
Efficient Use of GPU Memory for Large-Scale Deep Learning Model Training



Abstract
:1. Introduction
- First, we propose the most efficient memory advise for the three types of data required for deep learning. Deep learning data can be divided into three types according to access patterns: model parameters, input data, and intermediate results. Further, memory advise can manage data by dividing it into three types: Read mostly, Preferred location, and Access by. In addition, the access patterns of the three types of deep learning data are similar to those that can be managed with memory advise. Therefore, it is possible to efficiently utilize GPU memory by setting three types of deep learning data as appropriate memory advise. We conducted an experiment to train a large-scale model, BERT-Large [18], by applying our optimized memory advise scheme, and analyze the results of the experiment to suggest efficient memory advise.
- Second, we apply CUDA Unified Memory to PyTorch and set different memory advises for three types of data required for deep learning. It is difficult to train a large-scale model due to the limitation of single GPU memory. Existing PyTorch does not support CUDA Unified Memory technology, so it is impossible to perform deep learning if a memory size larger than the available GPU memory is required to perform deep learning. Most of the deep learning models that achieve high accuracy are very large, such as BERT. Therefore, we apply CUDA Unified Memory technology by modifying PyTorch, an open source deep learning framework, to train large-scale learning models that can achieve high accuracy. In addition, we use the modified PyTorch to verify efficient memory advise through an experiment in which we actually perform large-scale model training.
2. Background
2.1. CUDA Unified Memory
2.2. How to Use CUDA Unified Memory Efficiently
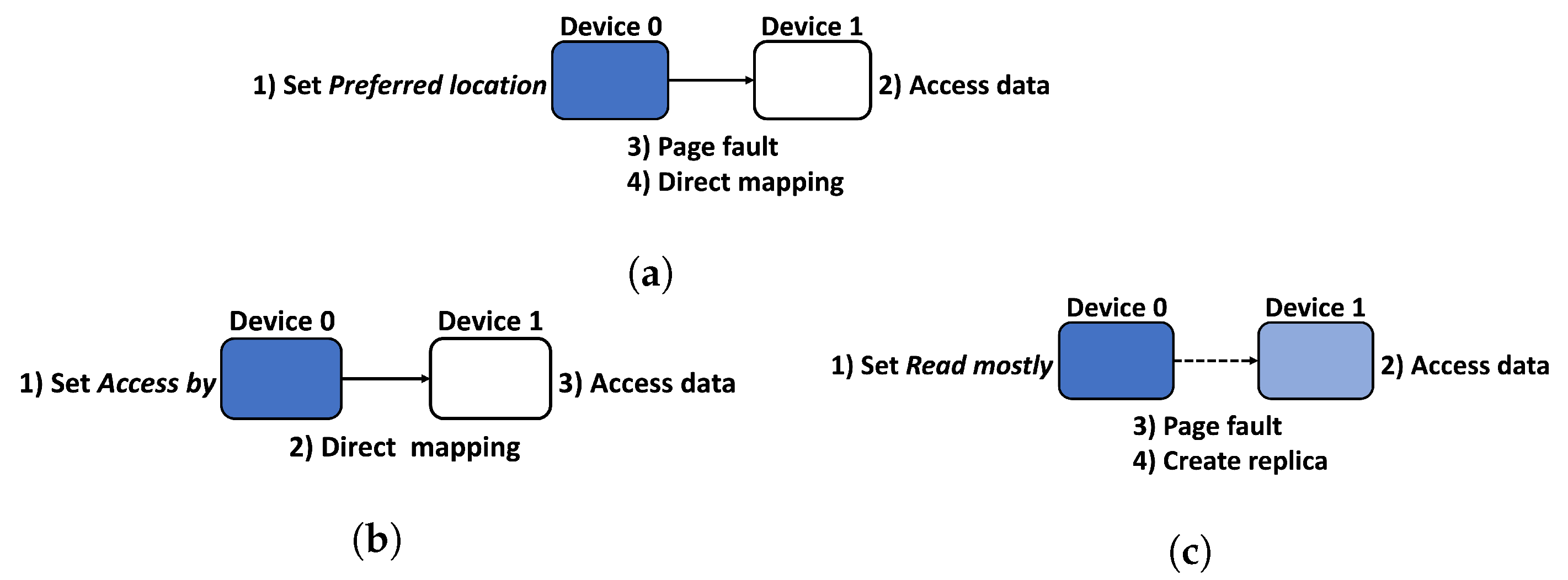
- Preferred location can set the physical location where data are actually stored. Data set as Preferred location are fixed in the designated physical location. Therefore, if the data are accessed from another device, data are not migrated to the device but data are directly mapped. For example, as shown in Figure 1a, if Device 1 attempts to access data fixed to Device 0, a page fault occurs in the first access. After the page fault, the data that are set as the Preferred location and fixed to Device 0 are mapped directly to the Device 1 instead of unmapping them from the memory of Device 0 and migrating to Device 1 memory. Therefore, the next time the Device 1 accesses the data, a page fault will not occur. Preferred location can operate efficiently when specific data needs to be physically fixed in specific device.
