
An Analytic Method for Improving the Reliability of Models Based on a Histogram for Prediction of Companion Dogs’ Behaviors


Abstract
:1. Introduction
- First, this paper suggests a dog behavior dataset called the YouTube Companion Dog’s Seven Behaviors Dataset (Youtube-C7B). We collected videos containing 2D RGB image-based behavior data of dogs (French Bulldogs, Siberian Huskies, and Retrievers) from the YouTube platform. The proposed Youtube-C7B helps the behavioral modeling of dogs become more natural by collecting videos of dog behaviors in real-world environments, unlike the conventional datasets that have collected behavior data through sensors in limited spaces. Furthermore, while the conventional datasets are without labels, the dataset proposed in this study was built by labeling behaviors suitable for deep learning. Finally, in contrast to the conventional datasets, the proposed dataset contains not only normal behaviors, but also convulsing, which is an abnormal behavior, and can be used in various applications for detecting the abnormal behaviors of dogs and responding to emergency situations.
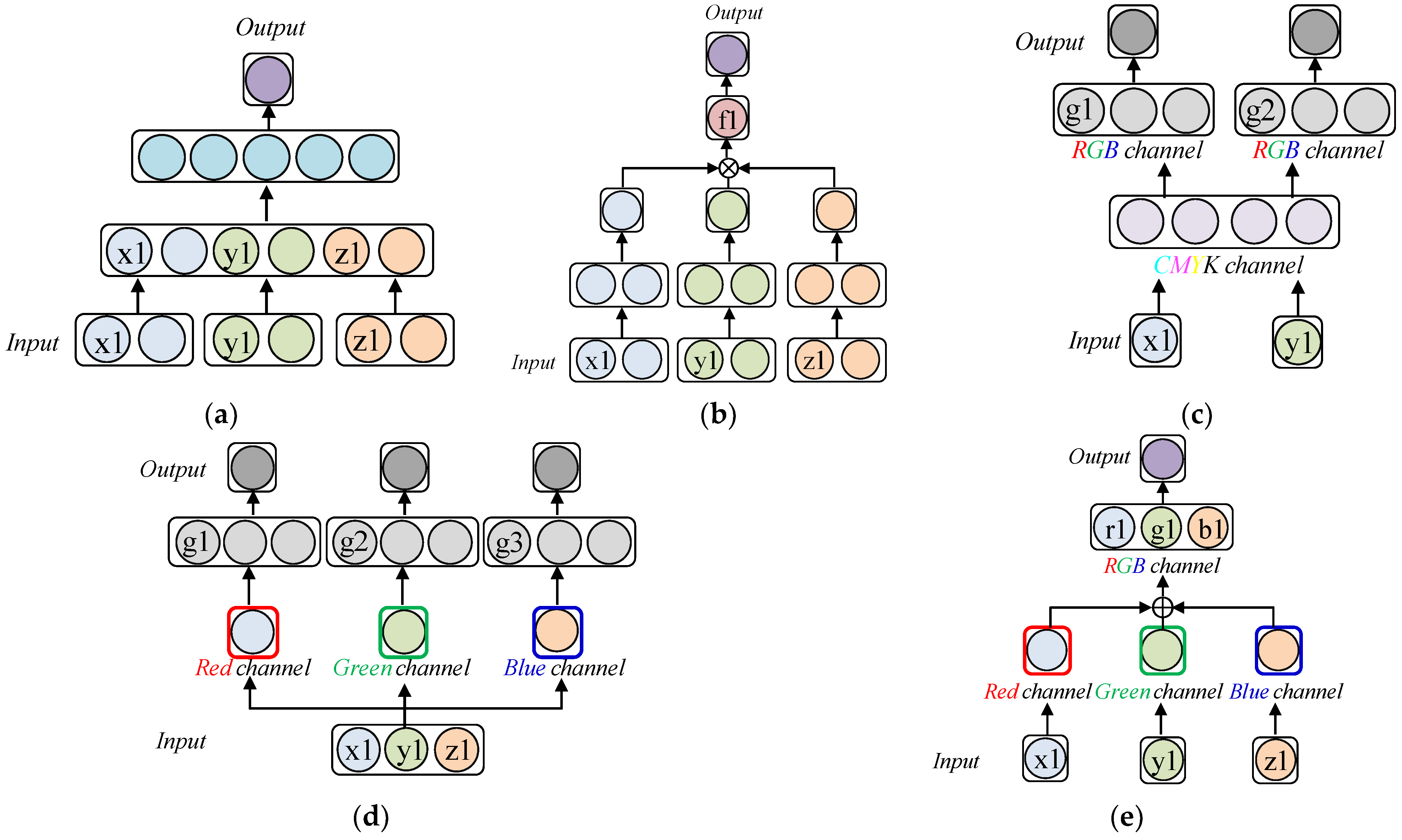
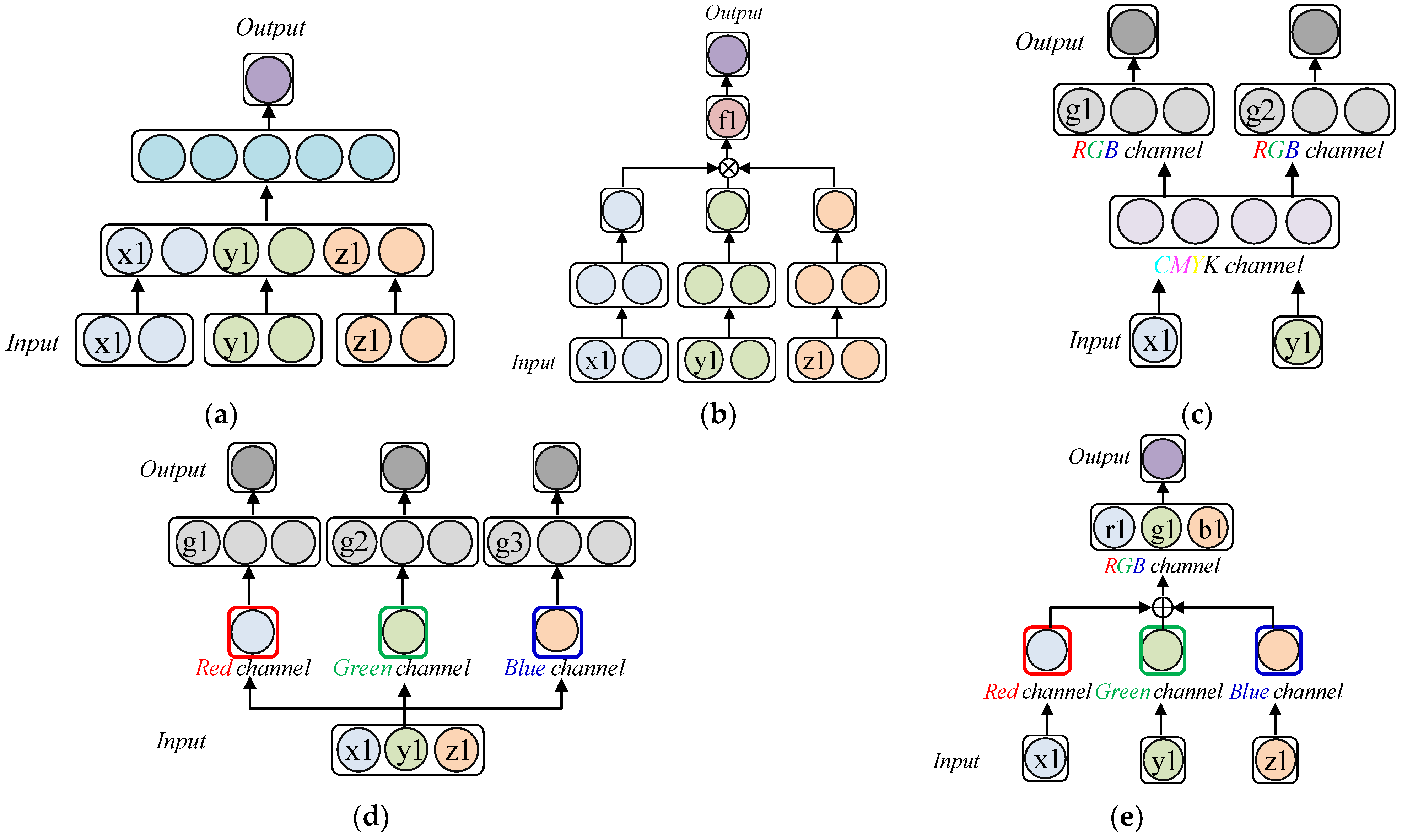
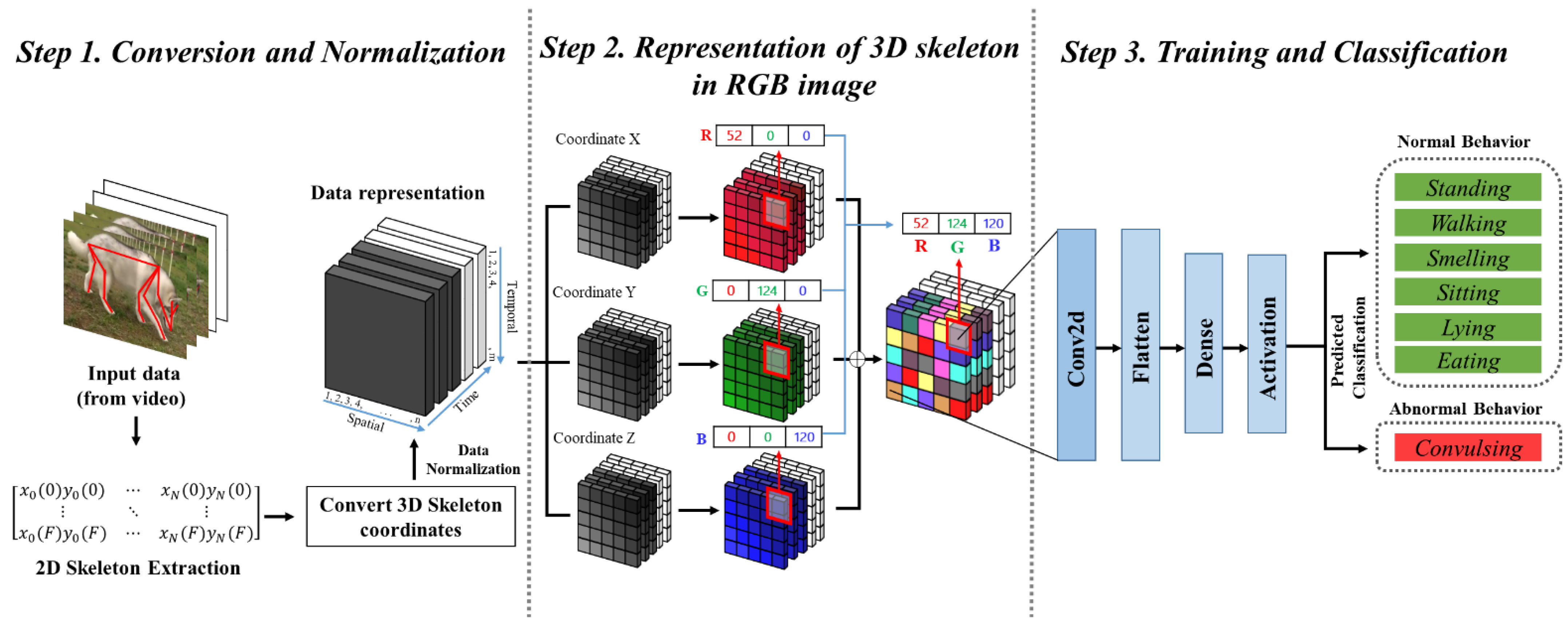
- Second, in this paper, to identify the postures of dogs, a Tightly Coupled RGB Time Tensor Network is proposed, which is an RGB-based data representation method that contains the correlations among the x-, y-, and z-axes, which change