
Double Linear Transformer for Background Music Generation from Videos



Abstract
:1. Introduction
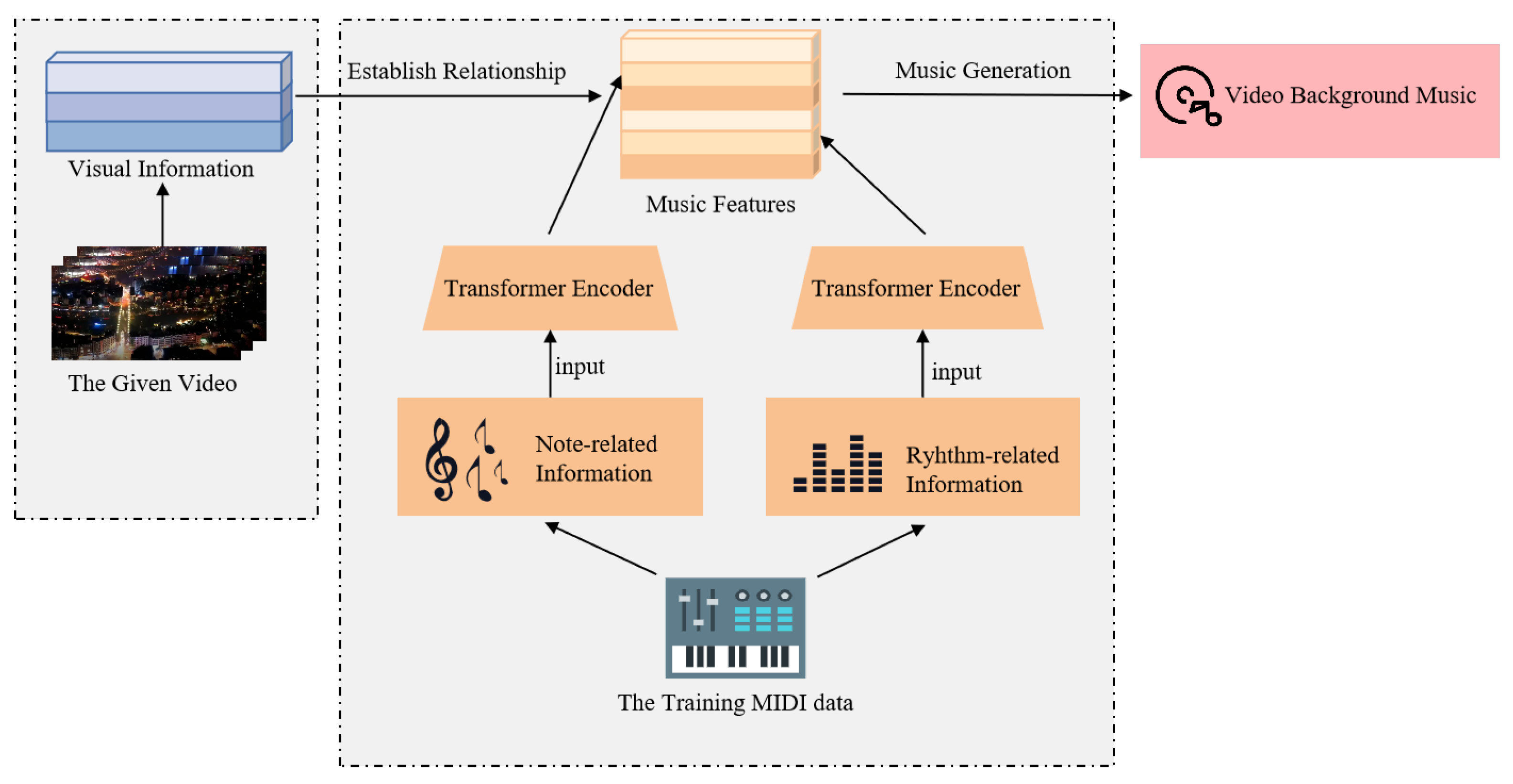
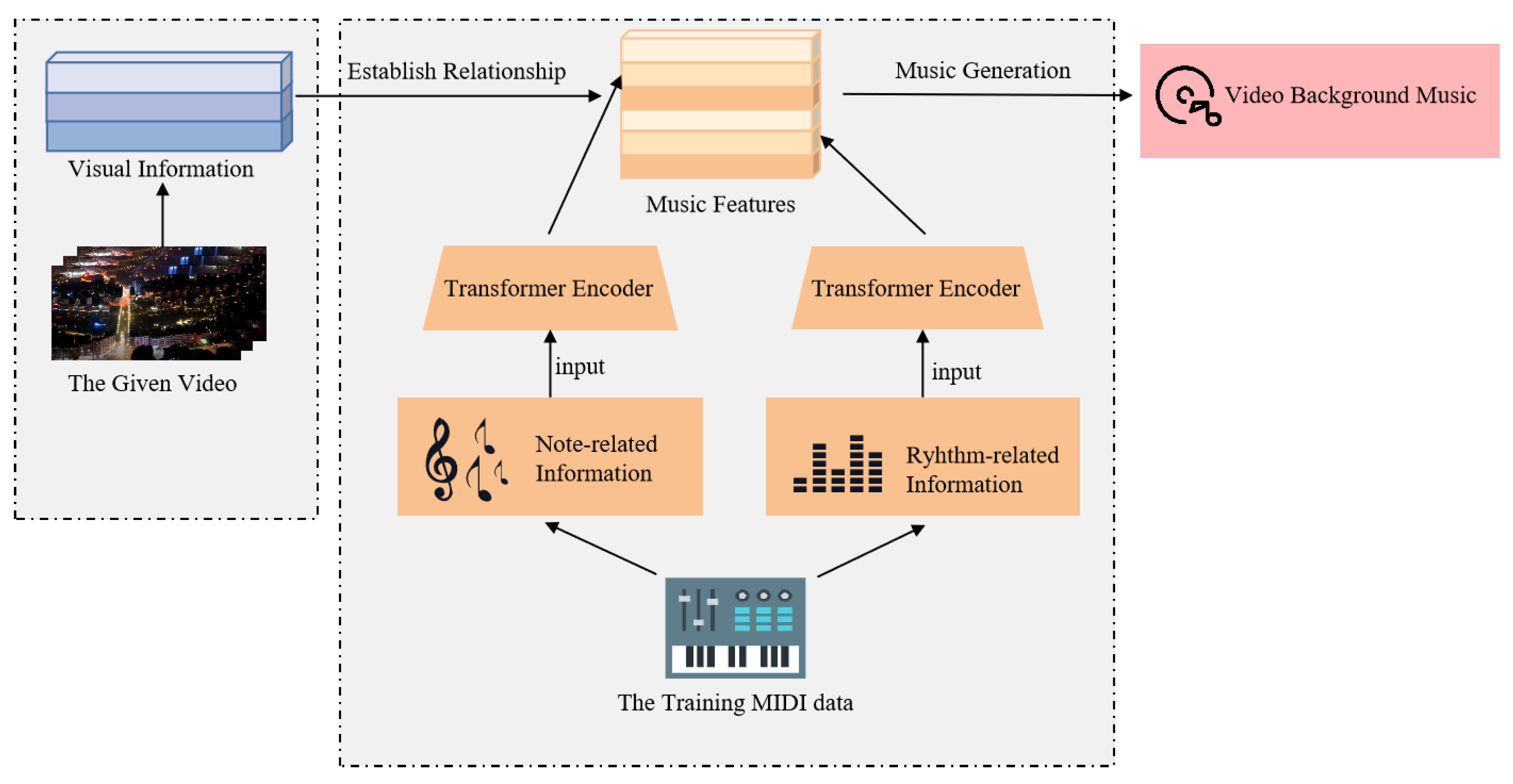
- In this paper, we propose a video background music generation model. Most background music generation works use only one Transformer to learn and extract all music elements, which leads to a weak melody. To establish the correlation and independence between rhythm-related and note-related music features, we use two linear Transformers training jointly. In particular, the two kinds of music features are put into each Transformer network separately;
- Compared to an RNN network such as LSTM and GRU, the proposed model uses a linear Transformer, considering its lightweight and linear complexity. We use the timing information of the given video to guide the generation of music by adding a time beat encoding to the Transformer network;
- After the model has learned the music features, we replace the density and strength features of the music with the optical flow information and rhythm of the video in the inference step, inspired by the state-of-the-art music video inference method. The proposed model combines the music feature learning step and the inference step to form a complete video background music generation model.
