
Methods for Weighting Decisions to Assist Modelers and Decision Analysts: A Review of Ratio Assignment and Approximate Techniques


Abstract
:1. Introduction
2. Materials and Methods
- Objective and attribute structure. The structure of the objectives and the selection of weighting methods affect results and should be aligned to avoid bias;
- Attribute definitions affect weighting. The detail with which certain attributes are specified affects the weight assigned to them; that is, the division of an attribute can increase or decrease the weight of an attribute. For example, weighing price, service level, and distance separately as criteria for a mechanic selection led to different results than weighing shop characteristics (comprised of price and service level) and distance did [62];
- Number of attributes affects method choice. It is very difficult to directly or indirectly weight when one has to consider many attributes (e.g., double digits or more), owing to the greater difficulty associated with answering all the questions needed for developing attribute weights; Miller [63] advocates the use of five to nine attributes to avoid cognitive overburden;
- More attributes are not necessarily better. As the number of attributes increases, there is a tendency for the weights to equalize, meaning that it becomes harder to distinguish the difference between attributes in terms of importance as the number of significant attributes increases [64];
- Attribute dominance. If one attribute is weighted heavier than all other attributes combined, the correlation between the individual attribute score and the total preference score approaches one;
- Weights compared within but not among decision frameworks. The interpretation of an attribute weight within a particular modeling framework should be the same regardless of the method used to obtain weights [65]; however, the same consistency in attribute weighting cannot be said to be present across all multi-criteria decision analysis frameworks [66];
- Consider the ranges of attributes. People tend to neglect accounting for attribute ranges when assigning weights using weighting methods that do not stress them [56,67]; rather, these individuals seem to apply some intuitive interpretation of weights as a very generic degree of importance of attributes, as opposed to explicitly stating ranges, which is preferred [68,69,70]. This problem could occur when evaluating job opportunities. People may assume that salary is the most important factor, however, if the salary range is very narrow (e.g., a few hundred dollars), then other factors such as vacation days or available benefits may in fact be more important in the decision maker’s happiness.
3. Results
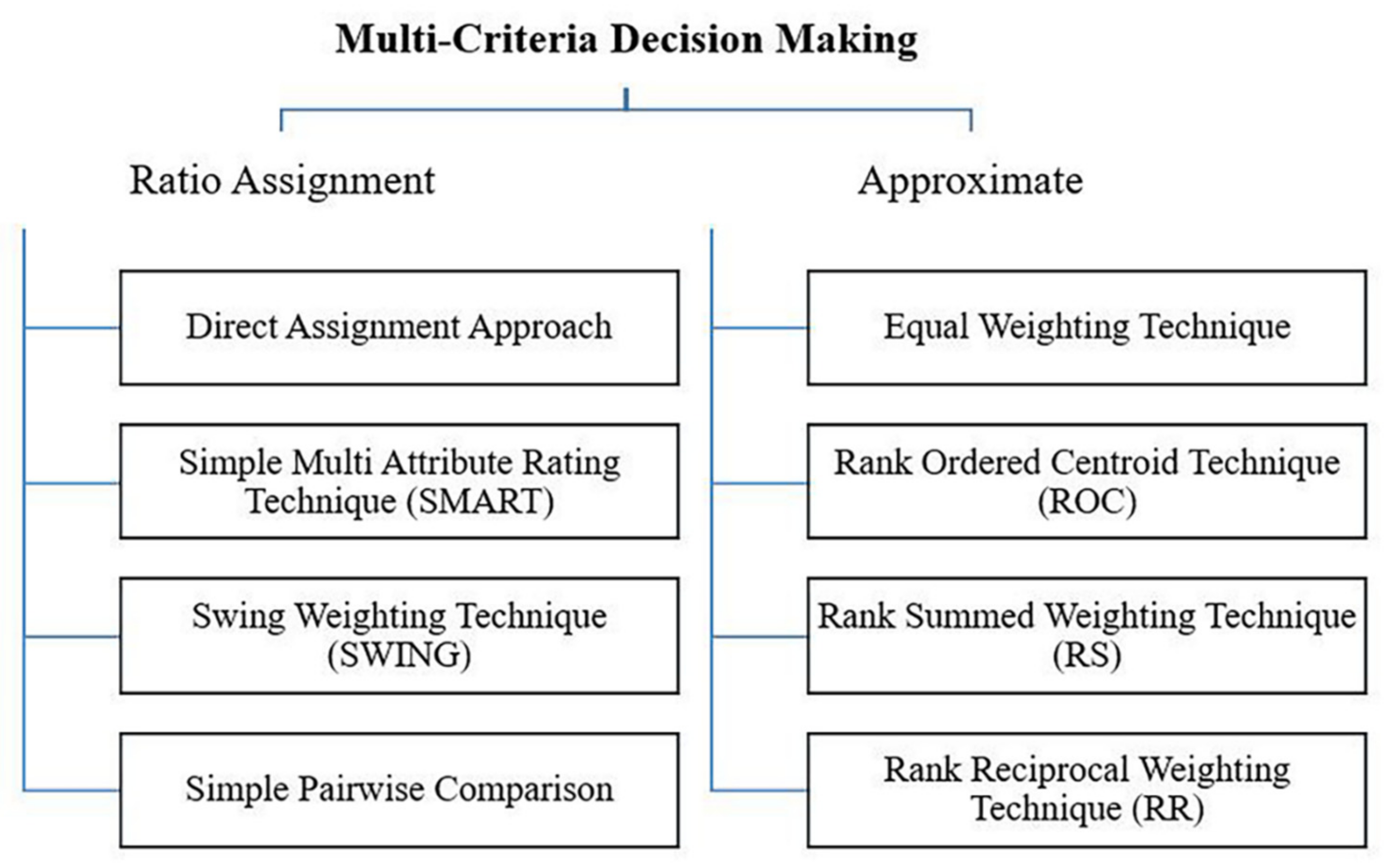
3.1. Ratio Assignment Techniques
3.1.1. Direct Assignment Technique (DAT)
DAT Step 1: Assign Points to Each Attribute
DAT Step 2: Calculate Weights
Strengths of This Approach
Limitations of This Approach
3.1.2. Simple Multi Attribute Rating Technique (SMART)
SMART Step 1: Rank Order Attributes
SMART Step 2: Establish the Reference Attribute
SMART Step 3: Score Attributes Relative to the Reference Attribute
Step 4: Calculate Weights
Strengths of This Approach
Limitations of This Approach
3.1.3. Swing Weighting Techniques (SWING)
SWING Step 1: Rank Order Attributes
SWING Step 2: Establish the Reference Attribute
SWING Step 3: Score Attributes Relative to the Reference Attribute
SWING Step 4: Calculate Weights
Strengths of This Approach
Limitations of This Approach
3.1.4. Simple Pairwise Comparison
Pairwise Step 1: Pairwise Rank the Attributes
- Purchase Price vs. Attractiveness: Purchase Price Wins;
- Purchase Price vs. Reliability: Purchase Price Wins;
- Purchase Price vs. Gas Mileage: Purchase Price Wins;
- Purchase Price vs. Safety Rating: Purchase Price Wins;
- Attractiveness vs. Reliability: Reliability Wins;
- Attractiveness vs. Gas Mileage: Attractiveness Wins;
- Attractiveness vs. Safety Rating: Safety Wins;
- Reliability vs. Gas Mileage: Reliability Wins;
- Reliability vs. Safety Rating: Reliability Wins;
- Gas Mileage vs. Safety Rating: Safety Wins;
Pairwise Step 2: Calculate Weights
Strengths of This Approach
Limitations of This Approach
3.2. Approximate Techniques
3.2.1. Equal Weighting Technique
Strengths of This Approach
Limitations of This Approach
3.2.2. Rank Ordered Centroid (ROC) Technique
ROC Step 1: Rank Order Attributes and Establish Rank Indices
ROC Step 2: Calculate the Rank Ordered Centroid for Each Attribute
Strengths of This Approach
Limitations of This Approach
3.2.3. Rank Summed Weighting (RS) Technique
RS Step 1: Rank Order Attributes and Establish Rank Indices
RS Step 2: Calculate the Rank Summed Weight for Each Attribute
Strengths of This Approach
Limitations of This Approach
3.2.4. Rank Reciprocal Weighting (RR) Technique
RR Step 1: Rank Order Attributes and Establish Rank Indices
RR Step 2: Calculate the Rank Summed Weight for Each Attribute
Strengths of This Approach
Limitations of This Approach
4. Discussion
4.1. Characteristics of Multi-Criteria Decision Analysis Techniques
