1. Introduction
Pruning is one of the most important horticultural intervention techniques with which the vegetative and reproductive growth of fruit trees can be balanced. This balance is important for producing a stable and high quality product in consecutive yield seasons [
1,
2]. Proper tree pruning also helps to prevent tree degradation, and reduces the chance of disease by providing sufficient light and air flow through the tree canopy [
3]. The knowledge of tree pruning is, thus, an essential skill for both professional and amateur fruit growers. In recent years, a number of software tools have emerged for computer-aided horticultural education [
4,
5,
6,
7]. They complement the field training by allowing the user to perform various actions on simulated tree models within a 3D virtual environment. The effects of such interactive tree manipulation on its growth are simulated to provide an informative feedback to the user. The use of software tools can be extended beyond education, since they allow analysis and comparison of various tree training techniques.
Another functionality enabled by software is algorithmic determination and evaluation of pruning performed on virtual trees with respect to specific goals. Existing research in this direction includes goal-oriented assessment of pruning effects [
8], selection of pruning points in 3D tree reconstructions from images or point clouds as part of automated pruning [
9,
10,
11], and algorithmic pruning optimization for support in computer-aided education [
12]. In a previous study, the immediate and delayed effects of selective pruning on fruit tree development were assessed using the estimated amount of light received by the flower buds in the current and the next season [
13]. In this case, the light intake was a proxy measure for the achieved ratio of vegetative and reproductive growth resulting from pruning, which was the object of optimization. It was shown that pre-growth and post-growth evaluation of a single metric can result in a complex bi-objective optimization problem with conflicting goals.
The limitation of existing approaches to tree pruning optimization is that they are focused on a single pruning objective, which is the improvement of lighting conditions in the crown. Only Westling et al. [
11] used the crown volume as an additional component in the calculation of the pruned tree’s final score. The problem of light intake maximization was approached from the perspective of both single-objective [
12] and multi-objective optimization [
13]. However, in the latter case, the objectives were homogeneous and their values were computed by the same function in different value spaces (after pruning and after regrowth). In practice, however, the objectives of pruning can reflect various additional goals, such as maintaining a desirable tree shape, volume, or balance [
14]. In this paper, we propose and evaluate the multi-objective pruning optimization with such heterogeneous criteria, which are evaluated on the same pruned model. This extends to the existing methodology by including diverse goals considered in manual pruning, and provides new educational and analytical functionality for the optimization framework, which is implemented within the EduAPPLE virtual tree simulation tool [
15].
Multi-objective optimization (MO) problems arise in many real-life and scientific tasks. Research of MO methods has produced a large number of efficient algorithms, which were used to solve practical problems ranging from groundwater remediation [
16] to workload balancing [
17]. Multi-objective problems can be approached using scalarization, Pareto-based algorithms, or hybrid approaches [
18]. Scalarization to single-objective problems can employ mature and competitive optimization methods for specialized tasks [
19]. However, state-of-the art results in multi-objective optimization problems were achieved by Pareto-based algorithms, which construct an approximation of a Pareto-optimal set of solutions [
20]. Improved versions of baseline algorithms address the problems of poor solution diversity and premature convergence using crowding mechanisms [
21,
22], dynamic archives [
23], or local exploration techniques [
24].
In the paper, we analyze and compare the performance of the NSGA-II [
25], the SPEA2 [
26], and the MOEA/D-EAM [
27] methods for pruning optimization in a 3D objective space. The objectives reflect the immediate effects of selective limb removal on light intake, crown symmetry, and the balance of a tree. We additionally propose the use of constraint objectives as a new regulative mechanism for reducing the overfitting of pruning solutions to individual objectives. The main contributions of this paper are:
Integration of multiple heterogeneous objectives into a multi-objective tree pruning optimization framework.
Introduction of secondary objectives, which are not the targets of optimization, but serve as constraints in the objective space of pruning solutions.
Comparison and analysis of Pareto front approximations obtained with three popular advanced MO methods, namely NSGA-II, SPEA2, and MOEA/D-EAM.
2. Materials and Methods
In this section, we briefly review the tree growth simulation model, and describe the way pruning is formulated as an MO problem. We then define the new set of heterogeneous quantitative objectives for the pruning optimization problem, and describe the proposed constrained MO procedure.
2.1. EduAPPLE Tree Growth Simulator
Tree growth simulator EduAPPLE [
7,
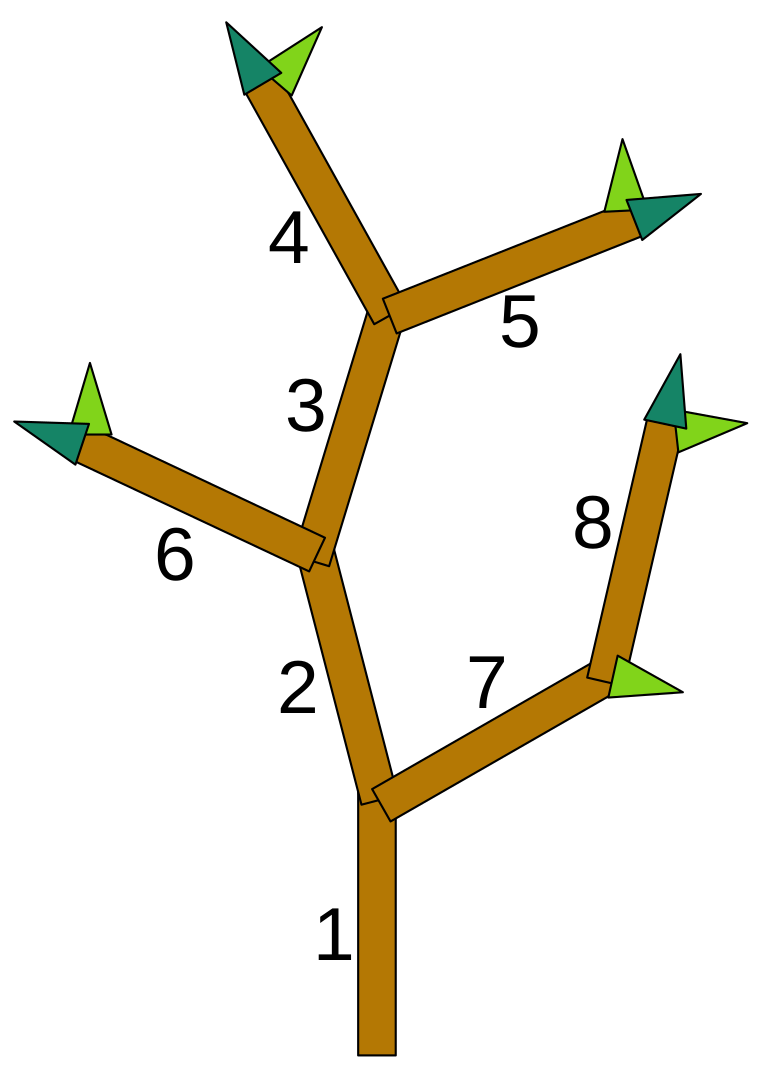
15] was developed as a software tool that allows the user to observe the effects of various tree training techniques, such as pruning, weighing, and spreading, on the formation of an apple tree crown. To this end, EduAPPLE implements a parameterized development model that allows simulation of different growth behaviors of apple trees. EduAPPLE uses a simplified tree structure representation, where the tree skeleton is composed of short linear segments called metamers, which are linked to form branches. Metamers also present the basic unit of increment in growth simulation. Each metamer consists of an internode and two buds, a terminal and a lateral one, which are used to extend or fork new branches upon growth. Internodes have assigned unique identifiers, which are used to indicate the cut locations for pruning.
Figure 1 shows an example of a simple tree structure with depth-order internode labeling.
