Abstract
Bidirectional Encoder Representations from Transformers (BERT) has gained increasing attention from researchers and practitioners as it has proven to be an invaluable technique in natural languages processing. This is mainly due to its unique features, including its ability to predict words conditioned on both the left and the right context, and its ability to be pretrained using the plain text corpus that is enormously available on the web. As BERT gained more interest, more BERT models were introduced to support different languages, including Arabic. The current state of knowledge and practice in applying BERT models to Arabic text classification is limited. In an attempt to begin remedying this gap, this review synthesizes the different Arabic BERT models that have been applied to text classification. It investigates the differences between them and compares their performance. It also examines how effective they are compared to the original English BERT models. It concludes by offering insight into aspects that need further improvements and future work.
1. Introduction
Text classification is a machine-learning task in which a document is assigned to one or more predefined categories according to its content. It is a fundamental task in natural language processing with diverse applications such as sentiment analysis, email routing, offensive language detection, spam filtering, and language identification [1]. Of these applications, sentiment analysis has attracted the most attention. The objective of sentiment analysis is to identify the polarity of text content, which can take the form of a binary positive/negative classification, or a more granular set of categories, such as a five-point satisfaction scale [2]. Despite the progress that has been achieved in improving the performance of text classification, there is much room for improvement, especially for the Arabic language.
Bidirectional Encoder Representations from Transformers (BERT) is a language representation model that was introduced in 2018 by Jacob Devlin and his colleagues from Google [3]. Since its introduction, it has become a ubiquitous baseline in natural language-processing research [4]. Unlike other language representation models that capture the context unidirectionally, BERT was designed as a bidirectional model that can predict words conditioned on both the left and right context [5]. BERT was also built as an unsupervised model that can be trained using the plain text corpus that is enormously available on the web in most languages. This combination of features allows BERT to demonstrate exceptional performance in various natural language-processing tasks, including text classification [6].
There are two main approaches for using BERT: feature extraction and finetuning. In feature extraction, the architecture of the BERT model is preserved, i.e., the model’s parameters are ‘frozen’. Features are extracted from the pretrained BERT model and then fed into a classifier model to solve a given task. In finetuning, the model’s parameters are finetuned by adding extra layers to the original BERT architecture. These new layers are used to train the model on the downstream tasks [3].
In the original paper of Devlin, Chang, Lee and Toutanova [3], two BERT models were introduced: BERT-large and BERT-base. They are both in English. They were pretrained from extremely large corpora extracted from the internet. Therefore, they have heavy computing requirements and a high memory footprint. As BERT gained more interest from researchers and practitioners, more BERT models were introduced. The new models attempt to address some of the shortcomings of the original models, improving the performance [7] or improving the inference speed [8]. There were also models that were developed to support languages other than English [9,10].
Several BERT models were pretrained to support the Arabic language. For example, Devlin and his team developed a multilingual model that supports more than 100 languages, including Arabic. Antoun, et al. [11] developed an Arabic model that they called Arabert. The model was pretrained on around 24 gigabytes of text. Similarly, Abdul-Mageed, et al. [12] used 1B tweets to train an Arabic BERT model that they named MARBERT. While these models have been used for Arabic text classification, it is not obvious which model is most suitable for the classification task. It is also not clear if one of them is more effective than the other and whether the process that has been used to pretrain each model has affected its performance. This systematic review provides a detailed examination of the different Arabic BERT models that have been used for text classification. The aim is to provide guidance for researchers and practitioners by critically appraising and summarizing existing research. To the best of our knowledge, this is the first systematic review study on this subject.
2. Research Methodology
A systematic review is a useful method for identifying, aggregating, and synthesizing existing research that is relevant to a research topic. It provides in-depth analysis to answer specific research questions with the aim of synthesizing evidence [13]. This systematic review follows the PRISMA guidelines [14]. What follows is a detailed description of the steps that have been performed to conduct the study.
2.1. Definition of Research Questions
The objective of this study is to investigate BERT models that have been used for Arabic text classification. Based on this objective, the following questions were defined:
- What Bert models have been used for Arabic text classification, and how do they differ?
- How effective are they in classifying Arabic text?
- How effective are they compared to the original English BERT models?
2.2. Search Strategy
An electronic search was conducted on six scientific databases: IEEE Xplore, ScienceDirect, Springer Link, Taylor & Francis Online, ACM digital library, and ProQuest journals. These databases were chosen considering their coverage and use in the domain of computer science. Google Scholar was also searched to increase publication coverage and to include gray literature, which could make important contributions to a systematic review [15]. The date of the last search was December 2021.
The search string was constructed following Population, Intervention, Comparison, and Outcomes (PICO), as suggested by Kitchenham and Charters [16].
- Population: BERT, Arabic.
- Intervention: text classification, sentiment analysis.
- Comparison and Outcomes: these two dimensions were omitted, as the research questions do not warrant a restriction of the results to a particular outcome or comparison.
Table 1 shows the final search strings that were used to search each database.

Table 1.
Search string for each database.
2.3. Selection of Studies
After articles were retrieved from the online databases, they were entered into a Reference Manager System, i.e., EndNote, and duplicates were removed. Then, the titles and abstracts of the remaining articles were screened using predefined selection criteria. An article was deemed suitable for inclusion in this systematic review if it met all the following inclusion criteria:
- It uses a BERT model for the Arabic text classification task.
- It evaluates the performance of the utilized BERT model.
- The dataset that has been used to evaluate the model is well described.
- It is written in English or Arabic.
An article was excluded if:
- The full text of the article is not available online.
- The article is in the form of a poster, tutorial, abstract, or presentation.
- It is not in English or Arabic.
- It does not evaluate the performance of the utilized BERT model.
- The dataset that was used to evaluate the model is not described.
Where a decision about the inclusion of an article was in doubt, the full text was read to make a final judgment. The whole selection process was reviewed by two independent researchers. The results were compared and discrepancies were discussed to reach a consensus.
2.4. Quality Assessment
The quality assessment was performed by using a quality appraisal tool adapted from Zhou, et al. [17]. The tool has criteria for assessing the reporting, rigor, credibility, and relevance of the included articles (See Table 2). In the assessment of each article, a score of zero was given if the criterion was not met, one if the criterion was partially met, and two if the criterion was fully met. The total quality-assessment score of an article was calculated by summing the individual criterion scores. The article quality was classified as “good” if the total score was ≥12, “adequate” if the total score was ≥8, and “poor” if the total score was <8.
Table 2.
Quality appraisal tool.
Due to the lack of consensus among scholars in regard to the role of quality assessment in systematic review studies, no article was excluded from this review based on its quality score [15,18]. The quality assessment helped us to understand the weaknesses and strengths of the included articles. As demonstrated by Morgan, et al. [19] and Alammary [20], articles with poor quality would contribute less to the synthesis. Similar to studies selection, quality assessment was performed by the author and was reviewed by two independent researchers. The result was discussed until an agreement was reached.
2.5. Data Extraction
A predefined data extraction form was used to extract data from the included articles. The form included the following variables: title, first author, country, type (e.g., conference/workshop/journal), publishing year, BERT model/s, evaluation dataset, adoption approach (i.e., feature extraction or finetuning), models that the BERT model was compared to, the performance of BERT model/s, and remark about the quality of the article. The extraction form was designed specifically for this systematic review and was piloted on a sample of five articles.
2.6. Synthesis of Results
After extracting data from the included studies, the extracted data were synthesized using a narrative format. Five predetermined themes emerged from the research questions and were used in the synthesis. Those themes are (1) Arabic BERT models, (2) evaluation dataset, (3) adoption approach, (4) models that the BERT model was compared to, and (5) performance of BERT models.
