
A Partially Interpretable Adaptive Softmax Regression for Credit Scoring




Abstract
:1. Introduction
- To achieve high predictive accuracy, usually, model complexity is increased. Therefore, machine learning models often make a deal with the predictive performance and interpretable predictions. We propose a model with both high predictive ability and partially explainable.
- In order to handle class imbalance problem without sampling techniques, our proposed model is designed.
- We extensively evaluate PIA-Soft model on four benchmark credit scoring datasets. The experimental results show that PIA-Soft achieves state-of-the-art performance in increasing the predictive accuracy, against machine learning baselines.
- It has proven that our proposed model could explore the partial relationship between input and target variables according to experiments on real-world datasets.
2. Related Work
2.1. Benchmark Classification Algorithms
2.2. Explainable Credit Scoring Model
3. Methodology
3.1. Softmax Regression
3.2. Neural Networks
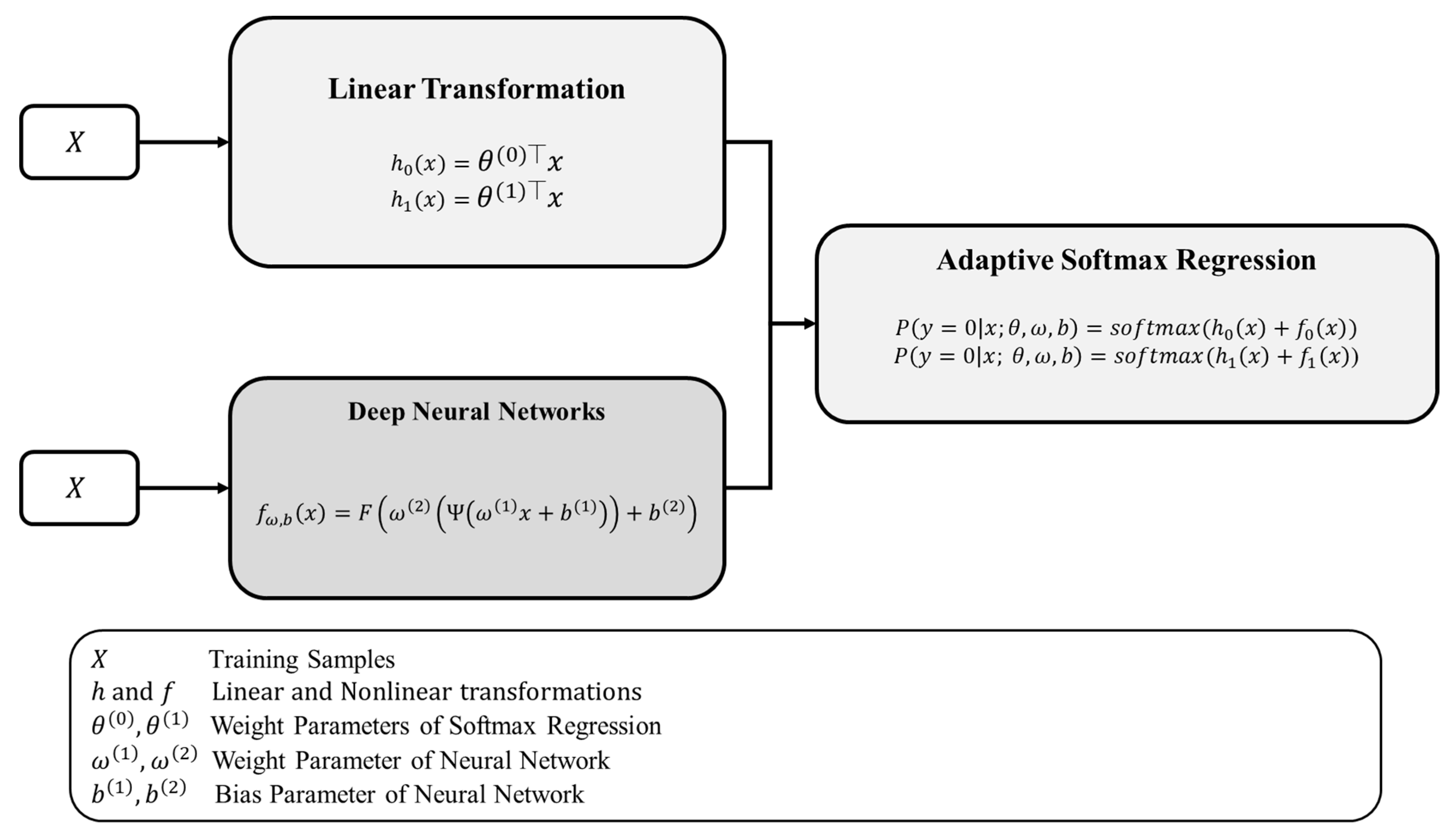
3.3. A Partially Interpretable Adaptive Softmax Regression (PIA-Soft)
4. Experimental Results
4.1. Dataset
4.2. Machine Learning Baselines and Hyperparameter Setting
Comparison of Predictive Performance
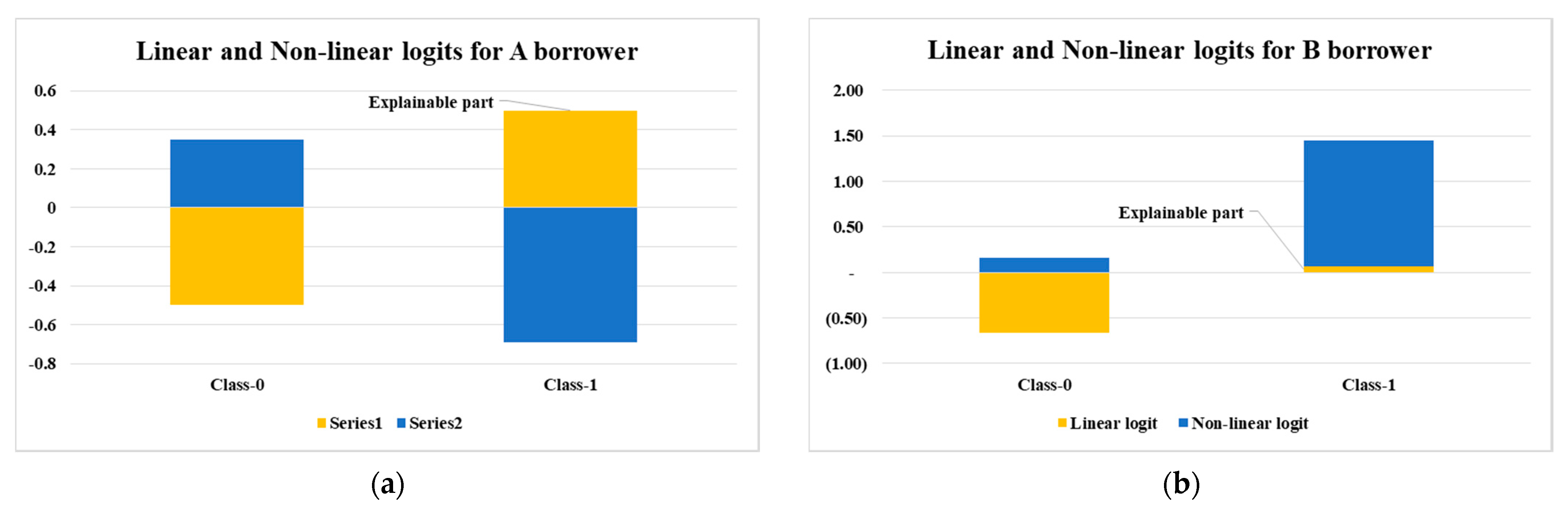
4.3. Model Interpretability
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A










References
- Dastile, X.; Celik, T.; Potsane, M. Statistical and machine learning models in credit scoring: A systematic literature survey. Appl. Soft Comput. 2020, 91, 106263–106284. [Google Scholar] [CrossRef]
- Munkhdalai, L.; Munkhdalai, T.; Namsrai, O.E.; Lee, J.Y.; Ryu, K.H. An empirical comparison of machine-learning methods on bank client credit assessments. Sustainability 2019, 11, 699. [Google Scholar] [CrossRef] [Green Version]
- Demajo, L.M.; Vella, V.; Dingli, A. Explainable AI for Interpretable Credit Scoring. arXiv 2020, arXiv:2012.03749. [Google Scholar]
- Bussmann, N.; Giudici, P.; Marinelli, D.; Papenbrock, J. Explainable machine learning in credit risk management. Comput. Econ. 2020, 57, 203–216. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. InMIPRO 2018, 41, 210–215. [Google Scholar]
- Modarres, C.; Ibrahim, M.; Louie, M.; Paisley, J. Towards explainable deep learning for credit lending: A case study. arXiv 2018, arXiv:1811.06471. [Google Scholar]
- Munkhdalai, L.; Wang, L.; Park, H.W.; Ryu, K.H. Advanced neural network approach, its explanation with lime for credit scoring application. InACIIDS 2019, 11432, 407–419. [Google Scholar]
- Brown, I.; Mues, C. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Syst. Appl. 2012, 39, 3446–3453. [Google Scholar] [CrossRef] [Green Version]