Simulation of tree growth in EduAPPLE is based on a source-sink model, and performed in discrete seasonal steps. The yearly increments are determined by first calculating the growth resources accumulated by a tree, and then redistributing them to different parts of the tree. The growth is realized by replacing the shooting buds with new metamers. The main sources of growth material are the tree’s own food reserves and photosynthesis. The amount of food reserve is modeled in EduAPPLE as a linear dependency on tree age
A, while the quantity of photosynthetic product is estimated from total bud illuminance
:
Here,
denotes the set of all buds, while
and
are adjustable model parameters. The hyperbolic tangent non-linearity is used to limit the tree growth with age. Bud illuminance is computed by estimating the amount of shadow the bud receives from other tree elements. The details of this calculation can be found in the original EduAPPLE paper [
15].
Following the allocation theory [
28], the accumulated resources
R are split into two exclusive portions, which are dedicated separately to vegetative and reproductive growth. The estimated reproductive requirements of a tree are calculated using the number
of flower buds as [
13]:
Here, and are the allocation model parameters that can be adjusted to obtain specific behavior. The rest of the resources are allocated to vegetative growth. The reproductive pressure on resources can be reduced by pruning, which controls the balance of reproductive and vegetative growth across seasons.
Once determined, the vegetative growth resources are redistributed back to the buds in proportion to their light exposure, orientation, and distance from the roots. The probability of shooting is higher for well lit and vertically oriented buds, but reduced for older buds. Given the final amount of growth resources, bud i can sprout a sequence of new metamers. Upon creation, new buds are differentiated into vegetative and flowering ones, where the probability of a bud becoming a flowering one is another model parameter.
2.2. Pruning as an Optimization Problem
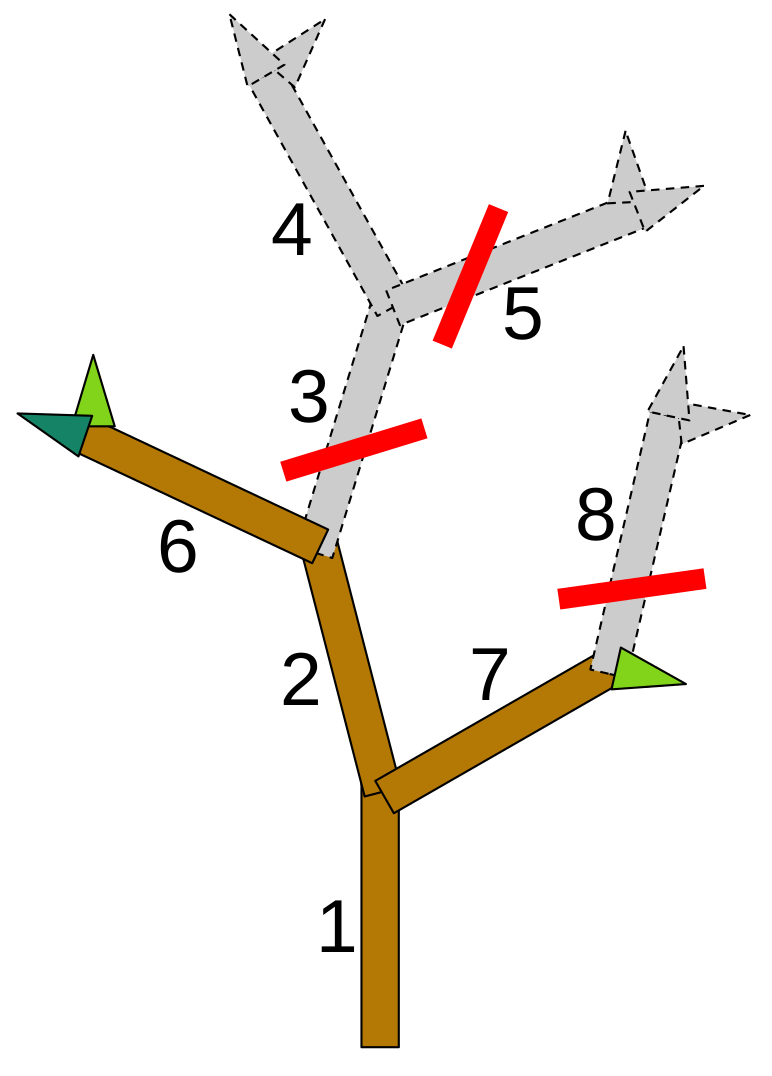
Algorithmic pruning optimization was introduced as an analytic tool by Strnad and Kohek [
12]. In this context, a pruning is represented as a vector
of cut locations, which correspond to individual internode identifiers. An example of this is shown in
Figure 2, which illustrates the realization of a pruning vector for a given tree model.
Figure 2 also shows that a cut can have no effect if another cut is present higher up in the tree hierarchy. This behavior is actually helpful during optimization, where changes to the pruning vector can activate and deactivate individual cuts.
The task of pruning optimization is to find a pruning solution that maximizes the values of selected quantitative objectives. Maximization of one objective, however, may result in a reduction of another objective. For instance, optimizing the crown shape towards some desired form may reduce the total resource accumulation of the tree, which affects the balance of vegetative and reproductive growth. Such conflict of goals is at the heart of multi-objective optimization proposed in this paper.
Let us formalize the pruning optimization problem with respect to a given set of objective functions . The objective value of a pruning solution vector is, in this case, given by . A solution vector is said to be dominated by another solution vector , which is denoted by , if the following conditions hold:
;
.
In other words, pruning dominates pruning if it is not worse in any objective, and is strictly better in at least one. Note that the above formulation of dominance corresponds to the case of objective maximization used in this paper. For the minimization case, one needs to invert the inequalities.
The goal of MO is to construct a set
of non-dominated pruning solutions, known as the Pareto front. Only an approximation of the Pareto front can usually be obtained in practical problems. For this task, one can choose between several MO algorithms [
29]. In this paper, the adaptations of three popular and efficient evolutionary MO methods were employed, known as NSGA-II [
25], SPEA2 [
26], and MOEA/D-EAM [
27]. The latter is an extension of the original MOEA/D [
30] method with a modified selection scheme that uses an external archive. In the terminology of evolutionary algorithms, the pruning solution vectors correspond to the genotypes, and their realizations on a tree model correspond to phenotypes. During the pruning optimization, the search is conducted in the genotype space, while the fitness evaluation is performed in the phenotype space.
2.3. Objectives
In a previous study by Strnad et al. [
13], the bi-objective value of a pruning solution
for a given tree model
was defined using the pre-growth objective value
and the post-growth objective value
:
The quantity is the estimated light intake of a tree after being pruned according to . The pre-growth objective reflects the short-term (i.e., immediate) effects of pruning, which can be assessed directly on the pruned tree model. On the other hand, the post-growth objective serves as a proxy measure for long-term (i.e., delayed) pruning effects. These are estimated by averaging the light intake over the results of multiple stochastic growth simulations of the pruned tree.
Improving the light conditions within the crown is one of the principal goals of tree pruning. However, there are other important aspects that practitioners need to consider, especially when performing the pruning as a corrective measure in neglected or damaged trees. For example, the amount of removed biomass may need to be constrained in order to prevent inflicting too much stress on the tree, or the disrupted tree balance needs to be restored by improving biomass distribution. Such heterogeneous criteria can constitute conflicting objectives for the pruning optimization task. In this paper, we analyze the results of such multi-objective optimization by introducing the following pruning objectives:
The average light exposure of flower buds after pruning, denoted by
, and calculated as:
Here,
denotes the set of the pruned tree’s flower buds. Note that this objective promotes aggressive pruning, since the maximum value can be achieved by a few fully exposed buds.
