4.1. Datasets
We conduct experiments on three public multimodal datasets: eNTERFACE’05, RAVDESS, and CMEW. eNTERFACE’05 [
53] is an audio-visual emotion database that contains 42 subjects, coming from 14 different nationalities. Six basic emotions are considered in this dataset, including anger, disgust, fear, happiness, sadness, and surprise. The data of this dataset are all in video format. Following [
17,
91], we extract 30 segments from each video. Then, for each segment, we use 94 mel filter banks with a 40 ms Hanning window and a 10 ms overlapping to extract the log mel spectrogram with the size of
as the audio modality. In addition, the human face with the size of
is detected by the multitask cascaded convolutional neural network (MTCNN) [
92] as the visual modality. In this way, segment samples are extracted from the original videos. Then, all samples are divided into three parts: training set, validation set, and test set. To verify that our model can cope with data insufficiency, we conduct experiments by empirically setting up training sets of three sizes: Setting1, where each emotion has 300 segment samples; Setting2, where each emotion has 1200 segment samples; Setting3, where each emotion has 2400 segment samples. It can be seen that Setting1 has the fewest samples, Setting2 has fewer, and Setting3 has the most. In each of the above three cases, our multimodal conditional GAN is trained for data augmentation. The number of segment samples per class in both the validation set and the test set is 990 to evaluate the classification performance of emotion recognition. Under Setting1, the ratio of training set, validation set, and test set is 10:33:33. The ratios of Setting2 and Setting3 are 40:33:33 and 80:33:33, respectively.
RAVDESS [
54] is a validated multimodal emotional database. It consists of 24 professional actors, vocalizing lexically-matched statements in a neutral North American accent. The data of this dataset are also in the form of video. The same six basic emotions as the eNTERFACE’05 dataset are studied here. Similar to the eNTERFACE’05 dataset, we also extract segment samples from original videos on the RAVDESS dataset and divide the samples into three parts: training set, validation set, and test set. On this dataset, we conduct experiments on training sets with three different settings: Setting1, where each emotion has 150 segment samples; Setting2, where each emotion has 300 segment samples; Setting3, where each emotion has 1200 segment samples. For the validation and test sets, each class has 870 segment samples. The ratios of training set, validation set, and test set under Setting1, Setting2, and Setting3 are 5:29:29, 10:29:29, and 40:29:29, respectively.
CMEW [
55,
56,
57] is an audio-visual emotion database collected from Chinese TV series and movies. It contains four emotional states, including neutral, sadness, happiness, and anger. Data preprocessing is similar to the eNTERFACE’05 dataset and the RAVDESS dataset. Training sets with three sizes are used to conduct experiments separately: Setting1, where each emotion has 300 segment samples; Setting2, where each emotion has 1200 segment samples; Setting3, where each emotion has 6000 segment samples. There are 3150 segment samples for each class of the validation set and the test set. The ratios of training set, validation set, and test set under Setting1, Setting2, and Setting3 are 2:21:21, 8:21:21, and 40:21:21, respectively.
4.2. Networks
In
Section 4.1, we show that the audio modality with the size of
and the visual modality with the size of
are extracted from original videos. If we directly feed them into our multimodal condition GAN, it will be difficult for our model to learn useful information from audio and visual modalities due to the high dimensionality of the multimodal data. Inspired by [
17,
44], we utilize the fully connected layer before the softmax layer of ResNet-34 [
93] to extract 512-dimensional features from the raw audio and visual modalities as the input of our framework. In other words, the dimensionality of both
and
is 512. In this way, audio and visual modalities are appropriately represented in our system. The dimensions of Gaussian noise vectors
and
are set to 50. In addition, the label
y corresponding to
and
are converted into the label embedding, and then sent to the generators of our multimodal conditional GAN along with
and
.
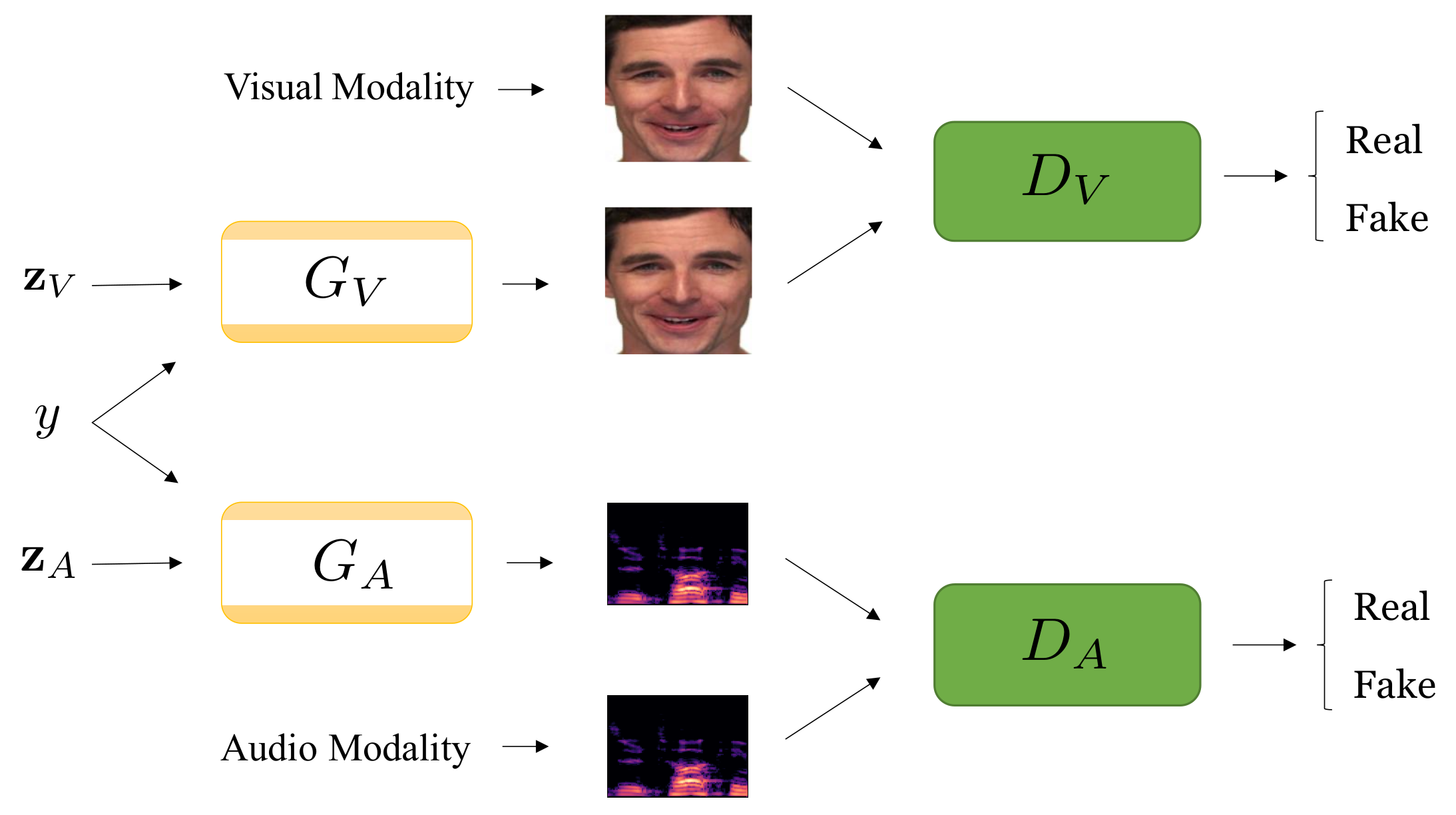