4.2. MCDA as Decision-Making Options for Computational Models
4.2.1. MCDA Applicability for Agent-Based Models
4.2.2. MCDA Applicability for Discrete Event Simulation Models
4.2.3. MCDA Applicability for System Dynamics Models
4.3. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ören, T. Simulation and Reality: The Big Picture. Int. J. Model. Simul. Sci. Comput. 2010, 1, 1–25. [Google Scholar] [CrossRef]
- Zeigler, B.P.; Prähofer, H.; Kim, T.G. Theory of Modeling and Simulation: Integrating Discrete Event and Continuous Complex Dynamic Systems, 2nd ed.; Academic Press: New York, NY, USA, 2000. [Google Scholar]
- Sargent, R.G. Verification and Validation of Simulation Models. J. Simul. 2013, 7, 12–24. [Google Scholar] [CrossRef] [Green Version]
- Zeigler, B.P.; Luh, C.; Kim, T. Model Base Management for Multifacetted Systems. Trans. Model. Comput. Simul. 1991, 1, 195–218. [Google Scholar]
- Yilmaz, L. On the Need for Contextualized Introspective Models to Improve Reuse and Composability of Defense Simulations. J. Def. Model. Simul. 2004, 1, 141–151. [Google Scholar] [CrossRef]
- Spiegel, M.; Reynolds, P.F.; Brogan, D.C. A Case Study of Model Context for Simulation Composability and Reusability. In Proceedings of the 2005 Winter Simulation Conference, Orlando, FL, USA, 4 December 2005; pp. 437–444. [Google Scholar]
- Casilimas, L.; Corrales, D.C.; Solarte Montoya, M.; Rahn, E.; Robin, M.-H.; Aubertot, J.-N.; Corrales, J.C. HMP-Coffee: A Hierarchical Multicriteria Model to Estimate the Profitability for Small Coffee Farming in Colombia. Appl. Sci. 2021, 11, 6880. [Google Scholar] [CrossRef]
- Lynch, C.J. A Multi-Paradigm Modeling Framework for Modeling and Simulating Problem Situations. Master’s Thesis, Old Dominion University, Norfolk, VA, USA, 2014. [Google Scholar]
- Vennix, J.A. Group Model-Building: Tackling Messy Problems. Syst. Dyn. Rev. 1999, 15, 379–401. [Google Scholar] [CrossRef]
- Fernández, E.; Rangel-Valdez, N.; Cruz-Reyes, L.; Gomez-Santillan, C. A New Approach to Group Multi-Objective Optimization under Imperfect Information and Its Application to Project Portfolio Optimization. Appl. Sci. 2021, 11, 4575. [Google Scholar] [CrossRef]
- Barry, P.; Koehler, M. Simulation in Context: Using Data Farming for Decision Support. In Proceedings of the 2004 Winter Simulation Conference, Washington, DC, USA, 5–8 December 2004. [Google Scholar]
- Keeney, R.L.; Raiffa, H.G. Decisions with Multiple Objectives: Preferences and Value Tradeoffs; Wiley & Sons: New York, NY, USA, 1976. [Google Scholar]
- Mendoza, G.A.; Martins, H. Multi-criteria decision analysis in natural resource management: A critical review of methods and new modelling paradigms. For. Ecol. Manag. 2006, 230, 1–22. [Google Scholar] [CrossRef]
- Aenishaenslin, C.; Gern, L.; Michel, P.; Ravel, A.; Hongoh, V.; Waaub, J.-P.; Milord, F.; Bélanger, D. Adaptation and evaluation of a multi-criteria decision analysis model for Lyme disease prevention. PLoS ONE 2015, 10, e0135171. [Google Scholar] [CrossRef]
- Hongoh, V.; Campagna, C.; Panic, M.; Samuel, O.; Gosselin, P.; Waaub, J.-P.; Ravel, A.; Samoura, K.; Michel, P. Assessing interventions to manage West Nile virus using multi-criteria decision analysis with risk scenarios. PLoS ONE 2016, 11, e0160651. [Google Scholar] [CrossRef]
- Scholten, L.; Maurer, M.; Lienert, J. Comparing multi-criteria decision analysis and integrated assessment to support long-term water supply planning. PLoS ONE 2017, 12, e0176663. [Google Scholar]
- Ezell, B.C. Infrastructure Vulnerability Assessment Model (I-VAM). Risk Anal. Int. J. 2007, 27, 571–583. [Google Scholar] [CrossRef]
- Collins, A.J.; Hester, P.; Ezell, B.; Horst, J. An Improvement Selection Methodology for Key Performance Indicators. Environ. Syst. Decis. 2016, 36, 196–208. [Google Scholar] [CrossRef]
- Ezell, B.; Lawsure, K. Homeland Security and Emergency Management Grant Allocation. J. Leadersh. Account. Ethics 2019, 16, 74–83. [Google Scholar]
- Caskey, S.; Ezell, B. Prioritizing Countries by Concern Regarding Access to Weapons of Mass Destruction Materials. J. Bioterror. Biodefense 2021, 12, 2. [Google Scholar]
- Sterman, J.D. Modeling managerial behavior: Misperceptions of feedback in a dynamic decision making experiment. Manag. Sci. 1989, 35, 321–339. [Google Scholar] [CrossRef] [Green Version]
- Forrester, J.W. Industrial Dynamics; The MIT Press: Cambridge, MA, USA, 1961. [Google Scholar]
- Robinson, S. Discrete-event simulation: From the pioneers to the present, what next? J. Oper. Res. Soc. 2005, 56, 619–629. [Google Scholar] [CrossRef] [Green Version]
- Hamrock, E.; Paige, K.; Parks, J.; Scheulen, J.; Levin, S. Discrete Event Simulation for Healthcare Organizations: A Tool for Decision Making. J. Healthc. Manag. 2013, 58, 110–124. [Google Scholar] [CrossRef]
- Padilla, J.J.; Lynch, C.J.; Kavak, H.; Diallo, S.Y.; Gore, R.; Barraco, A.; Jenkins, B. Using Simulation Games for Teaching and Learning Discrete-Event Simulation. In Proceedings of the 2016 Winter Simulation Conference, Arlington, VA, USA, 11–14 December 2016; pp. 3375–3385. [Google Scholar]