3. Results
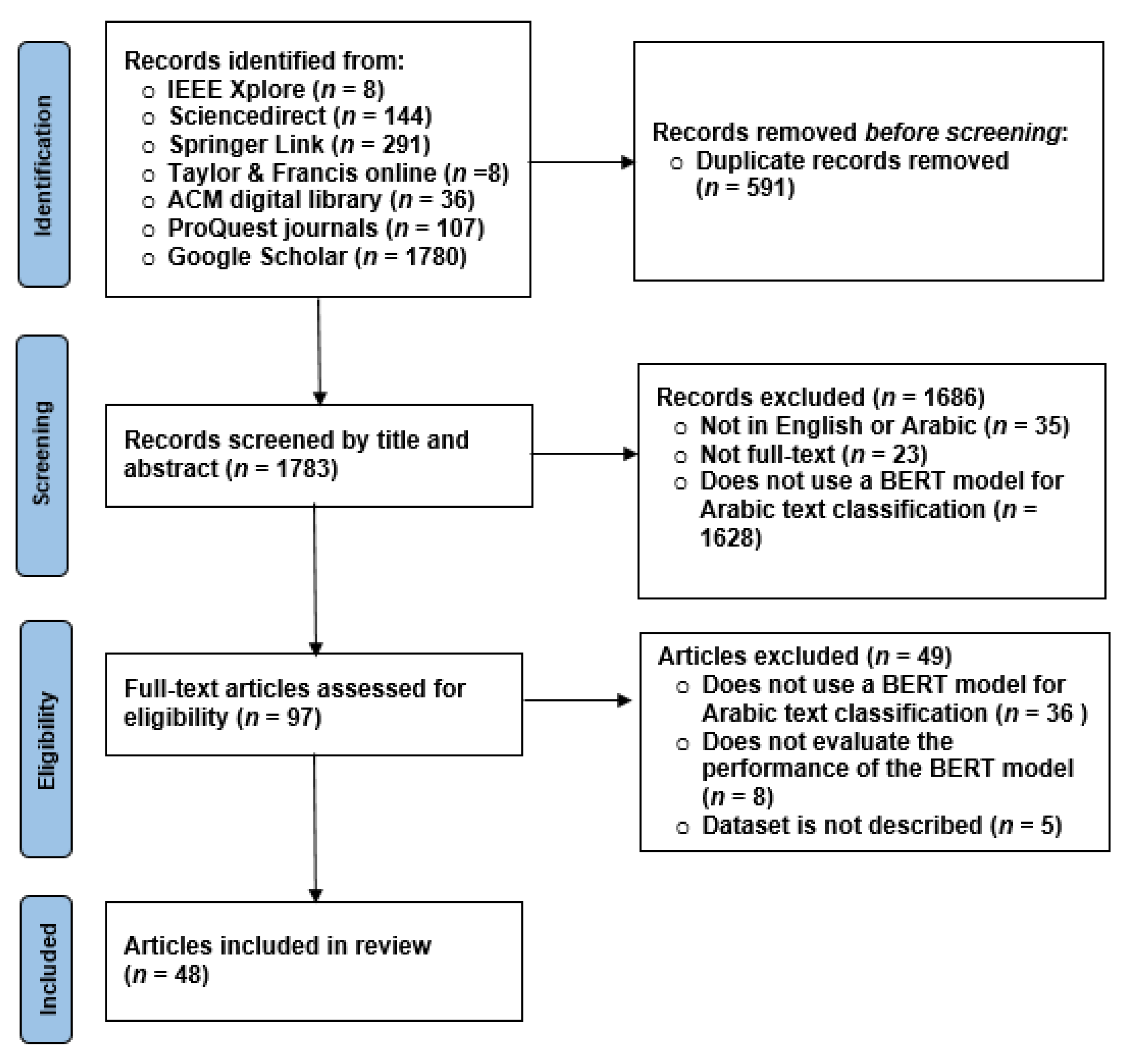
As can be seen in Figure 1, a total of 594 articles were found through the search in the six electronic databases. An additional 1780 articles were retrieved from Google Scholar. After adding them to EndNote, 591 were excluded for duplication. The screening of the remaining articles resulted in exclusion of 1686 articles. The vast majority of them did not use the BERT model for Arabic text classification. During the full-text reading, another 49 articles were excluded. Again, the reason for excluding the majority of these articles is that they did not use the BERT model for Arabic text classification. Eventually, 48 articles were deemed suitable for inclusion in this review and were appraised using the quality appraisal tool.
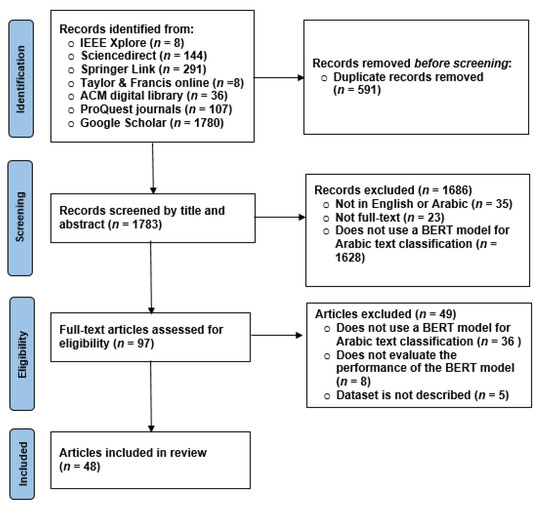
Figure 1.
The systematic review process.
3.1. Included Studies Overview
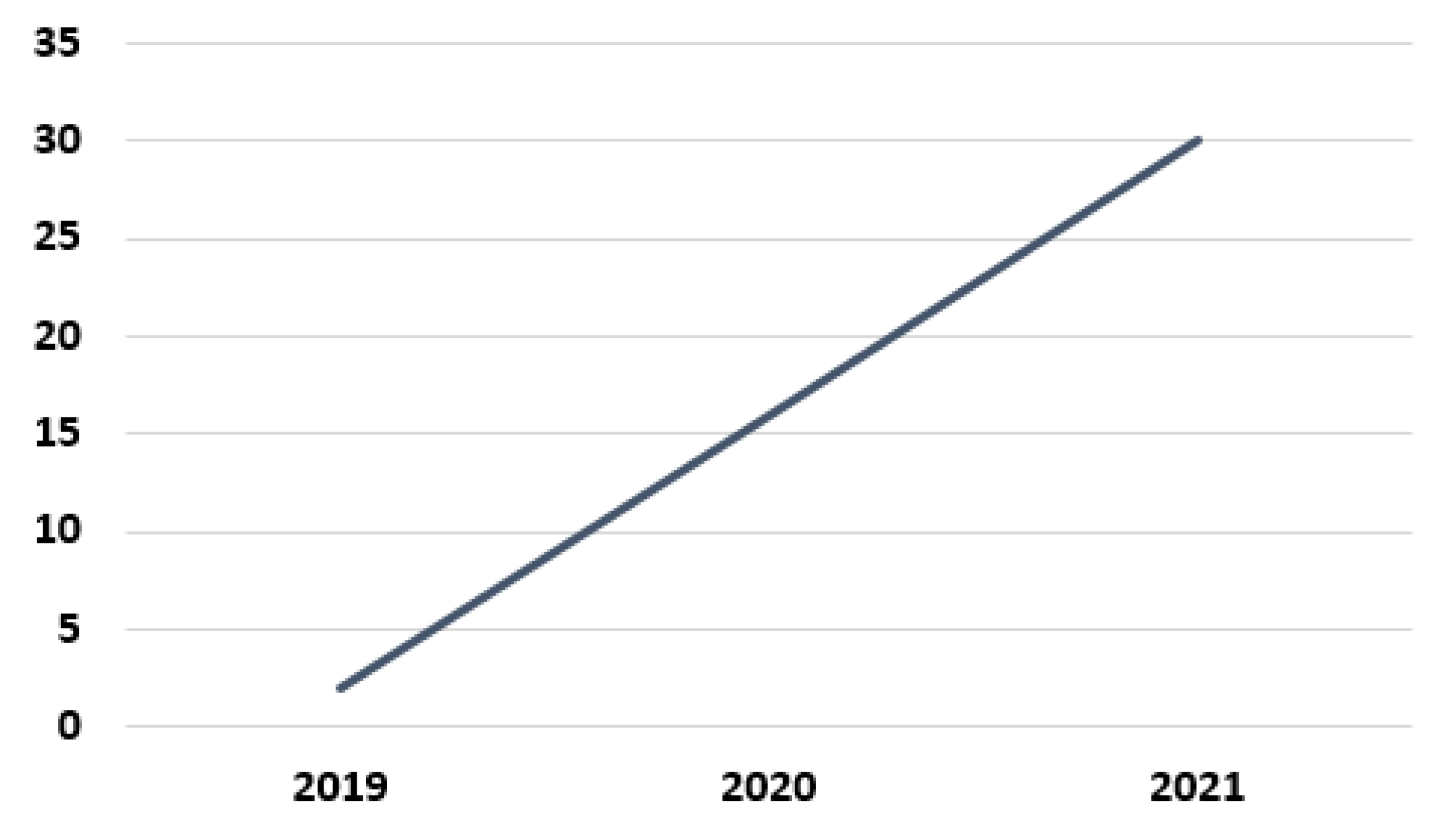
Figure 2 shows the distribution of articles by publication year. As can be seen, there has been a very sharp increase in the number of articles that utilized BERT for Arabic text classification in the last three years. While there were only two articles in 2019, the number increased to sixteen in 2020 and then to thirty in 2021.
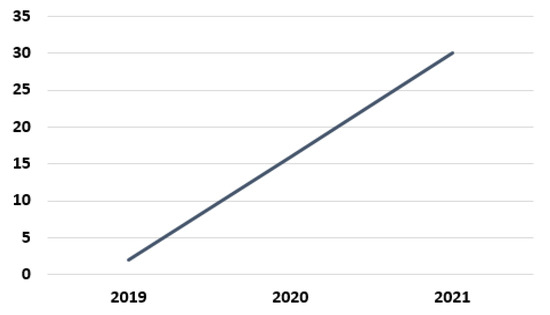
Figure 2.
