2. Materials and Methods
National health agencies, as of January 2021, have approved [
51] six vaccines for public use, including:
Tozinameran from US-German cooperation Pfizer–BioNTech;
BBIBP-CorV by Chinese Sinopharm;
CoronaVac by Chinese Sinovac;
Ad5-nCoV by Chinese CanSino Biologics;
mRNA-1273 by US Moderna and its partner Johnson and Johnson;
Gam-COVID-Vac by Russian Gamaleya Research Institute.
The three Chinese vaccines have been approved for use solely within China. The Russian one has been approved in Russia, Belarus, and Argentina and the Moderna–Johnson and Johnson vaccine for North America use (US and Canada). On the other hand, the Pfizer vaccine has had a wider adoption, having secured the approval of EU countries, the UK, US, and Canada, and 14 other countries on different continents. Among others, there is also the Oxford vaccine from British–Swedish Astrazeneca. Authorization and planning strategies differ among individual countries.
Only three of these companies have an Instagram account: Pfizer (pfizerinc), AstraZeneca (Astrazeneca) and Johnson and Johnson (jnj). The dates that these accounts have been created can be retrieved by the ‘About…’ option found on Instagram mobile application only. Moreover, at the time of writing (27 December 2020) their posts/and rate of posting, followers and following are shown on
Table 2:
Using Instaloader [
52], an open-source tool for downloading Instagram images and videos along with their captions and other metadata, we extracted all of
Table 2 posts from the three official company accounts. Each post consists of a .txt file with the post text, one or more images and/or videos (.jpg/.mp4) and a .json file containing additional metadata about the post.
We have developed a generic Python script to iteratively process all posts’ files as these reside in separate account folders and extract various post statistics. Using regular expressions in metadata files’ text, we also find and report comments, likes, and other related information. Comments and likes can be seen as the two most important actions that a user may engage in regarding a post and are the best representatives of active and passive interactions respectively. Post data and metadata information are arranged in a Pandas dataframe with features as columns:
DateTime, the date and time of post in UTC standard;
PostText, the text body of the post;
PostChars, the number of post characters;
PostWords, the number of post words;
HashTags, contained in post;
Likes, the number of likes scored;
Comments, the number of comments made;
Images, the number of uploaded images;
Videos, the number of uploaded videos, if any;
VGG16, image classification output from pretrained VGG16 model, as a list in case of more images;
InceptionV3, image classification output from pretrained InceptionV3 model, as a list in case of more images;
ResNet50, image classification output from pretrained ResNet50 model, as a list in case of more images.
For the last three columns, we employ a process known as Transfer Learning where deep pretrained neural network models can be downloaded and used as a starting point to build models for different than the original classification or regression tasks, based usually on image or text features. There are usually three different approaches on how to utilize the pretrained models:
Pretrained models used directly as classifiers in an application to classify new images;
Pretrained models used as feature extractors, with features subsequently be used as input to another model;
Pretrained models used for better weight initialization of the new integrated model.