- Kelton, W.D.; Sadowski, R.P.; Swets, N.B. Simulation with Arena, 5th ed.; McGraw-Hill: New York, NY, USA, 2010. [Google Scholar]
- Epstein, J.M. Agent-Based Computational Models and Generative Social Science. Complexity 1999, 4, 41–60. [Google Scholar] [CrossRef]
- Gilbert, N. Using Agent-Based Models in Social Science Research. In Agent-Based Models; Sage: Los Angeles, CA, USA, 2008; pp. 30–46. [Google Scholar]
- Epstein, J.M.; Axtell, R. Growing Artificial Societies: Social Science from the Bottom Up; The MIT Press: Cambridge, MA, USA, 1996. [Google Scholar]
- Schelling, T.C. Dynamic Models of Segregation. J. Math. Sociol. 1971, 1, 143–186. [Google Scholar] [CrossRef]
- Smith, E.B.; Rand, W. Simulating Macro-Level Effects from Micro-Level Observations. Manag. Sci. 2018, 64, 5405–5421. [Google Scholar] [CrossRef]
- Wooldridge, M.; Jennings, N.R. (Eds.) Agent Theories, Architectures, and Languages: A Survey. In Intelligent Agents ATAL; Springer: Berlin/Heidelberg, Germany, 1994; pp. 1–39. [Google Scholar]
- Lynch, C.J.; Diallo, S.Y.; Tolk, A. Representing the Ballistic Missile Defense System using Agent-Based Modeling. In Proceedings of the 2013 Spring Simulation Multi-Conference-Military Modeling & Simulation Symposium, San Diego, CA, USA, 7–10 April 2013; Society for Computer Simulation International: Vista, CA, USA, 2013; pp. 1–8. [Google Scholar]
- Shults, F.L.; Gore, R.; Wildman, W.J.; Lynch, C.J.; Lane, J.E.; Toft, M. A Generative Model of the Mutual Escalation of Anxiety Between Religious Groups. J. Artif. Soc. Soc. Simul. 2018, 21, 1–25. [Google Scholar] [CrossRef]
- Wooldridge, M.; Fisher, M. (Eds.) A Decision Procedure for a Temporal Belief Logic. In Temporal Logic ICTL 1994; Springer: Berlin/Heidelberg, Germany, 1994; pp. 317–331. [Google Scholar]
- Sarker, I.H.; Colman, A.; Han, J.; Khan, A.I.; Abushark, Y.B.; Salah, K. BehavDT: A Behavioral Decision Tree Learning to Build User-Centric Context-Aware Predictive Model. Mob. Netw. Appl. 2020, 25, 1151–1161. [Google Scholar] [CrossRef] [Green Version]
- Ching, W.-K.; Huang, X.; Ng, M.K.; Siu, T.-K. Markov Chains: Models, Algorithms and Applications, 2nd ed.; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Razzaq, M.; Ahmad, J. Petri Net and Probabilistic Model Checking Based Approach for the Modelling, Simulation and Verification of Internet Worm Propagation. PLoS ONE 2015, 10, e0145690. [Google Scholar] [CrossRef]
- Sokolowski, J.A.; Banks, C.M. Modeling and Simulation Fundamentals: Theoretical Underpinnings and Practical Domains; John Wiley & Sons: Hoboken, NJ, USA, 2010. [Google Scholar]
- Dawes, R.M.; Corrigan, B. Linear models in decision making. Psychol. Bull. 1974, 81, 95–106. [Google Scholar]
- Sokolowski, J.A. Enhanced decision modeling using multiagent system simulation. Simulation 2003, 79, 232–242. [Google Scholar]
- Maani, K.E.; Maharaj, V. Links between systems thinking and complex decision making. Syst. Dyn. Rev. J. Syst. Dyn. Soc. 2004, 20, 21–48. [Google Scholar] [CrossRef]
- Balke, T.; Gilbert, N. How do agents make decisions? A survey. J. Artif. Soc. Soc. Simul. 2014, 17, 1–30. [Google Scholar] [CrossRef]
- Jin, H.; Goodrum, P.M. Optimal Fall Protection System Selection Using a Fuzzy Multi-Criteria Decision-Making Approach for Construction Sites. Appl. Sci. 2021, 11, 5296. [Google Scholar] [CrossRef]
- Kim, B.-S.; Shah, B.; Al-Obediat, F.; Ullah, S.; Kim, K.H.; Kim, K.-I. An enhanced mobility and temperature aware routing protocol through multi-criteria decision making method in wireless body area networks. Appl. Sci. 2018, 8, 2245. [Google Scholar] [CrossRef] [Green Version]
- García, V.; Sánchez, J.S.; Marqués, A.I. Synergetic application of multi-criteria decision-making models to credit granting decision problems. Appl. Sci. 2019, 9, 5052. [Google Scholar] [CrossRef] [Green Version]
- Urbaniak, K.; Wątróbski, J.; Sałabun, W. Identification of Players Ranking in E-Sport. Appl. Sci. 2020, 10, 6768. [Google Scholar] [CrossRef]
- Panapakidis, I.P.; Christoforidis, G.C. Optimal selection of clustering algorithm via Multi-Criteria Decision Analysis (MCDA) for load profiling applications. Appl. Sci. 2018, 8, 237. [Google Scholar] [CrossRef] [Green Version]
- Shaikh, S.A.; Memon, M.; Kim, K.-S. A Multi-Criteria Decision-Making Approach for Ideal Business Location Identification. Appl. Sci. 2021, 11, 4983. [Google Scholar] [CrossRef]
- Clemente-Suárez, V.J.; Navarro-Jiménez, E.; Ruisoto, P.; Dalamitros, A.A.; Beltran-Velasco, A.I.; Hormeño-Holgado, A.; Laborde-Cárdenas, C.C.; Tornero-Aguilera, J.F. Performance of Fuzzy Multi-Criteria Decision Analysis of Emergency System in COVID-19 Pandemic. An Extensive Narrative Review. Int. J. Environ. Res. Public Health 2021, 18, 5208. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, H.; Wu, Y.; Dong, Y. Ranking Range Based Approach to MADM under Incomplete Context and its Application in Venture Investment Evaluation. Technol. Econ. Dev. Econ. 2019, 25, 877–899. [Google Scholar] [CrossRef]
