
Continuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks



Abstract
:1. Introduction
2. Related Works
3. Spatiotemporal Models for Continuous Emotion Recognition
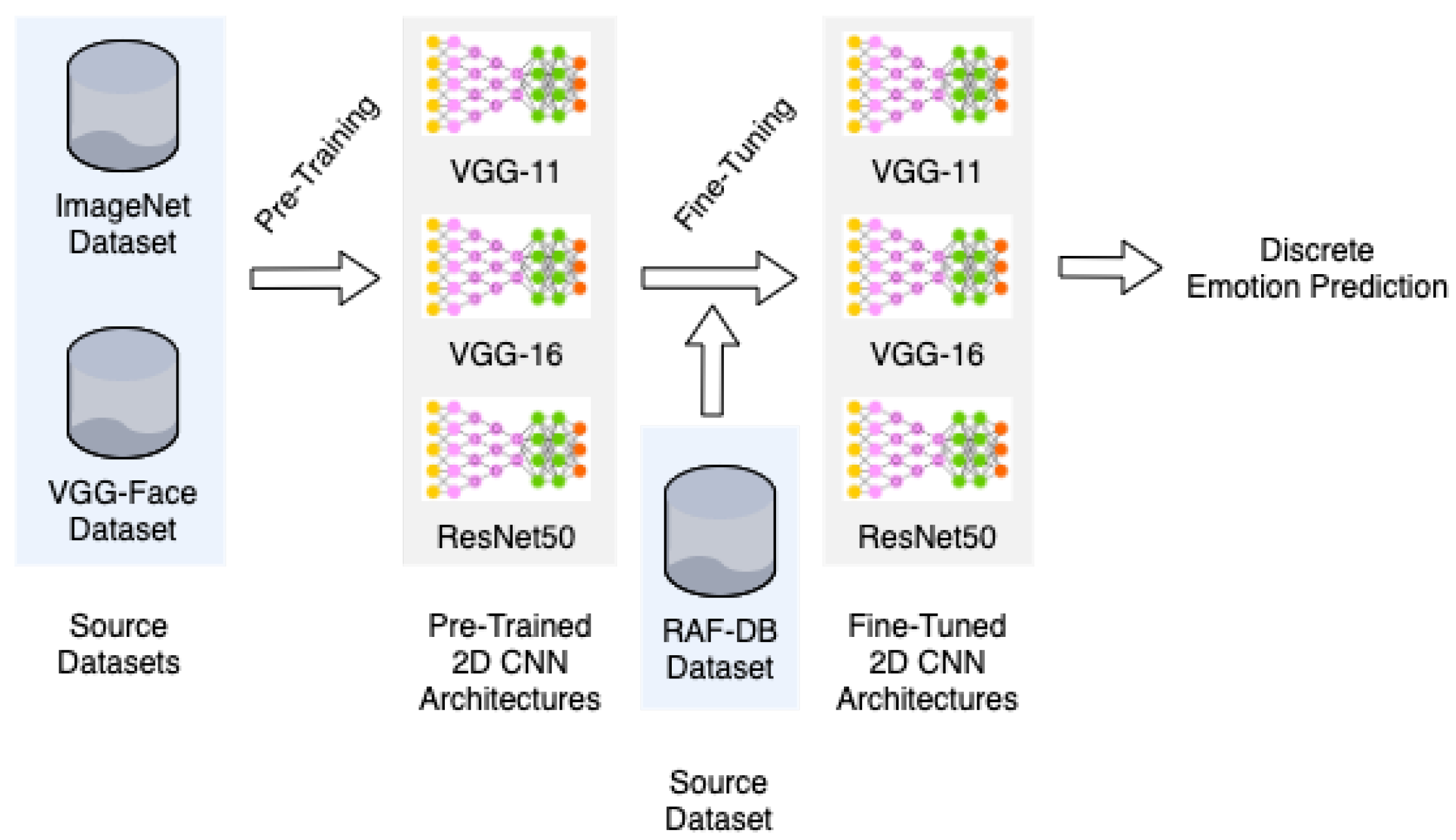
3.1. Pre-Training and Fine-Tuning of 2D CNNs
3.2. Pre-Processing
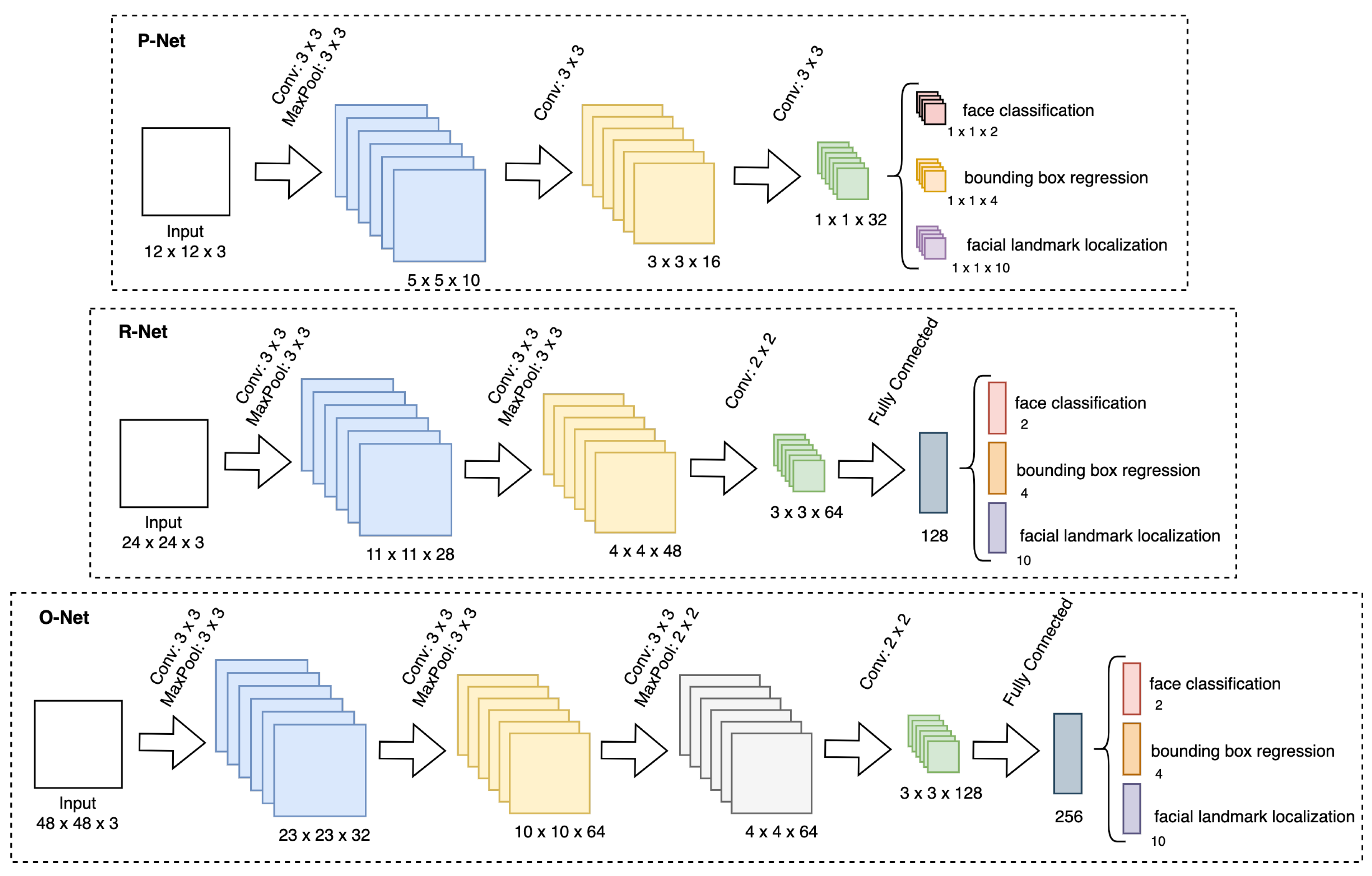
3.2.1. Frame and Face Extraction
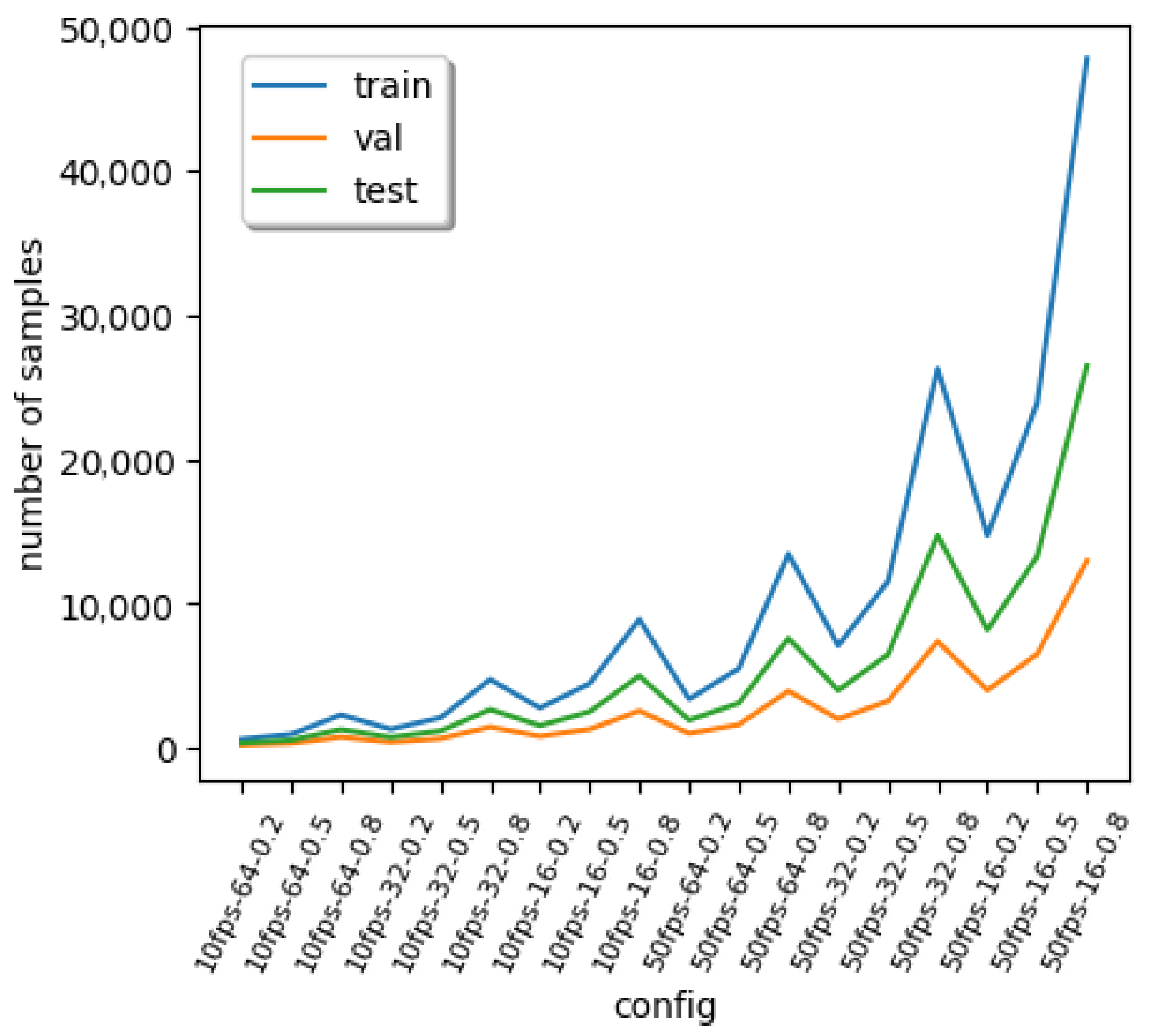
3.2.2. Sequence Learning
3.3. Spatiotemporal Models
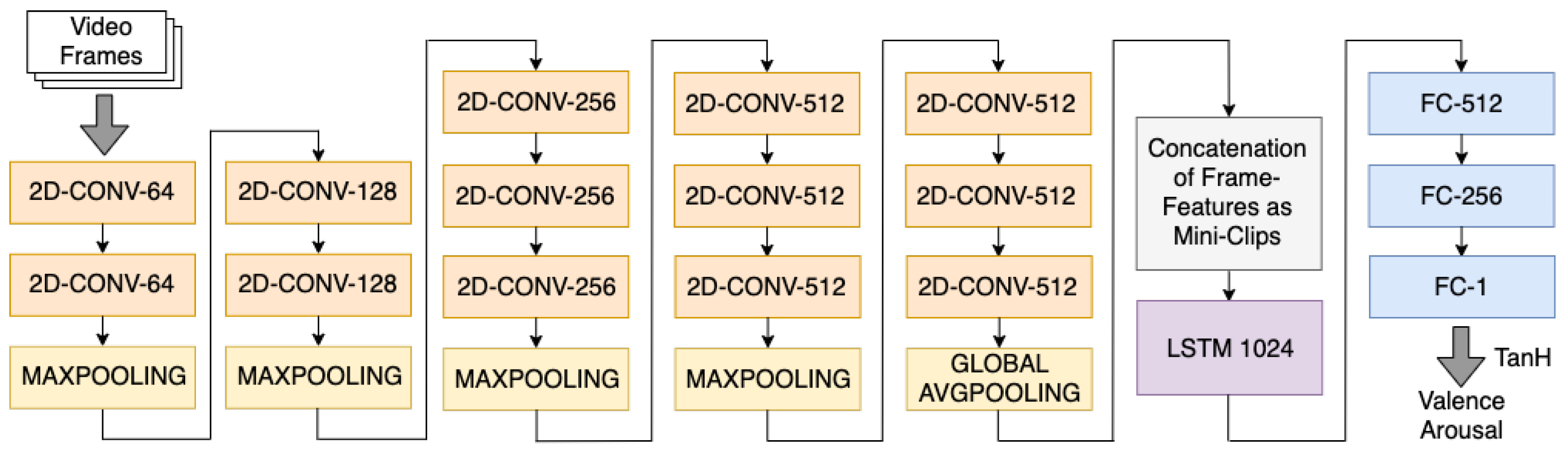
3.3.1. Cascaded Networks (2D CNN–LSTM)
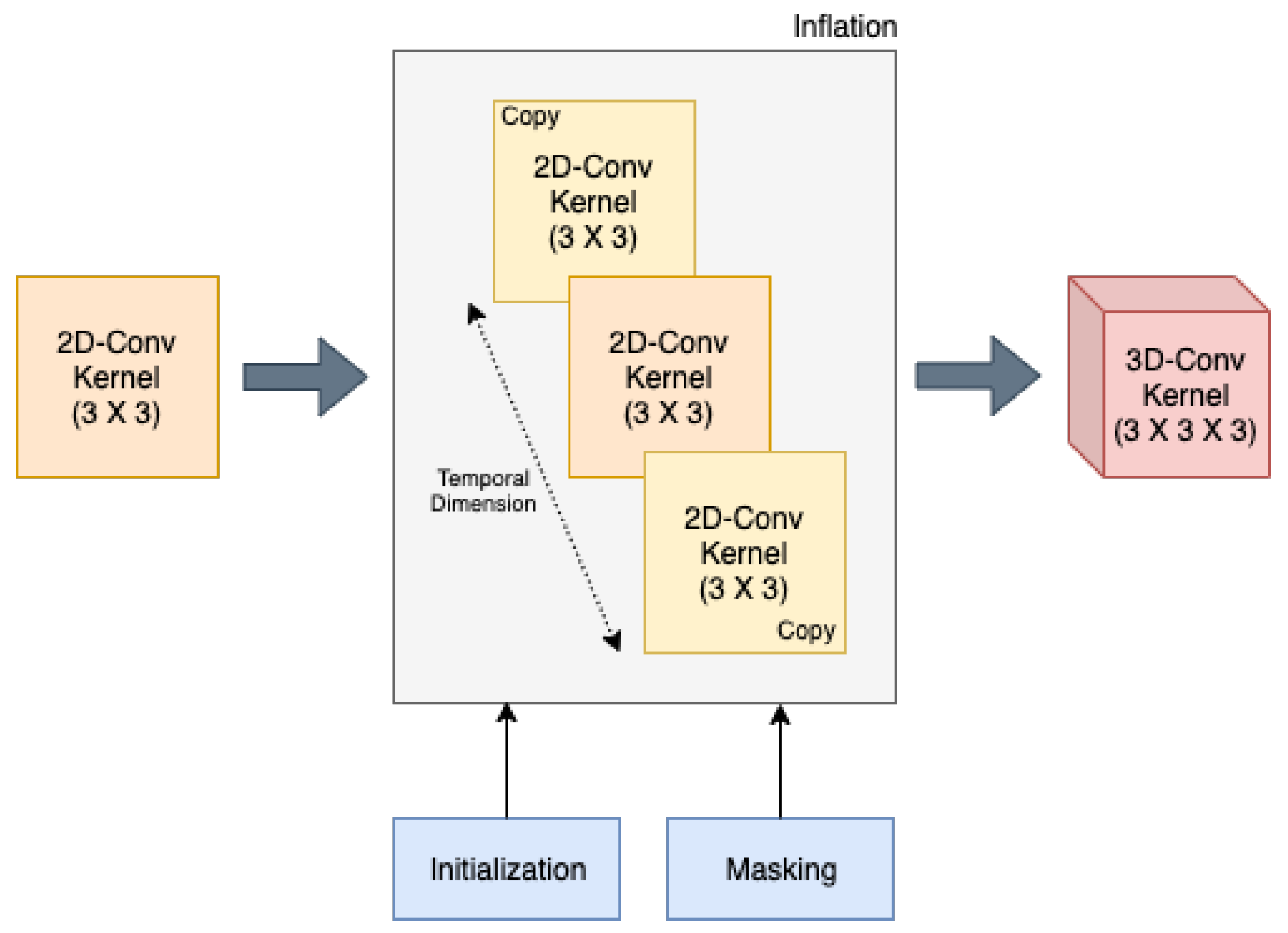
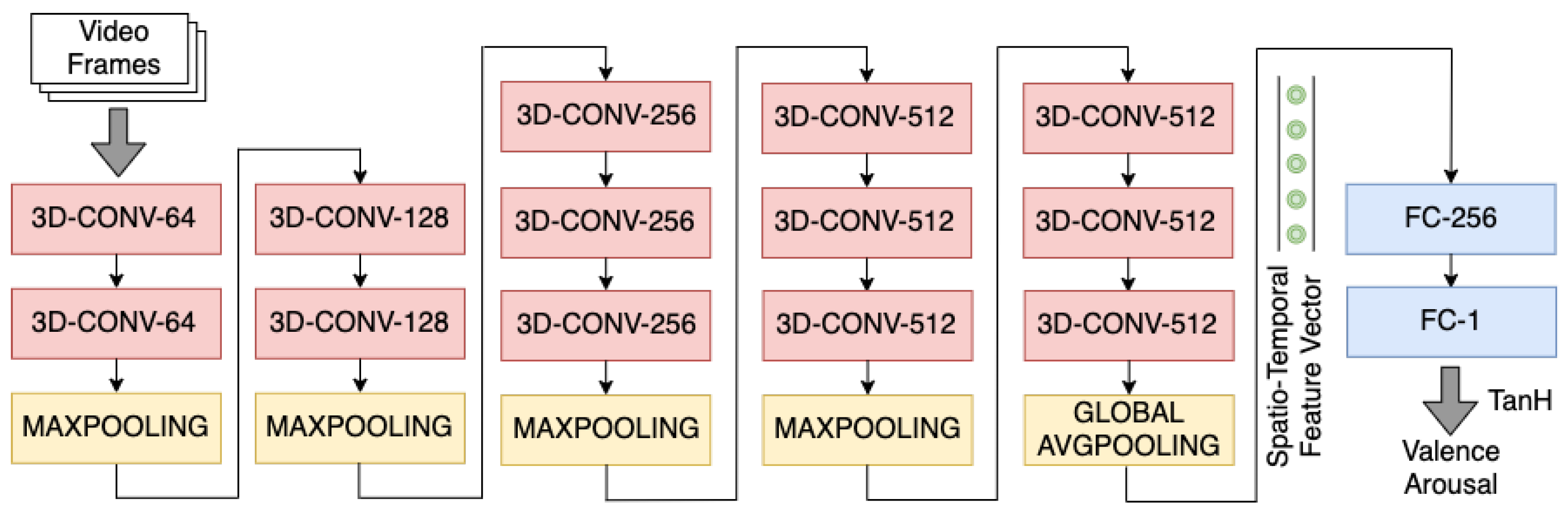
3.3.2. Inflated 3D CNN (i3D CNN)
3.4. Post-Processing
4. Experimental Results
4.1. Facial Expression Datasets
4.2. Performance Metrics
4.3. Training and Fine-Tuning 2D CNNs
4.4. 2D CNN–LSTM Architecture
4.5. i3D CNN Architecture
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Deng, W. Deep facial expression recognition: A survey. arXiv 2018, arXiv:1804.08348. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P. Strong evidence for universals in facial expressions: A reply to russell’s mistaken critique. Psychol. Bull. 1994, 115, 268–287. [Google Scholar] [CrossRef] [PubMed]
- Barrett, L.F.; Adolphs, R.; Marsella, S.; Martinez, A.M.; Pollak, S.D. Emotional Expressions Reconsidered: Challenges to Inferring Emotion From Human Facial Movements. Psychol. Sci. Public Interest 2019, 20, 1–68. [Google Scholar] [CrossRef] [Green Version]
- Barrett, L.F. AI weighs in on debate about universal facial expressions. Nature 2021, 589, 202–203. [Google Scholar] [CrossRef] [PubMed]
- Jack, R.E.; Garrod, O.G.; Yu, H.; Caldara, R.; Schyns, P.G. Facial expressions of emotion are not culturally universal. Proc Natl. Acad. Sci. USA 2012, 109, 7241–7244. [Google Scholar] [CrossRef] [PubMed] [Green Version]
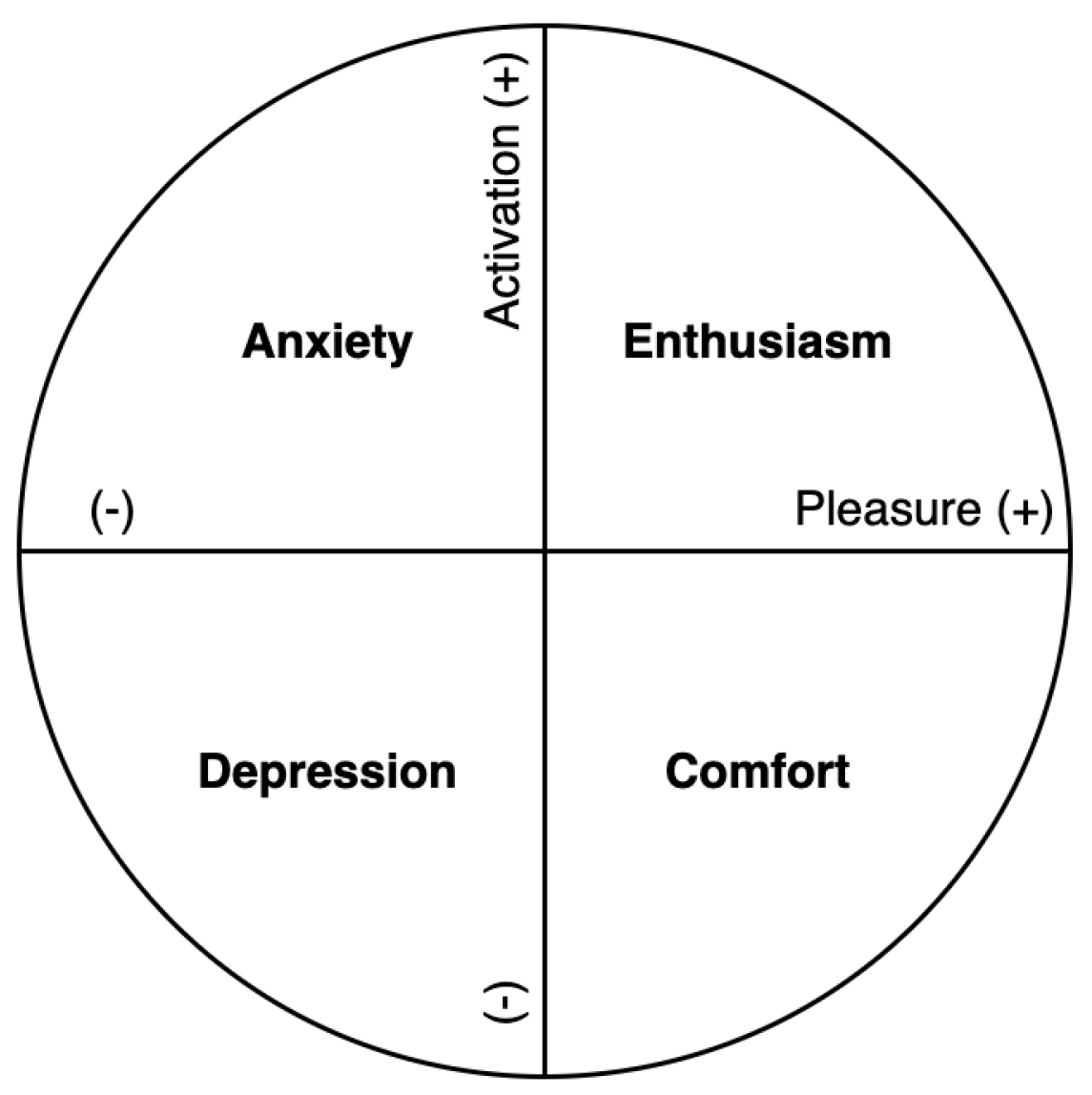
- Warr, P.; Bindl, U.; Parker, S.; Inceoglu, I. Four-quadrant investigation of job-related affects and behaviours. Eur. J. Work Organ. Psychol. 2014, 23, 342–363. [Google Scholar] [CrossRef] [Green Version]
- Oliveira, L.E.S.; Mansano, M.; Koerich, A.L.; de Souza Britto, A. 2D Principal Component Analysis for Face and Facial-Expression Recognition. Comput. Sci. Eng. 2011, 13, 9–13. [Google Scholar] [CrossRef] [Green Version]
- Zavaschi, T.H.H.; Koerich, A.L.; Oliveira, L.E.S. Facial expression recognition using ensemble of classifiers. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 1489–1492. [Google Scholar] [CrossRef] [Green Version]
- Shan, C.; Gong, S.; McOwan, P.W. Facial expression recognition based on local binary patterns: A comprehensive study. Image Vis. Comput. 2009, 27, 803–816. [Google Scholar] [CrossRef] [Green Version]