Generators and have the same architecture with four fully connected layers. The first layer is the input layer with the noise vector and the label embedding, the second layer has 128 nodes, the third layer has 256 nodes, and the last layer is the output layer with 512 nodes to generate fake audio modality or fake visual modality. The second and third layers are followed by the LeakyReLU function. Similarly, discriminators and have the same architecture. We first concatenate the label embedding with the input modality, which can be either a real modality or a fake one generated by generators. Then, we send them to the discriminator with four fully connected layers. The first layer is the input layer. Each of the following two layers has 256 LeakyReLU nodes, and the last layer has only one node to determine whether the input data is real or fake.
After generating data with our multimodal conditional GAN, we use classifiers to evaluate the generated data and perform the final emotion classification task. In [
94,
95,
96], DNN is shown to be effective in learning feature representations from audio and visual modalities. Inspired by this, we adopt DNN to design our emotion classifier. To be specific, we first concatenate the audio modality and the visual modality into a feature vector, and then send it into the DNN classifier with four fully connected layers. The first layer is the input layer with 1024 nodes. Each of the following two layers has 128 LeakyReLU nodes. The number of nodes in the last layer is the number of emotion categories (six for eNTERFACE’05 and RAVDESS, and four for CMEW).
4.3. Implementation Details
As far as we know, we are the first to design a multimodal GAN for data augmentation in the problem of audio-visual emotion recognition. Under different experimental settings, we compare our approach (Ours) with the following methods to show the superiority of our framework: (1) Baseline (A), which only uses the audio modality of the original training set for emotion classification. (2) Baseline (V), which only uses the visual modality of the original training set for emotion classification. (3) Baseline (A+V), which only uses the multimodal data of the original training set for emotion classification without data augmentation. In addition, some representative previous works of audio-visual emotion recognition are also compared, including (4) Attention Mechanism [
97], (5) Canonical Correlation Analysis (CCA) [
98], and (6) Tensor Fusion [
99]. Moreover, we report the performance of (7) Ours (wo corr), which first uses our multimodal conditional GAN without the correlation loss to generate data, and then augment the original dataset with the generated data, finally performing emotion classification with the augmented training set. By comparing the performance of Ours and Ours (wo corr), we can show the importance of the proposed correlation loss in our framework.
In the training stage, we use the segment-level samples to perform classification. After obtaining the segment-level classification results, we use the majority rule to predict the video-level emotion labels. To ensure the reliability of the experimental result, we repeat each experiment five times and use the average classification accuracy (%) as the final result. For eNTERFACE’05, RAVDESS, and CMEW, we set
to 0.001, 0.01, and 0.1, respectively. In addition, Adam optimizer [
100] with the learning rate of 0.0002 is adopted, and the batch size is set to 100. It is worth noting that our architecture is a GAN conditional on the class label. It can generate samples of different categories, which can internally prevent mode collapse [
40,
101]. In addition, inspired by [
102,
103], the above hyperparameters and network weights are carefully set to deal with other training problems of our multimodal conditional GAN. Pytorch [
104] is used to implement our architecture on an NVIDIA TITAN V GPU card.
4.4. Experiment Results
To show the effectiveness of our approach, we first compare the classification performance of our method with other methods on different datasets, including eNTERFACE’05, RAVDESS, and CMEW. On each dataset, three settings are used for experiments. Note that to take full advantage of the methods of Ours (wo corr) and Ours, false multimodal data with appropriate sizes should be generated for data augmentation. The classification accuracies of different methods on the test set are reported, as shown in
Table 1,
Table 2 and
Table 3.
