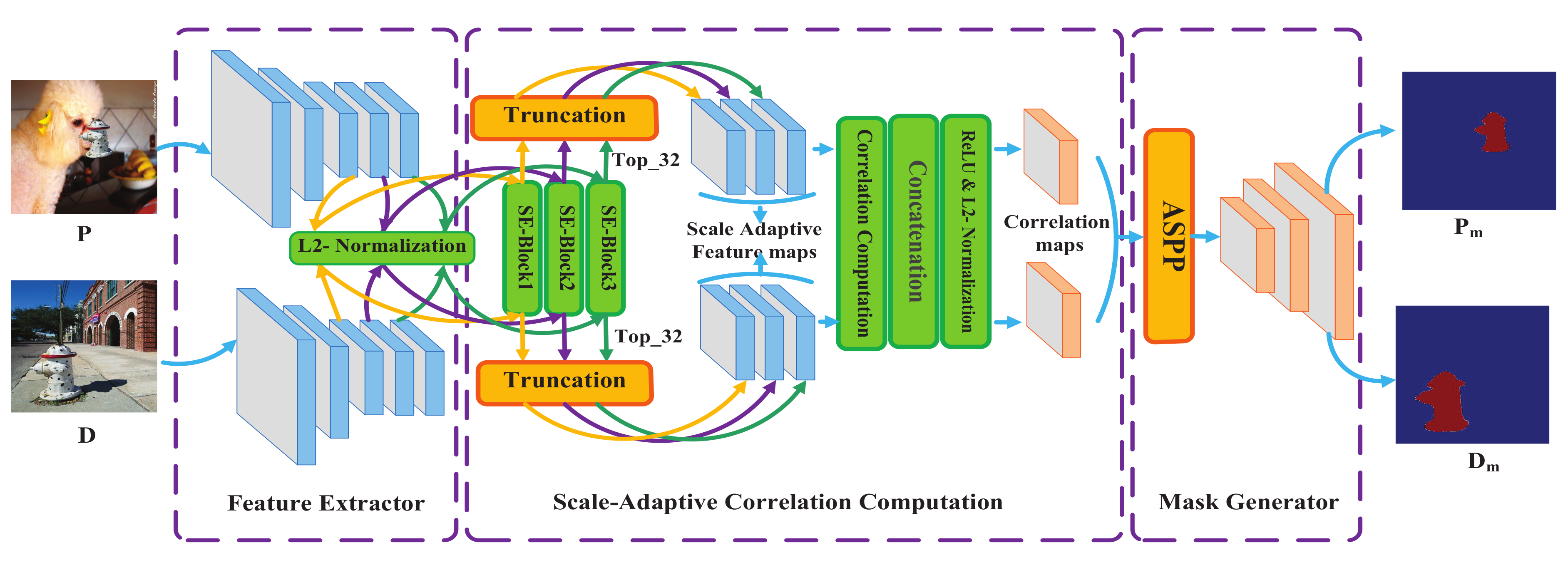
Our method has three components: the feature extractor, the scale-adaptive correlation computation module and the mask generator. The feature extractor employs VGG16, but removes the maxpooling operation while using atrous convolution in the last convolutional block. In
Figure 1, from the feature extractor, three feature maps are generated with the same size. The scale-adaptive correlation computation module adopts SE blocks and truncation operations to break the limit of image size. The mask generator designs an attention-based separable convolutional block based on depthwise separable convolution and spatial attention. Depthwise separable convolution can effectively improve the deep matching, and spatial attention can restore spatial information. In terms of the overall structure, we employ channel attention first, learning ‘what’ in the channel axes, and spatial attention second, learning ‘where’ in the spatial axes, for which can blend cross-channel and spatial information [
30]. Additionally, the pyramid version of SADM is proposed to make full use of multiscale information to improve the ability of multiscale objects location.
3.2. Scale-Adaptive Correlation Computation
As for previous studies, they can not handle arbitrary-sized images. Such as the process of matching response using cross-correlation in DMVN, it uses all pixels of the feature map relative to the size of the image. Similarly, DMAC and AttentionDM continued to use this approach. So, they are all restricted by the size of images. Therefore, distinctly accounting for image scale is essential for improving the model’s ability to process low-resolution and high-resolution images.
In order to address this defect, Liu et al. proposed a sliding window-based matching strategy to process high-resolution images, but it causes high computational complexity [
9]. In this paper, we employ correlation computation with SE blocks and truncation operations to boost our model’s ability to process arbitrary-sized images.
F,
F,
F (
k ∈ {1, 2}) are extracted from the feature extractor, and then each feature map has to go through the L2-normalization, SE blocks and truncation operations. At last, we utilize ReLU and L2-normalization to produce the final two correlation maps.