The first approach is naturally the simplest and less time-consuming one. Approaches 2 and 3 need new models to be designed and re-training is essential. In our case we opted for the first approach, but chose three different computer vision convolutional neural network models, perhaps the three most popular ones:
VGG16 [
53] from Oxford Visual Geometry Group, where 16 refers to the number of layers, with VGG19 also available. Innovative for introducing consistent and repeating structural blocks
InceptionV3 [
54] where inception modules, blocks of parallel convolutional layers with different sized filters are introduced
ResNet50 [
55] where residual modules are introduced. These employ unweighted, shortcut connections that memorize, e.g., input to later layers in the network architecture
These models are available under Keras and can be downloaded pre-trained on ImageNet. ImageNet is a large visual database, popular as a benchmark for visual object recognition tasks. ImageNet comprises 14 million color images and more than 20,000 object classes. To be used as standalone classifiers in our case some preprocessing has to be performed. The complete flow is as follows:
Load each image and resize it according to model (224 × 224 for VGG16 and ResNet50, 299 × 299 for InceptionV3)
Convert the color image to a Numpy array
Extract the three (or four in case of .png) color channels and reshape as a single one-dimensional array
Depending on model, scale pixel RGB intensities into either [0,1] (torch framework mode), [−1,+1] (tensorflow framework mode) or zero-center BGR intensities unscaled (caffe framework mode). These are internal details of the preprocess_input function, implemented differently for each model
Use the model to make predictions (probabilities) for all classes
Choose the highest probability as the most likely predicted result
The dataframe is also saved in .csv format for further processing. We have run the script for the three official Instagram accounts and results (top five rows only) are shown in
Figure 1,
Figure 2 and
Figure 3. The three classification models have not been optimized or tuned in any way. The models do not always agree with their prediction and there are quite a few cases where results are far from realistic. However, they correctly recognize people, e.g., in lab coats or scientific instruments.
A quick way to gain insight of the images used in the companies’ posts is via word clouds, as seen on
Figure 4, generated from all three model predictions for each company. It can be observed that companies post photos of their employees or other persons very frequently, thereby classifying the images as clothing items or another prop. They also upload graphic images which are identified accordingly, e.g., ‘web_site’.
By manual inspection of the results, we can confirm that there are cases where all three models agree in their ImageNet class predictions, cases where two of them agree and others where there is disagreement between them. There are also cases where all three models fail to correctly identify the image objects. As an example, the following
Figure 5 depicts images in pfizerinc posts where: (a) there is correct classification by all three models; (b) there is disagreement by one model; and (c) all of the models disagree, while at the same time none of them correctly identifies the image class.
The models’ prediction for the object classes were structured together in a new dataframe to facilitate the quantitative assessment of results. The models’ responses were merged in a single prediction in cases of total agreement (3/3) and partial agreement (2/3) with a simple voting scheme. For the cases of complete disagreement, we have opted to keep the prediction made by the Resnet50 model as it slightly outperforms InceptionV3 in accuracy for the ImageNet classification task (
https://paperswithcode.com/sota/image-classification-on-imagenet (accessed on 29 January 2021)). By accounting for multiple-image posts, we end up with a dataframe having 536 predicted image classes for pfizerinc, 1365 predicted image classes for astrazeneca and 64 predicted image classes for jnj. The top five rows for this new dataframe are shown on
Figure 6:
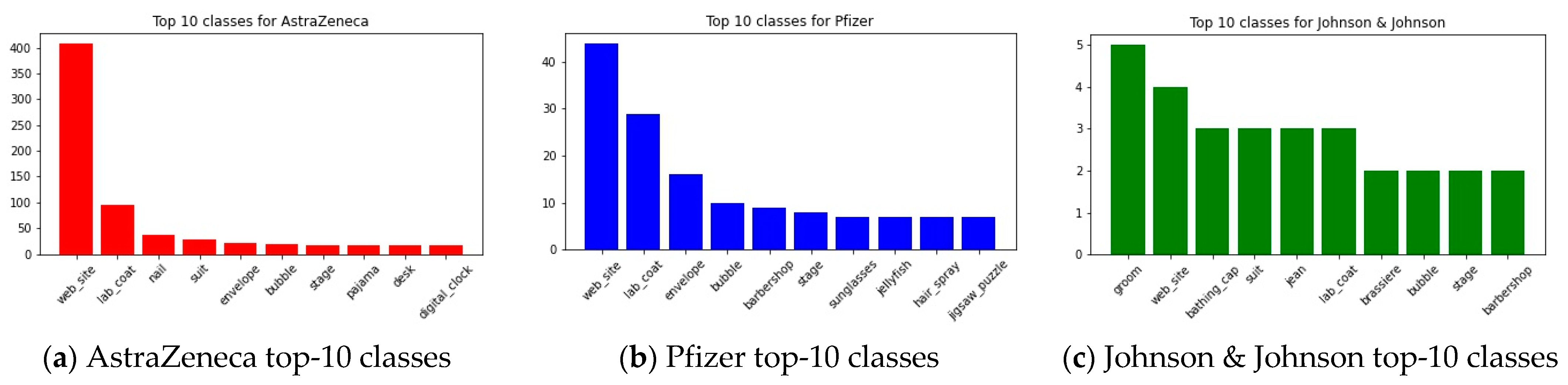
Creating dictionaries for the images’ classes, we can plot the top-10 most common encountered classes for the three companies, as shown on
Figure 7. We can infer that AstraZeneca mostly post synthetic images with some text superimposed, thus classified as ‘web_site’, followed by clothing items (‘lab_coat’) which denotes the presence of a human. The same applies to Pfizer, with results however following a flatter distribution. Johnson & Johnson, on the other hand, prefer posting images of humans, although their number of posts is significantly lower.
