
On the Use of Structured Prior Models for Bayesian Compressive Sensing of Modulated Signals

 ,
,  ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Proposed Method
2.1. Problem Formulation
2.1.1. Technical Background
2.1.2. Observation Model
2.1.3. Bayesian Framework
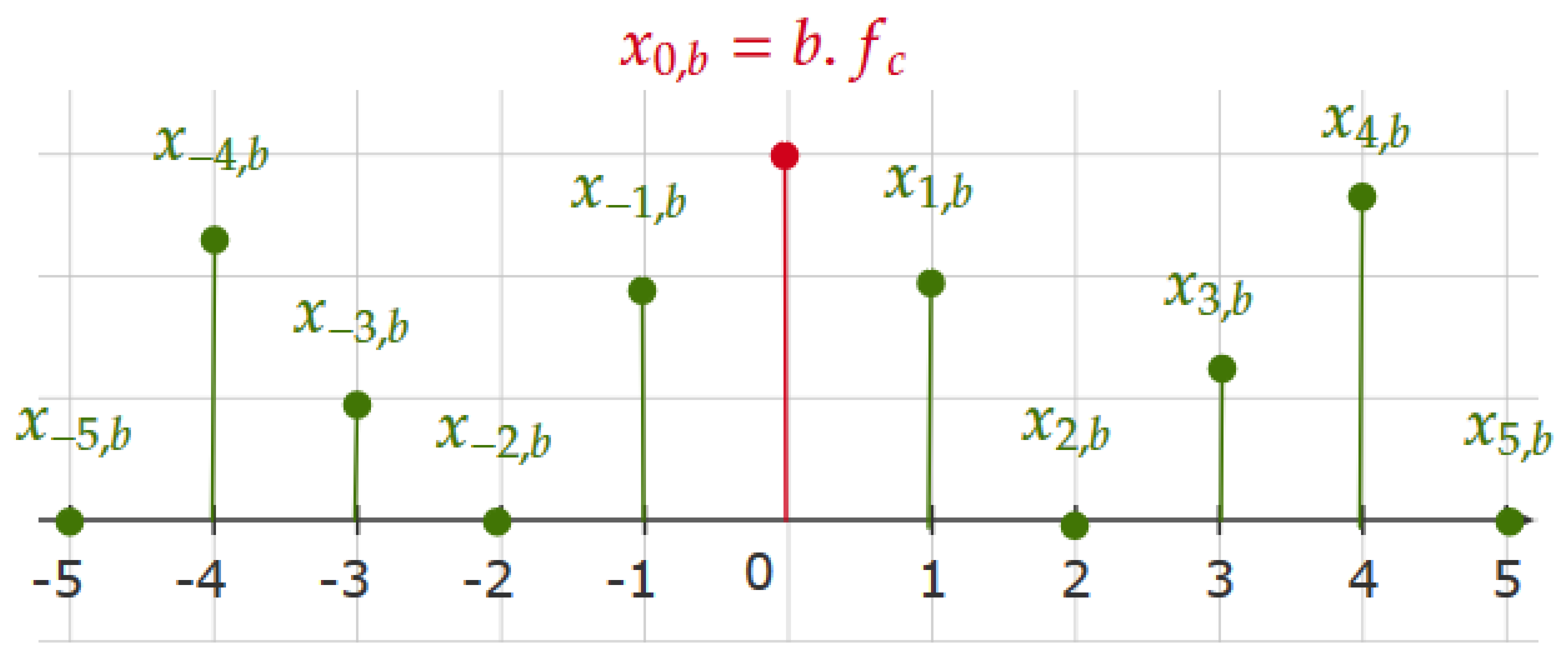
2.2. Structured Spectrum of Periodically Modulated Signals
2.3. Group Sparse Model for Modulated Signals
2.3.1. Related Works
2.3.2. Hierarchical Model
2.3.3. Setting the Mixing Hyperparameters
2.4. Structured Spike and Slab for Modulated Signals
2.4.1. Related Works
2.4.2. Strong Assumptions on In-Block Symmetry and Inter-Block Similarity
2.4.3. Strong Assumptions on In-Block Symmetry and Weak Assumption for Inter-Block Similarity
2.4.4. Weak Assumptions on In-Block Symmetry and Inter-Block Similarity
2.5. Practical Implementation
3. Experimental Results
3.1. Simulated Example
3.1.1. Test Signal
3.1.2. Considered Models
- Discrete models: we consider the univariate spike-slab that is defined in (A3), where is assumed to follow an Inverse Gamma density and the (unknown) prior probability of being non-zero is the same for all coefficients. We also compare six versions of the proposed structured spike-and-slab, namely -1A, -1B, -2A, -2B, -3A, and -3B, where the number denotes the prior assumption (from weaker to stronger) given by models (6)–(8), respectively, and the letter B or A denotes the use or not of additional prior assumption on energy contribution (i.e., can take any value as for the univariate model for A and for B).