We find the following summarizations: (1) Our approach achieves the highest performance compared to other methods, which shows that the data generated using our multimodal conditional GAN can significantly benefit audio-visual emotion recognition. (2) Although the classification performance of Ours (wo corr) is significantly higher than that of baseline methods, it is still lower than that of Ours, which shows that the correlation between the audio modality and the visual modality is helpful for data augmentation to improve the performance of emotion recognition. (3) In most cases, the classification accuracies of Attention Mechanism, CCA, and Tensor Fusion are higher than those of Baseline (A), Baseline (V), and Baseline (A+V), but still obviously lower than those of Ours (wo corr) and Ours. In addition, when the scale of training data is relatively small, especially in the case of Setting1, the performance of Attention Mechanism, CCA, and Tensor Fusion may be lower than that of Baseline (A+V). These findings show that the above previous works are not as effective as our method to utilize the information from the size-limited training set for classification. (4) We can further find that as the size of the original training set becomes smaller, the classification performance gap between Ours and Baseline (A+V) becomes larger. For example, on the RAVDESS dataset, the accuracy gap between Ours and Baseline (A+V) is 8.10% and 6.37% in the case of Setting1 and Setting3, respectively. This indicates that the fewer the real data, the more obvious the advantages of our approach. (5) In most cases, classification accuracies on