
Multimodal Interaction Systems Based on Internet of Things and Augmented Reality: A Systematic Literature Review




Abstract
:1. Introduction
2. Background
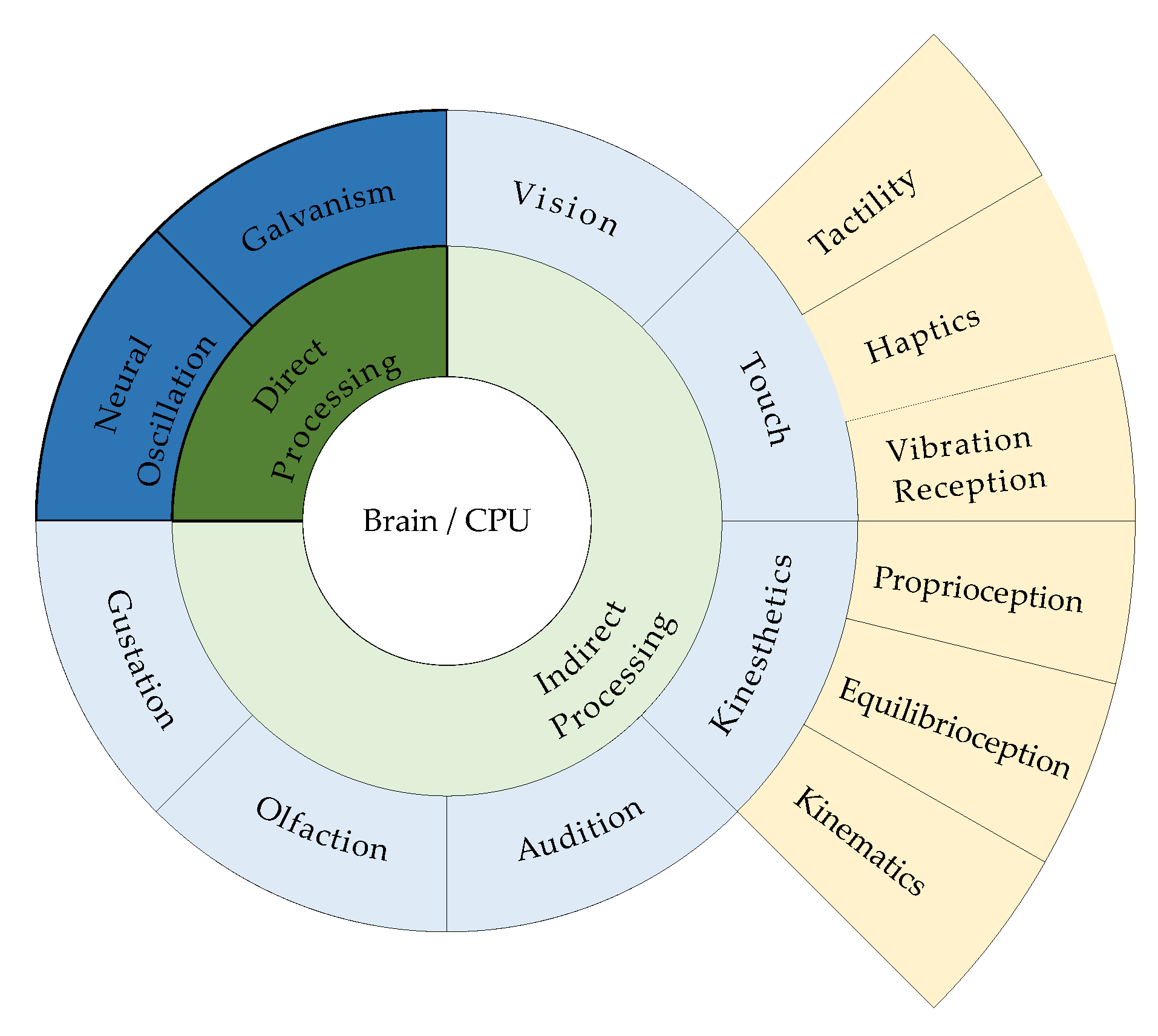
2.1. Terminology
2.2. Related Research
3. Methodology
3.1. Planning the Review
3.1.1. RQ 1. Which Modalities Are Used in MI Systems with IoT and AR?
3.1.2. RQ 2. Which Modalities Are Used in MI Systems with IoT and AR?
3.1.3. RQ 3. Which Modalities Are Used in MI Systems with IoT and AR?
3.1.4. RQ 4. Which Modalities Are Used in MI systems with IoT and AR?
3.1.5. RQ 5. Which Modalities Are Used in MI Systems with IoT and AR?
- ACM Digital Library
- Google Scholar
- IEEE Xplore
- ScienceDirect
- Scopus
- SpringerLink
- Taylor & Francis Online
- Interacting with Computers
- Journal on Multimodal User Interfaces
- We included studies that used MR instead of AR, because both technologies overlay virtual content on a real-world view.
- We excluded studies that did not have a practical implementation, as we only considered systems whose feasibility was validated by implementation.
- We excluded studies that used virtual reality (VR) instead of AR/MR, because VR separates users from the real-world, thus providing a different experience than AR and MR. As a result, the interaction methods that are based on dedicated modalities, such as motion controllers for a VR HMD, are not compatible with any modalities in current AR or MR environments.
- We excluded studies that did not provide sufficient implementation details of their MI systems for proper analysis.