- Access by specifies direct mapping to a specific device, as depicted in Figure 1b; therefore, a device that is directly mapped by designating Access by does not generate a page fault when accessing the corresponding data. The difference between data set as Access by and data set as Preferred location is that data set as Access by are not fixed to a specific device but can be moved freely; therefore, the direct mapped device has the advantage that the data can be accessed without a page fault no matter where they are physically located; however, in the case of frequently accessed data, they may be an overhead because it takes a long time to access them because they are physically located on a different device.
- Read mostly can be used efficiently when applied to read-intensive data. As you can see from Figure 1c, if data set to Read mostly are accessed by a device that is not physically stored, a replica is created on the accessed device instead of migrating the accessed data to the device that accessed the data. Therefore, the data set to Read mostly have the advantage that it can be accessed quickly from the device because there are copies in the device’s memory after a page fault occurs in the first access; however, if the data set to Read mostly are modified, there is a disadvantage that the data must be modified for all devices where replication exists.
2.3. PyTorch
3. Efficient Data Management Scheme for Deep Learning
- First, there are model parameters. Model parameters are generated and initialized before starting deep learning. Model parameters are weights for the features of the input data. When performing feed forwarding, the weight of each hidden layer(part of model parameters) generates feature map data to be passed to the next hidden layer through mathematical operation with the feature map data output from the previous hidden layer. After performing backpropagation, model parameters are updated with new values. The updated model parameters will be used by the GPU for training in the next iteration. In addition, in most deep learning models, model parameters account for the smallest proportion of the total data of deep learning [19]; therefore, we recommend that the model parameters remain on the GPU until training is complete.
- Second, there are intermediate results. The intermediate result is the feature map data of each hidden layer that is generated as a result of mathematical operation of model parameters and input data when performing feed forwarding, and a temporary buffer used when backpropagation is performed. Therefore, intermediate results are newly generated and used by feed forwarding and backpropagation at every iteration, and are not used again after the iteration ends. Further, since the intermediate results are the largest among the three types of data required to perform deep learning, it is difficult to store all the intermediate results in the GPU memory [19]. Every intermediate result generated in each hidden layer during feed forwarding does not always have to be in the GPU memory. However, when performing backpropagation, the intermediate results generated during feed forwarding in each hidden layer must be in GPU memory before backpropagation of that hidden layer is performed.
- Finally, there are input data. The input data are the data to be trained by passing them to the first layer (input layer) of the deep learning model. Input data are delivered to the GPU, which performs deep learning, with new data every iteration. In addition, the input data are not changed due to the deep learning operation and are no longer needed after one iteration. Therefore, the input data do not always have to be on the GPU until training is finished.