the eNTERFACE’05 dataset and the RAVDESS dataset are higher than those on the CMEW dataset, which is consistent with the experimental results of previous works [
10,
17].
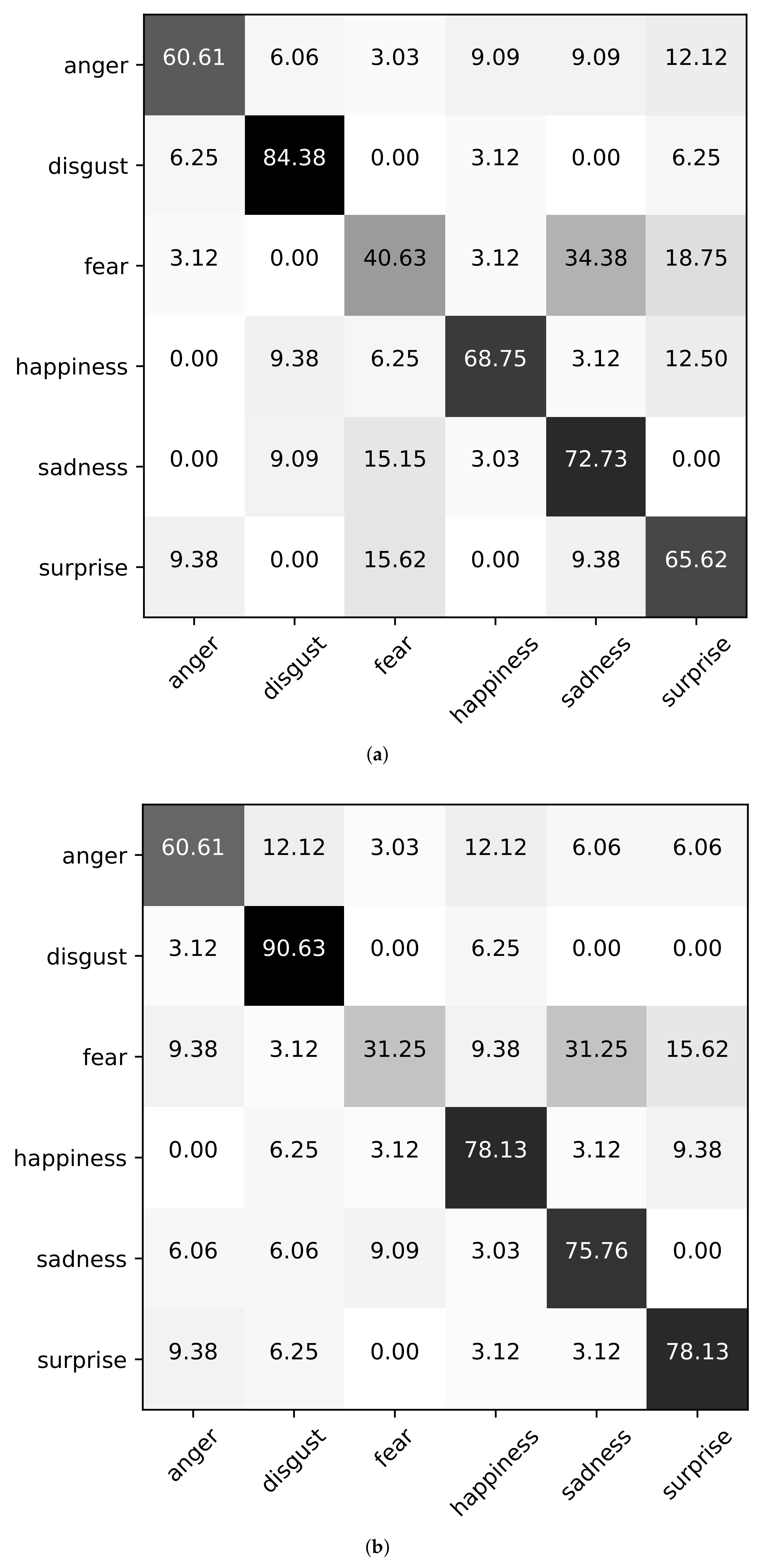
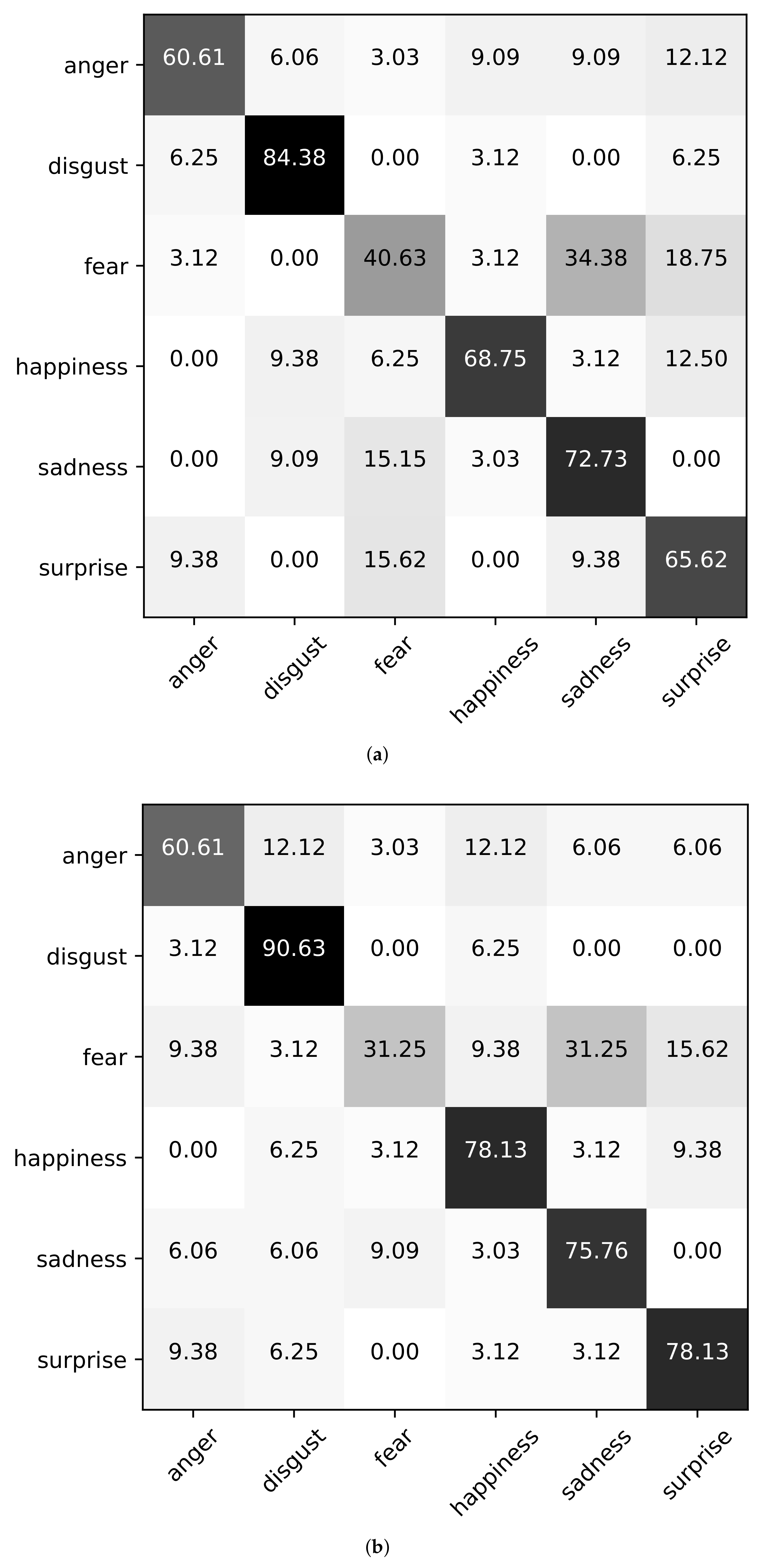
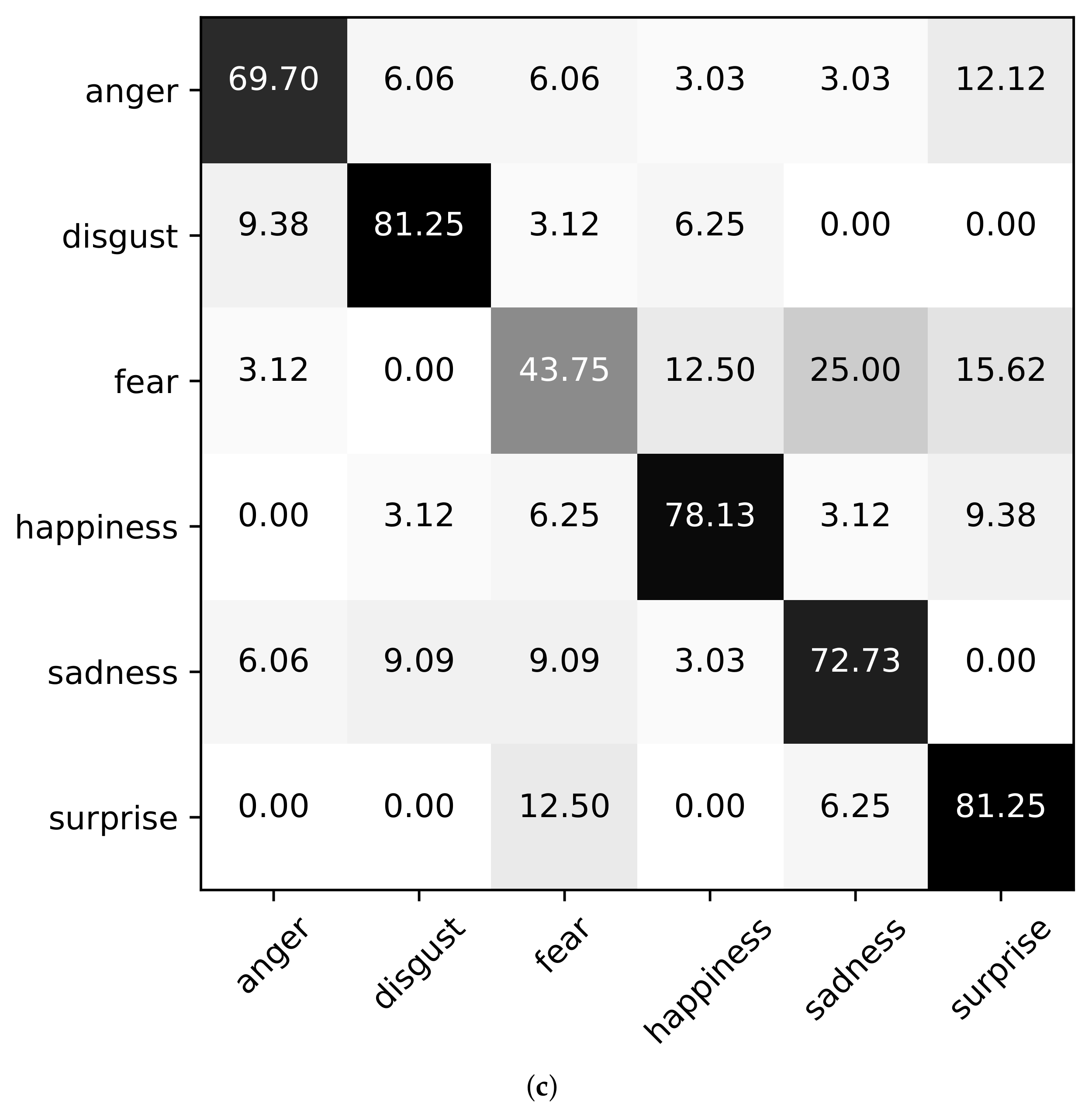
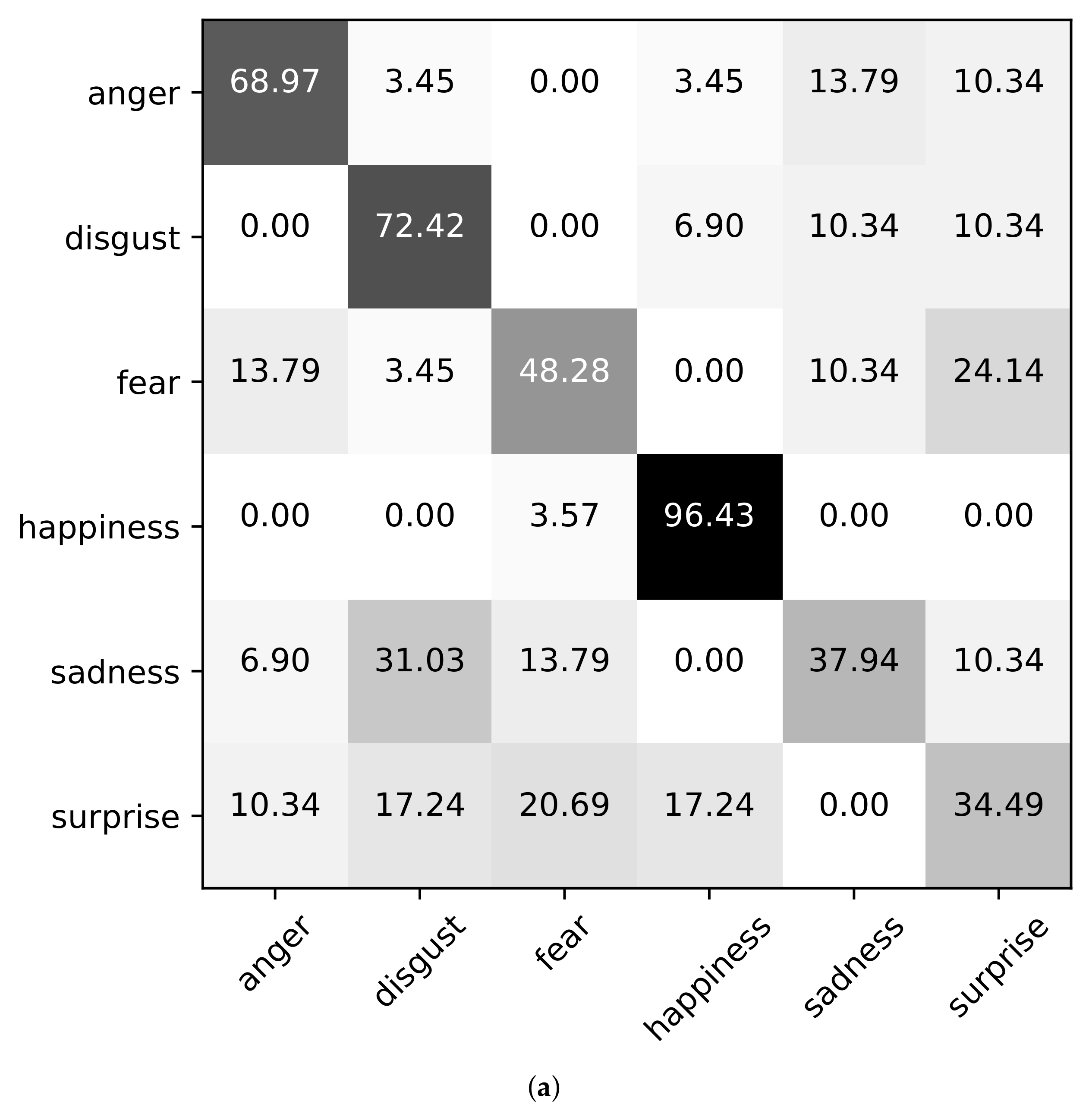
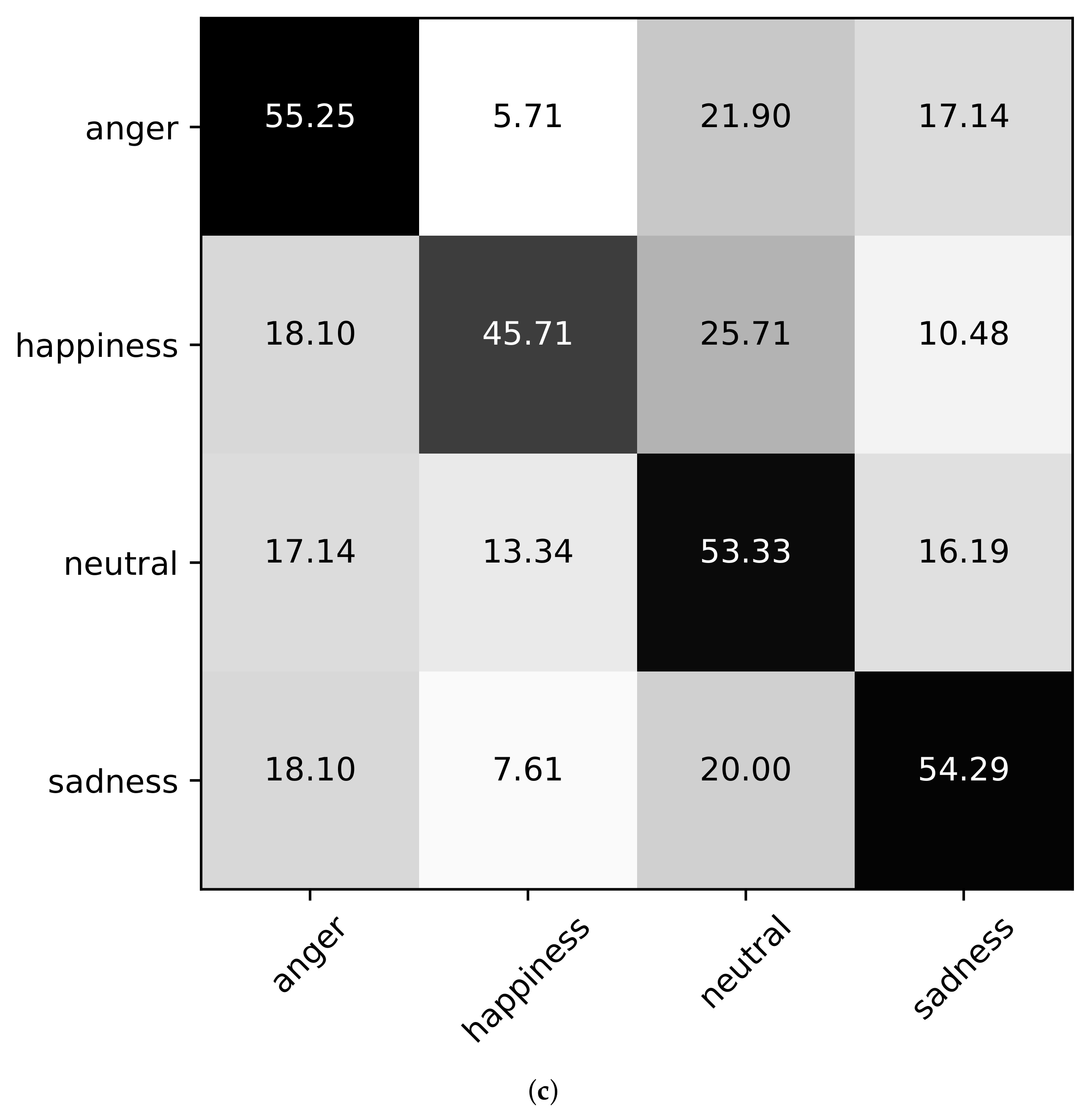
Next, we show the confusion matrices using Baseline (A+V), Ours (wo corr), and Ours in the case of Setting3 on the datasets of eNTERFACE’05, RAVDESS, and CMEW, as shown in
Figure 3,
Figure 4 and
Figure 5. It can be found that on the eNTERFACE’05 dataset, “disgust’’ is the easiest to be recognized. On the RAVDESS dataset, “happiness” is the easiest to be recognized. On the CMEW dataset, “anger” is the easiest to be recognized. This shows that