- Marqués, A.I.; García, V.; Sánchez, J.S. On the suitability of resampling techniques for the class imbalance problem in credit scoring. J. Oper. Res. Soc. 2013, 64, 1060–1070. [Google Scholar] [CrossRef] [Green Version]
- Junior, L.M.; Nardini, F.M.; Renso, C.; Trani, R.; Macedo, J.A. A novel approach to define the local region of dynamic selection techniques in imbalanced credit scoring problems. Expert Syst. Appl. 2020, 152, 113351. [Google Scholar] [CrossRef]
- Munkhdalai, L.; Munkhdalai, T.; Ryu, K.H. GEV-NN: A deep neural network architecture for class imbalance problem in binary classification. Knowl. Based Syst. 2020, 194, 105534. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Cox, D.R. The regression analysis of binary sequences. J. R. Stat. Soc. Ser. B Stat. Methodol. 1958, 20, 215–242. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. NIPS 2017, 30, 3146–3154. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Arik, S.O.; Pfister, T. Tabnet: Attentive interpretable tabular learning. arXiv 2019, arXiv:1908.07442. [Google Scholar]
- Hand, D.J.; Anagnostopoulos, C. A better Beta for the H measure of classification performance. Pattern Recognit. Lett. 2014, 40, 41–46. [Google Scholar] [CrossRef] [Green Version]
- Lessmann, S.; Baesens, B.; Seow, H.V.; Thomas, L.C. Benchmarking state-of-the-art classification algorithms for credit scoring: An update of research. Eur. J. Oper. Res. 2015, 247, 124–136. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Louzada, F.; Ara, A.; Fernandes, G.B. Classification methods applied to credit scoring: Systematic review and overall comparison. Comput. Oper. Res. 2016, 21, 117–134. [Google Scholar] [CrossRef] [Green Version]
- Orgler, Y.E. A credit scoring model for commercial loans. J. Money Credit. Bank 1970, 2, 435–445. [Google Scholar] [CrossRef]
- Bellotti, T.; Crook, J. Support vector machines for credit scoring and discovery of significant features. Expert Syst. Appl. 2009, 36, 3302–3308. [Google Scholar] [CrossRef] [Green Version]
- Ala’raj, M.; Abbod, M.F. Classifiers consensus system approach for credit scoring. Knowl. Based Syst. 2016, 104, 89–105. [Google Scholar] [CrossRef]
- Chuang, C.L.; Huang, S.T. A hybrid neural network approach for credit scoring. Expert Syst. 2011, 28, 185–196. [Google Scholar] [CrossRef]
- Munkhdalai, L.; Lee, J.Y.; Ryu, K.H. A Hybrid Credit Scoring Model Using Neural Networks and Logistic Regression. In Advances in Intelligent Information Hiding and Multimedia Signal Processing; Springer: Singapore, 2020; pp. 251–258. [Google Scholar]