Rather than just classifying the images in posts (and in fact single objects), it would be interesting to employ automatic caption generation, a process to textually describe the whole image scene. As Instagram is to a large extent image-powered (vs, e.g., Twitter) and images are naturally information-richer, this approach would result in more information being extracted and perhaps facilitate even sentiment analysis to be performed on images, rather than just text. Automatic caption generation is a particularly challenging active research application area field that lies on the intersection of natural language processing and computer vision. This task is significantly harder than image classification as it requires detecting all objects in a scene and how they relate to each other. We have had some initial experimentation with different encoder-decoder architectures, where a Convolutional Neural Network usually encodes the images and a Recurrent Neural Network, e.g., a LSTM (Long Short Term Memory) network, is employed to act as encoder/decoder between the text sequence and its vector representation. However, results were not that satisfactory and as extensive tuning and re-training with a GPU is needed; we opted not to pursue this approach any further.
3. Results
Reverting to textual information,
Table 3 displays the mean and standard deviation (in parentheses) values for the associated dataset features for the three companies. Although there is some difference in the number of posts for each company, it can be observed that while Johnson & Johnson is significantly less active in posting than the other two companies, they do post longer messages. Their messages also contain more hashtags, receive more likes and comments, and are richer (or at least as rich) in images and videos.
The official companies’ posts are a means of gaining insight into how their social media strategy expresses their policies, how it informs and promotes their products and services. Some degree of user perception can be measured with likes and comments, as these are the most user-familiar ways of passive and active interaction. The number of likes does carry an inherent positive sign; however, comments do not necessarily do so. Thus, in order to measure users’ perception we subsequently downloaded posts containing the three respective hashtags: #pfizer, #astrazeneca, and #jnj. We opted to download these posts for December 2020 and onwards, as it is the month just before and during the first vaccinations took place. We also opted to download posts only from public accounts. The total number of anytime hashtag-containing posts are (as of 27 December 2020); 99.519 for #pfizer, 26.222 for #astrazeneca, and 118.282 for #jnj. It is interesting that #jnj is significantly adopted by users, although the company Instagram profile is not as active as the other two. This may be justified by the company’s more recognizable brand and wider product range. For December 2020, we ended up with 646 public posts for #pfizer, 738 public posts for #astrazeneca, and 70 public posts for #jnj.