- (1)
SE blocks
For each channel of the convolution feature, SE blocks model their interdependencies explicitly. Specifically, SE blocks take each channel of feature map as a feature detector, then they utilize global information to emphasize informative features or suppress unuseful ones selectively. Before the SE blocks, L2-normalization is conducted:
where
F ∈
,
k ∈{1, 2},
(
,
) ∈
F,
(
,
) ∈
F. And then, we can get two feature maps after standardization,
,
. Next, SE blocks are applied to recalibrate informative features, making an improvement on discriminating features. Based on these above, our SE block has three steps: First, using global average pooling to exploit contextual information. We denote
z ∈
as channelwise statistics, and denote
as homologous channel dimensions feature,
H ×
W, the
cth element of
z is computed with:
This operation, global average pooling, is the simplest aggregation technique to collect local descriptors that can express the whole image. The second step is to capture channelwise dependencies, which consists of a ReLU and a sigmoid activation as a gating mechanism:
where
refers to the ReLU function,
W ∈
and
W ∈
. The third step is to weight the characteristics of each channel, with the weight obtained above. The final output is computed with:
where
= [
,
,⋯,
] and
F(
) indicate the channelwise multiplication between the scalar s
and the feature map
∈
.
- (2)
Correlation-computation with truncation operations
The process of this part is shown in
Figure 3.
and
refer to the feature maps computed from the SE blocks,
(
,
) ∈
,
(
,
) ∈
. The correlation maps are computed by:
where
C is obtained by comparing
(
,
) ∈
and
(
,
) ∈
. Since the corresponding
are not known in advance and most fraction of the features are irrelative, we sort the
C(
,
,
) along the (
h ×
w) channels, and select top-T values:
If apply a curve to show
(
,
), it is supposed to be a monotonic decreasing curve. Once an abrupt drop appeared, it means
(
,
) has matched regions. So, the T channels should include the most drops. Due to the operation of the top-T selection, our network was given the capability of accepting arbitrary-sized images. We summarize above correlation computation as:
This is an example of handling a correlation map between two feature maps. After input
F,
F,
F, the scale-adaptive correlation computation module procedure can be concluded as Algorithm 1.
| Algorithm 1: Scale-Adaptive Correlation Computation |
| Require: Image and |
| 1: “Hierarchical features extraction:” |
| 2: , F, F= Encoder()
|
| 3: , F, F= Encoder()
|
| 4: “Attention weighted feature maps generation for hierarchical features:” |
| 5: for c = 3 to 5 do |
| 6: “L2 normalization of Equation (2)”
|
| 7: = L2_norm(F)
|
| 8: = L2_norm(F)
|
| 9: “Refer to Equations (3)–(5)”
|
| 10: = |
| 11: = |
| 12: end for |
| 13: “Correlation computation based on hierarchical attention weighted feature maps:” |
| 14: for c = 3 to 5 do |
| 15: “Refer to Equation (8) based on Equations (6) and (7)”
|
| 16: = |
| 17: = |
| 18: = |
| 19: = |
| 20: “Concatenate correlation maps”
|
| 21: = |
| 22: = |
| 23: end for |
| 24: “Concatenate hierarchical correlation maps”
|
| 25: |
| 26: |
| 27: “ReLU and L2 normalization”
|
| 28: |
| 29: |
| Ensure: Correlation maps and of and |
In Algorithm 1, each group of the feature map, extracted from the same layer of feature extractor, will through the operation of L2-normalization and SE blocks. And then, for each two feature maps from the same layer, we utilize correlation computation and truncation operations to get two pairs of correlation maps, i.e., , and , are produced from and (n ∈ {1, 2, 3}). Next, concatenating each group of correlation maps, we get two correlation maps, i.e., and (n ∈ {1, 2, 3}). Last, correlation maps , are generated by concatenating and respectively. Since the associated areas should have the same symbol and should all be positive, we employ ReLU to convert negative values to zero. And then apply L2-normalization to access the normalized correlation maps as , . Next, the process of handling these correlation maps will be shown in the next section.
3.3. Mask Generator Based on Attention-Based Separable Convolutional Module
Our mask generator integrates ASPP blocks, maxpooling layers and attention-based separable convolutional blocks to generate high-resolution masks. The architecture and parameter settings are shown in
Figure 4. It consists of an ASPP block, three upsampling layers, three attention-based separable convolutional blocks and a 1 × 1 convolution to reduce channels at last. Additionally, each attention-based separable convolutional block is followed by an L2-normalization layer.
