
An Intelligent Approach to Resource Allocation on Heterogeneous Cloud Infrastructures


Abstract
:1. Introduction
- A resource allocation hierarchical framework (Section 3) based on: (i) an improved version of our data placement algorithm previously presented in [9], which can now handle multicloud storage, and (ii) an algorithm for efficient virtual machine allocation that can handle NUMA domains and the shared memory patterns of applications.
- A formulation of the problem of virtual machine placement on NUMA nodes as a genetic programming problem, and an implementation of an algorithm based on this formulation that optimizes virtual machine allocation, with the aim of improving the performance of applications running on virtual machines allocated to NUMA nodes (Section 3.1).
- A comparison of our genetic programming algorithms against alternative resource allocation algorithms by applying them to a big data cluster and NUMA nodes, and running a set of benchmarks that represent scientific applications (Section 4).
2. Background
2.1. Cloud Infrastructure for Data Storage and Processing
2.1.1. Hadoop Framework
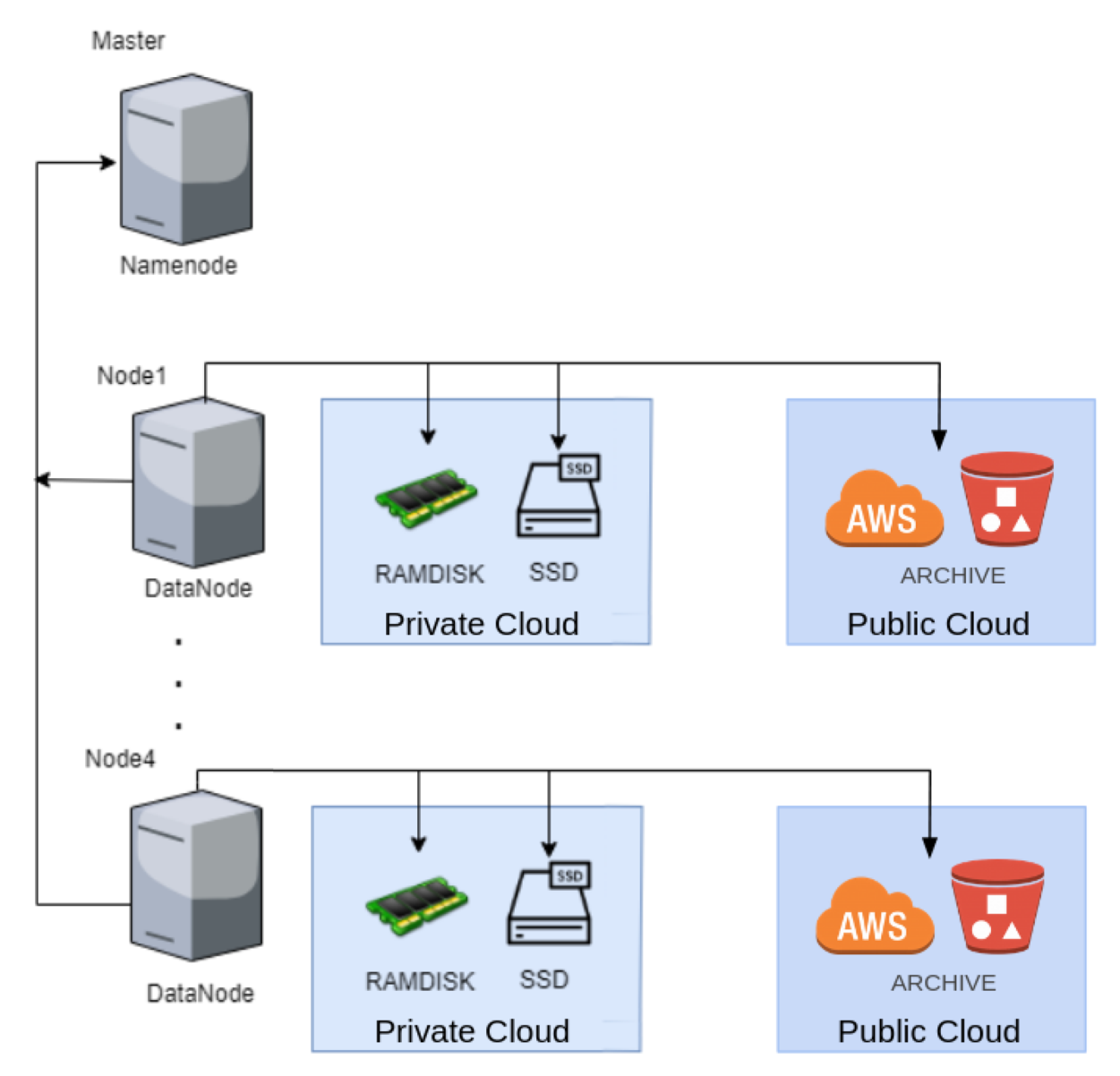
Hadoop Distributed File System
Hadoop Heterogeneous Storage
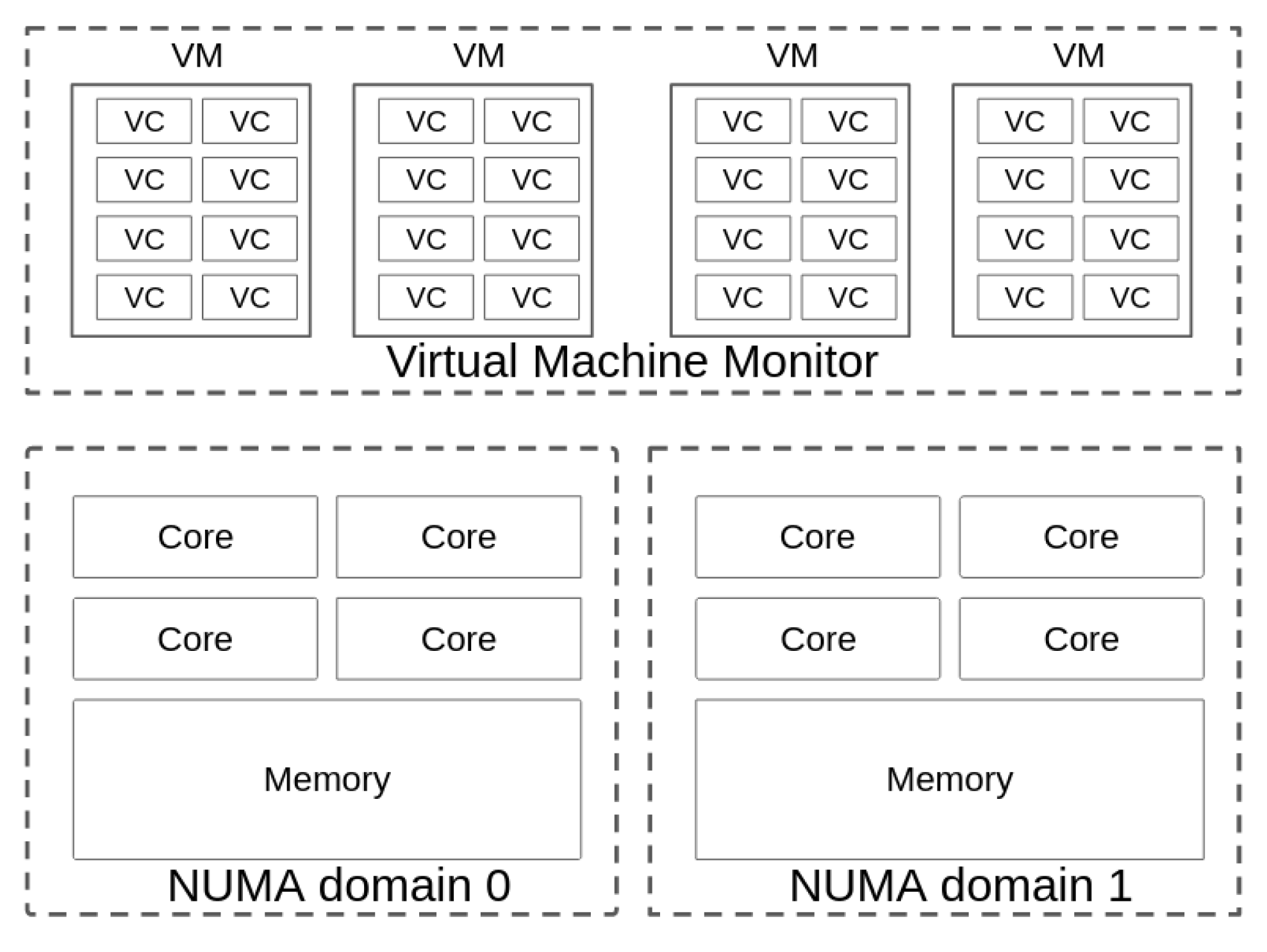
2.2. Virtual Machine Allocation on NUMA Nodes
2.3. Optimization Methods for Cloud Resource Allocation
2.3.1. Simplex
2.3.2. Generalized Reduced Gradient
- 1.