As before, using a similar Python script we have constructed a single dataframe, consisting of all the three hashtag containing user posts text, i.e., 1454 rows. The reason for doing so is partially due to #jnj being underrepresented and to the fact that we would like to increase our sample size for training purposes, as discussed later. Having a first look at the user posts we observe that there are different post languages and that the use of emojis is quite frequent, as seen in
Figure 8, so although emojis could be utilized, some preprocessing is deemed essential:
Google’s Python module CLD2 (Compact Language Detection) is based on a Naive Bayesian classifier and can identify up to three languages in a document and their associated probabilities. Keeping the highest probability for each post we detected its language, except for two unidentified language posts (‘un’) and results are shown in
Figure 9:
Detecting the English language for a post does not necessarily imply that it is completely free of non-English words and characters. In our study, this was shown later when we performed text ‘cleaning’. Our first preprocessing step was to filter out non-English language posts, so the new dataframe consisted of 675 English language posts: 339 for #pfizer, 291 for #astrazeneca, and 45 for #jnj. Our aim here was to classify users’ communication intents. Intent classification differs from sentiment and opinion mining, as it focuses on futuristic action rather than the current state of feelings [
56]. Four intent classes were specified, motivated by the works of [
57,
58] and were partially adopted and modified to fit in our context:
‘Acknowledge’ (ACK), for generic statements, reporting facts and sharing experience
‘Advise’ (ADV), for suggestions, recommendations, giving guidelines or offering help
‘Seek’ (SEK), for seeking help, advice, comments, or answers
‘Express’ (EXP), for any kind of expression, feeling, or thought, positive or negative (hybrid intent-sentiment)
These were label-encoded, leading to a multi-label classification problem, with all the challenges this may entail (most notably imbalanced classification). To construct the necessary annotated dataset, we employed INCEpTION [
59], an open-source semantic annotation tool which enables automatic text labelling at different levels; word entities, sentences or larger documents. After manual annotation of 100 posts, the tool’s recommender subsystem, a multi-token sequence classifier based on OpenNLP NER (named entity recognition) model, proposed the remaining post labels, which were human-inspected and either accepted or corrected. Degree of acceptance was quite high.
Table 4 displays the annotation results for the three hashtag containing posts, with ACK and SEK being larger and smaller respectively for #pfizer and #astrazeneca. The case of #jnj is different as there were a lot of EXP posts and by manual inspection we did verify that there were not as many COVID-19-related posts, but other cosmetic product related ones. As vocabulary is also different, this may have had its impact on the annotation process:
The 675 annotated English posts were further preprocessed by the following text ‘cleaning’ pipeline steps, where string handling routines and NLTK (Natural Language Tool Kit) were mostly utilized:
Substitute any other, possibly remaining, words containing language characters, accents, etc., with their closest ASCII equivalent, as user posts can be very noisy (e.g., changing the Greek word ‘ελληνικά’ to ‘ellenika’);
Remove URLs in posts, as they are also frequently used, using regular expressions;
Tokenize text and remove punctuation, using NLTK regular expressions tokenizer;
Convert all tokens to lower case, using python’s string method;
Normalize text, using NLTK lemmatization for verbs, nouns and adjectives;
Remove tokens than contain non-alphabetic characters, e.g., numbers, using python’s string method;
Remove English ‘stop words’, words of less importance that appear quite frequently in natural speech, using NLTK;
Remove any remaining non-English, or English un-normalized words (e.g., ‘amigo’, ‘yeaah’, ‘lol’) that may have survived in post, using NTLK corpus.