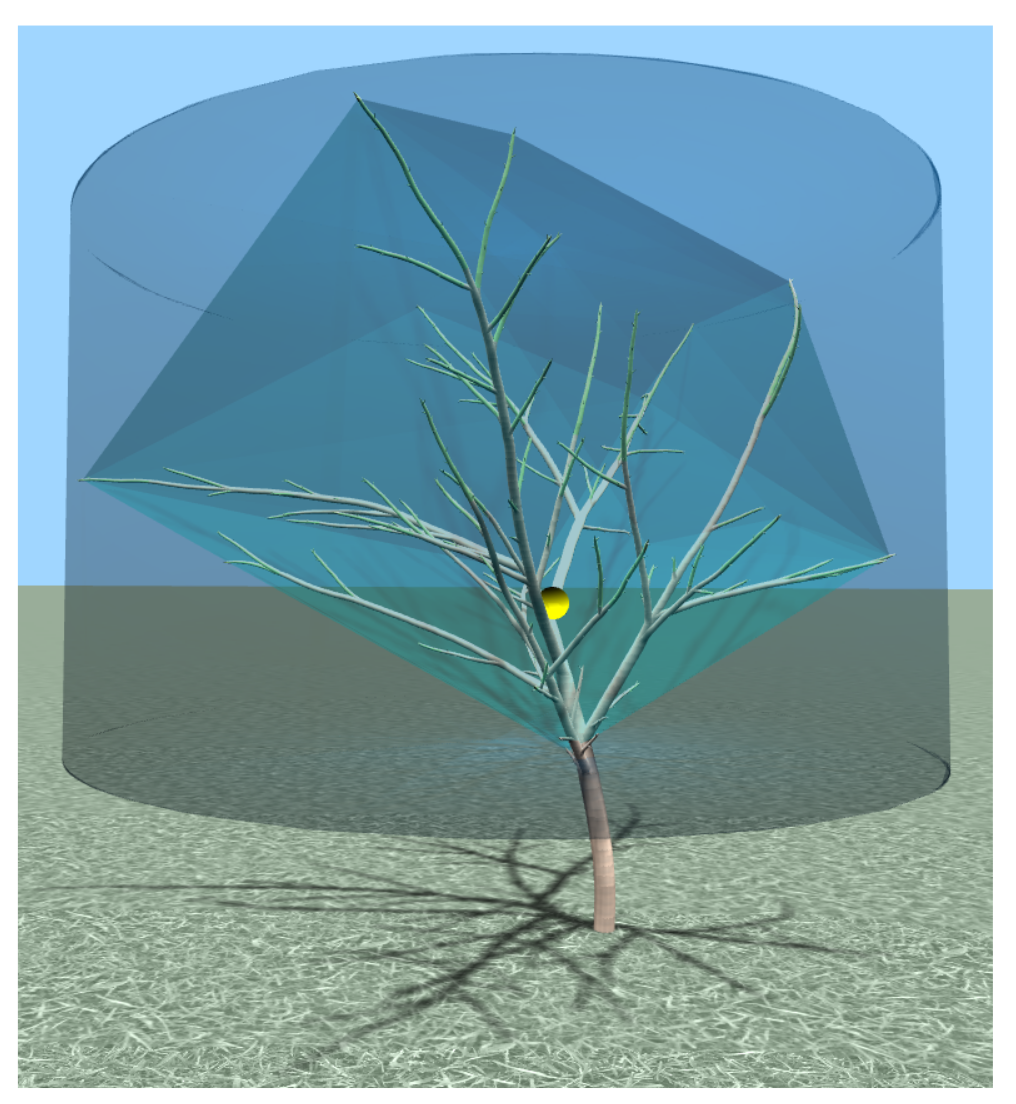
Conformance of crown shape to the desired training form, which is denoted by
. Its value is estimated using the inverse Hausdorff distance between the convex hull of the pruned tree and the hull’s bounding volume of target symmetric shape:
The convex hull
of the pruned tree is constructed using its branch tips. Once the hull is obtained, its bounding volume
with target shape is determined (
Figure 3). In our experiments, a cylindrical target shape was pursued, but other common training forms can be used (e.g., conical). The Hausdorff distance between two shapes is defined as:
where
d denotes the standard Euclidean distance between two points.
Tree balance, denoted by
, and represented by the inverse horizontal distance
between the above ground biomass center of gravity
and the vertical axis going through the stem origin:
The center of gravity location
for a tree
with internodes
is computed as:
Here,
is the midpoint of internode
i, and
is its mass. The computation of the latter is simplified by assuming homogeneous wood density, so the mass of internode
i with radius
and length
is proportional to its cylindrical volume:
The proportion of remaining tree biomass, denoted by
and calculated as:
Here,
is the above ground biomass of tree
:
2.4. Optimization Method
In this paper, pruning optimization is treated as a discrete combinatorial optimization problem, where the task is to find the set
of non-dominated pruning solution vectors with respect to a set of objectives
. Objective
, defined in
Section 2.3, is itself not an interesting target of optimization, since it can be maximized trivially by no pruning at all. Therefore, we propose a special role for objective
in order to constrain the search to certain regions of the solution space. For instance, we may prescribe that no more than
of the tree’s biomass should be removed, which could be imposed by the constraint
. This is especially important in order to regulate aggressive pruning stimulated by objective
. Adherence to constraint objective bounds is implemented in a soft manner by marking the violating solutions as dominated. Such approach does not completely reject borderline solutions, making it possible to use them for the derivation of better successors. We use only
as a constraint objective in this study, but other metrics could be used. The distinctive property of a constraint objective is that it evaluates the pruning solution globally, and not with respect to individual cuts. In general, both the lower and the upper bounds for a constraint objective can be specified by the user.
The use of constraint objectives to specify feasible regions in an auxiliary objective space is a new addition to the multi-objective pruning optimization framework, which complements heuristic constraints implemented in a decision space. The latter have been introduced by Strnad et al. [
13] in order to reduce the size of the solution space and make the search more efficient. This is achieved by two mechanisms:
By limiting the cut locations to those with certain local properties. In our tests, the following restrictions were enforced:
- -
Cutting was limited to the wood at most years old, in order to prevent pruning of scaffold limbs.
- -
Pruning was restricted to locations following a branch fork that result in removal of at least metamers.
By constraining the dimension of the solution vectors (i.e., the number of cuts) to a range .
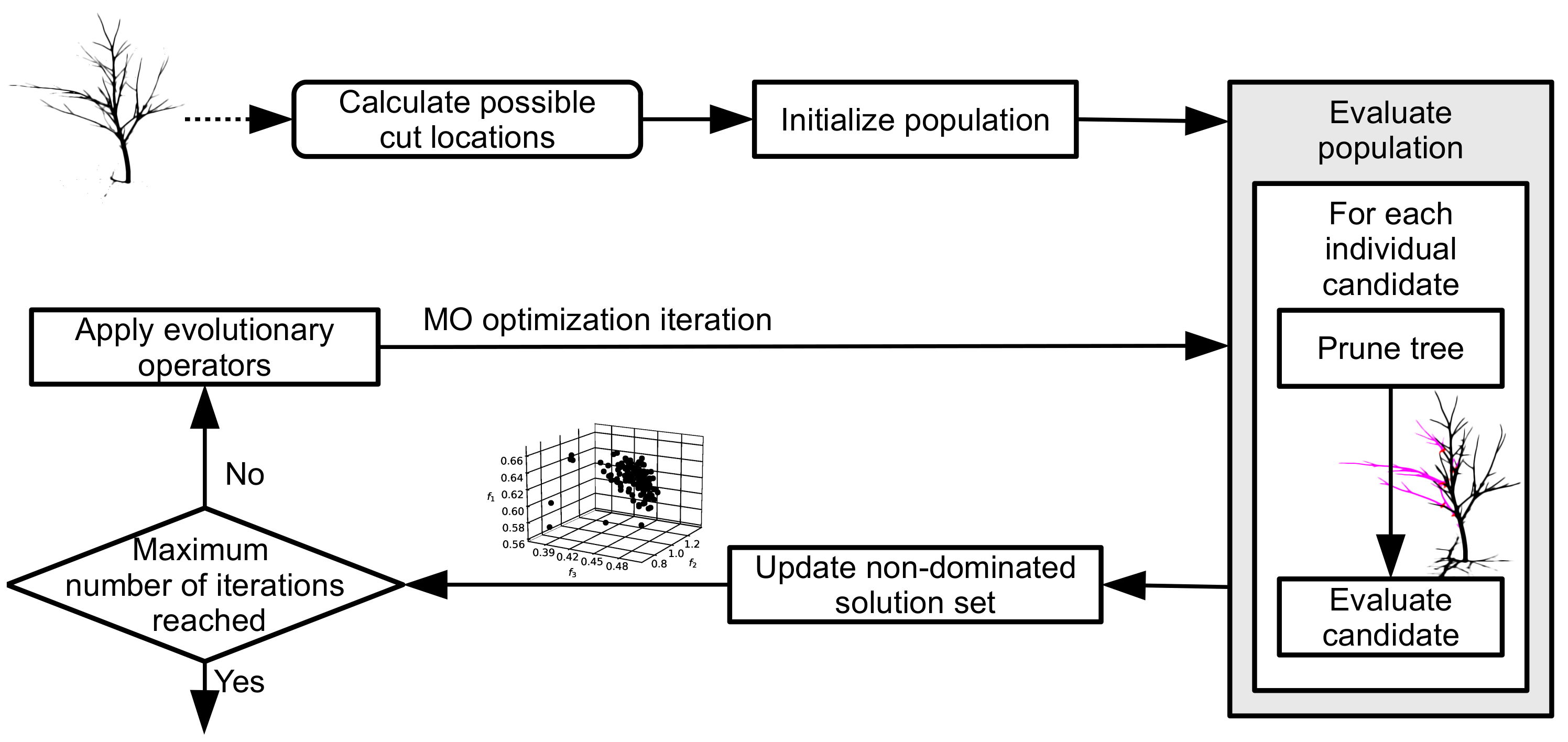
The high-level concept of the proposed multi-objective pruning optimization is outlined in
Figure 4 and Algorithm 1. It is an adaptation of a general evolutionary process for the construction of Pareto front approximation. Given a tree model
as input, a list
of potential cut locations is first built according to the heuristic constraints described above. From this list, the initial population
of
solution vectors is generated. Each solution vector is obtained by sampling
d-times randomly and without replacement from
, where
. The population size
is a method meta-parameter.