- Selection of a direction;
- 2.
- Movement in the selected direction;
- 3.
- Analysis of the convergence criteria.
- Direct, in which the objective function determines Step 1;
- Indirect, in which the derivative of the objective function determines Step 1.
Step 1—Selection of a Direction
Step 2—Movement in the Selected Direction
Step 3—Analysis of the convergence criteria
2.3.3. Genetic Algorithm
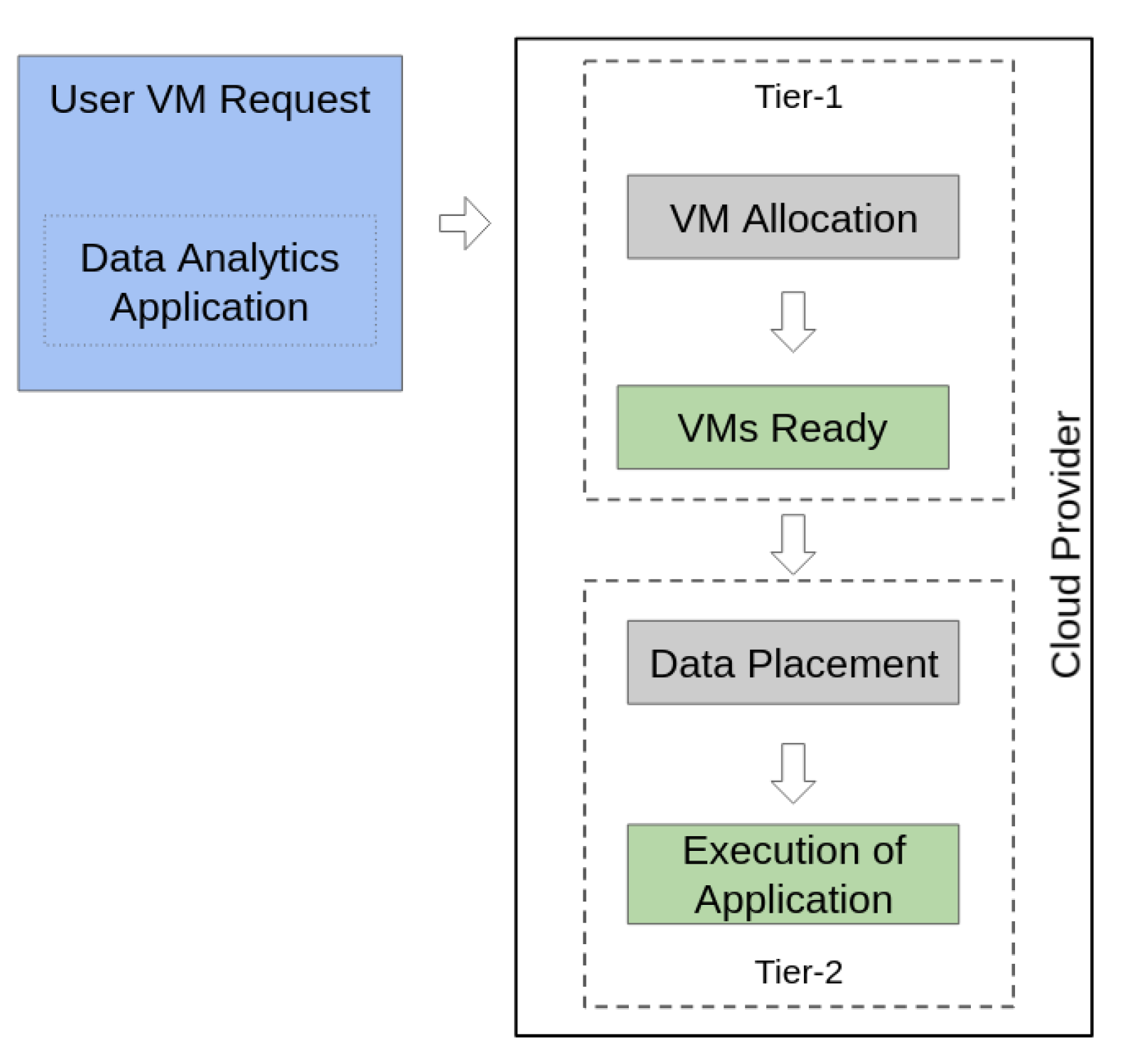
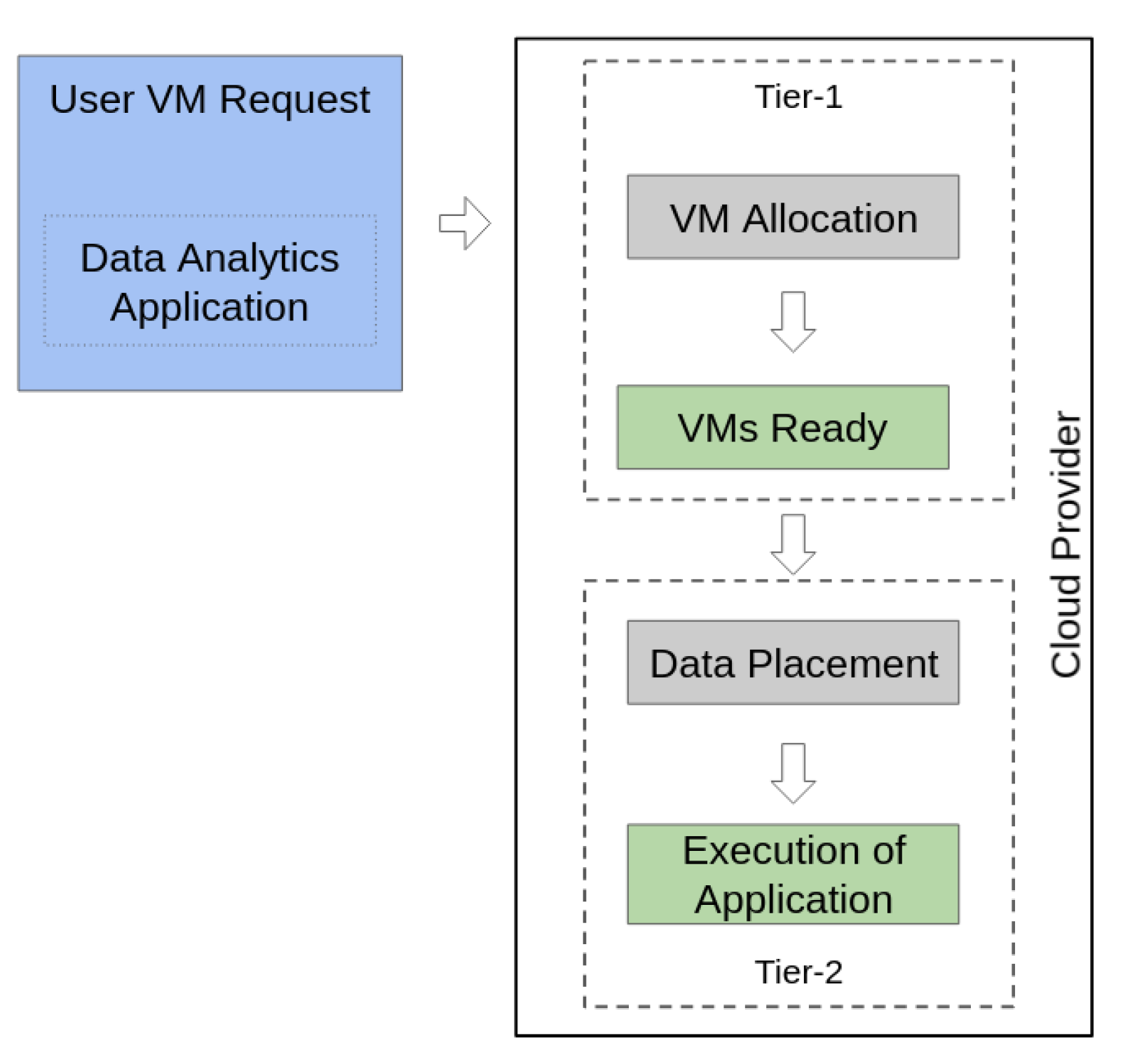
3. Allocating Resources in Heterogeneous Cloud Infrastructures
3.1. Tier 1: Node Allocation in the Cloud Using Genetic Programming
3.1.1. Allocating Nodes to Virtual Machines
3.1.2. Problem Formulation
Variables
Constraints
Objective Function
3.1.3. The Genetic Programming Algorithm
Chromosome
Population Initialization
Evaluation, Chromosome Repair, and Population Planning
Penalties
Elitism
Selection
Crossover
Mutation
