
Weakly Supervised Learning for Object Localization Based on an Attention Mechanism


Abstract
:1. Introduction
- There is no pre-processing task, such as hiding part of an image, required before training the model. Therefore, it does not take extra time to train the model.
- The number of learning parameters is minimized without an additional layer to solve the sub-optimal problem of WSOL, but the proposed method shows better performance than the existing methods.
- Some of the existing studies had to inject the same input several times to obtain the attention result for one image at the inference stage, but our method can obtain the attention with only one input.
2. Related Work
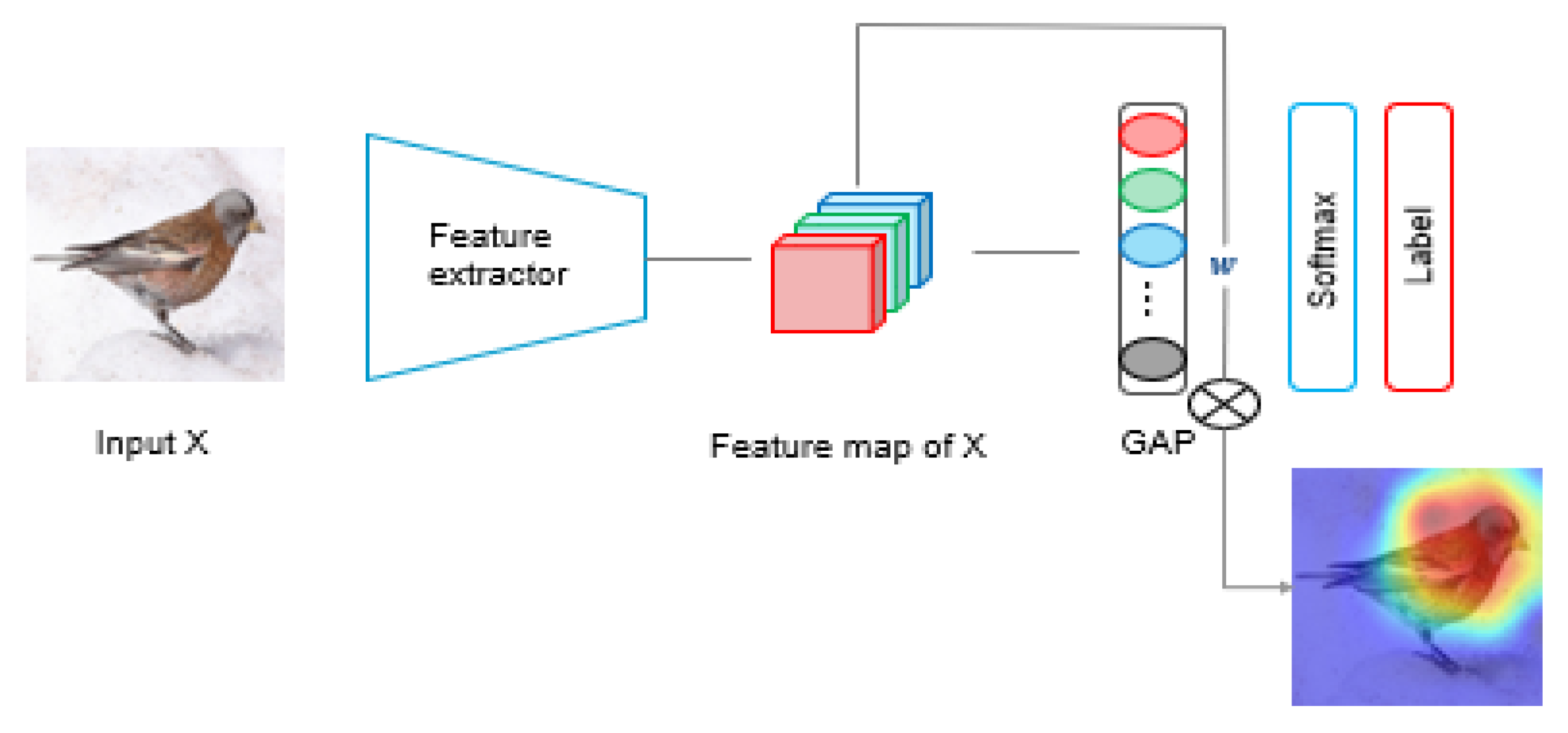
2.1. Class Activation Map
2.2. Attention Mechanism
2.3. Weakly Supervised Object Localization
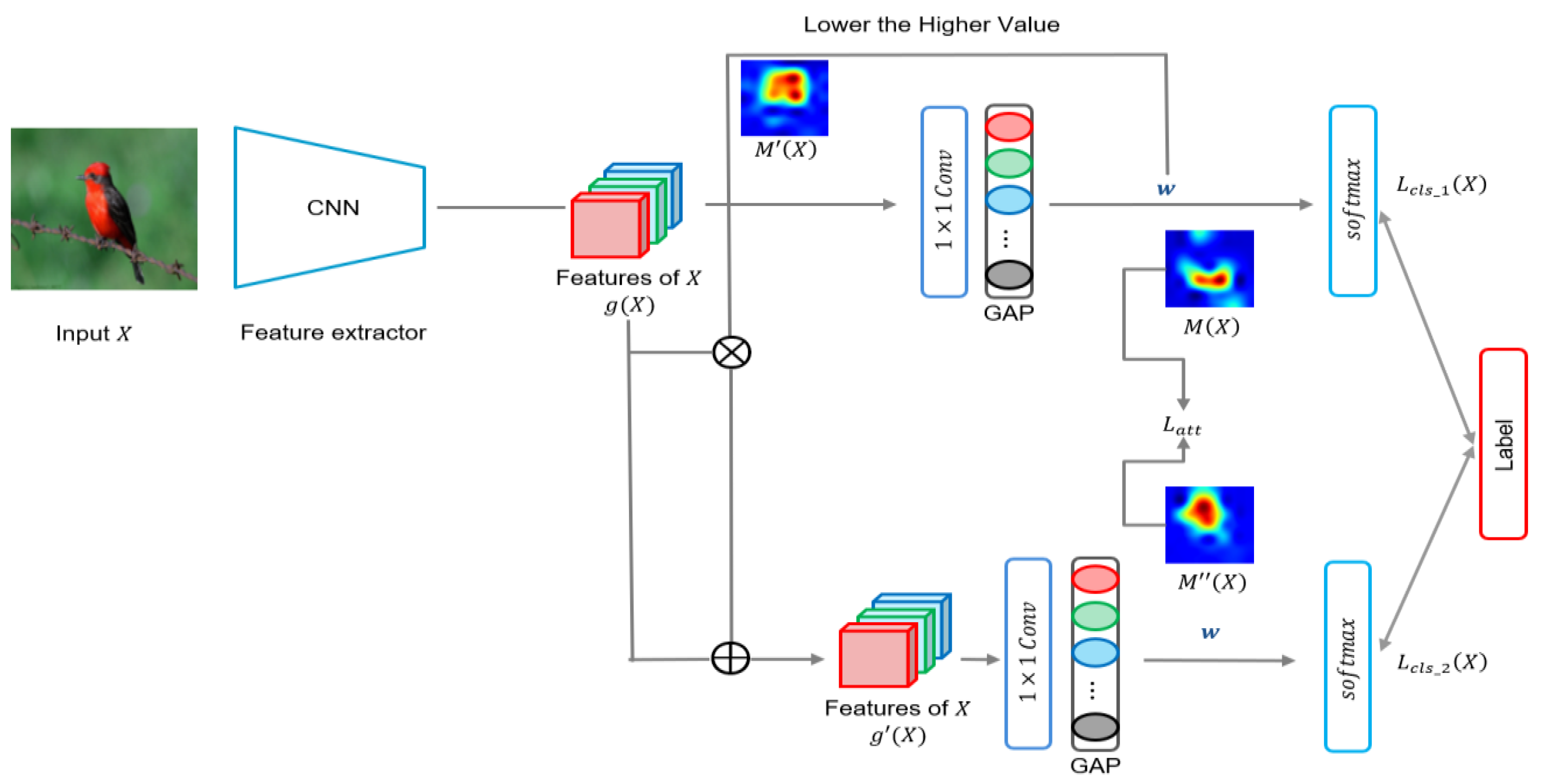
3. Proposed WSOL Method with Adjusted Weights
4. Experiments
4.1. Dataset
- Number of categories: 200;
- Number of images: 11,788;
- Annotations per image: 15 Part Locations, 312 Binary Attributes, 1 Bounding box.