2. Related Works
2.1. Representation of Music
2.2. Music Generation
2.3. Technical Architecture
3. The Proposed Framework
3.1. Data Representation
3.2. Training Two Linear Transformers Jointly with Position Encoding
3.3. Video Directs the Generation of Music
4. Experiment
4.1. Data and Implementation Details
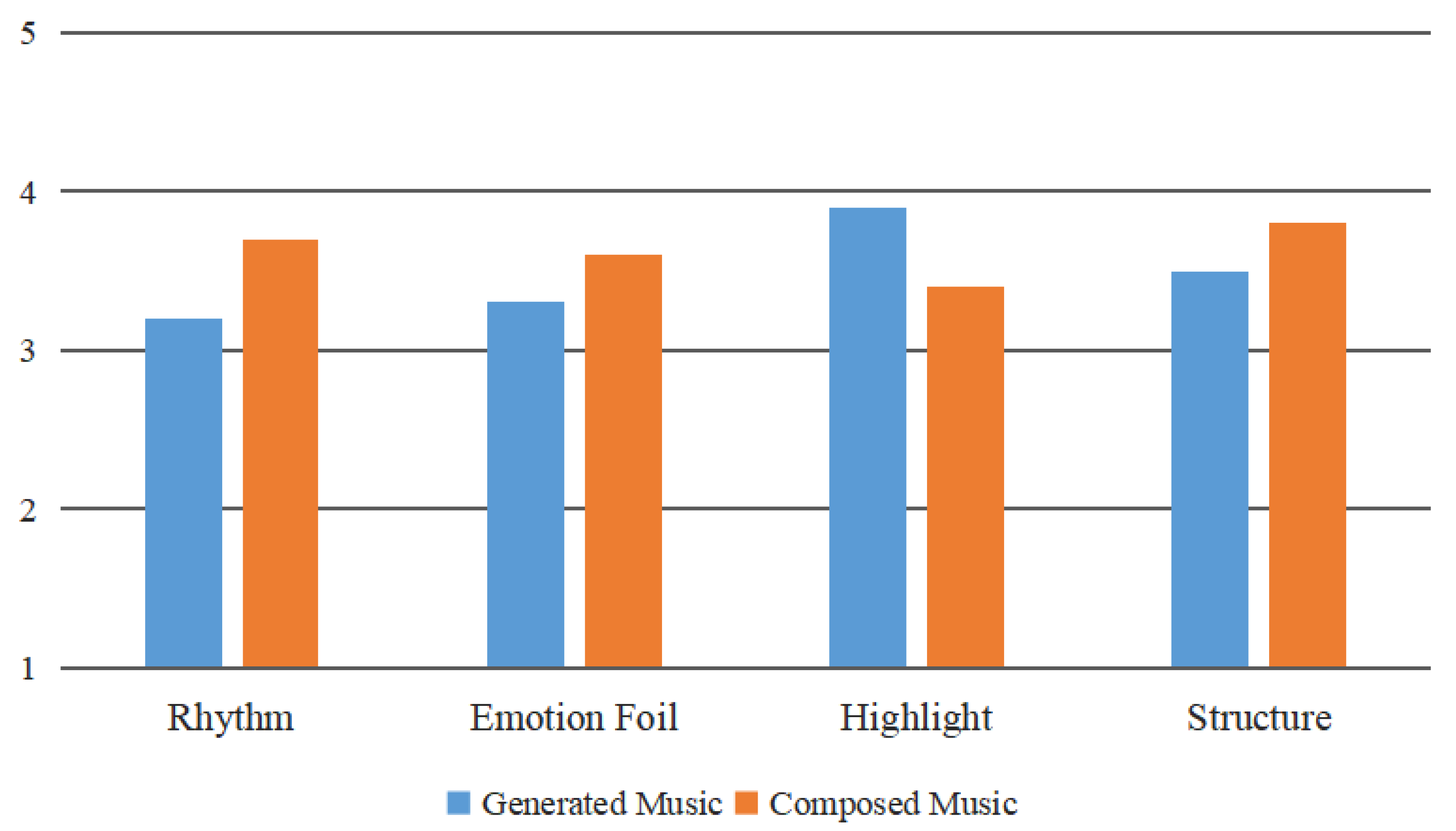
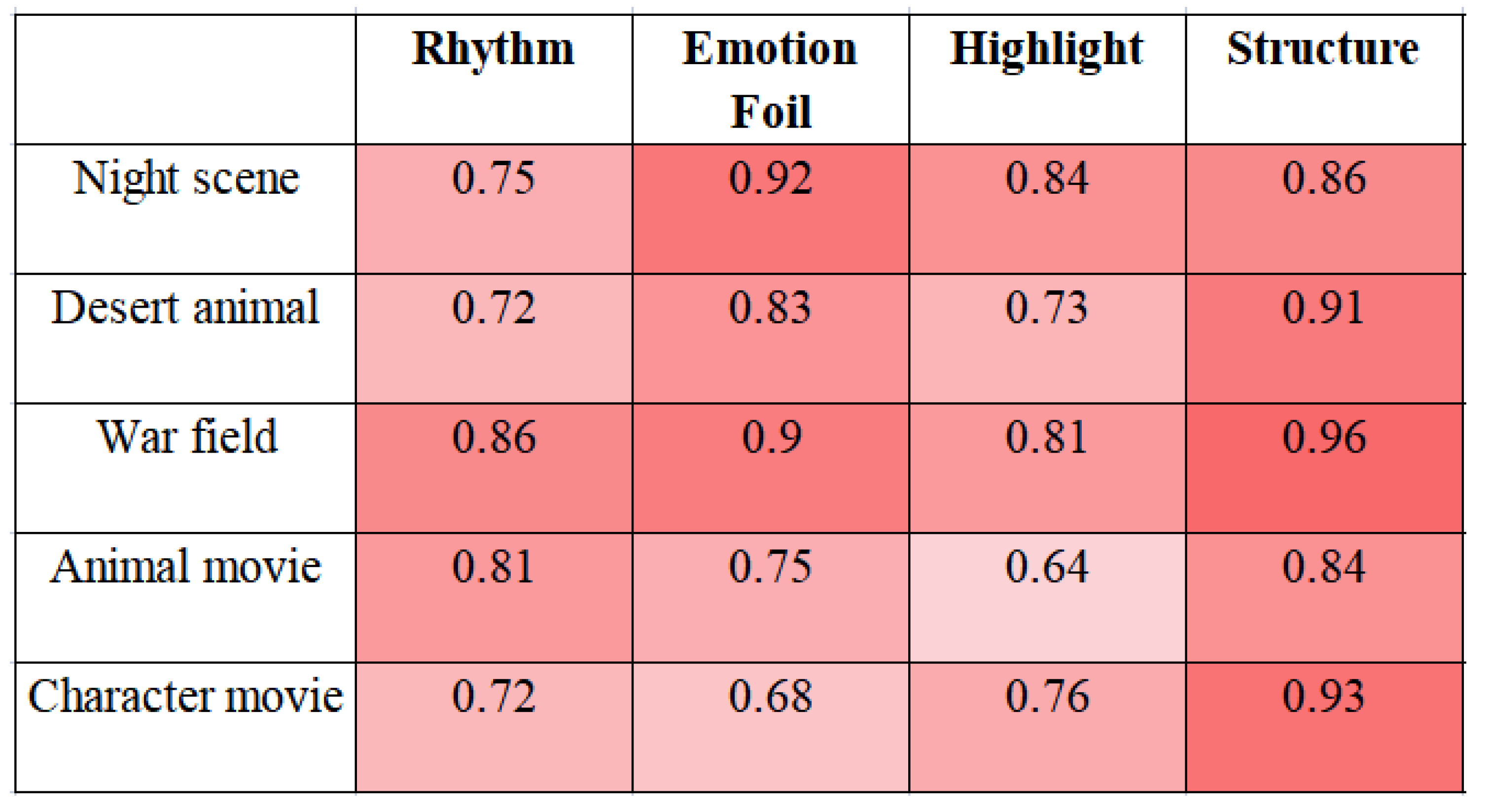
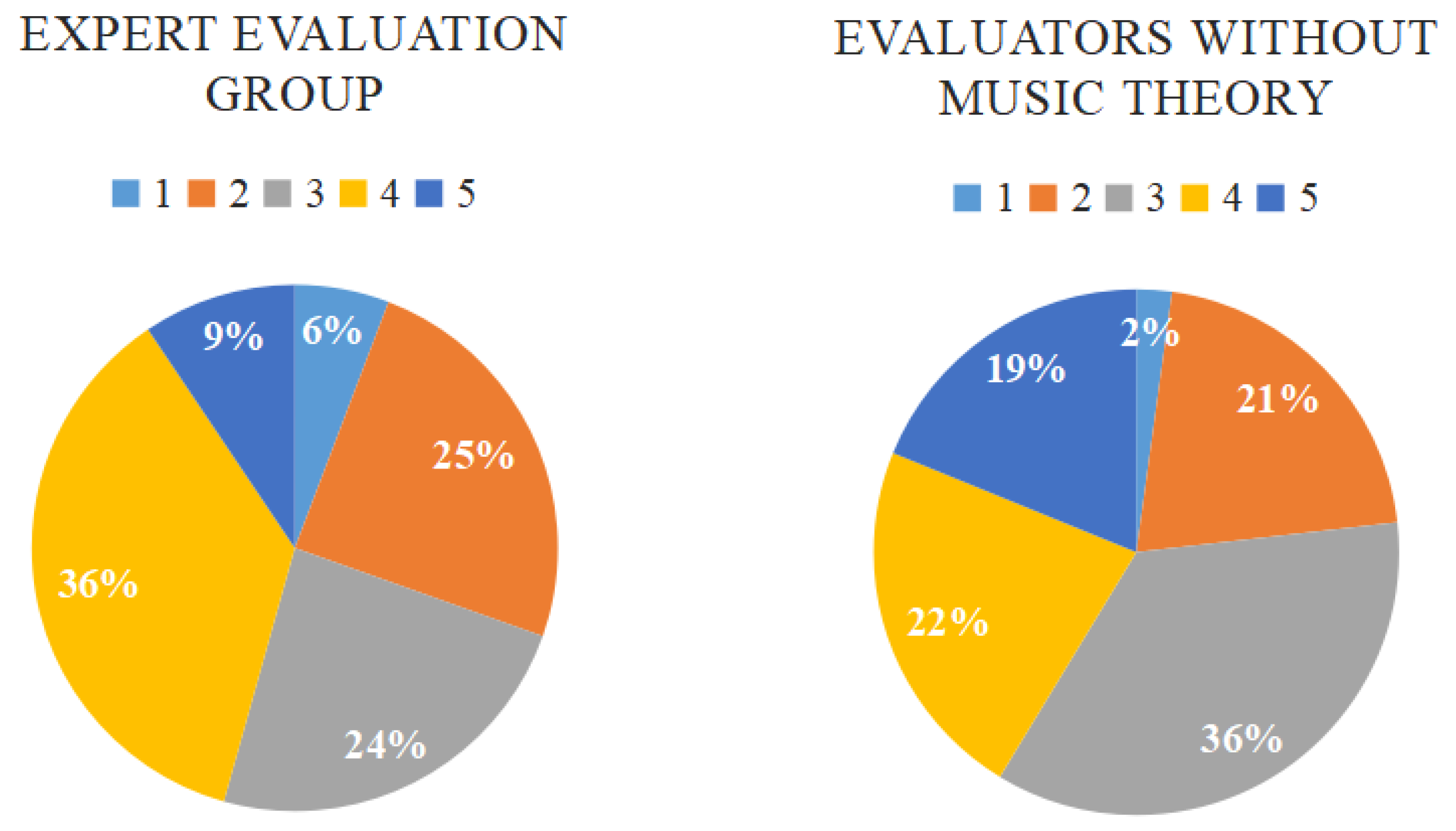
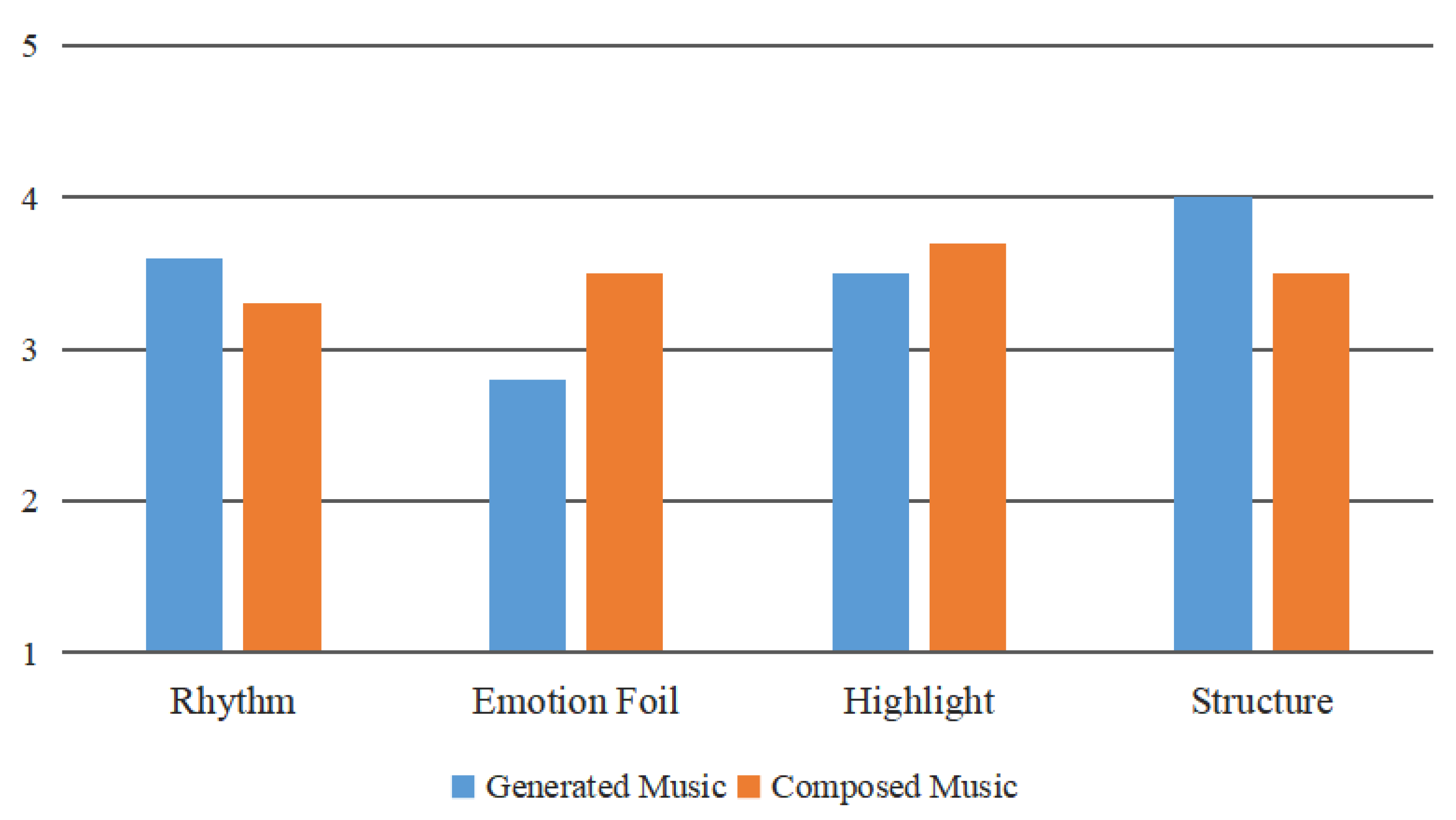
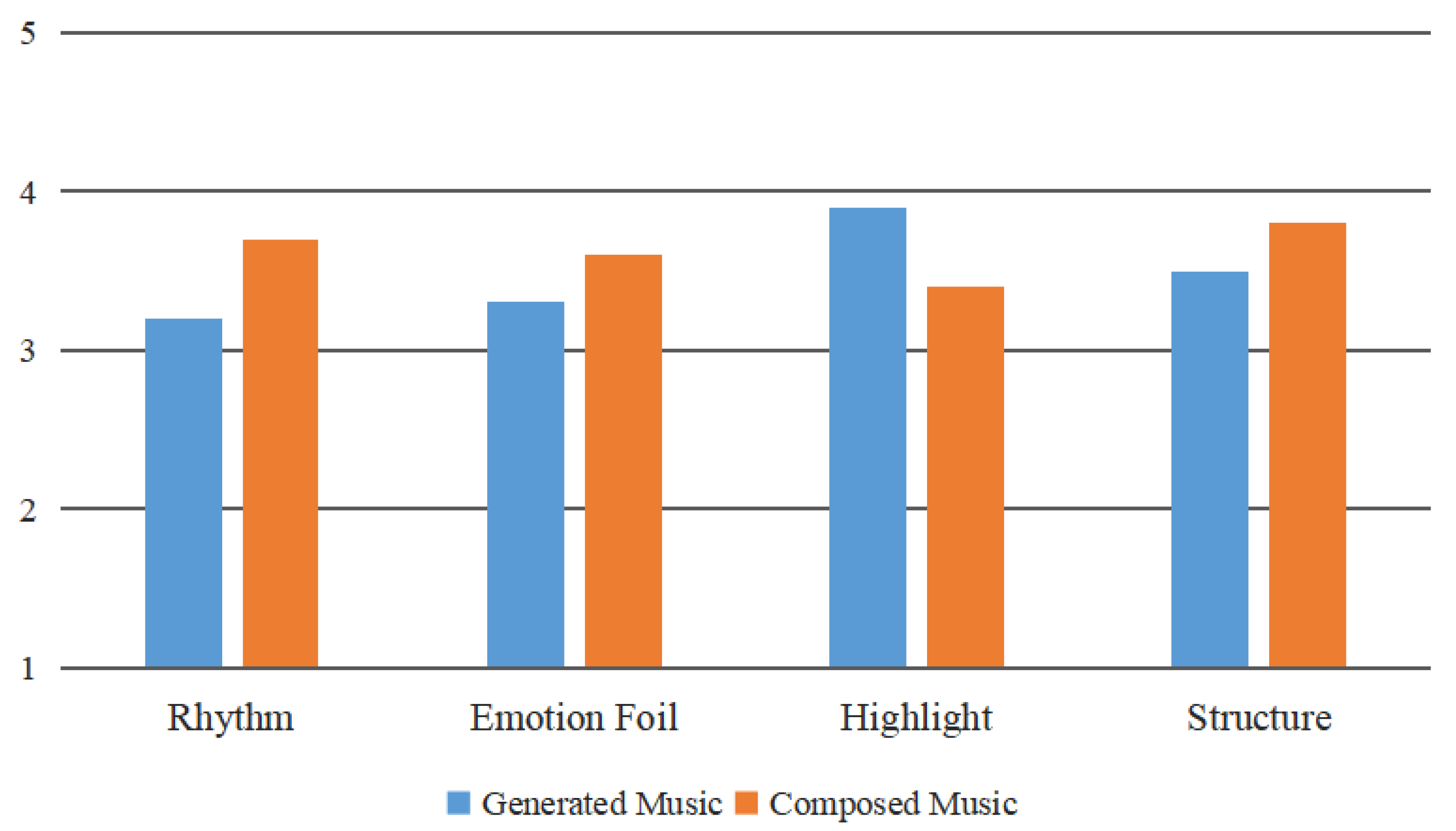
4.2. Subjective Evaluation
- Rhythm represents how the rhythm of the music fits into the pace of movement in the given video;
- Emotional foil indicates whether the emotional expression of music is suitable for the content of the video;
- Highlight says whether the music is stressed in key parts of the video;
- Structure indicates whether the music is suitable for the background music with a crescendo at the beginning and a weakening at the end of the video.
4.3. Objective Evaluation
- The pitch class histogram entropy measures the tonality of the music by the entropy of the pitch. The calculated method is shown in Formula (7), mentioned in Jazz Transformer; here P = 11. The clearer the music piece, the lower the histogram entropy;