3.2. Conducting the Review
3.2.1. Identification of Studies: Initial Literature Search and First Pass
3.2.2. Selection of Primary Studies: Second Pass and Quality Assessment
3.2.3. Data Extraction and Synthesis
4. Results
4.1. Statistics
4.1.1. Database Distribution
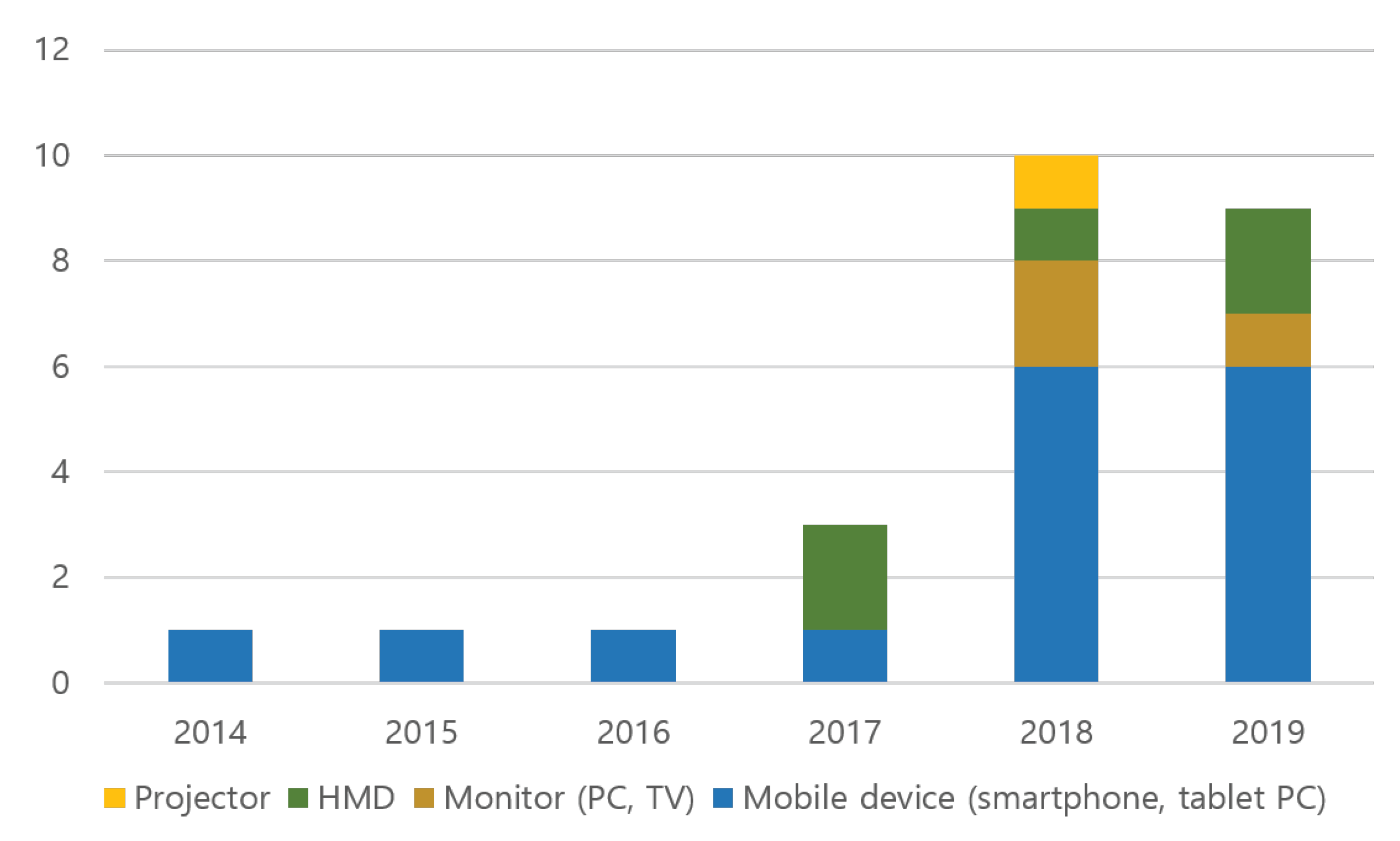
4.1.2. Yearly Distribution
4.1.3. Output Device Distribution
4.2. MI System Architectures
4.2.1. AR for Data Presentation
4.2.2. AR as an Interface
4.2.3. Markerless (Without Identifier) AR
4.2.4. Usage Ratio
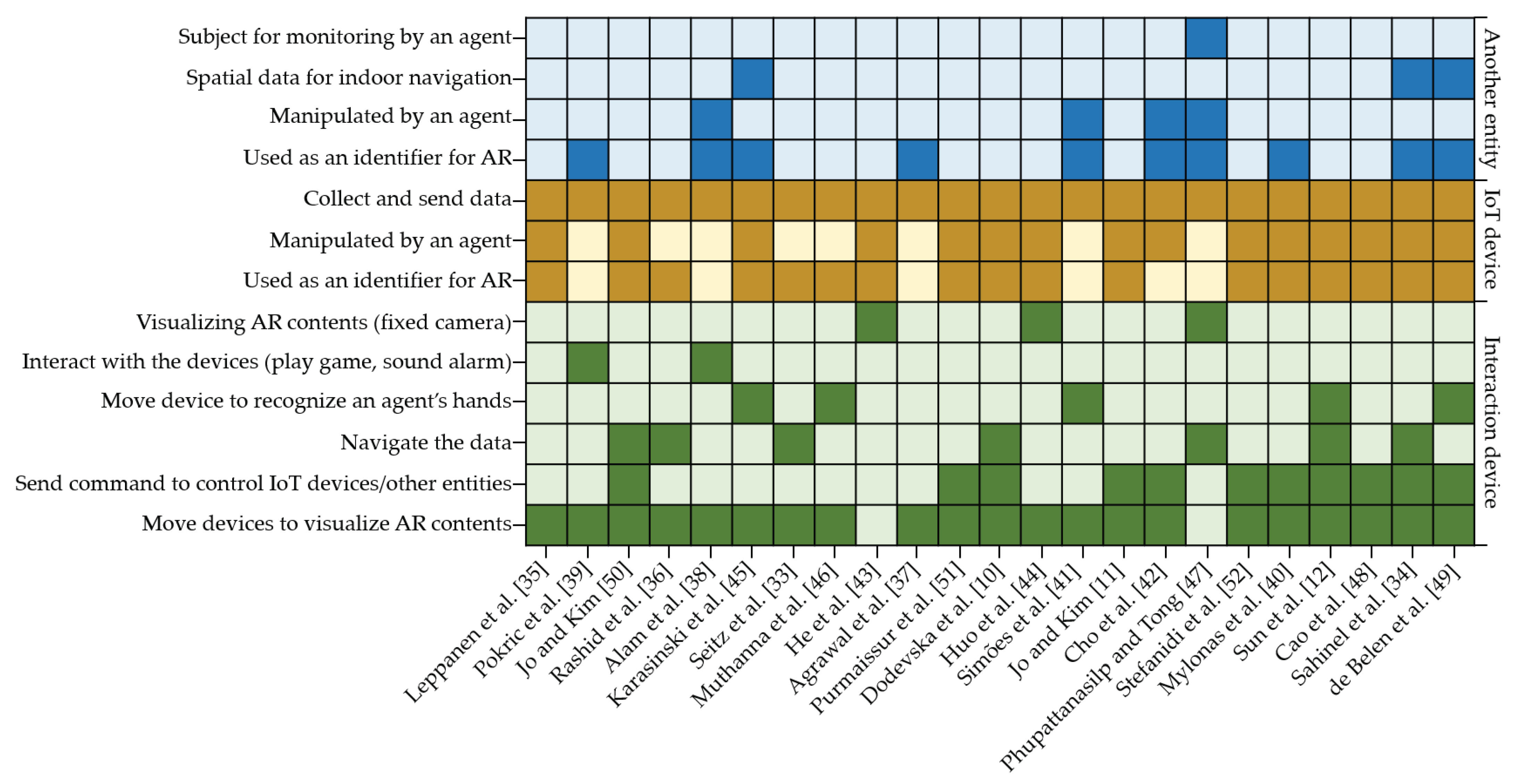
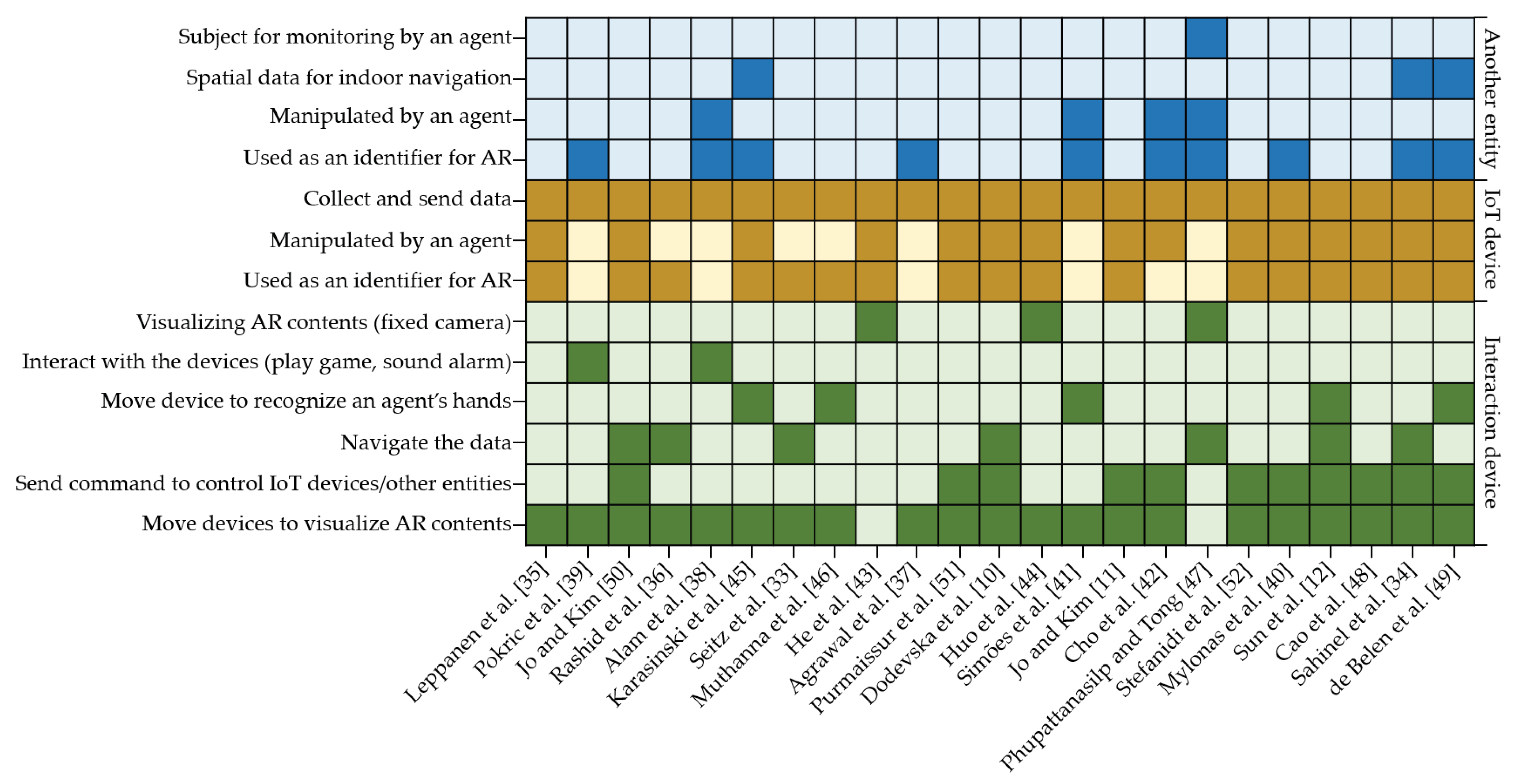
4.3. Interaction with an Agent
4.3.1. Interaction Devices
4.3.2. IoT Devices
4.3.3. Another Entity
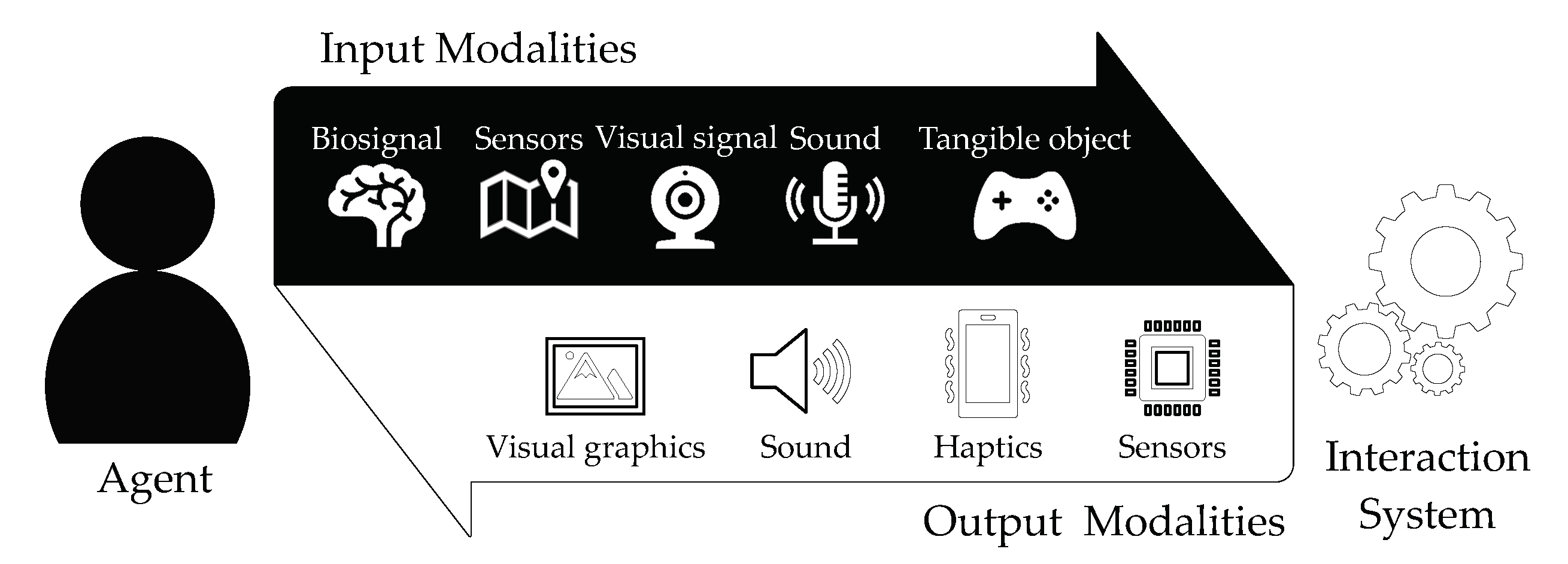
4.4. Modalities
4.4.1. Input
4.4.2. Output
4.4.3. Combinations
4.5. Open Research Challenges
4.6. Summary of Reviewed Studies
5. Discussion
5.1. RQ 1. Which Modalities Are Used in MI Systems with IoT and AR?
5.2. RQ 2. Which Modality Combinations Are Used in MI Systems with IoT and AR?
5.3. RQ 3. How Are IoT and AR Used in MI Systems?
5.4. RQ 4. Which Architectures Are Used to Construct MI Systems with IoT and AR?
5.5. RQ 5. Which Open Research Challenges Remain in MI Systems with IoT and AR?
- (1)
- Solutions to the identified research challenges that were related to hardware and technical limitations generally involve the development of technology and hardware. For example, the limited field of view in HoloLens, as noted by Karasinski et al. [45], has been solved in HoloLens 2, which has a larger field of view than the original HoloLens (i.e., 30° in HoloLens versus 52° in HoloLens 2). As another example, instability in vision-based tracking of object features caused by insufficient features can be corrected by a tracking recovery process [48]. These types of research challenges rely on the development of technology unless alternative approaches are developed.