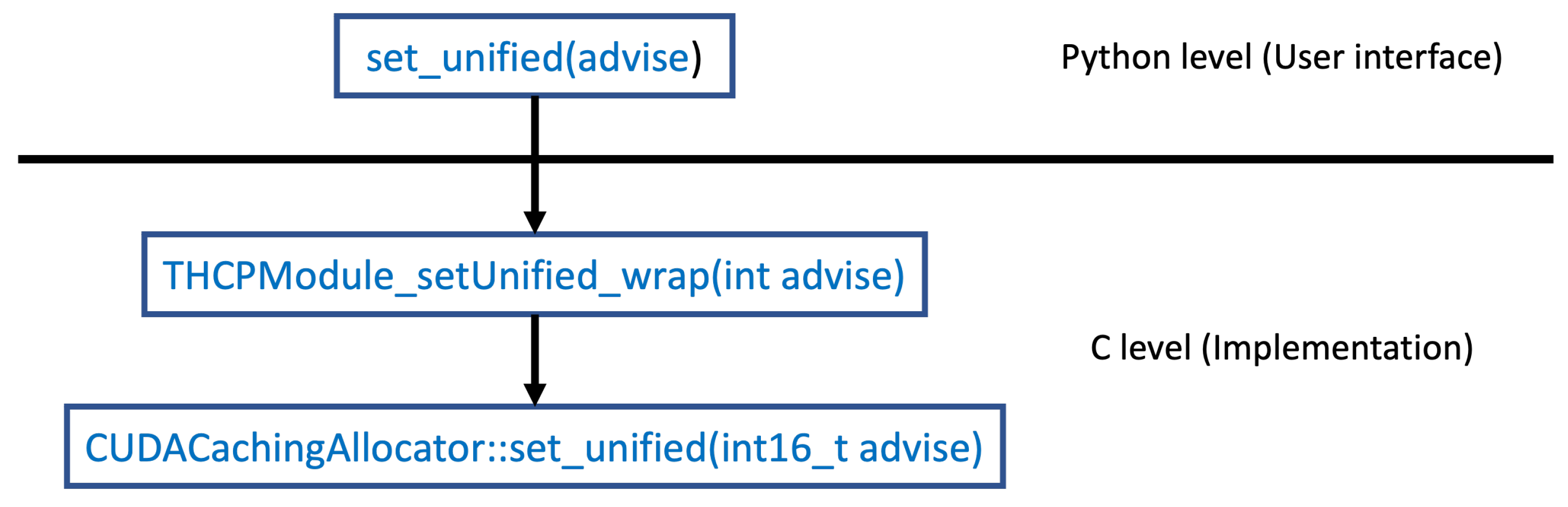
4. Implementation in PyTorch
5. Experiment and Performance Analysis
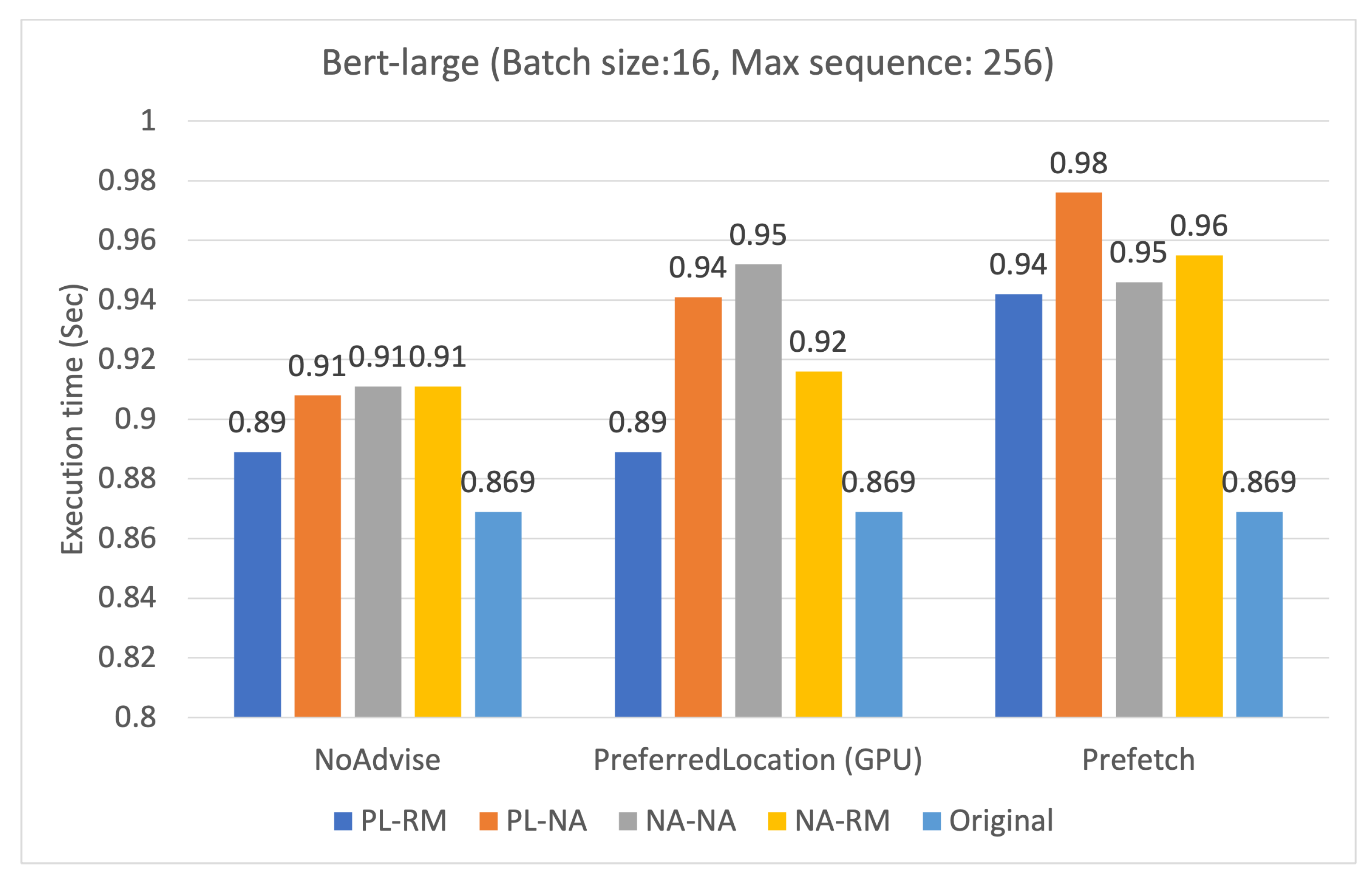
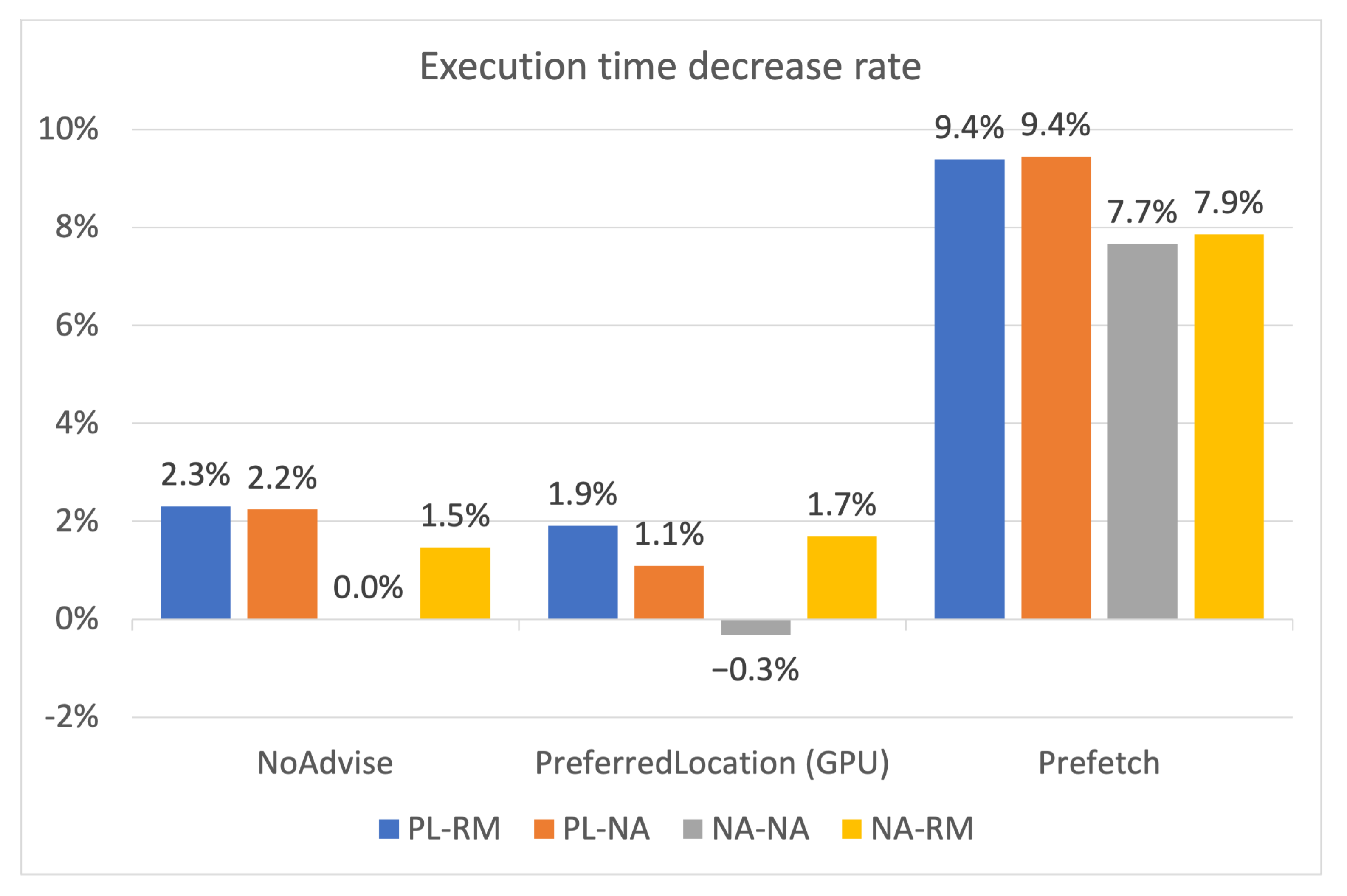
5.1. Execution Time According to Memory Advise
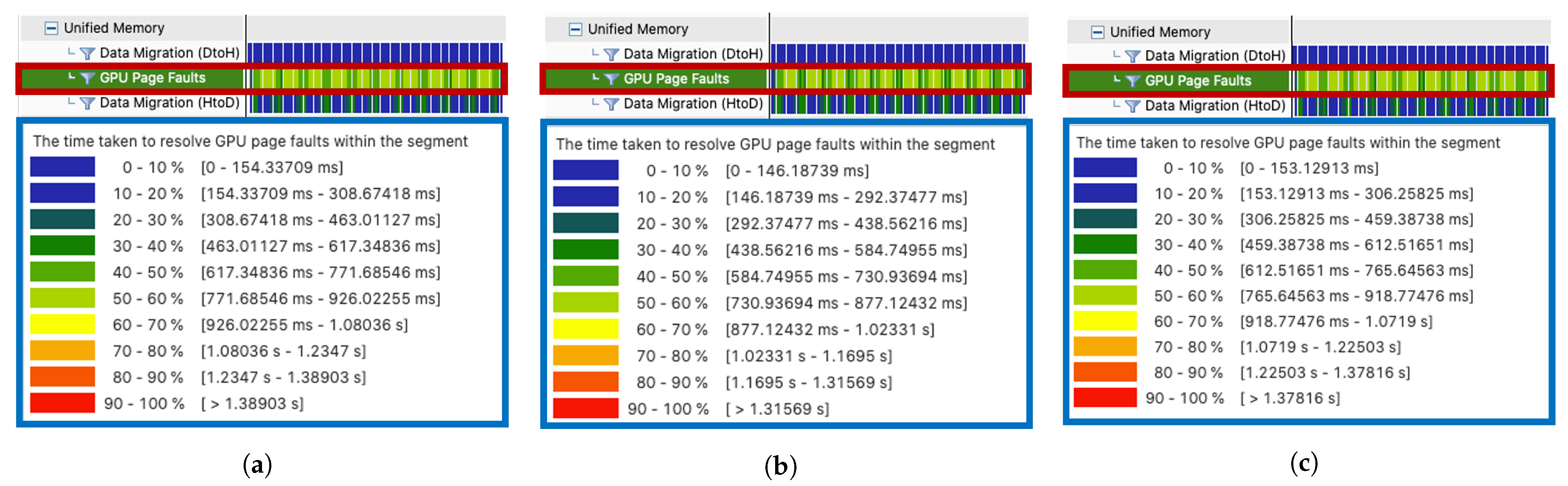
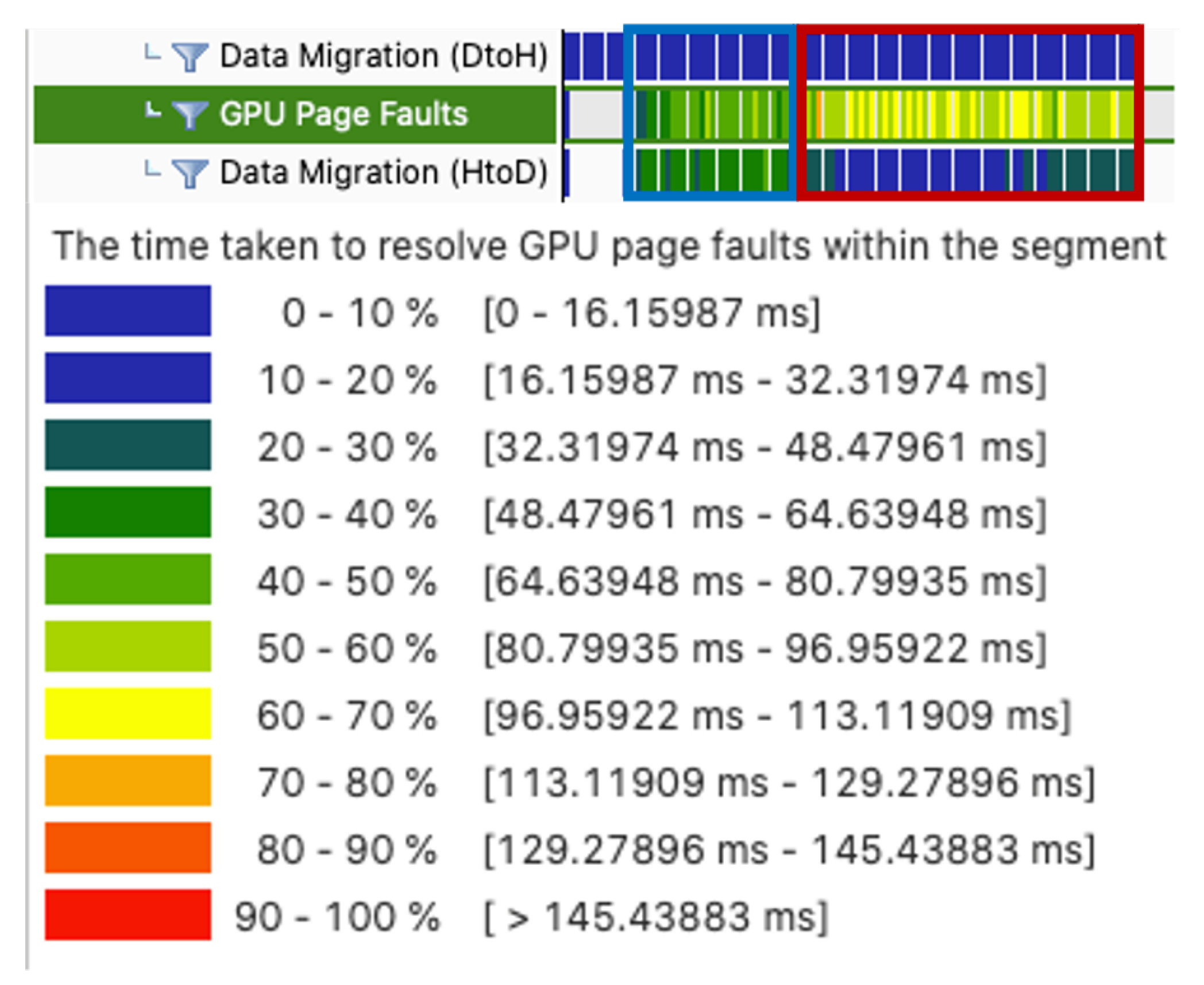
5.2. Results of GPU Page Fault Profiling Using Nvprof
6. Related Works
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Deng, J.; Wei, D.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q. Regularized Evolution for Image Classifier Architecture Search. Proc. Aaai Conf. Artif. Intell. 