- The grooving pattern similarity computes the music rhythmicity, music with higher melodies has higher scores;
- The structureness indicator measures the apparent repetition over a given length of time. The closer this indicator is to the music by composers, the better.
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hadjeres, G.; Pachet, F.; Nielsen, F. Deepbach: A steerable model for bach chorales generation. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2017; pp. 1362–1371. [Google Scholar]
- Scirea, M.; Togelius, J.; Eklund, P.; Risi, S. Metacompose: A compositional evolutionary music composer. In International Conference on Computational Intelligence in Music, Sound, Art and Design; Springer: Berlin/Heidelberg, Germany, 2016; pp. 202–217. [Google Scholar]
- Dong, H.W.; Hsiao, W.Y.; Yang, L.C.; Yang, Y.H. Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment. In Proceedings of the AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Mao, H.H.; Shin, T.; Cottrell, G. DeepJ: Style-specific music generation. In Proceedings of the 2018 IEEE 12th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 31 January–2 February 2018; pp. 377–382. [Google Scholar]
- Wu, S.; Li, X.; Sun, M. Chord-Conditioned Melody Choralization with Controllable Harmonicity and Polyphonicity. arXiv 2022, arXiv:2202.08423. [Google Scholar]
- Di, S.; Jiang, Z.; Liu, S.; Wang, Z.; Zhu, L.; He, Z.; Liu, H.; Yan, S. Video Background Music Generation with Controllable Music Transformer. In Proceedings of the 29th ACM International Conference on Multimedia, Nice, France, 21–25 October 2021; pp. 2037–2045. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In International Conference on Machine Learning; PMLR: New York, NY, USA, 2020; pp. 5156–5165. [Google Scholar]
- Hsiao, W.Y.; Liu, J.Y.; Yeh, Y.C.; Yang, Y.H. Compound Word Transformer: Learning to compose full-song music over dynamic directed hypergraphs. arXiv 2021, arXiv:2101.02402. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html (accessed on 21 April 2012).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Oore, S.; Simon, I.; Dieleman, S.; Eck, D.; Simonyan, K. This time with feeling: Learning expressive musical performance. Neural Comput. Appl. 2020, 32, 955–967. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.S.; Yang, Y.H. Pop music transformer: Beat-based modeling and generation of expressive pop piano compositions. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1180–1188. [Google Scholar]
- Chen, L.; Srivastava, S.; Duan, Z.; Xu, C. Deep cross-modal audio-visual generation. In Proceedings of the on Thematic Workshops of ACM Multimedia 2017, Mountain View, CA, USA, 23–27 October 2017; pp. 349–357. [Google Scholar]