as time passes. A good representation of the changing patterns of x, y, and z over time and their relationships help to achieve a modeling with a great distance between each behavioral feature. This leads to an improved accuracy of the dog pose identification. For example, because convulsing results in more shaking on the x-, y-, and z-axes compared to standing, the patterns that change over time and their relationships should be properly represented to effectively model the dog’s behaviors. For this reason, we encode the three components (x-, y-, and z-axes) of each 3D joint position into the 3D components (red, green, and blue channels) of the RGB images and then fuse these colors. When the colors are fused in this way, it can be seen as containing the correlations of the x-, y-, and z-axes because even after fusing, it is possible to infer the pre-fusion behavior information, unlike when they were represented by vectors. Furthermore, it helps the deep learning model decode meaningful information to better identify the dog’s behaviors.
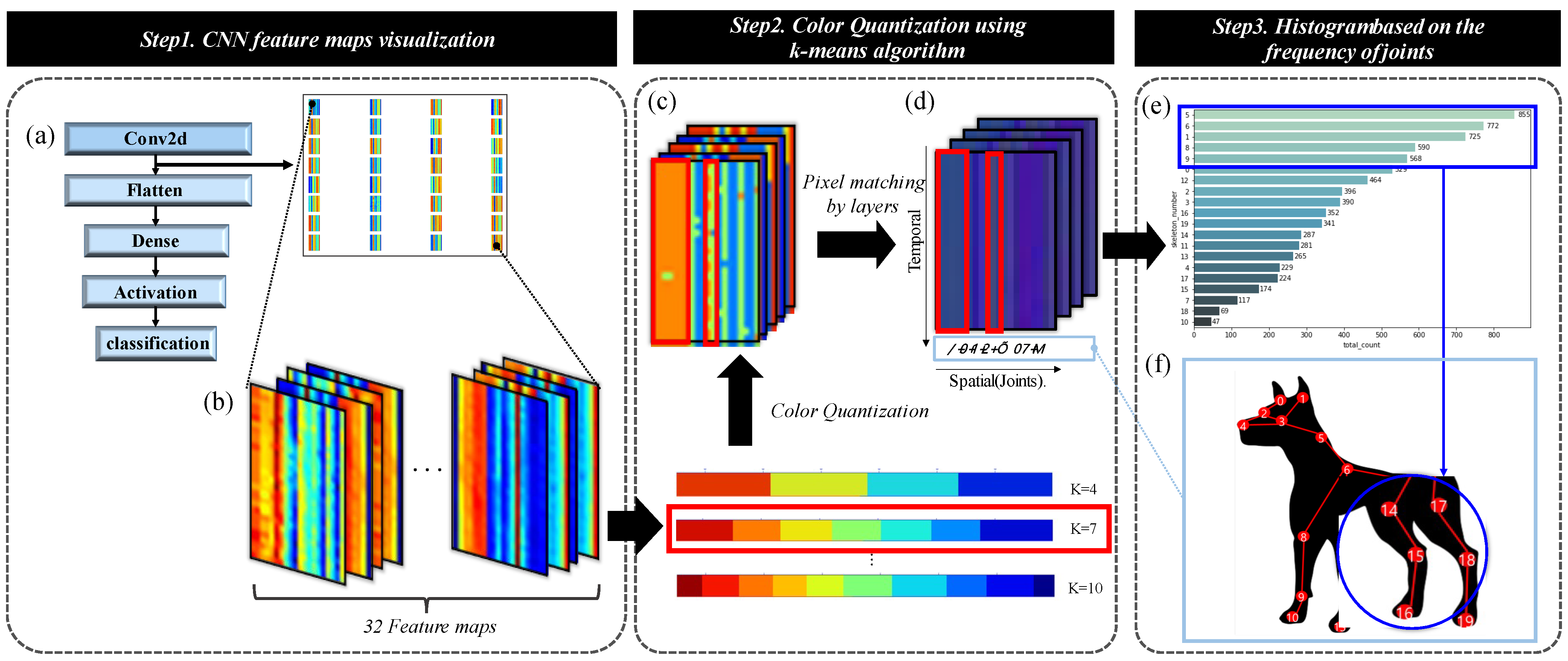
- Third, unlike conventional methods, the proposed method visualizes the filters of Conv-layer in analyzable feature maps. Thus, the patterns that the CNN memorizes for predictions can be understood. By displaying the joints extracted from the visualized feature maps based on a histogram, it is possible to know which joint part of the input image was mainly learned to make decisions.