- Xiao, J.; Wang, X.; Zhang, H. Exploring the Ordinal Classifications of Failure Modes in the Reliability Management: An Optimization-Based Consensus Model with Bounded Confidences. Group Decis. Negot. 2021, 1–32. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, S.; Kou, G.; Li, C.-C.; Dong, Y.; Herrera, F. An Overview on Feedback Mechanisms with Minimum Adjustment or Cost in Consensus Reaching in Group Decision Making: Research Paradigms and Challenges. Inf. Fusion 2020, 60, 65–79. [Google Scholar] [CrossRef]
- Sapiano, N.J.; Hester, P.T. Systemic Analysis of a Drug Trafficking Mess. Int. J. Syst. Syst. Eng. 2019, 9, 277–306. [Google Scholar] [CrossRef]
- Jiao, W.; Wang, L.; McCabe, M.F. Multi-Sensor Remote Sensing for Drought Characterization: Current Status, Opportunities and a Roadmap for the Future. Remote Sens. Environ. 2021, 256, 112313. [Google Scholar] [CrossRef]
- Keeney, R.L. Multiplicative Utility Functions. Oper. Res. 1974, 22, 22–34. [Google Scholar]
- Tervonen, T.; van Valkenhoef, G.; Baştürk, N.; Postmus, D. Hit-and-Run Enables Efficient Weight Generation for Simulation-based Multiple Criteria Decision Analysis. Eur. J. Oper. Res. 2013, 224, 552–559. [Google Scholar] [CrossRef]
- Zanakis, S.H.; Solomon, A.; Wishart, N.; Dublish, S. Multi-Attribute Decision Making: A Simulation Comparison of Select Methods. Eur. J. Oper. Res. 1998, 107, 507–529. [Google Scholar] [CrossRef]
- Von Nitzsch, R.; Weber, M. The effect of attribute ranges on weights in multiattribute utility measurements. Manag. Sci. 1993, 39, 937–943. [Google Scholar]
- Borcherding, K.; Eppel, T.; Von Winterfeldt, D. Comparison of weighting judgments in multiattribute utility measurement. Manag. Sci. 1991, 37, 1603–1619. [Google Scholar]
- Stillwell, W.; Seaver, D.; Edwards, W. A comparison of weight approximation techniques in multiattribute utility decision making. Organ. Behav. Hum. Perform. 1981, 28, 62–77. [Google Scholar]
- Pöyhönen, M.; Vrolijk, H.; Hämäläinen, R.P. Behavioral and procedural consequences of structural variation in value trees. Eur. J. Oper. Res. 2001, 134, 216–227. [Google Scholar] [CrossRef]
- Miller, G.A. The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capability for Processing Information. Psychol. Rev. 1956, 63, 81–97. [Google Scholar] [CrossRef] [Green Version]
- Stillwell, W.G.; von Winterfeldt, D.; John, R.S. Comparing hierarchical and non-hierarchical weighting methods for eliciting multiattribute value models. Manag. Sci. 1987, 33, 442–450. [Google Scholar] [CrossRef]
- Pöyhönen, M. On Attribute Weighting in Value Trees. Ph.D. Thesis, Helsinki University of Technology, Espoo, Finland, 1998. [Google Scholar]
- Choo, E.U.; Schoner, B.; Wedley, W.C. Interpretation of criteria weights in multicriteria decision making. Comput. Ind. Eng. 1999, 37, 527–541. [Google Scholar] [CrossRef]
- Fischer, G.W. Range sensitivity of attribute weights in multiattribute value models. Organ. Behav. Hum. Decis. Process. 1995, 62, 252–266. [Google Scholar]
- Korhonen, P.; Wallenius, J. Behavioral Issues in MCDM: Neglected research questions. J. Multicriteria Decis. Anal. 1996, 5, 178–182. [Google Scholar] [CrossRef]
- Belton, V.; Gear, T. On a short-coming of Saaty’s method of analytic hierarchies. Omega 1983, 3, 228–230. [Google Scholar]
- Salo, A.A.; Hämäläinen, R.P. On the measurement of preferences in the Analytic Hierarchy Process. J. Multicriteria Decis. Anal. 1997, 6, 309–343. [Google Scholar] [CrossRef]
- Edwards, W. How to use multiattribute utility measurement for social decisionmaking. IEEE Trans. Syst. Man Cybern. 1977, 7, 326–340. [Google Scholar] [CrossRef]
- Von Winterfeldt, D.; Edwards, W. Decision Analysis and Behavioral Research; Cambridge University Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Edwards, W.; Barron, F. SMARTS and SMARTER: Improved simple methods for multiattribute utility measurement. Organ. Behav. Hum. Decis. Process. 1994, 60, 306–325. [Google Scholar]
- Saaty, T.L. The Analytic Hierarchy Process; McGraw Hill: New York, NY, USA, 1980. [Google Scholar]
- Wallenius, J.; Dyer, J.S.; Fishburn, P.C.; Steuer, R.E.; Zionts, S.; Deb, K. Multiple Criteria Decision Making, Multiattribute Utility Theory: Recent Accomplishments and What Lies Ahead. Manag. Sci. 2008, 54, 1339–1340. [Google Scholar]
- Velasquez, M.; Hester, P.T. An analysis of multi-criteria decision making methods. Int. J. Oper. Res. 2013, 10, 56–66. [Google Scholar]
- Dyer, J.S. Remarks on the Analytic Hierarchy Process. Manag. Sci. 1990, 35, 249–258. [Google Scholar] [CrossRef]
- Jia, J.; Fischer, G.W.; Dyer, J.S. Attribute weighting methods and decision quality in the presence of response error: A simulation study. J. Behav. Decis. Mak. 1998, 11, 85–105. [Google Scholar]
- Kapur, J.N. Maximum Entropy Principles in Science and Engineering; New Age: New Dehli, India, 2009. [Google Scholar]
- Barron, F.; Barrett, B. Decision quality using ranked attribute weights. Manag. Sci. 1996, 42, 1515–1523. [Google Scholar]
- U.S. Coast Guard. Coast Guard Process Improvement Guide: Total Quality Tools for Teams and Individuals, 2nd ed.; U.S. Government Printing Office: Boston, MA, USA, 1994.
- Lynch, C.J.; Diallo, S.Y.; Kavak, H.; Padilla, J.J. A Content Analysis-based Approach to Explore Simulation Verification and Identify its Current Challenges. PLoS ONE 2020, 15, e0232929. [Google Scholar] [CrossRef]