- Vellido, A.; Martín-Guerrero, J.D.; Lisboa, P.J. Making machine learning models interpretable. InESANN 2012, 12, 163–172. [Google Scholar]
- West, D. Neural network credit scoring models. Comput. Oper. Res. 2000, 27, 1131–1152. [Google Scholar] [CrossRef]
- Pang, S.L. Study on Credit Scoring Model and Forecasting Based on Probabilistic Neural Network. Syst. Eng. Theory. Pract. 2005, 5, 006. [Google Scholar]
- Lisboa, P.J.; Etchells, T.A.; Jarman, I.H.; Arsene, C.T.; Aung, M.H.; Eleuteri, A.; Biganzoli, E. Partial logistic artificial neural network for competing risks regularized with automatic relevance determination. IEEE Trans. Neural Netw. 2009, 20, 1403–1416. [Google Scholar] [CrossRef]
- Marcano-Cedeño, A.; Quintanilla-Domínguez, J.; Andina, D. WBCD breast cancer database classification applying artificial metaplasticity neural network. Expert Syst. Appl. 2011, 38, 9573–9579. [Google Scholar] [CrossRef]
- Abdou, H.; Pointon, J.; El-Masry, A. Neural nets versus conventional techniques in credit scoring in Egyptian banking. Expert Syst. Appl. 2008, 35, 1275–1292. [Google Scholar] [CrossRef] [Green Version]
- Ala’raj, M.; Abbod, M.F. A new hybrid ensemble credit scoring model based on classifiers consensus system approach. Expert Syst. Appl. 2016, 64, 36–55. [Google Scholar] [CrossRef]
- Xiao, H.; Xiao, Z.; Wang, Y. Ensemble classification based on supervised clustering for credit scoring. Appl. Soft Comput. 2016, 43, 73–86. [Google Scholar] [CrossRef]
- Shen, F.; Zhao, X.; Kou, G.; Alsaadi, F.E. A new deep learning ensemble credit risk evaluation model with an improved synthetic minority oversampling technique. Appl. Soft Comput. 2021, 98, 106852. [Google Scholar] [CrossRef]
- He, H.; Zhang, W.; Zhang, S. A novel ensemble method for credit scoring: Adaption of different imbalance ratios. Expert Syst. Appl. 2018, 98, 105–117. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Zhang, S.; Ablanedo-Rosas, J.H.; Wu, X.; Lou, Y. A novel multi-stage ensemble model with enhanced outlier adaptation for credit scoring. Expert Syst. Appl. 2021, 165, 113872. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Torrent, N.L.; Visani, G.; Bagli, E. PSD2 Explainable AI Model for Credit Scoring. arXiv 2020, arXiv:2011.10367. [Google Scholar]
- Munkhdalai, L.; Munkhdalai, T.; Ryu, K.H. A locally adaptive interpretable regression. arXiv 2020, arXiv:2005.03350. [Google Scholar]
- Ariza-Garzón, M.J.; Arroyo, J.; Caparrini, A.; Segovia-Vargas, M.J. Explainability of a machine learning granting scoring model in peer-to-peer lending. IEEE Access 2020, 8, 64873–64890. [Google Scholar] [CrossRef]
- FICO Explainable Machine Learning Challenge. Available online: https://community.fico.com/community/xml (accessed on 24 January 2021).