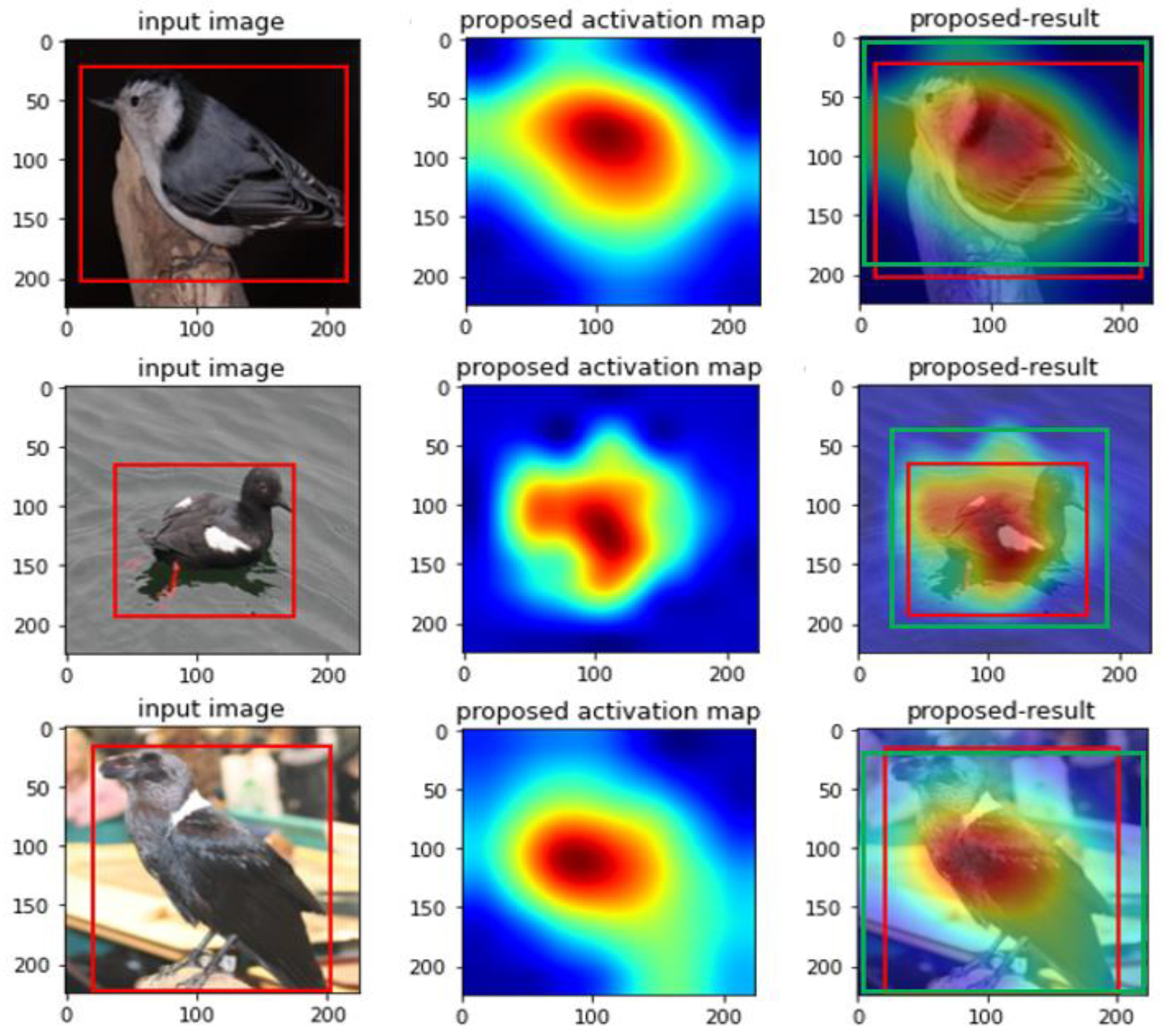
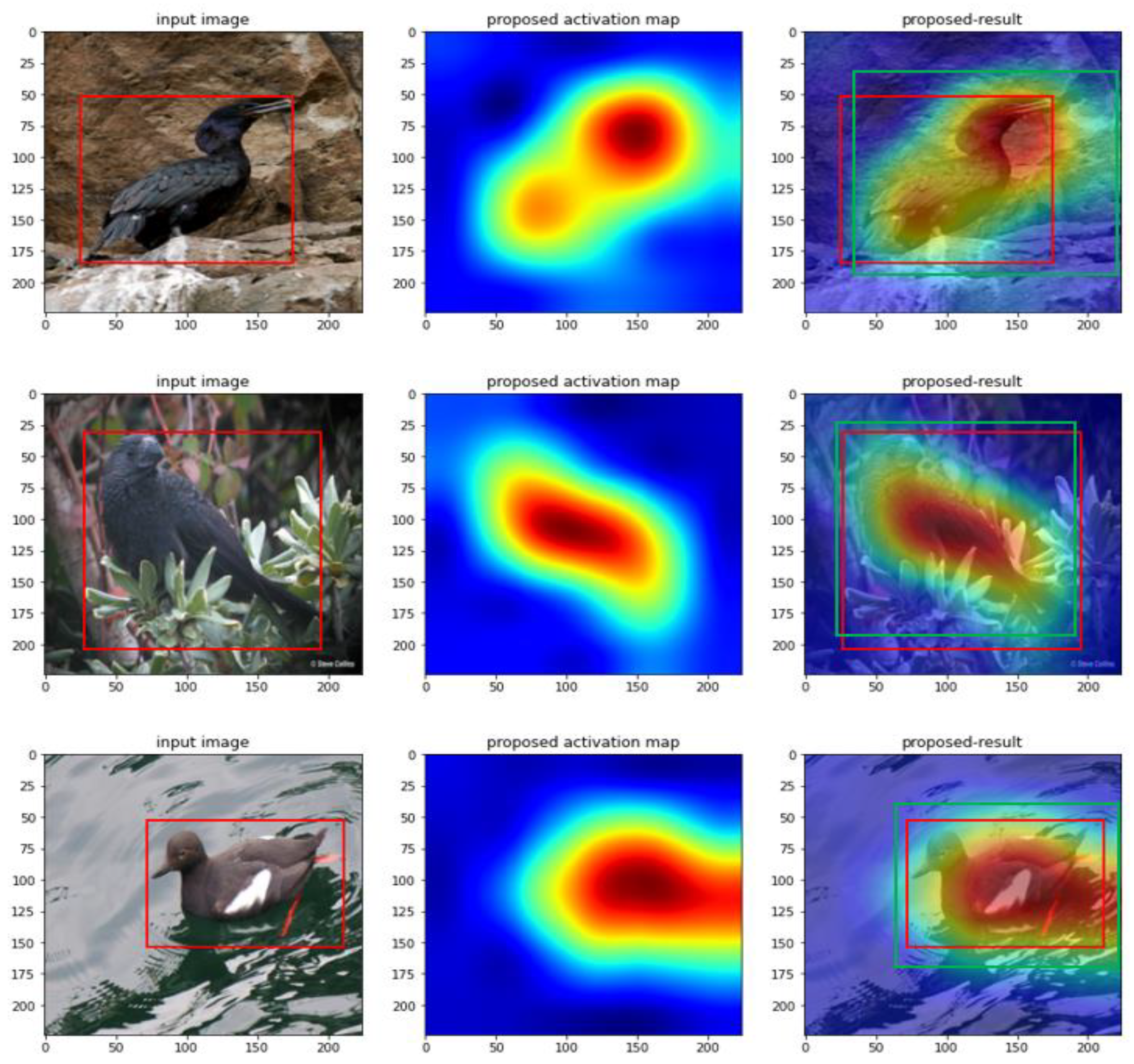
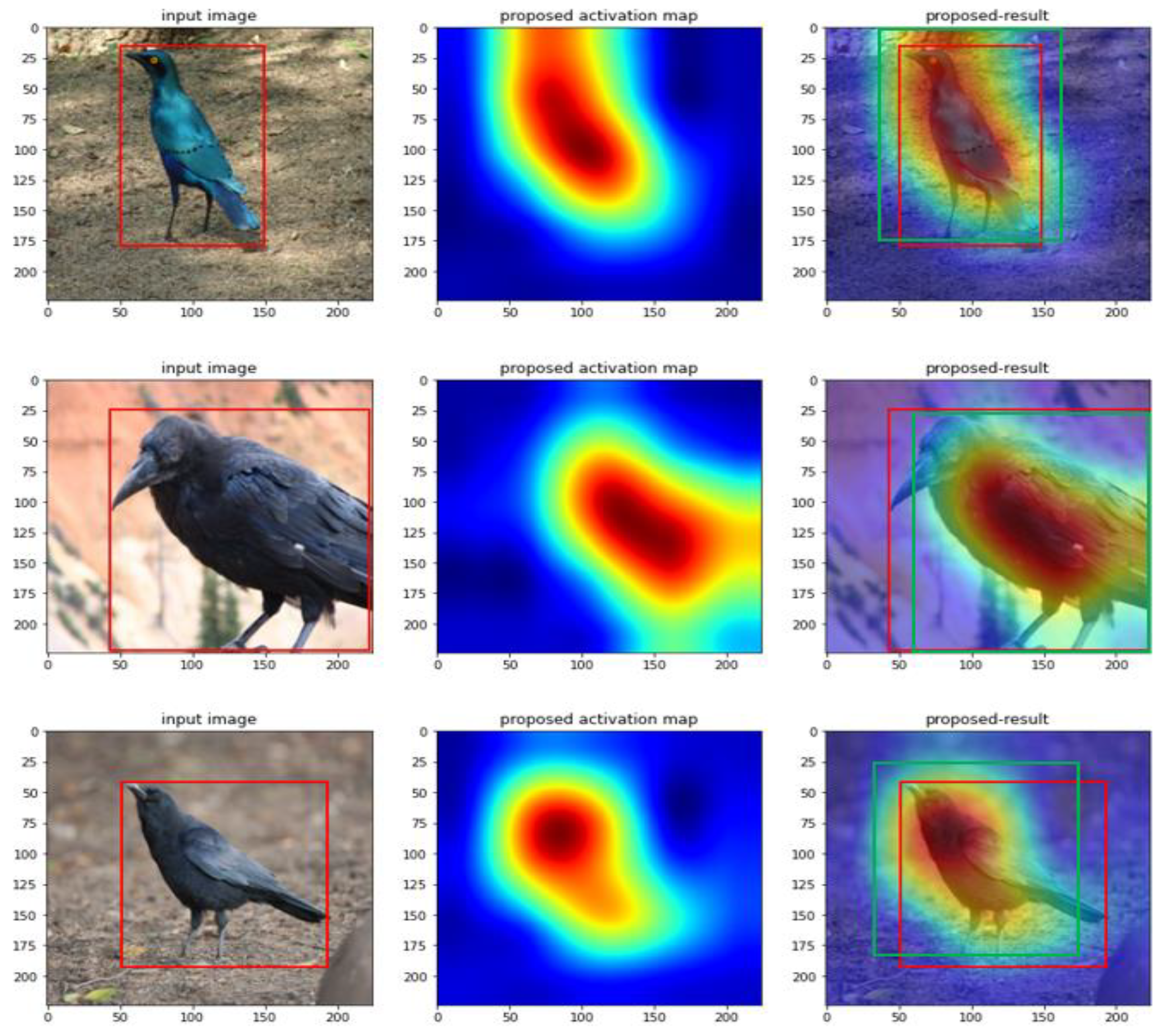
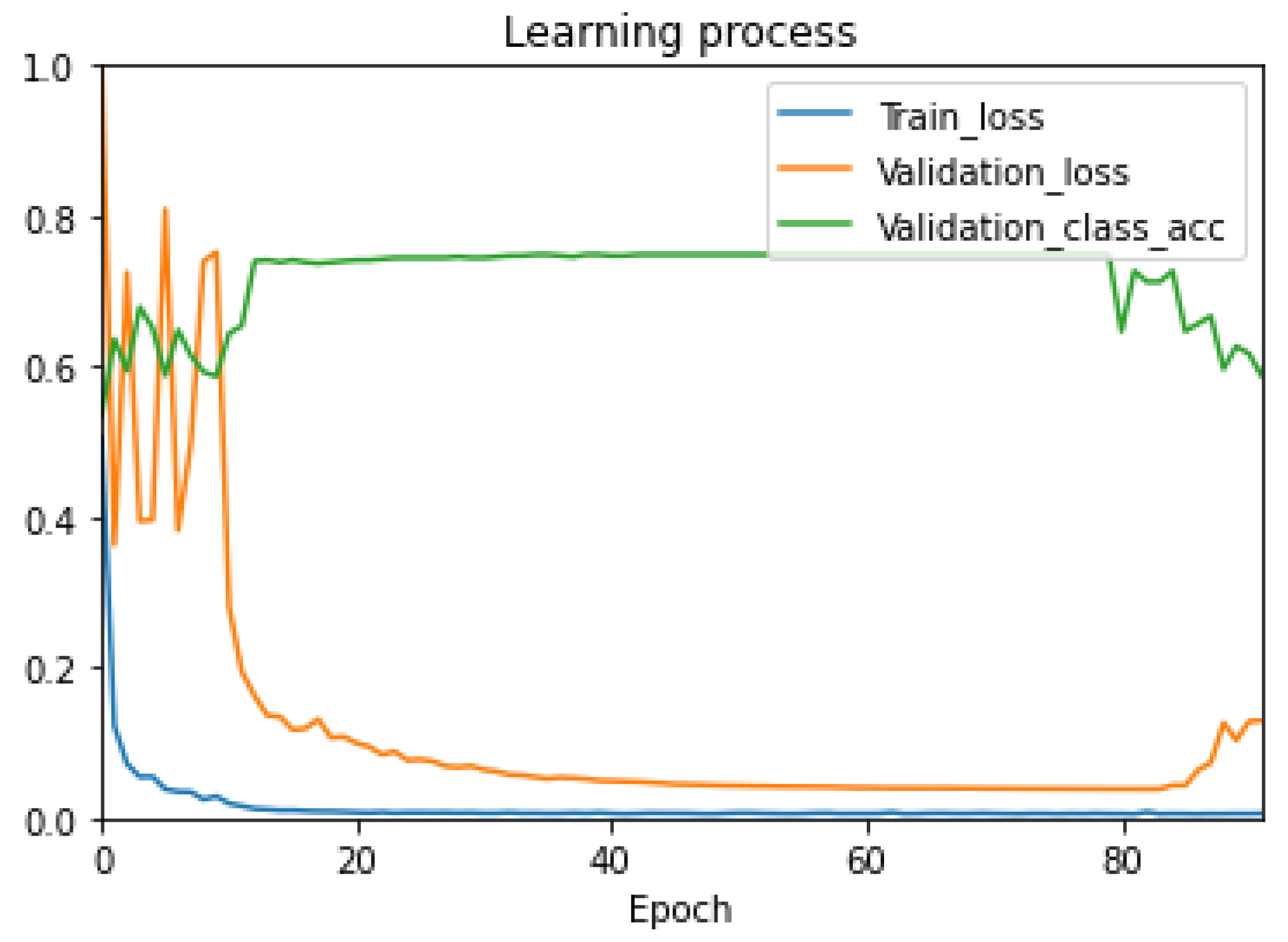
4.2. Results of the Experiments
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Jhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Z. Abrief introduction to weakly supervised learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Naoto, I.; Ryosuke, F.; Toshihiko, Y.; Kiyoharu, A. Cross-domain weakly-supervised object detection through progressive domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 18–23 June 2018; pp. 5001–5009. [Google Scholar]
- Chenhao, L.; Siwen, W.; Dongqi, X.; Yu, L.; Wayne, Z. Object Instance Mining for Weakly Supervised Object Detection. Proc. AAAI Conf. Artif. Intell. 2020, 34, 11482–11489. [Google Scholar]
- Yude, W.; Jie, Z.; Meina, K.; Shiguang, S.; Xilin, C. Self-supervised Equivariant Attention Mechanism for Weakly Supervised Sementic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12275–12284. [Google Scholar]