2018, 33, 4780–4789. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Cheng, Y.; Bapna, A.; Firat, O.; Chen, D.; Chen, M.; Lee, H.; Ngiam, J.; Le, Q.V.; Wu, Y.; et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 103–112. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Huang, G.; Sun, Y.; Liu, Z.; Sedra, D.; Weinberger, K.Q. Deep networks with stochastic depth. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 646–661. [Google Scholar]
- The Next Platform. Baidu Eyes Deep Learning Strategy in Wake of New GPU Options. 2016. Available online: www.nextplatform.com (accessed on 7 September 2021).
- Diamos, G.; Sengupta, S.; Catanzaro, B.; Chrzanowski, M.; Coates, A.; Elsen, E.; Engel, J.; Hannun, A.; Satheesh, S. Persistent RNNs: Stashing Recurrent Weights on-Chip. In Proceedings of the 33rd International Conference on International Conference on Machine Learning, ICML’16, New York City, NY, USA, 19–24 June 2016; pp. 2024–2033. [Google Scholar]
- Kim, Y.; Lee, J.; Kim, J.S.; Jei, H.; Roh, H. Efficient Multi-GPU Memory Management for Deep Learning Acceleration. In Proceedings of the 2018 IEEE 3rd International Workshops on Foundations and Applications of Self* Systems (FAS*W), Trento, Italy, 3–7 September 2018; pp. 37–43. [Google Scholar] [CrossRef]