| Algorithm 1. Multi-objective pruning optimization. |
Input: Tree model ; heuristic constraints , , and ; number of objective evaluations M; objective functions ; meta-parameters
Output: non-dominated set of solutions - 1:
procedureMO() - 2:
list of possible cut locations in according to , , and - 3:
initial population of random vectors sampled from - 4:
- 5:
for do - 6:
for do - 7:
prune according to - 8:
evaluate on - 9:
non-dominated vectors in - 10:
remove vectors from that violate bounds of constraint objective - 11:
update using - 12:
apply evolutionary operators on using and - 13:
return
|
The procedure then enters the optimization loop. The number of iterations N is either specified directly, or calculated from the maximum number of objective evaluations M as . Within the loop, three main steps are performed:
The current population is evaluated according to objectives .
The set of non-dominated solutions is updated, using the constraint objective to demote unsuitable solutions.
The next generation of solutions is produced by applying evolutionary operators to the current population.
Evaluation of individual candidate solution is performed by pruning the tree model according to , and computing the values of objectives on the resulting pruned tree. This part of the computation is performed by the simulation model, and is independent of the used optimization algorithm.
The set of non-dominated pruning solutions is updated next, which is a step that depends on the evolutionary method used. In NSGA-II, is updated with non-dominated solutions from the current population . In SPEA2 and MOEA/D-EAM, the current archive is used to update in each iteration. In both cases, solutions with objective value below the prescribed limit are not included in even if non-dominated.
The last step is the derivation of a new population from the current population using a method-dependent procedure. In all of our experiments, the following problem-specific implementations of evolutionary operators are used:
Selection of two parent vectors from the population (NSGA-II) or the mating pool (SPEA2 and MOEA/D-EAM).
Uniform crossover of parent vectors with probability .
Mutation of child vectors with change probabilities and mutation rate .
The selection step is method-dependent. In NSGA-II [
25] and SPEA2 [
26], binary tournaments are used to select the parents from the population and the mating pool, respectively. The mating pool is also used by MOEA/D-EAM [
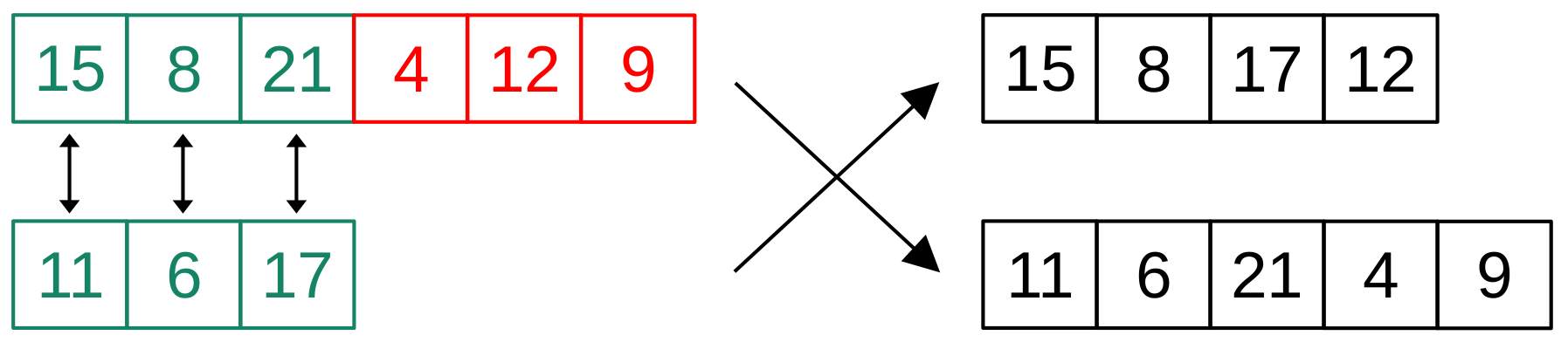
27], but its selection scheme combines random selection with a neighborhood-based one. During crossover, special consideration is necessary when recombining parent vectors of different sizes. In such cases, the surplus genes of the longer parent vector are distributed uniformly between the two child vectors (
Figure 5). Mutation of a child vector is performed in two steps. First, a randomly selected cut is relocated to a different valid position from
with probability
, removed from pruning with probability
, or added to pruning with probability
. Cut addition and removal are possible only if the size of the resulting pruning vector remains within the range
. In the second phase, all of the other cuts are replaced by randomly selected alternatives with small probability
. The complete implementation of crossover and mutation is shown in Algorithm 2.
The exploration/exploitation behavior of the search is regulated through meta-parameters
, and
. Sufficient exploration can usually be achieved even with small values of crossover and mutation rates, because local changes of a genotype (i.e., pruning vector) can result in significantly different phenotypes (i.e., pruned tree models).
| Algorithm 2. Implementation of crossover and mutation. |
Input: parent vectors and , crossover rate , mutation rate , change probability distribution , vector length constraints and
Output: offspring vector - 1:
procedureGenerate_child() - 2:
if rand() < then - 3:
, - 4:
for do - 5:
- 6:
for do - 7:
if rand() < 0.5 then - 8:
- 9:
else - 10:
- 11:
- 12:
if then - 13:
- 14:
else if then - 15:
- 16:
re-normalize , - 17:
if then - 18:
remove from - 19:
else if then - 20:
- 21:
else - 22:
- 23:
- 24:
for do - 25:
if rand() < then - 26:
- 27:
return
|
3. Results
The goals of the experiments presented in this section are to:
Determine the properties of Pareto front approximations obtained from pruning optimization with multiple heterogeneous objectives. In particular, we are interested in the relation of generated pruning solutions to three reference proposals, corresponding to non-pruning, non-selective pruning to cylindrical shape, and distance-based pruning, where the secondary branches are removed if their distance to the primary ones is below the threshold.
Investigate the pruning patterns produced by MO, and how they reflect the trade-offs between conflicting pruning goals.
Evaluate the effect of the proposed constraint objectives on the resulting Pareto front approximations and solution characteristics.
Compare the performance of NSGA-II, SPEA2, and MOEA/D-EAM on this problem, which is important from the perspective of future framework development.
In the continuation, we first describe the configuration and workflow of experiments, and then address the above research questions in order.
The hardware used for the experiments was a desktop computer with Intel i7 CPU, NVIDIA GeForce GTX 1060 GPU, and 16 GB of RAM. The software environment included the Linux operating system (kernel version ) and the GCC compiler version 11.1.