- Ahn, J.; Cho, S.; Kwak, S. Weakly Supervised Learning of Instance Segmentation with Inter-pixel Relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2209–2218. [Google Scholar]
- Gwak, J.; Choy, C.; Chandraker, M.; Garg, A.; Savarese, S. Weakly supervised 3D Reconstruction with Adversarial Constraint. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 263–272. [Google Scholar]
- Singh, K.K.; Lee, Y.J. Hide-and-Seek: Forcing a network to be meticulous for weakly-supervised object and action location. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3544–3553. [Google Scholar] [CrossRef] [Green Version]
- Babar, S.; Das, S. Where to Look? : Mining complementary image regions for weakly supervised object localization. In Proceeding of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1010–1019. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Ficklenet: Weakly and semi-supervised semantic image segmentation using stochastic inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5267–5276. [Google Scholar] [CrossRef] [Green Version]
- Yang, S.; Kim, Y.; Kim, Y.; Kim, C. Combinational class activation maps for weakly supervised object localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass, CO, USA, 1–5 March 2020; pp. 2941–2949. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Xue, H.; Liu, C.W.; Wan, F.; Jiao, J.; Ji, X.; Ye, Q. Danet: Divergent activation for weakly supervised object localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6589–6598. [Google Scholar]
- Zhang, X.; Wei, Y.; Feng, J.; Yang, Y.; Huang, T. Adversarial complementary learning for weakly supervised object localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1325–1334. [Google Scholar]
- Choe, J.; Shim, H. Attention-based dropout layer for weakly supervised object localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2219–2228. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef] [Green Version]