- (2)
- The standardization of MI systems is key in achieving high scalability [11,50]. When MI system developers begin to use unified forms of both software components (e.g., data structures, data communication protocols, and UI structures) and hardware components, MI systems will gain the ability to handle different types of IoT devices, interaction devices, and interaction modalities while being able to communicate with other MI systems. Therefore, standardized MI system development can reduce the burden on MI system developers, who must otherwise consider the diversity of IoT devices, interaction devices, and interaction modalities when building an MI system for use in a real scenario outside the testbed.
- (3)
- Scalability is a research challenge that must be solved to establish a large-scale environment that can manage multiple types of IoT devices and agents that are easily and automatically registered. The absence of standardized data structures for IoT devices is the reason for the difficulty of this research challenge. Moreover, the increase in the number of IoT devices in MI systems may lead to significant computational costs on central servers. These challenges can occur when adding not only IoT devices, but also input/output modalities and interaction devices to MI systems. Therefore, considering the technology added to standardized MI systems is essential in achieving scalability.
- (4)
- A multi-agent scenario is another critical case that MI system developers must take into account to achieve not only high scalability, but also high QoE. In the multi-agent scenario, the MI system must manage all interaction devices while maintaining quality of service, such as timely synchronization of data to all agents [44]. Moreover, the diversity of interaction devices and UIs can also enhance the QoE because agents have different preferences. The development of adaptive UIs is a challenge that can achieve a personalized experience for agents by providing customized interaction modalities, context-aware feedback, and even offering a specific interaction device, depending on the agent’s preferences. Our findings suggested that 12 of the 23 reviewed studies conducted a user evaluation regarding usability and/or QoE. However, none of the reviewed studies evaluated their MI system in a multi-agent scenario. This indicates that an in-depth study of the on QoE of an MI system in the context of multiple agents is essential.
- (5)
- The research challenges in the multidisciplinary category demonstrate the importance of collaboration with different disciplines. This importance can be observed, even in the development of MI systems utilizing AR without IoT [63]. The development of an MI system requires understanding the relevant technology and content to achieve a sufficient degree of QoE. For example, the use of emojis by Seitz et al. [33] to represent the state of IoT devices require psychological knowledge to avoid unintended results on various agents with different cultural backgrounds. In another study, He et al. [43] developed a smartboard to measure the state of an agent’s upper limb in order to support a doctor’s diagnosis. However, their MI system was not evaluated with real patients with upper limb disorders; thus, the effectiveness of their MI system must be reevaluated. This requires collaboration with an expert who is familiar with the technology and subjects that the MI system is used for.
- We identified missing modalities and modality combinations that have not yet been tested in MI systems that use AR and IoT.
- We proposed unexplored ways of using AR and IoT within an MI system.
- We described patterns of MI system architectures that other developers can refer to in designing their MI systems.
- We discussed open research challenges that can be considered in future research.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MI | Multimodal Interaction |
| IoT | Internet of Things |
| ICT | Information and Communication Technologies |
| AR | Augmented Reality |
| HMD | Head-mounted Display |
| UI | User Interface |
| QoE | Quality of Experience |
| HCI | Human-computer Interaction |
| ISO | International Organization for Standardization |
| MR | Mixed Reality |
| VR | Virtual Reality |
| 2D | Two-dimensional |
| 3D | Three-dimensional |
| LED | Light-emitting diode |
References
- Oviatt, S. Multimodal interfaces. In The Human-Computer Interaction Handbook: Fundamentals, Evolving Technologies and Emerging Applications, 2nd ed.; L. Erlbaum Associates Inc.: Mahwah, NJ, USA, 2003; Volume 14, pp. 286–304. [Google Scholar]
- Alam, M.R.; Reaz, M.B.I.; Ali, M.A.M. A Review of Smart Homes—Past, Present, and Future. IEEE Trans. Syst. Man, Cybern. Part C (Appl. Rev.) 2012, 42, 1190–1203. [Google Scholar] [CrossRef]
- Gharaibeh, A.; Salahuddin, M.A.; Hussini, S.J.; Khreishah, A.; Khalil, I.; Guizani, M.; Al-Fuqaha, A. Smart Cities: A Survey on Data Management, Security, and Enabling Technologies. IEEE Commun. Surv. Tutor. 2017, 19, 2456–2501. [Google Scholar] [CrossRef]
- Wang, J.; Liu, J.; Kato, N. Networking and Communications in Autonomous Driving: A Survey. IEEE Commun. Surv. Tutor. 2019, 21, 1243–1274. [Google Scholar] [CrossRef]
- Jaimes, A.; Sebe, N. Multimodal human–computer interaction: A survey. Comput. Vis. Image Underst. 2007, 108, 116–134. [Google Scholar] [CrossRef]
- Turk, M. Multimodal interaction: A review. Pattern Recognit. Lett. 2014, 36, 189–195. [Google Scholar] [CrossRef]
- Patel, K.K.; Patel, S.M.; Scholar, P. Internet of Things-IOT: Definition, Characteristics, Architecture, Enabling Technologies, Application & Future Challenges. Int. J. Eng. Sci. Comput. 2016, 6, 10. [Google Scholar]
- Nižetić, S.; Šolić, P.; López-de-Ipiña González-de Artaza, D.; Patrono, L. Internet of Things (IoT): Opportunities, issues and challenges towards a smart and sustainable future. J. Clean. Prod. 2020, 274, 122877. [Google Scholar] [CrossRef]
- Bhargava, M.; Dhote, P.; Srivastava, A.; Kumar, A. Speech enabled integrated AR-based multimodal language translation. In Proceedings of the 2016 Conference on Advances in Signal Processing (CASP), Pune, India, 9–11 June 2016; IEEE: New York, NY, USA, 2016; pp. 226–230. [Google Scholar] [CrossRef]
- Dodevska, Z.A.; Kvrgić, V.; Štavljanin, V. Augmented Reality and Internet of Things – Implementation in Projects by Using Simplified Robotic Models. Eur. Proj. Manag. J. 2018, 8, 27–35. [Google Scholar] [CrossRef]
- Jo, D.; Kim, G.J. IoT + AR: Pervasive and augmented environments for “Digi-log” shopping experience. Hum.-Centric Comput. Inf. Sci. 2019, 9. [Google Scholar] [CrossRef]
- Sun, Y.; Armengol-Urpi, A.; Reddy Kantareddy, S.N.; Siegel, J.; Sarma, S. MagicHand: Interact with IoT Devices in Augmented Reality Environment. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019; IEEE: New York, NY, USA, 2019; pp. 1738–1743. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, S.; Dong, H.; El Saddik, A. Visualizing Toronto City Data with HoloLens: Using Augmented Reality for a City Model. IEEE Consum. Electron. Mag. 2018, 7, 73–80. [Google Scholar] [CrossRef]