Articles by publication year.
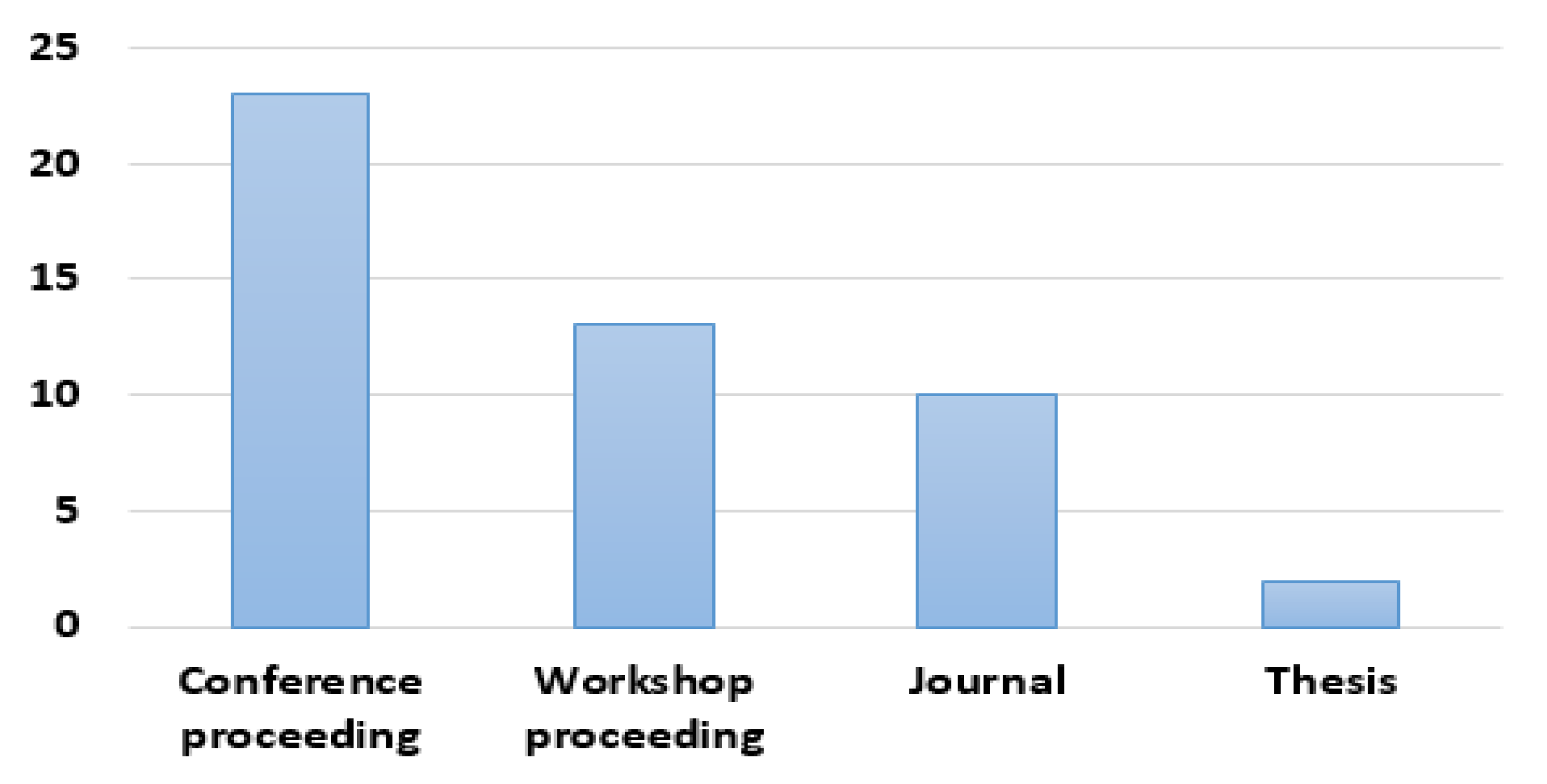
The distribution of articles by publication type is presented in Figure 3. The vast majority of articles included in this study (23 articles, 48%) are conference proceeding articles. Thirteen articles (27%) are workshop proceeding articles. There are also ten journal articles (21%) and two theses (4%).
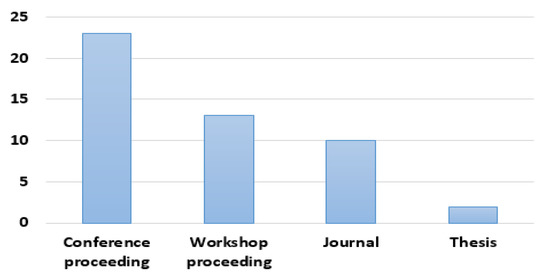
Figure 3.
Articles by publication type.
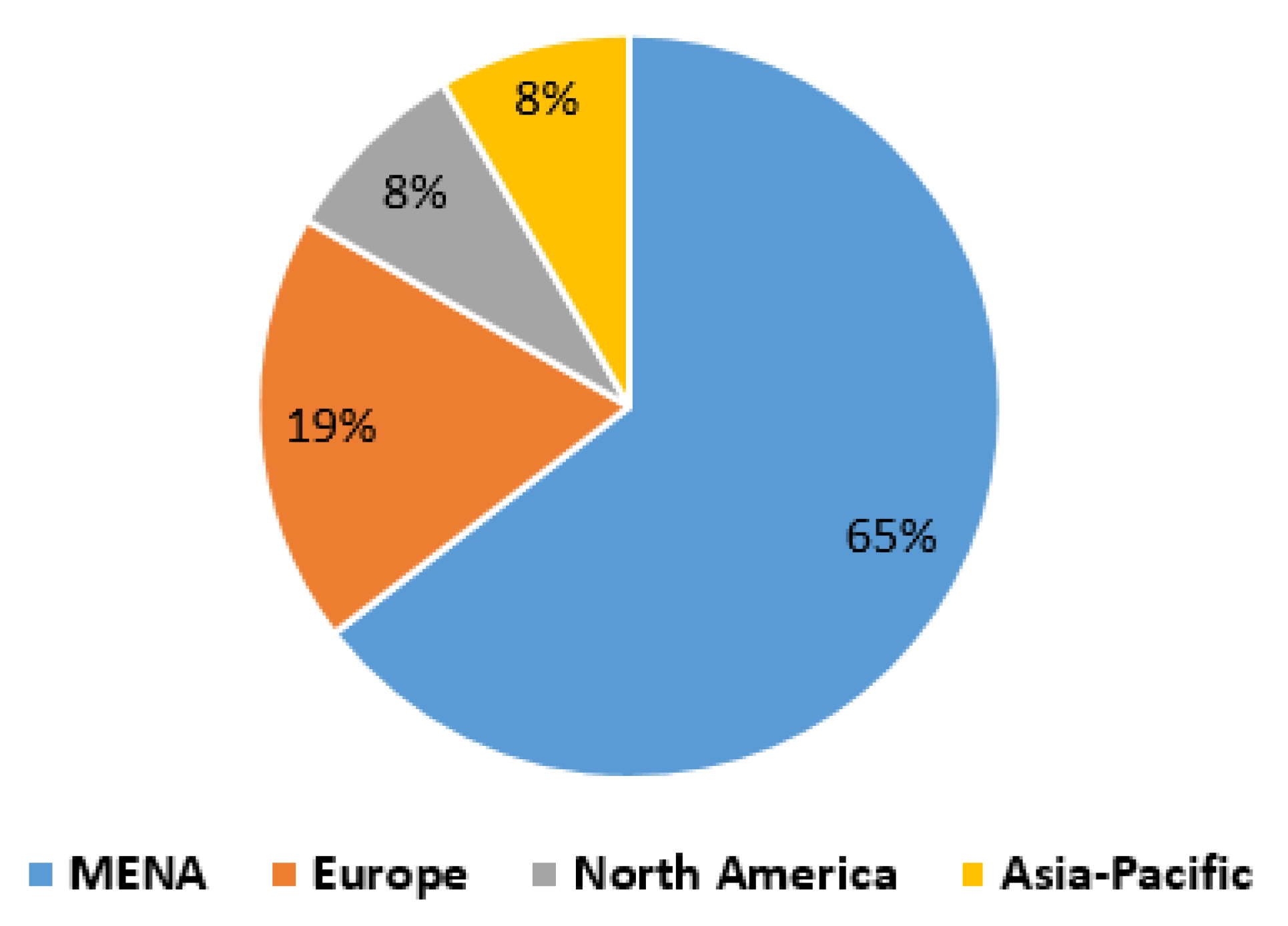
As one would expect, the majority of articles (31 articles, 65%) came from the Middle East and North Africa (MENA) where Arabic is the official language. Qatar and Saudi Arabia are accounted for around half of MENA articles. Europe contributed nine articles (19%), while North America and Asia-Pacific contributed four articles each (See Figure 4).
