
Elastic CRFs for Open-Ontology Slot Filling

 , ,
, , 
Abstract
:1. Introduction
2. Related Work
3. Proposed Model
3.1. Slot Description Encoder
3.2. BiLSTM Feature Extractor
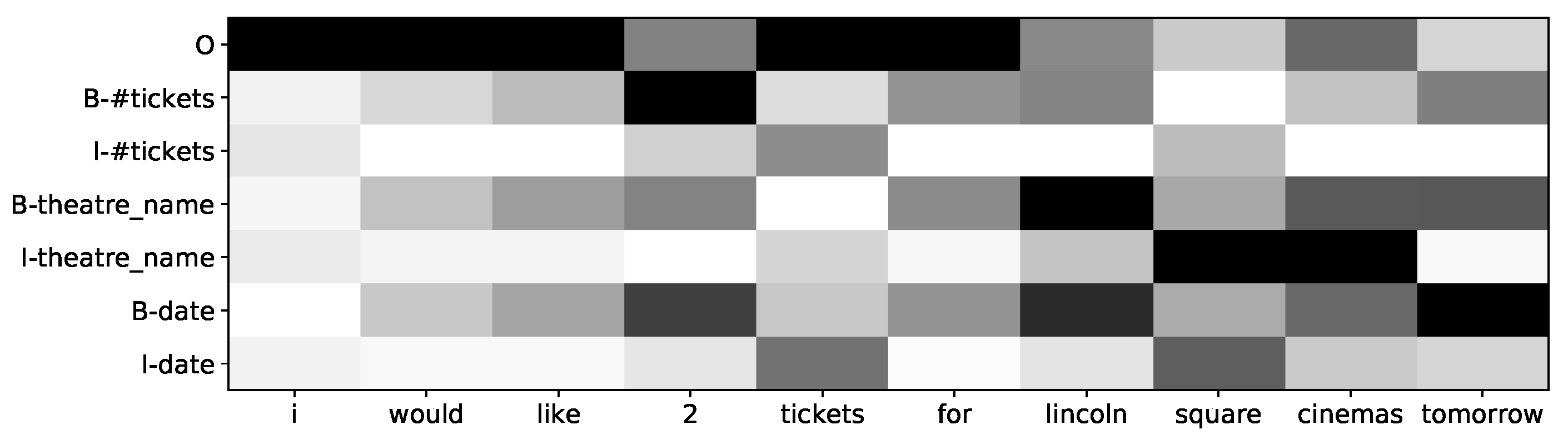
3.3. Elastic CRF (eCRF) Labeler
4. Dataset and Tasks
5. Experiments
5.1. Baselines
5.2. Experimental Setup
5.3. In-Domain Task Results
5.4. Cross-Domain Task Results
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, Y.Y.; Deng, L.; Acero, A. Spoken language understanding. Signal Process. Mag. IEEE 2005, 22, 16–31. [Google Scholar] [CrossRef]
- Mesnil, G.; Dauphin, Y.; Yao, K.; Bengio, Y.; Deng, L.; Hakkani-Tur, D.; He, X.; Heck, L.; Tur, G.; Yu, D. Using recurrent neural networks for slot filling in spoken language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 530–539. [Google Scholar] [CrossRef]
- Ramshaw, L.A.; Marcus, M.P. Text Chunking Using Transformation-Based Learning; Springer: Dordrecht, The Netherlands, 1999. [Google Scholar]
- Lafferty, J.D.; Mccallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the ICML, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Liu, B.; Lane, I. Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling; Interspeech: San Francisco, CA, USA, 2016. [Google Scholar]
- Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 Shared Task: Language-Independent Named Entity Recognition. In Proceedings of the HLT-NAACL, Edmonton, AB, Canada, 27 May 2003. [Google Scholar]
- Liu, B.; Lane, I. Recurrent Neural Network Structured Output Prediction for Spoken Language Understanding. In Proceedings of the NIPS Workshop on Machine Learning for Spoken Language Understanding and Interactions, Montreal, QC, Canada, 11 December 2015. [Google Scholar]
- Rastogi, A.; Hakkani-Tür, D.Z.; Heck, L.P. Scalable multi-domain dialogue state tracking. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Okinawa, Japan, 16–20 December 2017; pp. 561–568. [Google Scholar]
- Hakkani-Tür, D.; Tur, G.; Celikyilmaz, A.; Chen, Y.N.; Gao, J.; Deng, L.; Wang, Y.Y. Multi-Domain Joint Semantic Frame Parsing using Bi-directional RNN-LSTM; InterSpeech: San Francisco, CA, USA, 2016. [Google Scholar]
- Mrksic, N.; Séaghdha, D.Ó.; Thomson, B.; Gasic, M.; Su, P.H.; Vandyke, D.; Wen, T.H.; Young, S.J. Multi-Domain Dialog State Tracking Using Recurrent Neural Networks. In Proceedings of the ACL, Beijing, China, 26–31 July 2015. [Google Scholar]
- Jaech, A.; Heck, L.P.; Ostendorf, M. Domain Adaptation of Recurrent Neural Networks for Natural Language Understanding; Interspeech: San Francisco, CA, USA, 2016. [Google Scholar]
- Bapna, A.; Tür, G.; Hakkani-Tür, D.Z.; Heck, L.P. Towards Zero-Shot Frame Semantic Parsing for Domain Scaling; Interspeech: Stockholm, Sweden, 2017. [Google Scholar]