- Dash, S.; Günlük, O.; Wei, D. Boolean decision rules via column generation. arXiv 2018, arXiv:1805.09901. [Google Scholar]
- Bracke, P.; Datta, A.; Jung, C.; Sen, S. Machine learning explainability in finance: An application to default risk analysis. Bank Engl. Staff Work Paper 2019, 816, 1–44. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Zhou, M.; Su, W.; Wu, M.; She, J.; Hirota, K. Softmax regression based deep sparse autoencoder network for facial emotion recognition in human-robot interaction. Inf. Sci. 2018, 428, 49–61. [Google Scholar] [CrossRef]
- Asuncion, A.; Newman, D. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 24 January 2021).
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-Sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks, Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD 2004, 6, 20–29. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Instances | Variables | Good/Bad |
|---|---|---|---|
| German | 1000 | 24 | 700/300 |
| Australian | 690 | 14 | 387/307 |
| Taiwan | 6000 | 23 | 3000/3000 |
| FICO | 9871 | 24 | 5136/4735 |
| Model | Parameters | Search Space |
|---|---|---|
| Random Forest | max_depth | (2, 8) |
| min_samples_split | (1, 8) | |
| min_samples_leaf | (1, 8] | |
| criterion | {‘gini’, ‘entropy’} | |
| bootstrap | {True, False} | |
| AdaBoost | learning_rate | (0.1, 1) |
| algorithm | {‘SAMME.R’, ‘SAMME’} | |
| XGBoost | min_child_weight | (1, 10) |
| gamma | {0, 0.1, 0.5, 0.8, 1} | |
| subsample | {0.5, 0.75, 0.9} | |
| colsample_bytree | {0.5, 0.6, 0.7, 0.8, 0.9, 1} | |
| max_depth | {2, 8} | |
| learning_rate | {0.01, 0.1, 0.2, 0.3, 0.5} | |
| LightGBM | min_child_samples | (10, 60) |
| reg_alpha | {0, 0.1, 0.5, 0.8, 1} | |
| subsample | {0.5, 0.75, 0.9} | |
| colsample_bytree | {0.5, 0.6, 0.7, 0.8, 0.9, 1} | |
| max_depth | (2, 8) | |
| learning_rate | {0.01, 0.1, 0.2, 0.3, 0.5} | |
| CatBoost | min_child_samples | (10, 60) |
| subsample | {0.5, 0.75, 0.9} | |
| colsample_bytree | {0.5, 0.6, 0.7, 0.8, 0.9, 1} | |
| max_depth | (2, 8) | |
| learning_rate | {0.01, 0.1, 0.2, 0.3, 0.5} | |
| TabNet | n_d | (4, 16) |
| n_a | (4, 16) | |
| mask_type | {‘entmax’, ‘sparsemax’} |
| Sampling Method | Model | AUC | Accuracy | F-Sscore | G-Mean |
|---|---|---|---|---|---|
| No sampling | Logistic | 0.788 +/− 0.072 | 0.762 +/− 0.062 | 0.774 +/− 0.056 | 0.777 +/− 0.053 |
| Random forest | 0.788 +/− 0.071 | 0.771 +/− 0.070 | 0.783 +/− 0.065 | 0.778 +/− 0.067 | |
| AdaBoost | 0.762 +/− 0.038 | 0.721 +/− 0.040 | 0.736 +/− 0.041 | 0.737 +/− 0.039 | |
| XGBoost | 0.778 +/− 0.059 | 0.762 +/− 0.059 | 0.775 +/− 0.051 | 0.774 +/− 0.053 | |