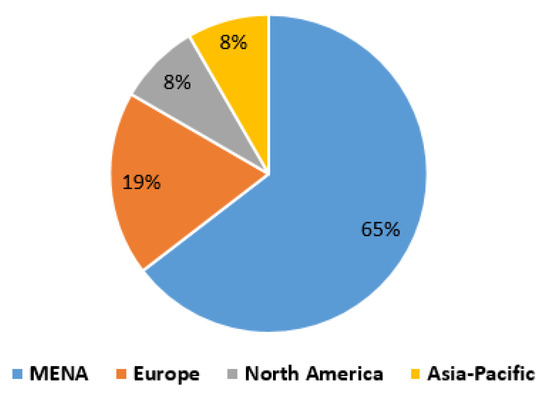
Figure 4.
Articles by region.
3.2. Quality of the Included Studies
Table 3 shows a summary of the quality assessment of the included studies. The overall quality of the 48 studies was good. Eighteen studies (38%) fully met the eight criteria, while twenty-one (44%) partially met these criteria. Only three studies (6%) had major quality issues, i.e., met less than four criteria. The most unmet criteria were the ones related to the presented data and conclusion. Nine studies (19%) were found not to present adequate data to support the study findings. Eight studies (17%) had conclusions that were not supported by the results. As discussed in the previous section, no study was excluded from this review on the basis of its quality.
Table 3.
Quality assessment results.
3.3. BERT Models
As can be seen in Table 4, nine different BERT models were used in the reviewed articles. Some articles used one model only, while others used more than one. The most widely used model was the Multilingual BERT of Devlin, Chang, Lee and Toutanova [3] which was utilized in 65% of the articles. It was followed by a model called AraBERT which was designed specifically for the Arabic language and was used by around 58% of the reviewed articles. The other models were used much less frequently, with MARBERT and ArabicBERT used by 19% and 11% of the articles, respectively, and the remaining six models used by less than 10% of the articles each. In the vast majority of the articles, BERT models were utilized by using the finetuning approach. Only five articles (10%) used BERT models as a feature-extraction approach.
Table 4.
Used BERT models.
3.4. Models Evaluation
The nine models were evaluated by comparing their performances to other BERT and non-BERT models. A total of 66 comparisons were conducted, as sixteen studies had more than one comparison each. As can be seen in Table 5, the finetuned Multilingual BERT was compared to 66 models. It outperformed 27 models (41%) and was outperformed by 39 models (59%). In comparison to the other Arabic BERT models, it only outperformed XLM-RoBERTa and was outperformed by the other eight models. The model scored the lowest F1 Score of all the other models (0.118). When using Multilingual BERT as a feature extraction method, the performance was better. The constructed models were able to outperform nineteen models, including the finetuned Multilingual BERT (83%). It was only outperformed by four models (17%).
Table 5.
Performance of the BERT models.
The finetuned AraBERT achieved better performance than Multilingual BERT. Of the 50 models that it was compared against, it outperformed 42 models (84%) and was only outperformed by eight models (16%). When compared to other BERT models, it outperformed all eight other models but was also outperformed by four of these models in some of the articles. The model scored the highest F1 Score of all the other models (0.99). AraBERT also showed excellent performance when it was used as a feature-extraction method. It outperformed fifteen of the models that it was compared against and was only outperformed by the finetuned AraBERT. MARBERT was one of the Arabic BERT models that achieved excellent performance. It outperformed 21 models (75%) and was outperformed by seven models (25%).
ArabicBERT also achieved good performance both when finetuned and when used as a feature-extraction method. Similar to AraBERT and Multilingual BERT, it achieved its best performance when it was utilized for feature extraction. It outperformed the five models that it was compared against. The finetuned ArabicBERT outperformed 15 models (71%); seven of them were Arabic BERT models. It was outperformed by six models (29%), five of which were Arabic BERT models. The performance of QARiB was also good. It outperformed 11 out of 18 models (61%). The model was able to outperform all the other eight Arabic BERT models, but was also outperformed by six of them.
ARBERT and XLM-RoBERTa scored a mixed performance. ARBERT outperformed six BERT and two non-BERT models. It was outperformed by five BERT and two non-BERT models. XLM-RoBERTa outperformed four BERT and five non-BERT models. It was outperformed by five BERT and one non-BERT model. The performance of the remaining two Arabic BERT models was poor. GigaBERT outperformed 2 out of 12 models (17%), and Arabic ALBERT outperformed 3 out of 11 models (27%).
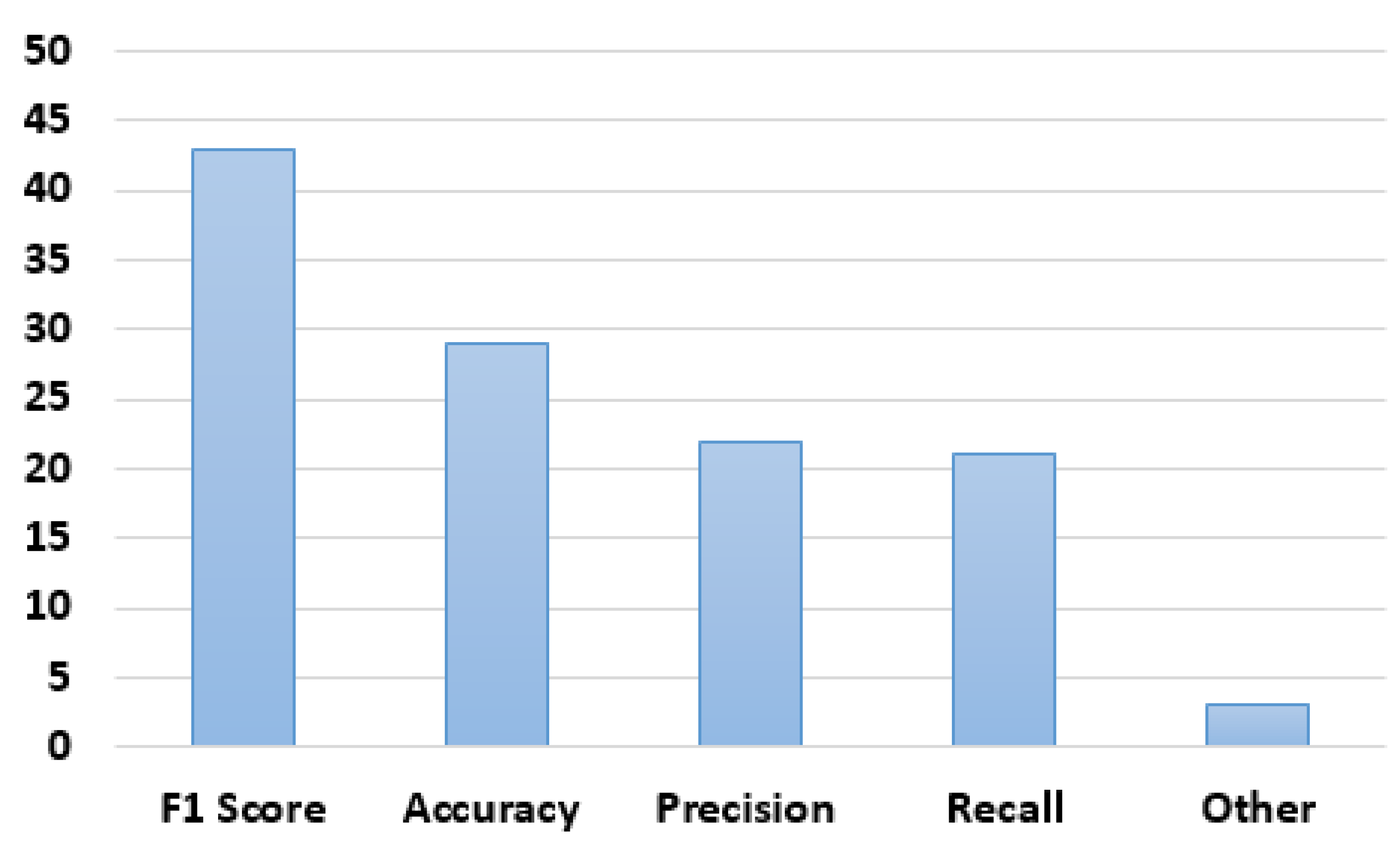
As can be seen in Figure 5, the vast majority of the articles (90%) used the F1 score to measure the performance of the models. Accuracy, precision, and recall were used in 60%, 46%, and 44% of the articles, respectively. Other measurements that were used include Area Under the Receiver Operating Characteristic Curve (AUROC), Precision-Recall Curve (PRC), and macro-average PR-AUC.