- Shah, P.; Hakkani-Tür, D.Z.; Tür, G.; Rastogi, A.; Bapna, A.; Nayak, N.; Heck, L.P. Building a Conversational Agent Overnight with Dialogue Self-Play. arXiv 2018, arXiv:1801.04871. [Google Scholar]
- Larochelle, H.; Erhan, D.; Bengio, Y. Zero-Data Learning of New Tasks. In Proceedings of the AAAI 2014, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Chen, Y.N.; Hakkani-Tür, D.; He, X. Zero-Shot Learning of Intent Embeddings for Expansion by Convolutional Deep Structured Semantic Models. In Proceedings of the ICASSP 2016, Shanghai, China, 20–25 March 2016. [Google Scholar]
- Zhao, T.; Eskénazi, M. Zero-Shot Dialog Generation with Cross-Domain Latent Actions; SIGDIAL: Edinburgh, UK, 2018. [Google Scholar]
- Shah, D.; Gupta, R.; Fayazi, A.; Hakkani-Tur, D. Robust Zero-Shot Cross-Domain Slot Filling with Example Values. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 5484–5490. [Google Scholar]
- Lin, Z.; Liu, B.; Moon, S.; Crook, P.; Zhou, Z.; Wang, Z.; Yu, Z.; Madotto, A.; Cho, E.; Subba, R. Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue StateTracking. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 4 November 2021; pp. 5640–5648. [Google Scholar] [CrossRef]
- Chen, T.; Xu, R.; He, Y.; Wang, X. Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN. Expert Syst. Appl. 2017, 72, 221–230. [Google Scholar] [CrossRef] [Green Version]
- Xu, P.; Sarikaya, R. Convolutional Neural Network Based Triangular CRF for Joint Intent Detection and Slot Filling; ASRU: Olomouc, Czech Republic, 2014; pp. 78–83. [Google Scholar]
- Kurata, G.; Xiang, B.; Zhou, B.; Yu, M. Leveraging Sentence-Level Information with Encoder LSTM for Semantic Slot Filling. In Proceedings of the EMNLP 2016, Austin, TX, USA, 1–5 November 2016. [Google Scholar]
- Vu, N.T.; Gupta, P.; Adel, H.; Schütze, H. Bi-Directional Recurrent Neural Network with Ranking Loss for Spoken Language Understanding. In Proceedings of the ICASSP 2016, Shanghai, China, 20–25 March 2016. [Google Scholar]
- Chen, Y.N.; Hakkani-Tür, D.; Tur, G.; Gao, J.; Deng, L. End-to-End Memory Networks with Knowledge Carryover for Multi-Turn Spoken Language Understanding; InterSpeech: San Francisco, CA, USA, 2016. [Google Scholar]
- Liu, Z.; Winata, G.I.; Xu, P.; Fung, P. Coach: A Coarse-to-Fine Approach for Cross-domain Slot Filling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 19–25. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A unified MRC framework for named entity recognition. arXiv 2019, arXiv:1910.11476. [Google Scholar]
- Gao, S.; Agarwal, S.; Chung, T.; Jin, D.; Hakkani-Tur, D. From machine reading comprehension to dialogue state tracking: Bridging the gap. arXiv 2020, arXiv:2004.05827. [Google Scholar]
- Yu, M.; Liu, J.; Chen, Y.; Xu, J.; Zhang, Y. Cross-Domain Slot Filling as Machine Reading Comprehension. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Montreal, QC, Canada, 19–26 August 2021; Zhou, Z.H., Ed.; pp. 3992–3998. [Google Scholar]