different datasets have different emotional cues. In addition, we can further find that for a few emotions, the classification accuracy using Baseline (A+V) may be higher than that using Ours (wo corr) or Ours, such as “disgust” on the RAVDESS dataset and “anger” on the CMEW dataset. However, for most emotions, the classification accuracy using Ours (wo corr) or Ours is higher. This shows that Ours (wo corr) or Ours can more effectively use the information of most emotions for the classification task.
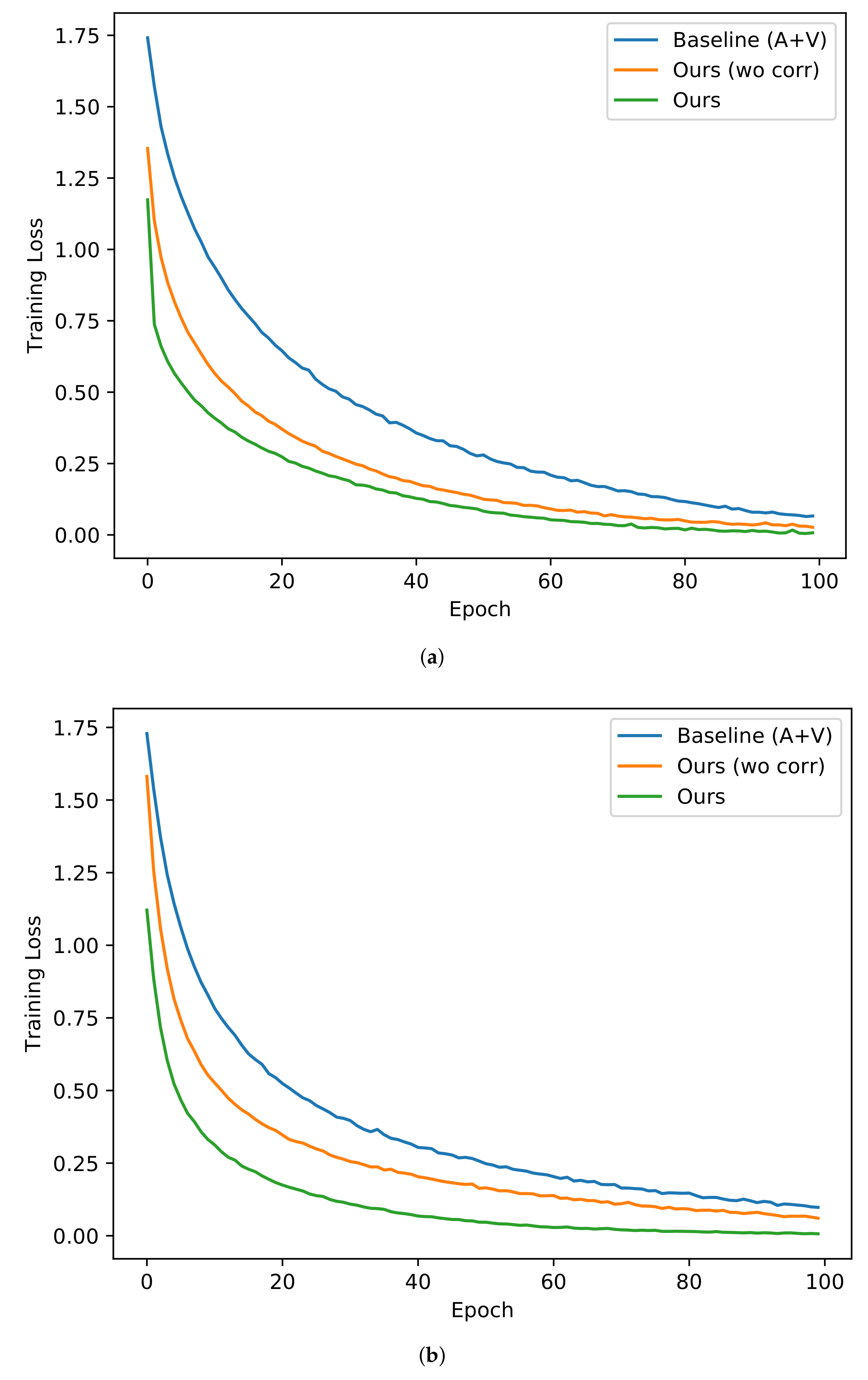
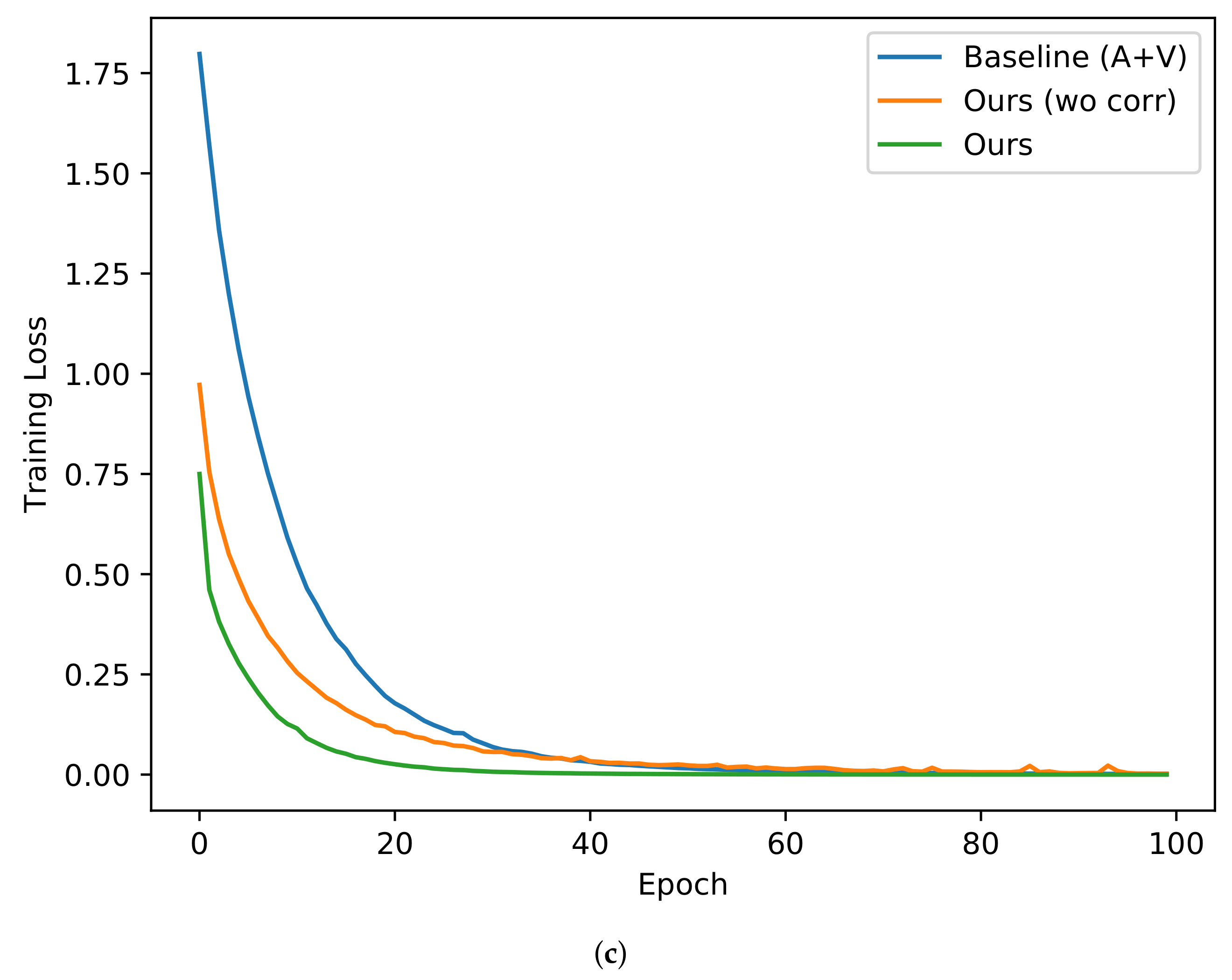
In the above discussion, we show that our approach can efficiently help improve the classification accuracy on the test set. Inspired by [
105], we next study the impact of the data generated by our multimodal conditional GAN on the training speed. On the datasets of eNTERFACE’05, RAVDESS, and CMEW, we plot the training loss with epochs of the DNN classifier in different methods, as shown in
Figure 6. It is worth pointing out that the DNN classifier in Baseline (A+V) only uses the original training set for training, while the DNN classifier in the method of Ours (wo corr) or Ours uses the real data and generated data together for training. It can be found that the training loss of our approach decreases the fastest with epochs, which means that its convergence is the fastest, the convergence of Ours (wo corr) is the second fastest, and the convergence of Baseline (A+V) is the slowest. This shows that in addition to helping improve the accuracy of emotion classification, our framework can effectively speed up the training of the emotion classifier.