3.1.3. Results
3.2. Application to Gearbox Vibrations
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Hierarchical Univariate Models
Appendix B. Sampling Algorithm
Appendix B.1. Conditional Distribution of x
Appendix B.2. Conditional Distribution of τ
Appendix B.3. Conditional Distributions of Prior Parameters and Hyperparameters of the Spike Component
Appendix B.4. Conditional Distributions of Prior Parameters and Hyperparameters of the Slab Component
Appendix B.5. Resulting Gibbs Sampler
References
- Gungor, V.C.; Hancke, G.P. Industrial wireless sensor networks: Challenges, design principles, and technical approaches. IEEE Trans. Ind. Electron. 2009, 56, 4258–4265. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candes, E.J.; Romberg, J.K.; Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. A J. Issued Courant Inst. Math. Sci. 2006, 59, 1207–1223. [Google Scholar] [CrossRef] [Green Version]
- de Oliveira, M.M.; Khosravy, M.; Monteiro, H.L.M.; Cabral, T.W.; Dias, F.M.; Lima, M.A.A.; Silva, L.R.M.; Duque, C.A. Compressive sensing of electroencephalogram: A review. In Compressive Sensing in Healthcare; Elsevier: Amsterdam, The Netherlands, 2020; pp. 247–268. [Google Scholar]
- Wimalajeewa, T.; Varshney, P.K. Application of compressive sensing techniques in distributed sensor networks: A survey. arXiv 2017, arXiv:1709.10401. [Google Scholar]
- Ender, J.H.G. On compressive sensing applied to radar. Signal Process. 2010, 90, 1402–1414. [Google Scholar] [CrossRef]
- Massa, A.; Rocca, P.; Oliveri, G. Compressive sensing in electromagnetics-a review. IEEE Antennas Propag. Mag. 2015, 57, 224–238. [Google Scholar] [CrossRef]
- Hannan, M.A.; Hassan, K.; Jern, K.P. A review on sensors and systems in structural health monitoring: Current issues and challenges. Smart Struct. Syst. 2018, 22, 509–525. [Google Scholar]
- Huang, Y.; Beck, J.L.; Wu, S.; Li, H. Stochastic optimization using automatic relevance determination prior model for Bayesian compressive sensing. In Health Monitoring of Structural and Biological Systems 2012; International Society for Optics and Photonics: Bellingham, WA, USA, 2012; Volume 8348, p. 834837. [Google Scholar]
- Rubinstein, R.; Bruckstein, A.M.; Elad, M. Dictionaries for sparse representation modeling. Proc. IEEE 2010, 98, 1045–1057. [Google Scholar] [CrossRef]
- Vimala, P.; Yamuna, G.; Nagar, A. Performance of Compressive Sensing Technique for Sparse Channel Estimation in Orthogonal Frequency Division Multiplexing Systems. Int. J. Eng. Technol. 2017, 9, 143–149. [Google Scholar]
- Duarte, M.F.; Baraniuk, R.G. Spectral compressive sensing. Appl. Comput. Harmon. Anal. 2013, 35, 111–129. [Google Scholar] [CrossRef]
- Bora, A.; Jalal, A.; Price, E.; Dimakis, A.G. Compressed sensing using generative models. arXiv 2017, arXiv:1703.03208. [Google Scholar]
- Davis, G.; Mallat, S.; Avellaneda, M. Adaptive greedy approximations. Constr. Approx. 1997, 13, 57–98. [Google Scholar] [CrossRef]
- Mallat, S.G.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef] [Green Version]
- Tropp, J.A. Greed is good: Algorithmic results for sparse approximation. IEEE Trans. Inf. Theory 2004, 50, 2231–2242. [Google Scholar] [CrossRef] [Green Version]
- Needell, D.; Tropp, J.A. CoSaMP: Iterative signal recovery from incomplete and inaccurate samples. Appl. Comput. Harmon. Anal. 2009, 26, 301–321. [Google Scholar] [CrossRef] [Green Version]