| Neural Network | 0.791 +/− 0.069 | 0.759 +/− 0.061 | 0.771 +/− 0.054 | 0.775 +/− 0.053 | |
| LightGBM | 0.766 +/− 0.022 | 0.764 +/− 0.019 | 0.777 +/− 0.018 | 0.773 +/− 0.023 | |
| CatBoost | 0.783 +/− 0.018 | 0.771 +/− 0.028 | 0.783 +/− 0.023 | 0.775 +/− 0.023 | |
| TabNet | 0.653 +/− 0.022 | 0.678 +/− 0.018 | 0.695 +/− 0.020 | 0.685 +/− 0.016 | |
| SMOTE | Logistic | 0.798 +/− 0.015 | 0.767 +/− 0.012 | 0.767 +/− 0.012 | 0.767 +/− 0.012 |
| Random forest | 0.776 +/− 0.025 | 0.752 +/− 0.023 | 0.754 +/− 0.018 | 0.753 +/− 0.020 | |
| AdaBoost | 0.725 +/− 0.019 | 0.715 +/− 0.021 | 0.715 +/− 0.021 | 0.715 +/− 0.020 | |
| XGBoost | 0.782 +/− 0.029 | 0.750 +/− 0.044 | 0.752 +/− 0.036 | 0.751 +/− 0.042 | |
| Neural Network | 0.795 +/− 0.020 | 0.764 +/− 0.019 | 0.765 +/− 0.014 | 0.765 +/− 0.015 | |
| LightGBM | 0.763 +/− 0.041 | 0.758 +/− 0.043 | 0.771 +/− 0.041 | 0.764 +/− 0.042 | |
| CatBoost | 0.775 +/− 0.039 | 0.759 +/− 0.058 | 0.772 +/− 0.054 | 0.770 +/− 0.053 | |
| TabNet | 0.717 +/− 0.039 | 0.720 +/− 0.043 | 0.735 +/− 0.037 | 0.727 +/− 0.038 | |
| ADASYN | Logistic | 0.794 +/− 0.067 | 0.788 +/− 0.055 | 0.799 +/− 0.051 | 0.797 +/− 0.054 |
| Random forest | 0.793 +/− 0.070 | 0.773 +/− 0.058 | 0.785 +/− 0.050 | 0.783 +/− 0.055 | |
| AdaBoost | 0.715 +/− 0.042 | 0.703 +/− 0.048 | 0.719 +/− 0.045 | 0.716 +/− 0.043 | |
| XGBoost | 0.765 +/− 0.075 | 0.764 +/− 0.058 | 0.776 +/− 0.052 | 0.772 +/− 0.054 | |
| Neural Network | 0.796 +/− 0.064 | 0.792 +/− 0.059 | 0.802 +/− 0.056 | 0.800 +/− 0.056 | |
| LightGBM | 0.758 +/− 0.024 | 0.742 +/− 0.038 | 0.756 +/− 0.036 | 0.749 +/− 0.037 | |
| CatBoost | 0.780 +/− 0.038 | 0.774 +/− 0.038 | 0.786 +/− 0.036 | 0.778 +/− 0.037 | |
| TabNet | 0.709 +/− 0.075 | 0.711 +/− 0.077 | 0.726 +/− 0.072 | 0.720 +/− 0.073 | |
| ROS | Logistic | 0.786 +/− 0.071 | 0.766 +/− 0.071 | 0.778 +/− 0.067 | 0.780 +/− 0.065 |
| Random forest | 0.797 +/− 0.068 | 0.764 +/− 0.084 | 0.777 +/− 0.077 | 0.779 +/− 0.077 | |
| AdaBoost | 0.710 +/− 0.050 | 0.688 +/− 0.052 | 0.704 +/− 0.052 | 0.710 +/− 0.045 | |
| XGBoost | 0.769 +/− 0.068 | 0.748 +/− 0.078 | 0.761 +/− 0.070 | 0.764 +/− 0.065 | |
| Neural Network | 0.788 +/− 0.067 | 0.749 +/− 0.047 | 0.761 +/− 0.043 | 0.761 +/− 0.043 | |
| LightGBM | 0.793 +/− 0.014 | 0.767 +/− 0.013 | 0.767 +/− 0.013 | 0.767 +/− 0.013 | |
| CatBoost | 0.794 +/− 0.013 | 0.767 +/− 0.010 | 0.767 +/− 0.010 | 0.766 +/− 0.010 | |
| TabNet | 0.780 +/− 0.014 | 0.760 +/− 0.014 | 0.760 +/− 0.015 | 0.759 +/− 0.014 | |
| PIA-Soft (Ours) | 0.798 +/− 0.045 | 0.781 +/− 0.051 | 0.795 +/− 0.047 | 0.795 +/− 0.049 | |