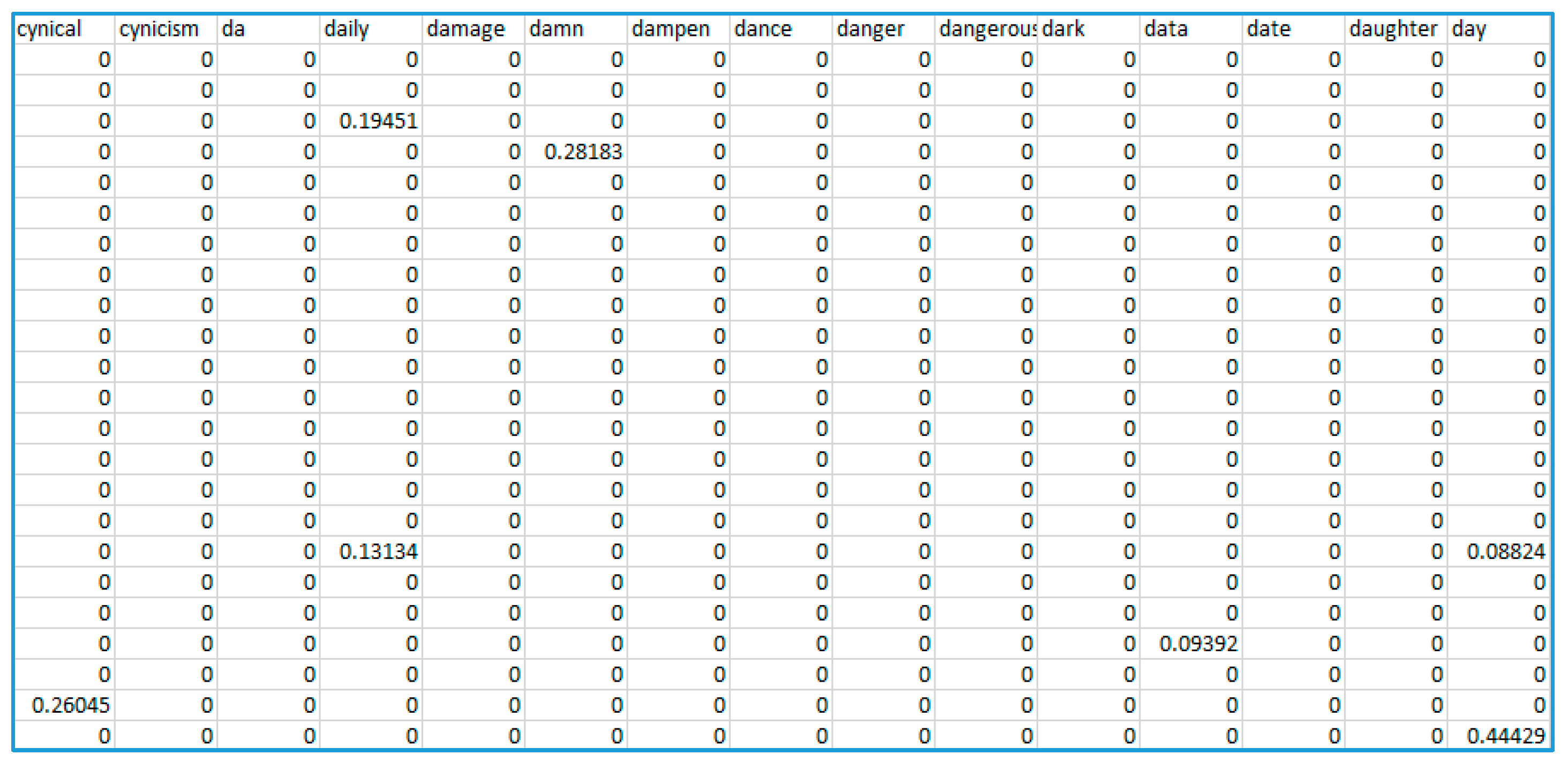
Stemming and lemmatization are the most popular normalization methods. Stemming refers to the process of transforming derivatives words to their root; however, with some undesired effects, e.g., trouble→troubl. Lemmatization refers to the process of grouping different word forms together, so that they can be analyzed under a single ‘lemma’, e.g., ‘better’ and ‘best’ could be lemmatized as ‘good’. The last is an example of adjective lemmatization. Lemmatization can also be applied to nouns (tables→table) and verbs (giving→give). Finally, the most important step of text preparation that was carried out was vectorization, a process that converts words (or tokens) to numerical feature representations. Popular vectorization approaches can utilize different models; Bag-of-Words (BoW) term frequency model, L1-normalized term frequency model, and L2-normalized TF-IDF (Term Frequency—Inverse Document Frequency) model. More recently, models that employ word embeddings are considered; Word2Vec/Doc2Vec (Google), GloVe (Stanford University) and fastText (Facebook). In our case, the corpus of 675 posts was TF-IDF vectorized using scikit-learn feature extractor. An excerpt from the vectorized, sparse dataset is shown in
Figure 10. The vocabulary (attributes) consisted of 3024 words:
The final vectorized and annotated dataset was split, using 10-fold cross validation, into two subsets for training and testing respectively. These subsets were used to train nine weka classifiers with their default configuration: one linear one, Logistic Regression (LOG), seven non-linear ones, Naïve Bayes (NB), C4.5 Decision Tree (DT), k-Nearest Neighbour (KNN), Support Vector Machine (SVM), Multi-Layer Perceptron (MLP), Bayes Net (BN), Logistic Model Tree (LMT), and one ensemble classifier, Random Forest (RF). The objective here was to evaluate the classifiers’ performance and choose the best suited algorithm for building a predictive model. The baseline performance was set by using the Zero-Rule (ZR) classifier which simply predicts the dataset class mode. In our case this was ‘ACK’ with 282 instances over a total of 675, thus an accuracy of 41.8%. Results are reported on
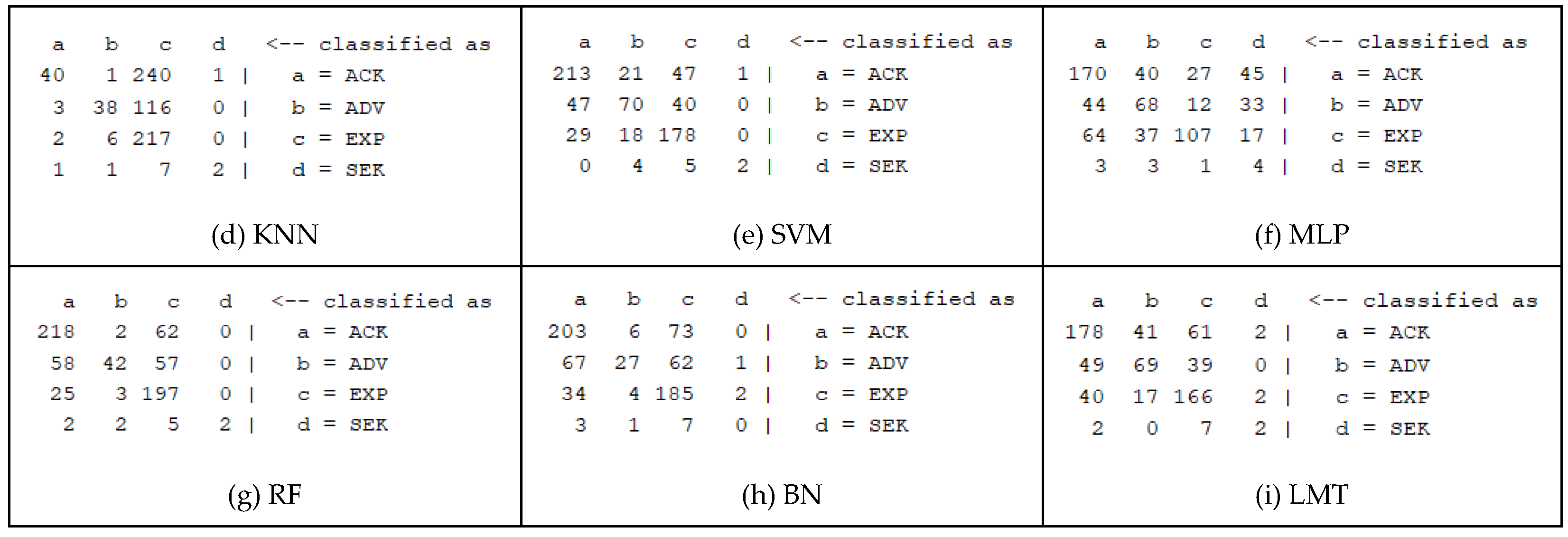
Table 5. Reducing the vocabulary by keeping only the, e.g., 1000 top words, did not improve the accuracy. Similarly, considering bigrams as well as unigrams led to worse results. However, it would be expected to improve with more data, i.e., more posts. Further individual parameter tuning for each algorithm might have also yielded better results. Different metrics are also reported (weighted averages) such as: Mathews Correlation Coefficient (MCC), Receiver Operating Characteristic (ROC) area, F-measure (harmonic precision-recall mean), and Cohen’s Kappa metric, with the last two suggested as more appropriate for imbalanced classification tasks. Confusion matrices (
Figure 11) are also useful for showing the numbers of true and false predictions for each class.