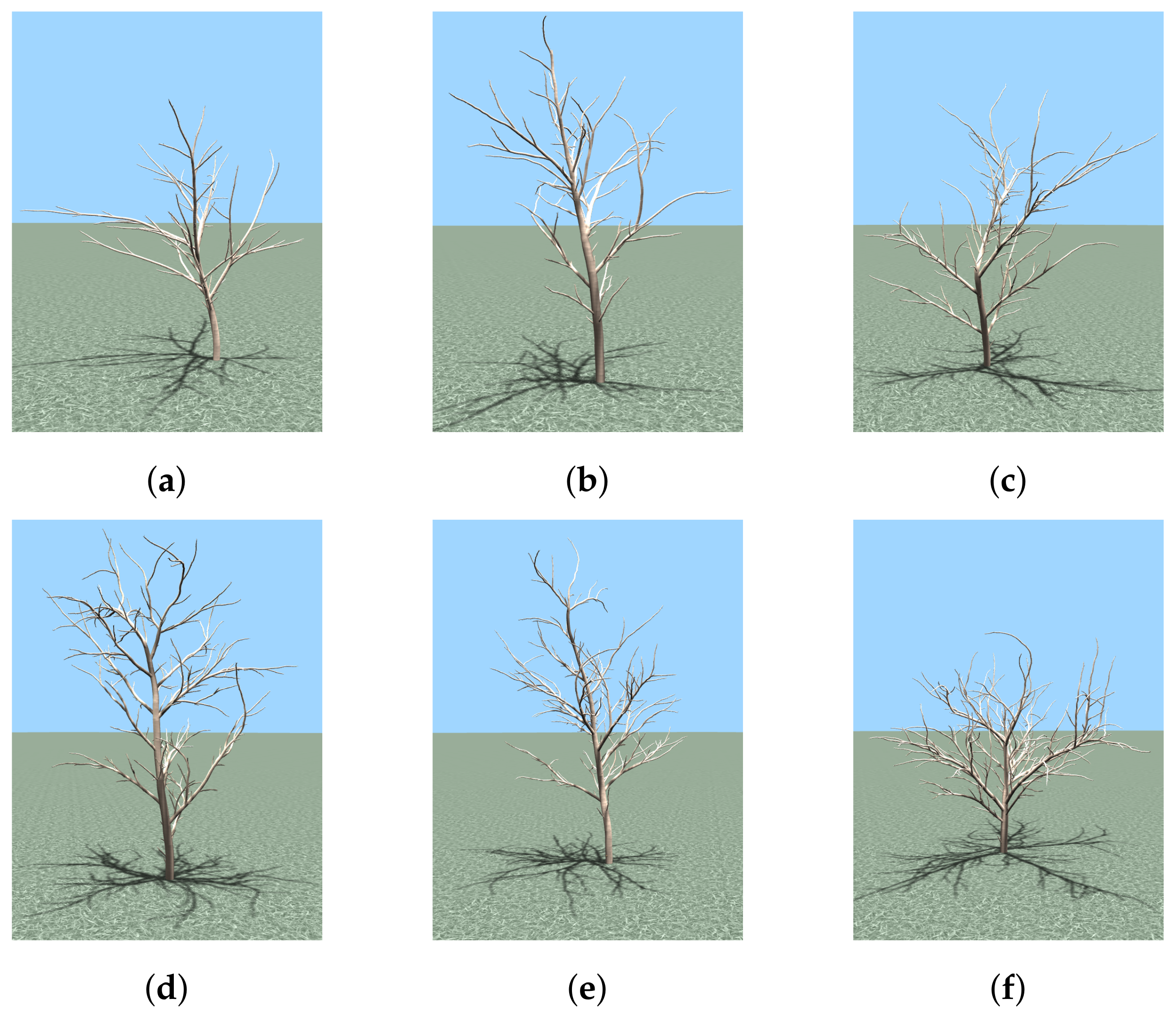
The tree models for experiments were generated by using the simulator with growth parameters
, and
. The models are shown in
Figure 6, and present different levels of complexity for pruning optimization. Their main structural properties and the corresponding combinatorial search space sizes are reported in
Table 1.
Tuning of methods’ meta-parameters was performed with a grid search using the pools
,
, and
. The best out of 5 optimization runs with 5000 objective evaluations was selected for each configuration. The configurations were ordered using the hypervolume indicator
[
31]. For NSGA-II and SPEA2, the configuration
was the configuration with the highest
value. Its performance was also stable across a selection of tree models, and was therefore used in the final experiments. For MOEA/D-EAM, a smaller
and
in combination with
proved to be optimal. The MOEA/D-EAM uses additional neighborhood size
parameter, which was set to the recommended value
. A wider neighborhood setting
was also experimented with, but performed worse than the default.
In order to analyze the effects of individual meta-parameters in more detail, we used the ratio of non-dominated individuals (RNI) [
32], which is computed between solution sets of the selected reference configuration and the modified configurations. The best solutions, in terms of RNI, were selected out of 5 optimization runs and used for configuration comparison. The effects of individual meta-parameters are reported in
Table 2.
It can be observed that, for NSGA-II and MOEA/D-EAM, the selection of is less sensitive than for SPEA2. For NSGA-II, larger population sizes can be used than for the other two methods, while SPEA2 performs comparatively for population sizes 30 and 50. Because the canonical NSGA-II does not use an external archive, the initial diversity with a small population can be exhausted before a large enough pool of feasible non-dominated solutions can be constructed. MOEA/D-EAM prefers smaller mutation rates than NSGA-II and SPEA2 because the changes are propagated faster across the population via the neighborhood mechanism.
The probability mass function for different mutation types was taken from the study by Strnad et al. [
13], where
performed well. Using equal probabilities for extending and shortening the solution vectors also encourages searching with mean pruning size. An empirical lower bound value
was used for the constraint objective
, i.e., no more than
of the tree’s biomass should be removed by pruning, which is a pragmatical limit. In order to reduce the search space and prevent negligible cuts, the same values for heuristic constraints
and
as in [
13] were used. The number of cuts in a pruning solution was also constrained empirically to the range
.
The number of objective evaluations in the final experiments was set to . The NSGA-II, SPEA2, and MOEA/D-EAM optimization methods were executed times for each tree model. Within each method, the obtained q non-dominated sets were compared in order to determine the number of overall non-dominated solutions in them. The fronts were then sorted by the decreasing number of non-dominated solutions. The best, median, and worst run of both optimization methods were finally used in the analysis of results and method comparison.
Figure 7 shows 3D approximations of Pareto fronts, obtained by the best runs of NSGA-II and SPEA2 for the tree models from
Figure 6.
Figure 8 shows the same comparison for MOEA/D-EAM and SPEA2.