| Sampling Method | Model | AUC | Accuracy | F-Score | G-Mean |
|---|---|---|---|---|---|
| No sampling | Logistic | 0.911 +/− 0.053 | 0.869 +/− 0.047 | 0.868 +/− 0.047 | 0.862 +/− 0.046 |
| Random forest | 0.916 +/− 0.064 | 0.883 +/− 0.053 | 0.883 +/− 0.052 | 0.876 +/− 0.052 | |
| AdaBoost | 0.928 +/− 0.035 | 0.894 +/− 0.024 | 0.894 +/− 0.023 | 0.891 +/− 0.024 | |
| XGBoost | 0.915 +/− 0.059 | 0.870 +/− 0.067 | 0.870 +/− 0.068 | 0.868 +/− 0.065 | |
| Neural Network | 0.904 +/− 0.052 | 0.867 +/− 0.051 | 0.866 +/− 0.051 | 0.860 +/− 0.049 | |
| LightGBM | 0.937 +/− 0.022 | 0.904 +/− 0.021 | 0.904 +/− 0.021 | 0.902 +/− 0.022 | |
| CatBoost | 0.938 +/− 0.015 | 0.910 +/− 0.018 | 0.910 +/− 0.018 | 0.907 +/− 0.017 | |
| TabNet | 0.852 +/− 0.047 | 0.823 +/− 0.034 | 0.822 +/− 0.034 | 0.816 +/− 0.038 | |
| SMOTE | Logistic | 0.910 +/− 0.054 | 0.873 +/− 0.056 | 0.873 +/− 0.056 | 0.867 +/− 0.056 |
| Random forest | 0.916 +/− 0.065 | 0.884 +/− 0.056 | 0.884 +/− 0.056 | 0.882 +/− 0.055 | |
| AdaBoost | 0.923 +/− 0.039 | 0.879 +/− 0.045 | 0.879 +/− 0.045 | 0.876 +/− 0.044 | |
| XGBoost | 0.903 +/− 0.058 | 0.855 +/− 0.060 | 0.854 +/− 0.061 | 0.848 +/− 0.060 | |
| Neural Network | 0.906 +/− 0.054 | 0.842 +/− 0.109 | 0.826 +/− 0.155 | 0.834 +/− 0.117 | |
| LightGBM | 0.936 +/− 0.025 | 0.898 +/− 0.023 | 0.898 +/− 0.023 | 0.897 +/− 0.023 | |
| CatBoost | 0.931 +/− 0.019 | 0.914 +/− 0.019 | 0.914 +/− 0.019 | 0.912 +/− 0.018 | |
| TabNet | 0.836 +/− 0.023 | 0.821 +/− 0.030 | 0.822 +/− 0.031 | 0.820 +/− 0.031 | |
| ADASYN | Logistic | 0.911 +/− 0.053 | 0.876 +/− 0.051 | 0.876 +/− 0.051 | 0.870 +/− 0.050 |
| Random forest | 0.917 +/− 0.065 | 0.880 +/− 0.055 | 0.880 +/− 0.054 | 0.875 +/− 0.054 | |
| AdaBoost | 0.916 +/− 0.039 | 0.873 +/− 0.039 | 0.873 +/− 0.039 | 0.871 +/− 0.038 | |
| XGBoost | 0.917 +/− 0.060 | 0.851 +/− 0.103 | 0.835 +/− 0.147 | 0.841 +/− 0.122 | |
| Neural Network | 0.904 +/− 0.054 | 0.863 +/− 0.046 | 0.863 +/− 0.046 | 0.859 +/− 0.045 | |
| LightGBM | 0.934 +/− 0.023 | 0.898 +/− 0.015 | 0.898 +/− 0.015 | 0.896 +/− 0.016 | |
| CatBoost | 0.934 +/− 0.018 | 0.904 +/− 0.016 | 0.904 +/− 0.016 | 0.901 +/− 0.015 | |
| TabNet | 0.800 +/− 0.063 | 0.804 +/− 0.058 | 0.804 +/− 0.058 | 0.801 +/− 0.057 | |
| ROS | Logistic | 0.911 +/− 0.053 | 0.879 +/− 0.052 | 0.878 +/− 0.052 | 0.872 +/− 0.052 |
| Random forest | 0.917 +/− 0.065 | 0.883 +/− 0.055 | 0.883 +/− 0.055 | 0.878 +/− 0.055 | |
| AdaBoost | 0.912 +/− 0.045 | 0.862 +/− 0.062 | 0.861 +/− 0.063 | 0.859 +/− 0.061 | |
| XGBoost | 0.909 +/− 0.067 | 0.857 +/− 0.052 | 0.855 +/− 0.052 | 0.849 +/− 0.052 | |
| Neural Network | 0.903 +/− 0.055 | 0.846 +/− 0.096 | 0.833 +/− 0.132 | 0.835 +/− 0.117 | |