- Zavaschi, T.H.H.; Britto, A.S., Jr.; Oliveira, L.E.S.; Koerich, A.L. Fusion of feature sets and classifiers for facial expression recognition. Expert Syst. Appl. 2013, 40, 646–655. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikainen, M. Dynamic Texture Recognition Using Local Binary Patterns with an Application to Facial Expressions. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 915–928. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; See, J.; Phan, R.C.; Oh, Y. LBP with Six Intersection Points: Reducing Redundant Information in LBP-TOP for Micro-expression Recognition. In Proceedings of the 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2014; Volume 9003, pp. 525–537. [Google Scholar] [CrossRef]
- Cossetin, M.J.; Nievola, J.C.; Koerich, A.L. Facial Expression Recognition Using a Pairwise Feature Selection and Classification Approach. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 5149–5155. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.C.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.; et al. Challenges in Representation Learning: A Report on Three Machine Learning Contests. In Proceedings of the 20th International Conference Neural Information Processing, Daegu, Korea, 3–7 November 2013; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2013; Volume 8228, pp. 117–124. [Google Scholar] [CrossRef] [Green Version]
- Susskind, J.M.; Anderson, A.K.; Hinton, G.E. The Toronto Face Dataset; Technical Report TR 2010-001; U. Toronto: Toronto, ON, Canada, 2010. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Static facial expression analysis in tough conditions: Data, evaluation protocol and benchmark. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCV Workshops), Barcelona, Spain, 6–13 November 2011; pp. 2106–2112. [Google Scholar]
- Georgescu, M.I.; Ionescu, R.T.; Popescu, M. Local Learning With Deep and Handcrafted Features for Facial Expression Recognition. IEEE Access 2019, 7, 64827–64836. [Google Scholar] [CrossRef]
- Kim, B.K.; Lee, H.; Roh, J.; Lee, S.Y. Hierarchical Committee of Deep CNNs with Exponentially-Weighted Decision Fusion for Static Facial Expression Recognition. In Proceedings of the International Conference on Multimodal Interaction, ICMI ’15, Seattle, WA, USA, 9–13 November 2015; pp. 427–434. [Google Scholar] [CrossRef]
- Liu, X.; Kumar, B.V.K.V.; You, J.; Jia, P. Adaptive Deep Metric Learning for Identity-Aware Facial Expression Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 522–531. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Learning Social Relation Traits from Face Images. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3631–3639. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Tao, D.; Yu, J.; Xiong, H.; Li, Y. Deep Neural Networks with Relativity Learning for facial expression recognition. In Proceedings of the IEEE International Conference on Multimedia Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Kim, B.; Dong, S.; Roh, J.; Kim, G.; Lee, S. Fusing Aligned and Non-aligned Face Information for Automatic Affect Recognition in the Wild: A Deep Learning Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1499–1508. [Google Scholar]
- Pramerdorfer, C.; Kampel, M. Facial Expression Recognition using Convolutional Neural Networks: State of the Art. arXiv 2016, arXiv:1612.02903. [Google Scholar]
- Fayolle, S.L.; Droit-Volet, S. Time Perception and Dynamics of Facial Expressions of Emotions. PLoS ONE 2014, 9, e97944. [Google Scholar] [CrossRef] [Green Version]
- Bargal, S.A.; Barsoum, E.; Ferrer, C.C.; Zhang, C. Emotion Recognition in the Wild from Videos Using Images. In Proceedings of the International Conference on Multimodal Interaction, ICMI ’16, Tokyo, Japan, 12–16 November 2016; pp. 433–436. [Google Scholar] [CrossRef]
- Ding, W.; Xu, M.; Huang, D.Y.; Lin, W.; Dong, M.; Yu, X.; Li, H. Audio and Face Video Emotion Recognition in the Wild Using Deep Neural Networks and Small Datasets. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, ICMI ’16, Tokyo, Japan, 12–16 November 2016; pp. 506–513. [Google Scholar] [CrossRef]
- Ayral, T.; Pedersoli, M.; Bacon, S.; Granger, E. Temporal Stochastic Softmax for 3D CNNs: An Application in Facial Expression Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 5–9 January 2021. [Google Scholar]
- Carneiro de Melo, W.; Granger, E.; Hadid, A. A Deep Multiscale Spatiotemporal Network for Assessing Depression from Facial Dynamics. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.D.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef] [Green Version]
- Abbasnejad, I.; Sridharan, S.; Nguyen, D.; Denman, S.; Fookes, C.; Lucey, S. Using Synthetic Data to Improve Facial Expression Analysis with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 1609–1618. [Google Scholar]
- Fan, Y.; Lu, X.; Li, D.; Liu, Y. Video-Based Emotion Recognition Using CNN-RNN and C3D Hybrid Networks. In Proceedings of the International Conference on Multimodal Interaction, ICMI ’16, Tokyo, Japan, 12–16 November 2016; pp. 445–450. [Google Scholar] [CrossRef]
- Nguyen, D.; Nguyen, K.; Sridharan, S.; Ghasemi, A.; Dean, D.; Fookes, C. Deep Spatio-Temporal Features for Multimodal Emotion Recognition. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1215–1223. [Google Scholar]
- Liu, K.; Liu, W.; Gan, C.; Tan, M.; Ma, H. T-C3D: Temporal Convolutional 3D Network for Real-Time Action Recognition. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7138–7145. [Google Scholar]