- Candes, E.J.; Wakin, M.B.; Boyd, S.P. Enhancing sparsity by reweighted l 1 minimization. J. Fourier Anal. Appl. 2008, 14, 877–905. [Google Scholar] [CrossRef]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef] [Green Version]
- Dantzig, G.B. Linear Programming and Extensions; Princeton University Press: Princeton, NJ, USA, 1965; Volume 48. [Google Scholar]
- Figueiredo, M.A.; Nowak, R.D.; Wright, S.J. Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 2007, 1, 586–597. [Google Scholar] [CrossRef] [Green Version]
- Lv, X.; Bi, G.; Wan, C. The group lasso for stable recovery of block-sparse signal representations. IEEE Trans. Signal Process. 2011, 59, 1371–1382. [Google Scholar] [CrossRef]
- Wipf, D.P.; Rao, B.D. An empirical Bayesian strategy for solving the simultaneous sparse approximation problem. IEEE Trans. Signal Process. 2007, 55, 3704–3716. [Google Scholar] [CrossRef]
- Wipf, D.P.; Rao, B.D.; Nagarajan, S. Latent variable Bayesian models for promoting sparsity. IEEE Trans. Inf. Theory 2011, 57, 6236–6255. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Mishali, M.; Eldar, Y.C. Reduce and boost: Recovering arbitrary sets of jointly sparse vectors. IEEE Trans. Signal Process. 2008, 56, 4692–4702. [Google Scholar] [CrossRef] [Green Version]
- Stojnic, M.; Parvaresh, F.; Hassibi, B. On the reconstruction of block-sparse signals with an optimal number of measurements. IEEE Trans. Signal Process. 2009, 57, 3075–3085. [Google Scholar] [CrossRef] [Green Version]
- Mishali, M.; Eldar, Y.C. Blind multiband signal reconstruction: Compressed sensing for analog signals. IEEE Trans. Signal Process. 2009, 57, 993–1009. [Google Scholar] [CrossRef] [Green Version]
- Marnissi, Y.; Benazza-Benyahia, A.; Chouzenoux, E.; Pesquet, J.C. Generalized multivariate exponential power prior for wavelet-based multichannel image restoration. In Proceedings of the 2013 IEEE International Conference on Image Processing (ICIP), Melbourne, Australia, 15–18 September 2013; pp. 2402–2406. [Google Scholar]
- Parvaresh, F.; Vikalo, H.; Misra, S.; Hassibi, B. Recovering sparse signals using sparse measurement matrices in compressed DNA microarrays. IEEE J. Sel. Top. Signal Process. 2008, 2, 275–285. [Google Scholar] [CrossRef] [Green Version]
- Gorodnitsky, I.F.; George, J.S.; Rao, B.D. Neuromagnetic source imaging with FOCUSS: A recursive weighted minimum norm algorithm. Electroencephalogr. Clin. Neurophysiol. 1995, 95, 231–251. [Google Scholar] [CrossRef]
- Eldar, Y.C.; Kuppinger, P.; Bolcskei, H. Block-sparse signals: Uncertainty relations and efficient recovery. IEEE Trans. Signal Process. 2010, 58, 3042–3054. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Jung, T.P.; Makeig, S.; Rao, B.D. Compressed sensing of EEG for wireless telemonitoring with low energy consumption and inexpensive hardware. IEEE Trans. Biomed. Eng. 2012, 60, 221–224. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Rao, B.D. Sparse signal recovery with temporally correlated source vectors using sparse Bayesian learning. IEEE J. Sel. Top. Signal Process. 2011, 5, 912–926. [Google Scholar] [CrossRef] [Green Version]
- Ferguson, D.; Catterson, V. Big data techniques for wind turbine condition monitoring. In Proceedings of the European Wind Energy Association Annual Event (EWEA 2014), Barcelona, Spain, 10–13 March 2014. [Google Scholar]
- Bao, Y.; Beck, J.L.; Li, H. Compressive sampling for accelerometer signals in structural health monitoring. Struct. Health Monit. 2011, 10, 235–246. [Google Scholar]