- Diallo, S.Y.; Gore, R.; Lynch, C.J.; Padilla, J.J. Formal Methods, Statistical Debugging and Exploratory Analysis in Support of System Development: Towards a Verification and Validation Calculator Tool. Int. J. Model. Simul. Sci. Comput. 2016, 7, 1641001. [Google Scholar] [CrossRef] [Green Version]
- Axelrod, R. Advancing the Art of Simulation in the Social Sciences. Complexity 1997, 3, 16–22. [Google Scholar] [CrossRef] [Green Version]
- Sterman, J.D. Deterministic chaos in models of human behavior: Methodological issues and experimental results. Syst. Dyn. Rev. 1988, 4, 148–178. [Google Scholar]
- Fortmann-Roe, S. Insight Maker: A General-Purpose Tool for Web-based Modeling & Simulation. Simul. Model. Pract. Theory 2014, 47, 28–45. [Google Scholar] [CrossRef] [Green Version]
- Padilla, J.J.; Diallo, S.Y.; Barraco, A.; Kavak, H.; Lynch, C.J. Cloud-Based Simulators: Making Simulations Accessible to Non-Experts and Experts Alike. In Proceedings of the 2014 Winter Simulation Conference, Savanah, GA, USA, 7–10 December 2014; pp. 3630–3639. [Google Scholar]
- Lynch, C.J.; Padilla, J.J.; Diallo, S.Y.; Sokolowski, J.A.; Banks, C.M. A Multi-Paradigm Modeling Framework for Modeling and Simulating Problem Situations. In Proceedings of the 2014 Winter Simulation Conference, Savanah, GA, USA, 7–10 December 2014; pp. 1688–1699. [Google Scholar]
- Lynch, C.J.; Diallo, S.Y. A Taxonomy for Classifying Terminologies that Describe Simulations with Multiple Models. In Proceedings of the 2015 Winter Simulation Conference, Huntington Beach, CA, USA, 6–9 December 2015; pp. 1621–1632. [Google Scholar]
- Tolk, A.; Diallo, S.Y.; Padilla, J.J.; Herencia-Zapana, H. Reference Modelling in Support of M&S—Foundations and Applications. J. Simul. 2013, 7, 69–82. [Google Scholar] [CrossRef]
- MacKenzie, G.R.; Schulmeyer, G.G.; Yilmaz, L. Verification technology potential with different modeling and simulation development and implementation paradigms. In Proceedings of the Foundations for V&V in the 21st Century Workshop, Laurel, MD, USA, 22–24 October 2002; pp. 1–40. [Google Scholar]
- Eldabi, T.; Balaban, M.; Brailsford, S.; Mustafee, N.; Nance, R.E.; Onggo, B.S.; Sargent, R. Hybrid Simulation: Historical Lessons, Present Challenges and Futures. In Proceedings of the 2016 Winter Simulation Conference, Arlington, VA, USA, 11–14 December 2016; pp. 1388–1403. [Google Scholar]
- Vangheluwe, H.; De Lara, J.; Mosterman, P.J. An Introduction to Multi-Paradigm Modelling and Simulation. In Proceedings of the AIS’2002 Conference (AI, Simulation and Planning in High Autonomy Systems), Lisboa, Portugal, 7–10 April 2002; pp. 9–20. [Google Scholar]
- Balaban, M.; Hester, P.; Diallo, S. Towards a Theory of Multi-Method M&S Approach: Part I. In Proceedings of the 2014 Winter Simulation Conference, Savanah, GA, USA, 7–10 December 2014; pp. 1652–1663. [Google Scholar]
- Bonabeau, E. Agent-based modeling: Methods and techniques for simulating human systems. Proc. Natl. Acad. Sci. USA. 2002, 99 (Suppl. S3), 7280–7287. [Google Scholar] [CrossRef] [Green Version]
- Epstein, J.M. Agent_Zero: Toward Neurocognitive Foundations for Generative Social Science; Princeton University Press: Princeton, NJ, USA, 2014. [Google Scholar]
- Shults, F.L.; Lane, J.E.; Wildman, W.J.; Diallo, S.; Lynch, C.J.; Gore, R. Modelling terror management theory: Computer simulations of the impact of mortality salience on religiosity. Relig. Brain Behav. 2018, 8, 77–100. [Google Scholar] [CrossRef]
- Lemos, C.M.; Gore, R.; Lessard-Phillips, L.; Shults, F.L. A network agent-based model of ethnocentrism and intergroup cooperation. Qual. Quant. 2019, 54, 463–489. [Google Scholar] [CrossRef] [Green Version]
- Knoeri, C.; Nikolic, I.; Althaus, H.-J.; Binder, C.R. Enhancing recycling of construction materials: An agent based model with empirically based decision parameters. J. Artif. Soc. Soc. Simul. 2014, 17, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Axelrod, R. An evolutionary approach to norms. Am. Political Sci. Rev. 1986, 80, 1095–1111. [Google Scholar] [CrossRef] [Green Version]
- Santos, F.P.; Santos, F.C.; Pacheco, J.M. Social Norms of Cooperation in Small-Scale Societies. PLoS Comput. Biol. 2016, 12, e1004709. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Borshchev, A. The Big Book of Simulation Modeling: Multimethod Modeling with AnyLogic 6; AnyLogic North America: Oakbrook Terrace, IL, USA, 2013; 612p. [Google Scholar]
- Schriber, T.J.; Brunner, D.T.; Smith, J.S. Inside Discrete-Event Simulation Software: How it Works and Why it Matters. In Proceedings of the 2013 Winter Simulation Conference, Washington, DC, USA, 8–11 December 2013; pp. 424–438. [Google Scholar]
- Padilla, J.J.; Lynch, C.J.; Kavak, H.; Evett, S.; Nelson, D.; Carson, C.; del Villar, J. Storytelling and Simulation Creation. In Proceedings of the 2017 Winter Simulation Conference, Las Vegas, NV, USA, 3–6 December 2017; pp. 4288–4299. [Google Scholar]
- Tanrıöver, Ö.Ö.; Bilgen, S. UML-Based Conceptual Models and V&V. In Conceptual Modeling for Discrete Event Simulation; Robinson, S., Brooks, R., Kotiadis, K., van Der Zee, D.-J., Eds.; CRC Press: Boca Raton, FL, USA, 2010; pp. 383–422. [Google Scholar]