3.2. Tier 2: Data Placement in Heterogeneous Storage
| Algorithm 1 Genetic algorithm for heterogeneous storage. |
|
Generate random population solutions (Chromosomes) while do evaluate each chromosome in the fitness function add penalty factor to the fitness function value if condition for crossover is satisfied then select parents with the best fitness value choose crossover parameters perform crossover end if if condition for mutation is satisfied then choose mutation point perform mutation end if end while |
4. Results and Discussion
4.1. Validating the VM Mapping Genetic Programming Algorithm
4.1.1. NUMA Placement Generation
4.1.2. NUMA Placement Performance
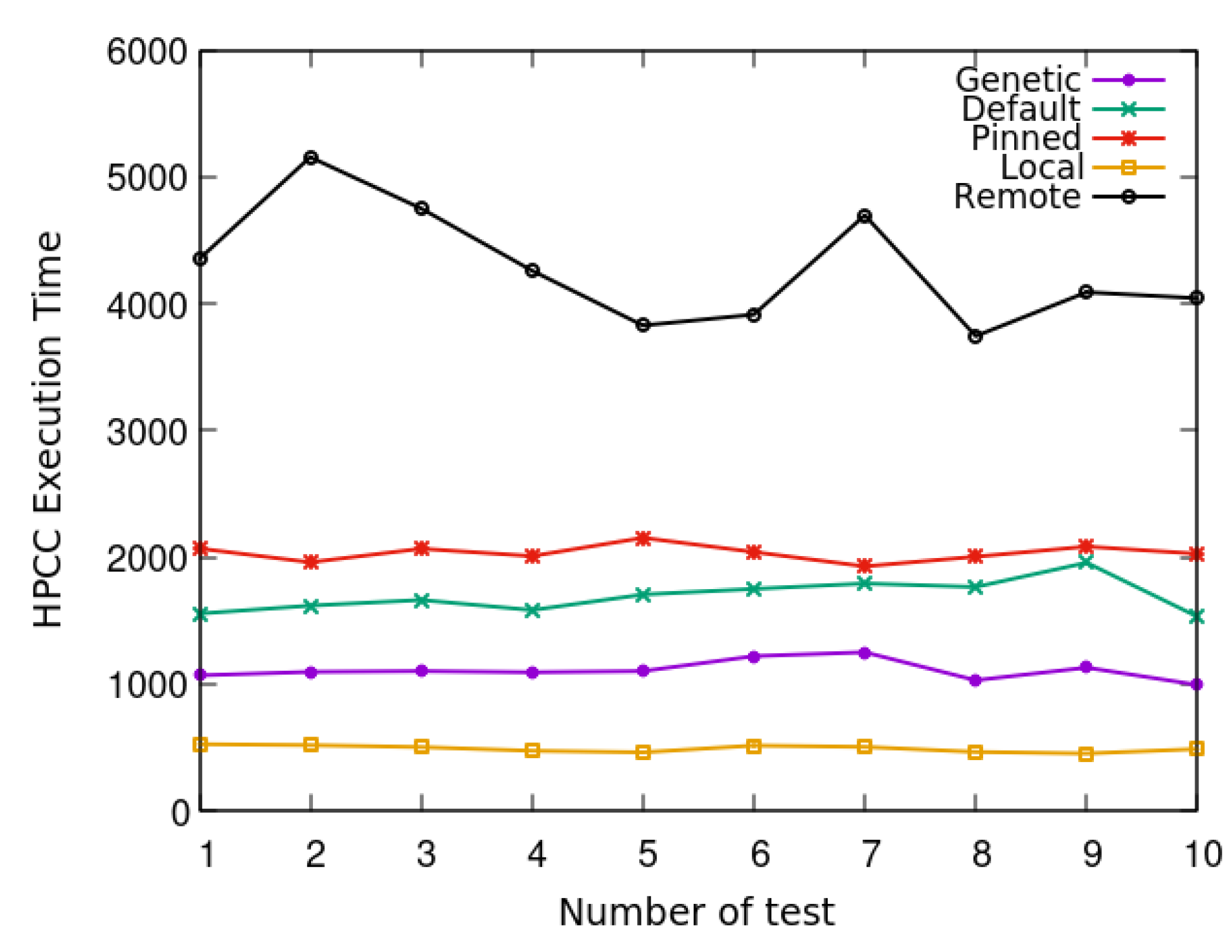
- Default: This is the default mapping of the virtual cores to the physical Xen cores. The default allocation has been modified since Xen 4.2, and now uses a heuristic method to find the VM allocation [27].