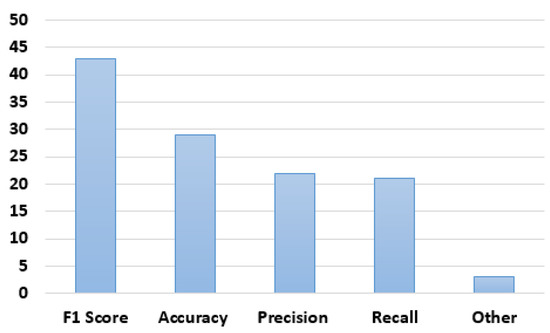
Figure 5.
Performance measures.
3.5. Evaluation Datasets
Table 6 shows the different datasets that were used to evaluate the nine BERT models. The vast majority of the datasets had a short text corpus. More than 67% contained tweets extracted from Twitter and around 28% had posts from other social media platforms such as Facebook. Only two datasets had a long text corpus. One of them had hotel and book reviews, while the other one had articles classified by subject. The sizes of the datasets varied; the smallest dataset had 2479 items and the largest had 2.4 million items. The majority, however, had less than twenty-thousand items each. In 34 articles (71%), the items in the datasets were classified as either positive, negative, or neutral. The remaining datasets had items belonging to multiple classes.
Table 6.
Datasets that were used to evaluate the models.
4. Discussion
The publication trend indicates the rapidly growing interest in using BERT models for Arabic text classification. However, given the relatively small number of articles that have been found in this review, more research is required. Overall, this review of the 48 articles helped to answer the three research questions.
4.1. What BERT Models Were Used for Arabic Text Classification, and How Do They Differ?
As was shown in the previous section, nine different BERT models were used for Arabic text classification. Some of them were designed specifically for the Arabic language, while others support multiple languages, including Arabic.
- Multilingual BERT:
The model was developed by Devlin et al., the same developer of the original BERT model. It was not designed for Arabic specifically, but rather supports 104 languages, including Arabic [21]. It was pretrained on Modern Standard Arabic data from Wikipedia. The size of the Arabic pretraining corpus is less than 1.4 gigabytes and has only 7292 tokens [65,66]. Regarding its architecture, Multilingual BERT has 12 layers of transformers blocks with 768 hidden units each. It also contains 12 self-attention heads and around 110 million trainable parameters [26].
- 2.
- AraBERT:
Unlike Multilingual BERT, AraBERT was built specifically for the Arabic language. The pretraining dataset contains Modern Standard Arabic news extracted from different Arabic media. Version 1 of the model has 77 million sentences and 2.7 billion tokens corresponding to around 23 gigabytes of text. This is 17 times the size of the Arabic pretraining dataset that was used to train the Multilingual BERT. The newest version of the model used 3.5 times more data for pretraining, i.e., 77 gigabytes of text. Similar to Multilingual BERT, AraBERT has 12 transformers blocks with 768 hidden units each. It also has 12 self-attention heads and a total of 110 million trainable parameters [11]. To support dialectical Arabic, the model was further pretrained on a corpus of 12,000 sentences written in different Arabic dialects. This customized version of AraBERT was called SalamBERT [59].
- 3.
- MARBERT:
This model was also designed specifically for the Arabic language, but unlike AraBERT, it was pretrained on huge Twitter data which contains text in both Modern Standard Arabic and various Arabic dialects. The pretraining corpus has 1 billion tweets, which sum up to almost 128 gigabytes of text. The number of tokens in the corpora is around 15.6 billion, which is almost double the number of tokens of Version 2 of AraBERT. This makes it the largest pretraining corpora of the nine models. MARBERT has the same architecture as Multilingual BERT, but without the next-sentence prediction (NSP). The reason for omitting NSP, according to the model’s developers, is that tweets are too short. The total number of trainable parameters in MARBERT is around 160 million [27].
- 4.
- ArabicBERT:
The model has several versions that were all trained specifically for Arabic. The base model has the same architecture as Multilingual BERT. It was pretrained on 8.2 billion tokens extracted from Wikipedia and other Arabic resources, which makes up around 95 gigabytes of text. The data are in Modern Standard Arabic. The multi dialect version, however, was further pretrained on 10 million tweets that were written in different Arabic dialects [58].
- 5.
- ARBERT:
This model was developed by the developer of MARABERT. The two differ in that ARBERT was pretrained on Modern Standard Arabic text only. The text was extracted from Wikipedia, news, and books sources. It has a total size of about 61 gigabytes and 6.2 billion tokens. ARBERT has the same architecture as the Multilingual BERT, with 12 layers of transformers blocks, 768 hidden units, and 12 self-attention heads, but a total of around 163 million trainable parameters [12].
- 6.
- XLM-RoBERTa:
This model was developed by researchers from Facebook. Similar to Multilingual BERT, XLM-RoBERTa supports multiple languages (100 languages), including Arabic. It was pretrained on Wikipedia and Common Crawl data. The Arabic pretraining corpus is in Modern Standard Arabic and it has 2869 tokens that sum up to around 28 gigabytes of data. The base version of the model has 12 layers of transformers blocks, 768 hidden units, 12 self-attention heads, and around 270 million trainable parameters. While the model optimizes the BERT approach, it removes the NSP task and introduces a dynamic masking technique [67].
- 7.
- QARiB:
The model was developed for the Arabic language specifically, by researchers from the Qatar Computing Research Institute. Similar to MARBERT, QARiB was pretrained on text in both Modern Standard Arabic and various Arabic dialects. The Modern Standard Arabic text includes news and movie/TV subtitles, while the dialectical text includes tweets. The model has the same architecture as the Multilingual BERTB. The latest version of the model was pretrained on a corpus of 14 billion tokens, which makes up around 127 gigabyte of text [40]. This is the second largest pretraining corpora after MARBERT.
- 8.
- GigaBERT:
The model was originally designed as a bilingual BERT for zero-shot transfer learning from English to Arabic. It was pretrained in both Arabic and English text. The English pretraining data have 6.1 billion tokens, while the Arabic data have 4.3 billion tokens. The Arabic data are on Modern Standard Arabic and are mostly comprised of news, Wikipedia articles, and Common Crawl data. Similar to Multilingual BERT, GigaBERT has 12 layers of transformers blocks with 768 hidden units each. It also contains 12 self-attention heads and around 110 million trainable parameters [68].
- 9.
- Arabic ALBERT:
The model is the Arabic version of ALBERT, which stands for A Lite BERT. ALBERT implements two design changes to BERT’s original architecture, i.e., parameter sharing and factorization of the embedding parameterization. These changes produced a model that has almost the same performance as the original BERT but has only a fraction of its parameters and computational cost. Arabic ALBERT has three different versions: the base one has 12 layers of transformers blocks, 768 hidden units each, 12 self-attention heads, and only 12 million trainable parameters. The model was pretrained on a Modern Standard Arabic corpus that has 4.4 billion tokens. The data are from Wikipedia articles and Common Crawl data [34,69].
4.2. How Effective Are They for Classifying Arabic Text?
In the majority of the 66 comparisons that were performed in the included studies, Arabic BERT models showed superior performance for classifying Arabic text over the other machine-learning models. Even in the few comparisons in which the used BERT model did not perform particularly well, the reason does not seem to be the BERT technique itself, but rather the specific Arabic BERT model that was used, as in most of these comparisons the used model was Multilingual BERT. As was discussed earlier, Multilingual BERT was not designed for Arabic specifically, but rather supports a large number of languages, including Arabic. The superior performance of Arabic BERT models seems to be related to the unique features of the BERT technique, i.e., its ability to be pretrained from the unlabeled text that is enormously available on the web and its ability to predict words conditioned on both their left and right context [3,5]. This finding is consistent with the many prior studies that found BERT models outperformed other machine learning models in a variety of natural language processing tasks including text classification [70,71]. This indicates that researchers and practitioners should have BERT among their first options for Arabic text classification tasks.
BERT models that were pretrained for the Arabic language specifically, e.g., AraBERT and MARBERT, showed much better performance than those that support multiple languages, i.e., Multilingual BERT and XLM-RoBERTa. An obvious explanation for this is the size of the pretraining corpora that were used to train these models. While Multilingual BERT and XLM-RoBERTa have 7292 and 2869 tokens in their pretraining corpus, respectively, AraBERT, for example, was pretrained with a corpus that has 2.7 billion tokens. This agrees with the results of studies on other languages. Virtanen, et al. [72] and Martin, et al. [73], for example, found monolingual BERT models that were designed specifically for Finnish and French outperformed Multilingual BERT on the natural language processing tasks, including text classification.
Using Arabic BERT models as feature-extraction approaches seems to yield better results than finetuning these models. In three out of four comparisons between the two approaches (feature extraction vs. finetuning), the feature extraction gave a better performance. However, this finding should be taken with caution considering the very few studies that compared the two approaches. It is also different than the finding of the developer of the original BERT model [3] who compared the two approaches and reported that their performance is comparable, with feature extraction being 0.3 F1 behind finetuning.