From these initial results we can infer that the SVM and RF classifiers seem more promising and require further investigation. In fact, a simple voting (averaging probability rule) scheme derived from these two classifiers gave a joint accuracy of 69.3%, with improvements in all other metrics as well. Other popular ensemble techniques are bootstrap aggregation (bagging, as in RF), boosting, and stacked generalization. Boosting the SVM or the RF classifier alone, did not improve the accuracy, with either 10 or 100 models. Stacking the two classifiers, with logistic regression as the meta-classifier rule, yielded an accuracy of 70.5%.
To validate our initial algorithm ranking, we design a controlled experiment where the top 5 classifiers (SVM, RF, DT, BN and LMT) were further analyzed. With the experiment, a result dataset of 500 rows was created (5 algorithms ×10-fold cross validation × 10 times run) and statistical tests (corrected paired T-tests) could be carried out on different performance evaluation metrics. The base algorithm was SVM. Reasonable assumptions about Gaussian distributions were made and significance level was set to 0.05.
Figure 12 shows that all four algorithms have worse accuracy than SVM, with results being significant (at the 0.05 confidence level, as denoted by the '*' symbol next to results) for DT, BN, and LMT. Thus, SVM and RF (with not significantly different results, as denoted by the absence of any symbol) are indeed the best choices, with accuracies as shown and standard deviations of 4.83 and 4.66 respectively. Similar controlled experiments can be set out for individual algorithm parameter tuning.
Therefore, in a potential, real-world application the finalized (trained on the entire dataset) model could be leveraged to automatically classify new posts as they are uploaded, e.g., in real-time or daily and automatically predicting and classifying the users’ communication intents for a company’s monitoring purposes and beneficiary goals.
With sentiment analysis, very frequently apart from opinion mining, the process also extracts the expression attributes, e.g., polarity, subject, and opinion holder. Subjectivity/Objectivity classification can also be performed, as well as retrieval of direct/comparative and explicit/implicit opinions. There have also been research efforts to detect affects within text. A list of six basic emotions is given in [
60]: happiness, sadness, surprise, anger, disgust, and fear. Ekman later expanded his list [
61] to include pride, shame, embarrassment, and excitement, while other researchers have additionally considered trust and anticipation [
62], or guilt and shyness [
63]. More recently, 27 discrete emotions were identified by self-reporting, in a study by Keltner and Cowen [
64].
Obviously, text must be vectorized if any sentiment analysis is to be performed. With Bag-Of-Words models, the ordering of words is not considered, thereby producing sparse numerical arrays for word representations. However, with Embedding models the position of words is learned from text, based on surrounding words and dense vector word projections are obtained. In the context of this work we trained a Convolution Neural Network (CNN) on the IMDB dataset for 100 epochs, under Keras, which supports Embedding layers. The CNN consisted of the following sequential layers and respective hyperparameter settings:
Embedding layer where input_dim = 100,000, output_dim = 32, input_length = 1000;
Conv1D layer with filters = 32, kernel_size = 3, size = ‘same’, activation = ‘relu’;
MaxPooling1D layer with pool_size = 2, strides = 2;
Flatten layer where the previous layer’s 2d output is flattened to a 1d vector;
Dense layer with 500 fully connected units, activation = ‘relu’;
Dense layer with a single output neuron, activation = ‘sigmoid’.