- Pegden, C.D. Introduction to SIMIO. In Proceedings of the 2008 Winter Simulation Conference, Piscataway, NJ, USA, 7–10 December 2008; pp. 229–235. [Google Scholar]
- Taylor, S.; Robinson, S. So Where to Next? A Survey of the Future for Discrete-Event Simulation. J. Simul. 2006, 1, 1–6. [Google Scholar] [CrossRef]
- Eldabi, T.; Irani, Z.; Paul, R.J.; Love, P.E. Quantitative and Qualitative Decision-Making Methods in Simulation Modelling. Manag. Decis. 2002, 40, 64–73. [Google Scholar] [CrossRef]
- Jones, J.W.; Secrest, E.L.; Neeley, M.J. Computer-based Support for Enhanced Oil Recovery Investment Decisions. Dynamica 1980, 6, 2–9. [Google Scholar]
- Mosekilde, E.; Larsen, E.R. Deterministic Chaos in the Beer Production-Distribution Model. Syst. Dyn. Rev. 1988, 4, 131–147. [Google Scholar] [CrossRef]
- Al-Qatawneh, L.; Hafeez, K. Healthcare logistics cost optimization using a multi-criteria inventory classification. In Proceedings of the International Conference on Industrial Engineering and Operations Management, Kuala Lumpur, Malaysia, 22–24 January 2011; pp. 506–512. [Google Scholar]
- Araz, O.M. Integrating Complex System Dynamics of Pandemic Influenza with a Multi-Criteria Decision Making Model for Evaluating Public Health Strategies. J. Syst. Sci. Syst. Eng. 2013, 22, 319–339. [Google Scholar] [CrossRef]
- Mendoza, G.A.; Prabhu, R. Combining Participatory Modeling and Multi-Criteria Analysis for Community-based Forest Management. For. Ecol. Manag. 2005, 207, 145–156. [Google Scholar] [CrossRef]
- Rebs, T.; Brandenburg, M.; Seuring, S. System Dynamics Modeling for Sustainable Supply Chain Management: A Literature Review and Systems Thinking Approach. J. Clean. Prod. 2019, 208, 1265–1280. [Google Scholar] [CrossRef]
- Kavak, H.; Vernon-Bido, D.; Padilla, J.J. Fine-Scale Prediction of People’s Home Location using Social Media Footprints. In Proceedings of the 2018 International Conference on Social Computing, Behavioral-Cultural Modling, & Prediction and Behavior Representation in Modeling and Simulation, Washington, DC, USA, 10–13 July 2018; pp. 1–6. [Google Scholar]
- Padilla, J.J.; Kavak, H.; Lynch, C.J.; Gore, R.J.; Diallo, S.Y. Temporal and Spatiotemporal Investigation of Tourist Attraction Visit Sentiment on Twitter. PLoS ONE 2018, 13, e0198857. [Google Scholar] [CrossRef] [Green Version]
- Gore, R.; Diallo, S.Y.; Padilla, J.J. You are what you Tweet: Connecting the Geographic Variation in America’s Obesity Rate to Twitter Content. PLoS ONE 2015, 10, e0133505. [Google Scholar] [CrossRef] [Green Version]
- Meza, X.V.; Yamanaka, T. Food Communication and its Related Sentiment in Local and Organic Food Videos on YouTube. J. Med. Internet Res. 2020, 22, e16761. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
| Abbreviation | Criteria | Least Preferred | Most Preferred | Score |
|---|---|---|---|---|
| (P) | Purchase Price | $30,000 | $15,000 | 400 points |
| (R) | Reliability (Initial Owner complaints) | 150 | 10 | 300 points |
| (S) | Safety | 3 star | 5 star | 150 points |
| (A) | Attractiveness (qualitative) | Low | High | 100 points |
| (G) | Gas Mileage | 20 mpg | 30 mpg | 50 points |
| (P) | Purchase Price | $30,000 | $15,000 | 400 points |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (P) | Purchase Price | 400/1000 | =0.40 |
| (R) | Reliability | 300/1000 | =0.30 |
| (S) | Safety | 150/1000 | =0.15 |
| (A) | Attractiveness | 100/1000 | =0.10 |
| (G) | Gas Mileage | 50/1000 | =0.05 |
| Sum | 1000 points | =1.00 |
| Abbreviation | Criteria | Formula |
|---|---|---|
| (G) | Gas Mileage | 1 |
| (A) | Attractiveness | 2 |
| (S) | Safety | 3 |
| (R) | Reliability | 4 |
| (P) | Purchase Price | 5 |
| Abbreviation | Criteria | Points | Total Points |
|---|---|---|---|
| (G) | Gas Mileage | 50 | =50 |
| (A) | Attractiveness | 50 | =100 |
| (S) | Safety | 100 | =150 |
| (R) | Reliability | 250 | =300 |
| (P) | Purchase Price | 350 | =400 |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (G) | Gas Mileage | 50/1000 | =0.050 |
| (A) | Attractiveness | 100/1000 | =0.100 |
| (S) | Safety | 150/1000 | =0.150 |
| (R) | Reliability | 300/1000 | =0.300 |
| (P) | Purchase Price | 400/1000 | =0.400 |
| Sum | 1000 points | =1.00 |
| Abbreviation | Criteria | Ordinal Ranking |
|---|---|---|
| (P) | Purchase Price | 100 |
| (R) | Reliability | 75 |
| (S) | Safety | 37.5 |
| (A) | Attractiveness | 25 |
| (G) | Gas Mileage | 12.5 |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (P) | Purchase Price | 100/250 | =0.400 |
| (R) | Reliability | 75/250 | =0.300 |
| (S) | Safety | 37.5/250 | =0.150 |
| (A) | Attractiveness | 25/250 | =0.100 |
| (G) | Gas Mileage | 12.5/250 | =0.050 |
| Sum | 250 points | =1.00 |
| Abbreviation | Criteria | Points |
|---|---|---|
| (P) | Purchase Price | 4 points |
| (R) | Reliability | 3 points |
| (S) | Safety | 2 points |
| (A) | Attractiveness | 1 point |
| (G) | Gas Mileage | 0 points |
| Abbreviation | Criteria | Points (2/10 Offset) |
|---|---|---|
| (P) | Purchase Price | 6 points/14 points |