2. Related Work
2.1. Wearable and Physical Devices for Data Collection
2.2. Spaito-Temporal Data Representation
3. Tightly Coupled RGB Time Tensor Network
3.1. Creation and Selection of Behaviors
3.2. Pose-Transition Feature to Image Encoding Technique
3.2.1. Pose and Transition Feature Extraction
3.2.2. Behavior Image Generation (RGB Color Encoding)
| Algorithm 1: Construct RGB-color based Video Tensor |
| Input: Output:  |
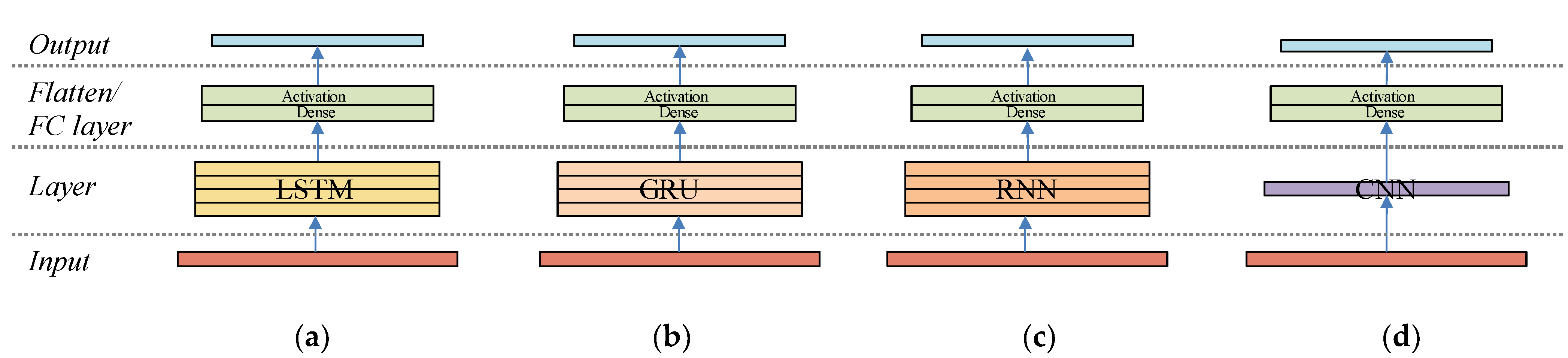
3.2.3. Hyperparameter Tuning
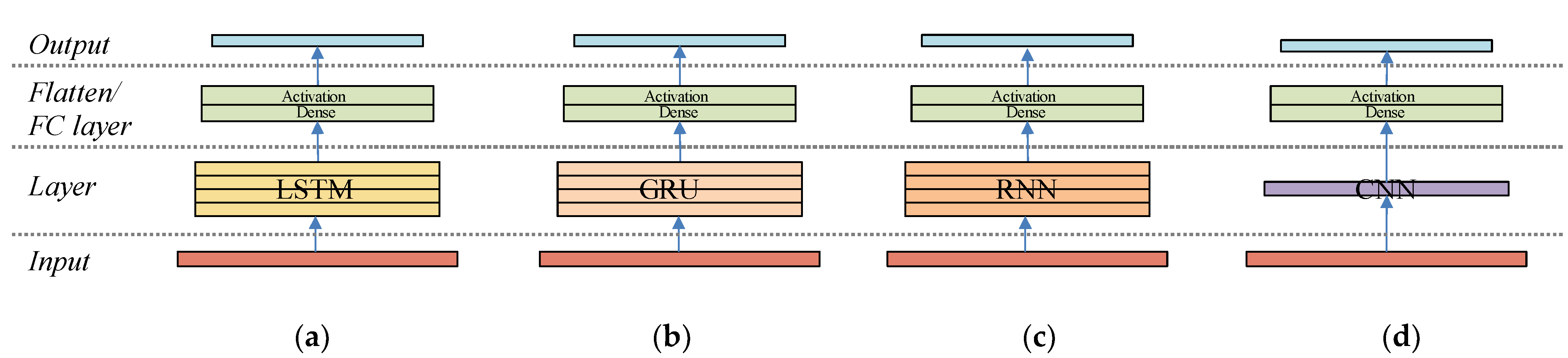
3.3. Model Pattern Analysis Based on Filter Visualization
4. Experiments
4.1. Experimental Setup
4.2. Experimental Details
- Experiments 1. Performance comparison of models in various color spaces
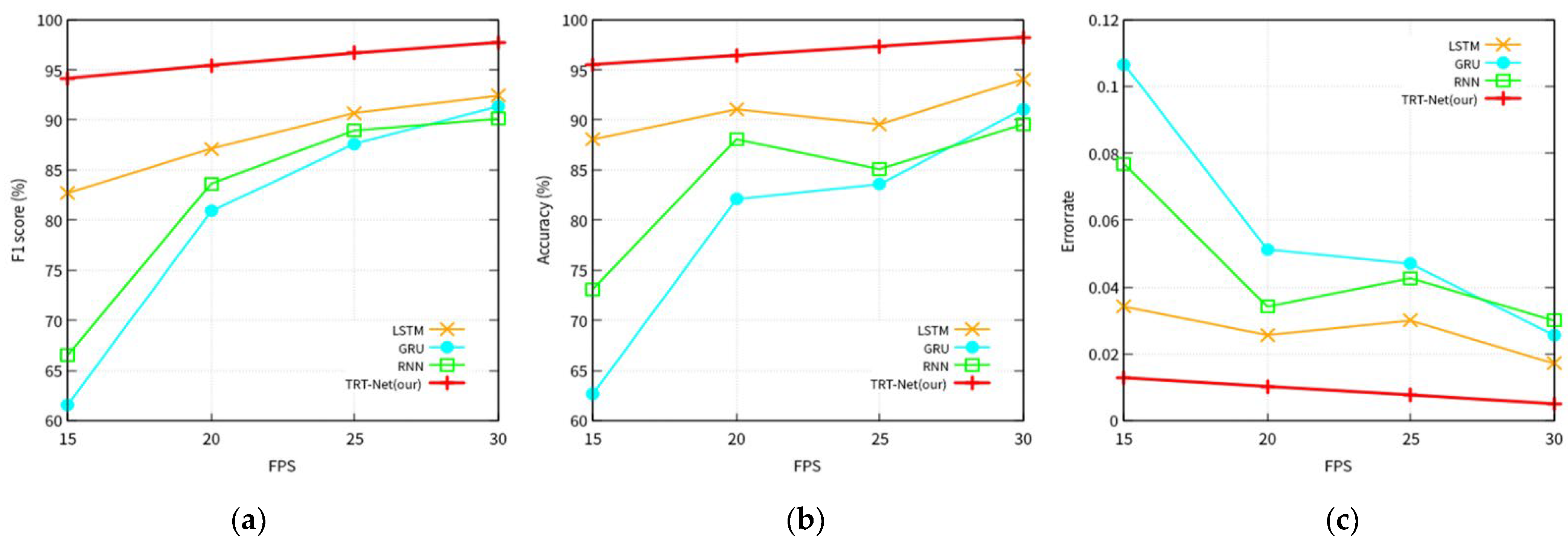
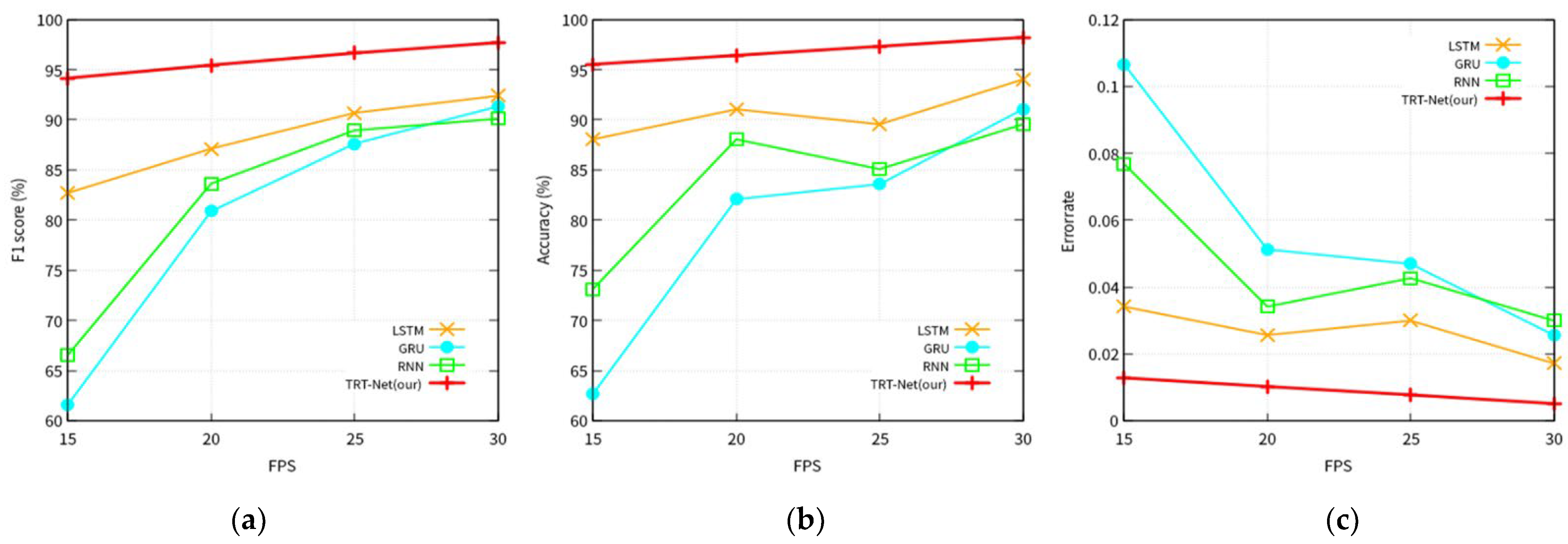
- Experiments 2. Performance comparison of models according to the fps
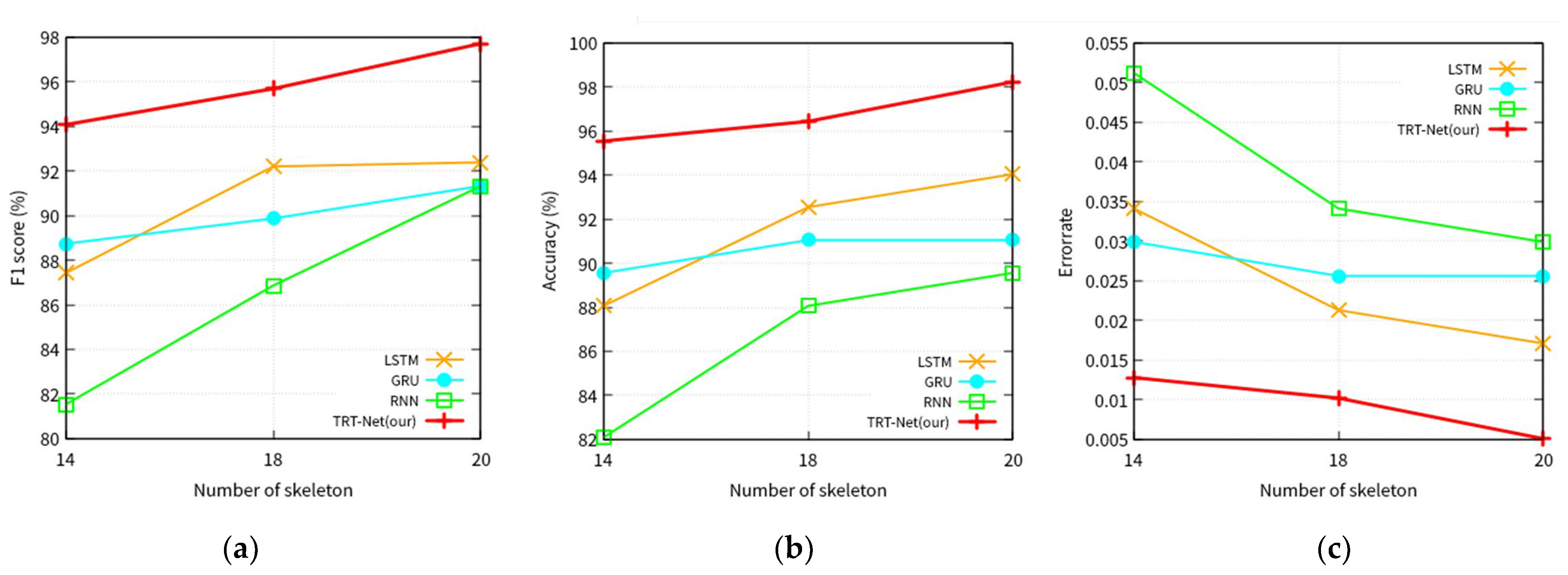
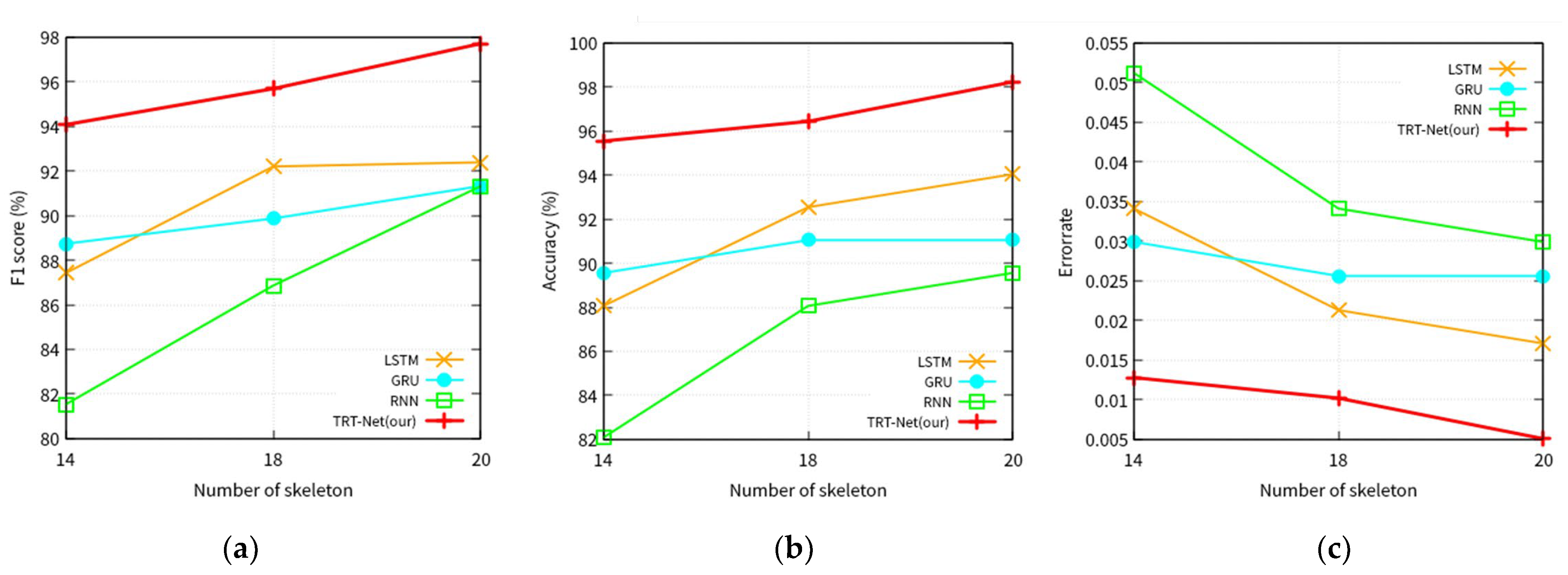
- Experiments 3. Performance comparison of models according to the number of skeleton joints
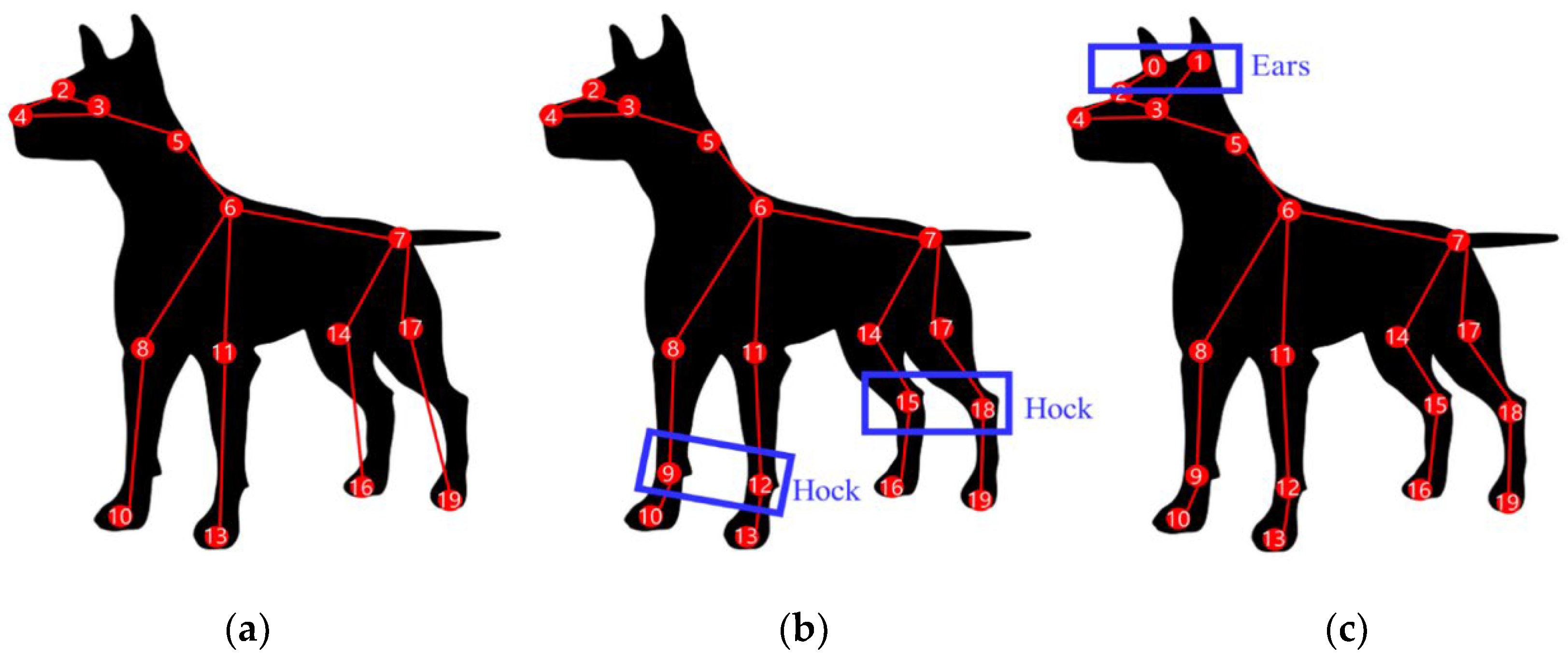
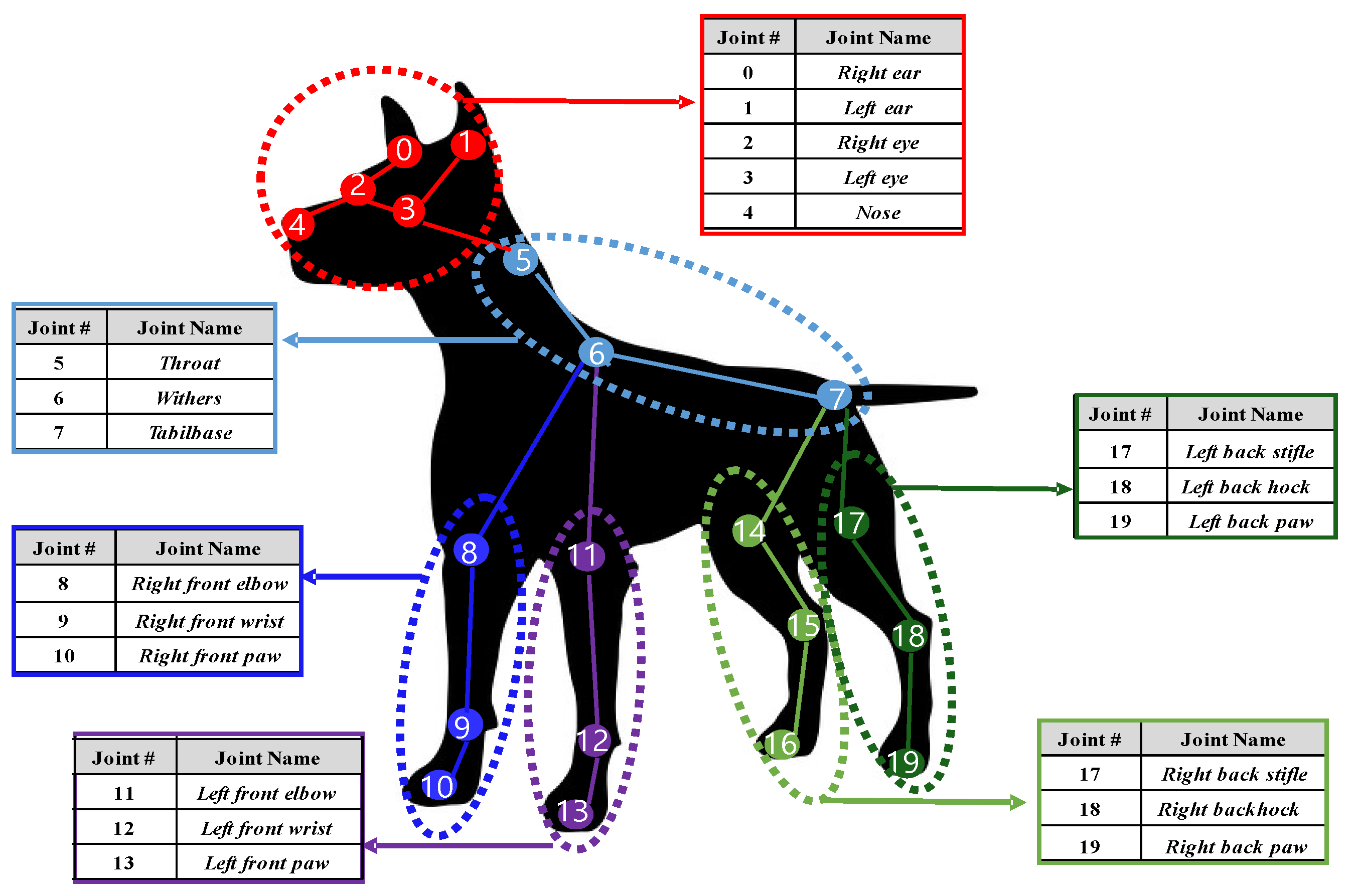
- Experiments 4. Analysis of joints that the CNN model mainly learns for each behavior
4.3. Experiments and Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boteju, W.J.M.; Herath, H.M.K.S.; Peiris, M.D.P.; Wathsala, A.K.P.E.; Samarasinghe, P.; Weerasinghe, L. Deep Learning Based Dog Behavioural Monitoring System. In Proceedings of the 2020 3rd International Conference on Intelligent Sustainable Systems (ICISS), Thoothukudi, India, 3–5 December 2020; pp. 82–87. [Google Scholar]
- Komori, Y.; Ohno, K.; Fujieda, T.; Suzuki, T.; Tadokoro, S. Detection of continuous barking actions from search and rescue dogs’ activities data. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 630–635. [Google Scholar]