- Su, K.; Liu, X.; Shlizerman, E. Audeo: Audio generation for a silent performance video. Adv. Neural Inf. Process. Syst. 2020, 33, 3325–3337. [Google Scholar]
- Gan, C.; Huang, D.; Chen, P.; Tenenbaum, J.B.; Torralba, A. Foley music: Learning to generate music from videos. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 758–775. [Google Scholar]
- De Prisco, R.; Zaccagnino, G.; Zaccagnino, R. Evocomposer: An evolutionary algorithm for 4-voice music compositions. Evol. Comput. 2020, 28, 489–530. [Google Scholar] [CrossRef] [PubMed]
- Mohamed, A.; Okhonko, D.; Zettlemoyer, L. Transformers with convolutional context for ASR. arXiv 2019, arXiv:1904.11660. [Google Scholar]
- Zhou, T.; Wang, W.; Konukoglu, E.; Van Gool, L. Rethinking Semantic Segmentation: A Prototype View. arXiv 2022, arXiv:2203.15102. [Google Scholar]
- Wang, S.; Zhou, T.; Lu, Y.; Di, H. Detail-Preserving Transformer for Light Field Image Super-Resolution. arXiv 2022, arXiv:2201.00346. [Google Scholar]
- Huang, C.Z.A.; Vaswani, A.; Uszkoreit, J.; Shazeer, N.; Simon, I.; Hawthorne, C.; Dai, A.M.; Hoffman, M.D.; Dinculescu, M.; Eck, D. Music transformer. arXiv 2018, arXiv:1809.04281. [Google Scholar]