- Pinned: After creating a default virtual machine, we can pin each virtual core to each physical core. In this case, each virtual core of a virtual machine is pinned to a different physical core in the same NUMA domain.
- All memory local: After creating a virtual machine, each virtual core is pinned to different physical cores in the same NUMA node. Regarding performance, this is the best case.
- All memory remote: The virtual machine is created and pinned to one node, and is then moved to another node, meaning that all memory accesses are remote.
4.2. Allocating Storage in a Hadoop Cluster
4.2.1. Experimental Setup
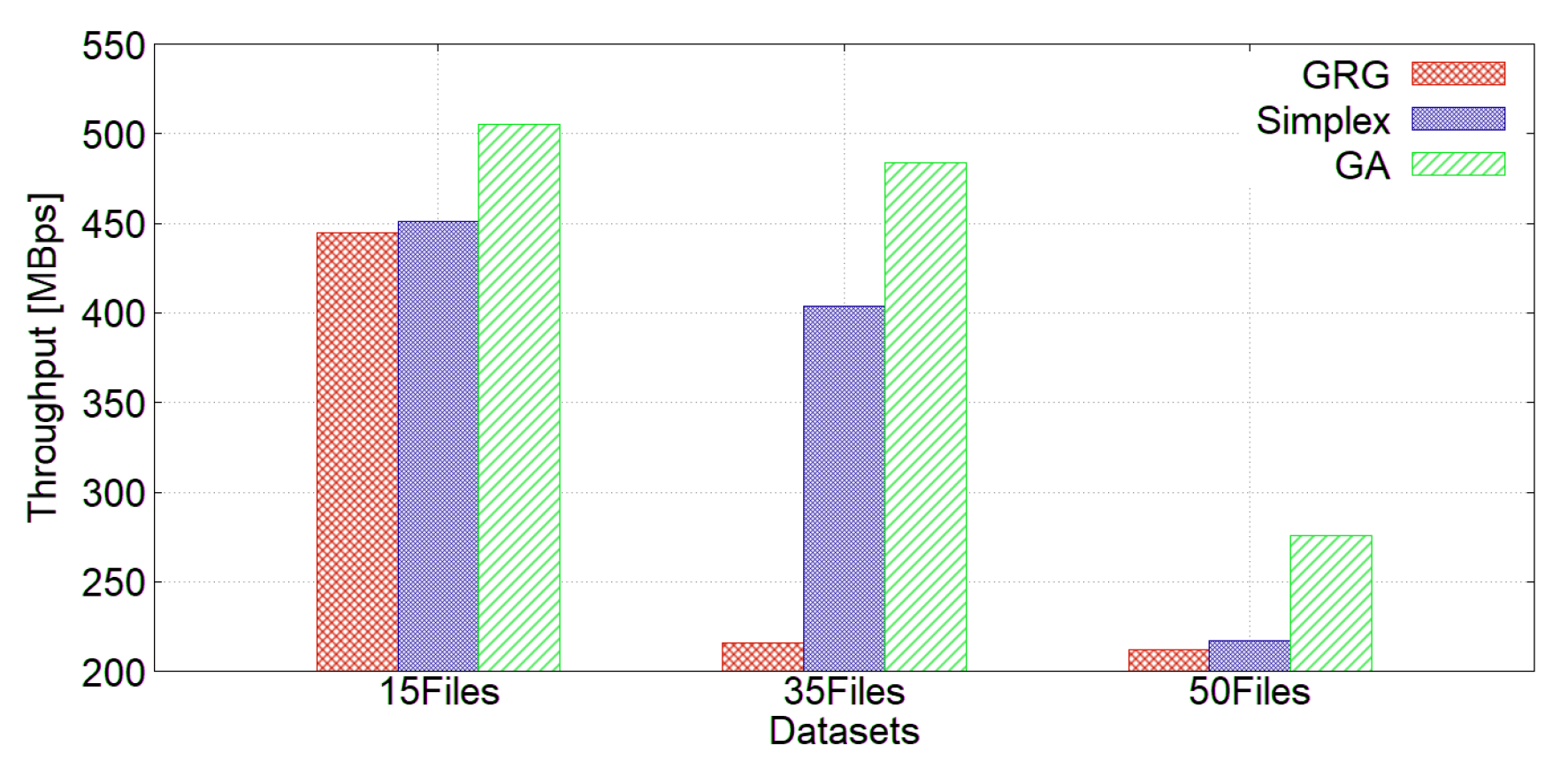
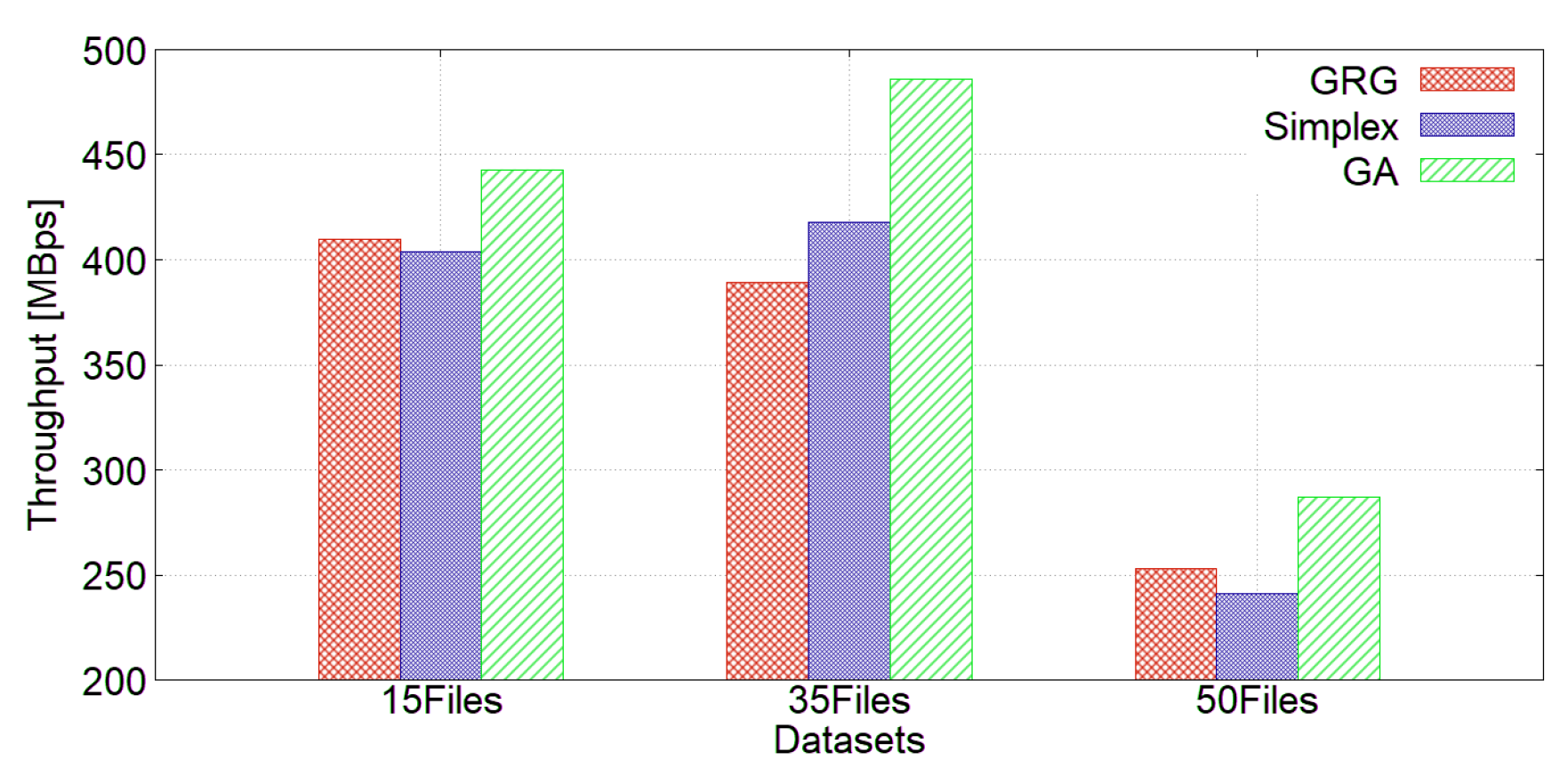
4.2.2. Placing Datasets into an HDFS Cluster Using ARCHIVE
5. Related Work
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rydning, D.R.J.G.J. The Digitization of the World from Edge to Core; International Data Corporation: Framingham, MA, USA, 2018; p. 16. [Google Scholar]
- Li, H.; Li, H.; Wen, Z.; Mo, J.; Wu, J. Distributed heterogeneous storage based on data value. In Proceedings of the 2017 IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 December 2017; pp. 264–271. [Google Scholar] [CrossRef]
- Bezerra, A.; Hernandez, P.; Espinosa, A.; Moure, J.C. Job scheduling in Hadoop with Shared Input Policy and RAMDISK. In Proceedings of the 2014 IEEE International Conference on Cluster Computing, CLUSTER 2014, Madrid, Spain, 22–26 September 2014; pp. 355–363. [Google Scholar] [CrossRef]
- Jeong, J.; Kwak, J.; Lee, D.; Choi, S.; Lee, J.; Choi, J.; Song, Y.H. Level Aware Data Placement Technique for Hybrid NAND Flash Storage of Log-Structured Merge-Tree Based Key-Value Store System. IEEE Access 2020, 8, 188256–188268. [Google Scholar] [CrossRef]
- Sheng, J.; Hu, Y.; Zhou, W.; Zhu, L.; Jin, B.; Wang, J.; Wang, X. Learning to schedule multi-NUMA virtual machines via reinforcement learning. Pattern Recognit. 2022, 121, 108254. [Google Scholar] [CrossRef]
- Sheng, S.; Chen, P.; Chen, Z.; Wu, L.; Yao, Y. Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing. Sensors 2021, 21, 1666. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Liu, R.; Kaushik, A. Hierarchical multi-agent optimization for resource allocation in cloud computing. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 692–707. [Google Scholar] [CrossRef]
- Apache Software Foundation. Hadoop; Apache Software Foundation: Snow Hill, MD, USA, 2009. [Google Scholar]
- Marquez, J.; Gonzalez, J.; Mondragon, O.H. Heterogeneity-aware data placement in Hybrid Clouds. In Proceedings of the 2019 International Conference on Cloud Computing (CLOUD 2019), San Diego, CA, USA, 25–30 June 2019. [Google Scholar]