| (R) | Reliability | 5 points/13 points |
| (S) | Safety | 4 points/12 points |
| (A) | Attractiveness | 3 point/11 points |
| (G) | Gas Mileage | 2 points/10 points |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (P) | Purchase Price | 4/10 | =0.4 |
| (R) | Reliability | 3/10 | =0.3 |
| (S) | Safety | 2/10 | =0.2 |
| (A) | Attractiveness | 1/10 | =0.1 |
| (G) | Gas Mileage | 0/10 | =0.0 |
| Sum | 10 points | =1.00 |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (P) | Purchase Price | 6 points/14 points | =0.30/0.233 |
| (R) | Reliability | 5 points/13 points | =0.25/0.217 |
| (S) | Safety | 4 points/12 points | =0.20/0.20 |
| (A) | Attractiveness | 3 point/11 points | =0.15/0.183 |
| (G) | Gas Mileage | 2 points/10 points | =0.10/0.167 |
| Sum | 20 points/60 points | =1.00 |
| Abbreviation | Criteria | Ordinal Ranking with Index |
|---|---|---|
| (P) | Purchase Price | i = 1 |
| (R) | Reliability | i = 2 |
| (S) | Safety | i = 3 |
| (A) | Attractiveness | i = 4 |
| (G) | Gas Mileage | i = 5 |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (P) | Purchase Price | w1 = 1/5 (1 + 1/2 + 1/3 + 1/4 + 1/5) | =0.457 |
| (R) | Reliability | w2 = 1/5 (1/2 + 1/3 + 1/4 + 1/5) | =0.257 |
| (S) | Safety | w3 = 1/5 (1/3 + 1/4 + 1/5) | =0.157 |
| (A) | Attractiveness | w4 = 1/5 (1/4 + 1/5) | =0.090 |
| (G) | Gas Mileage | w5 = 1/5 (1/5) | =0.040 |
| Sum | w1 + w2 + w3 + w4 + w5 | ~1.00 |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (P) | Purchase Price | w1 = (2 (5 + 1 − 1))/(5 (5 + 1)) | =0.333 |
| (R) | Reliability | w2 = (2 (5 + 1 − 2))/(5 (5 + 1)) | =0.267 |
| (S) | Safety | w3 = (2 (5 + 1 − 3))/(5 (5 + 1)) | =0.200 |
| (A) | Attractiveness | w4 = (2 (5 + 1 − 4))/(5 (5 + 1)) | =0.133 |
| (G) | Gas Mileage | w5 = (2 (5 + 1 − 5))/(5 (5 + 1)) | =0.067 |
| Sum | w1 + w2 + w3 + w4 + w5 | =1.00 |
| Abbreviation | Criteria | Formula | Weight |
|---|---|---|---|
| (P) | Purchase Price | w1 = 1/(i × ) = 1/(1 × ((1/1)+(1/2)+(1/3)+(1/4)+(1/5))) | =0.438 |
| (R) | Reliability | w2 = 1/(i × ) = 1/(2 × ((1/1)+(1/2)+(1/3)+(1/4)+(1/5))) | =0.218 |
| (S) | Safety | w3 = 1/(i × ) = 1/(3 × ((1/1)+(1/2)+(1/3)+(1/4)+(1/5))) | =0.146 |
| (A) | Attractiveness | w4 = 1/(i × ) = 1/(4 × ((1/1)+(1/2)+(1/3)+(1/4)+(1/5))) | =0.109 |
| (G) | Gas Mileage | w5 = 1/(i × ) = 1/(5 × ((1/1)+(1/2)+(1/3)+(1/4)+(1/5))) | =0.088 |
| Sum | w1 + w2 + w3 + w4 + w5 | ~1.00 |
| Method | Advantages | Disadvantages | Uses |
|---|---|---|---|
| Direct assignment technique | Straightforward | Must be repeated if attributes change Sensitive to reference point | Situations in which attributes have clear separation in terms of importance |
| Effort scales linearly with the number of attributes | |||
| Easily implemented with spreadsheet or calculator | |||
| Simple multi attribute rating technique (SMART)/SMARTER/SMARTS | Attributes can change without redoing assessment | Attribute value ranges influence weights | Situations in which attributes have clear separation in terms of importance |
| Effort scales linearly with number of attributes | Scenarios where scales for attributes are clear | ||
| Greater weight diversity than SWING | |||
| Swing weighting | Attributes can change without redoing assessment | Limited number of weights available | Situations in which attributes have clear separation in terms of importance |
| Effort scales linearly with number of attributes | Scenarios where scales for attributes are clear | ||
| Simple pairwise comparison | Low effort | Does not prevent weight inconsistency | Situations in which attributes have clear separation in terms of importance |
| Scenarios where scales for attributes are clear |
| Method | Advantages | Disadvantages | Uses |
|---|---|---|---|
| Equal weighting | Easiest of all methods | Few if any real world scenarios have all attributes of equal importance | Early in the decision process |
| Easily implemented with spreadsheet or calculator | Inaccurate relative to other techniques | Situations with incomplete or no attribute information | |
| Scenarios where a large number of attributes are present | |||
| Rank Ordered Centroid | Uses ordinal ranking only to determine weights | Based on uniform distribution | Analyst is unwilling to assign specifics weights |
| Easily implemented with spreadsheet or calculator | Scenarios when consensus may not be necessary or desirable, but ranking can be agreed upon [80] | ||
| Scenarios where a large number of attributes are present | |||
| Rank Sum | Uses ordinal ranking only to determine weights | Based on uniform distribution | Analyst is unwilling to assign specifics weights |
| Easily implemented with spreadsheet or calculator | Scenarios when consensus may not be necessary or desirable, but ranking can be agreed upon [80] | ||
| Scenarios where a large number of attributes are present | |||
| Rank Reciprocal | Uses ordinal ranking only to determine weights | Only useful when more precise weighting is not available | Analyst is unwilling to assign specific weights |
| Easily implemented with spreadsheet or calculator | Scenarios when consensus may not be necessary or desirable, but ranking can be agreed upon [80] | ||