- Kim, Y.; Choi, H.; Lee, J.; Kim, J.; Jei, H.; Roh, H. Efficient Large-Scale Deep Learning Framework for Heterogeneous Multi-GPU Cluster. In Proceedings of the 2019 IEEE 4th International Workshops on Foundations and Applications of Self* Systems (FAS*W), Umea, Sweden, 16–20 June 2019; pp. 176–181. [Google Scholar]
- Kim, Y.; Lee, J.; Kim, J.S.; Jei, H.; Roh, H. Comprehensive techniques of multi-GPU memory optimization for deep learning acceleration. Clust. Comput. 2020, 23, 2193–2204. [Google Scholar] [CrossRef]
- Kim, Y.; Choi, H.; Lee, J.; Kim, J.S.; Jei, H.; Roh, H. Towards an optimized distributed deep learning framework for a heterogeneous multi-GPU cluster. Clust. Comput. 2020, 23, 2287–2300. [Google Scholar] [CrossRef]
- Chien, S.W.; Peng, I.; Markidis, S. Performance Evaluation of Advanced Features in CUDA Unified Memory. In Proceedings of the 2019 IEEE/ACM Workshop on Memory Centric High Performance Computing (MCHPC), Denver, CO, USA, 18 November 2019; pp. 50–57. [Google Scholar]
- Mark Harris. Unified Memory for CUDA Beginners. 2017. Available online: https://developer.nvidia.com/blog/unified-memory-cuda-beginners/ (accessed on 7 September 2021).