- White, T. Hadoop: The Definitive Guide; Oreilly and Associate Series; O’Reilly: Sebastopol, CA, USA, 2012. [Google Scholar]
- Hadoop. Archival Storage, SSD & Memory; Apache Software Foundation: Snow Hill, MD, USA, 2009. [Google Scholar]
- Blagodurov, S.; Fedorova, A.; Zhuravlev, S.; Kamali, A. A case for NUMA-aware contention management on multicore systems. In Proceedings of the 2010 19th International Conference on Parallel Architectures and Compilation Techniques (PACT), Vienna, Austria, 11–15 September 2010; pp. 557–558. [Google Scholar]
- Nelder, J.A.; Mead, R. A simplex method for function minimization. Comput. J. 1965, 7, 308–313. [Google Scholar] [CrossRef]
- Lasdon, L.S.; Fox, R.L.; Ratner, M.W. Nonlinear optimization using the generalized reduced gradient method. Rev. Française D’automatique Inform. Rech. Opérationnelle Rech. Opérationnelle 1974, 8, 73–103. [Google Scholar] [CrossRef] [Green Version]
- Gabriele, G.; Ragsdell, K. The generalized reduced gradient method: A reliable tool for optimal design. J. Eng. Ind. 1977, 99, 394–400. [Google Scholar] [CrossRef]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Mondragon, O.H.; Bridges, P.G.; Levy, S.; Ferreira, K.B.; Widener, P. Understanding performance interference in next-generation HPC systems. In Proceedings of the SC’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 13–18 November 2016; pp. 384–395. [Google Scholar]
- Chen, X.; Li, W.; Lu, S.; Zhou, Z.; Fu, X. Efficient resource allocation for on-demand mobile-edge cloud computing. IEEE Trans. Veh. Technol. 2018, 67, 8769–8780. [Google Scholar] [CrossRef] [Green Version]
- Shabeera, T.; Kumar, S.M.; Salam, S.M.; Krishnan, K.M. Optimizing VM allocation and data placement for data-intensive applications in cloud using ACO metaheuristic algorithm. Eng. Sci. Technol. Int. J. 2017, 20, 616–628. [Google Scholar] [CrossRef] [Green Version]
- Farzai, S.; Shirvani, M.H.; Rabbani, M. Multi-objective communication-aware optimization for virtual machine placement in cloud datacenters. Sustain. Comput. Inform. Syst. 2020, 28, 100374. [Google Scholar] [CrossRef]
- Razali, N.M.; Geraghty, J. Genetic algorithm performance with different selection strategies in solving TSP. In Proceedings of the World Congress on Engineering, Hong Kong, China, 6–8 July 2011; Volume 2, pp. 1–6. [Google Scholar]
- Gwiazda, T.D. Genetic Algorithms Reference Vol. I. Crossover for Single-Objective Numerical Optimization Problems [Online]. TOMASZGWIAZDA E-BOOKS. 2006. Available online: http://www.tomaszgwiazda.com/Genetic_algorithms_reference_first_40_pages.pdf (accessed on 26 June 2021).