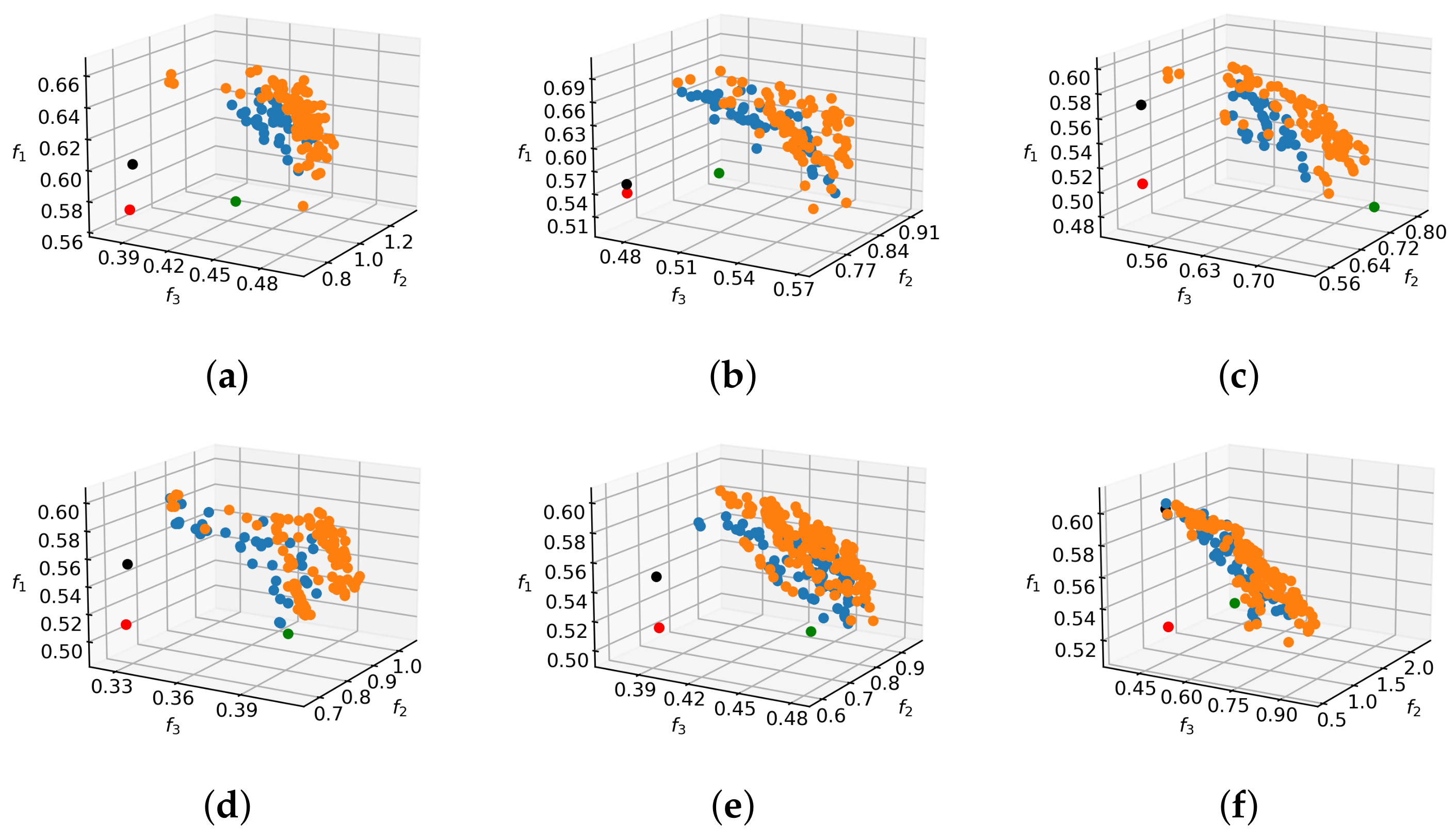
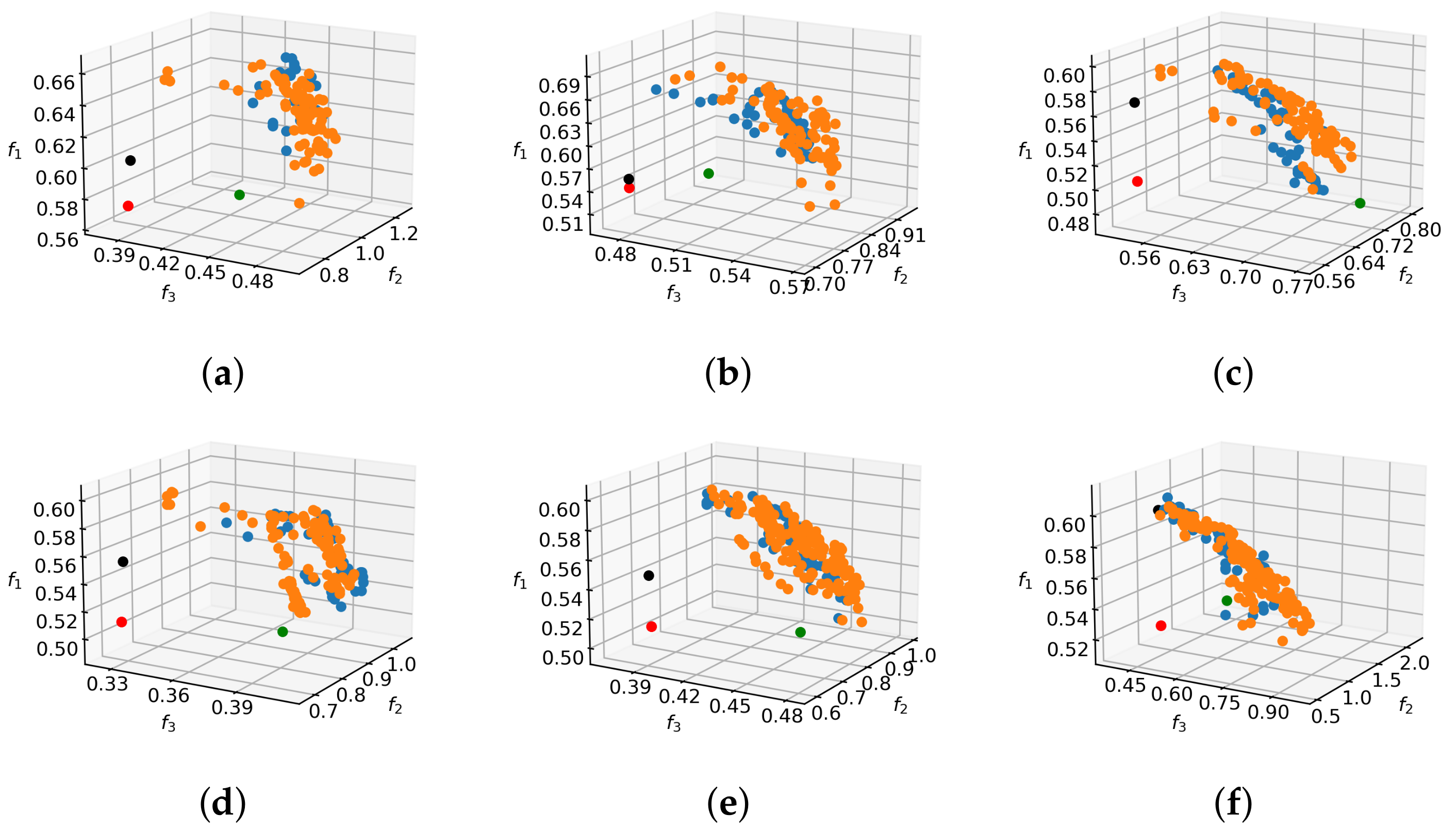
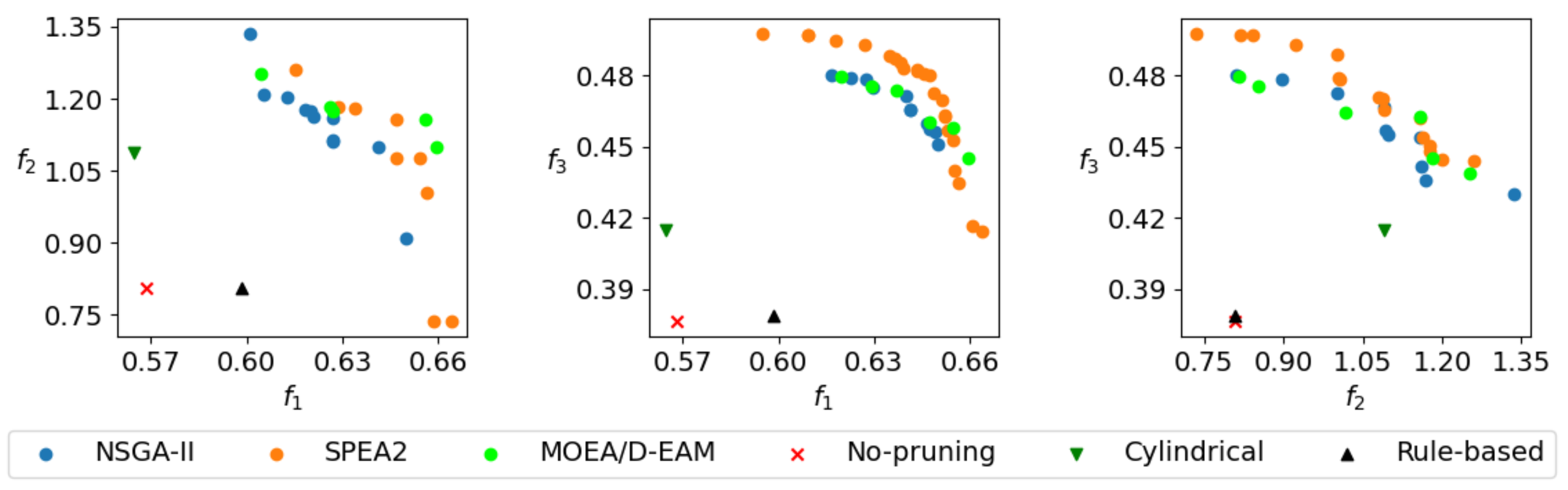
In order to convey a better sense of shape and relation to reference solutions, the 2D projections of the Pareto front approximation for the tree in
Figure 6a are shown in
Figure 9. The situation is similar for other tree models. It can be observed that all of the reference solutions are dominated by the majority of non-dominated individuals found by MO methods, because their positions in objective space projections are within the dominated regions behind the non-dominated fronts. As expected, the non-selective pruning to cylindrical form improves the value of objectives
and
with respect to no pruning, while the rule-based pruning increases the value of objective
. However, the results of pruning optimization demonstrate that simultaneous improvement on all objectives is possible. In relative terms, the hardest improvements to make are with respect to objective
. This can be explained by analyzing the behavior of that objective, which computes the average light exposure of flower buds. By pruning away branches, the number of buds that contribute to the objective value is reduced, but at the same time the light conditions for the remaining ones are improved and the denominator in Equation (
4) is lowered. This gain vs. loss ratio of light intake can be highly discontinuous even for small changes in the solution vector, which results in multiple local optima that make optimization difficult.