- Barros, P.; Wermter, S. Developing crossmodal expression recognition based on a deep neural model. Adapt. Behav. 2016, 24, 373–396. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Mao, X.; Zhang, J. Learning deep facial expression features from image and optical flow sequences using 3D CNN. Vis. Comput. 2018, 34, 1461–1475. [Google Scholar] [CrossRef]
- Ouyang, X.; Kawaai, S.; Goh, E.; Shen, S.; Ding, W.; Ming, H.; Huang, D.Y. Audio-visual emotion recognition using deep transfer learning and multiple temporal models. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 577–582. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [Green Version]
- Vielzeuf, V.; Pateux, S.; Jurie, F. Temporal multimodal fusion for video emotion classification in the wild. In Proceedings of the 19th ACM International Conference on Multimodal Interaction (ICMI), Glasgow, UK, 13–17 November 2017; pp. 569–576. [Google Scholar] [CrossRef] [Green Version]
- Campos, V.; Salvador, A.; Giro-iNieto, X.; Jou, B. Diving deep into sentiment: Understanding fine-tuned CNNs for visual sentiment prediction. In Proceedings of the 1st International Workshop on Affect and Sentiment in Multimedia, Brisbane, Australia, 30 October 2015; pp. 57–62. [Google Scholar]
- Xu, C.; Cetintas, S.; Lee, K.C.; Li, L.J. Visual Sentiment Prediction with Deep Convolutional Neural Networks. arXiv 2014, arXiv:1411.5731. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; pp. 41.1–41.12. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Dhall, A.; Kaur, A.; Goecke, R.; Gedeon, T. EmotiW 2018: Audio-Video, Student Engagement and Group-Level Affect Prediction. In Proceedings of the International Conference on Multimodal Interaction (ICMI), Boulder, CO, USA, 16–20 October 2018; pp. 653–656. [Google Scholar] [CrossRef]
- Ringeval, F.; Schuller, B.; Valstar, M.; Jaiswal, S.; Marchi, E.; Lalanne, D.; Cowie, R.; Pantic, M. AV+EC 2015: The First Affect Recognition Challenge Bridging Across Audio, Video, and Physiological Data. In Proceedings of the 5th International Workshop on Audio/Visual Emotion Challenge, AVEC ’15, Brisbane, Australia, 26 October 2015; pp. 3–8. [Google Scholar] [CrossRef]
- Wan, L.; Liu, N.; Huo, H.; Fang, T. Face Recognition with Convolutional Neural Networks and subspace learning. In Proceedings of the 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 228–233. [Google Scholar]
- Knyazev, B.; Shvetsov, R.; Efremova, N.; Kuharenko, A. Convolutional neural networks pretrained on large face recognition datasets for emotion classification from video. arXiv 2017, arXiv:1711.04598. [Google Scholar]