- Donahue, C.; Mao, H.H.; Li, Y.E.; Cottrell, G.W.; McAuley, J. LakhNES: Improving multi-instrumental music generation with cross-domain pre-training. arXiv 2019, arXiv:1907.04868. [Google Scholar]
- Wu, S.L.; Yang, Y.H. The Jazz Transformer on the front line: Exploring the shortcomings of AI-composed music through quantitative measures. arXiv 2020, arXiv:2008.01307. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.V.; Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. arXiv 2019, arXiv:1901.02860. [Google Scholar]
- Chen, Y.H.; Huang, Y.H.; Hsiao, W.Y.; Yang, Y.H. Automatic composition of guitar tabs by transformers and groove modeling. arXiv 2020, arXiv:2008.01431. [Google Scholar]
- Ren, Y.; He, J.; Tan, X.; Qin, T.; Zhao, Z.; Liu, T.Y. Popmag: Pop music accompaniment generation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1198–1206. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Chang, C.J.; Lee, C.Y.; Yang, Y.H. Variable-length music score infilling via XLNet and musically specialized positional encoding. arXiv 2021, arXiv:2108.05064. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rhythm | Emotion Foil | Highlight | Structure | Avg. | |
|---|---|---|---|---|---|
| Night scene | 3.6 (3.3) | 2.8 (3.5) | 3.5 (3.7) | 4.0 (3.5) | 3.48 (3.50) |