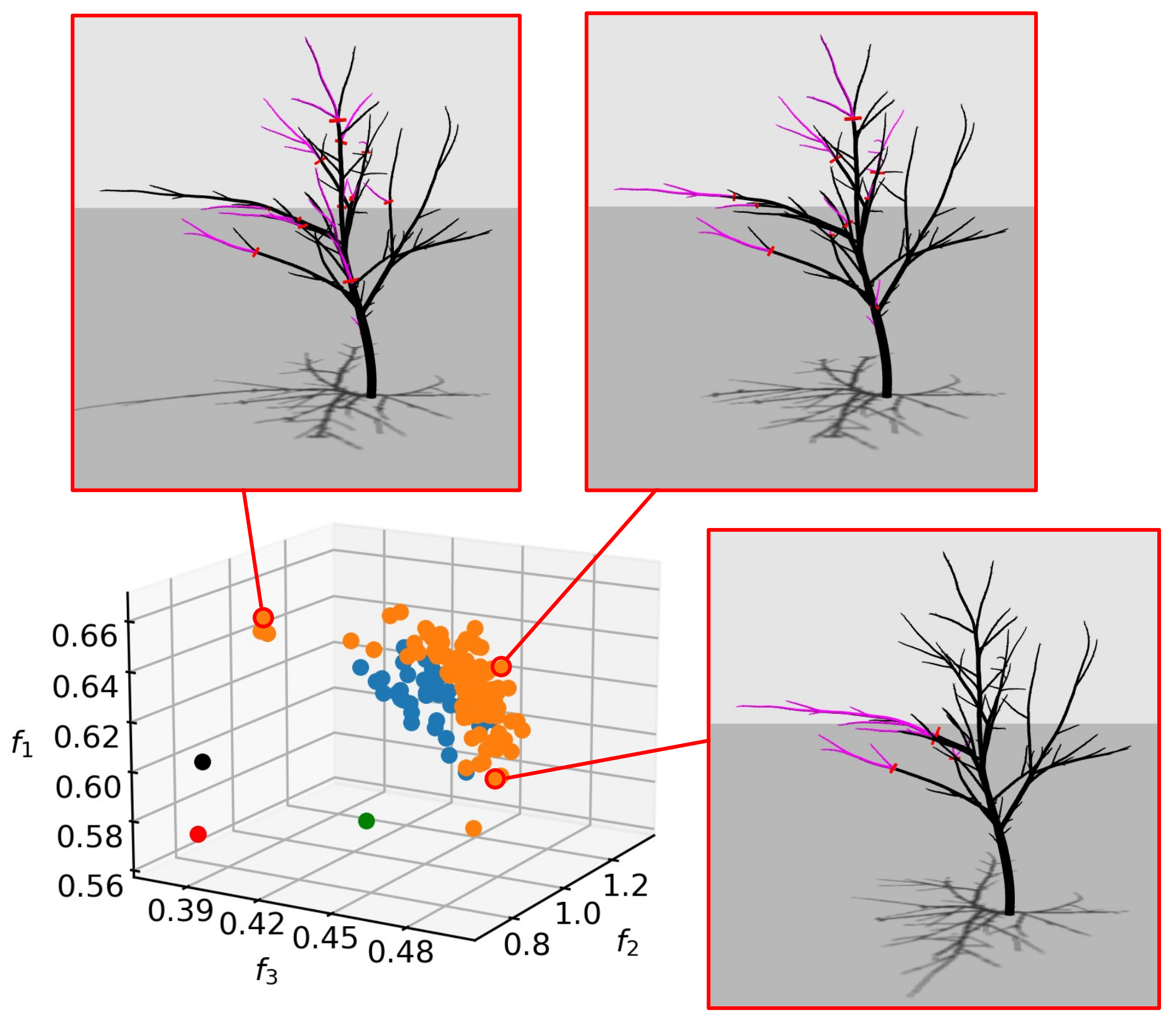
Figure 10 shows realizations of pruning vectors from different regions of the non-dominated set on the target tree model. It is informative to compare the pruning solutions that focus on maximization of individual objectives. For example, the pruning that maximizes the light objective tends to remove branches that cast or receive a lot of shadow, whereas the balance-oriented pruning promotes one-sided removal of wood in order to restore tree equilibrium. The pruning solution focusing on shape objective
advocates branch removal from multiple sides, but contains elements of the other two prunings in order to improve on objectives
and
as well.