- Ding, H.; Zhou, S.K.; Chellappa, R. FaceNet2ExpNet: Regularizing a Deep Face Recognition Net for Expression Recognition. In Proceedings of the 12th IEEE International Conference on Automatic Face & Gesture Recognition, Washington, DC, USA, 30 May–3 June 2017; pp. 118–126. [Google Scholar] [CrossRef] [Green Version]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef] [Green Version]
- Diba, A.; Fayyaz, M.; Sharma, V.; Karami, A.H.; Arzani, M.M.; Yousefzadeh, R.; Gool, L.V. Temporal 3D ConvNets: New Architecture and Transfer Learning for Video Classification. arXiv 2017, arXiv:1711.08200. [Google Scholar]
- Praveen, G.; Granger, E.; Cardinal, P. Deep DA for Ordinal Regression of Pain Intensity Estimation Using Weakly-Labeled Videos. arXiv 2020, arXiv:2010.15675. [Google Scholar]
- Praveen, G.; Granger, E.; Cardinal, P. Deep Weakly-Supervised Domain Adaptation for Pain Localization in Videos. In Proceedings of the 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 18–22 May 2020. [Google Scholar]
- Cardinal, P.; Dehak, N.; Koerich, A.L.; Alam, J.; Boucher, P. ETS System for AV+EC 2015 Challenge. In Proceedings of the ACM Multimedia Conference, Brisbane, Australia, 26–30 October 2015; pp. 17–23. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Kim, H.; Kim, Y.; Kim, S.J.; Lee, I. Building Emotional Machines: Recognizing Image Emotions through Deep Neural Networks. IEEE Trans. Multim. 2018, 20, 2980–2992. [Google Scholar] [CrossRef] [Green Version]
- Mou, W.; Celiktutan, O.; Gunes, H. Group-level arousal and valence recognition in static images: Face, body and context. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; Volume 5, pp. 1–6. [Google Scholar]
- Ben Henia, W.M.; Lachiri, Z. Emotion classification in arousal-valence dimension using discrete affective keywords tagging. In Proceedings of the International Conference on Engineering MIS (ICEMIS), Monastir, Tunisia, 8–10 May 2017; pp. 1–6. [Google Scholar]
- Kollias, D.; Zafeiriou, S. A Multi-component CNN-RNN Approach for Dimensional Emotion Recognition in-the-wild. arXiv 2018, arXiv:1805.01452. [Google Scholar]
- Kollias, D.; Tzirakis, P.; Nicolaou, M.A.; Papaioannou, A.; Zhao, G.; Schuller, B.; Kotsia, I.; Zafeiriou, S. Deep Affect Prediction in-the-Wild: Aff-Wild Database and Challenge, Deep Architectures, and Beyond. Int. J. Comput. Vis. 2019, 127, 907–929. [Google Scholar] [CrossRef] [Green Version]
- Kossaifi, J.; Schuller, B.W.; Star, K.; Hajiyev, E.; Pantic, M.; Walecki, R.; Panagakis, Y.; Shen, J.; Schmitt, M.; Ringeval, F.; et al. SEWA DB: A Rich Database for Audio-Visual Emotion and Sentiment Research in the Wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [Green Version]