- Hadj Sassi, M.S.; Chaari Fourati, L. Architecture for Visualizing Indoor Air Quality Data with Augmented Reality Based Cognitive Internet of Things. In Advanced Information Networking and Applications; Barolli, L., Amato, F., Moscato, F., Enokido, T., Takizawa, M., Eds.; Series: Advances in Intelligent Systems and Computing; Springer International Publishing: Cham, Switzerland, 2020; Volume 1151, pp. 405–418. [Google Scholar] [CrossRef]
- Mathews, N.S.; Chimalakonda, S.; Jain, S. AiR—An Augmented Reality Application for Visualizing Air Pollution. arXiv 2020, arXiv:2006.02136. [Google Scholar]
- White, G.; Cabrera, C.; Palade, A.; Clarke, S. Augmented Reality in IoT. In Service-Oriented Computing—ICSOC 2018 Workshops; Liu, X., Mrissa, M., Zhang, L., Benslimane, D., Ghose, A., Wang, Z., Bucchiarone, A., Zhang, W., Zou, Y., Yu, Q., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11434, pp. 149–160. [Google Scholar] [CrossRef]
- Jo, D.; Kim, G.J. AR Enabled IoT for a Smart and Interactive Environment: A Survey and Future Directions. Sensors 2019, 19, 4330. [Google Scholar] [CrossRef] [Green Version]
- Blackler, A.; Popovic, V.; Mahar, D. Investigating users’ intuitive interaction with complex artefacts. Appl. Ergon. 2010, 41, 72–92. [Google Scholar] [CrossRef] [Green Version]
- Hogan, T.; Hornecker, E. Towards a Design Space for Multisensory Data Representation. Interact. Comput. 2016. [Google Scholar] [CrossRef]
- Liang, R.; Liang, B.; Wang, X.; Zhang, T.; Li, G.; Wang, K. A Review of Multimodal Interaction. In Proceedings of the 2016 International Conference on Education, Management, Computer and Society, Shenyang, China, 1–3 January 2016; Atlantis Press: Amsterdam, The Netherlands, 2016. [Google Scholar] [CrossRef] [Green Version]
- Badouch, A.; Krit, S.D.; Kabrane, M.; Karimi, K. Augmented Reality services implemented within Smart Cities, based on an Internet of Things Infrastructure, Concepts and Challenges: An overview. In Proceedings of the Fourth International Conference on Engineering & MIS 2018—ICEMIS ’18, Istanbul, Turkey, 19–21 June 2018; ACM Press: New York, NY, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Norouzi, N.; Bruder, G.; Belna, B.; Mutter, S.; Turgut, D.; Welch, G. A Systematic Review of the Convergence of Augmented Reality, Intelligent Virtual Agents, and the Internet of Things. In Artificial Intelligence in IoT; Al-Turjman, F., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 1–24. [Google Scholar] [CrossRef]
- Picard, R.W. Affective Computing, 1st paperback ed.; OCLC: 247967780; The MIT Press: Cambridge, MA, USA; London, UK, 2000. [Google Scholar]
- ISO. Ergonomics of Human-System Interaction—Part 11: Usability: Definitions and Concepts; ISO 9241-11:2018(en); ISO: Geneva, Switzerland, 2018. [Google Scholar]
- ISO. Information Technology—Future Network—Problem Statement and Requirements—Part 6: Media Transport; ISO/IEC TR 29181-6:2013(en); ISO: Geneva, Switzerland, 2013. [Google Scholar]
- ITU. P.10: Vocabulary for Performance, Quality of Service and Quality of Experience; ITU: Geneva, Switzerland, 2017. [Google Scholar]
- Sánchez, J.; Saenz, M.; Garrido, J.M. Usability of a Multimodal Video Game to Improve Navigation Skills for Blind Children. ACM Trans. Access. Comput. 2010, 3, 1–29. [Google Scholar] [CrossRef]
- Blattner, M.; Glinert, E. Multimodal integration. IEEE Multimed. 1996, 3, 14–24. [Google Scholar] [CrossRef]
- Augstein, M.; Neumayr, T. A Human-Centered Taxonomy of Interaction Modalities and Devices. Interact. Comput. 2019, 31, 27–58. [Google Scholar] [CrossRef]
- Nizam, S.S.M.; Abidin, R.Z.; Hashim, N.C.; Chun, M.; Arshad, H.; Majid, N.A.A. A Review of Multimodal Interaction Technique in Augmented Reality Environment. Int. J. Adv. Sci. Eng. Inf. Technol. 2018, 8. [Google Scholar] [CrossRef] [Green Version]
- Mohamad Yahya Fekri, A.; Ajune Wanis, I. A review on multimodal interaction in Mixed Reality Environment. IOP Conf. Ser. Mater. Sci. Eng. 2019, 551, 012049. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report; Keele University: Keele, UK, 2007. [Google Scholar]
- Seitz, A.; Henze, D.; Nickles, J.; Sauer, M.; Bruegge, B. Augmenting the industrial Internet of Things with Emojis. In Proceedings of the 2018 Third International Conference on Fog and Mobile Edge Computing (FMEC), Barcelona, Spain, 23–26 April 2018; IEEE: New York, NY, USA, 2018; pp. 240–245. [Google Scholar] [CrossRef]
- Sahinel, D.; Akpolat, C.; Gorur, O.C.; Sivrikaya, F. Integration of Human Actors in IoT and CPS Landscape. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019; IEEE: New York, NY, USA, 2019; pp. 485–490. [Google Scholar] [CrossRef]
- Leppanen, T.; Heikkinen, A.; Karhu, A.; Harjula, E.; Riekki, J.; Koskela, T. Augmented Reality Web Applications with Mobile Agents in the Internet of Things. In Proceedings of the 2014 Eighth International Conference on Next Generation Mobile Apps, Services and Technologies, Oxford, UK, 10–12 September 2014; IEEE: New York, NY, USA, 2014; pp. 54–59. [Google Scholar] [CrossRef]
- Rashid, Z.; Melià-Seguí, J.; Pous, R.; Peig, E. Using Augmented Reality and Internet of Things to improve accessibility of people with motor disabilities in the context of Smart Cities. Future Gener. Comput. Syst. 2017, 76, 248–261. [Google Scholar] [CrossRef] [Green Version]
- Agrawal, D.; Mane, S.B.; Pacharne, A.; Tiwari, S. IoT Based Augmented Reality System of Human Heart: An Android Application. In Proceedings of the 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–12 May 2018; IEEE: New York, NY, USA, 2018; pp. 899–902. [Google Scholar] [CrossRef]
- Alam, M.F.; Katsikas, S.; Beltramello, O.; Hadjiefthymiades, S. Augmented and virtual reality based monitoring and safety system: A prototype IoT platform. J. Netw. Comput. Appl. 2017, 89, 109–119. [Google Scholar] [CrossRef]
- Pokric, B.; Krco, S.; Drajic, D.; Pokric, M.; Rajs, V.; Mihajlovic, Z.; Knezevic, P.; Jovanovic, D. Augmented Reality Enabled IoT Services for Environmental Monitoring Utilising Serious Gaming Concept. J. Wirel. Mob. Netw. Ubiquitous Comput. Dependable Appl. 2015, 6, 37–55. [Google Scholar]
- Mylonas, G.; Triantafyllis, C.; Amaxilatis, D. An Augmented Reality Prototype for supporting IoT-based Educational Activities for Energy-efficient School Buildings. Electron. Notes Theor. Comput. Sci. 2019, 343, 89–101. [Google Scholar] [CrossRef]
- Simões, B.; De Amicis, R.; Barandiaran, I.; Posada, J. X-Reality System Architecture for Industry 4.0 Processes. Multimodal Technol. Interact. 2018, 2, 72. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Jang, H.; Park, L.W.; Kim, S.; Park, S. Energy Management System Based on Augmented Reality for Human-Computer Interaction in a Smart City. In Proceedings of the 2019 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–13 January 2019; IEEE: New York, NY, USA, 2019; pp. 1–3. [Google Scholar] [CrossRef]