Arabic BERT models did not show significant differences in performance at multi-class classification compared to binary classification. The highest difference in performance was scored by Multilingual BERT. It had an average F1 score of 0.566 at multi-class classification and an average of 0.715 at binary classification. Most of the other models, however, scored slight differences in performance in the two classification tasks. For example, AraBERT had an average F1 score of 0.715 at multi-class classification compared to an average of 0.794 at binary classification. There is also the case of MARBERT, where the average F1 Score of the multi-class classification (0.724) was slightly higher than the one of binary classification (0.69). This indicates that the BERT technique is suitable for both Arabic multi-class and binary classification.
Considering the performance of all nine models, they can be classified into low-performing models (the ones with an average F1 Score < 0.7) and high-performing models (the ones with an average F1 Score ≥ 0.7). The low-performing models include Multilingual BERT, XLM-RoBERTa, Arabic ALBERT, and GigaBERT. The first two models were pretrained so they can support over 100 languages each and therefore, as has been explained earlier, had small Arabic pretraining corpuses which affected their performance. The same applies to Arabic ALBERT, which was pretrained on a slightly smaller corpus compared to the high-performing models. Regarding GigaBERT, it was not designed for text classification but rather as a bilingual BERT for zero-shot transfer learning from English to Arabic.
The high-performing models include AraBERT, MARBERT, ArabicBERT, ARBERT, and QARiB. A common feature that these high-performing models share is that they were all pretrained on large Arabic corpora. By looking at the number of times each one of them outperformed the other models, it can be said that MARBERT has the best performance of the other four. It is followed by QARiB then ARBERT. In fourth place comes AraBERT, and lastly, ArabicBERT. MARBERT and QARiB are the only models that were pretrained on both Modern Standard Arabic and dialectical Arabic corpus. This seems to have had a positive impact on their performance. The other three models, i.e., ARBERT, AraBERT, and ArabicBERT, were only pretrained on Modern Standard Arabic corpus. Therefore, when dealing with the testing datasets in which the majority of them contained dialectical text, MARBERT and QARiB were able to perform slightly better than ARBERT, AraBERT, and ArabicBERT.
A final point worth mentioning is that a large pretraining corpus does not always lead to a better performance. Version 1 of AraBERT, which was pretrained on around 23 gigabytes of text, showed better performance than ArabicBERT, which was pretrained on 95 gigabytes of text. Out of the six comparisons that included both models, AraBERT was able to outperform ArabicBERT in five comparisons (83%). Therefore, it can be said that the quality of the pretraining data has a significant impact on the performance of the BERT model.
4.3. How Effective Are They Compared to the Original English BERT Models?
The performance of the Arabic BERT models, as was found in the reviewed articles, is no different than the performance of the original English BERT model. The highest performance on a binary classification was scored by AraBERT (accuracy = 0.997, F1 Score = 0.981) on a dataset of 134,222 tweets classified as either spam or ham. The highest performance on a multi-class classification was also scored by AraBERT (accuracy = 0.99, F1 Score = 0.99) on a dataset of 22,429 articles classified by topics, e.g., economic, science, and low. Close results were reported for the English language in a comprehensive review conducted by Minaee, Kalchbrenner, Cambria, Nikzad, Chenaghlu and Gao [70]. They reported that the BERT-base model was able to achieve an accuracy score of 0.981 on the Yelp dataset that contained around 600,000 businesses reviews classified into two classes, i.e., negative and positive. For multi-class classification, Minaee et al. reported that the BERT- large model scored an accuracy score of 0.993 on the DBpedia dataset that contained around 630,000 items, each with a 14-class label.
This excellent performance was somewhat surprising considering the fact that the Arabic language is normally classified as a low-resource language that does not have a large amount of resources available on the web [74,75,76]. It seems that this classification is not valid anymore. The Developers of the Arabic BERT models were able to find billions of tokens of text to train their models. Wikipedia and news websites provided a plethora of text for training. The social media platform Twitter was also a major source of data. According to the latest report from Statista [77], two Arabic countries, i.e., Saudi Arabia and Egypt, are among the top leading countries based on the number of Twitter users as of January 2022.
Despite the excellent performance of Arabic BERT models compared to the original English BERT, two shortcomings of the included studies have to be highlighted. First, while English BERT was evaluated by a variety of long and short text corpus [70,78], the vast majority of the datasets that were used to evaluate the performance of the Arabic BERT models had short text corpus. In fact, only two datasets had a long text corpus. Therefore, the data that were found in the reviewed articles were not sufficient to judge the performance of Arabic BERT models when dealing with documents that had large text. According to Rao, et al. [79], short text has unique features that differ from long text including the syntactical structure, sparse nature, noise words, and the use of colloquial terminologies. The second shortcoming of the included studies is related to the type of data in the evaluation datasets. Unlike English BERT which has been evaluated with datasets from different knowledge domains [70,71], the vast majority of the datasets that have been used to evaluate Arabic BERT models had tweets extracted from the Twitter platform. Therefore, it is not clear whether the current Arabic BERT models are suitable to be applied in a variety of application domains.
5. Implications for Future Research
The outcomes of this systematic review have opened up new research areas for further improvements and future work. First, the nine models that were identified in this review are general-purpose BERT models that were pretrained on data from Wikipedia, Common Crawl, and social media posts. Therefore, it is most likely that the high performance that they showed will not be achieved when they are applied in specific domains such as medical, financial law, and industry. Lee, et al. [80], for example, found that applying the original English BERT model to biomedical corpora did not yield satisfactory results due to a word-distribution shift from general domain corpora to biomedical corpora. They developed a new BERT model that they called BioBERT. The model was pretrained on large-scale biomedical corpora and therefore was able to outperform the original BERT model in a variety of biomedical natural language processing tasks. It would be interesting to investigate domain-specific Arabic BERT models, if any, evaluate them on text classification tasks, and explore the different domains in which more models are needed.
It would be also interesting to investigate the impact of the quality of pretraining text on the performance of the pretrained model. As explained in the previous section, a large pretraining corpus does not always lead to a better performance. Previous studies also found that improving performance by relying on more pretraining data is very expensive because of the diminishing returns of such an approach [81,82]. Pretraining BERT models costs substantial time and money. The Arabic language is a very rich language that contains millions of words [83]. Therefore, it seems that careful selection of the type and amount of pretraining data would have a substantial impact on the performance of Arabic BERT models. More studies in this area are needed.
In addition, the study showed that using Arabic BERT models as a feature extraction approach mostly yields better results than finetuning. However, two issues should be noted regarding this finding. First, only few studies in this review compared the two approaches. Second, the finding does not agree with previous studies in other languages such as English and Chinese that compared the two approaches [3,84]. Therefore, more studies in this regard should be conducted to confirm this finding and also to explore when and how each approach would perform the best.
Furthermore, this review shows the need to develop more labeled datasets for Arabic natural language processing tasks. There is a relatively small number of Arabic datasets available for this type of task compared to English datasets. The majority of the available Arabic datasets, as found in this review, contain tweets only. According to Li, Peng, Li, Xia, Yang, Sun, Yu and He [71], the availability of labeled datasets for natural language processing tasks is a main driving force for the rapid advancement in this research field.
Lastly, none of the reviewed studies provided insights into how the morphological, syntactic, and orthographic features of Arabic versus English would influence the performance of BERT models. As these features differ greatly between the two languages [85,86], more research about their impact on the performance of BERT models is needed.
6. Conclusions
BERT proved to be an invaluable technique in natural languages processing. Most of the research, however, has looked at applying BERT to the resource-rich English language. Therefore, an analysis of the state-of-the-art application of BERT to Arabic text classification was conducted. The aim was to: (1) identify Bert models that have been used for Arabic text classification, (2) compare their performance, and (3) understand how effective they are compared to the original English BERT models. To the best of the author’s knowledge, this is the first systematic review on this topic. The review includes 48 articles and yields several findings. First, it identified nine different models that could be used for classifying Arabic text. Two of them support many languages, including Arabic; one supports both Arabic and English; while the remaining six were developed specifically for the Arabic language. In most of the reviewed studies, the models showed high performance comparable to that of the English BERT models. The highest performing models, in descending order of performance, were MARBERT, QARiB, ARBERT, AraBERT, and ArabicBERT. A common feature that these high-performing models share is that they were all pretrained for Arabic and on a large Arabic corpus. The first three models were pretrained on both Modern Standard Arabic and a dialectical Arabic corpus, which might have improved their performance further. Synthesizing the existing research on text classification using Arabic BERT models, this study also identified new research areas for further improvements and future work.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
I would like to thank Ehsan Ahmad and Abdulbasid Banga for their invaluable help in conducting this systematic review.
Conflicts of Interest
The author declares no conflict of interest.