- Brugarolas, R.; Roberts, D.; Sherman, B.; Bozkurt, A. Posture estimation for a canine machine interface based training system. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 4489–4492. [Google Scholar]
- Mealin, S.; Domínguez, I.X.; Roberts, D.L. Semi-supervised classification of static canine postures using the Microsoft Kinect. In Proceedings of the Third International Conference on Animal-Computer Interaction, Milton Keynes, UK, 15–17 November 2016; pp. 1–4. [Google Scholar]
- Kearney, S.; Li, W.; Parsons, M.; Kim, K.I.; Cosker, D. RGBD-dog: Predicting canine pose from RGBD sensors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8336–8345. [Google Scholar]
- Bleuer-Elsner, S.; Zamansky, A.; Fux, A.; Kaplun, D.; Romanov, S.; Sinitca, A.; van der Linden, D. Computational analysis of movement patterns of dogs with ADHD-like behavior. Animals 2019, 9, 1140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yao, Y.; Jafarian, Y.; Park, H.S. Monet: Multiview semi-supervised keypoint detection via epipolar divergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 753–762. [Google Scholar]
- Luo, J.; Wang, W.; Qi, H. Spatio-temporal feature extraction and representation for RGB-D human action recognition. Pattern Recognit. Lett. 2014, 50, 139–148. [Google Scholar] [CrossRef]
- Arivazhagan, S.; Shebiah, R.N.; Harini, R.; Swetha, S. Human action recognition from RGB-D data using complete local binary pattern. Cognit. Syst. Res. 2019, 58, 94–104. [Google Scholar] [CrossRef]
- Makantasis, K.; Voulodimos, A.; Doulamis, A.; Bakalos, N.; Doulamis, N. Space-Time Domain Tensor Neural Networks: An Application on Human Pose Classification. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4688–4695. [Google Scholar]
- Patel, C.I.; Garg, S.; Zaveri, T.; Banerjee, A.; Patel, R. Human action recognition using fusion of features for unconstrained video sequences. Comput. Electr. Eng. 2018, 70, 284–301. [Google Scholar] [CrossRef]