- He, Y.; Sawada, I.; Fukuda, O.; Shima, R.; Yamaguchi, N.; Okumura, H. Development of an evaluation system for upper limb function using AR technology. In Proceedings of the Genetic and Evolutionary Computation Conference Companion on—GECCO’18, Kyoto, Japan, 15–19 July 2018; ACM Press: New York, NY, USA, 2018; pp. 1835–1840. [Google Scholar] [CrossRef]
- Huo, K.; Cao, Y.; Yoon, S.H.; Xu, Z.; Chen, G.; Ramani, K. Scenariot: Spatially Mapping Smart Things Within Augmented Reality Scenes. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems—CHI’18, Montreal QC, Canada, 21–26 April 2018; ACM Press: New York, NY, USA, 2018; pp. 1–13. [Google Scholar] [CrossRef]
- Karasinski, J.A.; Joyce, R.; Carroll, C.; Gale, J.; Hillenius, S. An Augmented Reality/Internet of Things Prototype for Just-in-time Astronaut Training. In Virtual, Augmented and Mixed Reality; Lackey, S., Chen, J., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10280, pp. 248–260. [Google Scholar] [CrossRef]
- Muthanna, A.; Ateya, A.A.; Amelyanovich, A.; Shpakov, M.; Darya, P.; Makolkina, M. AR Enabled System for Cultural Heritage Monitoring and Preservation. In Internet of Things, Smart Spaces, and Next Generation Networks and Systems; Galinina, O., Andreev, S., Balandin, S., Koucheryavy, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 11118, pp. 560–571. [Google Scholar] [CrossRef]
- Phupattanasilp, P.; Tong, S.R. Augmented Reality in the Integrative Internet of Things (AR-IoT): Application for Precision Farming. Sustainability 2019, 11, 2658. [Google Scholar] [CrossRef] [Green Version]
- Cao, Y.; Xu, Z.; Li, F.; Zhong, W.; Huo, K.; Ramani, K.V. Ra: An In-Situ Visual Authoring System for Robot-IoT Task Planning with Augmented Reality. In Proceedings of the 2019 on Designing Interactive Systems Conference—DIS’19, San Diego, CA, USA, 23–28 June 2019; ACM Press: New York, NY, USA, 2019; pp. 1059–1070. [Google Scholar] [CrossRef]
- de Belen, R.A.J.; Bednarz, T.; Favero, D.D. Integrating Mixed Reality and Internet of Things as an Assistive Technology for Elderly People Living in a Smart Home. In Proceedings of the 17th International Conference on Virtual-Reality Continuum and its Applications in Industry, Brisbane, QLD, Australia, 14–16 November 2019; ACM: New York, NY, USA, 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Jo, D.; Kim, G.J. ARIoT: Scalable augmented reality framework for interacting with Internet of Things appliances everywhere. IEEE Trans. Consum. Electron. 2016, 62, 334–340. [Google Scholar] [CrossRef]
- Purmaissur, J.A.; Towakel, P.; Guness, S.P.; Seeam, A.; Bellekens, X.A. Augmented-Reality Computer-Vision Assisted Disaggregated Energy Monitoring and IoT Control Platform. In Proceedings of the 2018 International Conference on Intelligent and Innovative Computing Applications (ICONIC), Plaine Magnien, Mauritius, 6–7 December 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Stefanidi, E.; Foukarakis, M.; Arampatzis, D.; Korozi, M.; Leonidis, A.; Antona, M. ParlAmI: A Multimodal Approach for Programming Intelligent Environments. Technologies 2019, 7, 11. [Google Scholar] [CrossRef] [Green Version]
- Oviatt, S. Ten myths of multimodal interaction. Commun. ACM 1999, 42, 74–81. [Google Scholar] [CrossRef]
- Fuhl, W.; Santini, T.; Kasneci, G.; Kasneci, E. PupilNet: Convolutional Neural Networks for Robust Pupil Detection. arXiv 2016, arXiv:1601.04902. [Google Scholar]
- Gürkök, H.; Nijholt, A. Brain–Computer Interfaces for Multimodal Interaction: A Survey and Principles. Int. J. Hum.-Comput. Interact. 2012, 28, 292–307. [Google Scholar] [CrossRef]
- Gorzkowski, S.; Sarwas, G. Exploitation of EMG Signals for Video Game Control. In Proceedings of the 2019 20th International Carpathian Control Conference (ICCC), Krakow-Wieliczka, Poland, 26–29 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Liao, S.C.; Wu, F.G.; Feng, S.H. Playing games with your mouth: Improving gaming experience with EMG supportive input device. In Proceedings of the International Association of Societies of Design Research Conference, Manchester, UK, 2–5 September 2019. [Google Scholar]
- Risso, P.; Covarrubias Rodriguez, M.; Bordegoni, M.; Gallace, A. Development and Testing of a Small-Size Olfactometer for the Perception of Food and Beverages in Humans. Front. Digit. Humanit. 2018, 5, 7. [Google Scholar] [CrossRef]
- Ranasinghe, N.; Do, E.Y.L. Digital Lollipop: Studying Electrical Stimulation on the Human Tongue to Simulate Taste Sensations. ACM Trans. Multimed. Comput. Commun. Appl. 2016, 13, 1–22. [Google Scholar] [CrossRef]
- Zenner, A.; Kruger, A. Shifty: A Weight-Shifting Dynamic Passive Haptic Proxy to Enhance Object Perception in Virtual Reality. IEEE Trans. Vis. Comput. Graph. 2017, 23, 1285–1294. [Google Scholar] [CrossRef] [PubMed]
- Hussain, I.; Meli, L.; Pacchierotti, C.; Salvietti, G.; Prattichizzo, D. Vibrotactile haptic feedback for intuitive control of robotic extra fingers. In Proceedings of the 2015 IEEE World Haptics Conference (WHC), Evanston, IL, USA, 22–26 June 2015; IEEE: New York, NY, USA, 2015; pp. 394–399. [Google Scholar] [CrossRef]
- Al-Jabi, M.; Sammaneh, H. Toward Mobile AR-based Interactive Smart Parking System. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications, IEEE 16th International Conference on Smart City, IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; IEEE: New York, NY, USA, 2018; pp. 1243–1247. [Google Scholar] [CrossRef]
- Kim, J.C.; Lindberg, R.S.N.; Laine, T.H.; Faarinen, E.C.; Troyer, O.D.; Nygren, E. Multidisciplinary Development Process of a Story-based Mobile Augmented Reality Game for Learning Math. In Proceedings of the 2019 17th International Conference on Emerging eLearning Technologies and Applications (ICETA), Smokovec, Slovakia, 21–22 November 2019; IEEE: New York, NY, USA, 2019; pp. 372–377. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Keywords |
|---|---|
| 1 | multimodal interaction & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) & (framework ‖ architecture) |
| 2 | multimodal interaction & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) |
| 3 | multimodal interaction & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) & (framework ‖ architecture) |
| 4 | multimodal interaction & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) |
| 5 | multimodality & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) & (framework ‖ architecture) |
| 6 | multimodality & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) |
| 7 | multimodality & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) & (framework ‖ architecture) |
| 8 | multimodality & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) |
| 9 | multimodal & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) & (framework ‖ architecture) |
| 10 | multimodal & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) |
| 11 | multimodal & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) & (framework ‖ architecture) |
| 12 | multimodal & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) |
| 13 | interaction & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) & (framework ‖ architecture) |