| Scenarios where a large number of attributes are present |
| Ratio Assignment Technique | Agent Based Modeling | Discrete Event Simulation | System Dynamics |
|---|---|---|---|
| Direct assignment technique | Known * or accepted ^ criteria that direct an agent towards their goals or one decision outcome or another | Known or accepted decision path probabilities; Known or accepted resource schedules | Known or accepted coefficient values within ordinary differential equation (ODE), partial differential equation (PDE) or difference equation (DE) |
| Simple multi attribute rating technique (SMART)/ SMARTER/ SMARTS | There exists an accepted least important criterion and the remaining criteria are weighted relative to this option. Each agent population may utilize difference weighting preferences. | A least acceptable path is known and the remaining options are weighted relative to this option. Weighting preferences can vary by entity type. | The ODE, PDE, or DE contains a value whose coefficient is known to be least important. Remaining coefficients are weighted relative to this coefficient. |
| Swing weighting | Order of importance is known/accepted but the most important element is not always the top ranked. Current rankings and known important criterion are used to establish weightings of remaining criteria. | Top ranked path or most desirable schedule are known but do not always remain top ranked during execution. Selections are made relative to the known choice based on its current ranking. | Coefficient weightings are intended to weight towards a specified most important criterion; however, new weights are generated based on magnitude of change from previous check to incorporate stochasticity. |
| Simple pairwise comparison | No established known or accepted ranking of criteria weightings. Agent compares all available criteria to accumulate weighting scores. | No established known or accepted ranking of criteria weightings. Entities or resources compare all available criteria to accumulate weighting scores for path probabilities or scheduling. | No established known or accepted ranking of criteria (e.g., coefficient) weightings. Equation coefficient weightings accumulate based on comparisons of all criteria. |
| Approximate Technique | Agent Based Modeling | Discrete Event Simulation | System Dynamics |
|---|---|---|---|
| Equal Weighting | Agent decision criterion is assumed of equal importance. This technique may be applicable in cases where the use of the uniform distribution for sampling is appropriate. | Path selection or resource selection is assumed of equal importance. This technique may be applicable in cases where the use of the uniform distribution for sampling is appropriate. | Values of coefficient weightings are assumed of equal importance. |
| Rank Ordered Centroid Technique | Order of importance of decision criterion are based on the aggregate orderings from each agent and update over time. | Resource schedules depend on aggregate rankings of criterion from the entities or resources which change as resource availabilities (e.g., through schedules) change or as aggregated weight and processing times change. | Values of coefficient weightings are based on the aggregate performance of stock or auxiliary variable performance over time. |
| Rank Sum Technique | Weightings are based on aggregated rankings of importance from each agent based on a utility function. | Weightings are based on aggregated rankings of importance from each entity over time based on a utility function. | Weightings are based on aggregated rankings of importance of stocks or auxiliary variables over time based on a utility function. |
| Rank Reciprocal | Weightings are based on aggregated rankings of importance from each agent based on preference. | Weightings are based on aggregated rankings of preferred importance from each entity per entity type. | Weightings are based on aggregated rankings of importance of stocks or auxiliary variables over time based on preference. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ezell, B.; Lynch, C.J.; Hester, P.T. Methods for Weighting Decisions to Assist Modelers and Decision Analysts: A Review of Ratio Assignment and Approximate Techniques. Appl. Sci. 2021, 11, 10397. https://doi.org/10.3390/app112110397
Ezell B, Lynch CJ, Hester PT. Methods for Weighting Decisions to Assist Modelers and Decision Analysts: A Review of Ratio Assignment and Approximate Techniques. Applied Sciences. 2021; 11(21):10397. https://doi.org/10.3390/app112110397
Chicago/Turabian StyleEzell, Barry, Christopher J. Lynch, and Patrick T. Hester. 2021. "Methods for Weighting Decisions to Assist Modelers and Decision Analysts: A Review of Ratio Assignment and Approximate Techniques" Applied Sciences 11, no. 21: 10397. https://doi.org/10.3390/app112110397
APA StyleEzell, B., Lynch, C. J., & Hester, P. T. (2021). Methods for Weighting Decisions to Assist Modelers and Decision Analysts: A Review of Ratio Assignment and Approximate Techniques. Applied Sciences, 11(21), 10397. https://doi.org/10.3390/app112110397