The CNN model was configured to utilize logarithmic loss (binary_crossentropy) and the ADAM optimization procedure. There was a total of ~11M trainable parameters and without any further hyperparameter tuning, it achieved an accuracy of 86.6%. Deploying the model on the 675 English language posts, we obtained a list of sentiment polarity scores, with values in interval [0,1] (negative to positive respectively). The overall sentiment was 0.38, neutral to negative, with a rather large standard deviation however of 0.45. Results for posts corresponding to the three hashtags are shown on
Table 6 and distributions in
Figure 13. Posts made for #pfizer seem to be more positive than the other two hashtags and standard deviations are in all cases large. Distributions are also highly polarized towards the ends of the interval, with many positive and negative results. In any case, one does not have to neglect the fact that users’ short posts are very frequently full of peculiarities and cannot be considered as ‘proper text’.
4. Discussion
In this paper, we performed an analysis of textual and visual features regarding the Instagram posts of the three vaccine-offering companies, during the onset period of the first vaccinations. Our results can be compared with other studies, e.g., [
41], as we too found out that the companies post images of people to a large extent and users highly discuss the arrival of the vaccines and engage in opinion sharing with respect to their success.
Our research has shown that only three companies have an active account on Instagram, i.e., Pfizer, Astrazeneca, and Johnson & Johnson. Astrazeneca has had an Instagram account longer than the other two, and has had the most posts and the highest rate of posting, but the lowest number of followers. By descriptive statistics, we infer that Johnson & Johnson post less frequently than Pfizer and Astrazeneca, but when they do post, their posts are lengthier. Moreover, their posts contain more hashtags, receive more likes and comments, thus having a greater impact on users. This can be attributed to the fact that Johnson & Johnson is a larger company with a wider range of products, e.g., cosmetics. Their posts additionally include more images and videos. Regarding the images posted, the study has shown that all three companies upload photos of their employees or other persons, classifying the images as clothing items or props, e.g., stethoscope or microscope. Moreover, the image classification outputs from the three models have been organized as a dataset enabling the quantitative and qualitative assessment of results, which is demonstrated and discussed. AstraZeneca mostly post synthetic images followed by images of humans. The same applies to Pfizer, with results however following a flatter distribution. Johnson & Johnson on the other hand, prefer posting images of humans, although their number of posts is significantly lower.
With respect to the user posts, these are to a large extent written in English, with Spanish, Portuguese, and Italian following. After filtering out non-English language posts and preprocessing, the automatic annotation process has shown that the ‘acknowledge’ class is the largest, with ‘expression’ and ‘advice’ following and a very small size for the ‘seek’ class. Thus, users’ post intent was mainly devoted to making generic statements, reporting facts, and sharing their experiences, which in this context meant their experiences after vaccination. Users do not seem to be seeking help or advice about COVID-19 or vaccination process. For the predictive modelling application, results have shown that the best performing algorithms for intent classification, were equally Support Vector Machines and Random Forest, significantly better than the rest of the suite of algorithms examined. Finally, polarity analysis on users’ posts, leveraging a convolutional neural network, reveals a rather neutral to negative sentiment, with highly polarized user posts’ distributions.
Possible future extensions to this work include: investigation of other social media platforms, for example Facebook and Twitter; investigation of other vaccine producing companies, e.g., Moderna and augment the dataset with more recent posts; employment of automatic caption generation to retrieve the textual description of the image scene rather than mere object classification; performance of sentiment analysis on other affects as well, rather than just polarity; carrying out parameter tuning to improve model’s performance, as in all of the algorithms used in this work we have mostly opted to stick to the default configurations. Due to the tremendous increase in the data volumes being produced [
65,
66,
67,
68] and the big data explosion, an investigation on the use of big data from the social media platforms could be of great importance.


 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}