- Guzek, M.; Bouvry, P.; Talbi, E.G. A survey of evolutionary computation for resource management of processing in cloud computing. IEEE Comput. Intell. Mag. 2015, 10, 53–67. [Google Scholar] [CrossRef]
- Barham, P.; Dragovic, B.; Fraser, K.; Hand, S.; Harris, T.; Ho, A.; Neugebauer, R.; Pratt, I.; Warfield, A. Xen and the art of virtualization. ACM SIGOPS Oper. Syst. Rev. 2003, 37, 164–177. [Google Scholar] [CrossRef]
- Duplyakin, D.; Ricci, R.; Maricq, A.; Wong, G.; Duerig, J.; Eide, E.; Stoller, L.; Hibler, M.; Johnson, D.; Webb, K.; et al. The Design and Operation of CloudLab. In Proceedings of the USENIX Annual Technical Conference (ATC), Renton, WA, USA, 10–12 July 2019; pp. 1–14. [Google Scholar]
- Luszczek, P.; Dongarra, J.J.; Koester, D.; Rabenseifner, R.; Lucas, B.; Kepner, J.; McCalpin, J.; Bailey, D.; Takahashi, D. Introduction to the HPC Challenge Benchmark Suite; Technical Report; Ernest Orlando Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2005. [Google Scholar]
- Project, X. Xen 4.2 Automatic NUMA Placement; Xen Project: San Francisco, CA, USA, 2015. [Google Scholar]
- Voron, G.; Thomas, G.; Quéma, V.; Sens, P. An interface to implement NUMA policies in the Xen hypervisor. In Proceedings of the Twelfth European Conference on Computer Systems, Belgrade, Serbia, 23–26 April 2017; pp. 453–467. [Google Scholar]
- Keahey, K.; Anderson, J.; Zhen, Z.; Riteau, P.; Ruth, P.; Stanzione, D.; Cevik, M.; Colleran, J.; Gunawi, H.S.; Hammock, C.; et al. Lessons Learned from the Chameleon Testbed. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC ’20), Online, 15–17 July 2020. [Google Scholar]
- Qian, J.; Li, J.; Ma, R.; Guan, H. Optimizing Virtual Resource Management for Consolidated NUMA Systems. In Proceedings of the 2018 IEEE 36th International Conference on Computer Design (ICCD), Orlando, FL, USA, 7–10 October 2018; pp. 573–576. [Google Scholar]
- Wu, S.; Sun, H.; Zhou, L.; Gan, Q.; Jin, H. vprobe: Scheduling virtual machines on numa systems. In Proceedings of the 2016 IEEE International Conference on Cluster Computing (CLUSTER), Taipei, Taiwan, 12–16 September 2016; pp. 70–79. [Google Scholar]
- Mondragon, O.H.; Bridges, P.G.; Jones, T. Quantifying scheduling challenges for exascale system software. In Proceedings of the 5th International Workshop on Runtime and Operating Systems for Supercomputers, Portland, OR, USA, 16 June 2015; pp. 1–8. [Google Scholar]
- Rao, J.; Wang, K.; Zhou, X.; Xu, C.Z. Optimizing virtual machine scheduling in NUMA multicore systems. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 306–317. [Google Scholar]