When analyzing the experimental results in
Table 1,
Table 2 and
Table 3, we mention that when using Ours or Ours (wo corr), it is necessary to generate new data of appropriate size. Here, we discuss what scale of generated data is appropriate under different settings. We name the ratio of the size of the generated data to the size of the original training set as the augmentation ratio. It is used to measure the scale of the generated data compared to the original training set. Then, we analyze the classification performance of the methods of Ours and Ours (wo corr) with six augmentation ratios, including 0.5, 1, 2, 3, 4, and 5. The augmentation ratio of 2 means that the size of the generated data is twice the size of the original training set. Other ratios are represented in the same way. The experimental results on the datasets of eNTERFACE’05, RAVDESS, and CMEW are shown in
Table 4,
Table 5 and
Table 6, respectively.
We can find that on each setting, there is an augmentation ratio with the highest classification accuracy for Ours or Ours (wo corr). We can call this augmentation ratio the most appropriate augmentation ratio. In most cases, when the augmentation ratio is lower than the most appropriate augmentation ratio and increases, the corresponding classification accuracy also increases, while when the augmentation ratio is higher than the most appropriate augmentation ratio and increases, the corresponding classification accuracy decreases. For example, on Setting2 of the eNTERFACE’05 dataset, the most appropriate augmentation ratio is 3 for Ours. When the augmentation ratio increases from 0.5 to 1, 2, and then to 3, the corresponding classification accuracy also increases. However, when the augmentation ratio increases from 3 to 4 and then to 5, the corresponding classification accuracy becomes smaller. The reason behind this phenomenon may be that when the augmentation ratio is relatively small, the generated data is not enough for data augmentation effectively. Therefore, with the increase of augmentation ratio, the corresponding classification performance is improved. However, when the augmentation ratio is too large, the generated data may obscure the information of the original training set, which weakens the effect of data augmentation. Driven by these factors, we emphasize that the augmentation ratio should be selected appropriately for data augmentation.
From
Table 4,
Table 5 and
Table 6, it can be further found that when the scale of the original training set is relatively small, the augmentation ratio should be set larger, i.e., more generated data can be used for data augmentation, while when the scale of the original data is relatively large, the augmentation ratio should be set smaller. For example, on the eNTERFACE’05 dataset, the sizes of Setting1 and Setting2 are relatively small, and it is more appropriate to set the augmentation ratio to 2 or 3, while Setting3 has more samples, and it is better to set the augmentation ratio to 1. The RAVDESS dataset and the CMEW dataset are similar to the eNTERFACE’05 dataset. In addition, we can see that the classification performances of Ours and Ours (wo corr) have a similar trend with the augmentation ratio, but the classification performance of Ours is higher than that of Ours (wo corr) under each setting. For example, on the eNTERFACE’05 dataset, the most appropriate augmentation ratios of Ours or Ours (wo corr) are 3 and 2, respectively, for Setting2 and Setting3. However, under these two settings, the classification accuracy of Ours is 1.55% and 2.06% higher than that of Ours (wo corr), respectively, which again shows the importance of capturing the correlation between the audio modality and the visual modality in our framework.
Furthermore, we show that our multimodal conditional GAN can deal with the problem of class imbalance of the training data. We conduct experiments on the datasets of eNTERFACE’05, RAVDESS, and CMEW. As shown in previous works [
88,
106], the majority-to-minority class ratio is high in real-world class imbalance problems. Inspired by this, we consider two different training sets: Case1 and Case2. For the training set of Case1, there are 300 samples for a class, and 1200 samples for each of other classes. For the training set of Case2, there are 150 samples for a class, and 1200 samples for each of other classes. It can be seen that the majority-to-minority class ratio of Case 2 is higher than that of Case 1. We use our multimodal conditional GAN or the multimodal GAN without the correlation loss to augment the unbalanced training set to make an augmented training set containing 2400 samples for each class, which is class-balanced. Then, the augmented training set is further used to train a DNN classifier. In both Case1 and Case2, we also perform experiments with other methods. Additionally, to compare with the class-balanced case, we report the classification performance of different methods on the training set with 1200 samples per class (for Ours (wo corr) or Ours, each class is augmented to 2400 samples). It is worth pointing out that on each dataset, the validation and test sets are still set as in
Section 4.1, which means that they are still class-balanced. Under this setting, we report the classification accuracy of the test set on each dataset to evaluate the performance of our framework to cope with the class imbalance of the training data, as shown in
Table 7,
Table 8 and
Table 9.
We can observe that with the increase of the majority-to-minority class ratio, the classification accuracy of different methods decreases. However, compared with other methods, our approach achieves the highest classification performance in various settings of class imbalance, indicating that our framework can effectively deal with the problem of class imbalance. In addition, it can be found that compared with different baselines, the method of Ours (wo corr) can also improve the performance of emotion classification, but it is weaker than Ours, which indicates that our proposed correlation loss is useful in the scenario of class imbalance.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}