| LightGBM | 0.926 +/− 0.026 | 0.892 +/− 0.024 | 0.892 +/− 0.024 | 0.891 +/− 0.024 | |
| CatBoost | 0.924 +/− 0.012 | 0.902 +/− 0.018 | 0.902 +/− 0.019 | 0.900 +/− 0.018 | |
| TabNet | 0.842 +/− 0.048 | 0.802 +/− 0.059 | 0.803 +/− 0.058 | 0.802 +/− 0.059 | |
| PIA-Soft (Ours) | 0.934 +/− 0.041 | 0.896 +/− 0.079 | 0.894 +/− 0.086 | 0.895 +/− 0.075 | |
| Sampling Method | Model | AUC | Accuracy | F-Score | G-Mean |
|---|---|---|---|---|---|
| No sampling | Logistic | 0.637 +/− 0.028 | 0.644 +/− 0.025 | 0.644 +/− 0.025 | 0.643 +/− 0.024 |
| Random forest | 0.750 +/− 0.016 | 0.732 +/− 0.012 | 0.732 +/− 0.012 | 0.732 +/− 0.012 | |
| AdaBoost | 0.721 +/− 0.010 | 0.708 +/− 0.015 | 0.708 +/− 0.015 | 0.708 +/− 0.015 | |
| XGBoost | 0.744 +/− 0.019 | 0.724 +/− 0.016 | 0.724 +/− 0.016 | 0.725 +/− 0.016 | |
| Neural Network | 0.736 +/− 0.018 | 0.715 +/− 0.018 | 0.715 +/− 0.018 | 0.715 +/− 0.018 | |
| LightGBM | 0.751 +/− 0.011 | 0.732 +/− 0.012 | 0.731 +/− 0.012 | 0.731 +/− 0.012 | |
| CatBoost | 0.753 +/− 0.011 | 0.734 +/− 0.012 | 0.734 +/− 0.012 | 0.734 +/− 0.012 | |
| TabNet | 0.739 +/− 0.012 | 0.723 +/− 0.019 | 0.723 +/− 0.018 | 0.723 +/− 0.018 | |
| PIA-Soft (Ours) | 0.744 +/− 0.015 | 0.725 +/− 0.015 | 0.726 +/− 0.015 | 0.726 +/− 0.015 |
| Sampling Method | Model | AUC | Accuracy | F-Score | G-Mean |
|---|---|---|---|---|---|
| No sampling | Logistic | 0.798 +/− 0.015 | 0.767 +/− 0.012 | 0.767 +/− 0.012 | 0.767 +/− 0.012 |
| Random forest | 0.774 +/− 0.030 | 0.755 +/− 0.016 | 0.757 +/− 0.014 | 0.755 +/− 0.016 | |
| AdaBoost | 0.773 +/− 0.016 | 0.755 +/− 0.014 | 0.755 +/− 0.014 | 0.755 +/− 0.014 | |
| XGBoost | 0.787 +/− 0.018 | 0.754 +/− 0.035 | 0.756 +/− 0.029 | 0.757 +/− 0.025 | |
| Neural Network | 0.798 +/− 0.014 | 0.756 +/− 0.035 | 0.758 +/− 0.028 | 0.760 +/− 0.025 | |
| LightGBM | 0.792 +/− 0.015 | 0.766 +/− 0.014 | 0.766 +/− 0.014 | 0.766 +/− 0.014 | |
| CatBoost | 0.795 +/− 0.014 | 0.768 +/− 0.010 | 0.768 +/− 0.010 | 0.768 +/− 0.010 | |
| TabNet | 0.782 +/− 0.013 | 0.760 +/− 0.010 | 0.760 +/− 0.010 | 0.760 +/− 0.010 | |
| SMOTE | Logistic | 0.798 +/− 0.015 | 0.767 +/− 0.012 | 0.767 +/− 0.012 | 0.767 +/− 0.012 |
| Random forest | 0.776 +/− 0.025 | 0.752 +/− 0.023 | 0.754 +/− 0.018 | 0.753 +/− 0.020 | |
| AdaBoost | 0.725 +/− 0.019 | 0.715 +/− 0.021 | 0.715 +/− 0.021 | 0.715 +/− 0.020 | |
| XGBoost | 0.782 +/− 0.029 | 0.750 +/− 0.044 | 0.752 +/− 0.036 | 0.751 +/− 0.042 | |
| Neural Network | 0.795 +/− 0.020 | 0.764 +/− 0.019 | 0.765 +/− 0.014 | 0.765 +/− 0.015 | |
| LightGBM | 0.792 +/− 0.014 | 0.766 +/− 0.014 | 0.766 +/− 0.014 | 0.766 +/− 0.014 | |