- Zhou, L.; Chen, Y.; Wang, J.; Lu, H. Progressive bi-c3d pose grammar for human pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13033–13040. [Google Scholar]
- Wang, P.; Li, Z.; Hou, Y.; Li, W. Action recognition based on joint trajectory maps using convolutional neural networks. In Proceedings of the 24th ACM International Conference on Multimedia, New York, NY, USA, 15–19 October 2016; pp. 102–106. [Google Scholar]
- Park, S.H.; Park, Y.H. Audio-visual tensor fusion network for piano player posture classification. Appl. Sci. 2020, 10, 6857. [Google Scholar] [CrossRef]
- Jiang, W.; Yin, Z. Human activity recognition using wearable sensors by deep convolutional neural networks. In Proceedings of the 23rd ACM International Conference on Multimedia, Shanghai, China, 23–26 June 2015; pp. 1307–1310. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Aubry, S.; Laraba, S.; Tilmanne, J.; Dutoit, T. Action recognition based on 2D skeletons extracted from RGB videos. MATEC Web. Conf. 2019, 277, 02034. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Medford, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Lai, K.; Tu, X.; Yanushkevich, S. Dog identification using soft biometrics and neural networks. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Liu, J.; Kanazawa, A.; Jacobs, D.; Belhumeur, P. Dog breed classification using part localization. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 172–185. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A.; Jawahar, C.V. Cats and dogs. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3498–3505. [Google Scholar]
- Moreira, T.P.; Perez, M.L.; de Oliveira Werneck, R.; Valle, E. Where is my puppy? Retrieving lost dogs by facial features. Multimed. Tools Appl. 2017, 76, 15325–15340. [Google Scholar] [CrossRef]