- Cao, Q.; Shen, L.; Xie, W.; Parkhi, O.M.; Zisserman, A. VGGFace2: A Dataset for Recognising Faces across Pose and Age. In Proceedings of the 13th IEEE International Conference on Automatic Face & Gesture Recognition, Xi’an, China, 15–19 May 2018; pp. 67–74. [Google Scholar] [CrossRef] [Green Version]
- Jyoti, S.; Sharma, G.; Dhall, A. Expression Empowered ResiDen Network for Facial Action Unit Detection. In Proceedings of the 14th IEEE International Conference on Automatic Face & Gesture Recognition, Lille, France, 14–18 May 2019; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kaya, H.; Gürpınar, F.; Salah, A. Video-Based Emotion Recognition in the Wild using Deep Transfer Learning and Score Fusion. Image Vis. Comput. 2017, 65, 66–75. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Expression Recognition in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2584–2593. [Google Scholar]
- Li, S.; Deng, W. Reliable Crowdsourcing and Deep Locality-Preserving Learning for Unconstrained Facial Expression Recognition. IEEE Trans. Image Process. 2019, 28, 356–370. [Google Scholar] [CrossRef]
- Tannugi, D.L.; Britto, A.S., Jr.; Koerich, A.L. Memory Integrity of CNNs for Cross-Dataset Facial Expression Recognition. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3806–3811. [Google Scholar]
- Li, S.; Deng, W. A Deeper Look at Facial Expression Dataset Bias. IEEE Trans. Affect. Comput. 2020. [Google Scholar] [CrossRef] [Green Version]
- de Matos, J.; Britto, A.S., Jr.; Oliveira, L.E.S.; Koerich, A.L. Double Transfer Learning for Breast Cancer Histopathologic Image Classification. In Proceedings of the IEEE International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–6. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef] [Green Version]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Ortega, J.D.S.; Cardinal, P.; Koerich, A.L. Emotion Recognition Using Fusion of Audio and Video Features. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3827–3832. [Google Scholar]
- Li, Y.; Zeng, J.; Shan, S.; Chen, X. Occlusion Aware Facial Expression Recognition Using CNN With Attention Mechanism. IEEE Trans. Image Process. 2019, 28, 2439–2450. [Google Scholar] [CrossRef] [PubMed]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region Attention Networks for Pose and Occlusion Robust Facial Expression Recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, H.; Deng, Y.; Cheng, S.; Wang, Y.; Jiang, D.; Sahli, H. Efficient Spatial Temporal Convolutional Features for Audiovisual Continuous Affect Recognition. In Proceedings of the 9th International on Audio/Visual Emotion Challenge and Workshop, AVEC ’19, Nice, France, 21 October 2019; pp. 19–26. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Li, R.; Liang, J.; Chen, S.; Jin, Q. Adversarial Domain Adaption for Multi-Cultural Dimensional Emotion Recognition in Dyadic Interactions. In Proceedings of the 9th International on Audio/Visual Emotion Challenge and Workshop, AVEC ’19, Nice, France, 21 October 2019; pp. 37–45. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Model | Dataset for Pre-Training | Convolution Block | Accuracy (%) |