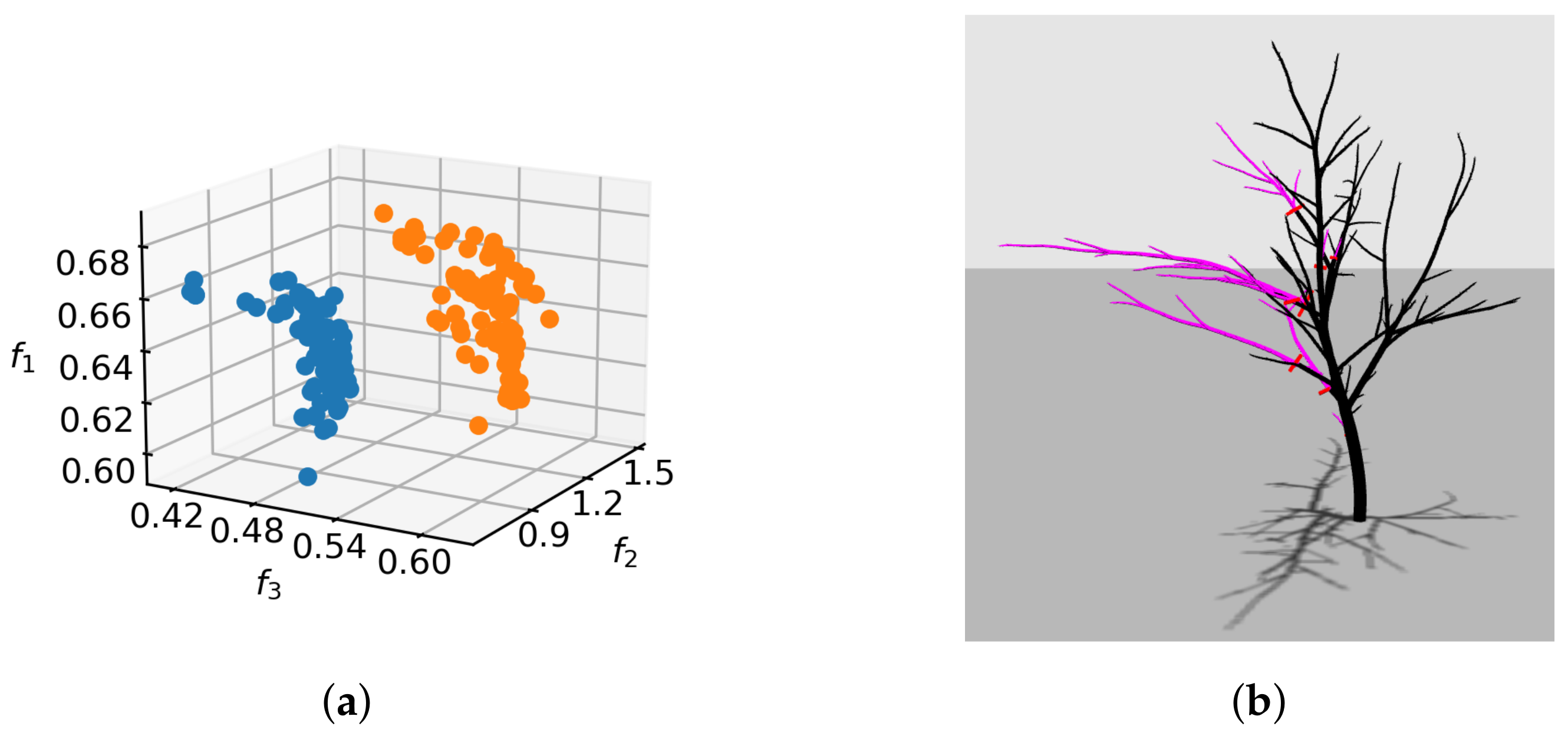
The next question addressed with the experiments was the evaluation of constraint objective
importance for regulating the optimization. To this end, we executed the SPEA2 optimization using a relaxed lower bound
for
. The comparison of non-dominated sets for the best SPEA2 run with tight and relaxed bound is shown in
Figure 11a. It is evident that further numerical improvement of objective values can be achieved by relaxing the constraint. However, the solutions tend to start overfitting on one or more pruning objectives through extensive biomass removal (
Figure 11b). A proper empirical selection of bounds is, thus, necessary to confine the solutions to viable regions.
Figure 11a shows that the effect of the constraint objective is in bounding the feasible region of the objective space. By relaxing the constraint, we allow a wider spread of individual objective values, which increases the possible distance of non-dominated fronts from the origin. Such indirect specification of feasible regions is in contrast to defining constraints in terms of optimization objectives themselves, which is more common in MO [
33].
The final goal of experiments is comparison of method performance.
Figure 7 suggests that SPEA2 outperformed NSGA-II consistently in our tests, and also performed better than MOEA/D-EAM in general. These conclusions are supported by
Table 3 and
Table 4, where the RNI values and the
values are reported based on the comparison of best, median, and worst runs of each method. The performance comparison of NSGA-II and MOEA/D-EAM shows that MOEA/D-EAM is always better in terms of RNI, but in some cases, NSGA-II can achieve better results with respect to the hypervolume indicator due to a better spread of solutions in the objective space. The reason for weak performance of MOEA/D-EAM in some cases is in the inherited MOEA/D replacement strategy. It was shown that the employed neighborhood replacement scheme in MOEA/D can result in poor population diversity and premature convergence [
34]. While MOEA/D-EAM addresses the reproduction step of MEOA/D, it uses the same replacement strategy, so the problem can persist.
The common feature of SPEA2 and MOEA/D-EAM, which gives them important advantage over NSGA-II, is their use of an external archive. This finding is consistent with recent studies, in which the NSGA-II equipped with external archive was used to improve optimization results of the canonical version [
35,
36]. In both SPEA2 and MOEA/D-EAM, the archive is used to construct the mating pool for recombination. In the case of SPEA2, the archive is also used to update the current set of non-dominated solutions, while in MOEA/D-EAM the non-dominated set is the external archive itself. Separating the two in SPEA2 may be one reason for the slight performance difference between SPEA2 and MOEA/D-EAM. Another one is that similarity-based selection in MOEA/D-EAM results in a more locally directed search, which requires more time to escape out of large basins of similar pruning solutions. It can be concluded that the exploration mechanism of SPEA2 is better suited to the discrete optimization task at hand, and allows building better Pareto front approximations within the constrained number of fitness evaluations.
The advantage of NSGA-II over the other two methods is faster execution, but the differences are small because the cost of objective evaluations dominates the run-time. The average optimization run-times are reported in
Table 5. The run-time variances between optimization executions of the same method on a single tree model are negligible. The slight differences between methods are in line with the expected time complexities of the methods, which are discussed in more detail in
Section 4. Comparison of
Table 1 and
Table 5 reveals that the run-time grows linearly with tree model complexity, which is expected because the objective functions in Equations (4)–(7) are linear in the number of internodes.
4. Discussion
The experiments demonstrate that diverse sets of non-dominated solutions can be obtained by using heterogeneous pruning objectives, which is valuable for both educational and analytical purposes. However, algorithmic pruning optimization has wider potential applicability to complement rule-based solutions in the developing field of automated pruning [
37]. The progress of scanning technology and computer vision allows producing increasingly faithful digital reconstructions of real trees [
38,
39,
40]. A wider availability of relatively low-cost devices equipped with LiDAR scanners should enable further advance of the field, as already demonstrated by some recent research [
11,
41]. In such scenarios, the multi-objective assessment of pruning effects may need to rely on estimation of tree parameters that are not fully observable, or cannot be captured to a sufficient level of accuracy.
The main limitation of the proposed methodology is the assumption of exact knowledge of tree properties, which are provided by the simulation environment. In order to account for the possibility of missing information, fuzzy objective measures should be incorporated into the optimization process. This would also improve the alignment of the methodology with the human perception of achieved pruning goals.
Another practical drawback of current implementation is its run-time, which needs to be improved for the use of methodology in interactive sessions. The differences between the optimization methods in this respect are small, because the run-time is governed by objective evaluations. The definitions of objectives in
Section 2.3 indicate that their evaluation should increase approximately linearly with problem size, i.e., the number of tree internodes. The objective
in Equation (4) sums over the flower buds, whose number is linear in the number of internodes. The most time consuming part of the objective
computation is the generation of a convex hull. This can be done in
, where
n is the number of branch tips and
h is the number of points in the hull. While
n increases approximately linearly with the tree size,
h was determined to be within a small constant factor for all trees. Objectives
and
are directly related to the number of internodes, so their computation is also linear. The linear relationship of run-time and problem size has been experimentally confirmed, as presented in
Table 5. The small run-time differences between methods arise from their average time complexities, which are
for NSGA-II,
for SPEA2 and
for MOEA/D-EAM, where
N is the population size and
M is the archive size. Further optimization and parallelization of objective value computation is one of priorities for future framework development.
The presented use of additional objective constraints to prevent overfitting of pruning on actual target objectives is a generally applicable concept. It can be used in other MO problems where the bounds are hard to specify on optimization objectives directly. In the proposed approach to pruning optimization, the objective constraints complement heuristic decision constraints in the search space. However, the violations of the latter can be easily detected and corrected within the optimization loop. In this way the waste of computational resources on evaluation of infeasible solutions can be avoided. Violations of objective constraints, on the other hand, can only be established after their evaluation, and it is usually not clear how to resolve them. A strategy for handling the infeasible solutions in the population is therefore required. In the currently implemented strategy, all solutions that violate the constraint objective become equally dominated due to the assignment of low score. However, a finer distinction between nearly feasible solutions and truly bad ones with adaptively increasing constraint violation penalty could improve the exploration efficiency of the method.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}