- Khosla, A.; Jayadevaprakash, N.; Yao, B.; Li, F. Novel dataset for fine-grained image categorization. In Proceedings of the First Workshop on Fine-Grained Visual Categorization, IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Mathis, A.; Mamidanna, P.; Cury, K.M.; Abe, T.; Murthy, V.N.; Mathis, M.W.; Bethge, M. DeepLabCut: Markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 2018, 21, 1281–1289. [Google Scholar] [CrossRef] [PubMed]
- Ladha, C.; Hammerla, N.; Hughes, E.; Olivier, P.; Ploetz, T. Dog’s life: Wearable activity recognition for dogs. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; pp. 415–418. [Google Scholar]
- Martinez, A.R.; Liseth, E. Epilepsia En Perros: Revisi De Tema. Rev. CITECSA 2016, 6, 5. [Google Scholar]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 579–583. [Google Scholar]
- Laraba, S.; Brahimi, M.; Tilmanne, J.; Dutoit, T. 3D skeleton-based action recognition by representing motion capture sequences as 2D-RGB images. Comput. Animat. Virtual Worlds 2017, 28. [Google Scholar] [CrossRef]
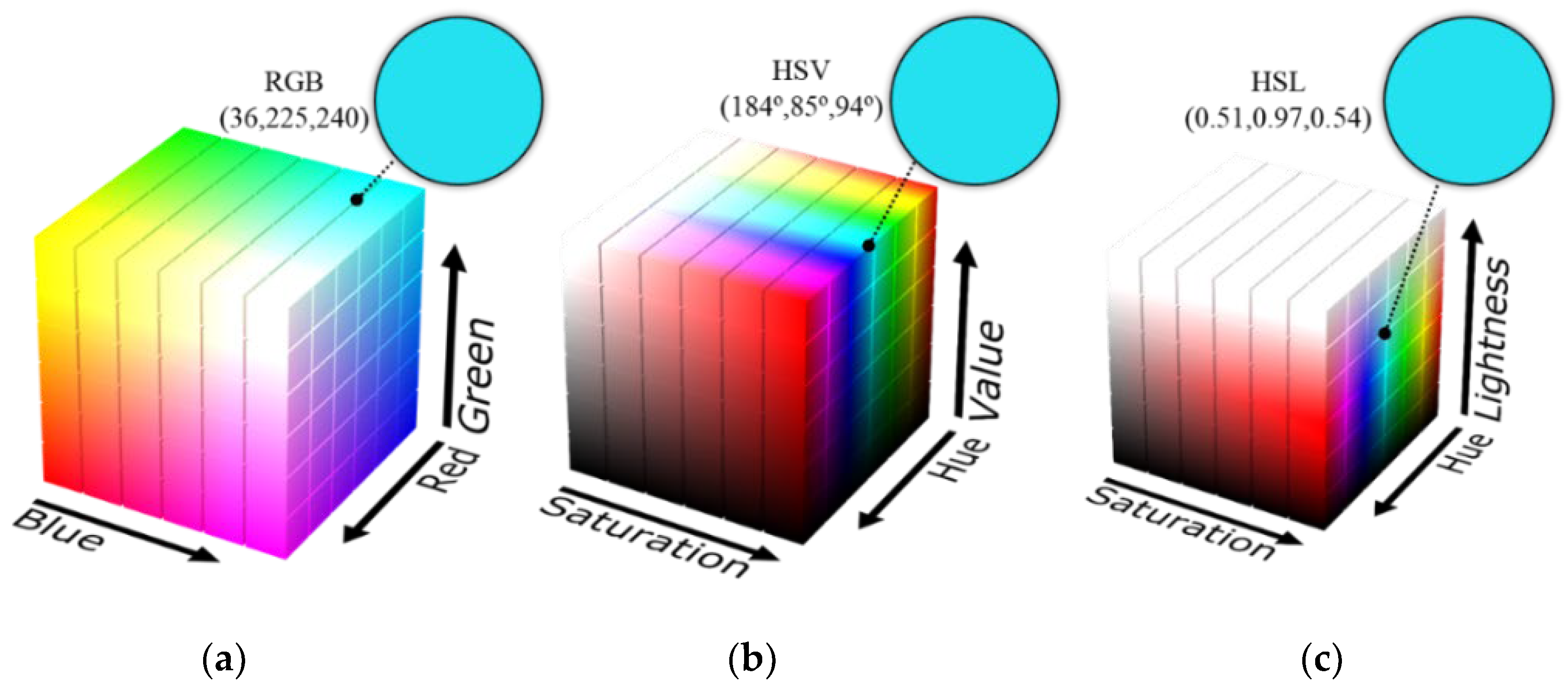
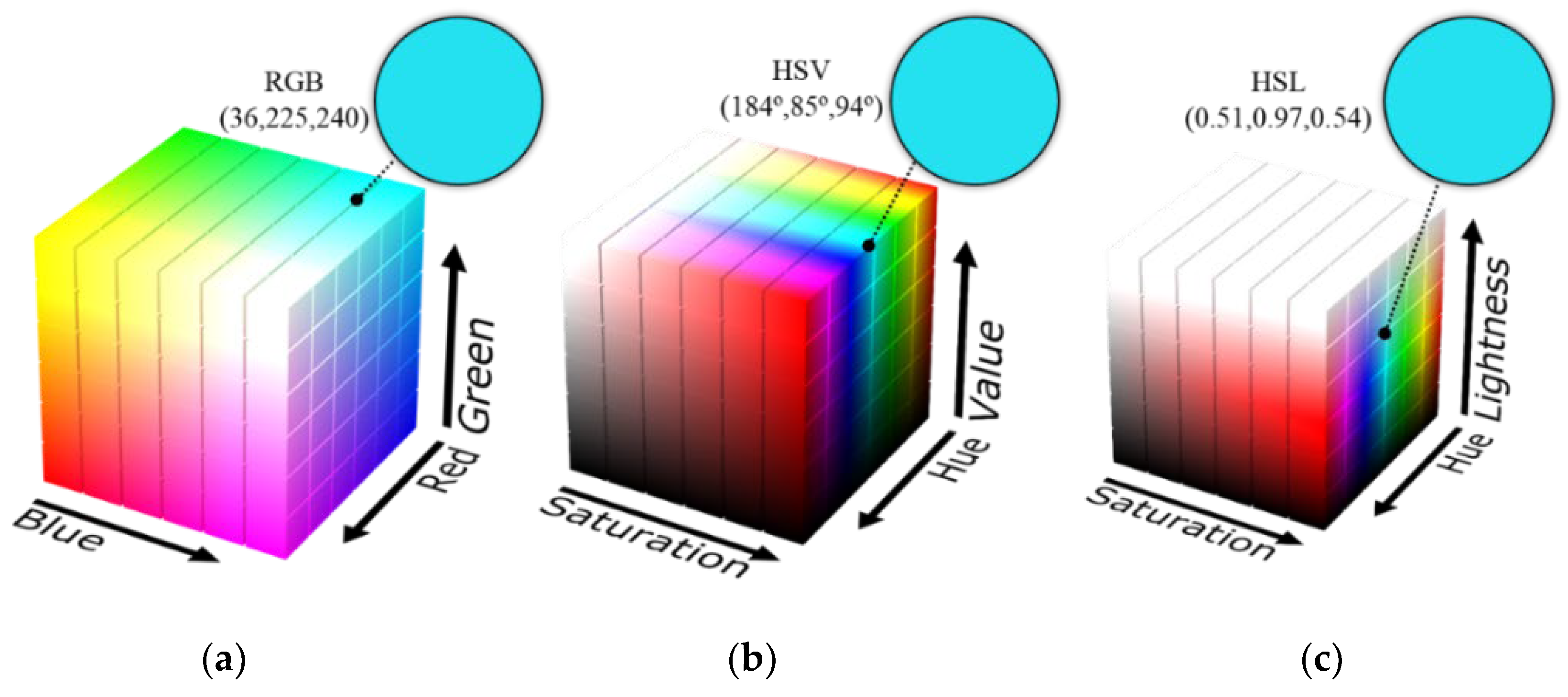
- Travis, D. Effective Color Displays: Theory and Practice; Academic Press: Cambridge, MA, USA; London, UK, 1991; ISBN 0-12-697690-2. [Google Scholar]
- Saravanan, G.; Yamuna, G.; Nandhini, S. Real time implementation of RGB to HSV/HSI/HSL and its reverse color space models. In Proceedings of the 2016 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 6–8 April 2016; pp. 462–466. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Year | Species | #Image | Resolution | Resource | Pose Labels | Key Points |
|---|---|---|---|---|---|---|---|
| Columbia Dogs [23] | 2012 | Dog | 8351 | Various | Flickr Image-Net | - | √ (Only Face) |
| Oxford-IIIT [24] | 2012 | Cat+Dog | 7349 | Various | Flickr Image-Net | - | - |
| Flickr-Dog [25] | 2016 | Dog | 374 | 250 × 250 | Flickr | - | - |
| Stanford Dogs [26] | 2011 | Dog | 20,580 | Various | - | - | |
| Youtube-C7B (our proposed method) | 2021 | Dog | 10,710 | Various | YouTube | √ | √ (Face+Body) |
