Deep Photo Enhancer: Unpaired Learning for Image Enhancement from Photographs with GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6306–6314. [Google Scholar]
- Zhang, Z.; Xie, Y.; Yang, L. Photographic Text-to-Image Synthesis with a Hierarchically-Nested Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6199–6208. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.J.; Wierstra, D. DRAW: A Recurrent Neural Network for Image Generation. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 1462–1471. [Google Scholar]
- Jin, Y.; Zhang, J.; Li, M.; Tian, Y.; Zhu, H. Towards the high-quality anime characters generation with generative adversarial network. In Proceedings of the Machine Learning for Creativity and Design, NIPS Workshop, Long Beach, CA, USA, 8 December 2017; pp. 1–13. [Google Scholar]
- van den Oord, A.; Kalchbrenner, N.; Vinyals, O.; Espeholt, L.; Graves, A.; Kavukcuoglu, K. Conditional Image Generation with PixelCNN Decoders. In Proceedings of the Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 4797–4805. [Google Scholar]
- Ledig, C.; Theis, L.; Huszar, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and locally consistent image completion. ACM Trans. Graph. 2017, 36, 107. [Google Scholar] [CrossRef]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 10004. [Google Scholar]
- Yu, Y.; Huang, Z.; Li, F.; Zhang, H.; Le, X. Point Encoder GAN: A deep learning model for 3D point cloud inpainting. Neurocomputing 2020, 384, 192–199. [Google Scholar] [CrossRef]
- Shin, H.; Tenenholtz, N.A.; Tenenholtz, A.; Rogers, J.; Schwarz, C.; Senjem, M.; Gunter, J.; Andriole, K.; Michalski, M. Medical Image Synthesis for Data Augmentation and Anonymization Using Generative Adversarial Networks. In Proceedings of the International Workshop on Simulation and Synthesis in Medical Imaging, Granada, Spain, 16 September 2018; pp. 1–11. [Google Scholar]
- Tian, Y.; Pei, K.; Jana, S.; Ray, B. DeepTest: Automated Testing of Deep-Neural-Network-driven Autonomous Cars. In Proceedings of the International Conference on Software Engineering 2018, Gothenburg, Sweden, 27 May–3 June 2018; pp. 303–314. [Google Scholar]
- Fang, H.; Gupta, S.; Iandola, F.N.; Srivastava, R.K.; Deng, L.; Doll´ar, P.; Gao, J.; He, X.; Mitchell, M.; Platt, J.C.; et al. From captions to visual concepts and back. In Proceedings of the IEEE Conference on Computer Vision and Pat-tern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 1473–1482. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative Adversarial Text to Image Synthesis. In Proceedings of the International Conference on Machine Learning, New York City, NY, USA, 19–24 June 2016; pp. 1060–1069. [Google Scholar]
- Gan, Z.; Gan, C.; He, X.; Pu, Y.; Tran, K.; Gao, J.; Carin, L.; Deng, L. Semantic compositional networks for visual captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 1141–1150. [Google Scholar]
- Reed, S.; Akata, Z.; Schiele, B.; Lee, H. Learning Deep Representations of Fine-grained Visual Descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 49–58. [Google Scholar]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D. StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5908–5916. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1316–1324. [Google Scholar]
- Zhu, Y.; Elhoseiny, M.; Liu, B.; Peng, X.; Elgammal, A. A generative adversarial approach for zero-shot learning from noisy texts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1004–1013. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. In Proceedings of the Association for the Advancement of Artificial Intelligence (AAAI), Montréal, QC, Canada, 15–18 May 2017; pp. 2852–2858. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Duerig, T.; et al. The Open Images Dataset V4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. A 10 million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 1452–1464. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Salimans, T.; Goodfellow, I.J.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Proceedings of the International Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 6629–6640. [Google Scholar]
- Ying, G.; Zou, Y.; Wan, L.; Hu, Y.; Feng, J. Better guider predicts future better: Difference guided generative adversarial networks. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Endo, Y.; Kanamori, Y.; Kuriyama, S. Animating landscape: Self-supervised learning of decoupled motion and appearance for single-image video synthesis. ACM Trans. Graph. 2019, 38, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Kwon, Y.; Park, M.G. Predicting future frames using retrospective cycle GAN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1811–1820. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | |
| CPU | i7-8700k |
| RAM | 64GB |
| GPU | nvidia 1080ti |
| Environment | |
| OS | Ubuntu 16.04.5 LTS |
| Docker | 18.06.1-ce |
| Python | python3.5.2 |
| IDE | Vscode1.34.0 |
| Tools | |
| pytorch | 1.0.1post2 |
| easydict | 1.9 |
| python-dateutil | 2.7.2 |
| pandas | 0.22.0 |
| torchfile | 0.1.0 |
| nltk | 3.4 |
| scikit-image | 0.14.2 |
| piexif | 1.1.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, H.-Y.; Yu, C.-C. Generating Scenery Images with Larger Variety According to User Descriptions. Appl. Sci. 2021, 11, 10224. https://doi.org/10.3390/app112110224
Cheng H-Y, Yu C-C. Generating Scenery Images with Larger Variety According to User Descriptions. Applied Sciences. 2021; 11(21):10224. https://doi.org/10.3390/app112110224
Chicago/Turabian StyleCheng, Hsu-Yung, and Chih-Chang Yu. 2021. "Generating Scenery Images with Larger Variety According to User Descriptions" Applied Sciences 11, no. 21: 10224. https://doi.org/10.3390/app112110224
APA StyleCheng, H.-Y., & Yu, C.-C. (2021). Generating Scenery Images with Larger Variety According to User Descriptions. Applied Sciences, 11(21), 10224. https://doi.org/10.3390/app112110224