- Ma, X.; Hovy, E. End-to-End Sequence Labeling via Bi-Directional LSTM-CNNs-CRF. In Proceedings of the ACL, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the NAACL-HLT 2016, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Belanger, D.; McCallum, A. Structured Prediction Energy Networks. In Proceedings of the ICML 2016, New York City, NY, USA, 19–24 June 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the OSDI 2016, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Value-Ratio | Average Accuracy for Known Values | Average Accuracy for Unknown Values | Average Accuracy for Total Values | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train: Test | BT | CT | eCRF | BT | CT | eCRF | BT | CT | eCRF | |
| sim-R | 75:25 | 0.959 ± 0.020 | 0.993 ± 0.005 | 0.982 ± 0.007 | 0.5550.122 | 0.7530.108 | 0.7910.047 | 0.7650.069 | 0.8620.060 | 0.8750.026 |
| 50:50 | 0.9680.017 | 0.9940.002 | 0.9840.011 | 0.3610.083 | 0.4740.066 | 0.6180.058 | 0.6390.048 | 0.6770.042 | 0.7540.035 | |
| 25:75 | 0.9670.041 | 0.9990.001 | 0.9850.009 | 0.3650.034 | 0.4410.035 | 0.5160.036 | 0.5540.016 | 0.5750.030 | 0.6240.027 | |
| sim-M | 75:25 | 0.9510.034 | 0.9820.005 | 0.9840.003 | 0.8430.009 | 0.8760.066 | 0.9050.011 | 0.9140.018 | 0.9300.037 | 0.9530.005 |
| 50:50 | 0.9410.028 | 0.9820.009 | 0.9750.017 | 0.6550.024 | 0.7230.076 | 0.8410.024 | 0.8030.014 | 0.8400.040 | 0.9100.017 | |
| 25:75 | 0.9480.024 | 0.9910.003 | 0.9880.005 | 0.5190.034 | 0.6110.030 | 0.6820.035 | 0.6620.027 | 0.7180.021 | 0.7840.023 | |
| Train | Test | Average Accuracy for Known Slots | Average Accuracy for Unknown Slots | Average Accuracy for Total Slots | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Domain | Domain | BT | CT | eCRF | BT | CT | eCRF | BT | CT | eCRF |
| sim-M | sim-R | 0.9800.025 | 0.9740.009 | 0.9880.004 | 0.1360.045 | 0.1210.077 | 0.2430.009 | 0.5020.036 | 0.4910.044 | 0.5660.007 |
| sim-R | sim-M | 0.8140.064 | 0.9150.013 | 0.9260.024 | 0.1650.040 | 0.2460.017 | 0.3770.031 | 0.5080.035 | 0.5990.006 | 0.6670.020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, Y.; Zhang, Y.; Liu, H.; Ou, Z.; Huang, Y.; Feng, J. Elastic CRFs for Open-Ontology Slot Filling. Appl. Sci. 2021, 11, 10675. https://doi.org/10.3390/app112210675
Dai Y, Zhang Y, Liu H, Ou Z, Huang Y, Feng J. Elastic CRFs for Open-Ontology Slot Filling. Applied Sciences. 2021; 11(22):10675. https://doi.org/10.3390/app112210675
Chicago/Turabian StyleDai, Yinpei, Yichi Zhang, Hong Liu, Zhijian Ou, Yi Huang, and Junlan Feng. 2021. "Elastic CRFs for Open-Ontology Slot Filling" Applied Sciences 11, no. 22: 10675. https://doi.org/10.3390/app112210675
APA StyleDai, Y., Zhang, Y., Liu, H., Ou, Z., Huang, Y., & Feng, J. (2021). Elastic CRFs for Open-Ontology Slot Filling. Applied Sciences, 11(22), 10675. https://doi.org/10.3390/app112210675