| Behavior | Description |
| Walking | Behavior of the companion dog moving to a different location when using all four legs |
| Standing on two Legs | Stretching the front legs straight and sitting with rear legs while the four soles are touching the ground |
| Standing of four legs | Posture of standing with four legs stretched straight and straightened body while the four soles are touching the ground |
| Lying down | Lying down with limbs either tucked under or placed in front of body |
| Eating off the ground | Eating food on the ground by grabbing it with front legs |
| Additional behavior class | |
| Smelling | Behavior of smelling the ground, objects, or things by getting the nose close to it |
| Convulsing | Behavior of shaking the face and body as if an electrical shock has been applied to the brain |
| Symbols | Definition |
|---|---|
| Mean frame per second | |
| n | Number of skeleton joints |
| Extracted skeleton coordinate from videos | |
| Conversion visual tensor | |
| pixRGB | RGB color pixels |
| Color visual tensor image | |
| Red channel in RGB | |
| Green channel in RGB | |
| B | Blue channel in RGB |
| Hyper-Parameter | Best Value | Description |
|---|---|---|
| Batch size | 200 | Number of training cases over which SGD update is computed. |
| Loss function | Categorical cross entropy | The objective function or optimization score function is also called multiclass log loss, which is appropriate for categorical targets. |
| Optimizer | SGD | Stochastic gradient descent optimizer. |
| Learning rate | 0.01 | Learning rate used by SGD optimizer. |
| Momentum | 0.9 | Momentum used by SGD optimizer. |
| Color Space | Accuracy | Precision | Recall | F1-Score | Error Rate (MSE) |
|---|---|---|---|---|---|
| HSV | 84.23 | 91.54 | 85.87 | 85.33 | 0.045 |
| HLS | 81.84 | 90.48 | 83.69 | 83.01 | 0.034 |
| RGB | 96.95 | 97.52 | 96.74 | 96.97 | 0.008 |