| Desert animal | 3.1 (3.4) | 3.6 (3.1) | 3.1 (3.1) | 4.2 (3.6) | 3.50 (3.30) |
| War field | 2.8 (3.1) | 1.4 (2.8) | 3.5 (3.3) | 3.1 (2.9) | 2.70 (3.03) |
| Animal movie | 3.2 (3.7) | 2.4 (3.2) | 3.8 (3.3) | 3.8 (3.4) | 3.30 (3.40) |
| Character movie | 3.5 (3.6) | 3.3 (3.5) | 2.8 (3.2) | 4.0 (3.6) | 3.40 (3.48) |
| Avg. | 3.24 (3.42) | 2.70 (3.22) | 3.34 (3.32) | 3.82 (3.40) | 3.28 (3.342) |
| It Is by AI | It Is by Human | Want to Use? | |
|---|---|---|---|
| Generated music | 89% (62%) | 11% (35%) | 56% (75%) |
| Composers’ music | 5% (23%) | 95% (64%) | 78% (63%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Yu, Y.; Wu, X. Double Linear Transformer for Background Music Generation from Videos. Appl. Sci. 2022, 12, 5050. https://doi.org/10.3390/app12105050
Yang X, Yu Y, Wu X. Double Linear Transformer for Background Music Generation from Videos. Applied Sciences. 2022; 12(10):5050. https://doi.org/10.3390/app12105050
Chicago/Turabian StyleYang, Xueting, Ying Yu, and Xiaoyu Wu. 2022. "Double Linear Transformer for Background Music Generation from Videos" Applied Sciences 12, no. 10: 5050. https://doi.org/10.3390/app12105050
APA StyleYang, X., Yu, Y., & Wu, X. (2022). Double Linear Transformer for Background Music Generation from Videos. Applied Sciences, 12(10), 5050. https://doi.org/10.3390/app12105050