|---|---|---|---|---|
| Proposed | VGG-11 | ImageNet | Full Conv_2_1 Conv_3_1 Conv_4_1 Conv_5_1 | 75.6 75.9 75.9 75.9 70.3 |
| VGG-11-BN | ImageNet | Full | 77.8 | |
| VGG-16 | VGG-Face | Full Conv_2_1 Conv_3_1 Conv_4_1 Conv_5_1 | 78.5 78.5 79.1 79.9 74.4 | |
| VGG-16-BN | VGG-Face | Full | 78.4 | |
| ResNet50 | VGG-Face | Full Conv_4_1 Conv_5_1 | 79.7 78.0 65.1 | |
| Jyoti et al. [62] | RCNN | NA | NA | 76.5 |
| CNN | NA | NA | 78.2 | |
| Li et al. [73] | ACNN | ImageNet | NA | 85.1 |
| Wang et al. [74] | CNN+RAN | MS-Celeb-1M | NA | 86.9 |
|
Dataset for Initialization | Configuration | |||||
|---|---|---|---|---|---|---|
| fps | Label | (SL, OR, FM) | PCC↑ | CCC↑ | MAPE(%)↓ | |
| VGG-Face | 10 | Valence | 16, 0.2, extremum | 0.590 | 0.560 | 3.8 |
| Arousal | 16, 0.2, mean | 0.549 | 0.542 | 8.7 | ||
| 50 | Valence | 64, 0.2, mean | 0.541 | 0.511 | 6.8 | |
| Arousal | 64, 0.2, extremum | 0.495 | 0.492 | 3.4 | ||
| RAF-DB | 10 | Valence | 64, 0.8, mean | 0.631 | 0.625 | 3.7 |
| Arousal | 64, 0.8, extremum | 0.558 | 0.557 | 9.4 | ||
| 50 | Valence | 64, 0.2, mean | 0.582 | 0.568 | 8.2 | |
| Arousal | 64, 0.2, extremum | 0.517 | 0.517 | 4.4 | ||
| Parameters | C1 | C2 |
|---|---|---|
| Inflation | Centered | Copied |
| Weight Initialization | Random | Zero |
| Masking | No | Yes |
| Dilation | Bloc1: 1 Bloc2: 1 Bloc3: 1 Bloc4: 1 | Bloc1: 1 Bloc2: 2 Bloc3: 4 Bloc4: 8 |
| Multiplier | ×1 | ×100 |
| Parameters | ||||||
|---|---|---|---|---|---|---|
| Base Models | Dataset for Initialization | Models Inflation | Dilation | Masking | Initialization Centered Weights | Mult |
| VGG-11-BN | RAF-DB | Centered | I | No | Zero | ×1 |
| ImageNet | Copied | I | No | Zero | ×100 | |
| VGG-16 | VGG-Face | Centered | I | No | Random | ×1 |
| RAF-DB | Copied | I | No | Random | ×1 | |
| ImageNet | Centered | I | No | Random | ×1 | |
| VGG-16-BN | VGG-Face | Centered | I | No | Random | ×1 |
| RAF-DB | Copied | I | Yes | Random | ×1 | |
| ImageNet | Copied | I | No | Random | ×1 | |
| ResNet50 | VGG-Face | Centered | I | Yes | Zero | ×100 |
| RAF-DB | Copied | VIII | No | Zero | ×1 | |
| ImageNet | Centered | VIII | Yes | Zero | ×1 | |
| Parameters | ||||||
|---|---|---|---|---|---|---|
| Base Models | Dataset for Initialization | Inflation | Dilation | Masking | Initialization Centered Weights | Mult |
| VGG-11-BN | RAF-DB | Centered | I | No | Random | ×1 |
| ImageNet | Centered | VIII | No | Zero | ×1 | |