Briefly, ASPP contains several atrous convolution for conducting multiscale objects. As shown in
Figure 5, the attention-based separable convolutional block is applied to generate fine-grained masks, including two layers of depthwise separable convolution and one layer of spatial attention. Depthwise separable convolution can improve the speed and accuracy for deep matching to locate and discriminate regions with less parameters and computation burden. Spatial attention can assign greater weights to critical sections so that the model can focus more attention on it. Qualitatively, this mask generator shows improvement in its ability to address spatial information problems as well as detect edges and small areas. And quantitatively, it reduces computational complexit with less model parameters. In summary, our SADM typically employs attention-based separable convolutional blocks to gain a good tradeoff between localization and detection performance and computation complexity.
- (1)
ASPP.
Before the ASPP block, the correlation computation module produces a feature tensor of size × × 96. ASPP is the first part of the mask generator with three parallel layers of atrous convolution to capture multiscale features, setting atrous rates with [6, 12, 18]. Then the feature maps are concatened into a 1 × 1 convolution to reduce channels.
- (2)
Attention-based separable convolutional block.
The mask generator uses attention-based separable convolutional block for three times, corresponding to the three times of upsampling operations. The design of attention-based separable convolutional block is shown in
Figure 5. It employs depthwise separable convolution for two times first and a spatial attention second, utilizing L2-normalization, ReLU among them.
Depthwise separable convolution. The depthwise separable convolution is shown in
Figure 6. Motivated by the architecture of [
31], we adopt a variant of depthwise separable convolution for our mask generator. Different from ecumenical depthwise separable convolution, we utilize the 1 × 1 pointwise convolution followed by the 3 × 3 depthwise convolution for each input channel and concatenate into the subsequent layers. We apply it to mask generator to reduce the model parameters uttermost. Similar to the Xception network [
31], we employ L2-normalization and ReLU between pointwise convolution and depthwise convolution.
Spatial attention. Spatial attention can capture the spatial dependencies and produce more powerful pixel-level characterization, helping recover the spatial detail information effectively. The detail of spatial attention is shown in
Figure 6. Let
P denote the feature map input to spatial attention blocks,
P(
i,
j) denotes a c-dimensional descriptor at at (
i,
j). Noted that
P ∈
,
i ∈ [1,
h],
j ∈ [1,
w],
h and
w indicate the height and width of the feature map and
h =
w in our work. Prior to reinforce
P using spatial attention, we employ L2-normalization and ReLU to modify it. Then, the first step is to transform
P into two feature spaces by the 1 × 1 convolution layer,
f(
P) =
PW +
and
g(
P) =
PW +
. The similarity between
f(
P) and each
g(
P) is calculated as follows:
In order to normalize these weights, we use a softmax function:
when predicting the
xth region,
denotes the extent that the model attends to the
yth location,
x,
y ∈ [1,
h ×
w]. The final attention is implemented as a 1 × 1 convolutional layer and computed as:
In the above equation,
. And
,
,
∈
,
∈
,
∈
,
∈
. After attention reinforced, the feature maps is calculated as:
where
= {
,
,⋯,
},
represents a scale parameter that can be initialized as zero and gradually learn a proper value.
3.4. Pyramid Version of SADM
The localization of object boundaries is vital for tampering detection. Specially, when multiscale objects appear in the image, it will increases the probe sophistication of tampered regions. Score maps play a crucial role in the CISDL task as it can reliably predict the presence and rough positioning of objects. But, score maps are not sensitive to pinpointing the exact outline of the tampered area. In this regime, explicitly accounting for object boundaries across different scales makes an essential contribution to CISDL’s successful handling of large and small objects. There are two main types of study designs to solve multiscale objects prediction challenge. The first approach is to train the model on a dataset that adapts to certain types of transformations, such as shift, rotation, scale, luminance and deformation changes. By applying multiple parallel filters with different rates, the second approach is to harness ASPP to exploit multiscale features. These two approaches have displayed an excellent capacity to represent scale.
In this paper, we employ an alternative method, called the pyramid version of SADM (PSADM), to handle this problem. First, feeding multiple rescaled versions of the original image to parallel module branches with the same parameters. Second, every scale score maps are bilinear interpolated to the original image resolution, converting image classification networks into dense feature extractors without learning any additional parameters, making the training speed of CNN in practice faster. Bilinear interpolation requires two linear transformations, the first one on the X-axis:
where
,
,
,
,
,
. Then find the target point in the region by another linear transformation:
Third, fuse them by taking the average response across scales for each position separately. Finally, a new score map is got. The discussion in the experimental section shows that the pyramid version with scale = {384, 512, 640} achieves the best performance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}