- Nikolay Sakharnykh. Everything You Need to Know about Unified Memory. 2021. Available online: https://on-demand-gtc.gputechconf.com/gtcnew/sessionview.php?sessionName=s8430-everything+you+need+to+know+about+unified+memory (accessed on 7 September 2021).
- Nikolay Sakharnykh. 2016. Beyond GPU Memory Limits with Unified Memory on Pascal. Available online: https://developer.nvidia.com/blog/beyond-gpu-memory-limits-unified-memory-pascal/ (accessed on 7 September 2021).
- NVIDIA. 2021. CUDA C++ Programming Guide. Available online: https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html (accessed on 7 September 2021).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Rhu, M.; Gimelshein, N.; Clemons, J.; Zulfiqar, A.; Keckler, S.W. vDNN: Virtualized Deep Neural Networks for Scalable, Memory-Efficient Neural Network Design. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Barcelona, Spain, 2019; pp. 8024–8035. [Google Scholar]
- Markthub, P.; Belviranli, M.E.; Lee, S.; Vetter, J.S.; Matsuoka, S. DRAGON: Breaking GPU Memory Capacity Limits with Direct NVM Access. In Proceedings of the SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 11–16 November 2018; pp. 414–426. [Google Scholar] [CrossRef]
- Rajbhandari, S.; Rasley, J.; Ruwase, O.; He, Y. ZeRO: Memory Optimizations toward Training Trillion Parameter Models. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020. [Google Scholar]
- Jain, A.; Awan, A.A.; Aljuhani, A.M.; Hashmi, J.M.; Anthony, Q.G.; Subramoni, H.; Panda, D.K.; Machiraju, R.; Parwani, A. GEMS: GPU-Enabled Memory-Aware Model-Parallelism System for Distributed DNN Training. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–15. [Google Scholar]
- Awan, A.A.; Chu, C.H.; Subramoni, H.; Lu, X.; Panda, D.K. OC-DNN: Exploiting Advanced Unified Memory Capabilities in CUDA 9 and Volta GPUs for Out-of-Core DNN Training. In Proceedings of the 2018 IEEE 25th International Conference on High Performance Computing (HiPC), Bengaluru, India, 17–20 December 2018; pp. 143–152. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Does Data Change Due to Deep Learning Operation? | Is Data Accessed by GPU on the Next Iteration? | Techniques for Managing Data |
|---|---|---|---|
| Model Parameters | Yes | Yes | Preferred location |
| Input Data | No | No | Read mostly or no memory advise |
| Intermediate results | Yes | No | Prefetch |
| Initialize Training Model | After Feed Forwarding | After Backpropagation |
|---|---|---|
| 519 MiB | 6027 MiB | 7121 MiB |
| No Advise | Best Advise | Worst Advise | |
|---|---|---|---|
| Page fault | 5,782,973 | 5,645,687 | 5,695,792 |
| Data migration Device to Host (s) | 23.327 | 24.068 | 23.334 |
| Data migration Host to Device (s) | 40.846 | 39.636 | 40.867 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.; Lee, J. Efficient Use of GPU Memory for Large-Scale Deep Learning Model Training. Appl. Sci. 2021, 11, 10377. https://doi.org/10.3390/app112110377
Choi H, Lee J. Efficient Use of GPU Memory for Large-Scale Deep Learning Model Training. Applied Sciences. 2021; 11(21):10377. https://doi.org/10.3390/app112110377
Chicago/Turabian StyleChoi, Hyeonseong, and Jaehwan Lee. 2021. "Efficient Use of GPU Memory for Large-Scale Deep Learning Model Training" Applied Sciences 11, no. 21: 10377. https://doi.org/10.3390/app112110377
APA StyleChoi, H., & Lee, J. (2021). Efficient Use of GPU Memory for Large-Scale Deep Learning Model Training. Applied Sciences, 11(21), 10377. https://doi.org/10.3390/app112110377