- Yang, Y.; Nagarajaiah, S. Structural damage identification via a combination of blind feature extraction and sparse representation classification. Mech. Syst. Signal Process. 2014, 45, 1–23. [Google Scholar] [CrossRef]
- Wang, Y.; Xiang, J.; Mo, Q.; He, S. Compressed sparse time–frequency feature representation via compressive sensing and its applications in fault diagnosis. Measurement 2015, 68, 70–81. [Google Scholar] [CrossRef]
- Sun, J.; Yu, Y.; Wen, J. Compressed-sensing reconstruction based on block sparse Bayesian learning in bearing-condition monitoring. Sensors 2017, 17, 1454. [Google Scholar] [CrossRef] [PubMed]
- Parellier, C.; Bovkun, T.; Denimal, T.; Gehin, J.; Abboud, D.; Marnissi, Y. Non-regular sampling and compressive sensing for gearbox monitoring. In Proceedings of the 2019 Second World Congress on Condition Monitoring (WCCM), Singapore, 2–5 December 2019. [Google Scholar]
- Ma, Y.; Jia, X.; Hu, Q.; Xu, D.; Guo, C.; Wang, Q.; Wang, S. Laplace prior-based Bayesian compressive sensing using K-SVD for vibration signal transmission and fault detection. Electronics 2019, 8, 517. [Google Scholar] [CrossRef] [Green Version]
- McFadden, P.D. Detecting fatigue cracks in gears by amplitude and phase demodulation of the meshing vibration. J. Vib. Acoust. Stress Reliab. 1986, 108, 165–170. [Google Scholar] [CrossRef]
- Ma, Y.; Jia, X.; Bai, H. Gearbox degradation assessment based on a sparse representation feature and Euclidean distance technique. Aust. J. Mech. Eng. 2020, 1–16. [Google Scholar] [CrossRef]
- Brie, D.; Tomczak, M.; Oehlmann, H.; Richard, A. Gear crack detection by adaptive amplitude and phase demodulation. Mech. Syst. Signal Process. 1997, 11, 149–167. [Google Scholar] [CrossRef]
- Randall, R.B. A new method of modeling gear faults. J. Mech. Des. 1982, 104, 259–267. [Google Scholar] [CrossRef]
- Feng, Z.; Zuo, M.J. Vibration signal models for fault diagnosis of planetary gearboxes. J. Sound Vib. 2012, 331, 4919–4939. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Gelman, A. Prior distributions for variance parameters in hierarchical models (comment on article by Browne and Draper). Bayesian Anal. 2006, 1, 515–534. [Google Scholar] [CrossRef]
- Babacan, S.D.; Nakajima, S.; Do, M.N. Bayesian group-sparse modeling and variational inference. IEEE Trans. Signal Process. 2014, 62, 2906–2921. [Google Scholar] [CrossRef]
- Polson, N.G.; Scott, J.G. On the half-Cauchy prior for a global scale parameter. Bayesian Anal. 2012, 7, 887–902. [Google Scholar] [CrossRef]
- Carvalho, C.M.; Polson, N.G.; Scott, J.G. Handling sparsity via the horseshoe. In Artificial Intelligence and Statistics; Clearwater: Beach, FL, USA, 2009; pp. 73–80. [Google Scholar]
- Piironen, J.; Vehtari, A. Sparsity information and regularization in the horseshoe and other shrinkage priors. Electron. J. Stat. 2017, 11, 5018–5051. [Google Scholar] [CrossRef]
- Makalic, E.; Schmidt, D.F. A simple sampler for the horseshoe estimator. IEEE Signal Process. Lett. 2015, 23, 179–182. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Carin, L. Exploiting structure in wavelet-based Bayesian compressive sensing. IEEE Trans. Signal Process. 2009, 57, 3488–3497. [Google Scholar]
- Yu, L.; Wei, C.; Jia, J.; Sun, H. Compressive sensing for cluster structured sparse signals: Variational Bayes approach. IET Signal Process. 2016, 10, 770–779. [Google Scholar] [CrossRef] [Green Version]
- Andersen, M.R.; Vehtari, A.; Winther, O.; Hansen, L.K. Bayesian inference for spatio-temporal spike-and-slab priors. J. Mach. Learn. Res. 2017, 18, 5076–5133. [Google Scholar]