| 14 | interaction & (Internet of Things ‖ IoT) & (augmented reality ‖ AR ‖ augmented) |
| 15 | interaction & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) & (framework ‖ architecture) |
| 16 | interaction & (Internet of Things ‖ IoT) & (mixed reality ‖ MR) |
| ID | Criteria |
|---|---|
| 1 | Did the proposed MI system actually use two or more modalities in input or output channels? |
| 2 | Is there a detailed description of the proposed MI system regarding its input/output modalities and architectures? |
| 3 | Was an application created with the proposed MI system evaluated by users? |
| 4 | Was there a statement about open research challenges? |
| Databases | Number of Studies |
|---|---|
| ACM Digital Library | 3 |
| Google Scholar | 7 |
| IEEE Xplore | 6 |
| ScienceDirect | 3 |
| Scopus | 0 |
| SpringerLink | 4 |
| Taylor & Francis Online | 0 |
| Interacting with Computers | 0 |
| Journal on Multimodal User Interfaces | 0 |
| Output Devices | Number of Studies |
|---|---|
| Handheld mobile device (e.g., smartphone, tablet PC) | 16 |
| HMD (e.g., HoloLens, wearable glasses) | 5 |
| Smartwatch | 1 |
| Monitor (e.g., PC, TV) | 3 |
| Projector | 1 |
| Pattern | Studies | % of Total |
|---|---|---|
| Figure 4a | [33,35,36,43,44,45,46] | 31 |
| Figure 4b | [37,38,39,41,47] | 22 |
| Figure 4c | [10,11,12,48,49,50,51,52] | 35 |
| Figure 4d | [42] | 4 |
| Figure 4c,d | [40] | 4 |
| Figure 4b,c | [34] | 4 |
| Modalities | Input Sources | Studies | Total | % of Total |
|---|---|---|---|---|
| Vision | Tracking of an AR content identifier from the camera view | [10,11,12,33,34,35,36,37,38,39,40,41,42,44,45,46,48,49,50,51,52] | 23 | 91 |
| Capturing of an agent’s hands from the camera view | [12,41,45,46,49] | 22 | ||
| Gaze interaction by head movement | [41,45,49] | 13 | ||
| Position of real-world objects | [43,44,47] | 13 | ||
| Touch: Tactility | Touching a touchscreen | [10,11,33,34,36,39,40,42,46,48,50,51,52] | 15 | 87 |
| Mouse click | [35] | 7 | ||
| Physical buttons on a machine for manipulation | [47] | 7 | ||
| Kinesthetics: Proprioception | Hand gestures | [12,41,45,49] | 7 | 57 |
| Position of hands | [46] | 14 | ||
| Position of an interaction device held by an agent | [44,48] | 29 | ||
| Kinesthetics: Kinematics | Detection of position change of a physical object | [43,45] | 2 | 100 |
| Audition | Voice command | [45,49] | 2 | 100 |
| Modalities | Output Sources | Studies | Total | % of Total |
|---|---|---|---|---|
| Vision | Presentation of 2D/3D graphics | [10,11,12,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52] | 23 | 100 |
| Presentation of controls to manipulate IoT devices | [10,11,12,34,40,42,48,49,50,51,52] | 48 | ||
| Audition | Sound cues for notification | [38,49] | 4 | 50 |
| Sound effects of AR contents | [37] | 25 | ||
| Sound from an external device | [12] | 25 |
| Modality Combinations | Studies | % of Total |
|---|---|---|
| Vision & Touch: Tactility | [10,11,33,34,35,36,39,40,42,47,50,51,52] | 57 |
| Vision & Audition | [12,37,38,49] | 17 |
| Vision & Kinesthetics: Kinematics | [43] | 4 |
| Vision & Kinesthetics: Proprioception | [12,41,44] | 13 |
| Vision & Touch: Tactility & Kinesthetics: Proprioception | [46,48] | 9 |
| Vision & Audition & Kinesthetics: Proprioception | [49] | 4 |
| Vision & Audition & Kinesthetics: Kinematics, proprioception | [45] | 4 |
| Keywords | Open Research Challenges | Studies |
|---|---|---|
| Technology | Narrow field of view in HoloLens | [45] |
| Hardware performance problem regarding noise reduction | [37] | |
| High cost of technologies | [47] | |
| Obstacles for displaying non-visible identifiers | [33] | |
| Unreliable vision-based coordinate estimation in a large-scale environment | [47] | |
| Limited detection range for QR codes | [40] | |
| Requirement of specific light conditions for running AR properly | [40] | |
| Limited object detection range | [12] | |
| Low success rate of object detection on reflective surface | [12] | |
| Unstable vision-based feature tracking with insufficient features | [48] | |
| Standardization | Standardization of MI system components | [50] |
| Standardization of AR feature data structure and data exchange protocol | [11] | |
| Scalability | Distributed system to reduce computational costs | [44] |
| Management of diverse interfaces with different IoT devices | [44] | |
| Automation of IoT device registration process | [48] | |
| Multi-agent | Individual preference for interaction devices | [36] |
| Data synchronization in multi-user scenario | [44] | |
| Personalized UI and feedback based on agent’s skill | [52] | |
| Multidisciplinary | Understanding of various cultures for different types of agents | [33] |
| Conducting user evaluations in real-world scenario | [43] |
| Authors | Input Modalities | Output Modalities | Output Devices | Objectives | PAT |
|---|---|---|---|---|---|
| [35] | Vision (camera view for AR marker detection), Touch (tactility: machine control) | Vision (2D/3D graphics) | Tablet PC | AR application for monitoring the power state of a coffee maker. | Figure 4a |
| [39] | Vision (camera view for AR marker and plane detection), Touch (tactility: touchscreen) | Vision (2D/3D graphics) | Smartphone | Serious game to raise awareness of air pollution problems. | Figure 4b |
| [50] | Vision (camera view for object recognition), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Smartphone | A system that presents the status and enables the manipulation of real-world objects that are recognized/tracked by data from IoT devices. | Figure 4c |
| [36] | Vision (camera view for AR marker detection), Touch (tactility: touchscreen) | Vision (2D/3D graphics) | Mobile device (smartphone, tablet PC) | Allows the agent to find items from a smart shelf using RFID data. | Figure 4a |
| [38] | Vision (camera view for image recognition) | Vision (2D/3D graphics), Audition (audio effect [alarm]) | HMD (wearable glasses) | Task procedure visualization with a safety warning system (for sending alarms to agents) that can sense problems using data from IoT devices that are held by the agent. | Figure 4b |
| [45] | Vision (camera view for hand gestures, head movement [gaze]), Audition (voice), Kinesthetics (kinematics: measuring the distance between an agent and a selected tool while detecting the pick-up motion; proprioception: hand gesture) | Vision (2D/3D graphics) | HMD (HoloLens) | Indoor navigation to guide the agent to a specific room where the selected tool is placed. The distance between the agent and tool is measured by IoT devices to detect the pick-up motion. | Figure 4a |
| [33] | Vision (camera view for color and object recognition), Touch (tactility: touchscreen) | Vision (2D/3D graphics) | Smartphone | Visualization of IoT device data using emojis. | Figure 4a |
| [46] | Vision (camera view for image recognition), Touch (tactility: touchscreen), Kinesthetics (proprioception: hand position [virtual button]) | Vision (2D/3D graphics) | Mobile device (smartphone, tablet PC) | A prototype AR application that can visualize either the information of an art object (The Starry Night painting by Vincent Van Gogh) for museum visitors, or data of IoT devices in the museum for administrators. | Figure 4a |