| CatBoost | 0.794 +/− 0.014 | 0.767 +/− 0.012 | 0.767 +/− 0.012 | 0.767 +/− 0.011 | |
| TabNet | 0.786 +/− 0.016 | 0.763 +/− 0.013 | 0.763 +/− 0.013 | 0.763 +/− 0.013 | |
| ADASYN | Logistic | 0.798 +/− 0.015 | 0.767 +/− 0.012 | 0.767 +/− 0.012 | 0.767 +/− 0.012 |
| Random forest | 0.773 +/− 0.033 | 0.751 +/− 0.025 | 0.753 +/− 0.020 | 0.751 +/− 0.025 | |
| AdaBoost | 0.727 +/− 0.028 | 0.718 +/− 0.018 | 0.718 +/− 0.018 | 0.718 +/− 0.018 | |
| XGBoost | 0.781 +/− 0.032 | 0.754 +/− 0.035 | 0.756 +/− 0.029 | 0.755 +/− 0.032 | |
| Neural Network | 0.795 +/− 0.021 | 0.764 +/− 0.018 | 0.766 +/− 0.013 | 0.766 +/− 0.014 | |
| LightGBM | 0.792 +/− 0.015 | 0.766 +/− 0.014 | 0.766 +/− 0.014 | 0.766 +/− 0.014 | |
| CatBoost | 0.795 +/− 0.014 | 0.768 +/− 0.010 | 0.768 +/− 0.010 | 0.768 +/− 0.010 | |
| TabNet | 0.783 +/− 0.016 | 0.759 +/− 0.014 | 0.759 +/− 0.014 | 0.759 +/− 0.014 | |
| ROS | Logistic | 0.798 +/− 0.015 | 0.767 +/− 0.012 | 0.767 +/− 0.012 | 0.767 +/− 0.012 |
| Random forest | 0.781 +/− 0.018 | 0.755 +/− 0.022 | 0.757 +/− 0.018 | 0.755 +/− 0.023 | |
| AdaBoost | 0.725 +/− 0.016 | 0.714 +/− 0.014 | 0.714 +/− 0.014 | 0.714 +/− 0.014 | |
| XGBoost | 0.786 +/− 0.019 | 0.750 +/− 0.047 | 0.752 +/− 0.040 | 0.755 +/− 0.029 | |
| Neural Network | 0.799 +/− 0.015 | 0.761 +/− 0.022 | 0.763 +/− 0.017 | 0.763 +/− 0.017 | |
| LightGBM | 0.793 +/− 0.014 | 0.767 +/− 0.013 | 0.767 +/− 0.013 | 0.767 +/− 0.013 | |
| CatBoost | 0.794 +/− 0.013 | 0.767 +/− 0.010 | 0.767 +/− 0.010 | 0.766 +/− 0.010 | |
| TabNet | 0.780 +/− 0.014 | 0.760 +/− 0.014 | 0.760 +/− 0.015 | 0.759 +/− 0.014 | |
| PIA-Soft (Ours) | 0.807 +/− 0.016 | 0.788 +/− 0.013 | 0.788 +/− 0.013 | 0.788 +/− 0.013 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Munkhdalai, L.; Ryu, K.H.; Namsrai, O.-E.; Theera-Umpon, N. A Partially Interpretable Adaptive Softmax Regression for Credit Scoring. Appl. Sci. 2021, 11, 3227. https://doi.org/10.3390/app11073227
Munkhdalai L, Ryu KH, Namsrai O-E, Theera-Umpon N. A Partially Interpretable Adaptive Softmax Regression for Credit Scoring. Applied Sciences. 2021; 11(7):3227. https://doi.org/10.3390/app11073227
Chicago/Turabian StyleMunkhdalai, Lkhagvadorj, Keun Ho Ryu, Oyun-Erdene Namsrai, and Nipon Theera-Umpon. 2021. "A Partially Interpretable Adaptive Softmax Regression for Credit Scoring" Applied Sciences 11, no. 7: 3227. https://doi.org/10.3390/app11073227
APA StyleMunkhdalai, L., Ryu, K. H., Namsrai, O.-E., & Theera-Umpon, N. (2021). A Partially Interpretable Adaptive Softmax Regression for Credit Scoring. Applied Sciences, 11(7), 3227. https://doi.org/10.3390/app11073227