- Kuzin, D.; Isupova, O.; Mihaylova, L. Spatio-temporal structured sparse regression with hierarchical Gaussian process priors. IEEE Trans. Signal Process. 2018, 66, 4598–4611. [Google Scholar] [CrossRef]
- Marnissi, Y.; Chouzenoux, E.; Benazza-Benyahia, A.; Pesquet, J.C. An auxiliary variable method for Markov chain Monte Carlo algorithms in high dimension. Entropy 2018, 20, 110. [Google Scholar] [CrossRef] [Green Version]
- Ishwaran, H.; Rao, J.S. Spike and slab variable selection: Frequentist and Bayesian strategies. Ann. Stat. 2005, 33, 730–773. [Google Scholar] [CrossRef] [Green Version]
- Babacan, S.D.; Molina, R.; Katsaggelos, A.K. Fast Bayesian compressive sensing using Laplace priors. In Proceedings of the 2009 IEEE International Conference on Acoustics, Speech and Signal Processing, Taipei, Taiwan, 19–24 April 2009; pp. 2873–2876. [Google Scholar]
- Carvalho, C.M.; Polson, N.G.; Scott, J.G. The horseshoe estimator for sparse signals. Biometrika 2010, 97, 465–480. [Google Scholar] [CrossRef] [Green Version]
- Bhadra, A.; Datta, J.; Polson, N.G.; Willard, B. The horseshoe+ estimator of ultra-sparse signals. Bayesian Anal. 2017, 12, 1105–1131. [Google Scholar] [CrossRef]
- George, E.I.; McCulloch, R.E. Variable selection via Gibbs sampling. J. Am. Stat. Assoc. 1993, 88, 881–889. [Google Scholar] [CrossRef]
- Malsiner-Walli, G.; Wagner, H. Comparing spike and slab priors for Bayesian variable selection. arXiv 2018, arXiv:1812.07259. [Google Scholar] [CrossRef]
- Carvalho, C.M.; Chang, J.; Lucas, J.E.; Nevins, J.R.; Wang, Q.; West, M. High-dimensional sparse factor modeling: Applications in gene expression genomics. J. Am. Stat. Assoc. 2008, 103, 1438–1456. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, M.E. Gibbs Sampling for the Probit Regression Model with Gaussian Markov Random Field Latent Variables. 2007. Available online: https://icapeople.epfl.ch/mekhan/Writings/EMTstatisticalcomputation.pdf (accessed on 15 March 2021).
- Van Dyk, D.A.; Park, T. Partially collapsed Gibbs samplers: Theory and methods. J. Am. Stat. Assoc. 2008, 103, 790–796. [Google Scholar] [CrossRef]
- Marnissi, Y.; Abboud, D.; Chouzenoux, E.; Pesquet, J.C.; El-Badaoui, M.; Benazza-Benyahia, A. A Data Augmentation Approach for Sampling Gaussian Models in High Dimension. In Proceedings of the 2019 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; pp. 1–5. [Google Scholar]
- Van Dyk, D.A.; Meng, X.L. The art of data augmentation. J. Comput. Graph. Stat. 2001, 10, 1–50. [Google Scholar] [CrossRef]
- Vono, M.; Dobigeon, N.; Chainais, P. Split-and-augmented Gibbs sampler—Application to large-scale inference problems. IEEE Trans. Signal Process. 2019, 67, 1648–1661. [Google Scholar] [CrossRef] [Green Version]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marnissi, Y.; Hawwari, Y.; Assoumane, A.; Abboud, D.; El-Badaoui, M. On the Use of Structured Prior Models for Bayesian Compressive Sensing of Modulated Signals. Appl. Sci. 2021, 11, 2626. https://doi.org/10.3390/app11062626
Marnissi Y, Hawwari Y, Assoumane A, Abboud D, El-Badaoui M. On the Use of Structured Prior Models for Bayesian Compressive Sensing of Modulated Signals. Applied Sciences. 2021; 11(6):2626. https://doi.org/10.3390/app11062626
Chicago/Turabian StyleMarnissi, Yosra, Yasmine Hawwari, Amadou Assoumane, Dany Abboud, and Mohamed El-Badaoui. 2021. "On the Use of Structured Prior Models for Bayesian Compressive Sensing of Modulated Signals" Applied Sciences 11, no. 6: 2626. https://doi.org/10.3390/app11062626