| [43] | Vision (position of object by light density resistor), Kinesthetics (kinematics: movement of smart object by hand) | Vision (2D/3D graphics) | TV screen | Testing the the agent’s upper limb disorder by moving a smart object on a smartboard. AR content is presented on a TV screen, while data from IoT devices are presented on the smartboard. | Figure 4a |
| [37] | Vision (camera view for image recognition) | Vision (2D/3D graphics), Audition (audio effect) | Smartphone | Visualizing a 3D model of a heart on the AR marker. The 3D heart model is a heartbeat animation synchronized with the agent’s heart rate measured by an IoT device on the agent’s fingertip. | Figure 4b |
| [51] | Vision (camera view for image recognition), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Smartphone | Presenting air quality monitoring data as AR content on an IoT device and allowing the agent to control the power of the IoT device. | Figure 4c |
| [10] | Vision (camera view for AR marker detection), Touch (tactility: touchscreen) | Vision (2D/3D graphics), device control [smart object]) | Mobile device (smartphone, tablet PC) | Allowing the agent to monitor and control a miniature centrifuge (IoT device). | Figure 4c |
| [44] | Vision (camera view for position of object and spatial mapping), Kinesthetics (proprioception: distance between device and IoT device) | Vision (2D/3D graphics) | Smartphone | Navigate a spatially registered room with an AR user interface that can present the position and status of eight IoT devices in the specific room. | Figure 4a |
| [41] | Vision (camera view for hand gesture and physical object detection, head movement [gaze]), Kinesthetics (proprioception: hand gesture) | Vision (2D/3D graphics) | HMD (HoloLens), projectors, PC screen | Presenting assembling process instructions of an electrical cabinet while cameras with depth sensors and projectors are used to track the agent’s hand movements to recognize input gestures. | Figure 4b |
| [11] | Vision (camera view for object recognition), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Smartphone | Manipulate merchandise in a shop; recognize and track objects using data from IoT devices. | Figure 4c |
| [42] | Vision (camera view for object recognition), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Mobile device (smartphone, tablet PC) | Energy management by AR presentation of data collected from IoT devices installed in rooms of a building. | Figure 4d |
| [47] | Vision (position of crops in camera view), Touch (tactility: mouse) | Vision (2D/3D graphics) | PC screen | Monitor the status of crops using data from IoT devices. | Figure 4b |
| [52] | Vision (camera view for object recognition), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Mobile device (smartphone, tablet PC) | The agent uses an AR interface to create rules on how IoT devices interact with each other in a smart home. | Figure 4c |
| [40] | Vision (camera view for AR marker detection), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Mobile device (smartphone, tablet PC) | A companion application of an educational toolkit to visualize IoT device data in AR. The agent can control IoT devices through the application, such as toggling an LED light or inserting a message on an LCD screen. | Figure 4c,d |
| [12] | Vision (camera view for object recognition and hand gesture [by external device]), Kinesthetics (proprioception: hand gesture) | Vision (2D/3D graphics, device control [smart object]), Audition (device control [sound from smart object]) | HMD (HoloLens) | The agent can control IoT devices (speaker and smart light bulb) with hand gestures in an MR interface. | Figure 4c |
| [48] | Vision (camera view for AR marker detection), Kinesthetics (proprioception: position of agent), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Smartphone | The agent can scan QR codes attached to IoT devices to give commands to a robot that subsequently interacts with the respective IoT devices. | Figure 4c |
| [34] | Vision (camera view for object/AR marker detection and environment/movement tracking), Touch (tactility: touchscreen) | Vision (2D/3D graphics, device control [smart object]) | Smartwatch, tablet PC | An AR application for a smart factory to visualize a path by indoor navigation (with AR markers) and provide information on the machines in the factory (without AR markers). | Figure 4b,c |
| [49] | Vision (camera view for hand gesture and image recognition, head movement [gaze]), Audition (voice) | Vision (2D/3D graphics), Audition (audio effect [sound cue]) | HMD (HoloLens) | Presenting an MR interface to control IoT devices while reading data collected from them and visualizing the data on the agent’s screen. | Figure 4c |
Short Biography of Authors
 | Joo Chan Kim is a computer scientist with an interest in augmented reality, Internet of Things, and human-computer interaction; he is a doctoral student at Luleå University of Technology. |
 | Teemu H. Laine received a Ph.D. in computer science from the University of Eastern Finland in 2012. He currently holds a position of an Associate Professor at Ajou University. Laine has a strong track record in researching context-aware games and applications for education and well-being. His other research interests include augmented and virtual reality, human-computer interaction, system architectures, and artificial intelligence. |
 | Christer Åhlund received the Ph.D. degree from the Luleå University of Technology, Skellefteå, Sweden, in 2005. He is a Chaired Professor of pervasive and mobile computing with the Luleå University of Technology. He is also the Scientific Director of excellence in research and innovation named Enabling ICT. Beyond his academic background, he has 12 years of industry experience in the ICT area. His research interests include Internet mobility, wireless access networks, Internet of Things, and cloud computing. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.C.; Laine, T.H.; Åhlund, C. Multimodal Interaction Systems Based on Internet of Things and Augmented Reality: A Systematic Literature Review. Appl. Sci. 2021, 11, 1738. https://doi.org/10.3390/app11041738
Kim JC, Laine TH, Åhlund C. Multimodal Interaction Systems Based on Internet of Things and Augmented Reality: A Systematic Literature Review. Applied Sciences. 2021; 11(4):1738. https://doi.org/10.3390/app11041738
Chicago/Turabian StyleKim, Joo Chan, Teemu H. Laine, and Christer Åhlund. 2021. "Multimodal Interaction Systems Based on Internet of Things and Augmented Reality: A Systematic Literature Review" Applied Sciences 11, no. 4: 1738. https://doi.org/10.3390/app11041738
APA StyleKim, J. C., Laine, T. H., & Åhlund, C. (2021). Multimodal Interaction Systems Based on Internet of Things and Augmented Reality: A Systematic Literature Review. Applied Sciences, 11(4), 1738. https://doi.org/10.3390/app11041738