- Larochelle, H.; Hinton, G.E. Learning to combine foveal glimpses with a third-order Boltzmann machine. Adv. Neural Inf. Process. Syst. 2010, 23, 1243–1251. [Google Scholar] [CrossRef] [Green Version]
- Woo, S.; Park, J.; Lee, J.; Kweon, I. Cbam: Convolutional black attention module. In Proceedings of the European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Fukui, H.; Hirakawa, T.; Yamashita, T.; Fujiyoshi, H. Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10705–10714. [Google Scholar] [CrossRef] [Green Version]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. Image large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Ku, B.; Kin, G.; Ahn, J.; Lee, J.; Ko, H. Attention-Based Convolutional Neural Network for Earthquake Event Classification. IEEE Geosci. Remote Sens. Lett. 2020, 1–5. [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset. In Computation & NeuralSystems Technical Report; CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Top-1 Loc | Top-1 Clas |
|---|---|---|
| Inception V3-CAM [1] | 43.67 | 73.80 |
| Inception V3-DANet [13] | 49.45 | 71.20 |
| Inception V3-Ours | 52.71 | 75.21 |
| VGG-CAM [1] | 34.41 | 67.55 |
| VGG-AcoL [14] | 45.92 | 71.90 |
| VGG-ADL [15] | 52.36 | 65.27 |
| VGG-CCAM [11] | 50.07 | 73.20 |
| VGG-Ours | 55.15 | 73.51 |
| Best-Performance | 55.15 | 75.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, N.; Ko, H. Weakly Supervised Learning for Object Localization Based on an Attention Mechanism. Appl. Sci. 2021, 11, 10953. https://doi.org/10.3390/app112210953
Park N, Ko H. Weakly Supervised Learning for Object Localization Based on an Attention Mechanism. Applied Sciences. 2021; 11(22):10953. https://doi.org/10.3390/app112210953
Chicago/Turabian StylePark, Nojin, and Hanseok Ko. 2021. "Weakly Supervised Learning for Object Localization Based on an Attention Mechanism" Applied Sciences 11, no. 22: 10953. https://doi.org/10.3390/app112210953
APA StylePark, N., & Ko, H. (2021). Weakly Supervised Learning for Object Localization Based on an Attention Mechanism. Applied Sciences, 11(22), 10953. https://doi.org/10.3390/app112210953