| VGG-16 | VGG-Face | Centered | I | No | Random | ×1 |
| RAF-DB | Copied | I | Yes | Random | ×100 | |
| ImageNet | Centered | I | No | Random | ×1 | |
| VGG-16-BN | VGG-Face | Centered | I | Yes | Random | ×1 |
| RAF-DB | Copied | I | No | Random | ×1 | |
| ImageNet | Centered | I | No | Zero | ×1 | |
| ResNet50 | VGG-Face | Copied | I | Yes | Zero | ×100 |
| RAF-DB | Centered | VIII | Yes | Zero | ×1 | |
| ImageNet | Centered | I | No | Zero | ×1 | |
| Valence | Arousal | ||||||
|---|---|---|---|---|---|---|---|
| Base Models | Dataset for Initialization | PCC↑ | CCC↑ | MAPE(%)↓ | PCC↑ | CCC↑ | MAPE(%)↓ |
| VGG-11-BN | RAF-DB | 0.035 | 0.018 | 2.9 | 0.359 | 0.348 | 8.1 |
| ImageNet | 0.040 | 0.025 | 4.2 | 0.342 | 0.203 | 3.0 | |
| VGG-16 | VGG-Face | 0.119 | 0.071 | 3.0 | 0.220 | 0.166 | 5.2 |
| RAF-DB | 0.036 | 0.028 | 3.5 | 0.242 | 0.119 | 4.6 | |
| ImageNet | 0.209 | 0.190 | 2.4 | 0.391 | 0.189 | 3.8 | |
| VGG-16-BN | VGG-Face | 0.203 | 0.105 | 3.6 | 0.347 | 0.304 | 5.3 |
| RAF-DB | 0.123 | 0.101 | 3.2 | 0.284 | 0.165 | 3.3 | |
| ImageNet | 0.346 | 0.304 | 5.6 | 0.382 | 0.326 | 5.3 | |
| ResNet50 | VGG-Face | 0.313 | 0.253 | 3.5 | 0.406 | 0.273 | 4.9 |
| RAF-DB | 0.113 | 0.063 | 2.9 | 0.262 | 0.207 | 4.9 | |
| ImageNet | 0.183 | 0.164 | 6.0 | 0.323 | 0.256 | 4.7 | |
| Valence | Arousal | ||||
|---|---|---|---|---|---|
| Reference | Model | PCC↑ | CCC↑ | PCC↑ | CCC↑ |
| Proposed | 2D-CNN-LSTM | 0.631 | 0.625 | 0.558 | 0.557 |
| i3D-CNN | 0.346 | 0.304 | 0.382 | 0.326 | |
| Kossaifi et al. [60] | SVR | 0.321 | 0.312 | 0.182 | 0.202 |
| RF | 0.268 | 0.207 | 0.181 | 0.123 | |
| LSTM | 0.322 | 0.281 | 0.173 | 0.115 | |
| ResNet18 (RMSE) | 0.290 | 0.270 | 0.130 | 0.110 | |
| ResNet18 (CCC) | 0.350 | 0.350 | 0.350 | 0.290 | |
| Chen et al. [75] ⋆ | ST-GCN | NA | 0.540 | NA | 0.581 |
| Zhao et al. [76] ⋆ | DenseNet-style CNN | NA | 0.580 | NA | 0.594 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Teixeira, T.; Granger, É.; Lameiras Koerich, A. Continuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks. Appl. Sci. 2021, 11, 11738. https://doi.org/10.3390/app112411738
Teixeira T, Granger É, Lameiras Koerich A. Continuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks. Applied Sciences. 2021; 11(24):11738. https://doi.org/10.3390/app112411738
Chicago/Turabian StyleTeixeira, Thomas, Éric Granger, and Alessandro Lameiras Koerich. 2021. "Continuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks" Applied Sciences 11, no. 24: 11738. https://doi.org/10.3390/app112411738
APA StyleTeixeira, T., Granger, É., & Lameiras Koerich, A. (2021). Continuous Emotion Recognition with Spatiotemporal Convolutional Neural Networks. Applied Sciences, 11(24), 11738. https://doi.org/10.3390/app112411738