- Ali, I.M.; Sallam, K.M.; Moustafa, N.; Chakraborty, R.; Ryan, M.J.; Choo, K.K.R. An automated task scheduling model using non-dominated sorting genetic algorithm ii for fog-cloud systems. IEEE Trans. Cloud Comput. 2020. [Google Scholar] [CrossRef]
- Tan, B.; Ma, H.; Mei, Y.; Zhang, M. A Cooperative Coevolution Genetic Programming Hyper-Heuristic Approach for On-line Resource Allocation in Container-based Clouds. IEEE Trans. Cloud Comput. 2020. [Google Scholar] [CrossRef]
- Belgacem, A.; Beghdad-Bey, K.; Nacer, H. Dynamic resource allocation method based on Symbiotic Organism Search algorithm in cloud computing. IEEE Trans. Cloud Comput. 2020. [Google Scholar] [CrossRef]
- Wang, W.; Tornatore, M.; Zhao, Y.; Chen, H.; Li, Y.; Gupta, A.; Zhang, J.; Mukherjee, B. Infrastructure-efficient Virtual-Machine Placement and Workload Assignment in Cooperative Edge-Cloud Computing over Backhaul Networks. IEEE Trans. Cloud Comput. 2021. [Google Scholar] [CrossRef]
- Liu, N.; Li, Z.; Xu, J.; Xu, Z.; Lin, S.; Qiu, Q.; Tang, J.; Wang, Y. A hierarchical framework of cloud resource allocation and power management using deep reinforcement learning. In Proceedings of the 2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS), Atlanta, GA, USA, 5–8 June 2017; pp. 372–382. [Google Scholar]
- Yang, C.T.; Chen, S.T.; Cheng, W.H.; Chan, Y.W.; Kristiani, E. A heterogeneous cloud storage platform with uniform data distribution by software-defined storage technologies. IEEE Access 2019, 7, 147672–147682. [Google Scholar] [CrossRef]
- Guan, Y.; Ma, Z.; Li, L. HDFS Optimization Strategy Based On Hierarchical Storage of Hot and Cold Data. Procedia CIRP 2019, 83, 415–418. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, J.; Shi, Y. Resource and Job Execution Context-Aware Hadoop Configuration Tuning. In Proceedings of the 2020 IEEE 13th International Conference on Cloud Computing (CLOUD), Beijing, China, 19–23 October 2020; pp. 116–123. [Google Scholar]
- Qian, Z.; Gao, Y.; Ji, M.; Peng, H.; Chen, P.; Jin, Y.; Lu, S. Workload-Aware Scheduling for Data Analytics upon Heterogeneous Storage. In Proceedings of the 2019 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Xiamen, China, 16–18 December 2019; pp. 580–587. [Google Scholar]
- Guerrero, C.; Lera, I.; Bermejo, B.; Juiz, C. Multi-objective optimization for virtual machine allocation and replica placement in virtualized hadoop. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 2568–2581. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description |