References
- Vijayan, V.K.; Bindu, K.; Parameswaran, L. A comprehensive study of text classification algorithms. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017; pp. 1109–1113. [Google Scholar]
- El-Din, D.M.; Hussein, M. A survey on sentiment analysis challenges. J. King Saud Univ.-Eng. Sci. 2018, 30, 330–338. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pretraining of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in BERTology: What We Know About How BERT Works. Trans. Assoc. Comput. Linguist. 2020, 8, 842–866. [Google Scholar] [CrossRef]
- Zaib, M.; Sheng, Q.Z.; Emma Zhang, W. A short survey of pretrained language models for conversational AI-a new age in NLP. In Proceedings of the Australasian Computer Science Week Multiconference, Canberra, Australia, 1–5 February 2016; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–4. [Google Scholar]
- Alshalan, R.; Al-Khalifa, H. A deep learning approach for automatic hate speech detection in the saudi twittersphere. Appl. Sci. 2020, 10, 8614. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V.J. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T.J. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Almuqren, L. Twitter Analysis to Predict the Satisfaction of Saudi Telecommunication Companies’ Customers. Ph.D. Thesis, Durham University, Durham, UK, 2021. [Google Scholar]
- Pelicon, A.; Shekhar, R.; Škrlj, B.; Purver, M.; Pollak, S. Investigating cross-lingual training for offensive language detection. PeerJ Comput. Sci. 2021, 7, e559. [Google Scholar] [CrossRef]
- Antoun, W.; Baly, F.; Hajj, H. Arabert: Transformer-based model for arabic language understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Abdul-Mageed, M.; Elmadany, A.; Nagoudi, E.M.B. ARBERT & MARBERT: Deep bidirectional transformers for Arabic. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 1–6 August 2021; pp. 7088–7105. [Google Scholar]
- James, K.L.; Randall, N.P.; Haddaway, N.R. A methodology for systematic mapping in environmental sciences. Environ. Evid. 2016, 5, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Moher, D.; Altman, D.G.; Liberati, A.; Tetzlaff, J. PRISMA statement. Epidemiology 2011, 22, 128. [Google Scholar] [CrossRef] [Green Version]
- Paez, A. Gray literature: An important resource in systematic reviews. J. Evid.-Based Med. 2017, 10, 233–240. [Google Scholar] [CrossRef] [PubMed]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; EBSE: Durham, UK, 2007. [Google Scholar]
- Zhou, Y.; Zhang, H.; Huang, X.; Yang, S.; Babar, M.A.; Tang, H. Quality assessment of systematic reviews in software engineering: A tertiary study. In Proceedings of the 19th International Conference on Evaluation and Assessment in Software Engineering, Nanjing, China, 27–29 April 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1–14. [Google Scholar]
- Bondas, T.; Hall, E.O. Challenges in approaching metasynthesis research. Qual. Health Res. 2007, 17, 113–121. [Google Scholar] [CrossRef] [PubMed]
- Morgan, J.A.; Olagunju, A.T.; Corrigan, F.; Baune, B.T. Does ceasing exercise induce depressive symptoms? A systematic review of experimental trials including immunological and neurogenic markers. J. Affect. Disord. 2018, 234, 180–192. [Google Scholar] [CrossRef] [PubMed]
- Alammary, A. Blended learning models for introductory programming courses: A systematic review. PLoS ONE 2019, 14, e0221765. [Google Scholar] [CrossRef] [PubMed]
- Bilal, S. A Linguistic System for Predicting Sentiment in Arabic Tweets. In Proceedings of the 2021 3rd International Conference on Natural Language Processing (ICNLP), Beijing, China, 26–28 March 2021; pp. 134–138. [Google Scholar]
- Al-Twairesh, N.; Al-Negheimish, H.J.I.A. Surface and deep features ensemble for sentiment analysis of arabic tweets. IEEE Access 2019, 7, 84122–84131. [Google Scholar] [CrossRef]
- Pàmies Massip, M. Multilingual Identification of Offensive Content in Social Media. Available online: https://www.diva-portal.org/smash/get/diva2:1451543/FULLTEXT01.pdf (accessed on 19 December 2021).
- Moudjari, L.; Akli-Astouati, K.; Benamara, F. An Algerian corpus and an annotation platform for opinion and emotion analysis. In Proceedings of the 12th Language Resources and Evaluation Conference, LREC 2020, Marseille, France, 11–16 May 2020; pp. 1202–1210. [Google Scholar]
- Khalifa, M.; Hassan, H.; Fahmy, A. Zero-Resource Multi-Dialectal Arabic Natural Language Understanding. Int. J. Adv. Comput. Sci. Appl. 2021, 12, 1–15. [Google Scholar] [CrossRef]
- Alshehri, A.; Nagoudi, E.M.B.; Abdul-Mageed, M. Understanding and Detecting Dangerous Speech in Social Media; European Language Resource Association: Paris, France, 2020. [Google Scholar]
- Abdul-Mageed, M.; Zhang, C.; Elmadany, A.; Ungar, L. Toward micro-dialect identification in diaglossic and code-switched environments. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 8–12 November 2020; pp. 5855–5876. [Google Scholar]
- Ameur, M.S.H.; Aliane, H. AraCOVID19-MFH: Arabic COVID-19 Multi-label Fake News & Hate Speech Detection Dataset. Procedia Comput. Sci. 2021, 189, 232–241. [Google Scholar]
- Moudjari, L.; Karima, A.-A. An Experimental Study On Sentiment Classification Of Algerian Dialect Texts. Procedia Comput. Sci. 2020, 176, 1151–1159. [Google Scholar] [CrossRef]
- Alsafari, S.; Sadaoui, S.; Mouhoub, M. Deep learning ensembles for hate speech detection. In Proceedings of the 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), Baltimore, MD, USA, 9–11 November 2020; pp. 526–531. [Google Scholar]
- Abdelali, A.; Mubarak, H.; Samih, Y.; Hassan, S.; Darwish, K. QADI: Arabic dialect identification in the wild. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 1–10. [Google Scholar]
- Alsafari, S.; Sadaoui, S.; Mouhoub, M.; Media. Hate and offensive speech detection on Arabic social media. Online Soc. Netw. 2020, 19, 100096. [Google Scholar] [CrossRef]
- Mubarak, H.; Hassan, S.; Abdelali, A. Adult content detection on arabic twitter: Analysis and experiments. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 136–144. [Google Scholar]
- Farha, I.A.; Magdy, W. Benchmarking transformer-based language models for Arabic sentiment and sarcasm detection. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 21–31. [Google Scholar]
- Uyangodage, L.; Ranasinghe, T.; Hettiarachchi, H. Transformers to fight the COVID-19 infodemic. Available online: https://arxiv.org/pdf/2104.12201.pdf (accessed on 4 December 2021).
- Obied, Z.; Solyman, A.; Ullah, A.; Fat’hAlalim, A.; Alsayed, A. BERT Multilingual and Capsule Network for Arabic Sentiment Analysis. In Proceedings of the 2020 International Conference on Computer, Control, Electrical, and Electronics Engineering (ICCCEEE), Khartoum, Sudan, 26–28 February 2021; pp. 1–6. [Google Scholar]
- Mubarak, H.; Rashed, A.; Darwish, K.; Samih, Y.; Abdelali, A. Arabic Offensive Language on Twitter: Analysis and Experiments. Available online: https://arxiv.org/pdf/2004.02192.pdf (accessed on 17 November 2021).