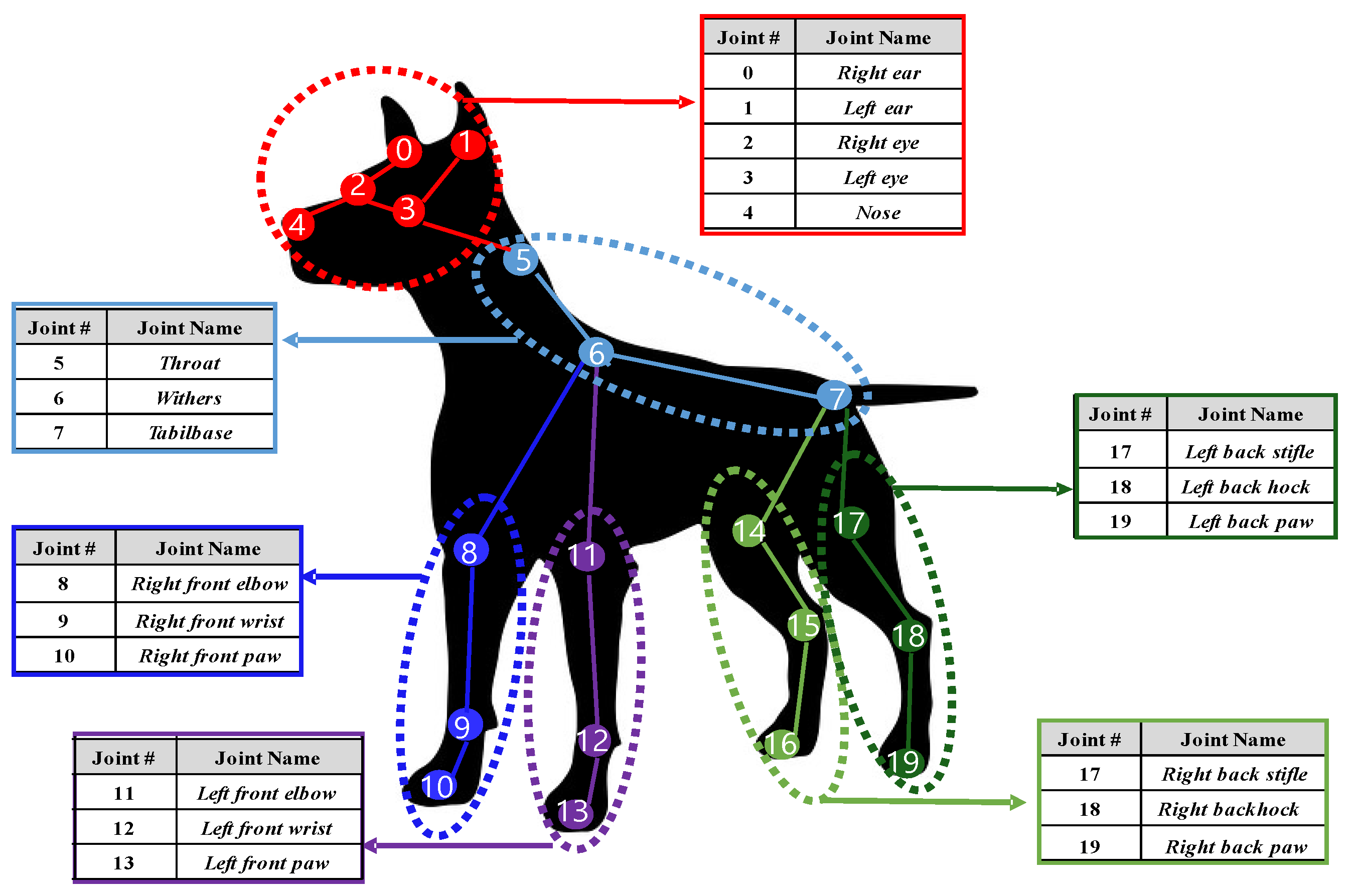
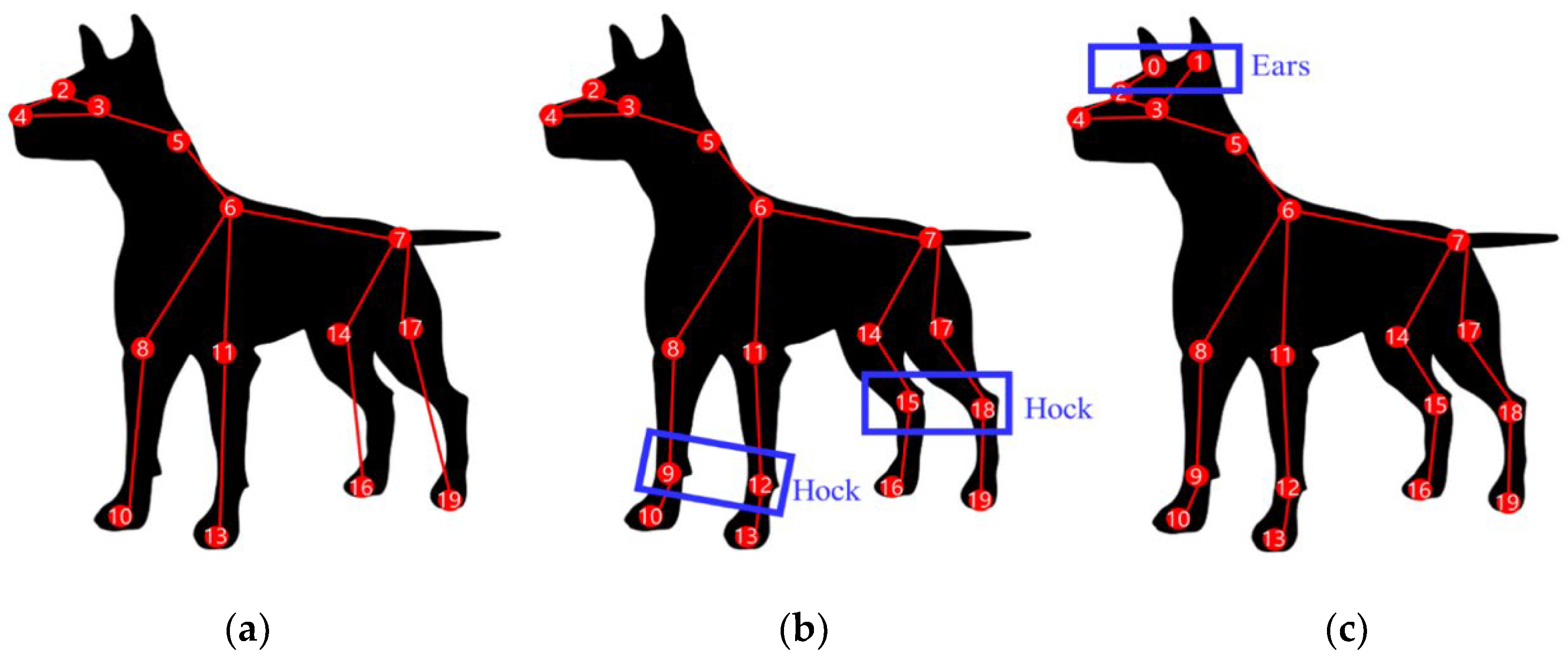
| Behaviors | Body Joints | Face Joints |
|---|---|---|
| Walking | front_right_wrist(9), front_left_wrist(12), back_left_paw(19) | right_eye(2), left_eye(3) |
| Standing Two legs | front_right_wrist(9), front_left_elbow(12) | right_ear(0), left_ear(1), left_eye(3) |
| Standing Four legs | front_right_elbow(8), front_right_wrist(9), front_left_elbow(11) | right_eye(2), left_eye(3) |
| Lying down | withers(6) | right_ear(0), left_ear(1), right_eye(2), left_eye(3) |
| Eating off ground | throat(5), withers(6), front_right_elbow(8), front_right_wrist(9) | left_ear(1) |
| Smelling | front_right_wrist(9) | right_ear(0), left_ear(1), right_eye(2), left_eye(3), |
| Convulsing | None | right_ear(0), left_ear(1), right_eye(2), left_eye(3), nose(4) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, H.-J.; Ihm, S.-Y.; Park, S.-H.; Park, Y.-H. An Analytic Method for Improving the Reliability of Models Based on a Histogram for Prediction of Companion Dogs’ Behaviors. Appl. Sci. 2021, 11, 11050. https://doi.org/10.3390/app112211050
Lee H-J, Ihm S-Y, Park S-H, Park Y-H. An Analytic Method for Improving the Reliability of Models Based on a Histogram for Prediction of Companion Dogs’ Behaviors. Applied Sciences. 2021; 11(22):11050. https://doi.org/10.3390/app112211050
Chicago/Turabian StyleLee, Hye-Jin, Sun-Young Ihm, So-Hyun Park, and Young-Ho Park. 2021. "An Analytic Method for Improving the Reliability of Models Based on a Histogram for Prediction of Companion Dogs’ Behaviors" Applied Sciences 11, no. 22: 11050. https://doi.org/10.3390/app112211050
APA StyleLee, H.-J., Ihm, S.-Y., Park, S.-H., & Park, Y.-H. (2021). An Analytic Method for Improving the Reliability of Models Based on a Histogram for Prediction of Companion Dogs’ Behaviors. Applied Sciences, 11(22), 11050. https://doi.org/10.3390/app112211050