|---|---|
| V | Set of virtual cores |
| P | Set of physical cores |
| Number of virtual cores | |
| Number of physical cores | |
| Number of NUMA domains | |
| Minimal utilization required by a virtual core i on a physical core j | |
| States if a virtual core i is mapped to a physical core j; if that mapping exits, is set to one, otherwise, it is set to 0 | |
| Physical core j utilization |
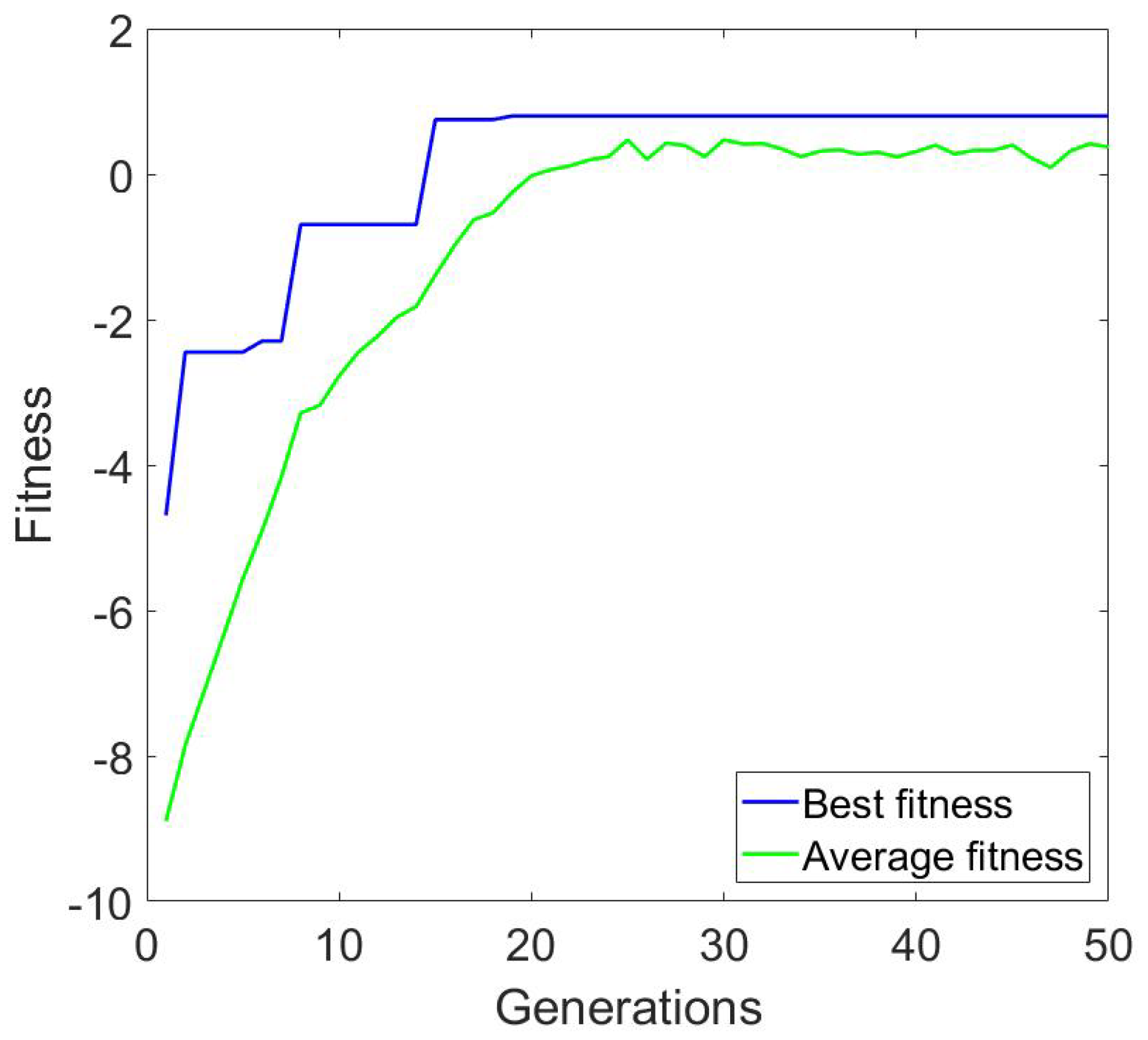
| Test | Parameters | Time to Solve (s) | Best Fitness | Avg. Fitness |
|---|---|---|---|---|
| 1 | , , , | 0.67 | 0.8 | 0.37 |
| 2 | , , , | 3.24 | 0.79 | 0.27 |
| 3 | , , , | 13.69 | 0.67 | −0.7 |
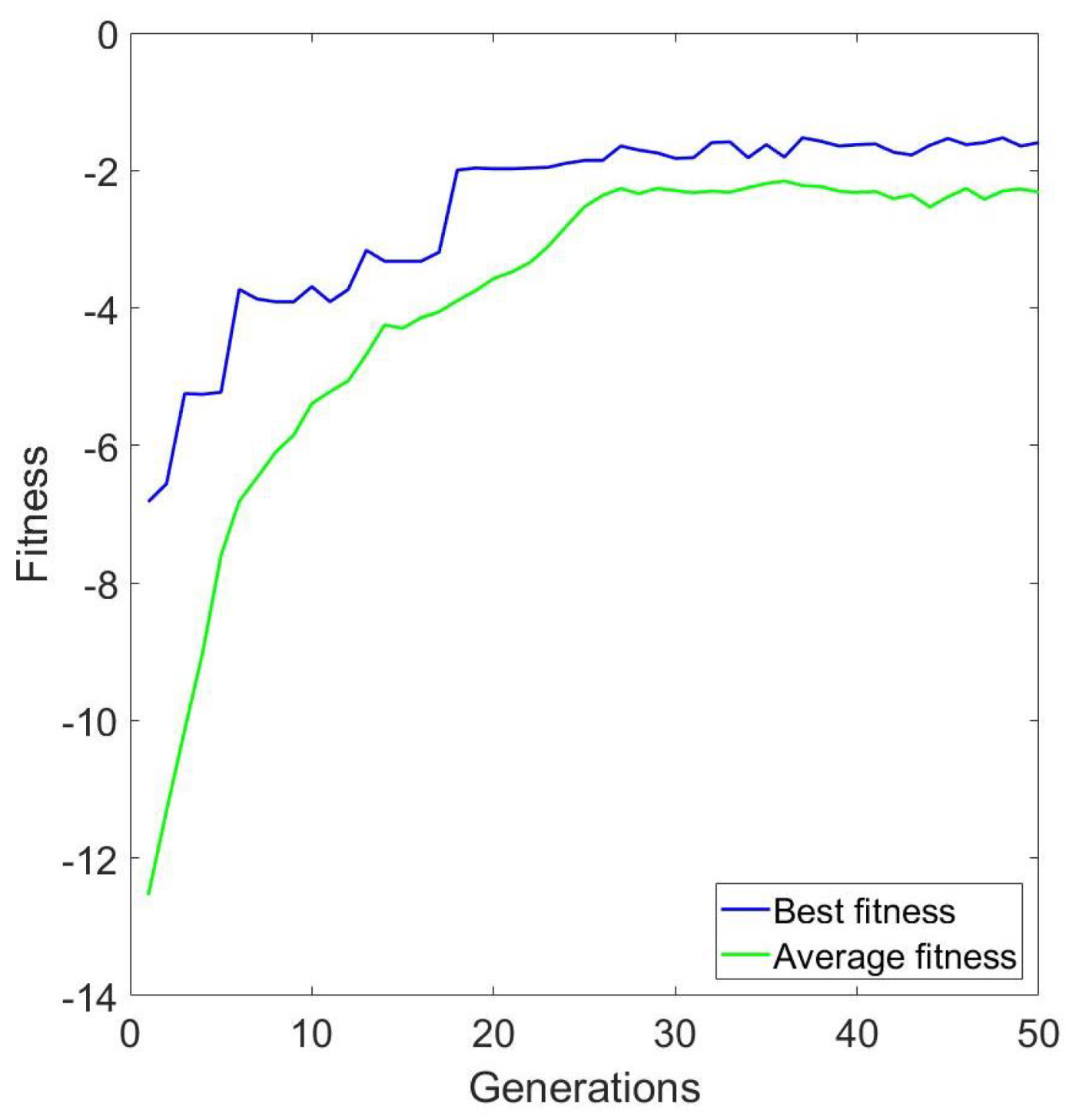
| Test | Parameters | Time to Solve (s) | Best Fitness | Avg. Fitness |
|---|---|---|---|---|
| 4 | , , , | 9.82 | −1.59 | −2.3 |
| 5 | , , , | 14.05 | −0.003 | −0.32 |
| 6 | , , , | 85.91 | −2.27 | −2.89 |
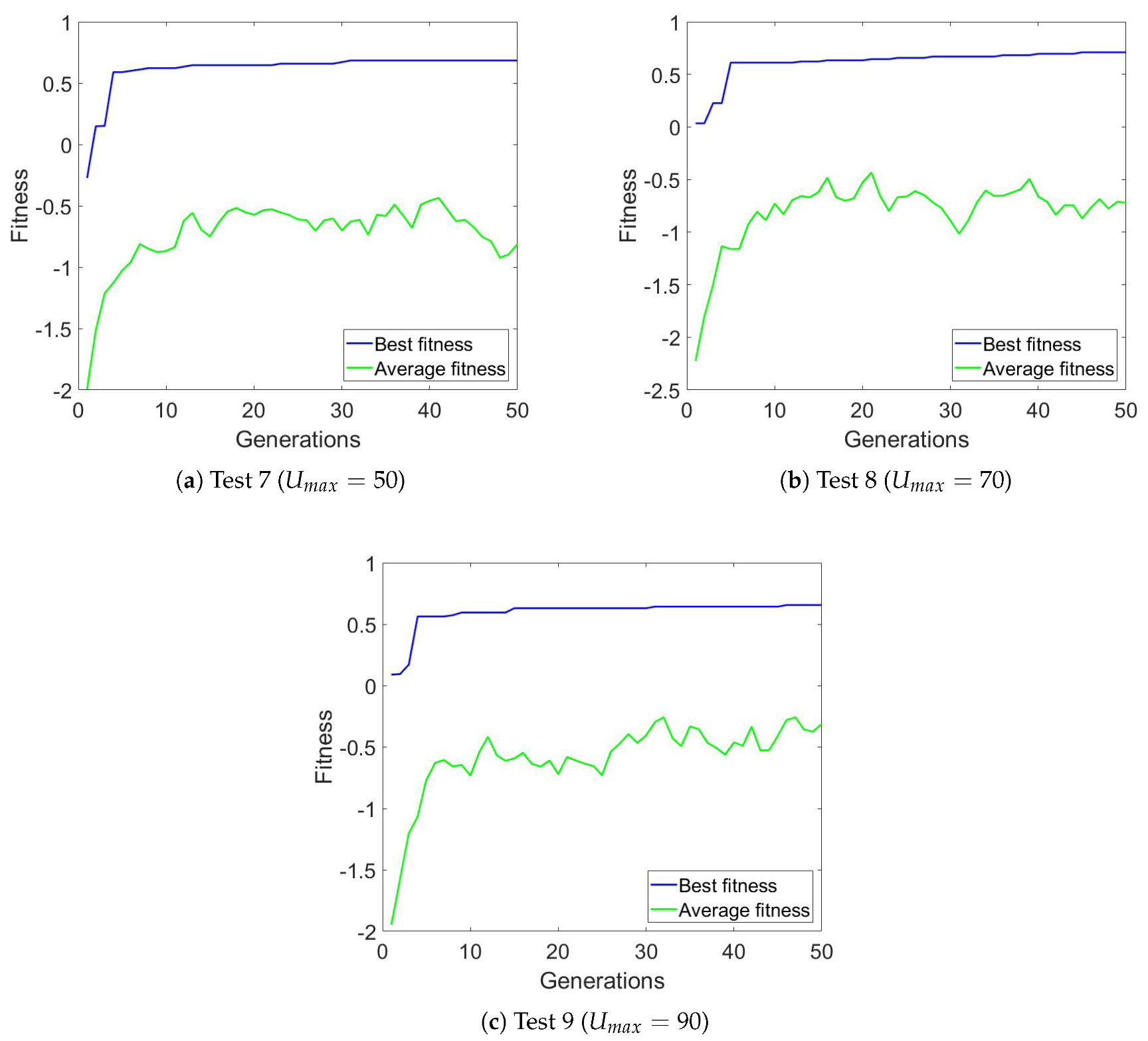
| Test | Parameters | Time to Solve (s) | Best Fitness | Avg. Fitness |
|---|---|---|---|---|
| 7 | 16.69 | 0.68 | −0.81 | |
| 8 | 15.49 | 0.71 | −0.72 | |
| 9 | 14.22 | 0.66 | −0.31 |
| Parameter | Element |
|---|---|
| Number of datasets | 15, 35, 50 |
| Number of storage types | 3 |
| Total cluster RAM_DISK storage capacity | 200 GB |
| Total cluster SSD storage capacity | 4 TB |
| Total cluster ARCHIVE storage capacity | Unlimited |
| RAM_DISK bandwidth | 1870 MB/s |
| SSD bandwidth | 295 MB/s |
| ARCHIVE bandwidth | 22 MB/s |
| Dataset size | 0 ≤ DSS ≤ 200 GB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marquez, J.; Mondragon, O.H.; Gonzalez, J.D. An Intelligent Approach to Resource Allocation on Heterogeneous Cloud Infrastructures. Appl. Sci. 2021, 11, 9940. https://doi.org/10.3390/app11219940
Marquez J, Mondragon OH, Gonzalez JD. An Intelligent Approach to Resource Allocation on Heterogeneous Cloud Infrastructures. Applied Sciences. 2021; 11(21):9940. https://doi.org/10.3390/app11219940
Chicago/Turabian StyleMarquez, Jack, Oscar H. Mondragon, and Juan D. Gonzalez. 2021. "An Intelligent Approach to Resource Allocation on Heterogeneous Cloud Infrastructures" Applied Sciences 11, no. 21: 9940. https://doi.org/10.3390/app11219940
APA StyleMarquez, J., Mondragon, O. H., & Gonzalez, J. D. (2021). An Intelligent Approach to Resource Allocation on Heterogeneous Cloud Infrastructures. Applied Sciences, 11(21), 9940. https://doi.org/10.3390/app11219940