- Safaya, A.; Abdullatif, M.; Yuret, D. Kuisail at semeval-2020 task 12: Bert-cnn for offensive speech identification in social media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 2054–2059. [Google Scholar]
- El-Alami, F.-z.; El Alaoui, S.O.; Nahnahi, N.E. Contextual semantic embeddings based on fine-tuned AraBERT model for Arabic text multi-class categorization. J. King Saud Univ. Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Abdelali, A.; Hassan, S.; Mubarak, H.; Darwish, K.; Samih, Y. Pre-training bert on arabic tweets: Practical considerations. arXiv 2021, arXiv:2102.10684. [Google Scholar]
- Mansour, M.; Tohamy, M.; Ezzat, Z.; Torki, M. Arabic dialect identification using BERT fine-tuning. In Proceedings of the Fifth Arabic Natural Language Processing Workshop, Barcelona, Spain, 12 December 2020; pp. 308–312. [Google Scholar]
- Balaji, N.N.A.; Bharathi, B. Semi-supervised fine-grained approach for Arabic dialect detection task. In Proceedings of the Fifth Arabic Natural Language Processing Workshop, Barcelona, Spain, 12 December 2020; pp. 257–261. [Google Scholar]
- Abuzayed, A.; Al-Khalifa, H. Sarcasm and sentiment detection in Arabic tweets using BERT-based models and data augmentation. In Proceedings of the sixth Arabic natural language processing workshop, Kyiv, Ukraine, 19 April 2021; pp. 312–317. [Google Scholar]
- Saeed, H.H.; Calders, T.; Kamiran, F. OSACT4 shared tasks: Ensembled stacked classification for offensive and hate speech in Arabic tweets. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection, Marseille, France, 12 May 2020; pp. 71–75. [Google Scholar]
- Zhang, C.; Abdul-Mageed, M. No army, no navy: Bert semi-supervised learning of arabic dialects. In Proceedings of the Fourth Arabic Natural Language Processing Workshop, Florence, Italy, 1 August 2019; pp. 279–284. [Google Scholar]
- Naski, M.; Messaoudi, A.; Haddad, H.; BenHajhmida, M.; Fourati, C.; Mabrouk, A.B.E. iCompass at Shared Task on Sarcasm and Sentiment Detection in Arabic. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 381–385. [Google Scholar]
- Hassan, S.; Samih, Y.; Mubarak, H.; Abdelali, A. ALT at SemEval-2020 task 12: Arabic and English offensive language identification in social media. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 1891–1897. [Google Scholar]
- Faraj, D.; Abdullah, M. Sarcasmdet at sarcasm detection task 2021 in arabic using arabert pretrained model. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 345–350. [Google Scholar]
- Israeli, A.; Nahum, Y.; Fine, S.; Bar, K. The IDC System for Sentiment Classification and Sarcasm Detection in Arabic. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 370–375. [Google Scholar]
- Aldjanabi, W.; Dahou, A.; Al-qaness, M.A.; Abd Elaziz, M.; Helmi, A.M.; Damaševičius, R. Arabic Offensive and Hate Speech Detection Using a Cross-Corpora Multi-Task Learning Model. Informatics 2021, 8, 69. [Google Scholar] [CrossRef]
- Elgabry, H.; Attia, S.; Abdel-Rahman, A.; Abdel-Ate, A.; Girgis, S. A contextual word embedding for Arabic sarcasm detection with random forests. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 340–344. [Google Scholar]
- Alam, F.; Shaar, S.; Dalvi, F.; Sajjad, H.; Nikolov, A.; Mubarak, H.; Martino, G.D.S.; Abdelali, A.; Durrani, N.; Darwish, K. Fighting the COVID-19 infodemic: Modeling the perspective of journalists, fact-checkers, social media platforms, policy makers, and the society. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing., Punta Cana, Dominican Republic, 7–11 November 2021. [Google Scholar]
- Al-Yahya, M.; Al-Khalifa, H.; Al-Baity, H.; AlSaeed, D.; Essam, A. Arabic Fake News Detection: Comparative Study of Neural Networks and Transformer-Based Approaches. Complexity 2021, 2021. [Google Scholar] [CrossRef]
- Mulki, H.; Ghanem, B.J. Let-mi: An Arabic Levantine Twitter dataset for misogynistic language. arXiv 2021, arXiv:2103.10195. [Google Scholar]
- Mubarak, H.; Abdelali, A.; Hassan, S.; Darwish, K. Spam detection on arabic twitter. In Proceedings of the International Conference on Social Informatics, Pisa, Italy, 6–9 October 2020; pp. 237–251. [Google Scholar]
- Mubarak, H.; Hassan, S. Arcorona: Analyzing arabic tweets in the early days of coronavirus (COVID-19) pandemic. In Proceedings of the 12th International Workshop on Health Text Mining and Information Analysis, Virtual Conference, Online, 19–20 April 2021. [Google Scholar]
- El-Alami, F.-z.; El Alaoui, S.O.; Nahnahi, N.E. A multilingual offensive language detection method based on transfer learning from transformer fine-tuning model. J. King Saud Univ. Comput. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Al-Twairesh, N. The Evolution of Language Models Applied to Emotion Analysis of Arabic Tweets. Information 2021, 12, 84. [Google Scholar] [CrossRef]
- Husain, F.; Uzuner, O. Leveraging offensive language for sarcasm and sentiment detection in Arabic. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 364–369. [Google Scholar]
- Wadhawan, A. Arabert and farasa segmentation based approach for sarcasm and sentiment detection in arabic tweets. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021. [Google Scholar]
- Bashmal, L.; AlZeer, D. ArSarcasm Shared Task: An Ensemble BERT Model for SarcasmDetection in Arabic Tweets. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 323–328. [Google Scholar]
- Gaanoun, K.; Benelallam, I. Sarcasm and Sentiment Detection in Arabic language A Hybrid Approach Combining Embeddings and Rule-based Features. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 351–356. [Google Scholar]
- Alharbi, A.I.; Lee, M. Multi-task learning using a combination of contextualised and static word embeddings for arabic sarcasm detection and sentiment analysis. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 318–322. [Google Scholar]
- Abdel-Salam, R. Wanlp 2021 shared-task: Towards irony and sentiment detection in arabic tweets using multi-headed-lstm-cnn-gru and marbert. In Proceedings of the Sixth Arabic Natural Language Processing Workshop, Kyiv, Ukraine, 19 April 2021; pp. 306–311. [Google Scholar]
- Wu, S.; Dredze, M. Are all languages created equal in multilingual BERT? In Proceedings of the 5th Workshop on Representation Learning for NLP, Online, 9 July 2020; pp. 120–130. [Google Scholar]
- Abdaoui, A.; Pradel, C.; Sigel, G. Load What You Need: Smaller Versions of Multilingual BERT. In Proceedings of the SustaiNLP: Workshop on Simple and Efficient Natural Language Processing, Online, 10 November 2021; pp. 119–123. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 8440–8451. [Google Scholar]
- Lan, W.; Chen, Y.; Xu, W.; Ritter, A. An Empirical Study of Pre-trained Transformers for Arabic Information Extraction. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 4727–4734. [Google Scholar]
- Safaya, A. Arabic-ALBERT. arXiv 2022, arXiv:2201.07434. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning--based text classification: A comprehensive review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Traditional to Deep Learning. ACM Trans. Intell. Syst. Technol. 2021, 37. [Google Scholar] [CrossRef]
- Virtanen, A.; Kanerva, J.; Ilo, R.; Luoma, J.; Luotolahti, J.; Salakoski, T.; Ginter, F.; Pyysalo, S. Multilingual is not enough: BERT for Finnish. arXiv 2019, arXiv:1912.07076. [Google Scholar]
- Martin, L.; Muller, B.; Suárez, P.J.O.; Dupont, Y.; Romary, L.; De La Clergerie, É.V.; Seddah, D.; Sagot, B. CamemBERT: A Tasty French Language Model. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7203–7219. [Google Scholar]
- Ranasinghe, T.; Zampieri, M. Multilingual offensive language identification for low-resource languages. Trans. Asian Low-Resour. Lang. Inf. Processing 2021, 21, 1–13. [Google Scholar] [CrossRef]
- Jain, M.; Mathew, M.; Jawahar, C. Unconstrained scene text and video text recognition for arabic script. In Proceedings of the 2017 1st International Workshop on Arabic Script Analysis and Recognition (ASAR), Nancy, France, 3–5 April 2017; pp. 26–30. [Google Scholar]
- Himdi, H.; Weir, G.; Assiri, F.; Al-Barhamtoshy, H. Arabic fake news detection based on textual analysis. Arab. J. Sci. Eng. 2022, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Statista. Leading Countries Based on Number of Twitter Users as of January 2022. Available online: https://www.statista.com/statistics/242606/number-of-active-twitter-users-in-selected-countries/ (accessed on 12 January 2022).
- Moores, B.; Mago, V. A Survey on Automated Sarcasm Detection on Twitter. arXiv 2022, arXiv:2202.02516. [Google Scholar]
- Rao, Y.; Xie, H.; Li, J.; Jin, F.; Wang, F.L.; Li, Q. Social emotion classification of short text via topic-level maximum entropy model. Inf. Manag. 2016, 53, 978–986. [Google Scholar] [CrossRef]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019, 36, 1234–1240. [Google Scholar] [CrossRef]
- Schwartz, R.; Dodge, J.; Smith, N.A.; Etzioni, O. Green AI. Commun. ACM 2020, 63, 54–63. [Google Scholar] [CrossRef]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Al-Maimani, M.R.; Al Naamany, A.; Bakar, A.Z.A. Arabic information retrieval: Techniques, tools and challenges. In Proceedings of the 2011 IEEE GCC Conference and Exhibition (GCC), Dubai, United Arab Emirates, 19–22 February 2011; pp. 541–544. [Google Scholar]
- Wang, Y.; Sun, Y.; Ma, Z.; Gao, L.; Xu, Y. Named Entity Recognition in Chinese Medical Literature Using Pretraining Models. Sci. Program. 2020, 2020, 8812754. [Google Scholar] [CrossRef]
- Khemakhem, I.T.; Jamoussi, S.; Hamadou, A.B. Integrating morpho-syntactic features in English-Arabic statistical machine translation. In Proceedings of the Second Workshop on Hybrid Approaches to Translation, Sofia, Bulgaria, 8 August 2013; pp. 74–81. [Google Scholar]
- Akan, M.F.; Karim, M.R.; Chowdhury, A.M.K. An analysis of Arabic-English translation: Problems and prospects. Adv. Lang. Lit. Stud. 2019, 10, 58–65. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).